

Hablemos de… ¿arquitectura?
Voy a abordar un tema importante, pero que tal vez no se comprenda bien: la arquitectura que usas para tu app web y, específicamente, cómo influyen tus decisiones de arquitectura cuando compilas una app web progresiva.
"Arquitectura" puede sonar vago, y tal vez no sea evidente de inmediato por qué es importante. Una forma de pensar en la arquitectura es hacerse las siguientes preguntas: Cuando un usuario visita una página de mi sitio, ¿qué HTML se carga? Y, luego, ¿qué se carga cuando visitan otra página?
Las respuestas a esas preguntas no siempre son sencillas y, una vez que empiezas a pensar en las apps web progresivas, pueden volverse aún más complicadas. Por lo tanto, mi objetivo es explicarte una posible arquitectura que me resultó eficaz. A lo largo de este artículo, etiquetaré las decisiones que tomé como "mi enfoque" para compilar una app web progresiva.
Puedes usar mi enfoque cuando compiles tu propia PWA, pero, al mismo tiempo, siempre hay otras alternativas válidas. Espero que ver cómo encajan todas las piezas te inspire y te sientas capaz de personalizarlo para que se adapte a tus necesidades.
AWP de Stack Overflow
Para acompañar este artículo, compilé una APW de Stack Overflow. Paso mucho tiempo leyendo y contribuyendo a Stack Overflow, y quería crear una app web que facilitara la búsqueda de preguntas frecuentes sobre un tema determinado. Se basa en la API pública de Stack Exchange. Es de código abierto y puedes obtener más información en el proyecto de GitHub.
Aplicaciones de varias páginas (MPA)
Antes de entrar en detalles, definamos algunos términos y expliquemos partes de la tecnología subyacente. Primero, explicaré lo que me gusta llamar "apps de varias páginas" o "MPA".
MPA es un nombre elegante para la arquitectura tradicional que se usa desde los inicios de la Web. Cada vez que un usuario navega a una URL nueva, el navegador renderiza de forma progresiva el código HTML específico de esa página. No se intenta conservar el estado de la página ni el contenido entre las navegaciones. Cada vez que visitas una página nueva, comienzas de cero.
Esto contrasta con el modelo de aplicación de una sola página (SPA) para compilar aplicaciones web, en el que el navegador ejecuta código JavaScript para actualizar la página existente cuando el usuario visita una nueva sección. Tanto las SPA como las MPA son modelos igualmente válidos para usar, pero, en esta publicación, quería explorar los conceptos de las PWA en el contexto de una app de varias páginas.
Confiablemente rápido
Me has oído (y a muchas otras personas) usar la frase "app web progresiva", o AWP. Es posible que ya conozcas parte del material de referencia, que se encuentra en otras secciones de este sitio.
Puedes pensar en una AWP como una app web que proporciona una experiencia del usuario de primer nivel y que realmente se gana un lugar en la pantalla principal del usuario. El acrónimo "FIRE", que significa Rápida, Integrada, Confiable y Atractiva, resume todos los atributos que se deben tener en cuenta al compilar una PWA.
En este artículo, me enfocaré en un subconjunto de esos atributos: Rápido y Confiable.
Rápido: Si bien "rápido" significa diferentes cosas en diferentes contextos, voy a abordar los beneficios de velocidad de cargar lo menos posible desde la red.
Confiable: Sin embargo, la velocidad bruta no es suficiente. Para que se sienta como una AWP, tu app web debe ser confiable. Debe ser lo suficientemente resistente como para cargar siempre algo, incluso si se trata solo de una página de error personalizada, independientemente del estado de la red.
Confiablemente rápida: Por último, voy a reformular ligeramente la definición de PWA y analizaré qué significa crear algo que sea confiablemente rápido. No es suficiente ser rápido y confiable solo cuando estás en una red de baja latencia. Ser confiablemente rápida significa que la velocidad de tu app web es constante, independientemente de las condiciones de red subyacentes.
Tecnologías de habilitación: Service Workers y API de Cache Storage
Las AWP establecen un estándar alto de velocidad y resiliencia. Afortunadamente, la plataforma web ofrece algunos componentes básicos para que ese tipo de rendimiento sea una realidad. Me refiero a los service workers y la API de Cache Storage.
Puedes compilar un service worker que escuche las solicitudes entrantes, pase algunas a la red y almacene una copia de la respuesta para su uso futuro a través de la API de Cache Storage.
