

我們來談談... 架構?
接下來,我要說明一個重要但可能遭到誤解的主題:您用於網頁應用程式的架構,以及在建構漸進式網頁應用程式時,架構決策如何發揮作用。
「架構」聽起來可能很模糊,而且可能無法立即瞭解這項概念的重要性。其中一種思考架構的方式是問自己以下問題:使用者造訪我網站上的網頁時,會載入哪些 HTML?然後,使用者造訪其他網頁時會載入哪些內容?
這些問題的答案並不總是簡單明瞭,而且一旦開始思考漸進式網頁應用程式,問題就會變得更加複雜。因此,我的目標是帶您瞭解我認為有效的其中一種架構。在本文中,我會將自己建構漸進式網頁應用程式的決策標示為「我的方法」。
您可以在建構自己的 PWA 時自由使用我的方法,但同時也有其他有效的替代方案。希望您在瞭解所有環節如何環環相扣後,能受到啟發,並有信心根據自身需求進行自訂。
Stack Overflow PWA
為搭配本文,我建構了 Stack Overflow PWA。我花了很多時間閱讀和貢獻 Stack Overflow,因此想建構一個網路應用程式,方便瀏覽特定主題的常見問題。這項工具是以公開的 Stack Exchange API 為基礎建構而成。這項工具為開放原始碼,如要瞭解詳情,請前往 GitHub 專案。
多頁面應用程式 (MPA)
在深入探討細節之前,讓我們先定義一些術語,並說明基礎技術的各個部分。首先,我要介紹的是我所謂的「多頁面應用程式」(MPA)。
MPA 是傳統架構的別稱,自網路問世以來就一直使用這種架構。每當使用者前往新網址時,瀏覽器就會逐步算繪該網頁專屬的 HTML。系統不會嘗試保留導覽之間的網頁狀態或內容。每次造訪新頁面時,都會重新開始。
