
Permitir que los service workers indiquen a los navegadores qué páginas funcionan sin conexión

¿Qué es la API de indexación de contenido?
Usar una app web progresiva significa tener acceso a la información importante para las personas (imágenes, videos, artículos, etc.), independientemente del estado actual de tu conexión de red. Tecnologías como los service workers, la API de Cache Storage, y IndexedDB proporcionan los componentes básicos para almacenar y entregar datos interactuar directamente con una AWP. Pero crear una AWP de alta calidad que prioriza el uso sin conexión es son solo una parte de la historia. Si los usuarios no se dan cuenta de que el contenido de una aplicación web está disponibles sin conexión, no aprovecharán al máximo el trabajo que destinar a implementar esa funcionalidad.
Este es un problema de descubrimiento; ¿cómo puede tu AWP hacer que los usuarios conozcan su sin conexión para descubrir y ver lo que hay disponible? El La API de Content Indexing es una solución a este problema. La parte orientada al desarrollador de esta solución es una extensión para los service workers, que permite a los desarrolladores agregar las URL y los metadatos de las páginas que funcionan sin conexión a un índice local mantenido por el navegador. Esta mejora está disponible en Chrome 84 y versiones posteriores.
Una vez que el índice se complete con contenido de tu AWP, así como de cualquier otro o AWP instaladas, el navegador mostrará como se muestra a continuación.
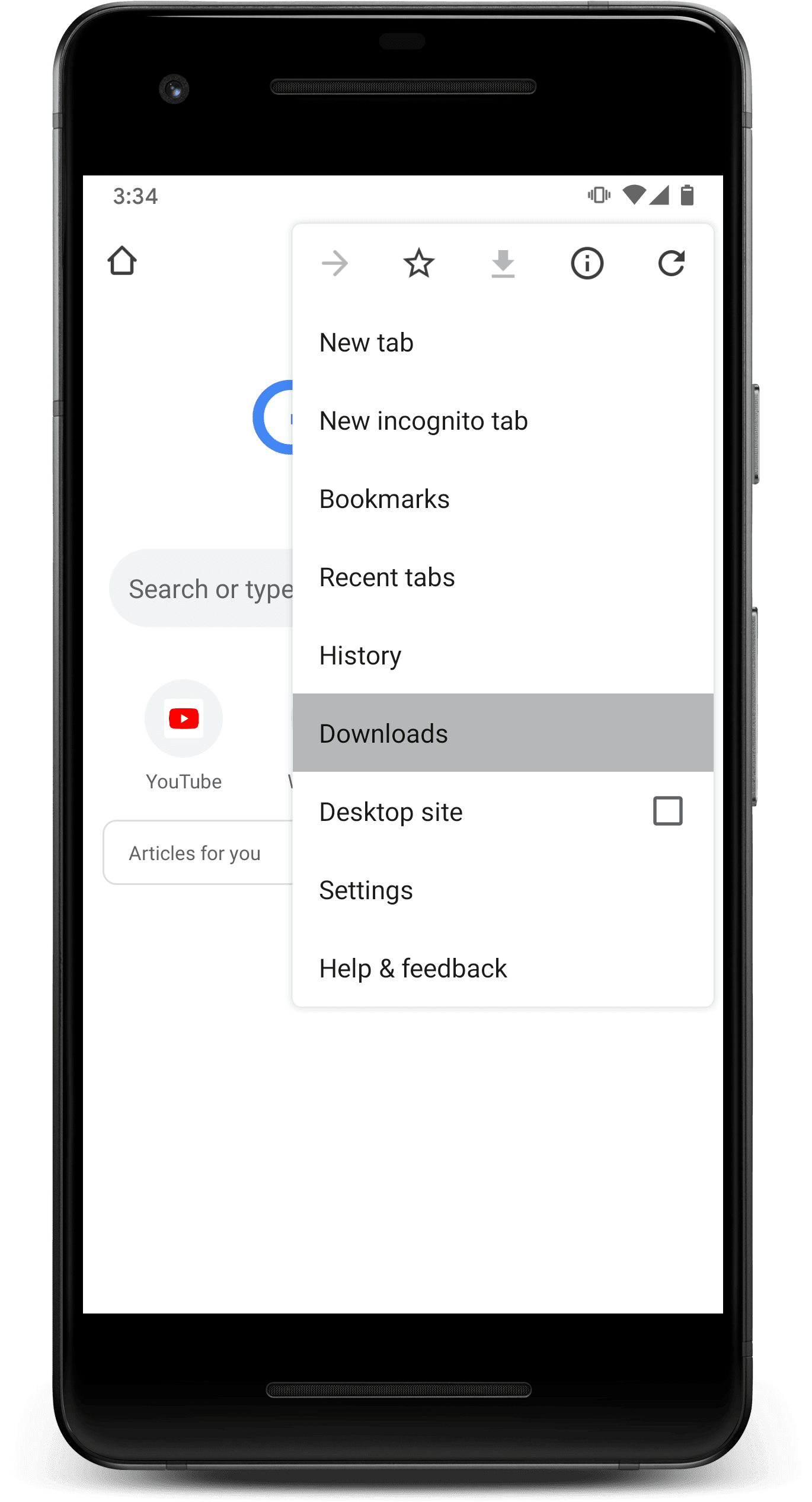
Además, Chrome puede recomendar contenido de manera proactiva cuando detecta que un usuario está sin conexión.
