


Independente do tipo de aplicativo que você está desenvolvendo, otimizar a performance dele e garantir que ele carregue rápido e ofereça interações fluidas é fundamental para a experiência do usuário e o sucesso do aplicativo. Uma maneira de fazer isso é inspecionar a atividade de um aplicativo usando ferramentas de criação de perfil para ver o que está acontecendo por baixo do capô enquanto ele é executado durante um período. O painel Performance no DevTools é uma ótima ferramenta de criação de perfis para analisar e otimizar a performance de aplicativos da Web. Se o app estiver sendo executado no Chrome, você terá uma visão geral visual detalhada do que o navegador está fazendo enquanto o aplicativo é executado. Entender essa atividade ajuda a identificar padrões, gargalos e pontos de alta performance que podem ser usados para melhorar o desempenho.
O exemplo a seguir mostra como usar o painel Performance.
Como configurar e recriar nosso cenário de criação de perfil
Recentemente, definimos uma meta para melhorar a performance do painel Performance. Em especial, queríamos que ele carregasse grandes volumes de dados de performance com mais rapidez. É o caso, por exemplo, ao criar perfis de processos complexos ou de longa duração ou ao capturar dados de alta granularidade. Para isso, primeiro foi necessário entender como o aplicativo estava funcionando e por que ele funcionava dessa forma, o que foi alcançado usando uma ferramenta de criação de perfil.
Como você já deve saber, o DevTools é um aplicativo da Web. Por isso, ele pode ser analisado usando o painel Performance. Para criar um perfil do próprio painel, abra o DevTools e outra instância anexada a ele. No Google, essa configuração é conhecida como DevTools no DevTools.
Com a configuração pronta, o cenário a ser analisado precisa ser recriado e gravado. Para evitar confusão, a janela original do DevTools será chamada de "primeira instância do DevTools", e a janela que está inspecionando a primeira instância será chamada de "segunda instância do DevTools".
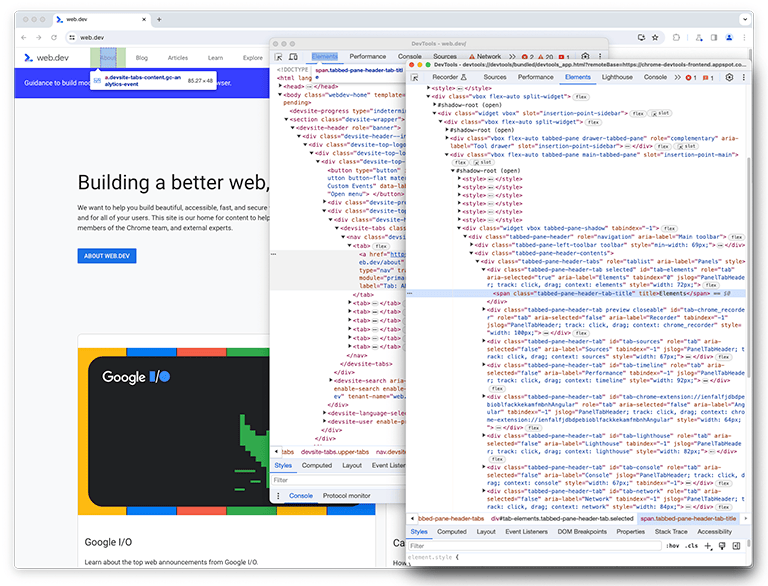
Na segunda instância do DevTools, o painel Performance, que será chamado de painel perf daqui em diante, observa a primeira instância do DevTools para recriar o cenário, que carrega um perfil.
Na segunda instância do DevTools, uma gravação ao vivo é iniciada, enquanto na primeira, um perfil é carregado de um arquivo no disco. Um arquivo grande é carregado para criar um perfil preciso do desempenho do processamento de entradas grandes. Quando as duas instâncias terminam de carregar, os dados de criação de perfil de performance, geralmente chamados de rastreamento, são exibidos na segunda instância do DevTools do painel de performance carregando um perfil.
O estado inicial: identificando oportunidades de melhoria
Depois que o carregamento for concluído, o seguinte na nossa segunda instância do painel de desempenho será observado na próxima captura de tela. Concentre-se na atividade da linha de execução principal, que fica visível na faixa Principal. É possível ver que há cinco grandes grupos de atividade no gráfico de chamas. Essas tarefas são as que levam mais tempo para carregar. O tempo total dessas tarefas foi de aproximadamente 10 segundos. Na captura de tela a seguir, o painel de desempenho é usado para se concentrar em cada um desses grupos de atividade e ver o que pode ser encontrado.
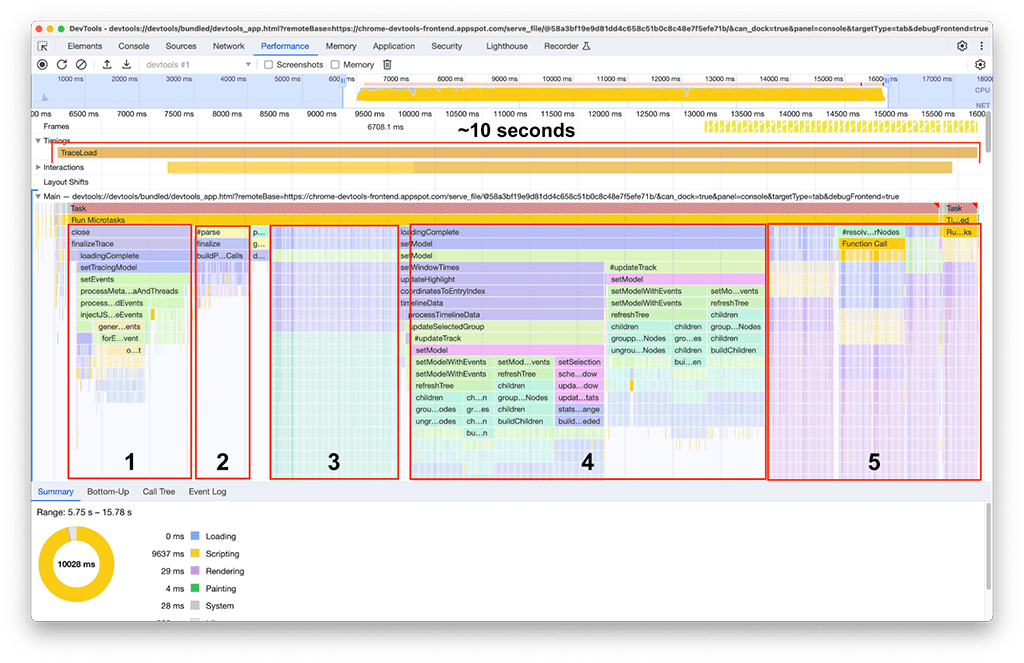
Primeiro grupo de atividades: trabalho desnecessário
Ficou claro que o primeiro grupo de atividades era um código legado que ainda era executado, mas não era realmente necessário. Basicamente, tudo no bloco verde rotulado como processThreadEvents foi um esforço desperdiçado. Essa foi uma vitória rápida. A remoção dessa chamada de função economizou cerca de 1,5 segundo. Legal!