這與用於建構網頁應用程式的單頁應用程式 (SPA) 模型不同,在 SPA 模型中,使用者造訪新區段時,瀏覽器會執行 JavaScript 程式碼來更新現有網頁。SPA 和 MPA 都是同樣有效的模型,但本文想在多頁面應用程式的脈絡中,探討 PWA 概念。
速度飛快
您應該聽過我 (和無數其他人) 使用「漸進式網頁應用程式」或 PWA 這個詞彙。您可能已在本網站的其他位置,瞭解部分背景資料。
您可以將 PWA 視為提供頂級使用者體驗的網頁應用程式,並在使用者主畫面中佔有一席之地。「FIRE」這個縮寫字代表快速、整合、可靠和吸引力,總結了建構 PWA 時需要考慮的所有屬性。
在本文中,我將著重於這些屬性的子集:快速和可靠。
速度快: 「速度快」在不同情境中代表的意義不同,但我要說明的是從網路載入的內容越少,速度就越快。
可靠: 但光是提升速度還不夠,如要讓網頁應用程式有 PWA 的感覺,就必須具備可靠性。即使網路狀態不佳,也必須能載入內容 (即使只是自訂錯誤頁面)。
可靠快速: 最後,我要稍微改寫 PWA 的定義,並探討建構可靠快速的應用程式有何意義。如果只有在低延遲網路下才能快速穩定運作,那就還不夠好。穩定快速是指無論基礎網路狀況如何,網路應用程式的速度都能保持一致。
啟用技術:Service Worker + Cache Storage API
PWA 對速度和韌性有很高的要求。幸好,網頁平台提供了一些建構區塊,可實現這類效能。我指的是服務工作人員和 Cache Storage API。