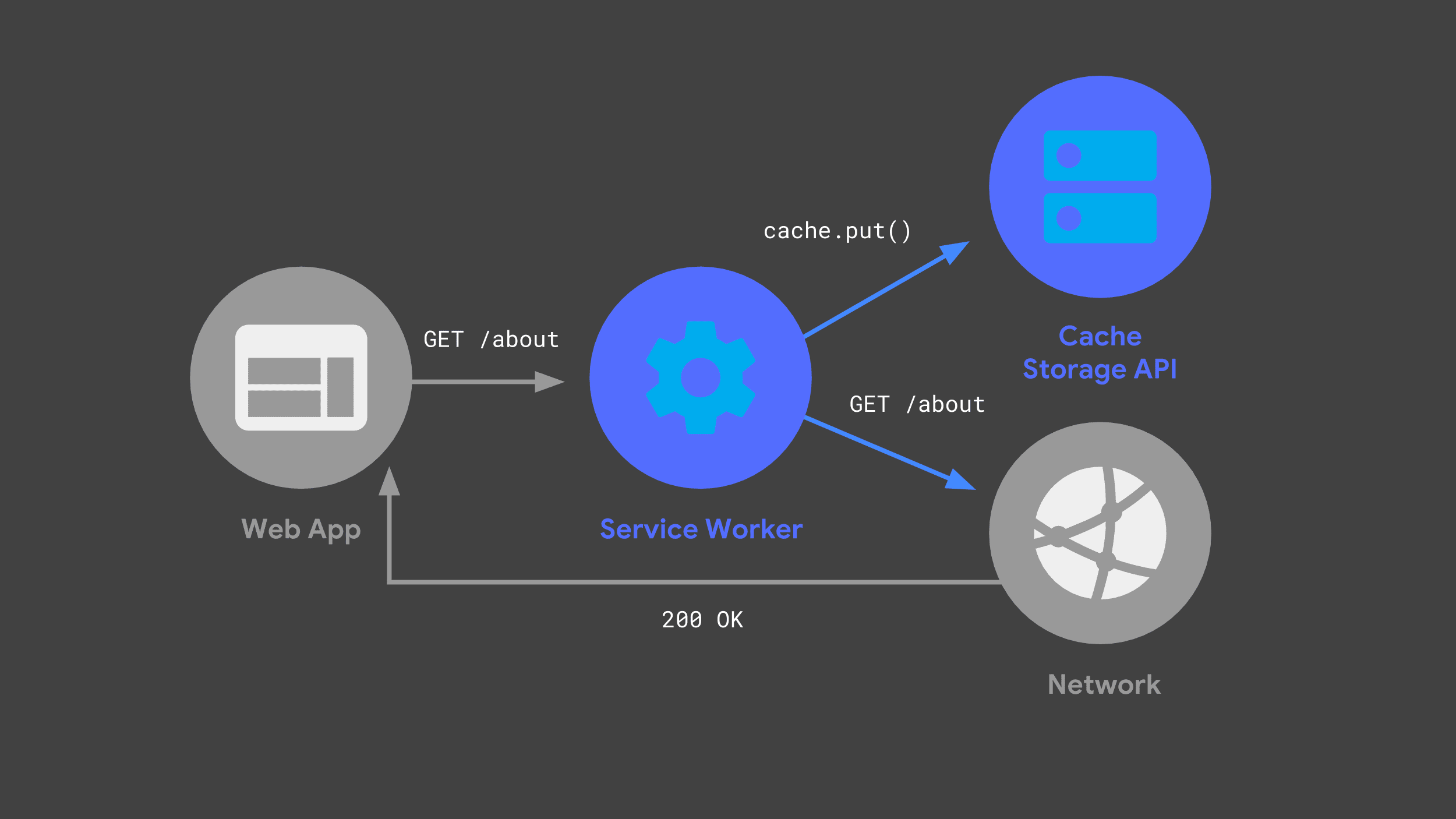
La próxima vez que la app web realice la misma solicitud, su service worker puede verificar sus cachés y solo devolver la respuesta almacenada en caché anteriormente.
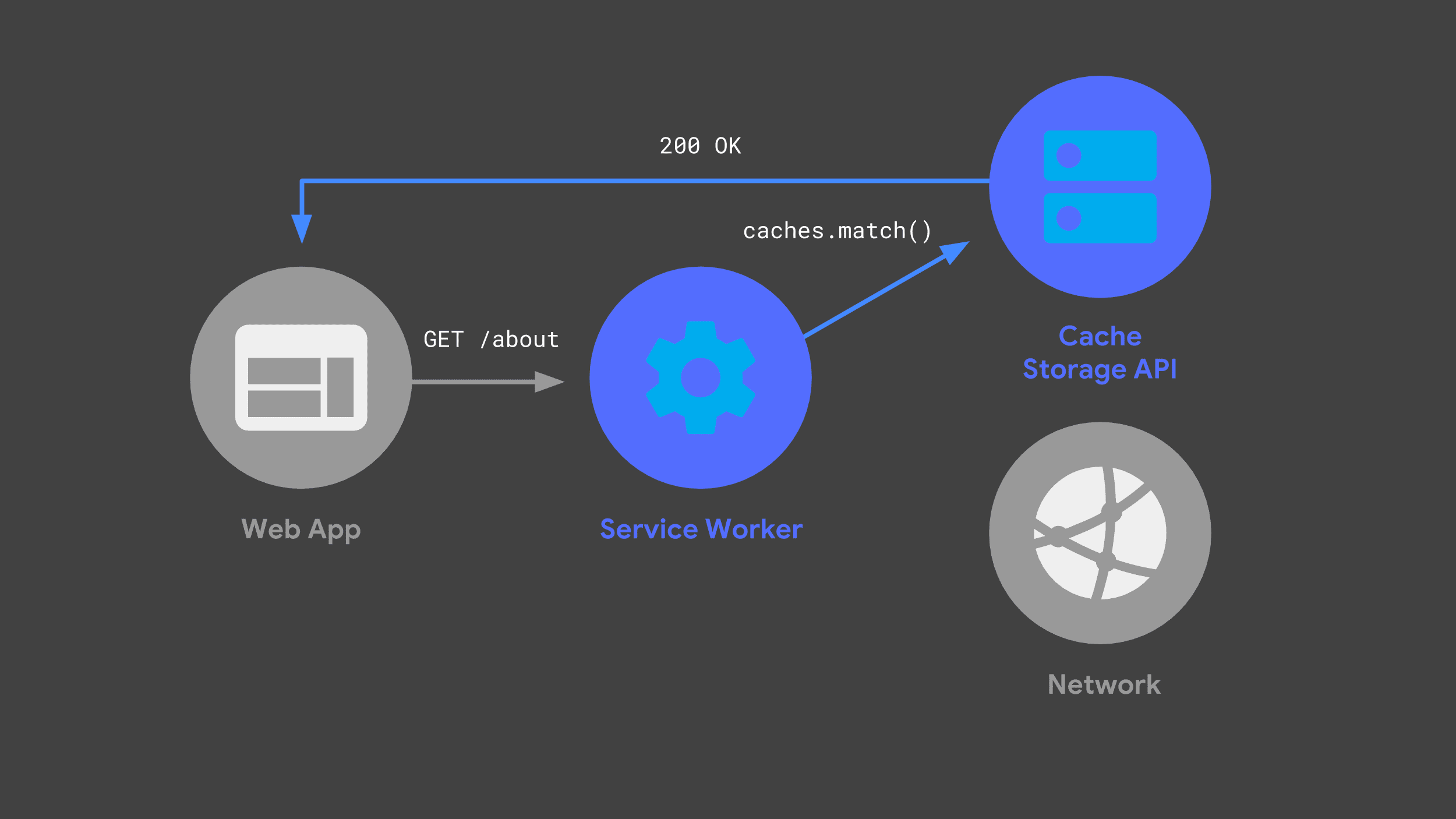
Evitar la red siempre que sea posible es una parte fundamental para ofrecer un rendimiento rápido y confiable.
JavaScript "isomórfico"
Otro concepto que quiero abordar es lo que a veces se conoce como JavaScript "isomórfico" o "universal". En pocas palabras, es la idea de que el mismo código JavaScript se puede compartir entre diferentes entornos de ejecución. Cuando compilé mi PWA, quería compartir código JavaScript entre mi servidor de backend y el service worker.
Hay muchos enfoques válidos para compartir código de esta manera, pero mi enfoque fue usar módulos ES como el código fuente definitivo. Luego, transpilé y empaqueté esos módulos para el servidor y el trabajador de servicio con una combinación de Babel y Rollup. En mi proyecto, los archivos con la extensión .mjs son código que reside en un módulo ES.
El servidor
Teniendo en cuenta esos conceptos y la terminología, veamos cómo creé mi PWA de Stack Overflow. Comenzaré por explicar nuestro servidor de backend y cómo se adapta a la arquitectura general.
Buscaba una combinación de un backend dinámico con alojamiento estático, y mi enfoque fue usar la plataforma de Firebase.
Firebase Cloud Functions activará automáticamente un entorno basado en Node cuando haya una solicitud entrante y se integrará con el popular framework HTTP de Express, que ya conocía. También ofrece alojamiento listo para usar para todos los recursos estáticos de mi sitio. Veamos cómo el servidor controla las solicitudes.
