

Parlons d'architecture.
Je vais aborder un sujet important, mais potentiellement mal compris : l'architecture que vous utilisez pour votre application Web, et plus précisément, comment vos décisions architecturales entrent en jeu lorsque vous créez une application Web progressive.
Le terme "architecture" peut sembler vague et son importance n'est pas toujours évidente. Pour comprendre l'architecture, posez-vous les questions suivantes : lorsqu'un utilisateur visite une page de mon site, quel code HTML est chargé ? Et qu'est-ce qui est chargé lorsqu'ils visitent une autre page ?
Les réponses à ces questions ne sont pas toujours simples, et elles peuvent devenir encore plus compliquées lorsque vous commencez à réfléchir aux applications Web progressives. Mon objectif est de vous présenter une architecture possible que j'ai trouvée efficace. Dans cet article, je vais qualifier les décisions que j'ai prises comme étant "mon approche" pour créer une progressive web app.
Vous êtes libre d'utiliser mon approche lorsque vous créez votre propre PWA, mais il existe toujours d'autres alternatives valables. J'espère que la présentation de tous les éléments vous inspirera et vous donnera les moyens de personnaliser cette solution pour l'adapter à vos besoins.
PWA Stack Overflow
Pour accompagner cet article, j'ai créé une PWA Stack Overflow. Je passe beaucoup de temps à lire et à contribuer à Stack Overflow. Je voulais donc créer une application Web qui me permettrait de parcourir facilement les questions fréquentes sur un sujet donné. Elle est basée sur l'API Stack Exchange publique. Il s'agit d'un projet Open Source. Pour en savoir plus, consultez le projet GitHub.
Applications multipages
Avant d'entrer dans les détails, définissons certains termes et expliquons des éléments de la technologie sous-jacente. Je vais commencer par ce que j'aime appeler les "applications multipages" ou "MPA".
MPA est un nom sophistiqué pour l'architecture traditionnelle utilisée depuis les débuts du Web. Chaque fois qu'un utilisateur accède à une nouvelle URL, le navigateur affiche progressivement le code HTML spécifique à cette page. Aucune tentative n'est faite pour préserver l'état de la page ou le contenu entre les navigations. Chaque fois que vous accédez à une nouvelle page, vous repartez de zéro.
Cela contraste avec le modèle d'application monopage (SPA) pour la création d'applications Web, dans lequel le navigateur exécute du code JavaScript pour mettre à jour la page existante lorsque l'utilisateur visite une nouvelle section. Les SPA et les MPA sont des modèles tout aussi valides à utiliser, mais pour cet article, je voulais explorer les concepts PWA dans le contexte d'une application multipage.
Une connexion rapide et fiable
Vous m'avez entendu (et d'innombrables autres personnes) utiliser l'expression "progressive web app", ou PWA. Vous connaissez peut-être déjà certains éléments de contexte sur ce site.
Vous pouvez considérer une PWA comme une application Web qui offre une expérience utilisateur de premier ordre et qui mérite vraiment sa place sur l'écran d'accueil de l'utilisateur. L'acronyme FIRE, qui signifie Fast (rapide), Integrated (intégrée), Reliable (fiable) et Engaging (attrayante), résume tous les attributs à prendre en compte lors de la création d'une PWA.
Dans cet article, je vais me concentrer sur un sous-ensemble de ces attributs : Rapide et Fiable.
Rapidité : même si le terme "rapide" peut avoir différentes significations selon le contexte, je vais aborder les avantages en termes de vitesse liés au chargement du minimum de contenu possible à partir du réseau.
Fiabilité : la vitesse brute ne suffit pas. Pour donner l'impression d'être une PWA, votre application Web doit être fiable. Il doit être suffisamment résilient pour toujours charger quelque chose, même s'il s'agit simplement d'une page d'erreur personnalisée, quel que soit l'état du réseau.
Fiabilité et rapidité : enfin, je vais reformuler légèrement la définition des PWA et examiner ce que signifie créer quelque chose de fiable et rapide. Il ne suffit pas d'être rapide et fiable uniquement lorsque vous êtes sur un réseau à faible latence. Être fiable et rapide signifie que la vitesse de votre application Web est constante, quelles que soient les conditions du réseau sous-jacent.
Technologies d'activation : Service Workers et API Cache Storage
Les PWA imposent des exigences élevées en termes de vitesse et de résilience. Heureusement, la plate-forme Web propose des éléments de base pour que ce type de performances devienne une réalité. Je fais référence aux service workers et à l'API Cache Storage.
Vous pouvez créer un service worker qui écoute les requêtes entrantes, en transmettant certaines au réseau et en stockant une copie de la réponse pour une utilisation ultérieure, via l'API Cache Storage.
