

Dữ liệu thô của Báo cáo trải nghiệm người dùng trên Chrome (CrUX) có trên BigQuery, một cơ sở dữ liệu trên Google Cloud. Để sử dụng BigQuery, bạn cần có dự án GCP và kiến thức cơ bản về SQL.
Trong hướng dẫn này, hãy tìm hiểu cách sử dụng BigQuery để viết truy vấn dựa trên tập dữ liệu CrUX nhằm trích xuất các kết quả chi tiết về trạng thái trải nghiệm người dùng trên web:
- Hiểu cách dữ liệu được sắp xếp
- Viết một truy vấn cơ bản để đánh giá hiệu suất của nguồn gốc
- Viết truy vấn nâng cao để theo dõi hiệu suất theo thời gian
Sắp xếp dữ liệu
Hãy bắt đầu bằng cách xem một truy vấn cơ bản:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
Để chạy truy vấn, hãy nhập truy vấn đó vào trình chỉnh sửa truy vấn rồi nhấn nút "Chạy truy vấn" nút:
Có hai phần của truy vấn này:
SELECT COUNT(DISTINCT origin)có nghĩa là truy vấn số lượng nguồn gốc trong bảng. Nói một cách thẳng thắn, hai URL là một phần của cùng một nguồn gốc nếu chúng có cùng lược đồ, máy chủ lưu trữ và cổng.FROM chrome-ux-report.all.202206chỉ định địa chỉ của bảng nguồn, có ba phần:- Tên dự án trên đám mây
chrome-ux-report, trong đó tất cả dữ liệu CrUX được sắp xếp - Tập dữ liệu
all, đại diện cho dữ liệu ở tất cả các quốc gia - Bảng
202206, năm và tháng của dữ liệu ở định dạng YYYYMM
- Tên dự án trên đám mây
Ngoài ra còn có các tập dữ liệu cho mọi quốc gia. Ví dụ: chrome-ux-report.country_ca.202206 chỉ đại diện cho dữ liệu trải nghiệm người dùng bắt nguồn từ Canada.
Trong mỗi tập dữ liệu, có các bảng cho mỗi tháng kể từ năm 201710. Các bảng mới trong tháng trước theo lịch được xuất bản thường xuyên.
Cấu trúc của bảng dữ liệu (còn gọi là giản đồ) chứa:
- Nguồn gốc, ví dụ:
origin = 'https://www.example.com', thể hiện mức phân bổ trải nghiệm người dùng tổng hợp của tất cả các trang trên trang web đó - Tốc độ kết nối tại thời điểm tải trang, ví dụ:
effective_connection_type.name = '4G' - Loại thiết bị, ví dụ:
form_factor.name = 'desktop' - Bản thân các chỉ số trải nghiệm người dùng
Dữ liệu cho mỗi chỉ số được sắp xếp dưới dạng một mảng các đối tượng. Trong ký hiệu JSON, first_contentful_paint.histogram.bin sẽ có dạng như sau:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
Mỗi vùng chứa chứa thời gian bắt đầu và kết thúc tính bằng mili giây, cũng như mật độ thể hiện tỷ lệ phần trăm trải nghiệm người dùng trong phạm vi thời gian đó. Nói cách khác, 12,34% trải nghiệm FCP cho nguồn gốc, tốc độ kết nối và loại thiết bị giả định này có thời gian dưới 100 mili giây. Tổng của tất cả mật độ thùng là 100%.
Duyệt qua cấu trúc của các bảng trong BigQuery.
Đánh giá hiệu suất
Chúng ta có thể sử dụng kiến thức về giản đồ bảng để viết một truy vấn trích xuất dữ liệu hiệu suất này.
