

我们来聊聊…架构?
接下来,我将介绍一个重要但可能被误解的主题:您为 Web 应用使用的架构,特别是当您构建渐进式 Web 应用时,您的架构决策会如何发挥作用。
“架构”一词可能听起来很模糊,您可能无法立即明白这有何重要意义。一种思考架构的方式是问自己以下问题:当用户访问我网站上的某个网页时,会加载哪些 HTML?然后,当用户访问其他网页时,会加载什么内容?
这些问题的答案并不总是那么简单明了,一旦您开始考虑渐进式 Web 应用,情况可能会变得更加复杂。因此,我的目标是向您介绍一种我发现有效的可能架构。在本文中,我将我做出的决策标记为“我的方法”,以表明这是我构建渐进式 Web 应用的方式。
您可以在构建自己的 PWA 时随意使用我的方法,但同时,也始终存在其他有效的替代方案。我希望,了解所有部分如何组合在一起能激发您的灵感,让您有能力根据自己的需求自定义此功能。
Stack Overflow PWA
为了配合本文,我构建了一个 Stack Overflow PWA。我花了很多时间阅读 Stack Overflow 上的内容并为其贡献内容,因此我想构建一个 Web 应用,让用户可以轻松浏览特定主题的常见问题解答。它基于公共 Stack Exchange API 构建。它是开源的,您可以访问 GitHub 项目了解详情。
多页面应用 (MPA)
在深入探讨具体细节之前,我们先定义一些术语并说明一些底层技术。首先,我将介绍我所说的“多页面应用”(MPA)。
MPA 是自 Web 诞生以来一直使用的传统架构的别称。每次用户前往新网址时,浏览器都会逐步呈现该网页特有的 HTML。系统不会尝试在导航之间保留网页的状态或内容。每次访问新网页时,您都会重新开始。