Cuando un navegador realiza una solicitud de navegación a nuestro servidor, se sigue el siguiente flujo:
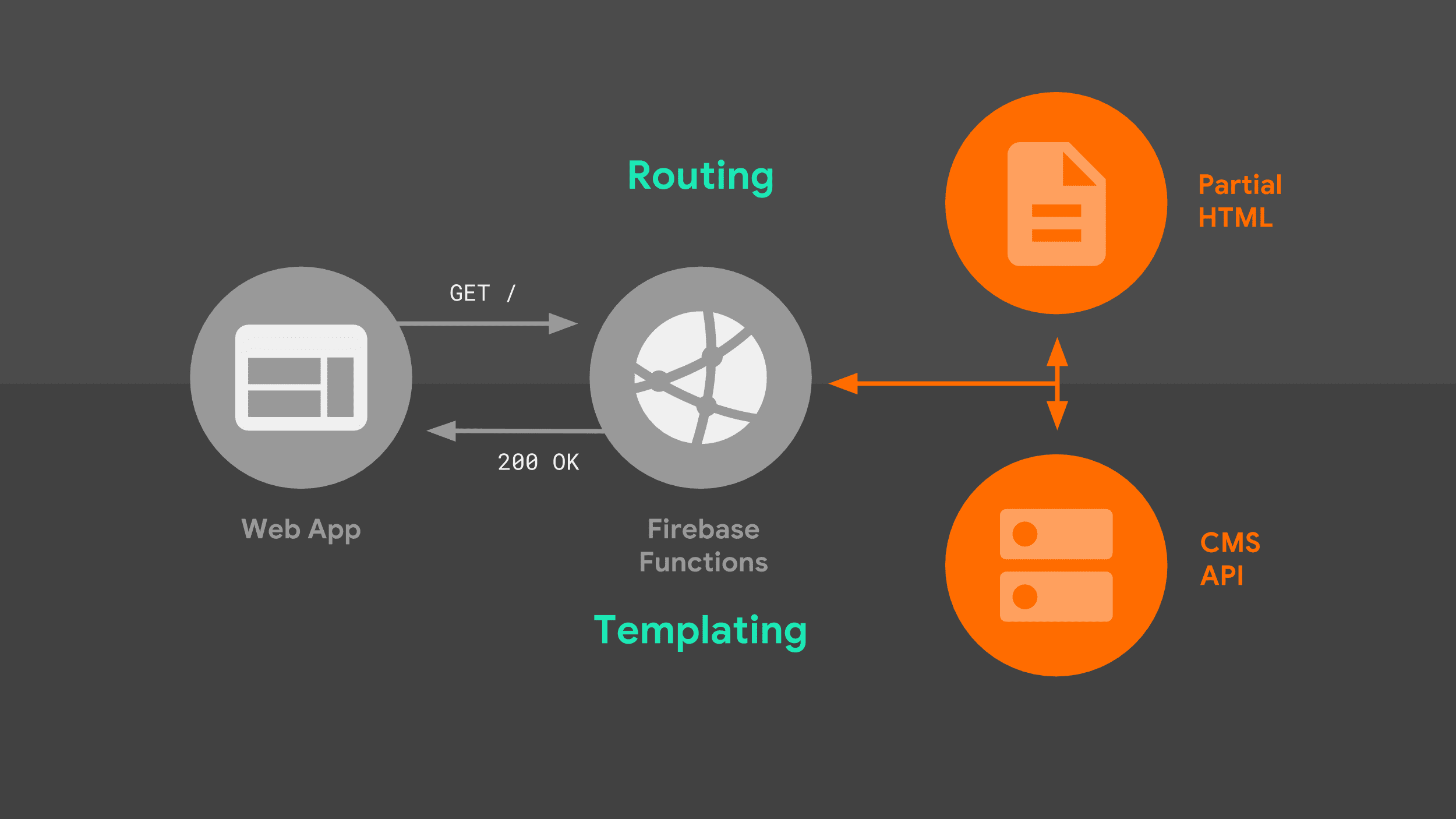
El servidor enruta la solicitud según la URL y usa la lógica de plantillas para crear un documento HTML completo. Uso una combinación de datos de la API de Stack Exchange y fragmentos HTML parciales que el servidor almacena de forma local. Una vez que nuestro service worker sabe cómo responder, puede comenzar a transmitir HTML a nuestra app web.
Hay dos aspectos de esta imagen que vale la pena explorar con más detalle: el enrutamiento y las plantillas.
Enrutamiento
En cuanto al enrutamiento, mi enfoque fue usar la sintaxis de enrutamiento nativa del framework de Express. Es lo suficientemente flexible como para coincidir con prefijos de URL simples, así como con URLs que incluyen parámetros como parte de la ruta. Aquí, creo una asignación entre los nombres de las rutas y el patrón de Express subyacente con el que se realizará la comparación.
const routes = new Map([
['about', '/about'],
['questions', '/questions/:questionId'],
['index', '/'],
]);
export default routes;
Luego, puedo hacer referencia a esta asignación directamente desde el código del servidor. Cuando hay una coincidencia para un patrón de Express determinado, el controlador adecuado responde con una lógica de plantillas específica para la ruta coincidente.
import routes from './lib/routes.mjs';
app.get(routes.get('index'), async (req, res) => {
// Templating logic.
});
Plantillas del servidor
¿Y cómo se ve esa lógica de plantillas? Bueno, adopté un enfoque que unía fragmentos HTML parciales en secuencia, uno tras otro. Este modelo se presta bien para la transmisión.