SELECT
fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
effective_connection_type.name = '4G' AND
form_factor.name = 'phone' AND
fcp.start = 0
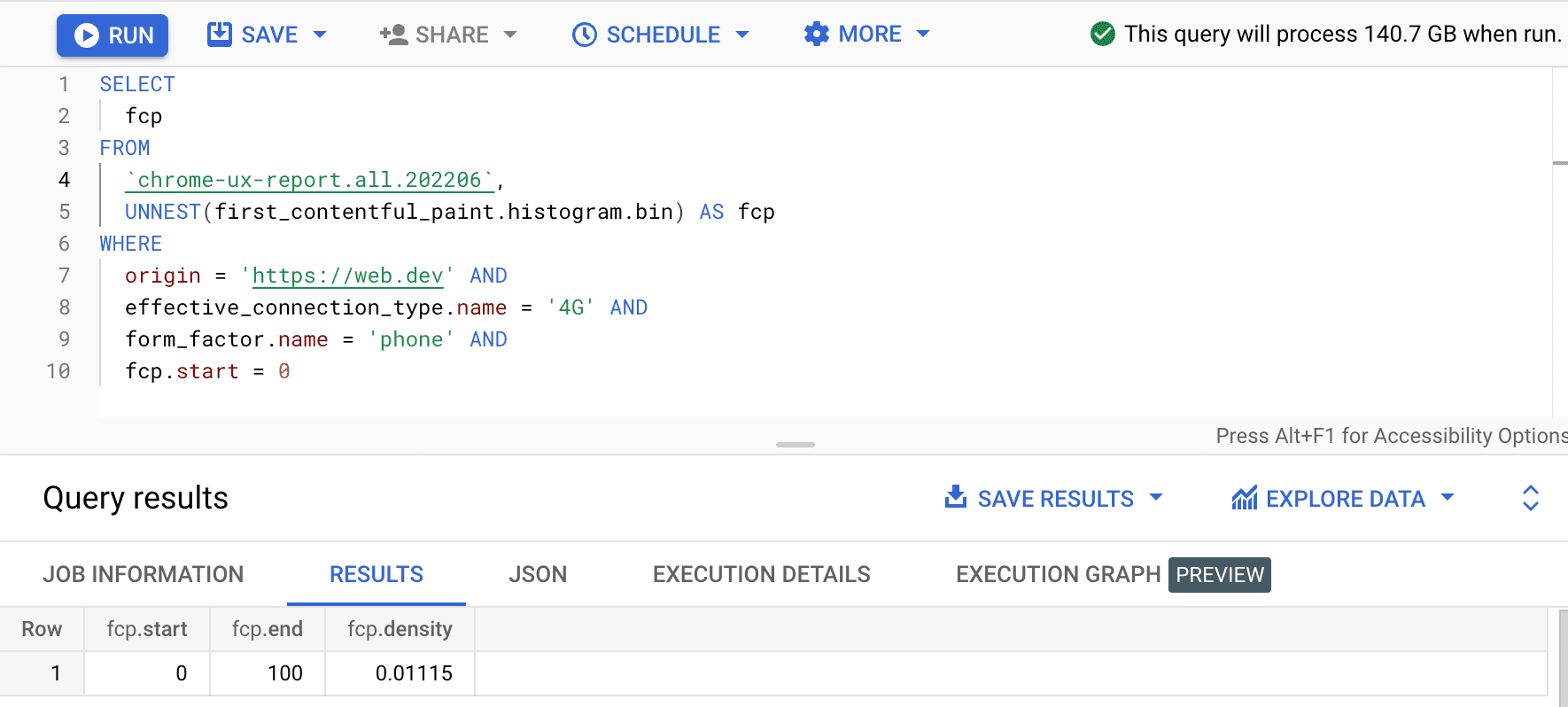
Kết quả là 0.01115, có nghĩa là 1,115% trải nghiệm người dùng trên nguồn gốc này là từ 0 đến 100 mili giây trên 4G và trên điện thoại. Nếu muốn tổng quát hoá truy vấn của mình cho mọi kết nối và loại thiết bị, chúng ta có thể loại chúng khỏi mệnh đề WHERE và sử dụng hàm tổng hợp SUM để cộng tất cả mật độ thùng tương ứng:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
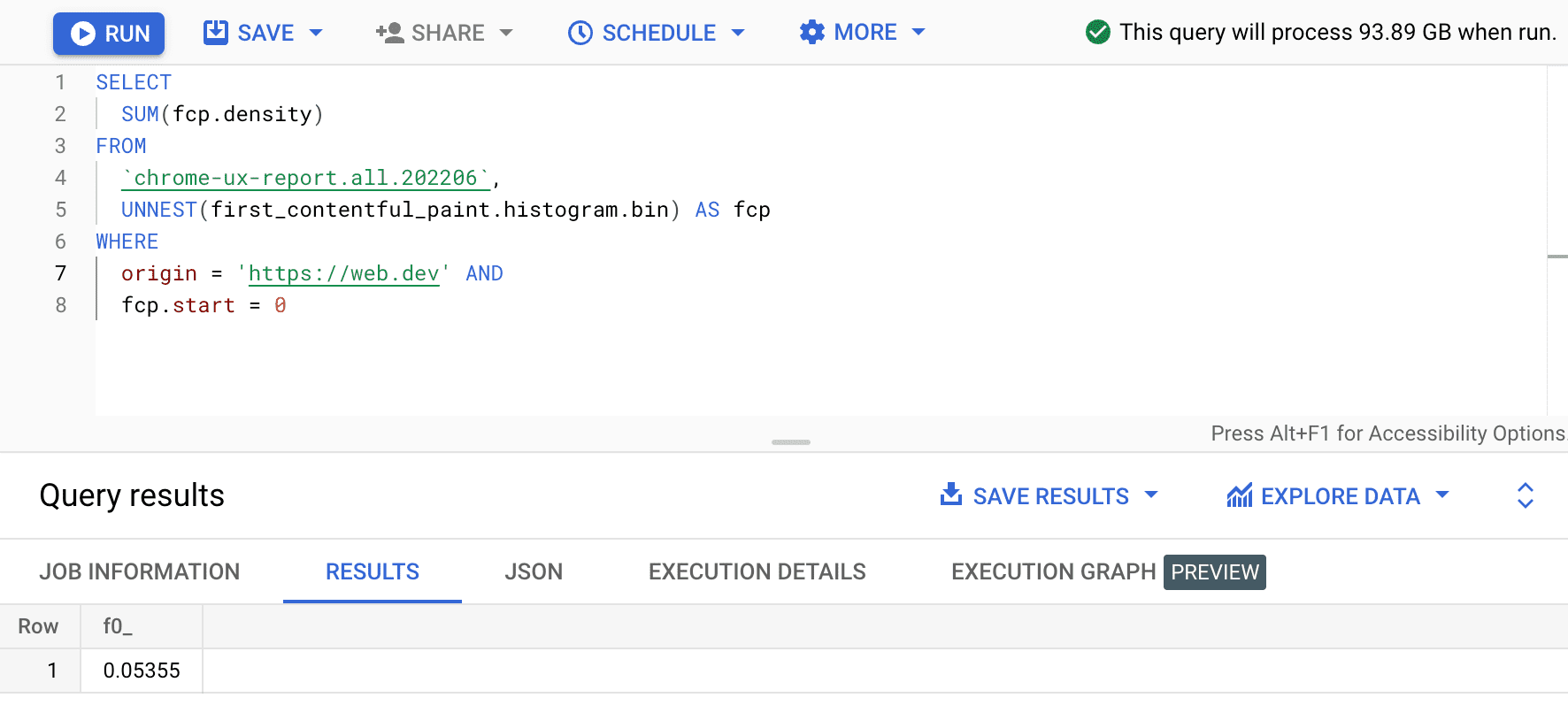
