

Давайте поговорим об... архитектуре?
Я собираюсь рассмотреть важную, но, возможно, неправильно понятую тему: архитектуру, которую вы используете для своего веб-приложения, и, в частности, то, как ваши архитектурные решения вступают в силу при создании прогрессивного веб-приложения.
«Архитектура» может звучать расплывчато, и не сразу понятно, почему это важно. Один из способов разобраться в архитектуре — задать себе следующие вопросы: какой HTML-код загружается, когда пользователь посещает страницу моего сайта? И что загружается, когда он посещает другую страницу?
Ответы на эти вопросы не всегда однозначны, и как только вы начинаете думать о прогрессивных веб-приложениях, они могут стать ещё сложнее. Поэтому моя цель — познакомить вас с одной из возможных архитектур, которую я считаю эффективной. В этой статье я буду называть принятые мной решения «моим подходом» к созданию прогрессивного веб-приложения.
Вы можете использовать мой подход при создании собственного PWA, но в то же время всегда есть и другие приемлемые альтернативы. Надеюсь, что, увидев, как все элементы сочетаются друг с другом, вы вдохновитесь и почувствуете себя увереннее в адаптации под свои нужды.
Stack Overflow PWA
Для этой статьи я создал PWA для Stack Overflow . Я много времени провожу за чтением и участием в Stack Overflow , и мне хотелось создать веб-приложение, которое упростило бы просмотр часто задаваемых вопросов по заданной теме. Оно построено на основе общедоступного API Stack Exchange . У него открытый исходный код, и вы можете узнать больше , посетив проект GitHub .
Многостраничные приложения (MPA)
Прежде чем перейти к деталям, давайте определимся с некоторыми терминами и объясним базовые технологии. Сначала я расскажу о том, что я называю «многостраничными приложениями» (MPA).
MPA — это причудливое название традиционной архитектуры, используемой с самого зарождения интернета. Каждый раз, когда пользователь переходит по новому URL-адресу, браузер постепенно отображает HTML-код, соответствующий этой странице. При этом не предпринимается никаких попыток сохранить состояние страницы или её содержимое между переходами. Каждый раз, когда вы открываете новую страницу, вы начинаете всё заново.
Это отличается от модели одностраничных приложений (SPA) для создания веб-приложений, в которой браузер запускает код JavaScript для обновления текущей страницы при посещении пользователем нового раздела. Как SPA, так и MPA-приложения одинаково приемлемы для использования, но в этой статье я хотел рассмотреть концепции PWA в контексте многостраничного приложения.
Надежно быстро
Вы слышали от меня (и бесчисленного множества других) выражение «прогрессивное веб-приложение», или PWA. Возможно, вы уже знакомы с некоторыми справочными материалами на этом сайте .
PWA можно представить как веб-приложение, обеспечивающее первоклассный пользовательский интерфейс и по-настоящему заслуживающее место на главном экране. Аббревиатура « FIRE », означающая «Быстрый », «Интегрированный» , « Надежный» и «Взаимодействующий », отражает все характеристики, которые следует учитывать при создании PWA.
В этой статье я собираюсь сосредоточиться на подмножестве этих характеристик: Быстрота и Надежность .
Быстро: Хотя «быстро» имеет разное значение в разных контекстах, я собираюсь рассказать о преимуществах скорости за счет минимальной загрузки из сети.
Надёжность: Но одной скорости недостаточно. Чтобы ваше веб-приложение выглядело как PWA, оно должно быть надёжным. Оно должно быть достаточно устойчивым, чтобы всегда что-то загружать, даже если это всего лишь персонализированная страница с ошибкой, независимо от состояния сети.
Надёжно быстро: И наконец, я немного перефразирую определение PWA и разберу, что значит создать что-то надёжно быстрое. Недостаточно быть быстрым и надёжным только при работе в сети с низкой задержкой. Надёжно быстрое означает, что скорость вашего веб-приложения остаётся стабильной независимо от состояния сети.
Внедрение технологий: Service Workers + API кэш-хранилища
PWA предъявляют высокие требования к скорости и отказоустойчивости. К счастью, веб-платформа предлагает ряд базовых компонентов, позволяющих реализовать такую производительность. Я имею в виду сервис-воркеры и API кэширования .
Вы можете создать сервис-работника, который прослушивает входящие запросы, передает некоторые из них в сеть и сохраняет копию ответа для будущего использования с помощью API Cache Storage.