El servidor envía de inmediato una plantilla HTML inicial, y el navegador puede renderizar esa página parcial de inmediato. A medida que el servidor une el resto de las fuentes de datos, las transmite al navegador hasta que el documento se completa.
Para ver a qué me refiero, observa el código de Express de una de nuestras rutas:
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
Con el método write() del objeto response y haciendo referencia a plantillas parciales almacenadas de forma local, puedo iniciar el flujo de respuesta de inmediato, sin bloquear ninguna fuente de datos externa. El navegador toma este código HTML inicial y renderiza de inmediato una interfaz significativa y un mensaje de carga.
La siguiente parte de nuestra página usa datos de la API de Stack Exchange. Obtener esos datos significa que nuestro servidor debe realizar una solicitud de red. La app web no puede renderizar nada más hasta que recibe una respuesta y la procesa, pero, al menos, los usuarios no miran una pantalla en blanco mientras esperan.
Una vez que la app web recibe la respuesta de la API de Stack Exchange, llama a una función de plantillas personalizada para traducir los datos de la API a su HTML correspondiente.
Lenguaje de plantillas
Las plantillas pueden ser un tema sorprendentemente polémico, y lo que elegí es solo un enfoque entre muchos. Te recomendamos que sustituyas tu propia solución, en especial si tienes vínculos heredados con un framework de plantillas existente.
Para mi caso de uso, lo más lógico fue usar los literales de plantilla de JavaScript, con algo de lógica desglosada en funciones auxiliares. Una de las ventajas de compilar una MPA es que no tienes que hacer un seguimiento de las actualizaciones de estado ni volver a renderizar tu HTML, por lo que un enfoque básico que produjo HTML estático me funcionó.