Segundo grupo de atividades
No segundo grupo de atividades, a solução não foi tão simples quanto no primeiro. O buildProfileCalls levou cerca de 0,5 segundo, e essa tarefa não poderia ter sido evitada.
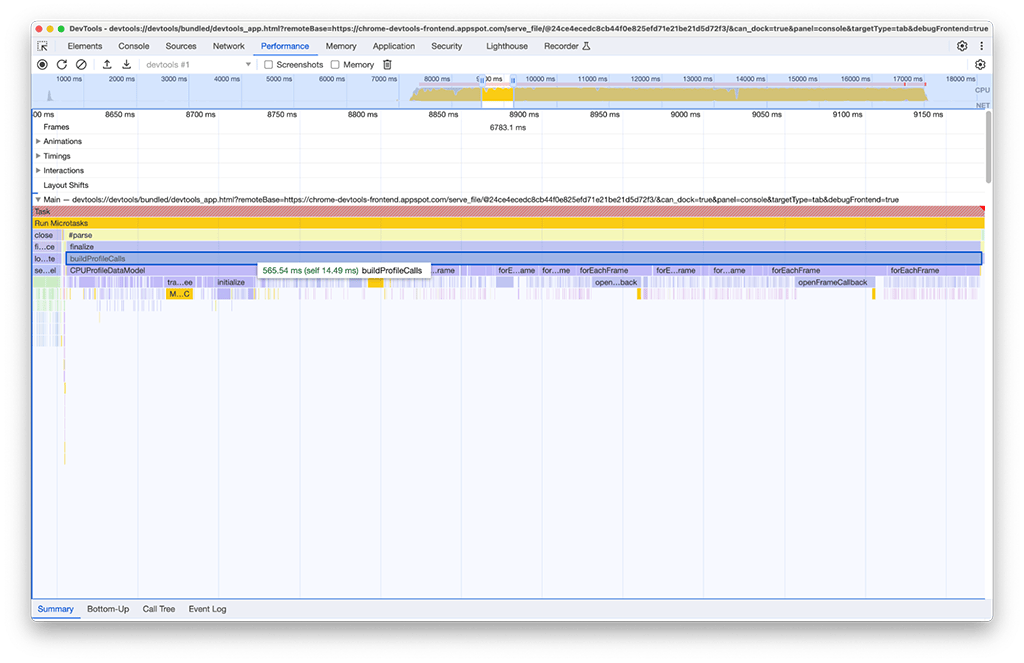
Por curiosidade, ativamos a opção Memória no painel de desempenho para investigar mais a fundo e descobrimos que a atividade buildProfileCalls também estava usando muita memória. Aqui, é possível ver como o gráfico de linhas azuis muda repentinamente quando buildProfileCalls é executado, o que sugere um possível vazamento de memória.
Para investigar essa suspeita, usamos o painel "Memória" (outro painel no DevTools, diferente da gaveta "Memória" no painel "Desempenho"). No painel "Memória", o tipo de criação de perfil "Amostragem de alocação" foi selecionado, o que registrou o snapshot de heap para o painel de desempenho que carrega o perfil da CPU.