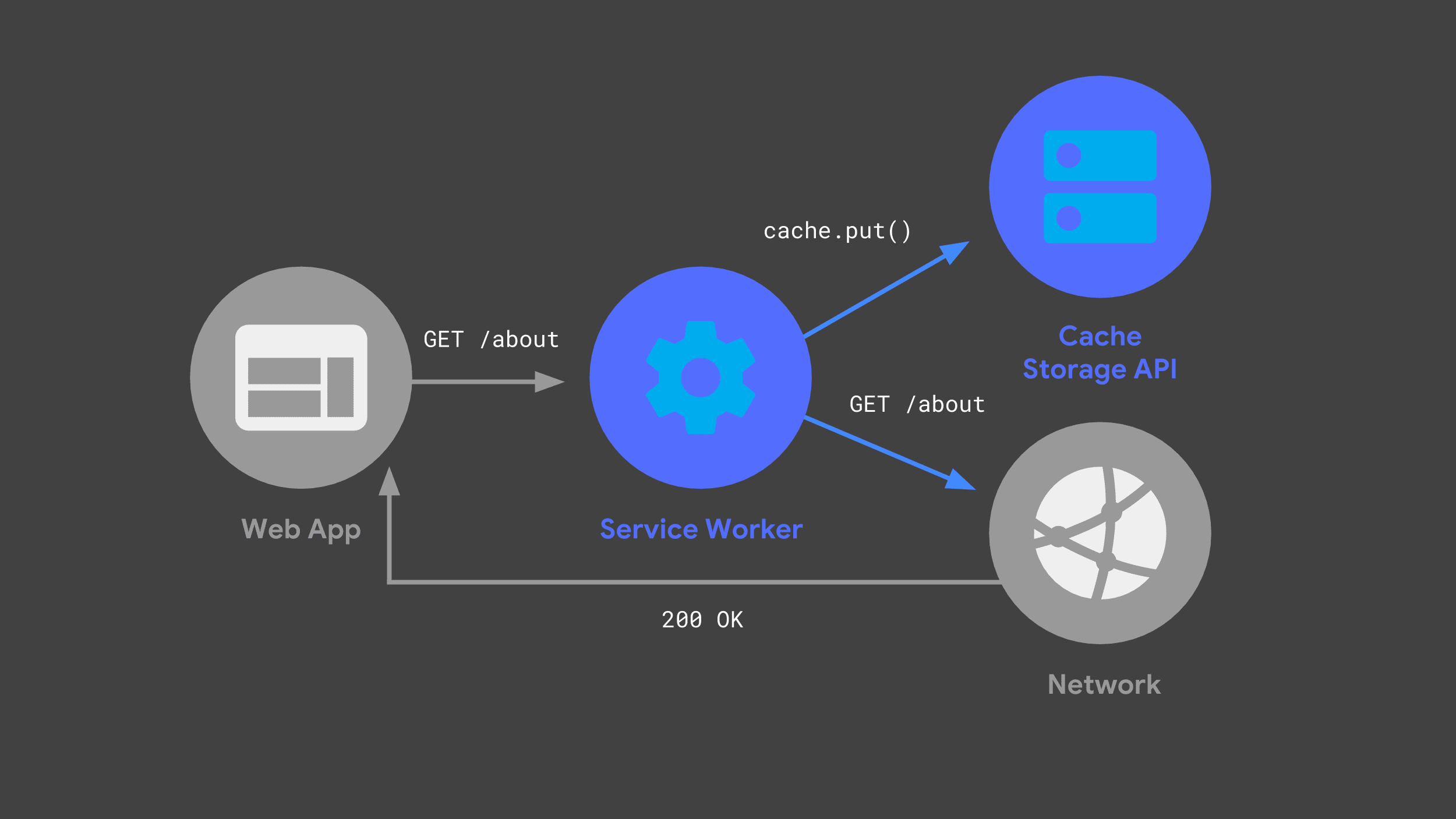
В следующий раз, когда веб-приложение сделает тот же запрос, его service worker сможет проверить свои кэши и просто вернуть ранее кэшированный ответ.
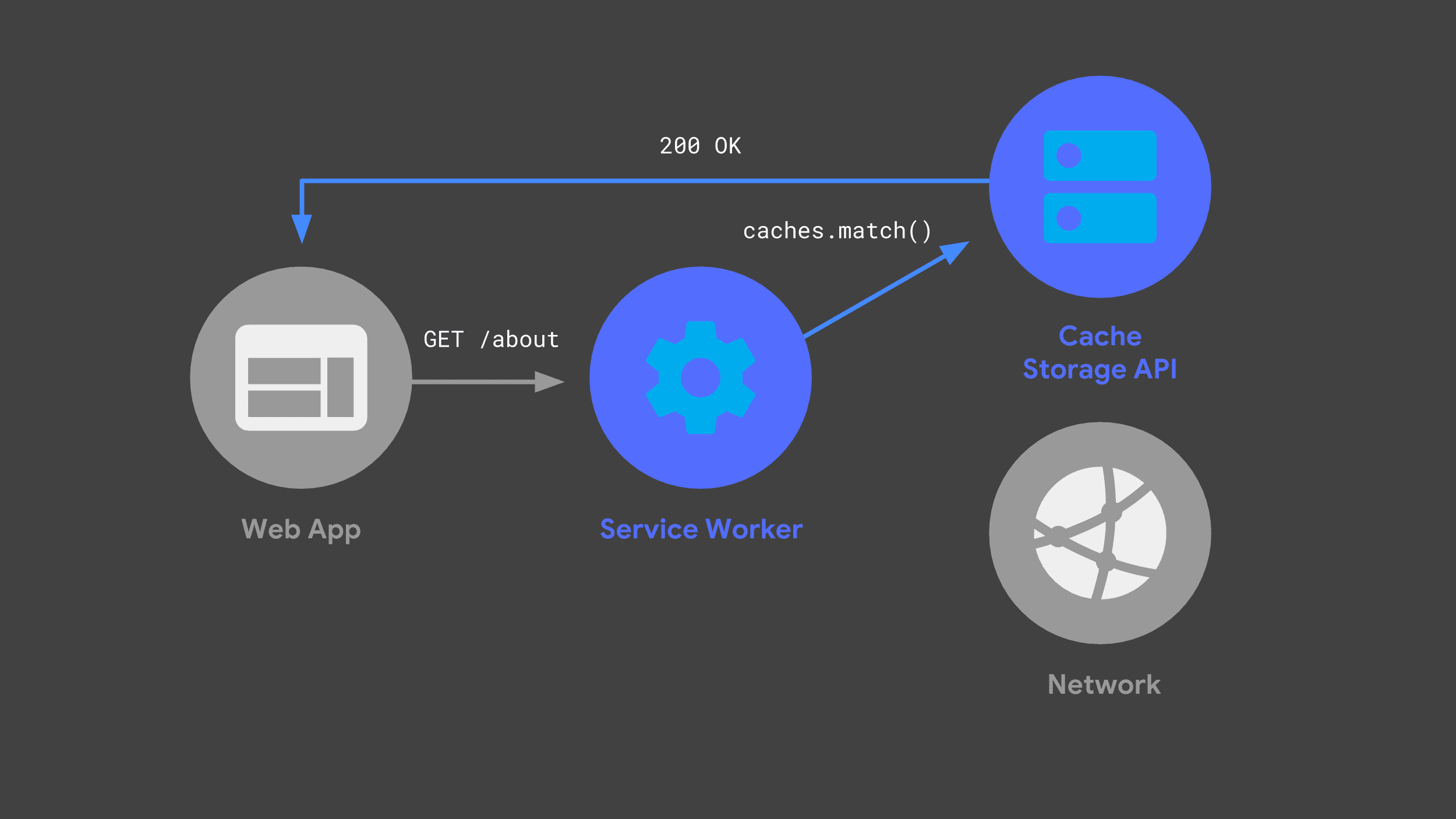
По возможности избегание сети является важнейшей частью обеспечения надежной и быстрой производительности.
«Изоморфный» JavaScript
Ещё одна концепция, которую я хочу рассмотреть, — это то, что иногда называют «изоморфным», или «универсальным», JavaScript . Проще говоря, это идея о том, что один и тот же код JavaScript может использоваться совместно в различных средах выполнения. При разработке PWA я хотел обеспечить общий код JavaScript для моего внутреннего сервера и сервис-воркера.
Существует множество приемлемых подходов к такому совместному использованию кода, но мой подход заключался в использовании модулей ES в качестве окончательного исходного кода. Затем я транспилировал и объединил эти модули для сервера и сервис-воркера, используя комбинацию Babel и Rollup . В моём проекте файлы с расширением .mjs — это код, находящийся в модуле ES.
Сервер
Учитывая эти концепции и терминологию, давайте подробно рассмотрим, как я создавал своё PWA на Stack Overflow. Начну с описания нашего внутреннего сервера и объясню, как он вписывается в общую архитектуру.
Я искал комбинацию динамического бэкэнда и статического хостинга, и мой подход заключался в использовании платформы Firebase.
Firebase Cloud Functions автоматически развернёт среду на базе Node при поступлении входящего запроса и интегрируется с популярным HTTP-фреймворком Express , с которым я уже был знаком. Кроме того, он предлагает готовый хостинг для всех статических ресурсов моего сайта. Давайте посмотрим, как сервер обрабатывает запросы.