Este es un ejemplo de cómo estoy creando una plantilla para la parte dinámica en HTML del índice de mi app web. Al igual que con mis rutas, la lógica de plantillas se almacena en un módulo ES que se puede importar tanto en el servidor como en el service worker.
export function index(tag, items) {
const title = `<h3>Top "${escape(tag)}" Questions</h3>`;
const form = `<form method="GET">...</form>`;
const questionCards = items
.map(item =>
questionCard({
id: item.question_id,
title: item.title,
})
)
.join('');
const questions = `<div id="questions">${questionCards}</div>`;
return title + form + questions;
}
Estas funciones de plantilla son JavaScript puro, y es útil dividir la lógica en funciones auxiliares más pequeñas cuando sea apropiado. Aquí, paso cada uno de los elementos que se muestran en la respuesta de la API a una de esas funciones, que crea un elemento HTML estándar con todos los atributos adecuados establecidos.
function questionCard({id, title}) {
return `<a class="card"
href="/questions/${id}"
data-cache-url="${questionUrl(id)}">${title}</a>`;
}
En particular, es importante un atributo de datos que agrego a cada vínculo, data-cache-url, establecido en la URL de la API de Stack Exchange que necesito para mostrar la pregunta correspondiente. Ten eso en cuenta. Lo volveré a ver más tarde.
Volviendo a mi controlador de rutas, una vez que se completa la creación de plantillas, transmito la parte final del código HTML de mi página al navegador y finalizo la transmisión. Esta es la señal para el navegador de que se completó la renderización progresiva.
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
Ese es un breve recorrido por la configuración de mi servidor. Los usuarios que visiten mi app web por primera vez siempre recibirán una respuesta del servidor, pero cuando un visitante regrese a mi app web, mi service worker comenzará a responder. Comencemos.
El service worker
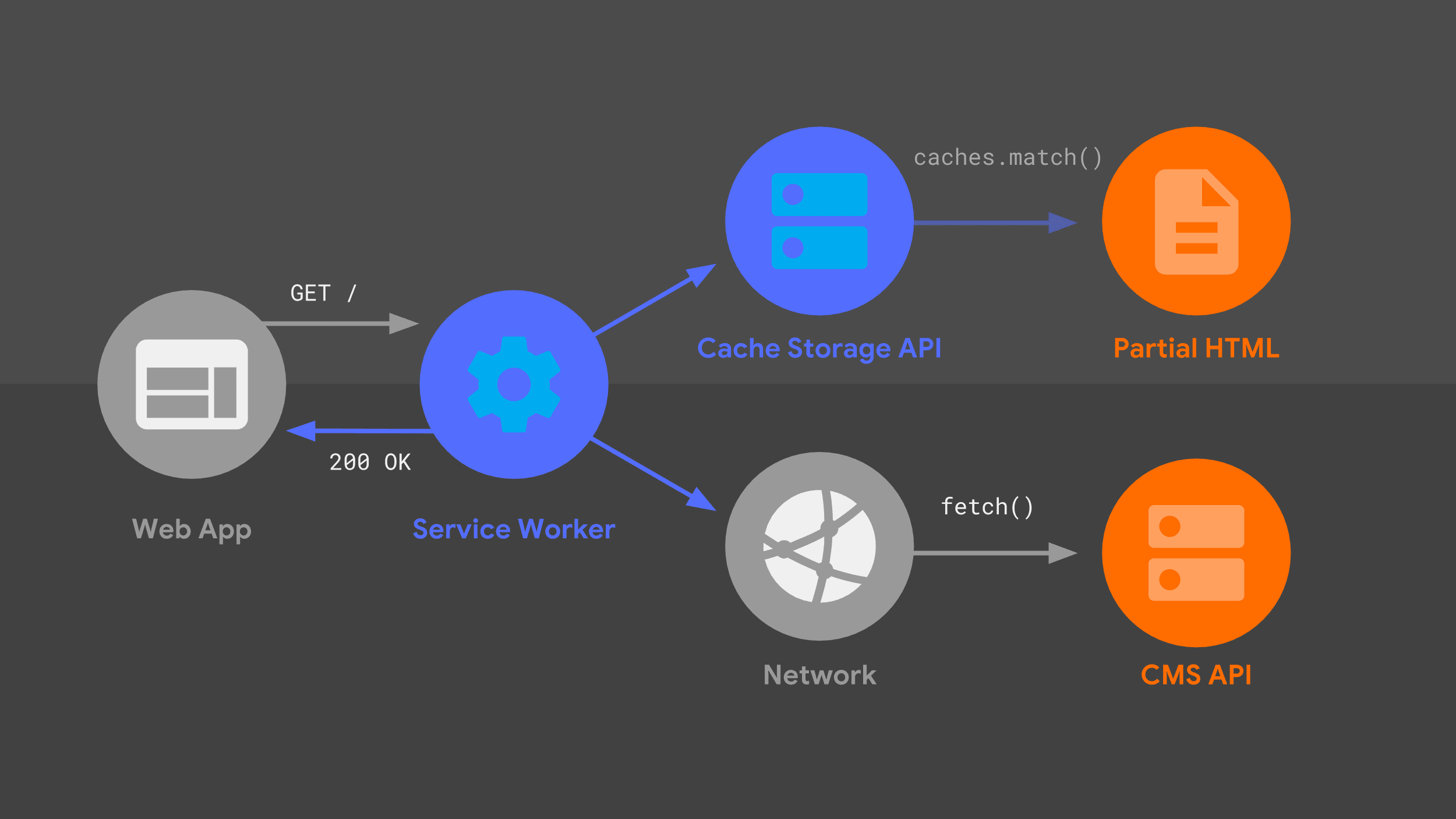
Este diagrama debería resultarte familiar, ya que muchas de las partes que ya expliqué se encuentran aquí en una disposición ligeramente diferente. Veamos el flujo de solicitudes, teniendo en cuenta el service worker.