这与用于构建 Web 应用的单页应用 (SPA) 模型形成对比,在 SPA 模型中,当用户访问新部分时,浏览器会运行 JavaScript 代码来更新现有页面。SPA 和 MPA 都是同样有效的模型,但在这篇博文中,我想在多页应用的背景下探索 PWA 概念。
可靠快速
您可能听过我(以及无数其他人)使用“渐进式 Web 应用”(PWA) 这个词组。您可能已经熟悉本网站其他位置上的一些背景资料。
您可以将 PWA 视为可提供出色用户体验且真正值得在用户主屏幕上占据一席之地的 Web 应用。“FIRE”一词代表 Fast(快速)、Integrated(集成)、Reliable(可靠)和 Engaging(吸引人),总结了构建 PWA 时需要考虑的所有属性。
在本文中,我将重点介绍这些属性中的一部分:快速和可靠。
快速:虽然“快速”在不同的语境中意味着不同的含义,但我将介绍尽可能少地从网络加载内容所带来的速度优势。
可靠:但仅靠原始速度还不够。为了让 Web 应用看起来像 PWA,它应该可靠。它需要足够灵活,即使网络状态不佳,也能始终加载某些内容,哪怕只是自定义的错误页面。
可靠的快速:最后,我要稍微改写一下 PWA 的定义,并探讨构建可靠快速的应用意味着什么。仅在低延迟网络上快速可靠是不够的。可靠的快速是指无论底层网络状况如何,Web 应用的速度都保持一致。
启用技术:Service Worker + Cache Storage API
PWA 对速度和恢复能力提出了很高的要求。幸运的是,Web 平台提供了一些构建块,可实现这种性能。 我指的是 service worker 和 Cache Storage API。