Когда браузер отправляет навигационный запрос на наш сервер, он проходит следующий поток:
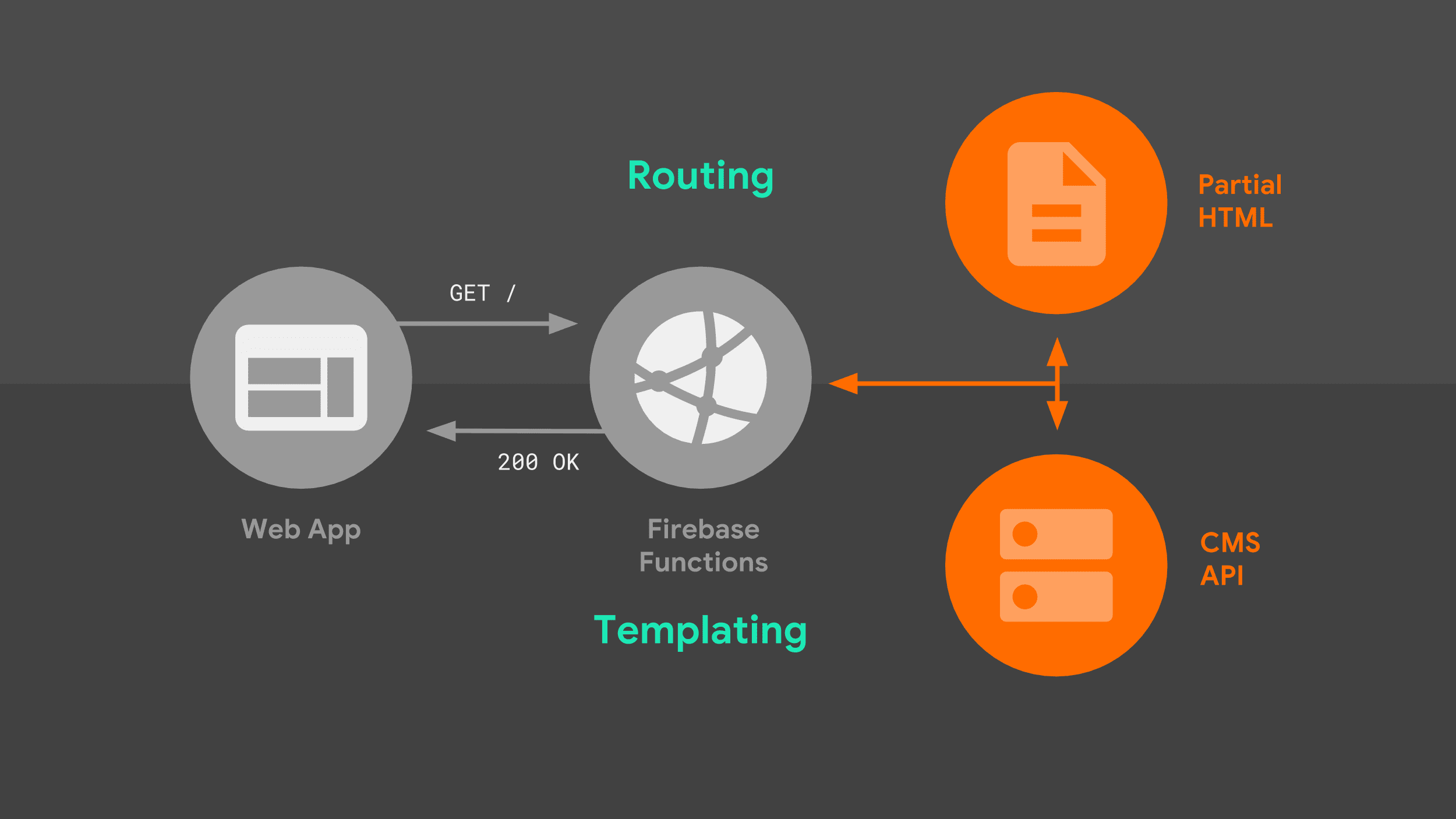
Сервер маршрутизирует запрос на основе URL и, используя шаблонную логику, создаёт полноценный HTML-документ. Я использую комбинацию данных из API Stack Exchange, а также частичные HTML-фрагменты, которые сервер хранит локально. Как только наш сервис-воркер определит, как реагировать, он может начать потоковую передачу HTML обратно в наше веб-приложение.
В этой картине есть две части, которые стоит рассмотреть более подробно: маршрутизация и шаблонизация.
Маршрутизация
Что касается маршрутизации, я решил использовать собственный синтаксис маршрутизации фреймворка Express. Он достаточно гибок для сопоставления простых префиксов URL-адресов, а также URL-адресов, включающих параметры в качестве части пути. Здесь я создаю сопоставление между именами маршрутов, с которыми будет сравниваться базовый шаблон Express.
const routes = new Map([
['about', '/about'],
['questions', '/questions/:questionId'],
['index', '/'],
]);
export default routes;
Затем я могу ссылаться на это сопоставление непосредственно из кода сервера . При обнаружении соответствия заданному шаблону Express соответствующий обработчик отвечает шаблонной логикой, соответствующей совпавшему маршруту.
import routes from './lib/routes.mjs';
app.get(routes.get('index'), async (req, res) => {
// Templating logic.
});
Шаблонизация на стороне сервера
И как выглядит эта логика шаблонизации? Я выбрал подход, при котором фрагменты HTML-кода собираются последовательно, один за другим. Эта модель хорошо подходит для потоковой передачи.