Nuestro service worker controla una solicitud de navegación entrante para una URL determinada y, al igual que mi servidor, usa una combinación de lógica de enrutamiento y plantillas para determinar cómo responder.
El enfoque es el mismo que antes, pero con diferentes elementos primitivos de bajo nivel, como fetch() y la API de Cache Storage. Uso esas fuentes de datos para construir la respuesta HTML, que el trabajador de servicio pasa a la app web.
Workbox
En lugar de comenzar desde cero con elementos primitivos de bajo nivel, voy a compilar mi trabajador de servicio sobre un conjunto de bibliotecas de alto nivel llamadas Workbox. Proporciona una base sólida para la lógica de almacenamiento en caché, enrutamiento y generación de respuestas de cualquier trabajador de servicio.
Enrutamiento
Al igual que con mi código del servidor, mi trabajador de servicio necesita saber cómo hacer coincidir una solicitud entrante con la lógica de respuesta adecuada.
Mi enfoque fue traducir cada ruta de Express en una expresión regular correspondiente, utilizando una biblioteca útil llamada regexparam. Una vez que se realiza esa traducción, puedo aprovechar la compatibilidad integrada de Workbox con el enrutamiento de expresiones regulares.
Después de importar el módulo que tiene las expresiones regulares, registro cada expresión regular con el enrutador de Workbox. Dentro de cada ruta, puedo proporcionar lógica de plantillas personalizada para generar una respuesta. La creación de plantillas en el trabajador de servicio es un poco más compleja que en mi servidor de backend, pero Workbox ayuda con gran parte del trabajo pesado.
import regExpRoutes from './regexp-routes.mjs';
workbox.routing.registerRoute(
regExpRoutes.get('index')
// Templating logic.
);
Almacenamiento en caché de recursos estáticos
Una parte clave de la historia de las plantillas es asegurarse de que mis plantillas HTML parciales estén disponibles de forma local a través de la API de Cache Storage y se mantengan actualizadas cuando implemento cambios en la app web. El mantenimiento de la caché puede ser propenso a errores cuando se realiza de forma manual, por lo que recurro a Workbox para controlar el almacenamiento previo en caché como parte de mi proceso de compilación.
Le indico a Workbox qué URLs precachear con un archivo de configuración, que apunta al directorio que contiene todos mis recursos locales junto con un conjunto de patrones para que coincidan. La CLI de Workbox lee este archivo automáticamente, y se ejecuta cada vez que recompilo el sitio.
module.exports = {
globDirectory: 'build',
globPatterns: ['**/*.{html,js,svg}'],
// Other options...
};
Workbox toma una instantánea del contenido de cada archivo y, luego, inserta automáticamente esa lista de URLs y revisiones en mi archivo final del service worker. Workbox ahora tiene todo lo que necesita para que los archivos almacenados previamente en caché estén siempre disponibles y actualizados. El resultado es un archivo service-worker.js que contiene algo similar a lo siguiente:
workbox.precaching.precacheAndRoute([
{
url: 'partials/about.html',
revision: '518747aad9d7e',
},
{
url: 'partials/foot.html',
revision: '69bf746a9ecc6',
},
// etc.
]);
Para las personas que usan un proceso de compilación más complejo, Workbox tiene un complemento webpack y un módulo genérico de Node, además de su interfaz de línea de comandos.
Transmisión
A continuación, quiero que el service worker transmita ese HTML parcial almacenado previamente en caché a la app web de inmediato. Esta es una parte fundamental de ser "confiablemente rápido": siempre obtengo algo significativo en la pantalla de inmediato. Afortunadamente, usar la Streams API dentro de nuestro service worker lo hace posible.
Es posible que ya hayas oído hablar de la API de Streams. Mi colega Jake Archibald ha elogiado esta función durante años. Hizo la audaz predicción de que 2016 sería el año de las transmisiones web. Y la API de Streams sigue siendo tan increíble hoy como lo era hace dos años, pero con una diferencia crucial.
Si bien en ese entonces solo Chrome admitía Streams, la API de Streams ahora tiene una mayor compatibilidad. La historia general es positiva y, con el código de resguardo adecuado, nada te impide usar transmisiones en tu service worker hoy mismo.
Bueno… es posible que haya algo que te detenga, y es comprender cómo funciona realmente la API de Streams. Expone un conjunto muy potente de elementos primitivos, y los desarrolladores que se sienten cómodos con su uso pueden crear flujos de datos complejos, como los siguientes:
const stream = new ReadableStream({
pull(controller) {
return sources[0]
.then(r => r.read())
.then(result => {
if (result.done) {
sources.shift();
if (sources.length === 0) return controller.close();
return this.pull(controller);
} else {
controller.enqueue(result.value);
}
});
},
});
Sin embargo, comprender todas las implicaciones de este código podría no ser para todos. En lugar de analizar esta lógica, hablemos de mi enfoque para la transmisión de Service Workers.
Estoy usando un wrapper de alto nivel completamente nuevo, workbox-streams.