Kết quả là 0.05355, tương đương với 5,355% trên tất cả thiết bị và loại kết nối. Chúng ta có thể sửa đổi truy vấn một chút và thêm mật độ cho tất cả các thùng "nhanh" Phạm vi FCP từ 0 đến 1000 mili giây:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
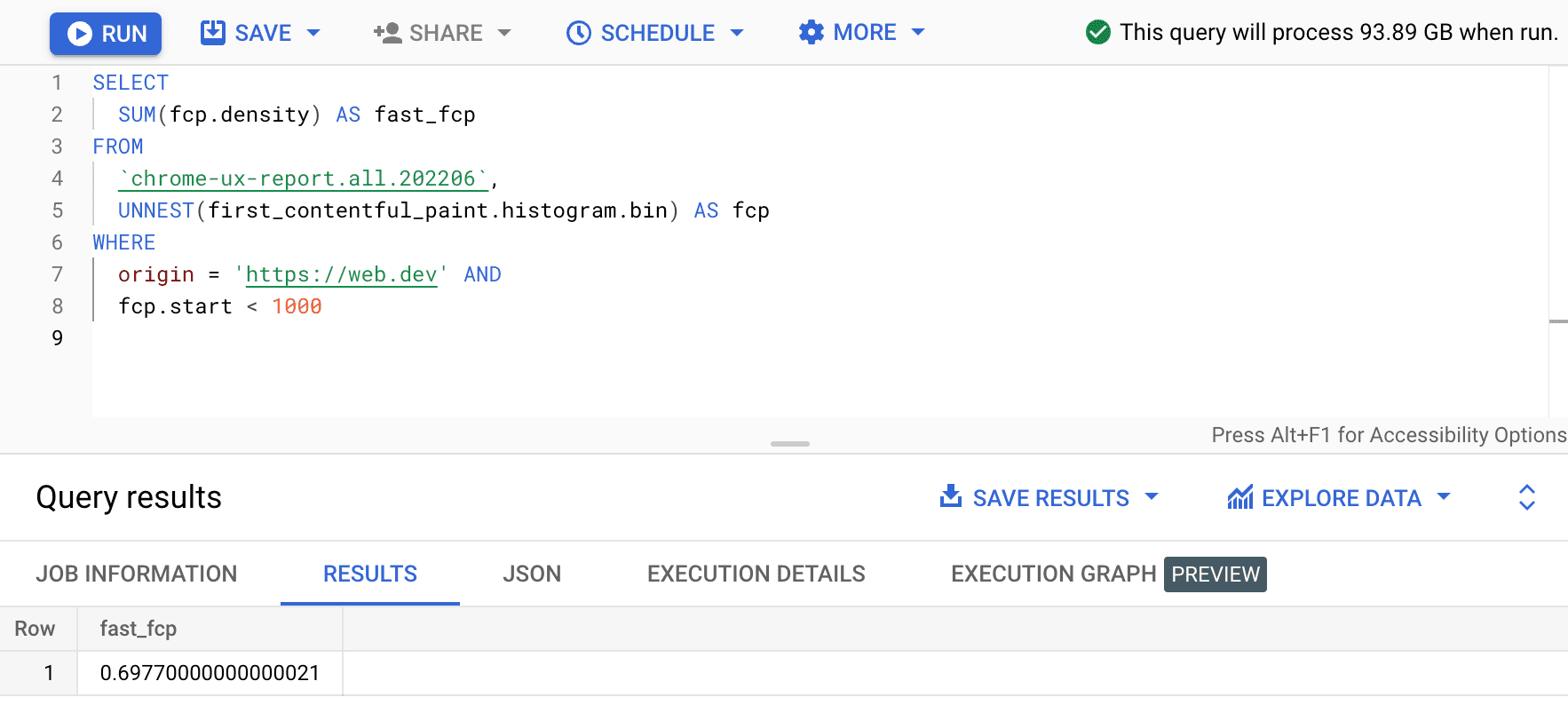
Điều này mang lại cho chúng ta 0.6977. Nói cách khác, 69,77% trải nghiệm người dùng FCP trên web.dev được coi là "nhanh" theo định nghĩa phạm vi FCP.
Theo dõi hiệu suất
Sau khi trích xuất dữ liệu hiệu suất về một nguồn gốc, chúng ta có thể so sánh dữ liệu đó với dữ liệu trong quá khứ trong các bảng cũ. Để làm được việc đó, chúng ta có thể viết lại địa chỉ bảng thành một tháng trước đó hoặc sử dụng cú pháp ký tự đại diện để truy vấn tất cả các tháng:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