Сервер немедленно отправляет исходный HTML-шаблон, и браузер может сразу же отобразить эту часть страницы. По мере того, как сервер собирает оставшиеся данные, он передаёт их браузеру, пока документ не будет готов.
Чтобы понять, что я имею в виду, взгляните на код экспресса для одного из наших маршрутов:
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
Используя метод write() объекта response и ссылаясь на локально сохранённые частичные шаблоны, я могу немедленно запустить поток ответа, не блокируя внешние источники данных. Браузер принимает этот начальный HTML-код и сразу же отображает понятный интерфейс и сообщение о загрузке.
Следующая часть нашей страницы использует данные из API Stack Exchange . Для получения этих данных нашему серверу необходимо выполнить сетевой запрос. Веб-приложение не может отображать ничего, пока не получит ответ и не обработает его, но, по крайней мере, пользователи не смотрят на пустой экран в ожидании.
Получив ответ от API Stack Exchange, веб-приложение вызывает пользовательскую функцию шаблонизации для перевода данных из API в соответствующий HTML-код.
Язык шаблонов
Шаблонизация может быть на удивление спорной темой, и выбранный мной подход — лишь один из многих. Вам наверняка захочется найти собственное решение, особенно если у вас есть старые связи с существующим шаблонизатором.
В моём случае имело смысл просто положиться на шаблонные литералы JavaScript, выделив часть логики во вспомогательные функции. Одним из преимуществ создания MPA является отсутствие необходимости отслеживать обновления состояния и повторно рендерить HTML, поэтому мне подошёл базовый подход, создающий статический HTML.