Con él, puedo pasarlo en una combinación de fuentes de transmisión, tanto de cachés como de datos de tiempo de ejecución que podrían provenir de la red. Workbox se encarga de coordinar las fuentes individuales y unirlas en una sola respuesta de transmisión.
Además, Workbox detecta automáticamente si se admite la API de Streams y, cuando no es así, crea una respuesta equivalente que no es de transmisión. Esto significa que no tienes que preocuparte por escribir alternativas, ya que las transmisiones se acercan cada vez más al 100% de compatibilidad con los navegadores.
Almacenamiento en caché del tiempo de ejecución
Veamos cómo mi service worker maneja los datos de tiempo de ejecución de la API de Stack Exchange. Utilizo la compatibilidad integrada de Workbox con una estrategia de almacenamiento en caché stale-while-revalidate, junto con la caducidad, para garantizar que el almacenamiento de la app web no crezca sin límites.
Configuré dos estrategias en Workbox para controlar las diferentes fuentes que compondrán la respuesta de transmisión. Con algunas llamadas a funciones y configuraciones, Workbox nos permite hacer lo que, de otro modo, requeriría cientos de líneas de código escritas a mano.
const cacheStrategy = workbox.strategies.cacheFirst({
cacheName: workbox.core.cacheNames.precache,
});
const apiStrategy = workbox.strategies.staleWhileRevalidate({
cacheName: API_CACHE_NAME,
plugins: [new workbox.expiration.Plugin({maxEntries: 50})],
});
La primera estrategia lee los datos que se almacenaron previamente en la caché, como nuestras plantillas HTML parciales.
La otra estrategia implementa la lógica de almacenamiento en caché stale-while-revalidate, junto con el vencimiento de la caché de elementos usados menos recientemente una vez que alcanzamos las 50 entradas.
Ahora que tengo esas estrategias implementadas, solo me queda indicarle a Workbox cómo usarlas para construir una respuesta completa y de transmisión. Paso un array de fuentes como funciones, y cada una de esas funciones se ejecutará de inmediato. Workbox toma el resultado de cada fuente y lo transmite a la app web, en secuencia, y solo se retrasa si la siguiente función del array aún no se completó.
workbox.streams.strategy([
() => cacheStrategy.makeRequest({request: '/head.html'}),
() => cacheStrategy.makeRequest({request: '/navbar.html'}),
async ({event, url}) => {
const tag = url.searchParams.get('tag') || DEFAULT_TAG;
const listResponse = await apiStrategy.makeRequest(...);
const data = await listResponse.json();
return templates.index(tag, data.items);
},
() => cacheStrategy.makeRequest({request: '/foot.html'}),
]);
Las dos primeras fuentes son plantillas parciales almacenadas previamente en caché que se leen directamente desde la API de Cache Storage, por lo que siempre estarán disponibles de inmediato. Esto garantiza que nuestra implementación del trabajador de servicio responderá a las solicitudes de forma confiable y rápida, al igual que mi código del servidor.
Nuestra siguiente función de origen recupera datos de la API de Stack Exchange y procesa la respuesta en el HTML que espera la app web.
La estrategia stale-while-revalidate significa que, si tengo una respuesta almacenada en caché anteriormente para esta llamada a la API, podré transmitirla a la página de inmediato y, al mismo tiempo, actualizar la entrada de caché "en segundo plano" para la próxima vez que se solicite.
Por último, transmito una copia almacenada en caché de mi pie de página y cierro las etiquetas HTML finales para completar la respuesta.
El código de uso compartido mantiene todo sincronizado
Notarás que ciertos fragmentos del código del Service Worker te resultarán familiares. El HTML parcial y la lógica de plantillas que usa mi Service Worker son idénticos a los que usa mi controlador del servidor. Este uso compartido de código garantiza que los usuarios tengan una experiencia coherente, ya sea que visiten mi app web por primera vez o que regresen a una página renderizada por el Service Worker. Esa es la belleza de JavaScript isomorfo.
Mejoras dinámicas y progresivas
Ya revisé el servidor y el trabajador de servicio de mi PWA, pero queda un último fragmento de lógica por cubrir: hay una pequeña cantidad de JavaScript que se ejecuta en cada una de mis páginas después de que se transmiten por completo.
Este código mejora progresivamente la experiencia del usuario, pero no es fundamental: la app web seguirá funcionando si no se ejecuta.
Metadatos de página
Mi app usa JavaScript del cliente para actualizar los metadatos de una página según la respuesta de la API. Como uso el mismo fragmento inicial de HTML almacenado en caché para cada página, la app web termina con etiquetas genéricas en el encabezado de mi documento. Sin embargo, a través de la coordinación entre mi código de plantillas y el código del cliente, puedo actualizar el título de la ventana con metadatos específicos de la página.
Como parte del código de plantilla, mi enfoque es incluir una etiqueta de secuencia de comandos que contenga la cadena con los caracteres de escape adecuados.
const metadataScript = `<script>
self._title = '${escape(item.title)}';
</script>`;
Luego, una vez que mi página se cargó, leo esa cadena y actualizo el título del documento.
if (self._title) {
document.title = unescape(self._title);
}
Si hay otros elementos de metadatos específicos de la página que deseas actualizar en tu propia app web, puedes seguir el mismo enfoque.
UX sin conexión
La otra mejora progresiva que agregué se usa para destacar nuestras capacidades sin conexión. Creé una PWA confiable y quiero que los usuarios sepan que, cuando estén sin conexión, podrán cargar las páginas que visitaron anteriormente.