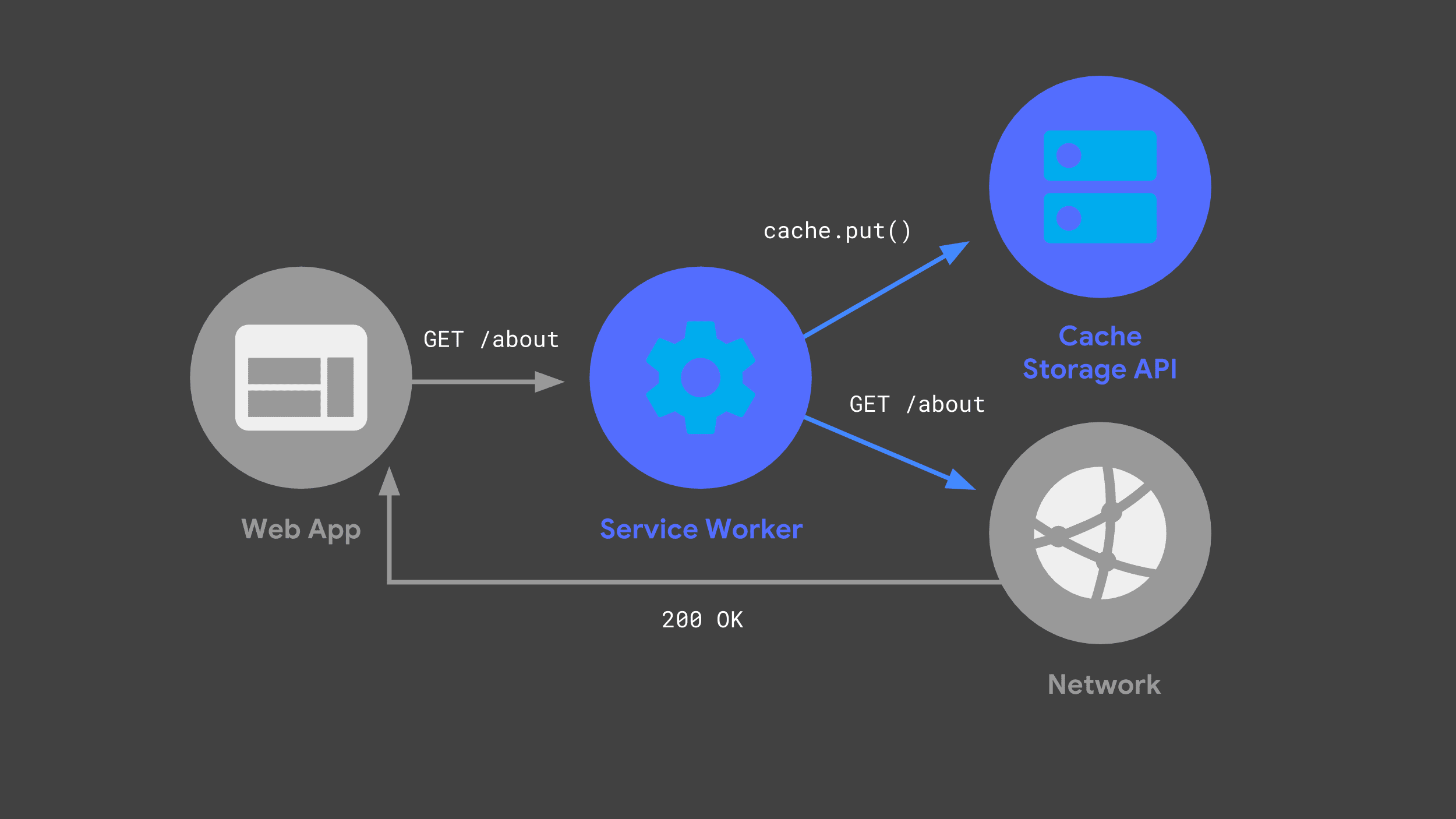
La prochaine fois que l'application Web enverra la même requête, son service worker pourra vérifier ses caches et renvoyer simplement la réponse précédemment mise en cache.
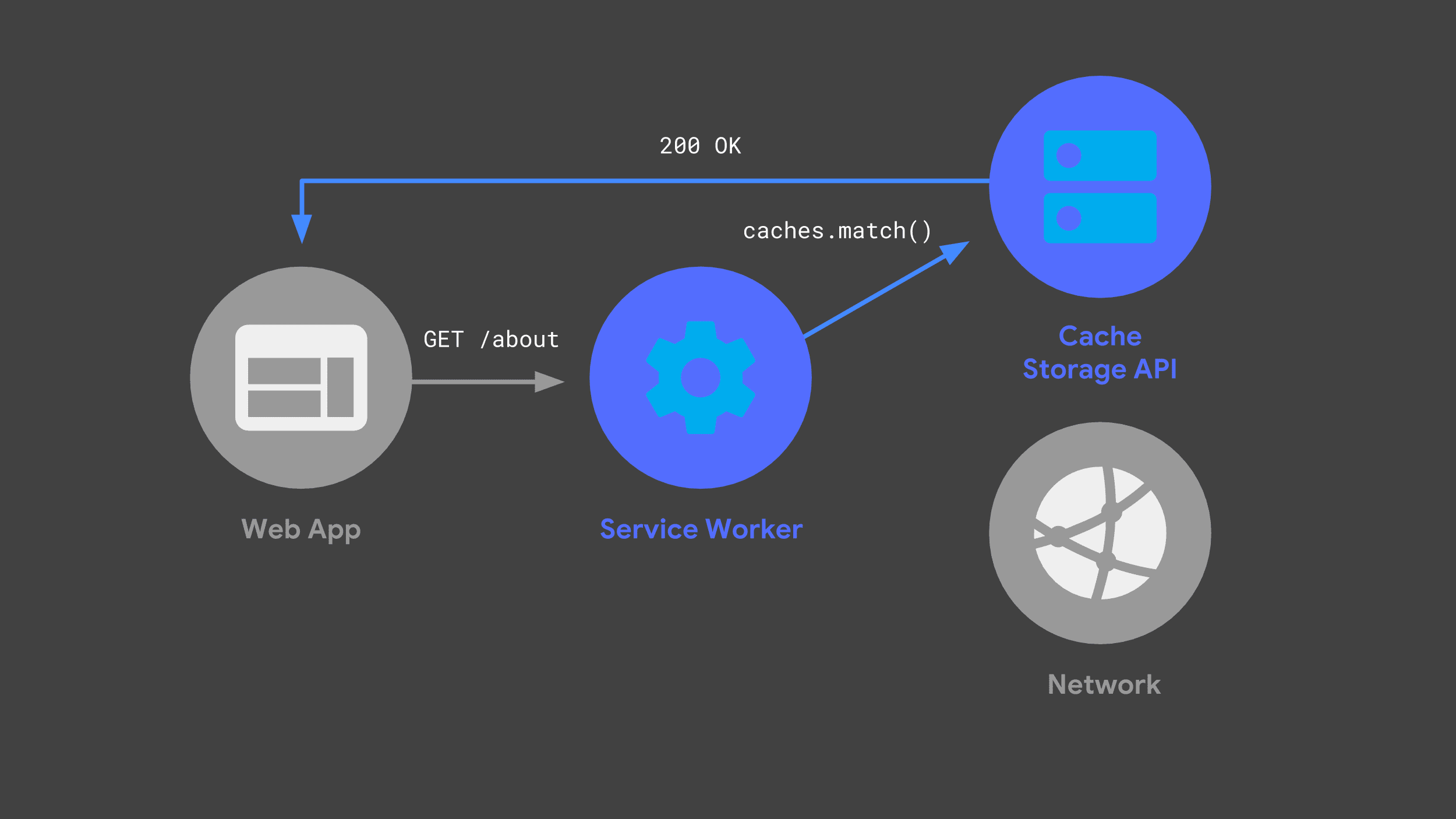
Éviter le réseau autant que possible est essentiel pour offrir des performances rapides et fiables.
JavaScript "isomorphe"
Un autre concept que je souhaite aborder est ce que l'on appelle parfois JavaScript"isomorphe" ou "universel". En d'autres termes, il s'agit de l'idée selon laquelle le même code JavaScript peut être partagé entre différents environnements d'exécution. Lorsque j'ai créé ma PWA, je voulais partager du code JavaScript entre mon serveur backend et le service worker.
Il existe de nombreuses approches valides pour partager du code de cette manière, mais mon approche consistait à utiliser les modules ES comme code source définitif. J'ai ensuite transpilé et regroupé ces modules pour le serveur et le service worker à l'aide d'une combinaison de Babel et Rollup. Dans mon projet, les fichiers avec l'extension .mjs sont du code qui se trouve dans un module ES.
Le serveur
Maintenant que vous avez ces concepts et cette terminologie en tête, voyons comment j'ai créé ma PWA Stack Overflow. Je vais commencer par aborder notre serveur backend et expliquer comment il s'intègre dans l'architecture globale.
Je recherchais une combinaison d'un backend dynamique avec un hébergement statique, et mon approche consistait à utiliser la plate-forme Firebase.
Firebase Cloud Functions crée automatiquement un environnement basé sur Node en cas de requête entrante et s'intègre au célèbre framework HTTP Express, que je connaissais déjà. Il offre également un hébergement prêt à l'emploi pour toutes les ressources statiques de mon site. Voyons comment le serveur gère les requêtes.