La API de Content Indexing no es una alternativa para almacenar contenido en caché. Es una forma de proporcionar metadatos sobre las páginas que el servicio ya almacena en caché de modo que el navegador pueda mostrar esas páginas cuando es probable que los usuarios quieren verlos. La API de Content Indexing ayuda con la visibilidad de las páginas almacenadas en caché.
Observa cómo funciona
La mejor manera de conocer cómo funciona la API de Content Indexing es probar una muestra y mantener la integridad de su aplicación.
- Asegúrate de usar un navegador y una plataforma compatibles. Actualmente,
que se limite a Chrome 84 o una versión posterior en Android. Ve a
about://versionpara ver qué versión de Chrome tienes. - Visita https://contentindex.dev
- Haz clic en el botón
+junto a uno o más elementos de la lista. - (Opcional) Inhabilita la conexión de datos móviles y Wi-Fi del dispositivo, o bien habilita modo de avión para simular que el navegador está sin conexión.
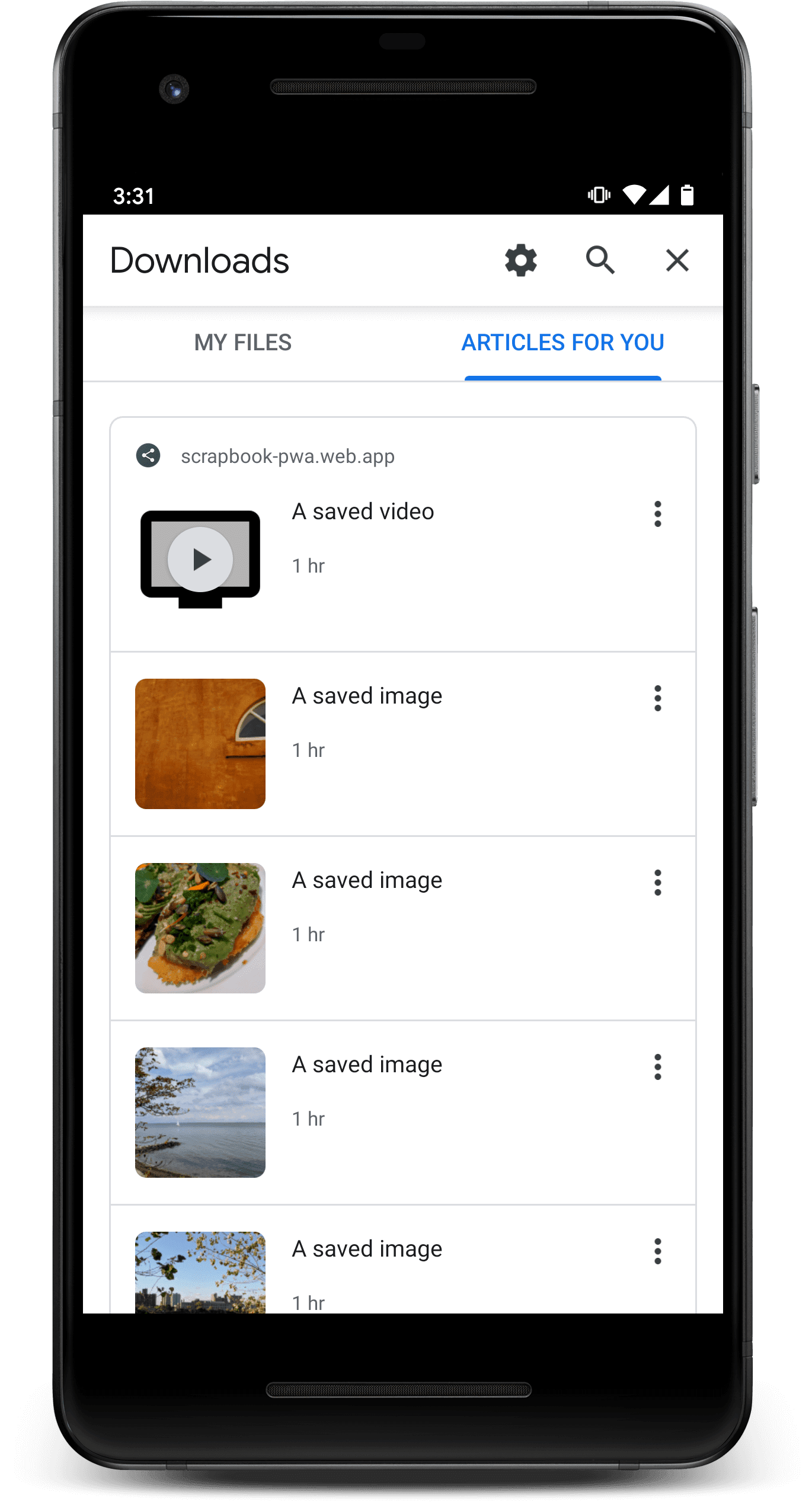
- Elige Descargas en el menú de Chrome y cambia a la pestaña Artículos para ti.
- Explora el contenido que guardaste anteriormente.
Puedes ver el código fuente de la aplicación de ejemplo en GitHub.
Otra aplicación de ejemplo, una AWP de libro de recortes, Se muestra el uso de la API de Content Indexing con la API de Web Share Target. El código muestra una técnica para mantener la API de indexación de contenido sincronizada con los elementos almacenados por una aplicación web con la API de Cache Storage.
Cómo usar la API
Para usar la API, tu app debe tener un service worker y URLs navegables sin conexión. Si tu app web no tiene actualmente un service worker, las bibliotecas de Workbox pueden simplificar creando uno.