Primero, uso la API de Cache Storage para obtener una lista de todas las solicitudes a la API almacenadas en caché anteriormente y la traduzco a una lista de URLs.
¿Recuerdas esos atributos de datos especiales de los que te hablé, cada uno de los cuales contiene la URL de la solicitud a la API necesaria para mostrar una pregunta? Puedo comparar esos atributos de datos con la lista de URLs almacenadas en caché y crear un array de todos los vínculos a preguntas que no coincidan.
Cuando el navegador entra en un estado sin conexión, itero la lista de vínculos sin almacenar en caché y atenúo los que no funcionarán. Ten en cuenta que esto es solo una sugerencia visual para el usuario sobre lo que debe esperar de esas páginas. En realidad, no estoy inhabilitando los vínculos ni impidiendo que el usuario navegue.
const apiCache = await caches.open(API_CACHE_NAME);
const cachedRequests = await apiCache.keys();
const cachedUrls = cachedRequests.map(request => request.url);
const cards = document.querySelectorAll('.card');
const uncachedCards = [...cards].filter(card => {
return !cachedUrls.includes(card.dataset.cacheUrl);
});
const offlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '0.3';
}
};
const onlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '1.0';
}
};
window.addEventListener('online', onlineHandler);
window.addEventListener('offline', offlineHandler);
Errores comunes
Ahora ya conoces mi enfoque para compilar una PWA de varias páginas. Hay muchos factores que deberás tener en cuenta cuando definas tu propio enfoque, y es posible que termines tomando decisiones diferentes a las que tomé yo. Esa flexibilidad es una de las mejores cosas de crear contenido para la Web.
Hay algunos errores comunes que puedes encontrar cuando tomas tus propias decisiones de arquitectura, y quiero ahorrarte algo de dolor.
No almacenes en caché el código HTML completo
No recomiendo almacenar documentos HTML completos en la caché. Para empezar, es una pérdida de espacio. Si tu app web usa la misma estructura HTML básica para cada una de sus páginas, terminarás almacenando copias del mismo lenguaje de marcado una y otra vez.
Lo que es más importante, si implementas un cambio en la estructura HTML compartida de tu sitio, todas esas páginas almacenadas en caché previamente seguirán teniendo tu diseño anterior. Imagina la frustración de un visitante recurrente que ve una combinación de páginas antiguas y nuevas.
Desviación del servidor o del trabajador de servicio
El otro inconveniente que debes evitar es que tu servidor y tu service worker se desincronicen. Mi enfoque fue usar JavaScript isomorfo, de modo que se ejecutara el mismo código en ambos lugares. Según la arquitectura del servidor existente, eso no siempre es posible.
Cualquiera sea la decisión arquitectónica que tomes, debes tener alguna estrategia para ejecutar el código equivalente de enrutamiento y plantillas en tu servidor y en tu service worker.
Situaciones extremas
Diseño o diseño incoherente
¿Qué sucede cuando ignoras esos inconvenientes? Bueno, son posibles todo tipo de fallas, pero el peor caso es que un usuario recurrente visite una página almacenada en caché con un diseño muy desactualizado, tal vez uno con texto de encabezado desactualizado o que use nombres de clases CSS que ya no son válidos.
Peor caso posible: Enrutamiento interrumpido
Como alternativa, un usuario puede encontrar una URL que controla tu servidor, pero no tu service worker. Un sitio lleno de diseños zombie y callejones sin salida no es una AWP confiable.
Sugerencias para tener éxito
Pero no estás solo en esto. Las siguientes sugerencias pueden ayudarte a evitar esos inconvenientes:
Usa bibliotecas de plantillas y de enrutamiento que tengan implementaciones en varios idiomas
Intenta usar bibliotecas de plantillas y de enrutamiento que tengan implementaciones de JavaScript. Ahora bien, sé que no todos los desarrolladores tienen el lujo de migrar de su servidor web y lenguaje de plantillas actuales.
Sin embargo, varios frameworks de enrutamiento y plantillas populares tienen implementaciones en varios lenguajes. Si encuentras uno que funcione con JavaScript y con el lenguaje de tu servidor actual, estarás un paso más cerca de mantener sincronizados tu servidor y tu service worker.
Prefiere plantillas secuenciales en lugar de anidadas
A continuación, te recomiendo que uses una serie de plantillas secuenciales que se puedan transmitir una tras otra. No hay problema si las partes posteriores de tu página usan una lógica de plantillas más complicada, siempre y cuando puedas transmitir la parte inicial de tu HTML lo más rápido posible.
Almacena en caché el contenido estático y dinámico en tu service worker
Para obtener el mejor rendimiento, debes almacenar en caché previamente todos los recursos estáticos críticos de tu sitio. También debes configurar la lógica de almacenamiento en caché del tiempo de ejecución para controlar el contenido dinámico, como las solicitudes de API. Usar Workbox significa que puedes compilar sobre estrategias bien probadas y listas para producción en lugar de implementar todo desde cero.
Bloquea solo en la red cuando sea absolutamente necesario
Además, solo debes bloquear la red cuando no sea posible transmitir una respuesta desde la caché. Mostrar de inmediato una respuesta de la API almacenada en caché suele generar una mejor experiencia del usuario que esperar datos nuevos.