Lorsqu'un navigateur envoie une requête de navigation à notre serveur, il suit le flux suivant :
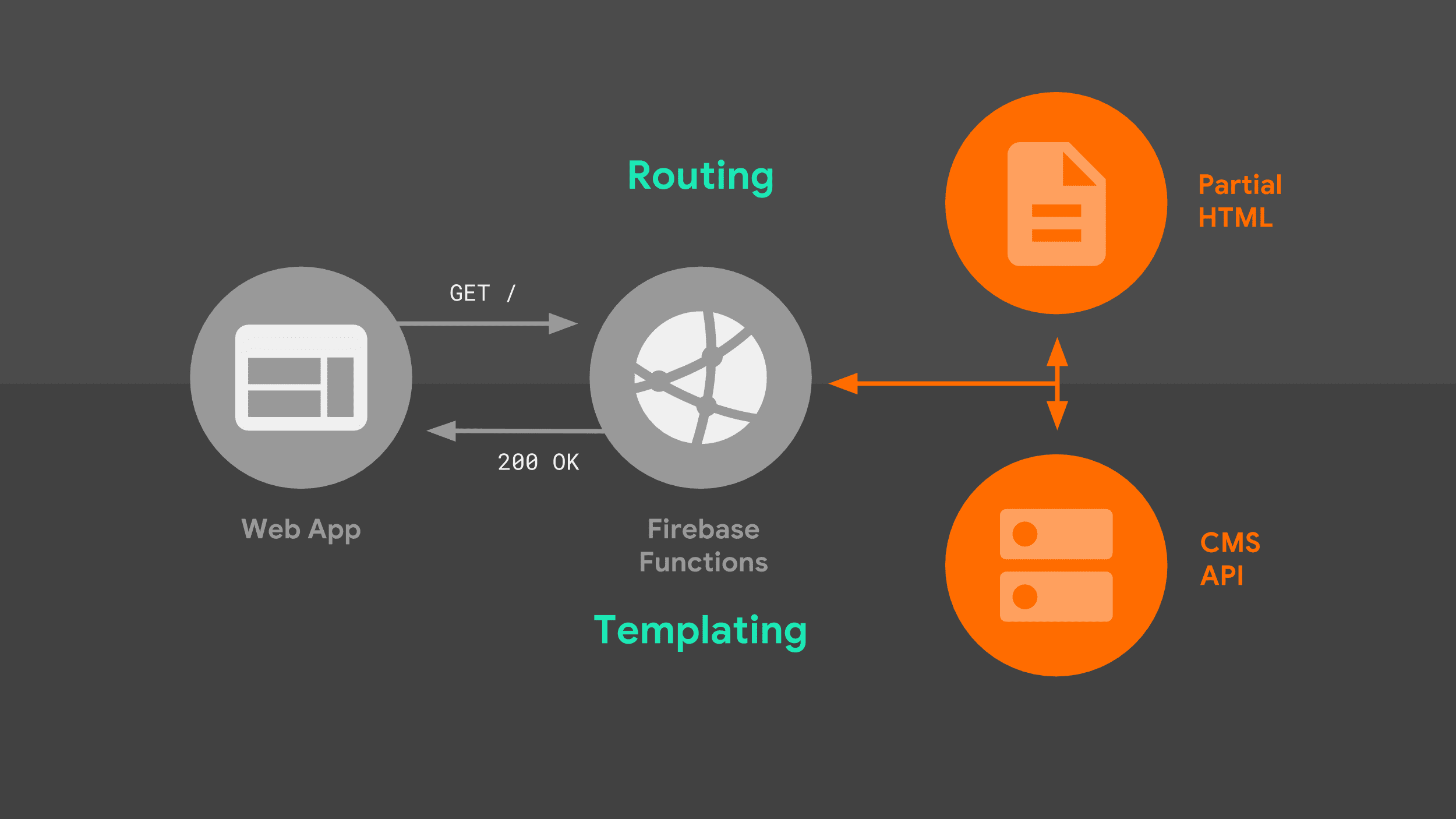
Le serveur route la requête en fonction de l'URL et utilise une logique de création de modèles pour créer un document HTML complet. J'utilise une combinaison de données provenant de l'API Stack Exchange, ainsi que des fragments HTML partiels que le serveur stocke localement. Une fois que notre service worker sait comment répondre, il peut commencer à diffuser du code HTML vers notre application Web.
Deux éléments de cette image méritent d'être explorés plus en détail : le routage et les modèles.
Routage
En ce qui concerne le routage, mon approche consistait à utiliser la syntaxe de routage native du framework Express. Elle est suffisamment flexible pour correspondre à des préfixes d'URL simples, ainsi qu'à des URL incluant des paramètres dans le chemin. Ici, je crée un mappage entre les noms de routes et le modèle Express sous-jacent à mettre en correspondance.
const routes = new Map([
['about', '/about'],
['questions', '/questions/:questionId'],
['index', '/'],
]);
export default routes;
Je peux ensuite référencer ce mappage directement à partir du code du serveur. Lorsqu'un modèle Express donné est trouvé, le gestionnaire approprié répond avec une logique de création de modèles spécifique à la route correspondante.
import routes from './lib/routes.mjs';
app.get(routes.get('index'), async (req, res) => {
// Templating logic.
});
Modèles côté serveur
À quoi ressemble cette logique de création de modèles ? J'ai opté pour une approche qui consistait à assembler des fragments HTML partiels en séquence, les uns après les autres. Ce modèle se prête bien au streaming.
Le serveur renvoie immédiatement un boilerplate HTML initial, et le navigateur est en mesure d'afficher cette page partielle immédiatement. À mesure que le serveur rassemble le reste des sources de données, il les diffuse en continu au navigateur jusqu'à ce que le document soit complet.