Вот пример того, как я шаблонизирую динамическую HTML-часть индекса моего веб-приложения. Как и в случае с маршрутами, логика шаблонизации хранится в модуле ES , который можно импортировать как на сервер, так и в сервис-воркер.
export function index(tag, items) {
const title = `<h3>Top "${escape(tag)}" Questions</h3>`;
const form = `<form method="GET">...</form>`;
const questionCards = items
.map(item =>
questionCard({
id: item.question_id,
title: item.title,
})
)
.join('');
const questions = `<div id="questions">${questionCards}</div>`;
return title + form + questions;
}
Эти шаблонные функции написаны на чистом JavaScript, и при необходимости полезно разбить логику на более мелкие вспомогательные функции. Здесь я передаю каждый элемент, возвращаемый в ответе API, в одну такую функцию, которая создаёт стандартный HTML-элемент со всеми необходимыми атрибутами.
function questionCard({id, title}) {
return `<a class="card"
href="/questions/${id}"
data-cache-url="${questionUrl(id)}">${title}</a>`;
}
Особого внимания заслуживает атрибут data , который я добавляю к каждой ссылке, data-cache-url , и который указывает на URL-адрес API Stack Exchange, необходимый для отображения соответствующего вопроса. Имейте это в виду. Я вернусь к этому позже.
Возвращаясь к обработчику маршрутов , после завершения шаблонизации я передаю последнюю часть HTML-кода страницы в браузер и завершаю поток. Это сигнал для браузера о завершении прогрессивного рендеринга.
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
Итак, вот краткий обзор настроек моего сервера. Пользователи, впервые посещающие моё веб-приложение, всегда получают ответ от сервера, но когда посетитель возвращается в моё веб-приложение, мой сервис-воркер начинает отвечать. Давайте разберёмся.
Работник сферы услуг
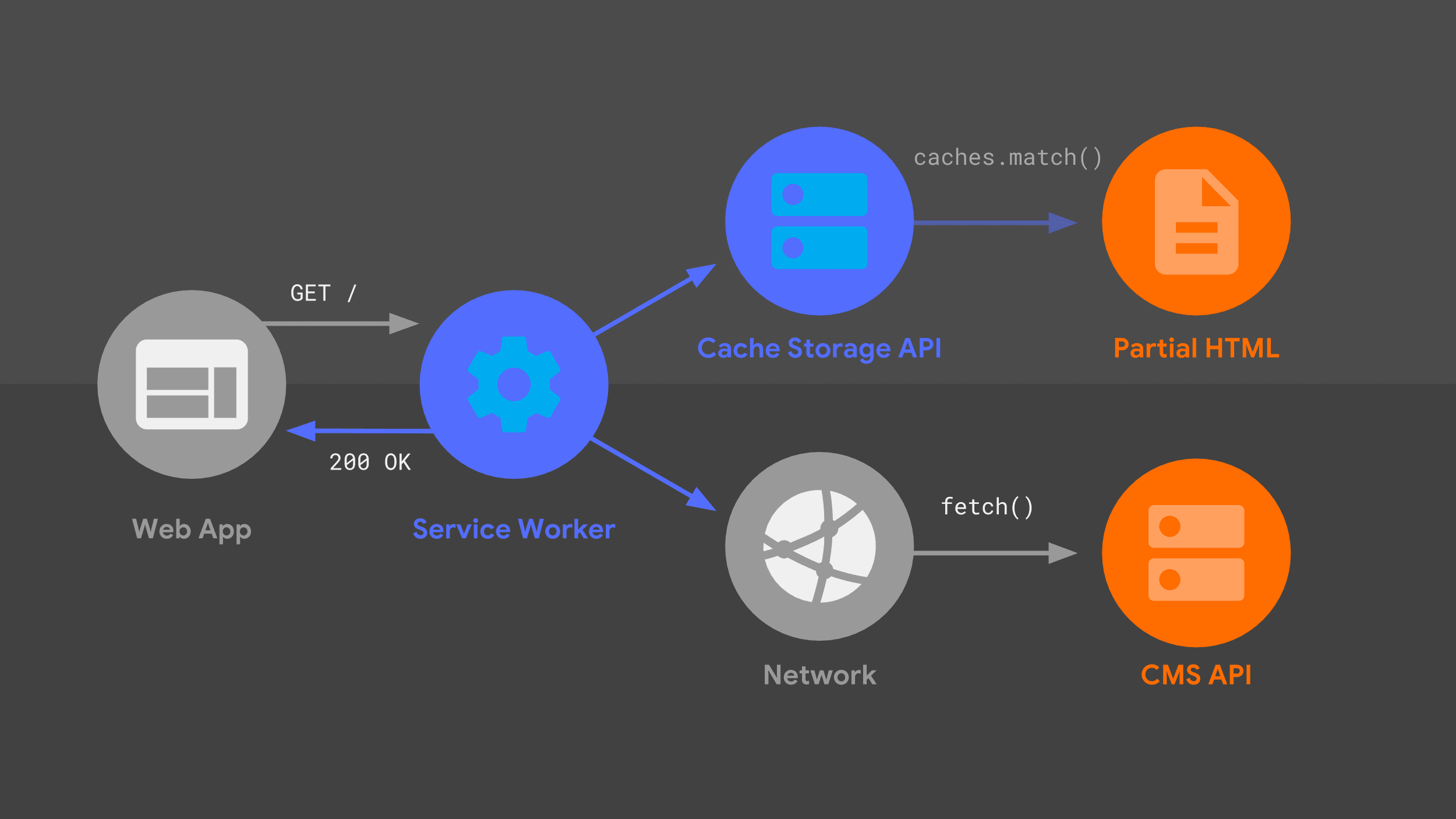
Эта диаграмма должна показаться вам знакомой — многие из рассмотренных ранее элементов здесь представлены немного иначе. Давайте рассмотрим поток запросов, учитывая сервис-воркер.