您可以构建一个服务工作线程,该线程会侦听传入的请求,将部分请求传递到网络,并通过 Cache Storage API 存储响应的副本以供日后使用。
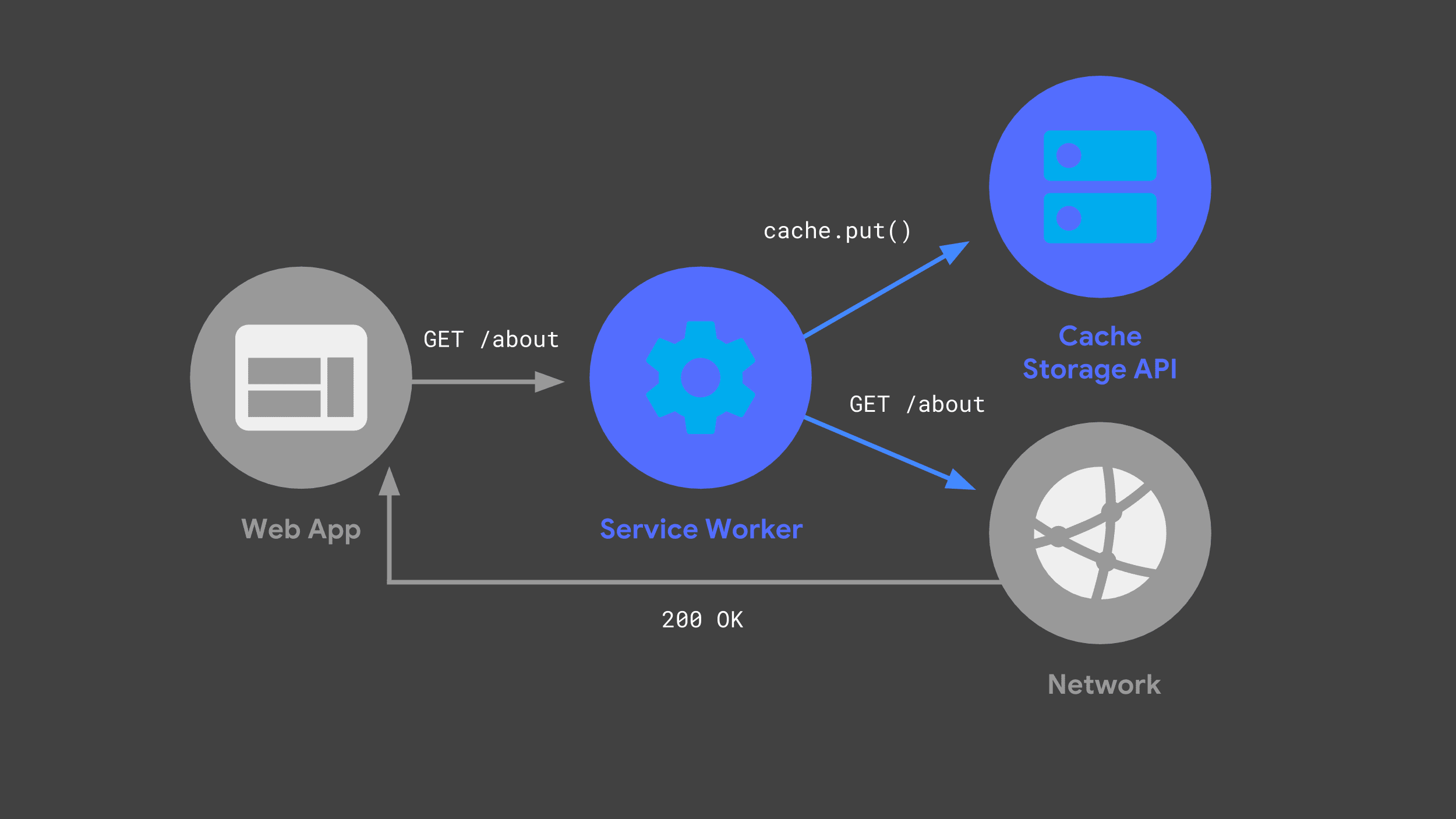
下次 Web 应用发出相同请求时,其 Service Worker 可以检查其缓存,并直接返回之前缓存的响应。
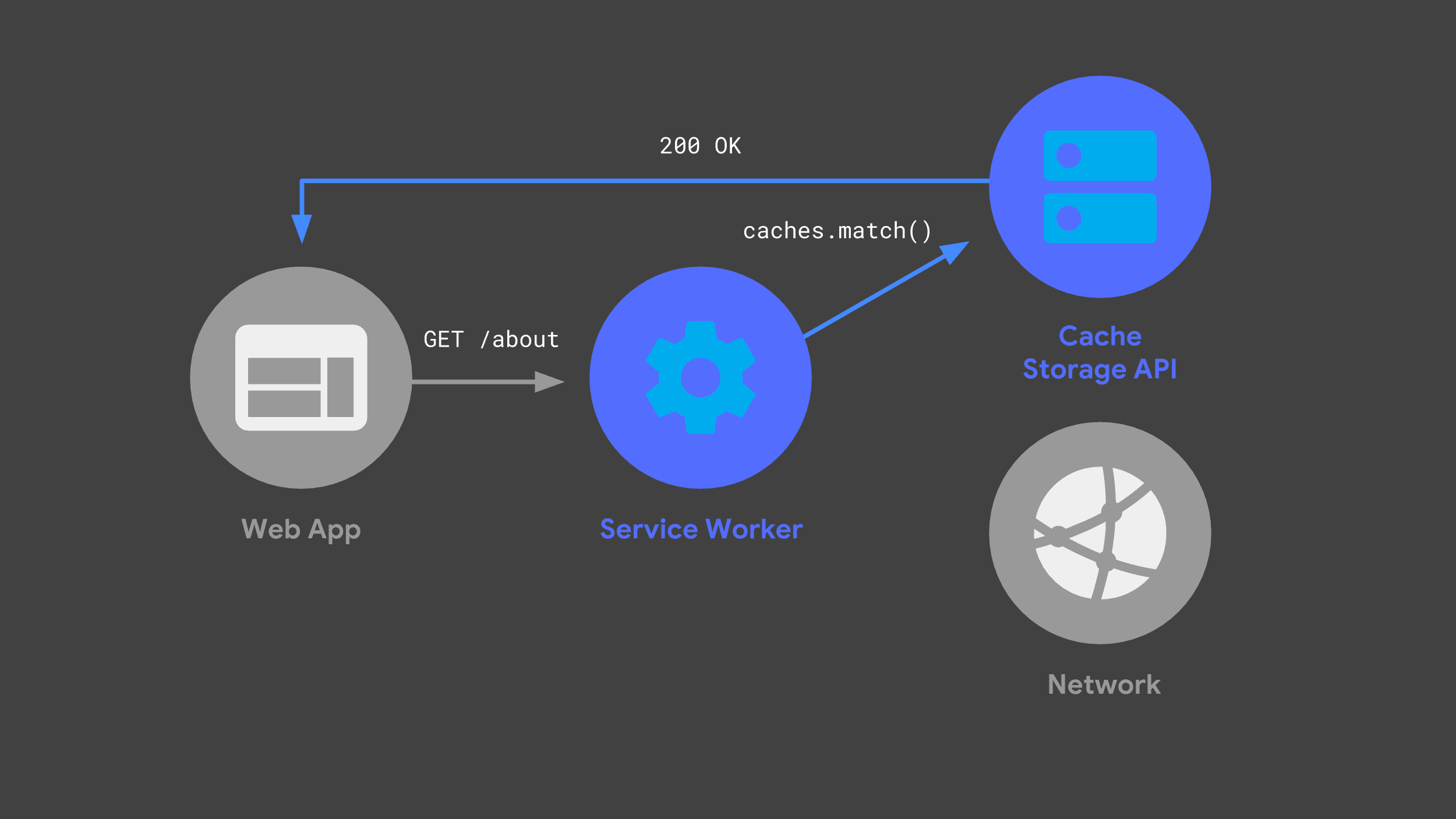
尽可能避免使用网络是提供可靠快速性能的关键。
“同构”JavaScript
我想介绍的另一个概念是有时称为“同构”或“通用”JavaScript。简而言之,它是一种理念,即相同的 JavaScript 代码可以在不同的运行时环境之间共享。在构建 PWA 时,我希望在后端服务器和服务工作线程之间共享 JavaScript 代码。
有很多有效的方法可以这样分享代码,但我的方法是使用 ES 模块作为最终的源代码。然后,我使用 Babel 和 Rollup 的组合对这些模块进行了转译和打包,以用于服务器和服务工作器。在我的项目中,扩展名为 .mjs 的文件是位于 ES 模块中的代码。
服务器
在了解了这些概念和术语后,我们来深入探讨一下我实际构建 Stack Overflow PWA 的过程。我将首先介绍我们的后端服务器,并说明它如何融入整体架构。
我一直在寻找动态后端与静态托管的组合,而我的方法是使用 Firebase 平台。