您可以建立服務工作人員,監聽傳入的要求、將部分要求傳遞至網路,並透過 Cache Storage API 儲存回應副本,以供日後使用。
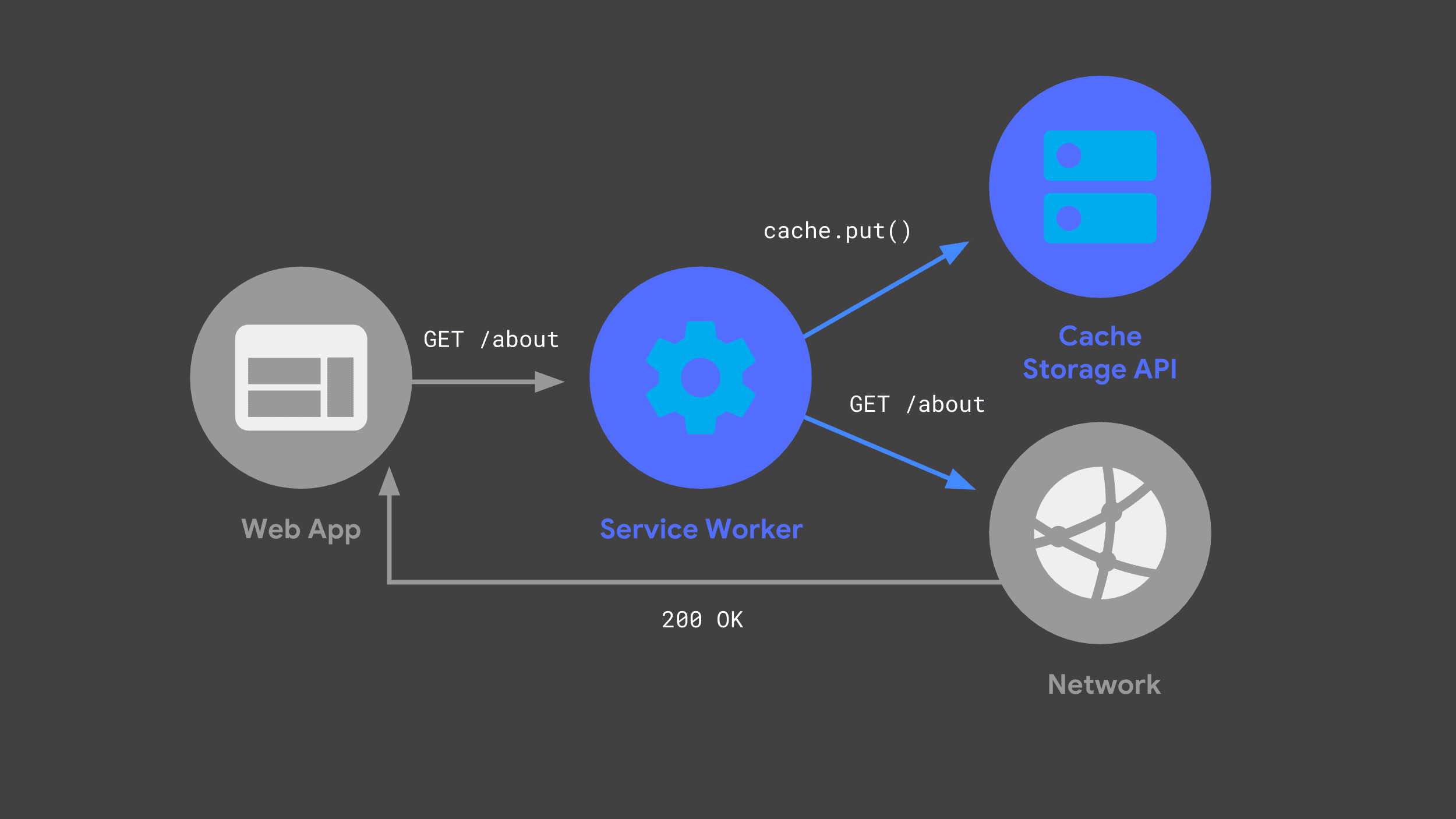
下次網路應用程式發出相同要求時,Service Worker 可以檢查快取,並只傳回先前快取的回應。
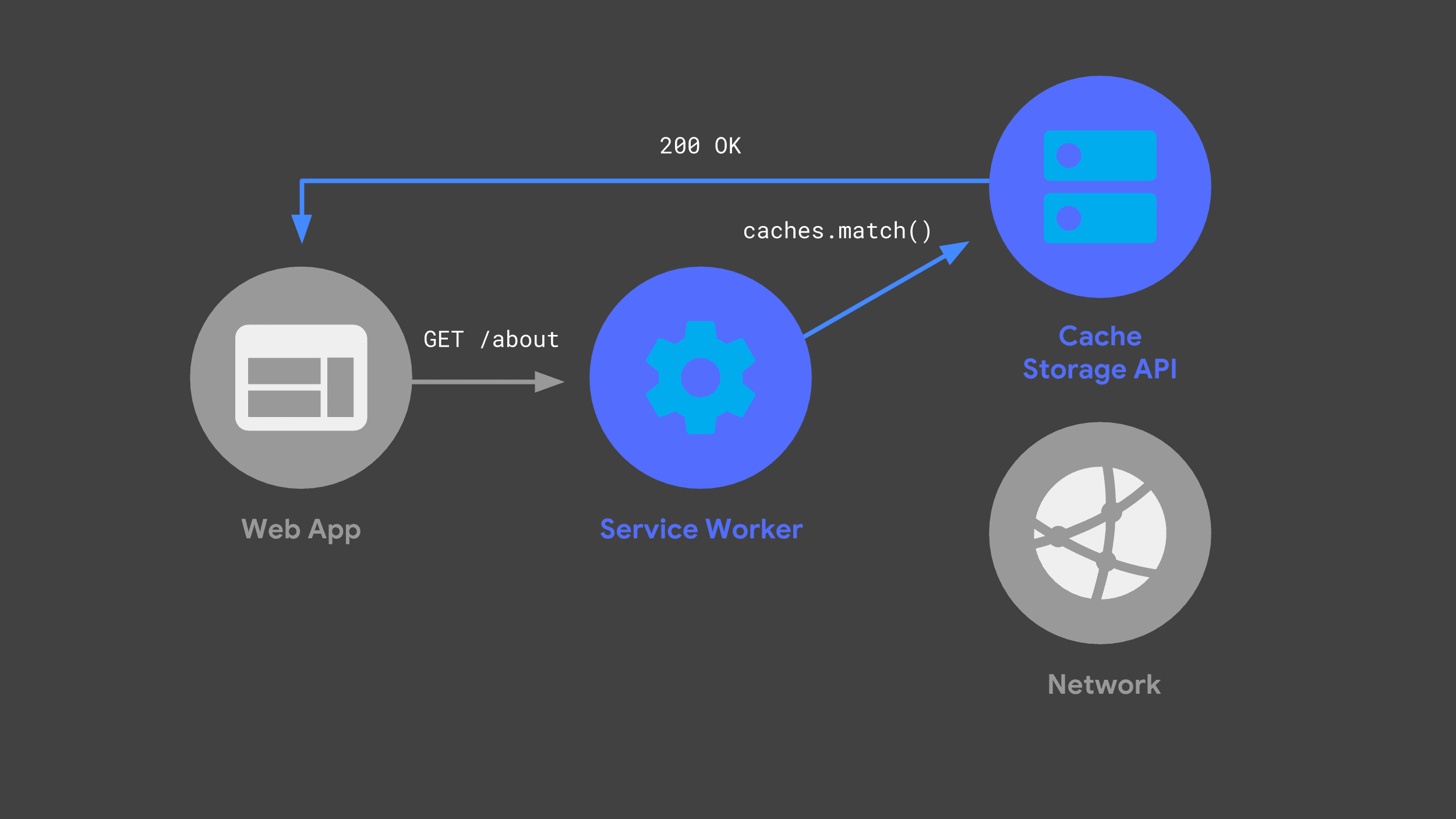
盡可能避免使用網路,是提供可靠快速效能的關鍵。
「同構」JavaScript
最後一個要介紹的概念是「同構」或「通用」JavaScript。簡單來說,這項概念是指相同的 JavaScript 程式碼可以在不同的執行階段環境之間共用。建構 PWA 時,我想要在後端伺服器和 Service Worker 之間共用 JavaScript 程式碼。
以這種方式分享程式碼有很多有效方法,但我的方法是使用 ES 模組做為明確的原始碼。接著,我使用 Babel 和 Rollup 的組合,轉譯並組合伺服器和 Service Worker 的模組。在我的專案中,副檔名為 .mjs 的檔案是 ES 模組中的程式碼。
伺服器
請記住這些概念和術語,接下來我們將深入瞭解我如何建構 Stack Overflow PWA。首先,我會介紹後端伺服器,並說明後端伺服器在整體架構中的作用。
我想要結合動態後端和靜態代管,因此選擇使用 Firebase 平台。
Firebase Cloud Functions 會在收到要求時自動啟動 Node 環境,並與我已熟悉的熱門 Express HTTP 架構整合。此外,它還提供開箱即用的代管服務,可代管我網站的所有靜態資源。讓我們看看伺服器如何處理要求。