Наш сервисный работник обрабатывает входящий навигационный запрос для заданного URL-адреса и, как и мой сервер, он использует комбинацию маршрутизации и логики шаблонов, чтобы определить, как ответить.
Подход тот же, что и раньше, но с другими низкоуровневыми примитивами, такими как fetch() и API Cache Storage . Я использую эти источники данных для формирования HTML-ответа, который сервис-воркер передаёт обратно в веб-приложение.
Рабочий ящик
Вместо того, чтобы начинать с нуля с низкоуровневых примитивов, я собираюсь создать свой сервис-воркер на основе набора высокоуровневых библиотек Workbox . Он обеспечивает надёжную основу для любой логики кэширования, маршрутизации и генерации ответов сервис-воркера.
Маршрутизация
Как и в случае с кодом на стороне сервера, мой сервис-воркер должен знать, как сопоставлять входящий запрос с соответствующей логикой ответа.
Мой подход заключался в том, чтобы преобразовать каждый маршрут Express в соответствующее регулярное выражение , используя полезную библиотеку regexparam . После этого преобразования я могу воспользоваться встроенной поддержкой маршрутизации на основе регулярных выражений в Workbox.
После импорта модуля с регулярными выражениями я регистрирую каждое регулярное выражение в маршрутизаторе Workbox. Внутри каждого маршрута я могу реализовать собственную логику шаблонизации для генерации ответа. Шаблонизация в сервис-воркере немного сложнее, чем на моём внутреннем сервере, но Workbox помогает справиться со значительной частью работы.
import regExpRoutes from './regexp-routes.mjs';
workbox.routing.registerRoute(
regExpRoutes.get('index')
// Templating logic.
);
Кэширование статических активов
Одна из ключевых задач шаблонизации — обеспечить локальный доступ к моим частичным HTML-шаблонам через API Cache Storage и их актуальность при внесении изменений в веб-приложение. Обслуживание кэша вручную может быть подвержено ошибкам, поэтому я использую Workbox для предварительного кэширования в процессе сборки.
Я указываю Workbox, какие URL-адреса следует предварительно кэшировать, с помощью файла конфигурации , указывающего на каталог, содержащий все мои локальные ресурсы, а также набор шаблонов для сопоставления. Этот файл автоматически считывается интерфейсом командной строки Workbox , который запускается при каждой пересборке сайта.
module.exports = {
globDirectory: 'build',
globPatterns: ['**/*.{html,js,svg}'],
// Other options...
};
Workbox делает снимок содержимого каждого файла и автоматически добавляет этот список URL-адресов и версий в мой финальный файл сервис-воркера. Теперь у Workbox есть всё необходимое, чтобы предварительно кэшированные файлы всегда были доступны и поддерживались в актуальном состоянии. Результатом является файл service-worker.js , содержащий примерно следующее:
workbox.precaching.precacheAndRoute([
{
url: 'partials/about.html',
revision: '518747aad9d7e',
},
{
url: 'partials/foot.html',
revision: '69bf746a9ecc6',
},
// etc.
]);
Для тех, кто использует более сложный процесс сборки, в Workbox есть как плагин webpack , так и универсальный модуль Node , а также интерфейс командной строки .
Потоковое вещание
Затем я хочу, чтобы сервис-воркер немедленно передал этот предварительно кэшированный фрагмент HTML обратно в веб-приложение. Это критически важный фактор «надёжной скорости» — я всегда сразу получаю на экране что-то значимое. К счастью, использование API Streams в нашем сервис-воркере делает это возможным.
Возможно, вы уже слышали о Streams API. Мой коллега Джейк Арчибальд годами расхваливал его. Он смело предсказал, что 2016 год станет годом веб-трансляций. И Streams API сегодня так же хорош, как и два года назад, но с одним существенным отличием.
Хотя тогда потоки поддерживались только в Chrome, сейчас API потоков получил более широкую поддержку . В целом, ситуация позитивная, и при наличии подходящего резервного кода ничто не мешает вам использовать потоки в вашем сервис-воркере уже сегодня.
Что ж... вас может остановить одна вещь: вам нужно разобраться, как на самом деле работает API Streams. Он предоставляет очень мощный набор примитивов, и разработчики, которые умеют им пользоваться, могут создавать сложные потоки данных, например, такие:
const stream = new ReadableStream({
pull(controller) {
return sources[0]
.then(r => r.read())
.then(result => {
if (result.done) {
sources.shift();
if (sources.length === 0) return controller.close();
return this.pull(controller);
} else {
controller.enqueue(result.value);
}
});
},
});
Но понимание всех последствий этого кода может быть не всем по плечу. Вместо того, чтобы разбираться в этой логике, давайте поговорим о моём подходе к потоковой передаче сервис-воркеров.