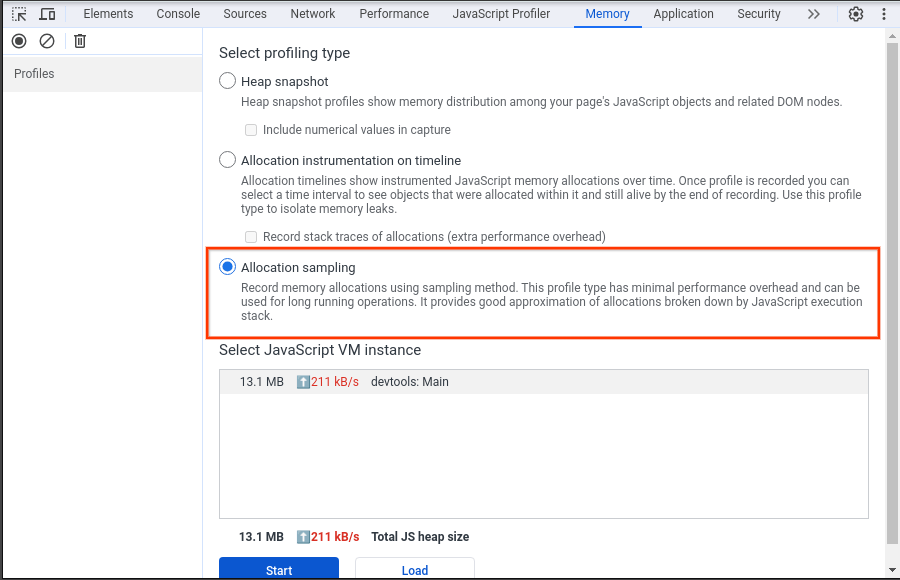
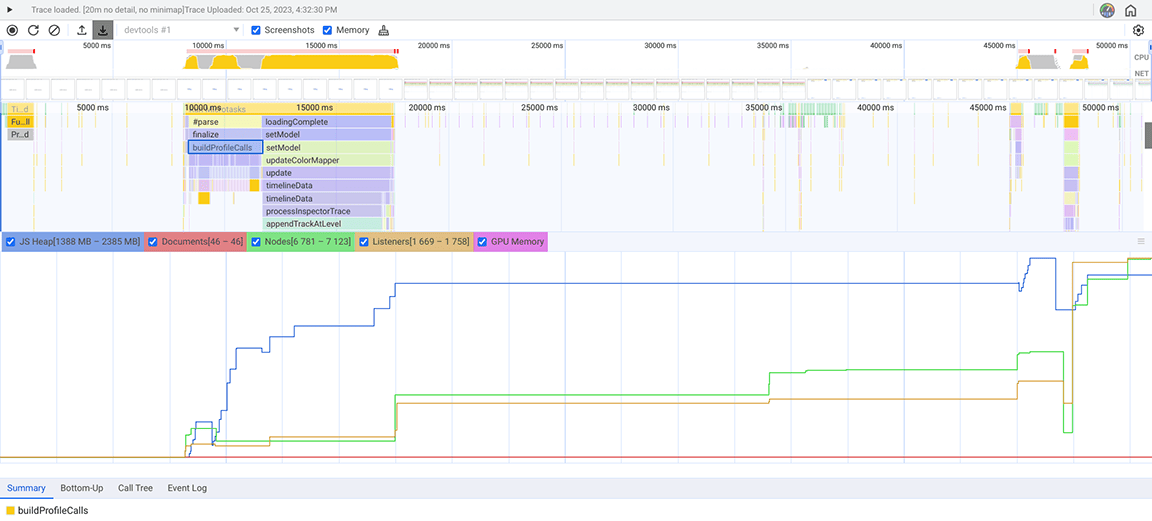
A captura de tela a seguir mostra o instantâneo de heap coletado.
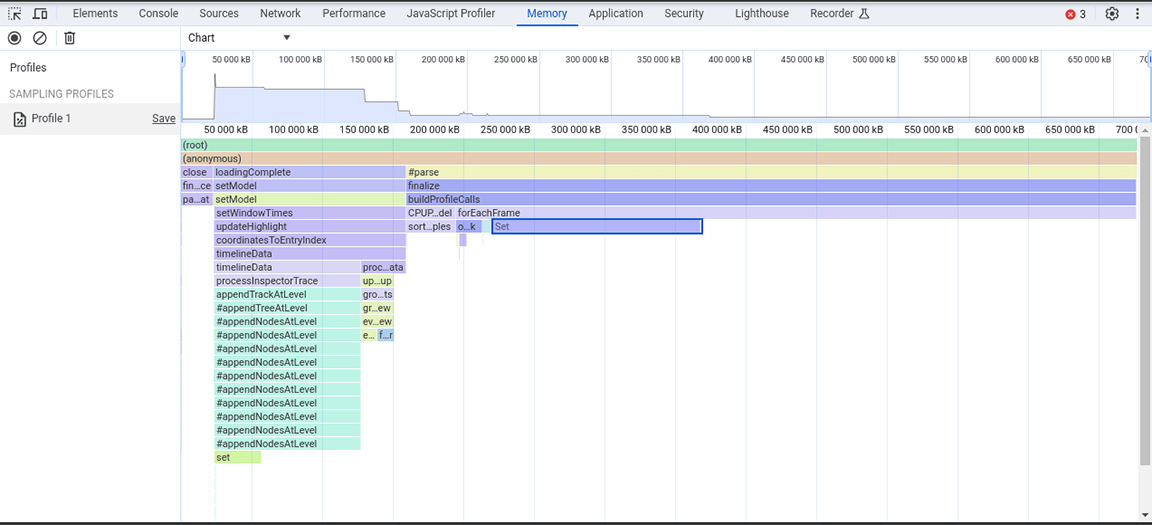
Neste snapshot de heap, foi observado que a classe Set estava consumindo muita memória. Ao verificar os pontos de chamada, descobrimos que estávamos atribuindo desnecessariamente propriedades do tipo Set a objetos criados em grandes volumes. Esse custo estava aumentando e muita memória era consumida, a ponto de ser comum o aplicativo falhar em entradas grandes.
Os conjuntos são úteis para armazenar itens exclusivos e oferecem operações que usam a exclusividade do conteúdo, como a remoção de duplicações em conjuntos de dados e pesquisas mais eficientes. No entanto, esses recursos não eram necessários, já que os dados armazenados eram garantidos como exclusivos da fonte. Por isso, os conjuntos não eram necessários. Para melhorar a alocação de memória, o tipo de propriedade foi alterado de um Set para uma matriz simples. Depois de aplicar essa mudança, outro instantâneo de heap foi criado, e uma alocação de memória reduzida foi observada. Embora não tenha havido melhorias consideráveis na velocidade com essa mudança, o benefício secundário foi que o aplicativo passou a falhar com menos frequência.