Pour comprendre ce que je veux dire, regardez le code Express pour l'une de nos routes :
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
En utilisant la méthode write() de l'objet response et en référençant les modèles partiels stockés localement, je peux démarrer le flux de réponse immédiatement, sans bloquer aucune source de données externe. Le navigateur prend ce code HTML initial et affiche immédiatement une interface pertinente et un message de chargement.
La partie suivante de notre page utilise les données de l'API Stack Exchange. Pour obtenir ces données, notre serveur doit effectuer une requête réseau. L'application Web ne peut rien afficher d'autre tant qu'elle n'a pas reçu de réponse et qu'elle ne l'a pas traitée. Au moins, les utilisateurs ne sont pas obligés de regarder un écran vide en attendant.
Une fois que l'application Web a reçu la réponse de l'API Stack Exchange, elle appelle une fonction de création de modèles personnalisée pour traduire les données de l'API dans le code HTML correspondant.
Langage de templating
La création de modèles peut être un sujet étonnamment controversé. L'approche que j'ai choisie n'est qu'une parmi tant d'autres. Vous devrez remplacer votre propre solution, en particulier si vous avez des liens hérités avec un framework de modèles existant.
Pour mon cas d'utilisation, il était logique de s'appuyer uniquement sur les littéraux de modèle de JavaScript, avec une partie de la logique répartie dans des fonctions d'assistance. L'un des avantages de la création d'une MPA est que vous n'avez pas à suivre les mises à jour de l'état ni à rendre à nouveau votre code HTML. Une approche de base qui produit du code HTML statique a donc fonctionné pour moi.