Я использую совершенно новую высокоуровневую обёртку workbox-streams . С её помощью я могу передавать данные из разных источников потокового вещания, как из кэшей, так и из данных времени выполнения, которые могут поступать из сети. Workbox берёт на себя координацию отдельных источников и их объединение в единый потоковый ответ.
Кроме того, Workbox автоматически определяет, поддерживается ли API Streams, и если нет, создаёт эквивалентный ответ, не требующий потоковой передачи. Это означает, что вам не придётся беспокоиться о написании резервных вариантов, поскольку поддержка потоков браузерами постепенно приближается к 100%.
Кэширование во время выполнения
Давайте посмотрим, как мой сервис-воркер обрабатывает данные времени выполнения из API Stack Exchange. Я использую встроенную в Workbox поддержку стратегии кэширования «устаревание при повторной проверке» , а также функцию истечения срока действия, чтобы гарантировать, что хранилище веб-приложения не будет расти бесконтрольно.
Я настроил в Workbox две стратегии для обработки различных источников, которые будут формировать потоковый ответ. Всего несколько вызовов функций и настройка Workbox позволяют нам делать то, что в противном случае потребовало бы написания сотен строк кода вручную.
const cacheStrategy = workbox.strategies.cacheFirst({
cacheName: workbox.core.cacheNames.precache,
});
const apiStrategy = workbox.strategies.staleWhileRevalidate({
cacheName: API_CACHE_NAME,
plugins: [new workbox.expiration.Plugin({maxEntries: 50})],
});
Первая стратегия считывает данные, которые были предварительно кэшированы, например наши частичные HTML-шаблоны.
Другая стратегия реализует логику кэширования «устаревание при повторной проверке», а также истечение срока действия кэша для наиболее давно использовавшихся записей после достижения 50 записей.
Теперь, когда все эти стратегии готовы, остаётся только указать Workbox , как использовать их для построения полноценного потокового ответа. Я передаю массив источников в виде функций, и каждая из этих функций будет выполнена немедленно. Workbox получает результат из каждого источника и последовательно передаёт его в веб-приложение, задержавшись только в том случае, если следующая функция в массиве ещё не завершена.
workbox.streams.strategy([
() => cacheStrategy.makeRequest({request: '/head.html'}),
() => cacheStrategy.makeRequest({request: '/navbar.html'}),
async ({event, url}) => {
const tag = url.searchParams.get('tag') || DEFAULT_TAG;
const listResponse = await apiStrategy.makeRequest(...);
const data = await listResponse.json();
return templates.index(tag, data.items);
},
() => cacheStrategy.makeRequest({request: '/foot.html'}),
]);
Первые два источника представляют собой предварительно кэшированные частичные шаблоны, считываемые непосредственно из API Cache Storage, поэтому они всегда будут доступны немедленно. Это гарантирует, что наша реализация сервис-воркера будет стабильно быстро реагировать на запросы, как и мой серверный код.
Наша следующая функция источника извлекает данные из API Stack Exchange и преобразует ответ в HTML, который ожидает веб-приложение.
Стратегия «stale-while-revalidate» означает, что если у меня есть ранее кэшированный ответ для этого вызова API, я смогу немедленно передать его на страницу, одновременно обновляя запись кэша «в фоновом режиме» для следующего раза, когда он будет запрошен.
Наконец, я передаю кэшированную копию нижнего колонтитула и закрываю последние HTML-теги, чтобы завершить ответ.
Общий код обеспечивает синхронизацию
Вы заметите, что некоторые фрагменты кода сервис-воркера кажутся вам знакомыми. Часть HTML-кода и логика шаблонизации, используемые моим сервис-воркером, идентичны той, что используется в моём серверном обработчике. Такое совместное использование кода гарантирует единообразие взаимодействия пользователей, независимо от того, посещают ли они моё веб-приложение впервые или возвращаются на страницу, отрисованную сервис-воркером. В этом и заключается прелесть изоморфного JavaScript.
Динамические, прогрессивные улучшения
Я рассмотрел и сервер, и сервис-воркера для моего PWA, но осталось рассмотреть еще один последний логический элемент: на каждой из моих страниц после их полной загрузки выполняется небольшой фрагмент JavaScript .
Этот код постепенно улучшает пользовательский интерфейс, но не является критически важным — веб-приложение будет работать, даже если оно не запущено.
Метаданные страницы
Моё приложение использует клиентский JavaScipt для обновления метаданных страницы на основе ответа API. Поскольку я использую один и тот же начальный фрагмент кэшированного HTML для каждой страницы, веб-приложение в конечном итоге использует общие теги в заголовке документа. Но благодаря координации между шаблонизатором и клиентским кодом я могу обновлять заголовок окна, используя метаданные, специфичные для страницы.
В качестве части шаблонного кода мой подход заключается в том, чтобы включить тег скрипта, содержащий правильно экранированную строку.
const metadataScript = `<script>
self._title = '${escape(item.title)}';
</script>`;
Затем, как только моя страница загрузилась , я считываю эту строку и обновляю заголовок документа.
if (self._title) {
document.title = unescape(self._title);
}
Если вы хотите обновить в своем веб-приложении другие метаданные, относящиеся к конкретной странице, вы можете использовать тот же подход.