¿Qué tipo de URLs se pueden indexar para que funcionen sin conexión?
La API admite URLs de indexación correspondientes a documentos HTML. Una URL para un recurso multimedia, por ejemplo, no se pueden indexar directamente. En cambio, debes proporcionar una URL para una página que muestra contenido multimedia y que funciona sin conexión.
Un patrón recomendado es crear un “visualizador” página HTML que podría aceptar el URL de medios subyacente como parámetro de consulta y mostrar el contenido de las con controles adicionales o contenido en la página.
Las aplicaciones web solo pueden agregar URL al índice de contenido que están en la alcance del service worker actual. En otras palabras, una aplicación web no puede agregar una URL pertenecientes a un dominio completamente diferente en el índice de contenido.
Descripción general
La API de indexación de contenido admite tres operaciones: agregar, mostrar listas y
quitar los metadatos. Estos métodos se exponen desde una nueva propiedad, index, que
se agregó al
ServiceWorkerRegistration
interfaz de usuario.
El primer paso para indexar contenido es obtener una referencia
ServiceWorkerRegistration Usar navigator.serviceWorker.ready es la manera más directa:
const registration = await navigator.serviceWorker.ready;
// Remember to feature-detect before using the API:
if ('index' in registration) {
// Your Content Indexing API code goes here!
}
Si realizas llamadas a la API de Content Indexing desde un service worker,
en lugar de dentro de una página web, puedes consultar la ServiceWorkerRegistration
directamente a través de registration. Ya estará definido.
como parte de ServiceWorkerGlobalScope.