Voici un exemple de la façon dont je crée un modèle pour la partie HTML dynamique de l'index de mon application Web. Comme pour mes routes, la logique de templating est stockée dans un module ES qui peut être importé à la fois dans le serveur et dans le service worker.
export function index(tag, items) {
const title = `<h3>Top "${escape(tag)}" Questions</h3>`;
const form = `<form method="GET">...</form>`;
const questionCards = items
.map(item =>
questionCard({
id: item.question_id,
title: item.title,
})
)
.join('');
const questions = `<div id="questions">${questionCards}</div>`;
return title + form + questions;
}
Ces fonctions de modèle sont du JavaScript pur. Il est utile de décomposer la logique en fonctions d'assistance plus petites, le cas échéant. Ici, je transmets chacun des éléments renvoyés dans la réponse de l'API à l'une de ces fonctions, qui crée un élément HTML standard avec tous les attributs appropriés définis.
function questionCard({id, title}) {
return `<a class="card"
href="/questions/${id}"
data-cache-url="${questionUrl(id)}">${title}</a>`;
}
À noter tout particulièrement, l'attribut de données que j'ajoute à chaque lien, data-cache-url, est défini sur l'URL de l'API Stack Exchange dont j'ai besoin pour afficher la question correspondante. Gardez cela à l'esprit. J'y reviendrai plus tard.
Revenons à mon gestionnaire de routes. Une fois la création de modèles terminée, je diffuse la dernière partie du code HTML de ma page au navigateur et je mets fin au flux. Il s'agit de l'indice indiquant au navigateur que le rendu progressif est terminé.
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
Voilà une brève présentation de la configuration de mon serveur. Les utilisateurs qui visitent mon application Web pour la première fois recevront toujours une réponse du serveur, mais lorsqu'un visiteur revient sur mon application Web, mon service worker commence à répondre. Allons-y.
Le service worker
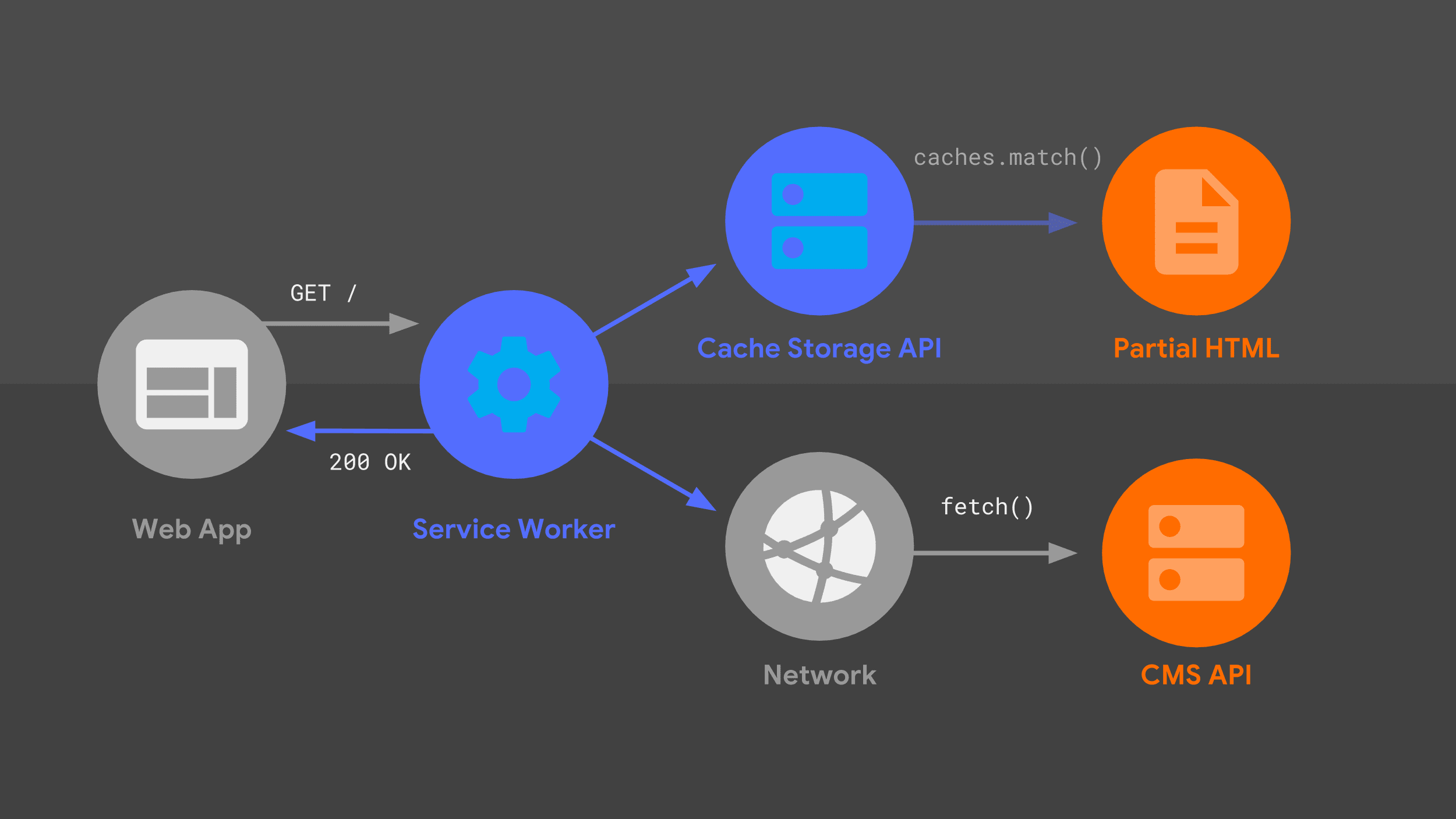
Ce diagramme devrait vous sembler familier : la plupart des éléments que j'ai déjà abordés sont ici, dans un arrangement légèrement différent. Examinons le flux de requêtes en tenant compte du service worker.