Оффлайн UX
Другое прогрессивное улучшение, которое я добавил, призвано привлечь внимание к нашим офлайн-возможностям. Я создал надёжное PWA-приложение и хочу, чтобы пользователи знали, что даже в офлайн-режиме они могут загружать ранее посещённые страницы.
Сначала я использую API хранилища кэша, чтобы получить список всех ранее кэшированных запросов API, и перевожу его в список URL-адресов.
Помните те специальные атрибуты данных, о которых я говорил , каждый из которых содержит URL-адрес API-запроса, необходимого для отображения вопроса? Я могу сопоставить эти атрибуты данных со списком кэшированных URL-адресов и создать массив всех ссылок на вопросы, которые не совпали.
Когда браузер переходит в офлайн-режим, я перебираю список некэшированных ссылок и затемняю те, которые не работают. Имейте в виду, что это всего лишь визуальная подсказка пользователю о том, чего ему следует ожидать от этих страниц — я на самом деле не отключаю ссылки и не ограничиваю навигацию.
const apiCache = await caches.open(API_CACHE_NAME);
const cachedRequests = await apiCache.keys();
const cachedUrls = cachedRequests.map(request => request.url);
const cards = document.querySelectorAll('.card');
const uncachedCards = [...cards].filter(card => {
return !cachedUrls.includes(card.dataset.cacheUrl);
});
const offlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '0.3';
}
};
const onlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '1.0';
}
};
window.addEventListener('online', onlineHandler);
window.addEventListener('offline', offlineHandler);
Распространенные ошибки
Я подробно рассказал о своём подходе к созданию многостраничных PWA. При выборе собственного подхода вам придётся учитывать множество факторов, и, возможно, ваш выбор будет отличаться от моего. Такая гибкость — одно из главных преимуществ веб-разработки.
Есть несколько распространенных ошибок, с которыми вы можете столкнуться при принятии собственных архитектурных решений, и я хочу избавить вас от лишних хлопот.
Не кэшировать полный HTML
Я не рекомендую хранить в кэше полные HTML-документы. Во-первых, это пустая трата места. Если ваше веб-приложение использует одну и ту же базовую HTML-структуру для каждой страницы, вам придётся снова и снова хранить копии одной и той же разметки.
Что ещё важнее, если вы внедрите изменения в общую HTML-структуру своего сайта, все ранее кэшированные страницы останутся в старом макете. Представьте себе разочарование вернувшегося посетителя, увидевшего смесь старых и новых страниц.
Дрейф сервера/работника сервиса
Другая ловушка, которой следует избегать, — это рассинхронизация сервера и сервис-воркера. Мой подход заключался в использовании изоморфного JavaScript, чтобы один и тот же код выполнялся в обоих местах. В зависимости от архитектуры вашего сервера, это не всегда возможно.
Какие бы архитектурные решения вы ни приняли, у вас должна быть некая стратегия для запуска эквивалентного кода маршрутизации и шаблонизации на вашем сервере и в вашем сервис-воркере.
Наихудшие сценарии
Непоследовательная компоновка/дизайн
Что произойдёт, если игнорировать эти подводные камни? Конечно, возможны любые сбои, но в худшем случае вернувшийся пользователь попадёт на кэшированную страницу с очень устаревшим макетом — возможно, с устаревшим текстом заголовка или с недействительными именами CSS-классов.
Наихудший сценарий: нарушенная маршрутизация
В противном случае пользователь может столкнуться с URL-адресом, который обрабатывается вашим сервером, но не вашим сервис-воркером. Сайт, полный зомби-макетов и тупиков, не является надёжным PWA.
Советы для достижения успеха
Но вы не одиноки! Следующие советы помогут вам избежать этих ловушек:
Используйте библиотеки шаблонов и маршрутизации, имеющие многоязыковые реализации.
Старайтесь использовать библиотеки шаблонизации и маршрутизации, реализующие JavaScript. Конечно, я знаю, что не каждый разработчик может позволить себе отказаться от своего текущего веб-сервера и языка шаблонизации.
Однако ряд популярных фреймворков шаблонизации и маршрутизации реализованы на нескольких языках. Если вам удастся найти тот, который работает как с JavaScript, так и с языком вашего текущего сервера, вы станете на шаг ближе к синхронизации вашего сервис-воркера и сервера.
Отдавайте предпочтение последовательным, а не вложенным шаблонам
Далее я рекомендую использовать серию последовательных шаблонов, которые можно загружать один за другим. Не страшно, если последующие части страницы будут использовать более сложную логику шаблонизации, главное, чтобы вы могли загружать начальную часть HTML-кода как можно быстрее.
Кэшируйте как статический, так и динамический контент в вашем сервис-воркере.
Для достижения максимальной производительности следует предварительно кэшировать все критически важные статические ресурсы вашего сайта. Также следует настроить логику кэширования во время выполнения для обработки динамического контента, например, запросов API. Использование Workbox позволяет разрабатывать решения на основе проверенных и готовых к использованию стратегий, а не реализовывать всё с нуля.
Блокируйте сеть только в случае крайней необходимости.
В связи с этим блокировку сети следует применять только в тех случаях, когда невозможно получить потоковое сообщение из кэша. Немедленное отображение кэшированного ответа API часто может обеспечить лучший пользовательский опыт, чем ожидание новых данных.