Firebase Cloud Functions 会在有传入请求时自动启动基于 Node 的环境,并与我已熟悉的常用 Express HTTP 框架集成。它还为我网站的所有静态资源提供开箱即用的托管服务。我们来看看服务器如何处理请求。
当浏览器针对我们的服务器发出导航请求时,会经历以下流程:
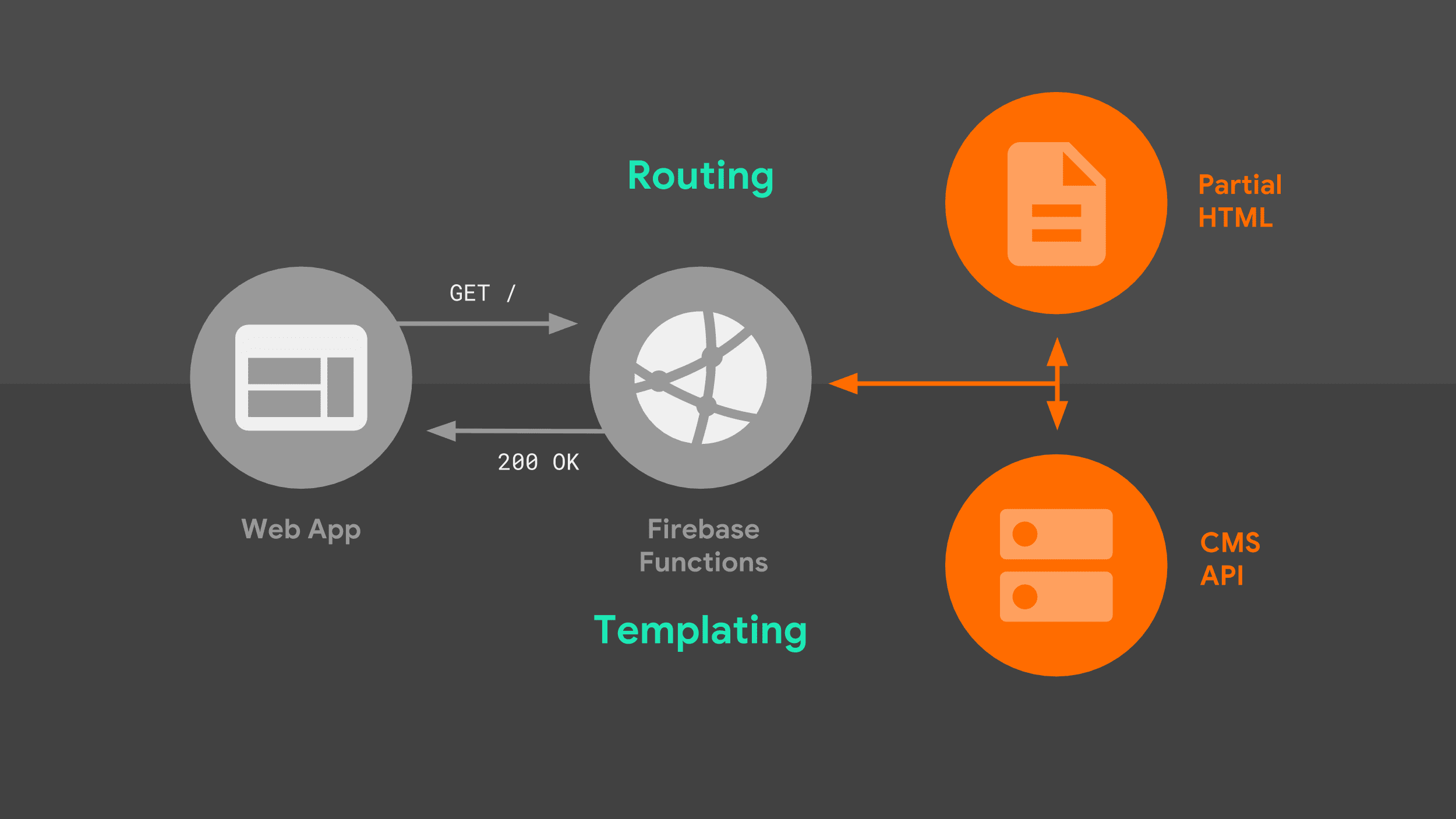
服务器根据网址路由请求,并使用模板化逻辑创建完整的 HTML 文档。我同时使用了 Stack Exchange API 中的数据以及服务器在本地存储的部分 HTML 片段。一旦我们的服务工作线程知道如何响应,它就可以开始将 HTML 流式传输回我们的 Web 应用。
此图中有两个值得更详细探讨的部分:路由和模板。
路由
在路由方面,我的方法是使用 Express 框架的原生路由语法。它非常灵活,不仅可以匹配简单的网址前缀,还可以匹配将参数作为路径一部分的网址。在此示例中,我创建了路由名称与要匹配的底层 Express 模式之间的映射。
const routes = new Map([
['about', '/about'],
['questions', '/questions/:questionId'],
['index', '/'],
]);
export default routes;
然后,我可以从服务器的代码中直接引用此映射。 如果给定的 Express 模式存在匹配项,相应的处理程序会使用特定于匹配路由的模板化逻辑进行响应。
import routes from './lib/routes.mjs';
app.get(routes.get('index'), async (req, res) => {
// Templating logic.