Notre service worker gère une requête de navigation entrante pour une URL donnée et, tout comme mon serveur, il utilise une combinaison de logique de routage et de création de modèles pour déterminer comment répondre.
L'approche est la même qu'auparavant, mais avec des primitives de bas niveau différentes, comme fetch() et l'API Cache Storage. J'utilise ces sources de données pour construire la réponse HTML, que le service worker renvoie à l'application Web.
Workbox
Plutôt que de partir de zéro avec des primitives de bas niveau, je vais créer mon service worker sur un ensemble de bibliothèques de haut niveau appelées Workbox. Il fournit une base solide pour la logique de mise en cache, de routage et de génération de réponses de tout service worker.
Routage
Tout comme mon code côté serveur, mon service worker doit savoir comment faire correspondre une requête entrante à la logique de réponse appropriée.
Mon approche consistait à traduire chaque route Express en expression régulière correspondante, en utilisant une bibliothèque utile appelée regexparam. Une fois cette traduction effectuée, je peux profiter de la prise en charge intégrée de Workbox pour le routage des expressions régulières.
Après avoir importé le module contenant les expressions régulières, j'enregistre chaque expression régulière avec le routeur Workbox. Dans chaque route, je peux fournir une logique de modèle personnalisée pour générer une réponse. La création de modèles dans le service worker est un peu plus complexe que dans mon serveur de backend, mais Workbox facilite une grande partie du travail.
import regExpRoutes from './regexp-routes.mjs';
workbox.routing.registerRoute(
regExpRoutes.get('index')
// Templating logic.
);
Mise en cache des éléments statiques
Un élément clé de la création de modèles consiste à s'assurer que mes modèles HTML partiels sont disponibles localement via l'API Cache Storage et qu'ils sont à jour lorsque je déploie des modifications dans l'application Web. La maintenance du cache peut être sujette à des erreurs lorsqu'elle est effectuée manuellement. Je me tourne donc vers Workbox pour gérer le pré-cache dans le cadre de mon processus de compilation.
J'indique à Workbox les URL à précharger à l'aide d'un fichier de configuration, en pointant vers le répertoire contenant tous mes éléments locaux ainsi qu'un ensemble de modèles à faire correspondre. Ce fichier est lu automatiquement par la CLI Workbox, qui est exécutée chaque fois que je reconstruis le site.
module.exports = {
globDirectory: 'build',
globPatterns: ['**/*.{html,js,svg}'],
// Other options...
};
Workbox prend un instantané du contenu de chaque fichier et injecte automatiquement cette liste d'URL et de révisions dans mon fichier de service worker final. Workbox dispose désormais de tout ce dont il a besoin pour que les fichiers pré-cachés soient toujours disponibles et à jour. Le résultat est un fichier service-worker.js qui contient un élément semblable à ce qui suit :
workbox.precaching.precacheAndRoute([
{
url: 'partials/about.html',
revision: '518747aad9d7e',
},
{
url: 'partials/foot.html',
revision: '69bf746a9ecc6',
},
// etc.
]);
Pour les utilisateurs qui utilisent un processus de compilation plus complexe, Workbox propose un plug-in webpack et un module Node générique, en plus de son interface de ligne de commande.
Streaming
Ensuite, je souhaite que le service worker renvoie immédiatement ce code HTML partiel pré-mis en cache à l'application Web. C'est un élément crucial pour être "fiablement rapide" : j'obtiens toujours quelque chose d'utile à l'écran immédiatement. Heureusement, l'utilisation de l'API Streams dans notre service worker rend cela possible.
Vous avez peut-être déjà entendu parler de l'API Streams. Mon collègue Jake Archibald ne tarit pas d'éloges à son sujet depuis des années. Il a fait la prédiction audacieuse que 2016 serait l'année des flux Web. L'API Streams est toujours aussi géniale aujourd'hui qu'il y a deux ans, mais avec une différence cruciale.
À l'époque, seuls les flux Chrome étaient compatibles, mais l'API Streams est désormais plus largement acceptée. L'histoire globale est positive et, avec le code de secours approprié, rien ne vous empêche d'utiliser des flux dans votre service worker dès aujourd'hui.
Il y a peut-être une chose qui vous arrête : comprendre comment fonctionne réellement l'API Streams. Il expose un ensemble de primitives très puissant. Les développeurs qui sont à l'aise avec son utilisation peuvent créer des flux de données complexes, comme les suivants :
const stream = new ReadableStream({
pull(controller) {
return sources[0]
.then(r => r.read())
.then(result => {
if (result.done) {
sources.shift();
if (sources.length === 0) return controller.close();
return this.pull(controller);
} else {
controller.enqueue(result.value);
}
});
},
});
Cependant, tout le monde n'est pas forcément en mesure de comprendre toutes les implications de ce code. Plutôt que d'analyser cette logique, parlons de mon approche du streaming de service worker.
J'utilise un tout nouveau wrapper de haut niveau, workbox-streams.
Avec lui, je peux le transmettre dans un mélange de sources de streaming, à la fois à partir de caches et de données d'exécution pouvant provenir du réseau. Workbox se charge de coordonner les sources individuelles et de les assembler en une seule réponse de streaming.