瀏覽器對伺服器發出導覽要求時,會經過下列流程:
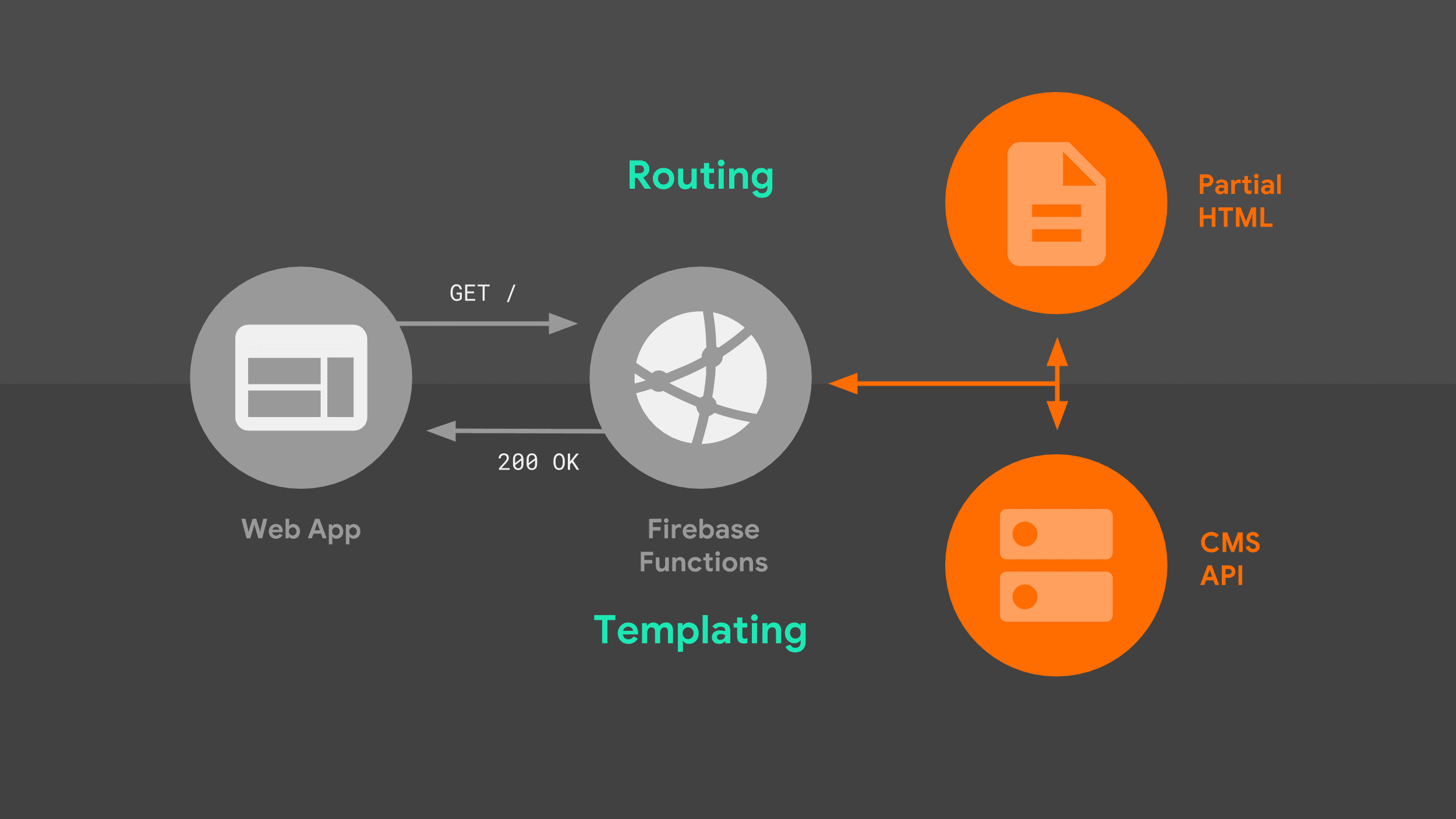
伺服器會根據網址轉送要求,並使用範本邏輯建立完整的 HTML 文件。我會使用 Stack Exchange API 的資料,以及伺服器在本機儲存的部分 HTML 片段。服務工作站知道如何回應後,即可開始將 HTML 串流傳回網頁應用程式。
這張圖片有兩個部分值得深入探討:路徑和範本。
轉送
就路徑而言,我採用的是 Express 架構的原生路徑語法。這項功能十分彈性,不僅能比對簡單的網址前置字元,也能比對路徑中包含參數的網址。在這裡,我建立對應,在路徑名稱與要比對的基礎 Express 模式之間建立對應。
const routes = new Map([
['about', '/about'],
['questions', '/questions/:questionId'],
['index', '/'],
]);
export default routes;
然後我可以直接從伺服器的程式碼參照這個對應。 如果與特定 Express 模式相符,適當的處理常式會以符合路徑的專屬範本邏輯回應。
import routes from './lib/routes.mjs';
app.get(routes.get('index'), async (req, res) => {
// Templating logic.