});
服务器端模板
那么,该模板逻辑是什么样的呢?我采用的方法是按顺序将部分 HTML 片段拼接在一起。此模型非常适合流式传输。
服务器会立即发回一些初始 HTML 样板,浏览器能够立即渲染该部分网页。当服务器将剩余的数据源拼凑在一起时,它会将这些数据源流式传输到浏览器,直到文档完成为止。
如需了解我的意思,请查看我们其中一个路由的 Express 代码:
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
通过使用 response 对象的 write() 方法并引用本地存储的部分模板,我可以立即开始响应流,而不会阻塞任何外部数据源。浏览器会获取此初始 HTML,并立即呈现有意义的界面和加载消息。
我们网页的下一部分使用了 Stack Exchange API 中的数据。获取这些数据意味着我们的服务器需要发出网络请求。在收到响应并处理之前,Web 应用无法呈现任何其他内容,但至少用户在等待时不会盯着空白屏幕。
Web 应用从 Stack Exchange API 收到响应后,会调用自定义模板函数,将 API 中的数据转换为相应的 HTML。
模板语言
模板化可能是一个出人意料的有争议的话题,而我所采用的只是众多方法中的一种。您可能需要替换自己的解决方案,尤其是在您与现有模板框架存在旧版关联的情况下。
对于我的使用情形,最合理的做法是仅依赖 JavaScript 的模板字面量,并将一些逻辑分解为辅助函数。构建 MPA 的一个好处是,您不必跟踪状态更新并重新呈现 HTML,因此生成静态 HTML 的基本方法对我来说非常有效。
下面是一个示例,展示了如何为 Web 应用索引的动态 HTML 部分创建模板。与我的路由一样,模板化逻辑存储在 ES 模块中,可以导入到服务器和服务工作器中。
export function index(tag, items) {
const title = `<h3>Top "${escape(tag)}" Questions</h3>`;
const form = `<form method="GET">...</form>`;
const questionCards = items
.map(item =>
questionCard({
id: item.question_id,
title: item.title,
})
)
.join('');
const questions = `<div id="questions">${questionCards}</div>`;
return title + form + questions;
}
这些模板函数是纯 JavaScript,在适当的时候将逻辑分解为更小的辅助函数非常有用。在这里,我将 API 响应中返回的每个商品传递给这样一个函数,该函数会创建一个设置了所有相应属性的标准 HTML 元素。
function questionCard({id, title}) {
return `<a class="card"
href="/questions/${id}"
data-cache-url="${questionUrl(id)}">${title}</a>`;
}
特别值得注意的是,我为每个链接添加了一个数据属性 data-cache-url,并将其设置为我需要用来显示相应问题的 Stack Exchange API 网址。请谨记这一点。稍后我会重新查看。
回到我的路由处理程序,完成模板化后,我会将网页 HTML 的最后一部分流式传输到浏览器,然后结束流。这是向浏览器发出的信号,表示渐进式渲染已完成。