De plus, Workbox détecte automatiquement si l'API Streams est compatible. Si ce n'est pas le cas, il crée une réponse équivalente sans flux. Cela signifie que vous n'avez pas à vous soucier d'écrire des solutions de secours, car les flux se rapprochent de la compatibilité à 100 % avec les navigateurs.
Mise en cache de l'exécution
Voyons comment mon service worker gère les données d'exécution de l'API Stack Exchange. J'utilise la prise en charge intégrée de Workbox pour une stratégie de mise en cache "stale-while-revalidate", ainsi que l'expiration pour m'assurer que le stockage de l'application Web ne croît pas de manière illimitée.
J'ai configuré deux stratégies dans Workbox pour gérer les différentes sources qui composeront la réponse de streaming. En quelques appels de fonction et configurations, Workbox nous permet de faire ce qui prendrait autrement des centaines de lignes de code manuscrit.
const cacheStrategy = workbox.strategies.cacheFirst({
cacheName: workbox.core.cacheNames.precache,
});
const apiStrategy = workbox.strategies.staleWhileRevalidate({
cacheName: API_CACHE_NAME,
plugins: [new workbox.expiration.Plugin({maxEntries: 50})],
});
La première stratégie lit les données pré-mises en cache, comme nos modèles HTML partiels.
L'autre stratégie implémente la logique de mise en cache "obsolète pendant la revalidation", ainsi que l'expiration du cache le moins récemment utilisé une fois que nous atteignons 50 entrées.
Maintenant que ces stratégies sont en place, il ne me reste plus qu'à indiquer à Workbox comment les utiliser pour construire une réponse complète et en streaming. Je transmets un tableau de sources en tant que fonctions, et chacune de ces fonctions sera exécutée immédiatement. Workbox prend le résultat de chaque source et le transmet à l'application Web, dans l'ordre, en ne retardant la transmission que si la fonction suivante du tableau n'est pas encore terminée.
workbox.streams.strategy([
() => cacheStrategy.makeRequest({request: '/head.html'}),
() => cacheStrategy.makeRequest({request: '/navbar.html'}),
async ({event, url}) => {
const tag = url.searchParams.get('tag') || DEFAULT_TAG;
const listResponse = await apiStrategy.makeRequest(...);
const data = await listResponse.json();
return templates.index(tag, data.items);
},
() => cacheStrategy.makeRequest({request: '/foot.html'}),
]);
Les deux premières sources sont des modèles partiels pré-mis en cache qui sont lus directement à partir de l'API Cache Storage. Elles seront donc toujours disponibles immédiatement. Cela garantit que l'implémentation du service worker répondra rapidement aux requêtes, tout comme mon code côté serveur.
Notre prochaine fonction source récupère les données de l'API Stack Exchange et traite la réponse au format HTML attendu par l'application Web.
La stratégie "stale-while-revalidate" signifie que si j'ai une réponse précédemment mise en cache pour cet appel d'API, je pourrai la diffuser immédiatement sur la page, tout en mettant à jour l'entrée de cache "en arrière-plan" pour la prochaine fois qu'elle sera demandée.
Enfin, je diffuse une copie mise en cache de mon pied de page et ferme les balises HTML finales pour terminer la réponse.
Un code de partage pour une synchronisation parfaite
Vous remarquerez que certains éléments du code du service worker vous sont familiers. La logique HTML partiel et de création de modèles utilisée par mon service worker est identique à celle utilisée par mon gestionnaire côté serveur. Ce partage de code garantit aux utilisateurs une expérience cohérente, qu'ils visitent mon application Web pour la première fois ou qu'ils reviennent sur une page affichée par le service worker. C'est tout l'intérêt du JavaScript isomorphe.
Améliorations dynamiques et progressives
J'ai parcouru le serveur et le service worker de ma PWA, mais il reste une dernière partie de la logique à couvrir : il y a une petite quantité de JavaScript qui s'exécute sur chacune de mes pages, une fois qu'elles sont entièrement diffusées.
Ce code améliore progressivement l'expérience utilisateur, mais n'est pas essentiel. L'application Web fonctionnera toujours s'il n'est pas exécuté.
Métadonnées de page
Mon application utilise JavaScript côté client pour mettre à jour les métadonnées d'une page en fonction de la réponse de l'API. Comme j'utilise le même fragment HTML mis en cache pour chaque page, l'application Web se retrouve avec des balises génériques dans l'en-tête de mon document. Toutefois, grâce à la coordination entre mon code de création de modèles et mon code côté client, je peux mettre à jour le titre de la fenêtre à l'aide de métadonnées spécifiques à la page.
Dans le code de modèle, mon approche consiste à inclure une balise de script contenant la chaîne correctement échappée.
const metadataScript = `<script>
self._title = '${escape(item.title)}';
</script>`;
Ensuite, une fois ma page chargée, je lis cette chaîne et mets à jour le titre du document.
if (self._title) {
document.title = unescape(self._title);
}
Si vous souhaitez mettre à jour d'autres éléments de métadonnées spécifiques à une page dans votre propre application Web, vous pouvez suivre la même approche.
Expérience utilisateur hors connexion
L'autre amélioration progressive que j'ai ajoutée sert à attirer l'attention sur nos fonctionnalités hors connexion. J'ai créé une PWA fiable et je veux que les utilisateurs sachent qu'ils peuvent toujours charger les pages qu'ils ont déjà consultées lorsqu'ils sont hors connexion.