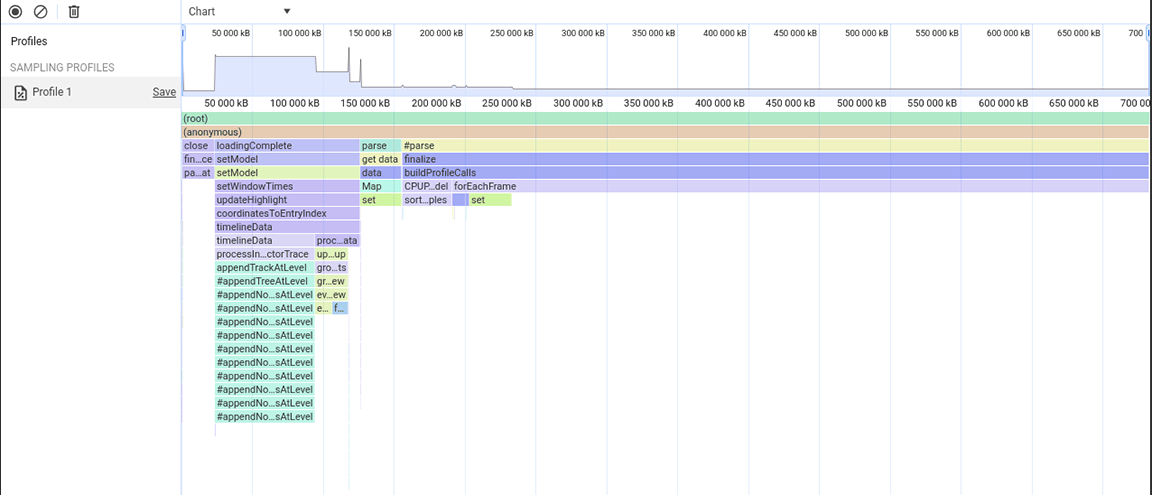
Terceiro grupo de atividades: ponderação das compensações da estrutura de dados
A terceira seção é peculiar: no gráfico de chamas, ela consiste em colunas estreitas, mas altas, que denotam chamadas de função profundas e recursões profundas neste caso. No total, essa seção durou cerca de 1,4 segundos. Ao analisar a parte de baixo desta seção, ficou evidente que a largura dessas colunas era determinada pela duração de uma função: appendEventAtLevel, o que sugeriu que poderia ser um gargalo.
Na implementação da função appendEventAtLevel, uma coisa se destacou. Para cada entrada de dados na entrada (conhecida no código como "evento"), um item foi adicionado a um mapa que rastreava a posição vertical das entradas da linha do tempo. Isso era problemático porque a quantidade de itens armazenados era muito grande. Os mapas são rápidos para pesquisas baseadas em chaves, mas essa vantagem não é sem custo financeiro. À medida que um mapa aumenta, adicionar dados a ele pode, por exemplo, ficar caro devido ao rehashing. Esse custo se torna perceptível quando grandes quantidades de itens são adicionadas ao mapa sucessivamente.
/**
* Adds an event to the flame chart data at a defined vertical level.
*/
function appendEventAtLevel (event, level) {
// ...
const index = data.length;
data.push(event);
this.indexForEventMap.set(event, index);
// ...
}
Testamos outra abordagem que não exigia adicionar um item em um mapa para cada entrada no gráfico de chamas. A melhoria foi significativa, confirmando que o gargalo estava realmente relacionado à sobrecarga causada pela adição de todos os dados ao mapa. O tempo que o grupo de atividades levou diminuiu de cerca de 1,4 segundo para cerca de 200 milissegundos.
Antes:
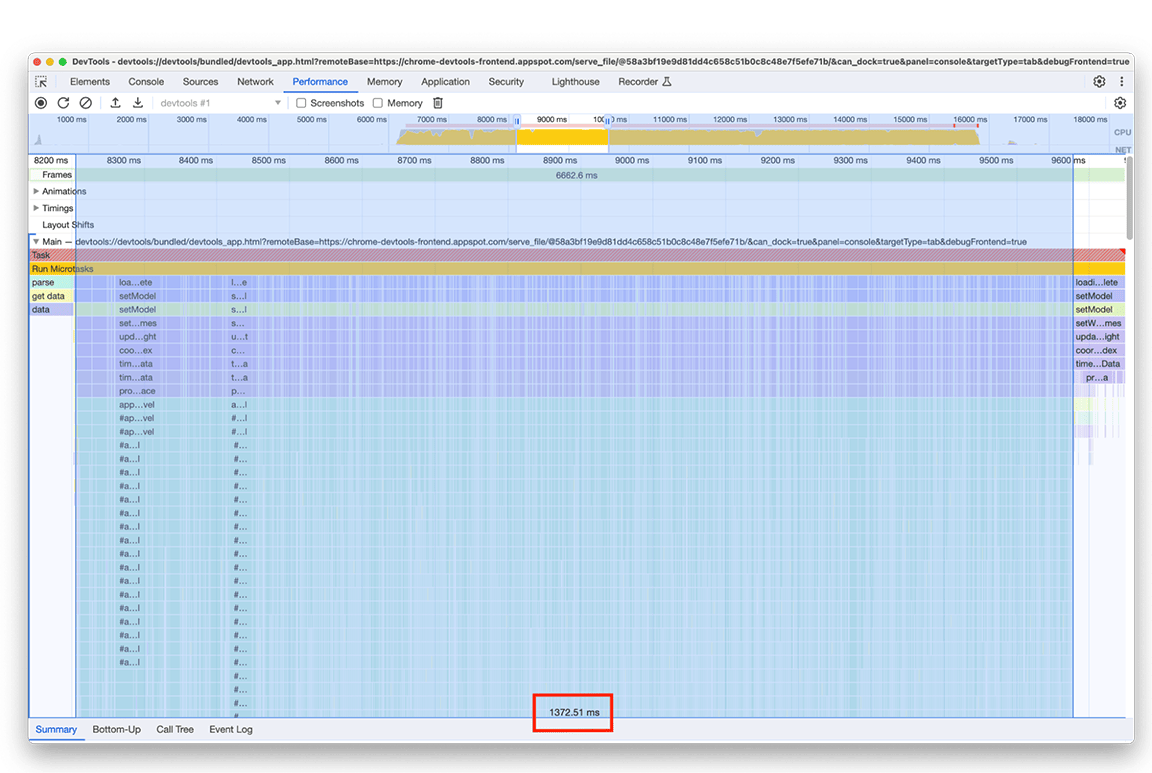
Depois:
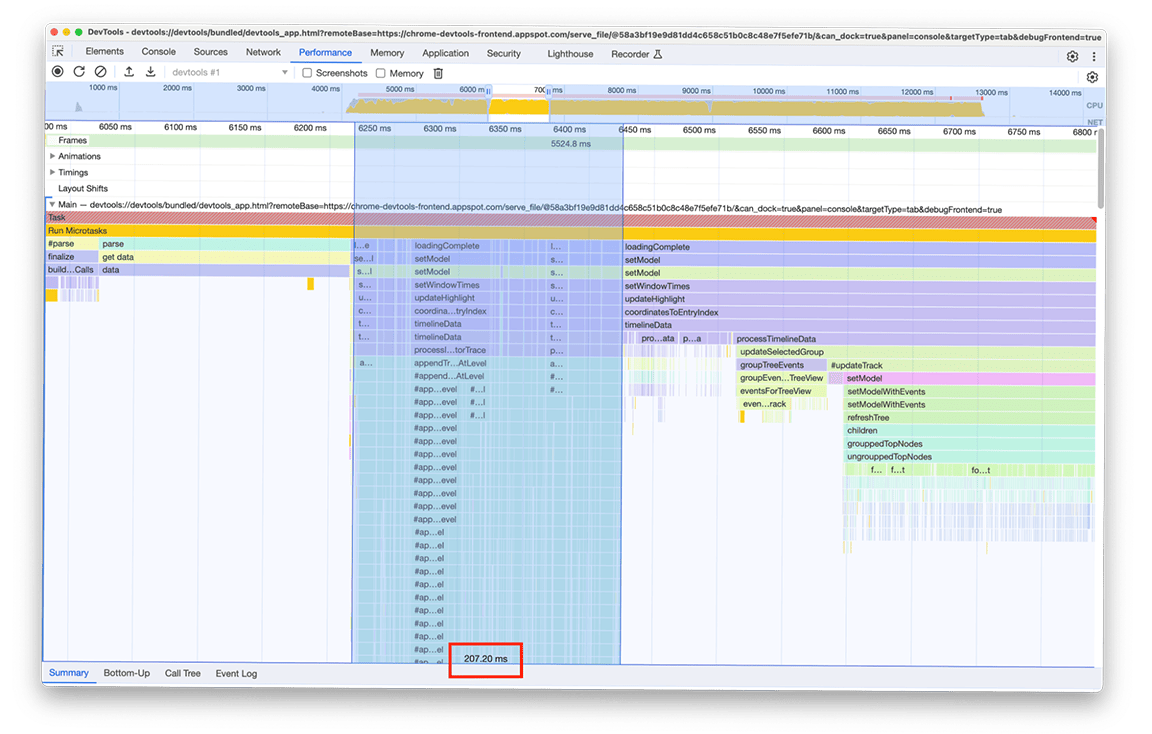
Quarto grupo de atividades: adiar o trabalho não essencial e armazenar dados em cache para evitar trabalho duplicado