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
以上就是我的服务器设置的简要介绍。首次访问我的 Web 应用的用户始终会收到服务器的响应,但当访问者返回我的 Web 应用时,我的服务工作线程将开始响应。让我们深入了解一下。
Service Worker
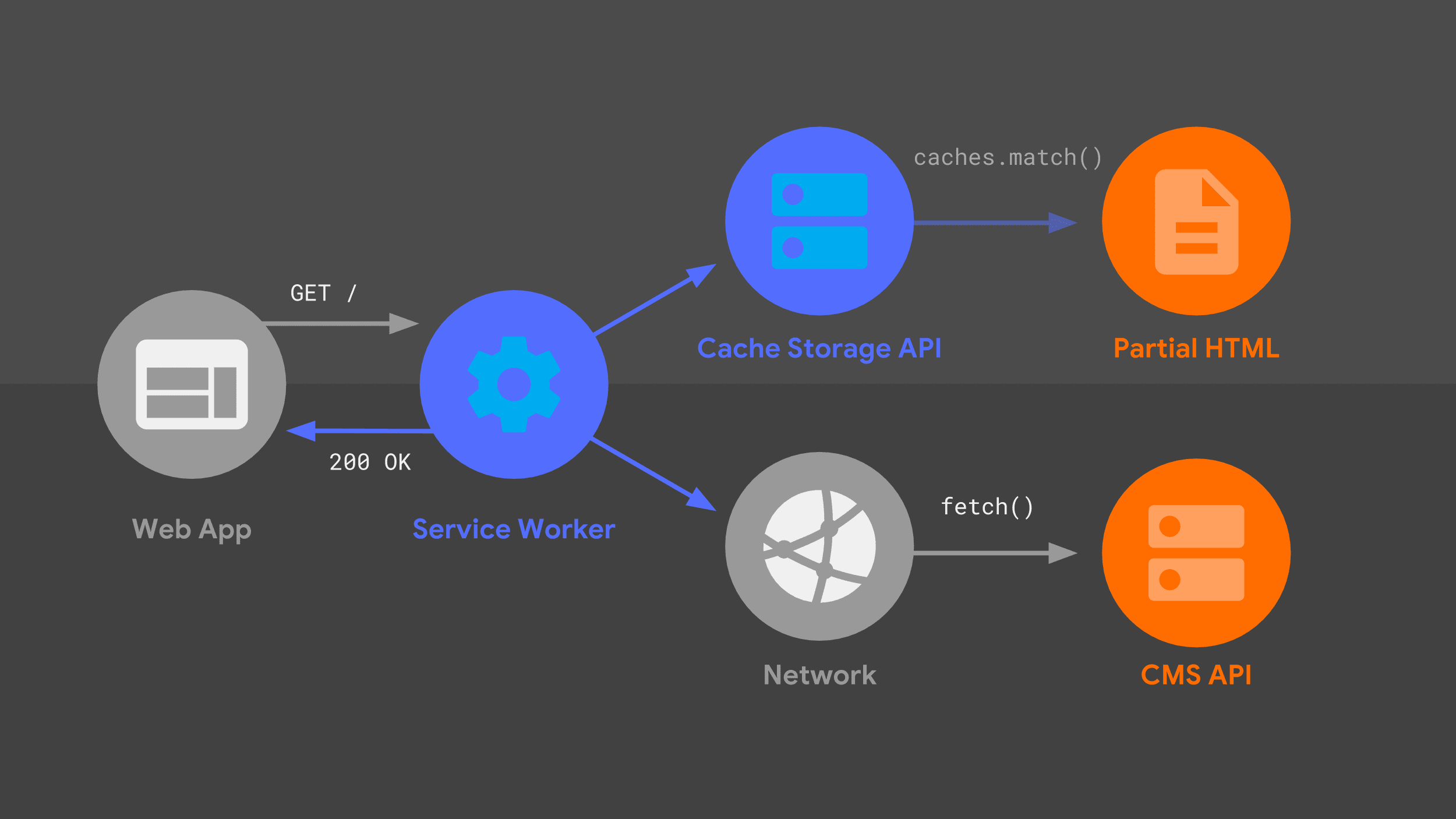
此图表看起来应该很熟悉,因为我之前介绍的许多相同部分都以略有不同的排列方式显示在此处。我们来了解一下请求流程,并考虑服务工作线程。
我们的 Service Worker 会处理针对给定网址的传入导航请求,并且与我的服务器一样,它会使用路由和模板化逻辑的组合来确定如何响应。
该方法与之前的方法相同,但使用了不同的底层原语,例如 fetch() 和 Cache Storage API。我使用这些数据源来构建 HTML 响应,然后服务工作线程会将该响应传递回 Web 应用。
Workbox
我不会从低级原语开始从头构建,而是会基于一组名为 Workbox 的高级库来构建我的服务工作线程。它为任何服务工作线程的缓存、路由和响应生成逻辑提供了坚实的基础。
路由
与服务器端代码一样,我的服务工作线程需要知道如何将传入的请求与相应的响应逻辑相匹配。
我的方法是将每个 Express 路由转换为相应的正则表达式,并使用一个名为 regexparam 的实用库。完成该转换后,我便可以利用 Workbox 对正则表达式路由的内置支持。
导入包含正则表达式的模块后,我将每个正则表达式注册到 Workbox 的路由器。在每个路由中,我都可以提供自定义模板逻辑来生成响应。Service Worker 中的模板化比后端服务器中的模板化要复杂一些,但 Workbox 可以帮助我们完成许多繁重的工作。
import regExpRoutes from './regexp-routes.mjs';
workbox.routing.registerRoute(
regExpRoutes.get('index')
// Templating logic.
);
静态资源缓存
模板化方面的一个关键部分是确保我的部分 HTML 模板可通过 Cache Storage API 在本地使用,并在我将更改部署到 Web 应用时保持最新状态。手动进行缓存维护很容易出错,因此我求助于 Workbox 来处理构建过程中的预缓存。
我使用配置文件告知 Workbox 要预缓存哪些网址,该文件指向包含所有本地资源的目录以及一组要匹配的模式。此文件由 Workbox 的 CLI 自动读取,每次我重建网站时,该 CLI 都会运行。
module.exports = {
globDirectory: 'build',
globPatterns: ['**/*.{html,js,svg}'],
// Other options...
};
Workbox 会拍摄每个文件内容的快照,并自动将该网址和修订版本列表注入到我的最终服务工作线程文件中。现在,Workbox 拥有了让预缓存文件始终可用并保持最新状态所需的一切。结果是一个 service-worker.js 文件,其中包含类似以下内容:
workbox.precaching.precacheAndRoute([
{
url: 'partials/about.html',
revision: '518747aad9d7e',
},
{
url: 'partials/foot.html',
revision: '69bf746a9ecc6',
},
// etc.