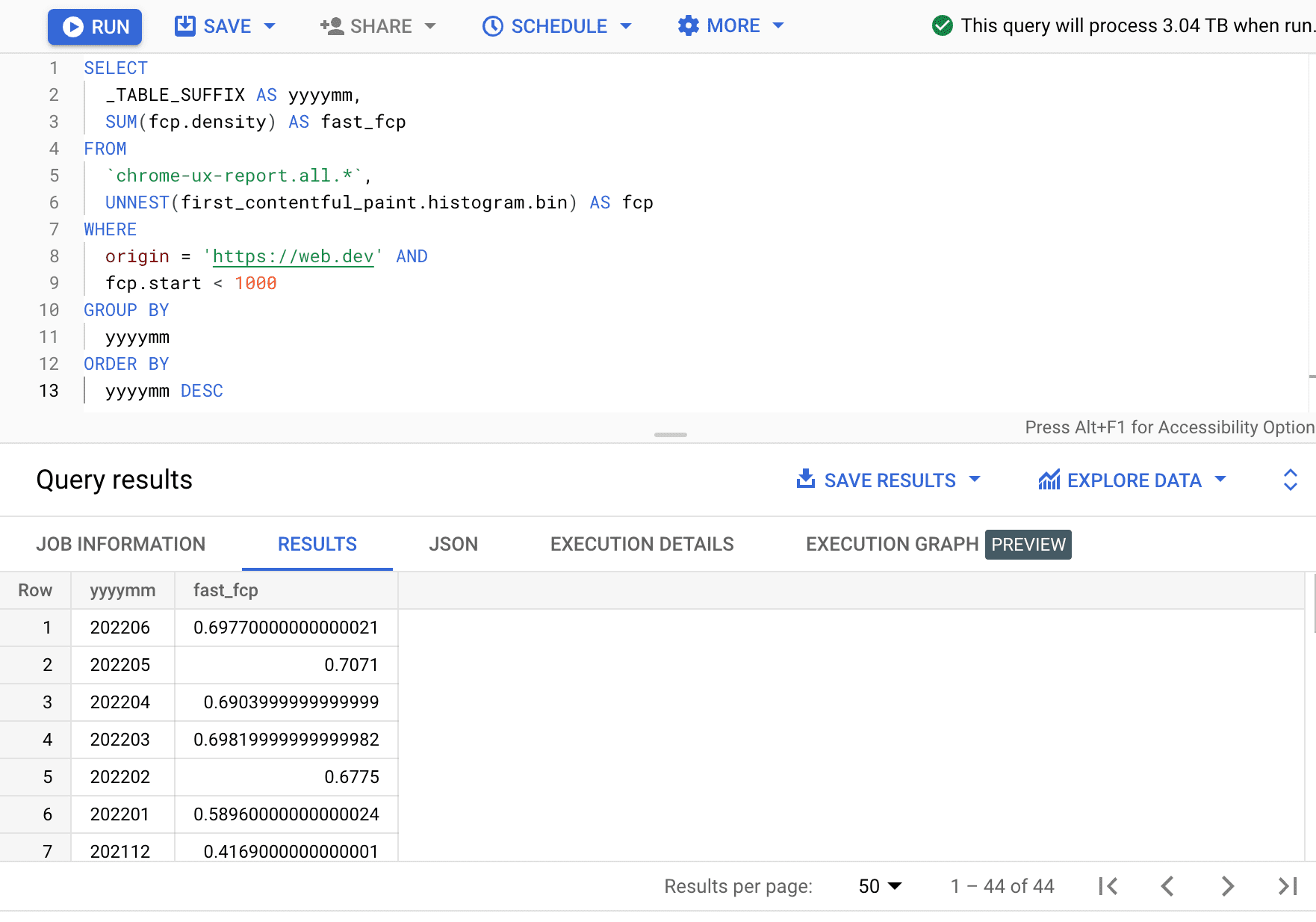
Ở đây, chúng ta thấy rằng phần trăm trải nghiệm FCP nhanh thay đổi vài phần trăm mỗi tháng.
| năm tháng | fast_fcp |
|---|---|
| 202206 | 69,77% |
| 202205 | 70,71% |
| 202204 | 69,04% |
| 202203 | 69,82% |
| 202202 | 67,75% |
| 202201 | 58,96% |
| 202112 | 41,69% |
| ... | ... |
Nhờ những kỹ thuật này, bạn có thể tra cứu hiệu suất theo một nguồn gốc, tính toán tỷ lệ phần trăm trải nghiệm nhanh và theo dõi hiệu suất theo thời gian. Bước tiếp theo, hãy thử truy vấn 2 hoặc nhiều nguồn gốc rồi so sánh hiệu suất của các nguồn gốc đó.
Câu hỏi thường gặp
Sau đây là một số câu hỏi thường gặp về tập dữ liệu CrUX BigQuery:
Khi nào tôi sẽ sử dụng BigQuery thay vì các công cụ khác?
Bạn chỉ cần BigQuery khi không thể nhận được thông tin tương tự từ các công cụ khác như Trang tổng quan CrUX và Thông tin chi tiết về tốc độ trang. Ví dụ: BigQuery cho phép bạn cắt dữ liệu theo những cách có ý nghĩa và thậm chí là kết hợp dữ liệu đó với các tập dữ liệu công khai khác như HTTP Archive để thực hiện một số hoạt động khai thác dữ liệu nâng cao.
Việc sử dụng BigQuery có bất kỳ giới hạn nào không?
Có, giới hạn quan trọng nhất là theo mặc định, người dùng chỉ có thể truy vấn 1TB dữ liệu mỗi tháng. Ngoài ra, chúng tôi sẽ áp dụng mức giá tiêu chuẩn là 5 USD/TB.
Tôi có thể tìm hiểu thêm về BigQuery ở đâu?
Hãy tham khảo tài liệu về BigQuery để biết thêm thông tin.