Ao ampliar essa janela, é possível ver que há dois blocos quase idênticos de chamadas de função. Ao analisar o nome das funções chamadas, é possível inferir que esses blocos consistem em código que está criando árvores (por exemplo, com nomes como refreshTree ou buildChildren). Na verdade, o código relacionado é o que cria as visualizações em árvore na gaveta da parte de baixo do painel. O interessante é que essas visualizações em árvore não são mostradas logo após o carregamento. Em vez disso, o usuário precisa selecionar uma visualização em árvore (as guias "De baixo para cima", "Árvore de chamadas" e "Registro de eventos" no painel) para que as árvores sejam mostradas. Além disso, como você pode ver na captura de tela, o processo de criação da árvore foi executado duas vezes.
Identificamos dois problemas com esta imagem:
- Uma tarefa não crítica estava prejudicando o desempenho do tempo de carregamento. Os usuários nem sempre precisam da saída dele. Portanto, a tarefa não é essencial para o carregamento do perfil.
- O resultado dessas tarefas não foi armazenado em cache. Por isso, as árvores foram calculadas duas vezes, mesmo que os dados não tenham mudado.
Começamos adiando o cálculo da árvore para quando o usuário abria manualmente a visualização em árvore. Só então vale a pena pagar o preço de criar essas árvores. O tempo total de execução duas vezes foi de cerca de 3,4 segundos.Portanto, o adiamento fez uma diferença significativa no tempo de carregamento. Também estamos investigando o armazenamento em cache desses tipos de tarefas.
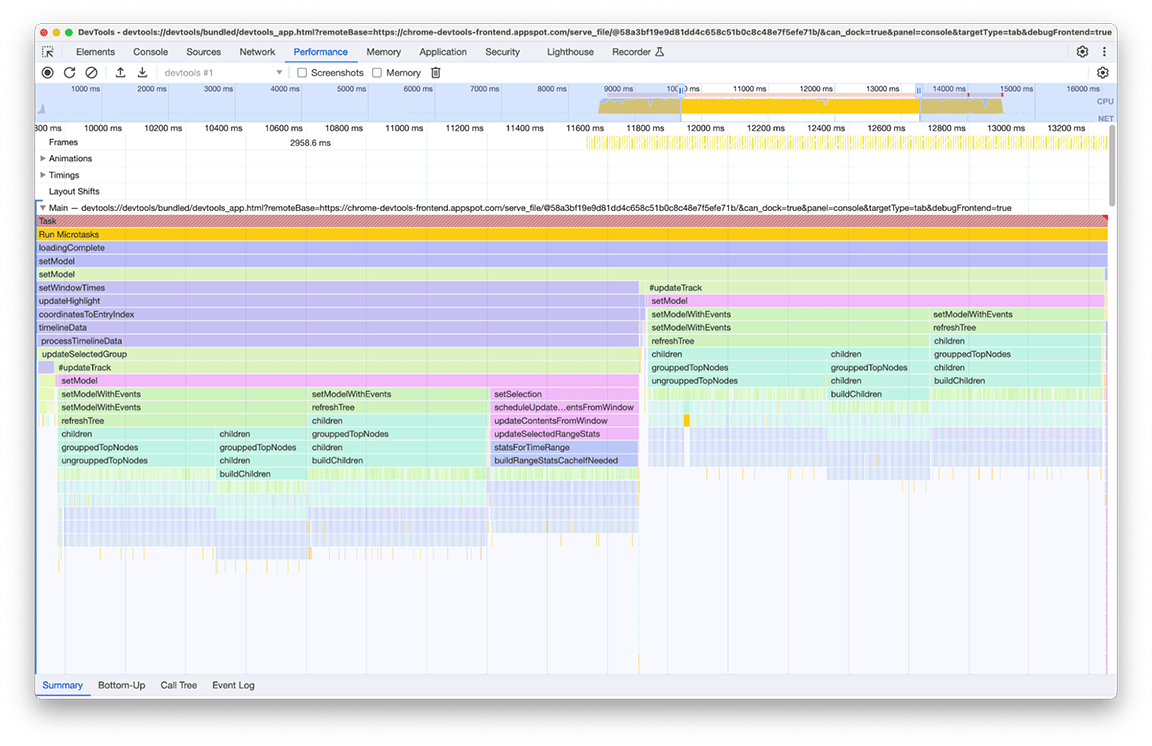
Quinto grupo de atividades: evite hierarquias de chamadas complexas sempre que possível
Analisando esse grupo, ficou claro que uma cadeia de chamadas específica estava sendo invocada repetidamente. O mesmo padrão apareceu seis vezes em diferentes lugares no gráfico de chamas, e a duração total dessa janela foi de cerca de 2,4 segundos.