Tout d'abord, j'utilise l'API Cache Storage pour obtenir la liste de toutes les requêtes d'API précédemment mises en cache, que je traduis en liste d'URL.
Vous vous souvenez des attributs de données spéciaux dont je vous ai parlé, chacun contenant l'URL de la requête API nécessaire pour afficher une question ? Je peux croiser ces attributs de données avec la liste des URL mises en cache et créer un tableau de tous les liens de questions qui ne correspondent pas.
Lorsque le navigateur passe en mode hors connexion, je parcours la liste des liens non mis en cache et estompe ceux qui ne fonctionneront pas. N'oubliez pas qu'il s'agit simplement d'un indice visuel pour l'utilisateur sur ce à quoi il doit s'attendre de ces pages. Je ne désactive pas réellement les liens ni n'empêche l'utilisateur de naviguer.
const apiCache = await caches.open(API_CACHE_NAME);
const cachedRequests = await apiCache.keys();
const cachedUrls = cachedRequests.map(request => request.url);
const cards = document.querySelectorAll('.card');
const uncachedCards = [...cards].filter(card => {
return !cachedUrls.includes(card.dataset.cacheUrl);
});
const offlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '0.3';
}
};
const onlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '1.0';
}
};
window.addEventListener('online', onlineHandler);
window.addEventListener('offline', offlineHandler);
Écueils les plus courants
Je viens de vous présenter mon approche pour créer une PWA multipage. Vous devrez tenir compte de nombreux facteurs lorsque vous élaborerez votre propre approche. Il est possible que vous fassiez des choix différents des miens. Cette flexibilité est l'un des grands avantages du développement pour le Web.
Vous pouvez rencontrer quelques pièges courants lorsque vous prenez vos propres décisions architecturales. Je veux vous éviter quelques désagréments.
Ne mettez pas en cache le code HTML complet.
Je vous déconseille de stocker des documents HTML complets dans votre cache. Tout d'abord, c'est un gaspillage d'espace. Si votre application Web utilise la même structure HTML de base pour chacune de ses pages, vous finirez par stocker des copies du même balisage encore et encore.
Plus important encore, si vous déployez une modification de la structure HTML partagée de votre site, chacune de ces pages mises en cache précédemment reste bloquée avec votre ancienne mise en page. Imaginez la frustration d'un visiteur régulier qui voit un mélange d'anciennes et de nouvelles pages.
Décalage entre le serveur et le service worker
L'autre piège à éviter concerne la désynchronisation de votre serveur et de votre service worker. Mon approche consistait à utiliser JavaScript isomorphe, afin que le même code soit exécuté aux deux endroits. En fonction de l'architecture de votre serveur existant, cela n'est pas toujours possible.
Quelles que soient les décisions architecturales que vous prenez, vous devez avoir une stratégie pour exécuter le code de routage et de création de modèles équivalent dans votre serveur et votre service worker.
Pires scénarios
Mise en page / design incohérents
Que se passe-t-il si vous ignorez ces pièges ? De nombreux types d'échecs sont possibles, mais le pire scénario est qu'un utilisateur récurrent visite une page mise en cache avec une mise en page très obsolète, par exemple une page avec un texte d'en-tête obsolète ou qui utilise des noms de classes CSS qui ne sont plus valides.
Pire scénario : routage défaillant
Il est également possible qu'un utilisateur tombe sur une URL gérée par votre serveur, mais pas par votre service worker. Un site rempli de mises en page zombies et d'impasses n'est pas une PWA fiable.
Les clés de la réussite
Mais vous n'êtes pas seul·e ! Voici quelques conseils pour vous aider à éviter ces pièges :
Utilisez des bibliothèques de modèles et de routage qui disposent d'implémentations multilingues.
Essayez d'utiliser des bibliothèques de modèles et de routage qui ont des implémentations JavaScript. Je sais que tous les développeurs n'ont pas le luxe de migrer depuis leur serveur Web et leur langage de templating actuels.
Toutefois, un certain nombre de frameworks de routage et de création de modèles populaires disposent d'implémentations dans plusieurs langages. Si vous en trouvez un qui fonctionne avec JavaScript et la langue de votre serveur actuel, vous serez un peu plus près de synchroniser votre service worker et votre serveur.
Privilégiez les modèles séquentiels plutôt que les modèles imbriqués
Ensuite, je vous recommande d'utiliser une série de modèles séquentiels qui peuvent être diffusés les uns après les autres. Il n'y a pas de problème si les parties ultérieures de votre page utilisent une logique de modèle plus complexe, à condition que vous puissiez diffuser la partie initiale de votre code HTML le plus rapidement possible.
Mettre en cache le contenu statique et dynamique dans votre service worker
Pour des performances optimales, vous devez prémettre en cache toutes les ressources statiques critiques de votre site. Vous devez également configurer une logique de mise en cache d'exécution pour gérer le contenu dynamique, comme les requêtes API. L'utilisation de Workbox signifie que vous pouvez vous appuyer sur des stratégies bien testées et prêtes pour la production au lieu de tout implémenter à partir de zéro.
Ne bloquez les annonces sur le réseau qu'en cas d'absolue nécessité.
De plus, vous ne devez bloquer le réseau que lorsqu'il n'est pas possible de diffuser une réponse à partir du cache. Afficher immédiatement une réponse d'API mise en cache peut souvent améliorer l'expérience utilisateur par rapport à l'attente de données actualisées.