});
伺服器端範本
範本邏輯會是什麼樣子?我採用了這種方法,將部分 HTML 片段依序拼湊在一起。這個模型很適合用於串流。
伺服器會立即傳回一些初始 HTML 樣板,瀏覽器可以立即轉譯該部分網頁。伺服器會將其餘資料來源拼湊在一起,然後串流至瀏覽器,直到文件完成為止。
如要瞭解我的意思,請查看其中一個路徑的 Express 程式碼:
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
使用 response 物件的 write() 方法,並參照本機儲存的部分範本,我能夠立即啟動回應串流,而不必封鎖任何外部資料來源。瀏覽器會採用這個初始 HTML,立即算繪有意義的介面和載入訊息。
網頁的下一部分會使用 Stack Exchange API 的資料。如要取得這項資料,我們的伺服器必須發出網路要求。在收到並處理回應前,網頁應用程式無法轉譯任何其他內容,但至少使用者在等待時不會看到空白畫面。
網頁應用程式收到 Stack Exchange API 的回應後,會呼叫自訂範本函式,將 API 中的資料轉換為對應的 HTML。
範本語言
範本化可能是一個出乎意料有爭議的主題,而我選擇的只是眾多方法之一。建議您改用自己的解決方案,尤其是與現有範本架構有舊版連結時。
就我的用途而言,只依賴 JavaScript 的範本常值,並將部分邏輯分成輔助函式,是比較合理的做法。建構 MPA 的好處之一,就是不必追蹤狀態更新和重新轉譯 HTML,因此產生靜態 HTML 的基本方法對我來說很實用。
以下範例說明如何為網頁應用程式索引的動態 HTML 部分建立範本。與我的路徑一樣,範本邏輯儲存在 ES 模組中,可匯入伺服器和 Service Worker。
export function index(tag, items) {
const title = `<h3>Top "${escape(tag)}" Questions</h3>`;
const form = `<form method="GET">...</form>`;
const questionCards = items
.map(item =>
questionCard({
id: item.question_id,
title: item.title,
})
)
.join('');
const questions = `<div id="questions">${questionCards}</div>`;
return title + form + questions;
}
這些範本函式是純 JavaScript,適時將邏輯分解為較小的輔助函式,有助於提升效率。在這裡,我會將 API 回應中傳回的每個項目傳遞至其中一個函式,該函式會建立標準 HTML 元素,並設定所有適當的屬性。
function questionCard({id, title}) {
return `<a class="card"
href="/questions/${id}"
data-cache-url="${questionUrl(id)}">${title}</a>`;
}
特別值得注意的是我新增至每個連結的資料屬性 data-cache-url,並設為顯示對應問題所需的 Stack Exchange API 網址。請留意這一點。我稍後再回來查看。
跳回我的路徑處理常式,範本完成後,我會將網頁 HTML 的最後一部分串流至瀏覽器,並結束串流。這是瀏覽器的提示,表示漸進式算繪已完成。