]);
对于使用更复杂的构建流程的用户,除了 命令行界面之外,Workbox 还提供 webpack 插件和通用 Node 模块。
流式
接下来,我希望服务工作线程立即将预缓存的部分 HTML 流式传输回 Web 应用。这是“可靠快速”的关键部分 - 我总能立即在屏幕上看到有意义的内容。 幸运的是,在我们的服务工作线程中使用 Streams API 可以实现这一点。
您之前可能听说过 Streams API。我的同事 Jake Archibald 多年来一直对它赞不绝口。他大胆预测,2016 年将是网络直播之年。Streams API 如今依然像两年前一样出色,但有一个关键区别。
虽然当时只有 Chrome 支持 Streams,但现在 Streams API 得到了更广泛的支持。总而言之,情况是积极的,而且只要有适当的回退代码,您就可以立即在服务工作线程中使用流。
不过,您可能还面临一个障碍,那就是难以理解 Streams API 的实际运作方式。它提供了一组非常强大的基元,熟悉使用这些基元的开发者可以创建复杂的数据流,例如:
const stream = new ReadableStream({
pull(controller) {
return sources[0]
.then(r => r.read())
.then(result => {
if (result.done) {
sources.shift();
if (sources.length === 0) return controller.close();
return this.pull(controller);
} else {
controller.enqueue(result.value);
}
});
},
});
但并非所有人都能完全理解此代码的含义。我们先不解析此逻辑,而是来谈谈我处理 service worker 流式传输的方法。
我使用的是全新的高级封装容器 workbox-streams。
借助它,我可以将其传递到混合的流式来源中,包括来自缓存和可能来自网络的运行时数据。Workbox 会负责协调各个来源,并将它们拼接成一个流式响应。
此外,Workbox 会自动检测是否支持 Streams API,如果不支持,则会创建等效的非流式响应。这意味着,随着流越来越接近 100% 的浏览器支持,您无需担心编写后备方案。
运行时缓存
我们来了解一下我的 service worker 如何处理来自 Stack Exchange API 的运行时数据。我利用 Workbox 内置的对过时重验证缓存策略的支持以及过期机制,确保 Web 应用的存储空间不会无限增长。
我在 Workbox 中设置了两种策略来处理将构成流式响应的不同来源。只需几个函数调用和配置,Workbox 就能让我们实现原本需要数百行手写代码才能实现的功能。
const cacheStrategy = workbox.strategies.cacheFirst({
cacheName: workbox.core.cacheNames.precache,
});
const apiStrategy = workbox.strategies.staleWhileRevalidate({
cacheName: API_CACHE_NAME,
plugins: [new workbox.expiration.Plugin({maxEntries: 50})],
});
第一种策略读取的是已预缓存的数据,例如我们的部分 HTML 模板。
另一种策略实现了 stale-while-revalidate 缓存逻辑,以及在达到 50 个条目后最近最少使用的缓存过期。
现在,我已制定好这些策略,接下来只需告知 Workbox 如何使用这些策略来构建完整的流式响应。我传入了一个函数数组作为来源,每个函数都会立即执行。Workbox 会按顺序从每个来源获取结果并将其流式传输到 Web 应用,只有当数组中的下一个函数尚未完成时才会延迟。
workbox.streams.strategy([
() => cacheStrategy.makeRequest({request: '/head.html'}),
() => cacheStrategy.makeRequest({request: '/navbar.html'}),
async ({event, url}) => {
const tag = url.searchParams.get('tag') || DEFAULT_TAG;
const listResponse = await apiStrategy.makeRequest(...);
const data = await listResponse.json();
return templates.index(tag, data.items);
},
() => cacheStrategy.makeRequest({request: '/foot.html'}),
]);
前两个来源是直接从 Cache Storage API 读取的预缓存部分模板,因此它们始终可立即使用。这样可确保我们的 service worker 实现能够像服务器端代码一样,可靠地快速响应请求。
我们的下一个源函数会从 Stack Exchange API 中提取数据,并将响应处理为 Web 应用所需的 HTML。
“过时后重新验证”策略意味着,如果我之前缓存了此 API 调用的响应,我将能够立即将其流式传输到网页,同时在“后台”更新缓存条目,以便下次请求时使用。
最后,我将页脚的缓存副本进行流式传输,并关闭最终的 HTML 标记,以完成响应。
分享代码可让一切保持同步
您会注意到,部分 Service Worker 代码看起来很熟悉。我的服务工作线程使用的部分 HTML 和模板化逻辑与服务器端处理程序使用的相同。这种代码共享可确保用户获得一致的体验,无论他们是首次访问我的 Web 应用,还是返回到由 Service Worker 呈现的网页。这正是同构 JavaScript 的精妙之处。