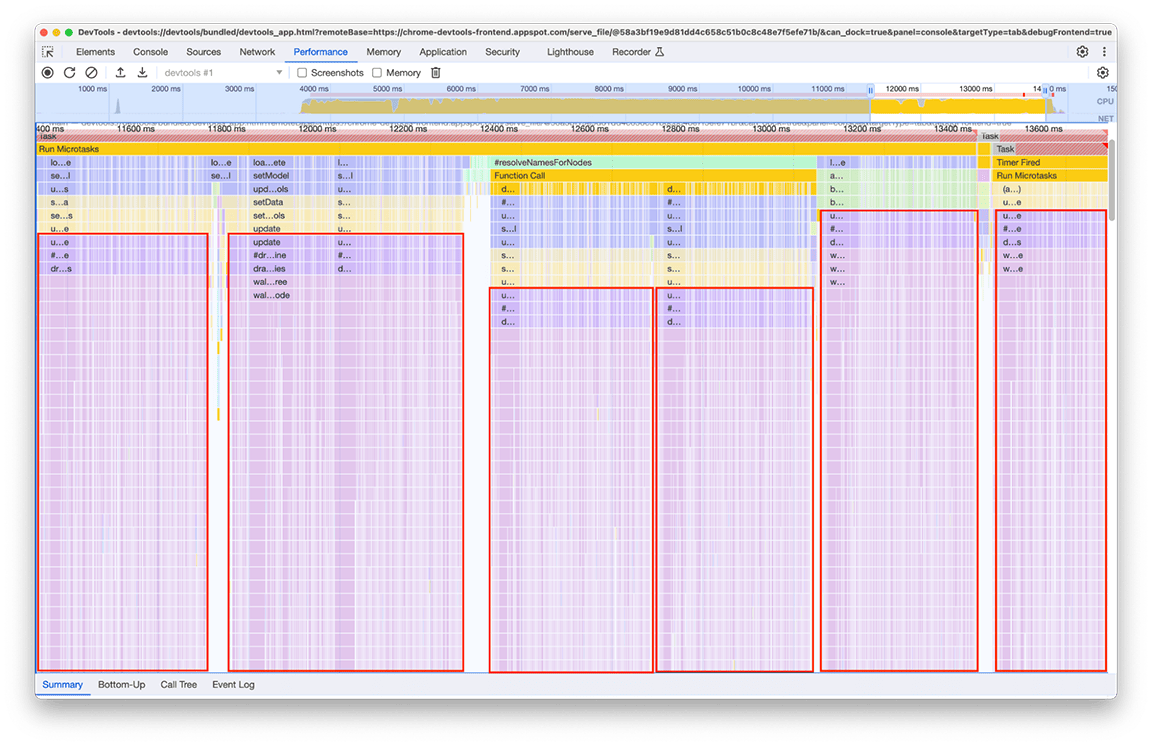
O código relacionado que é chamado várias vezes é a parte que processa os dados a serem renderizados no "minimapa" (a visão geral da atividade da linha do tempo na parte superior do painel). Não estava claro por que isso estava acontecendo várias vezes, mas certamente não precisava acontecer seis vezes! Na verdade, a saída do código vai permanecer atualizada se nenhum outro perfil for carregado. Em teoria, o código só deve ser executado uma vez.