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
以上就是伺服器設定的簡短導覽。初次造訪我網頁應用程式的使用者一律會收到伺服器的回應,但訪客返回網頁應用程式時,服務工作人員就會開始回應。讓我們深入瞭解。
Service Worker
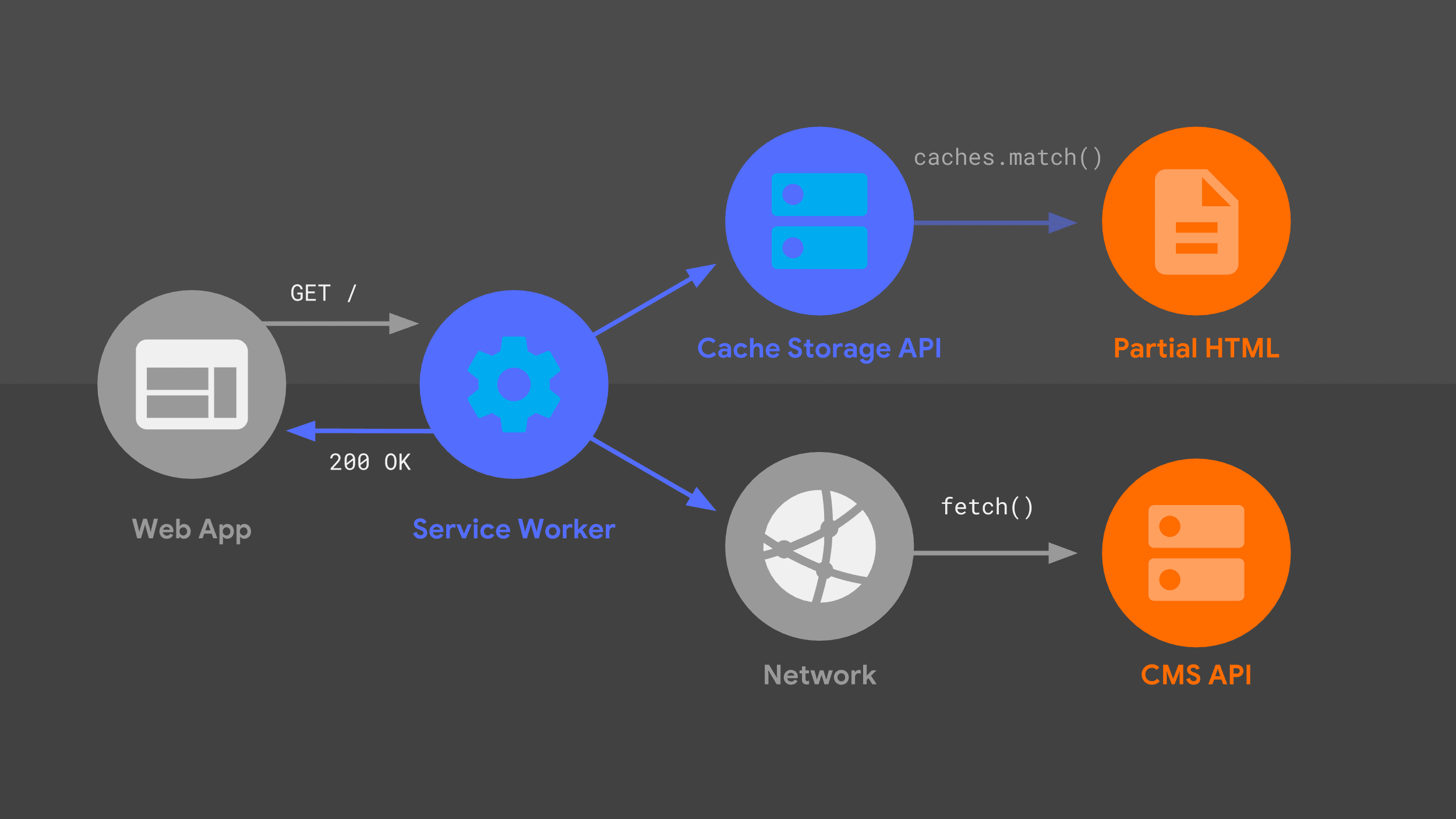
這個圖表應該很眼熟,因為我先前介紹的許多相同部分,都以稍微不同的排列方式出現在這裡。我們來逐步瞭解要求流程,並將 Service Worker 納入考量。
我們的 Service Worker 會處理特定網址的傳入導覽要求,並像伺服器一樣,使用路由和範本邏輯的組合,判斷如何回應。
做法與先前相同,但使用不同的低階基本類型,例如 fetch() 和 Cache Storage API。我會使用這些資料來源建構 HTML 回應,然後服務工作人員會將該回應傳回給網頁應用程式。
Workbox
我不會從低階基本型別從頭開始,而是要以一組稱為 Workbox 的高階程式庫為基礎,建構服務工作站。為任何 Service Worker 的快取、路徑和回應產生邏輯提供穩固的基礎。
轉送
就像伺服器端程式碼一樣,服務工作人員也需要知道如何將傳入要求與適當的回應邏輯相符。
我的做法是將每個 Express 路由轉換為對應的規則運算式,並使用名為 regexparam 的實用程式庫。完成翻譯後,我就可以利用 Workbox 內建的規則運算式轉送支援功能。
匯入含有規則運算式的模組後,我會向 Workbox 的路由器註冊每個規則運算式。在每個路徑中,我都能提供自訂範本邏輯來生成回覆。服務工作人員中的範本比後端伺服器中的範本複雜一些,但 Workbox 可協助處理許多繁重的工作。
import regExpRoutes from './regexp-routes.mjs';
workbox.routing.registerRoute(
regExpRoutes.get('index')
// Templating logic.
);
靜態資產快取
範本故事的其中一個重要部分,是確保我的部分 HTML 範本可透過 Cache Storage API 在本機使用,並在我將變更部署至網頁應用程式時保持最新狀態。手動維護快取容易出錯,因此我使用 Workbox 處理預先快取,做為建構程序的一部分。
我使用設定檔告知 Workbox 要預先快取哪些網址,並指向包含所有本機資產的目錄,以及要比對的一組模式。Workbox 的 CLI 會自動讀取這個檔案,每次重建網站時都會執行。
module.exports = {
globDirectory: 'build',
globPatterns: ['**/*.{html,js,svg}'],
// Other options...
};
Workbox 會為每個檔案的內容建立快照,並自動將該網址和修訂版本清單插入最終的 Service Worker 檔案。Workbox 現在已具備所有必要條件,可確保預先快取的檔案隨時可用,並保持在最新狀態。結果是 service-worker.js 檔案,其中包含類似下列內容:
workbox.precaching.precacheAndRoute([
{
url: 'partials/about.html',
revision: '518747aad9d7e',
},
{
url: 'partials/foot.html',
revision: '69bf746a9ecc6',
},
// etc.