动态渐进增强
我已介绍了 PWA 的服务器和 Service Worker,但还有最后一点逻辑需要介绍:在每个网页完全流式传输后,都会运行少量 JavaScript。
此代码可逐步提升用户体验,但并非至关重要,即使不运行,Web 应用仍可正常运行。
页面元数据
我的应用使用客户端 JavaScript 根据 API 响应更新网页的元数据。由于我为每个网页使用了相同的初始缓存 HTML 位,因此 Web 应用最终会在文档的头部中包含通用标记。不过,通过协调我的模板和客户端代码,我可以使用特定于页面的元数据来更新窗口的标题。
作为模板代码的一部分,我的方法是包含一个包含正确转义字符串的脚本标记。
const metadataScript = `<script>
self._title = '${escape(item.title)}';
</script>`;
然后,在网页加载完毕后,我读取该字符串并更新文档标题。
if (self._title) {
document.title = unescape(self._title);
}
如果您想在自己的 Web 应用中更新其他特定于网页的元数据,可以采用相同的方法。
离线用户体验
我添加的另一个渐进式增强功能用于突出显示我们的离线功能。我构建了一个可靠的 PWA,希望用户知道,即使在离线状态下,他们仍然可以加载之前访问过的网页。
首先,我使用 Cache Storage API 获取之前缓存的所有 API 请求的列表,并将其转换为网址列表。
还记得我之前提到过的那些特殊数据属性吗?每个属性都包含显示问题所需的 API 请求的网址。我可以将这些数据属性与缓存的网址列表进行交叉对比,并创建一个不匹配的所有问题链接的数组。
当浏览器进入离线状态时,我会遍历未缓存的链接列表,并使无法正常使用的链接变暗。请注意,这只是向用户直观地提示这些网页的预期效果,我实际上并未停用这些链接,也没有阻止用户进行导航。
const apiCache = await caches.open(API_CACHE_NAME);
const cachedRequests = await apiCache.keys();
const cachedUrls = cachedRequests.map(request => request.url);
const cards = document.querySelectorAll('.card');
const uncachedCards = [...cards].filter(card => {
return !cachedUrls.includes(card.dataset.cacheUrl);
});
const offlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '0.3';
}
};
const onlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '1.0';
}
};
window.addEventListener('online', onlineHandler);
window.addEventListener('offline', offlineHandler);
常见误区
现在,我已完成有关如何构建多页 PWA 的方法导览。 在制定自己的方法时,您需要考虑许多因素,最终做出的选择可能与我不同。这种灵活性是构建 Web 应用的一大优势。
在自行做出架构决策时,您可能会遇到一些常见的陷阱,我想帮您避免一些麻烦。
不缓存完整 HTML
我不建议在缓存中存储完整的 HTML 文档。首先,这会浪费空间。如果您的 Web 应用的每个网页都使用相同的基本 HTML 结构,您最终会反复存储相同的标记副本。
更重要的是,如果您部署了对网站共享 HTML 结构的更改,之前缓存的每个网页仍会沿用旧布局。试想一下,回访者看到新旧网页混杂在一起时会有多沮丧。
服务器 / 服务工作线程漂移
需要避免的另一个陷阱是服务器与 service worker 不同步。我的方法是使用同构 JavaScript,以便在两个位置运行相同的代码。但根据您现有的服务器架构,这并不总是可行的。
无论您做出何种架构决策,都应制定某种策略,以便在服务器和服务工作器中运行等效的路由和模板代码。
最坏情况
布局 / 设计不一致
如果您忽略这些陷阱,会发生什么情况?当然,可能会出现各种各样的故障,但最糟糕的情况是,回访用户访问的缓存网页的布局非常过时,例如标题文字过时,或者使用的 CSS 类名称不再有效。
最糟糕的情况:路由中断
或者,用户可能会遇到由您的服务器处理但不由您的 Service Worker 处理的网址。如果网站充斥着僵尸布局和死胡同,就不是可靠的 PWA。
成功秘诀
但您并非孤军奋战!以下提示可帮助您避免这些陷阱:
使用具有多语言实现的模板和路由库
尝试使用具有 JavaScript 实现的模板和路由库。现在,我知道并非所有开发者都有条件从当前 Web 服务器和模板语言迁移。
不过,许多热门的模板和路由框架都有多种语言的实现。如果您能找到一个既支持 JavaScript 又支持当前服务器语言的模板,那么您就离保持服务工作线程和服务器同步更近了一步。
首选顺序模板,而非嵌套模板
接下来,我建议使用一系列可以按顺序逐个播放的模板。如果网页的后续部分使用更复杂的模板逻辑,也没关系,只要您能尽快以流式传输方式提供 HTML 的初始部分即可。
在 Service Worker 中缓存静态和动态内容
为获得最佳性能,您应预缓存网站的所有关键静态资源。您还应设置运行时缓存逻辑来处理动态内容,例如 API 请求。使用 Workbox 意味着您可以基于经过充分测试、可用于生产环境的策略进行构建,而无需从头开始实现所有内容。
仅在绝对必要时才在网络上屏蔽
与此相关的是,只有在无法从缓存中流式传输响应时,您才应阻塞网络。与等待新数据相比,立即显示缓存的 API 响应通常可以带来更好的用户体验。