Após a investigação, descobrimos que o código relacionado foi chamado como consequência de várias partes no pipeline de carregamento que chamavam direta ou indiretamente a função que calcula o minimapa. Isso acontece porque a complexidade do gráfico de chamadas do programa evoluiu com o tempo, e mais dependências foram adicionadas ao código sem que ninguém soubesse. Não há uma correção rápida para esse problema. A maneira de resolver isso depende da arquitetura da base de código em questão. No nosso caso, tivemos que reduzir um pouco a complexidade da hierarquia de chamadas e adicionar uma verificação para impedir a execução do código se os dados de entrada permanecessem inalterados. Depois de implementar isso, tivemos esta visão geral da linha do tempo:
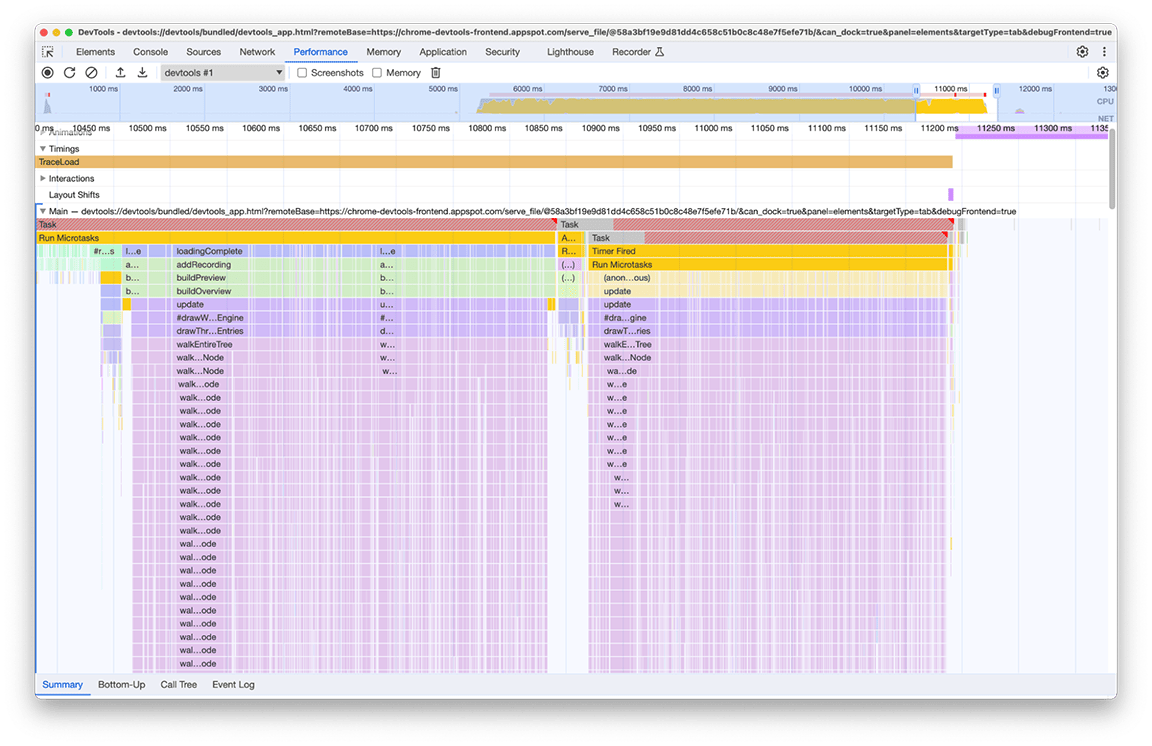
A execução da renderização do minimapa ocorre duas vezes, não uma. Isso acontece porque há dois minimapas sendo desenhados para cada perfil: um para a visão geral na parte de cima do painel e outro para o menu suspenso que seleciona o perfil visível no momento no histórico. Cada item desse menu contém uma visão geral do perfil que ele seleciona. No entanto, os dois têm exatamente o mesmo conteúdo, então um pode ser reutilizado para o outro.
Como esses minimapas são imagens desenhadas em uma tela, usamos o drawImage utilitário de tela e executamos o código apenas uma vez para economizar tempo. Como resultado desse esforço, a duração do grupo foi reduzida de 2,4 segundos para 140 milissegundos.
Conclusão
Depois de aplicar todas essas correções (e algumas outras menores aqui e ali), a mudança na linha do tempo de carregamento do perfil ficou assim:
Antes:
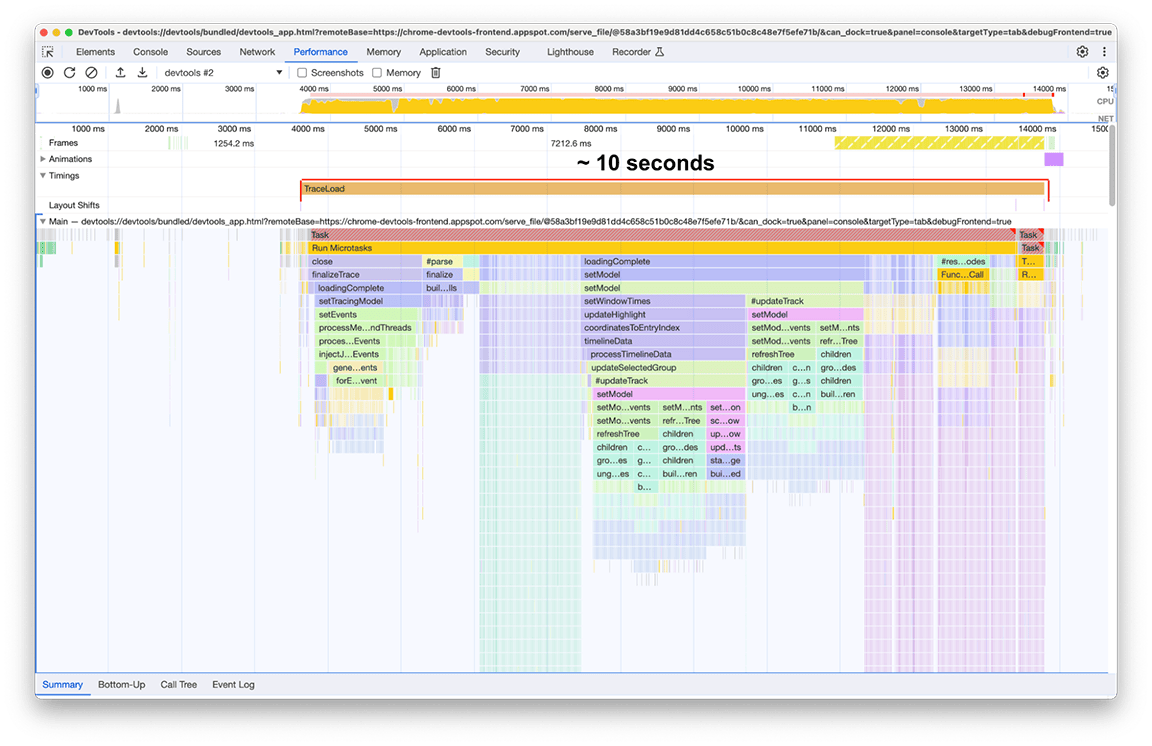
Depois:
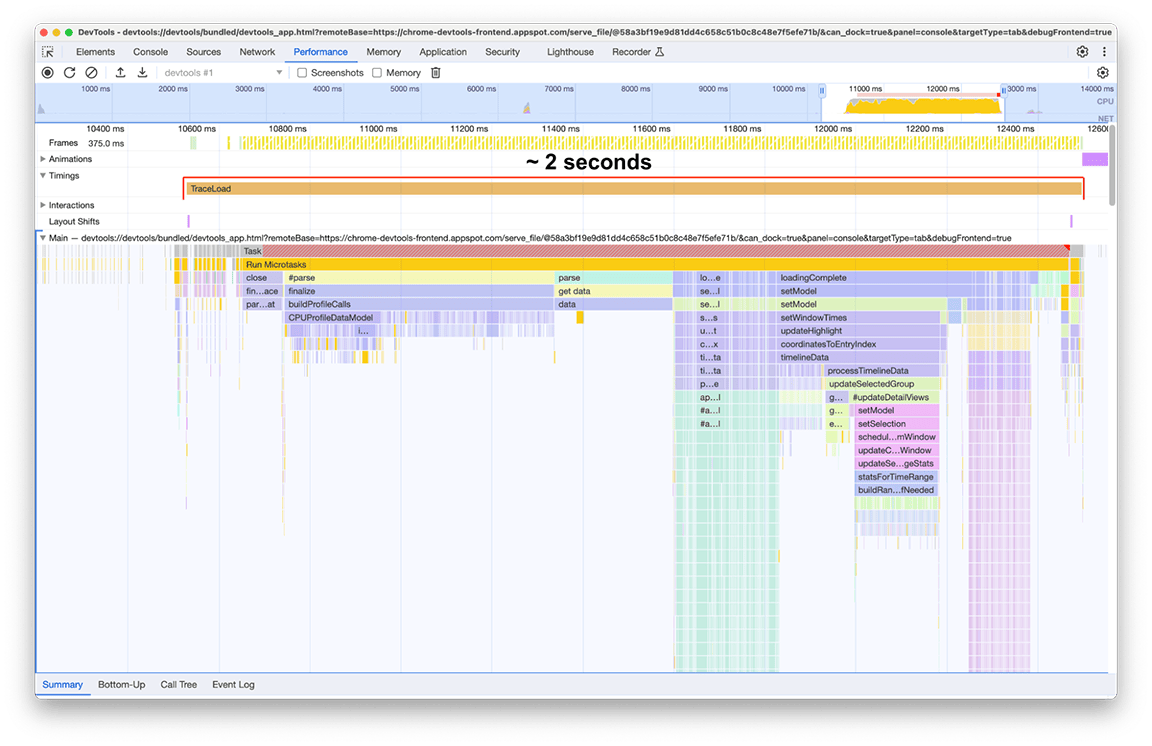
O tempo de carregamento após as melhorias foi de 2 segundos, o que significa que uma melhoria de cerca de 80% foi alcançada com um esforço relativamente baixo, já que a maior parte do que foi feito consistiu em correções rápidas. É claro que identificar corretamente o que fazer inicialmente foi fundamental, e o painel de desempenho foi a ferramenta certa para isso.
Também é importante destacar que esses números são específicos de um perfil usado como objeto de estudo. O perfil era interessante para nós porque era particularmente grande. No entanto, como o pipeline de processamento é o mesmo para todos os perfis, a melhoria significativa alcançada se aplica a todos os perfis carregados no painel de desempenho.
Aprendizados
Há algumas lições a serem aprendidas com esses resultados em termos de otimização de desempenho do aplicativo:
1. Use ferramentas de criação de perfil para identificar padrões de desempenho de tempo de execução