Agregar al índice
Usa el método add() para indexar las URLs y sus metadatos asociados. Depende de
para que elijas cuándo se agregan elementos al índice. Es posible que quieras agregar
índice en respuesta a una entrada, como hacer clic en “Guardar sin conexión” . O tú
puede agregar elementos automáticamente cada vez que se actualizan los datos almacenados en caché a través de un mecanismo
como la sincronización periódica en segundo plano.
await registration.index.add({
// Required; set to something unique within your web app.
id: 'article-123',
// Required; url needs to be an offline-capable HTML page.
url: '/articles/123',
// Required; used in user-visible lists of content.
title: 'Article title',
// Required; used in user-visible lists of content.
description: 'Amazing article about things!',
// Required; used in user-visible lists of content.
icons: [{
src: '/img/article-123.png',
sizes: '64x64',
type: 'image/png',
}],
// Optional; valid categories are currently:
// 'homepage', 'article', 'video', 'audio', or '' (default).
category: 'article',
});
Agregar una entrada solo afecta el índice de contenido. no agrega nada al caché.
Caso extremo: Llama a add() desde el contexto window si tus íconos dependen de un controlador fetch.
Cuando llames a add(), Chrome solicitará lo siguiente:
la URL de cada ícono para asegurarte de que tenga una copia del ícono para usar cuando
mostrar una lista de contenido indexado
Si llamas a
add()desde el contextowindow(en otras palabras, desde tu esta solicitud activará un eventofetchen tu service worker.Si llamas a
add()en tu service worker (quizás dentro de otro evento) ), la solicitud no activará el controladorfetchdel service worker. Los íconos se recuperarán directamente, sin la participación de un service worker. Conservar esto si tus íconos dependen de tu controladorfetch, quizás porque solo existen en la caché local y no en la red. Si es así, asegúrate de que Solo llamas aadd()desde el contextowindow.
Obtén una lista del contenido del índice
El método getAll() muestra una promesa para una lista iterable de entradas indexadas.
y sus metadatos. Las entradas devueltas contendrán todos los datos guardados con
add()
const entries = await registration.index.getAll();
for (const entry of entries) {
// entry.id, entry.launchUrl, etc. are all exposed.
}
Eliminación de elementos del índice
Para quitar un elemento del índice, llama a delete() con el id del elemento en
quitar:
await registration.index.delete('article-123');