]);
對於使用較複雜建構程序的開發人員,除了 指令列介面,Workbox 也提供 webpack 外掛程式和一般節點模組。
串流
接著,我希望 Service Worker 立即將預先快取的局部 HTML 串流傳回網頁應用程式。這是「可靠快速」的關鍵環節,因為我總是能立即在畫面上看到有意義的內容。幸好,在服務工作人員中使用 Streams API 即可達成這個目標。
您可能聽過 Streams API。我的同事 Jake Archibald 多年來一直對這項技術讚不絕口。他大膽預測 2016 年將是網路串流的時代。Streams API 如今依然出色,但與兩年前相比,有著至關重要的差異。
當時只有 Chrome 支援 Streams,但現在 Streams API 的支援範圍更廣。整體而言,這項技術的發展前景十分樂觀,只要有適當的回退程式碼,您就能在 Service Worker 中使用串流。
不過,您可能還有一件事需要瞭解,那就是如何實際運用 Streams API。這項工具提供一組非常強大的基本類型,熟悉這項工具的開發人員可以建立複雜的資料流程,例如:
const stream = new ReadableStream({
pull(controller) {
return sources[0]
.then(r => r.read())
.then(result => {
if (result.done) {
sources.shift();
if (sources.length === 0) return controller.close();
return this.pull(controller);
} else {
controller.enqueue(result.value);
}
});
},
});
但瞭解這段程式碼的完整含義可能不適合所有人。我們不會剖析這項邏輯,而是要討論我處理 Service Worker 串流的方式。
我使用的是全新的高階包裝函式,
workbox-streams。
我可以透過這個物件,在串流來源中傳遞資料,包括來自快取和網路的執行階段資料。Workbox 會負責協調各個來源,並將其縫合為單一串流回應。
此外,Workbox 會自動偵測是否支援 Streams API,如果不支援,就會建立對等的非串流回應。也就是說,隨著串流技術越來越普及,您不必擔心編寫備援程式碼。
執行階段快取
讓我們看看我的服務工作人員如何處理 Stack Exchange API 的執行階段資料。我利用 Workbox 內建的過時重新驗證快取策略,以及到期時間,確保網頁應用程式的儲存空間不會無限擴充。
我在 Workbox 中設定了兩種策略,用來處理構成串流回應的不同來源。只要呼叫幾個函式並進行設定,Workbox 就能完成原本需要手寫數百行程式碼的工作。
const cacheStrategy = workbox.strategies.cacheFirst({
cacheName: workbox.core.cacheNames.precache,
});
const apiStrategy = workbox.strategies.staleWhileRevalidate({
cacheName: API_CACHE_NAME,
plugins: [new workbox.expiration.Plugin({maxEntries: 50})],
});
第一種策略會讀取預先快取的資料,例如部分 HTML 範本。
另一項策略則會實作 stale-while-revalidate 快取邏輯,並在達到 50 個項目後,一併實作最近最少使用的快取到期時間。
現在我已制定這些策略,接下來只要告訴 Workbox 如何使用這些策略建構完整的串流回應即可。我傳遞來源陣列做為函式,且每個函式都會立即執行。Workbox 會依序從每個來源取得結果,並將結果串流至網頁應用程式,只有在陣列中的下一個函式尚未完成時才會延遲。
workbox.streams.strategy([
() => cacheStrategy.makeRequest({request: '/head.html'}),
() => cacheStrategy.makeRequest({request: '/navbar.html'}),
async ({event, url}) => {
const tag = url.searchParams.get('tag') || DEFAULT_TAG;
const listResponse = await apiStrategy.makeRequest(...);
const data = await listResponse.json();
return templates.index(tag, data.items);
},
() => cacheStrategy.makeRequest({request: '/foot.html'}),
]);
前兩個來源是預先快取的局部範本,可直接從 Cache Storage API 讀取,因此一律會立即提供。這可確保服務工作人員導入作業能快速回應要求,就像伺服器端程式碼一樣。
下一個來源函式會從 Stack Exchange API 擷取資料,並將回應處理成網頁應用程式預期的 HTML。
「過時後重新驗證」策略是指,如果我先前已快取這個 API 呼叫的回應,就能立即將其串流至網頁,同時「在背景」更新快取項目,以供下次要求時使用。
最後,我會串流頁尾的快取副本,並關閉最終的 HTML 標記,完成回應。
分享代碼可確保資料同步
你會發現服務工作人員程式碼的某些部分看起來很熟悉。我的服務工作人員使用的部分 HTML 和範本邏輯,與伺服器端處理常式使用的內容相同。這樣一來,無論使用者是首次造訪網頁應用程式,還是返回由 Service Worker 算繪的網頁,都能獲得一致的體驗。這就是同構 JavaScript 的優點。