As ferramentas de criação de perfil são muito úteis para entender o que está acontecendo no aplicativo enquanto ele está em execução, principalmente para identificar oportunidades de melhorar a performance. O painel "Performance" no Chrome DevTools é uma ótima opção para aplicativos da Web, já que é a ferramenta nativa de criação de perfis da Web no navegador e é mantida ativamente para ficar atualizada com os recursos mais recentes da plataforma Web. Além disso, agora ele é muito mais rápido. 😉
Use amostras que podem ser usadas como cargas de trabalho representativas e veja o que você pode encontrar.
2. Evite hierarquias de chamadas complexas
Quando possível, evite tornar seu gráfico de chamadas muito complicado. Com hierarquias de chamadas complexas, é fácil introduzir regressões de performance e difícil entender por que o código está sendo executado da maneira como está, o que dificulta a implementação de melhorias.
3. Identificar trabalho desnecessário
É comum que bases de código antigas contenham código que não é mais necessário. No nosso caso, o código legado e desnecessário estava consumindo uma parte significativa do tempo total de carregamento. Remover esse recurso foi a solução mais fácil.
4. Use estruturas de dados adequadamente
Use estruturas de dados para otimizar a performance, mas também entenda os custos e as compensações que cada tipo de estrutura traz ao decidir quais usar. Isso não é apenas a complexidade de espaço da própria estrutura de dados, mas também a complexidade de tempo das operações aplicáveis.
5. Armazenar resultados em cache para evitar trabalho duplicado em operações complexas ou repetitivas
Se a operação for cara para executar, faz sentido armazenar os resultados dela para a próxima vez que for necessário. Também faz sentido fazer isso se a operação for realizada muitas vezes, mesmo que cada vez não seja particularmente custosa.
6. Adiar tarefas não essenciais
Se a saída de uma tarefa não for necessária imediatamente e a execução dela estiver estendendo o caminho crítico, considere adiar a tarefa chamando-a de forma lenta quando a saída for realmente necessária.
7. Usar algoritmos eficientes em entradas grandes
Para entradas grandes, os algoritmos de complexidade de tempo ideal são cruciais. Não analisamos essa categoria neste exemplo, mas a importância dela não pode ser exagerada.
8. Bônus: faça um comparativo de mercado dos seus pipelines
Para garantir que seu código em evolução permaneça rápido, é recomendável monitorar o comportamento e compará-lo com os padrões. Assim, você identifica regressões de forma proativa e melhora a confiabilidade geral, preparando-se para o sucesso a longo prazo.