Llamar a delete() solo afecta el índice. No borra nada de la
caché.
Controla un evento de eliminación de un usuario
Cuando el navegador muestra el contenido indexado, puede incluir su propio usuario con un elemento de menú Borrar, lo que da a las personas la oportunidad de indicar lo siguiente: terminar de ver contenido indexado previamente. Así es como la eliminación interfaz de la app en Chrome 80:
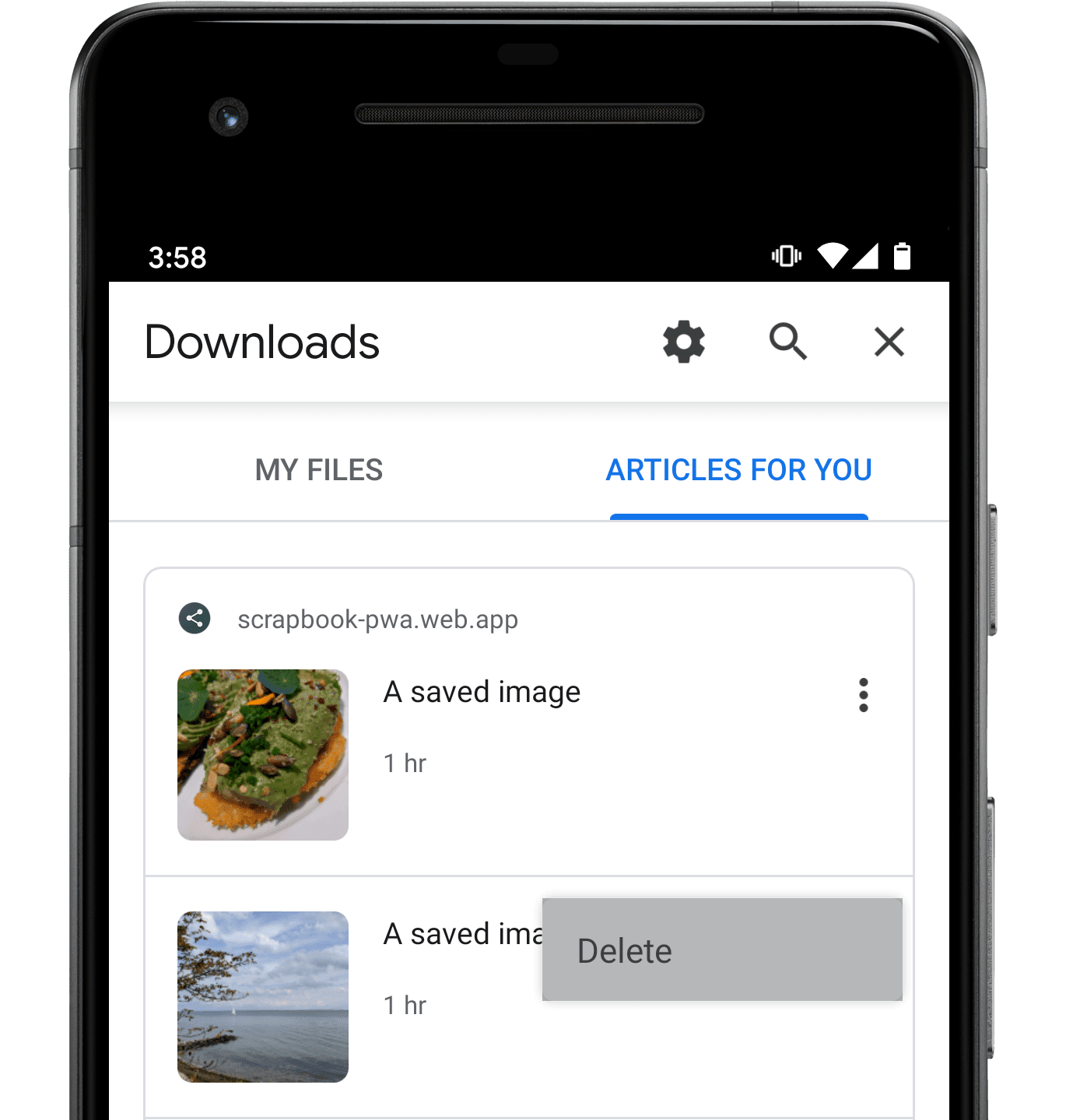
Cuando alguien seleccione ese elemento de menú, el service worker de tu app web recibirá
un evento contentdelete Aunque controlar este evento es opcional, proporciona un
la posibilidad de que tu service worker "limpie" contenido, como el contenido multimedia almacenado en caché local
con los que alguien indicó que ha terminado.
No es necesario que llames a registration.index.delete() en tu
controlador contentdelete; Si el evento se activó, el índice relevante
eliminación ya la realizó el navegador.
self.addEventListener('contentdelete', (event) => {
// event.id will correspond to the id value used
// when the indexed content was added.
// Use that value to determine what content, if any,
// to delete from wherever your app stores it—usually
// the Cache Storage API or perhaps IndexedDB.
});
Comentarios sobre el diseño de la API
¿Hay algo en la API que sea incómodo o que no funcione como se esperaba? O ¿faltan piezas que necesites para implementar tu idea?
Informa sobre un problema en el repositorio de GitHub de la explicación de la API de Content Indexing o agrega lo que piensas. a un problema existente.
¿Tiene problemas con la implementación?
¿Encontraste un error en la implementación de Chrome?
Informa un error en https://new.crbug.com. Incluye tanto
detalles como puedas, instrucciones simples de reproducción y la definición de componentes.
a Blink>ContentIndexing.
¿Piensas usar la API?
¿Piensas usar la API de Content Indexing en tu app web? Tu apoyo público ayuda a Chrome a priorizar funciones y muestra a otros proveedores de navegadores la importancia que tiene para respaldarlos.
- Envía un tweet a @ChromiumDev con el hashtag
#ContentIndexingAPIy detalles sobre dónde y cómo lo utilizas.
¿Cuáles son algunas implicaciones de seguridad y privacidad de la indexación de contenido?
Consulta las respuestas proporcionados en respuesta al cuestionario de seguridad y privacidad de W3C. Si Si tienes más preguntas, inicia una conversación a través del repositorio de GitHub del proyecto.
Hero image de Maksym Kaharlytskyi en Unsplash.