動態漸進式強化
我已逐步說明 PWA 的伺服器和 Service Worker,但還有最後一小段邏輯要介紹:少量 JavaScript 會在每個網頁完全串流後執行。
這段程式碼可逐步提升使用者體驗,但並非必要,即使未執行,網路應用程式仍可正常運作。
網頁中繼資料
我的應用程式使用用戶端 JavaScript,根據 API 回應更新網頁的中繼資料。由於我為每個網頁使用相同的初始快取 HTML 位元,網頁應用程式最終會在文件標題中加入通用標記。但透過範本和用戶端程式碼之間的協調,我可以使用網頁專屬中繼資料更新視窗標題。
在範本程式碼中,我的做法是加入含有正確逸出字串的指令碼標記。
const metadataScript = `<script>
self._title = '${escape(item.title)}';
</script>`;
然後,在我的頁面載入後,我會讀取該字串並更新文件標題。
if (self._title) {
document.title = unescape(self._title);
}
如果想在自己的網頁應用程式中更新其他網頁專屬中繼資料,也可以採用相同做法。
離線使用者體驗
我新增的另一項漸進式強化功能,是用來強調我們的離線功能。我已建構可靠的 PWA,希望使用者知道離線時仍可載入先前造訪的網頁。
首先,我使用 Cache Storage API 取得先前快取的所有 API 要求清單,並將其轉換為網址清單。
還記得我提到的特殊資料屬性嗎?每個屬性都包含顯示問題所需的 API 要求網址。我可以交叉參照這些資料屬性和快取網址清單,並建立所有不相符問題連結的陣列。
當瀏覽器進入離線狀態時,我會逐一檢查未快取連結的清單,並將無法運作的連結調暗。請注意,這只是向使用者提供視覺提示,說明這些網頁的預期內容,我並未實際停用連結或禁止使用者瀏覽。
const apiCache = await caches.open(API_CACHE_NAME);
const cachedRequests = await apiCache.keys();
const cachedUrls = cachedRequests.map(request => request.url);
const cards = document.querySelectorAll('.card');
const uncachedCards = [...cards].filter(card => {
return !cachedUrls.includes(card.dataset.cacheUrl);
});
const offlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '0.3';
}
};
const onlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '1.0';
}
};
window.addEventListener('online', onlineHandler);
window.addEventListener('offline', offlineHandler);
常見陷阱
我已完成多頁 PWA 建構方法的導覽。 在制定自己的方法時,您必須考量許多因素,最終可能做出與我不同的選擇。這種彈性是建構網頁應用程式的優點之一。
在自行做出架構決策時,您可能會遇到一些常見的陷阱,因此我想幫您避開這些問題。
請勿快取完整 HTML
建議您不要在快取中儲存完整的 HTML 文件。首先,這會浪費空間。如果網頁應用程式的每個網頁都使用相同的基本 HTML 結構,您最終會重複儲存相同的標記。
更重要的是,如果您將變更部署至網站的共用 HTML 結構,先前快取的每個網頁仍會停留在舊版版面配置。試想一下,回訪者看到新舊網頁混雜的內容,會有多麼沮喪。
伺服器 / 服務工作人員漂移
另一個要避免的陷阱是伺服器和服務工作人員不同步。我的做法是使用同構 JavaScript,這樣就能在兩處執行相同的程式碼。視現有伺服器架構而定,這項操作不一定可行。
無論您做出什麼架構決策,都應該制定策略,在伺服器和 Service Worker 中執行對等的路由和範本程式碼。
最糟情況
版面配置 / 設計不一致
如果忽略這些陷阱,會發生什麼事?當然,各種失敗都有可能,但最糟的情況是回訪者造訪的快取網頁版面配置非常過時,可能標題文字過時,或使用無效的 CSS 類別名稱。
最糟情況:路由中斷
或者,使用者可能會遇到由伺服器處理的網址,但並非由服務工作人員處理。如果網站充斥著殭屍版面配置和死胡同,就不是可靠的 PWA。
成功秘訣
但你並非孤軍奮戰!以下提示有助於避免這些陷阱:
使用已實作多種語言的範本和轉送程式庫
請嘗試使用具有 JavaScript 實作項目的範本和轉送程式庫。我知道並非所有開發人員都有時間和資源,可以從目前的網路伺服器和範本語言遷移。
不過,許多熱門的範本和路由架構都提供多種語言的實作方式。如果找到支援 JavaScript 和目前伺服器語言的函式庫,就能進一步讓服務工作人員和伺服器保持同步。
建議使用循序範本,而非巢狀範本
接著,建議使用一系列可依序串流的範本。只要能盡快串流 HTML 的初始部分,網頁後續部分使用更複雜的範本邏輯也沒關係。
在 Service Worker 中快取靜態和動態內容
為獲得最佳效能,您應預先快取網站的所有重要靜態資源。您也應設定執行階段快取邏輯,處理動態內容 (例如 API 要求)。使用 Workbox 代表您可以根據經過充分測試、適用於正式環境的策略進行建構,而不必從頭開始實作所有內容。
如非絕對必要,請勿封鎖網路
此外,只有在無法從快取串流回應時,才應封鎖網路。與等待新資料相比,立即顯示快取 API 回應通常能帶來更優質的使用者體驗。