

アーキテクチャについて説明します。
今回は、重要なテーマでありながら誤解されやすいテーマを取り上げます。それは、ウェブアプリで使用するアーキテクチャ、特にプログレッシブ ウェブアプリを構築する際にアーキテクチャの決定がどのように影響するかです。
「アーキテクチャ」という言葉は曖昧に聞こえることがあり、なぜこれが重要なのかがすぐに理解できないことがあります。アーキテクチャについて考える方法の 1 つは、次の質問を自問することです。ユーザーがサイトのページにアクセスしたときに、どのような HTML が読み込まれるか?また、別のページにアクセスしたときに読み込まれるものは何ですか?
これらの質問に対する答えは必ずしも簡単ではありません。プログレッシブ ウェブアプリについて考え始めると、さらに複雑になる可能性があります。そこで、私が効果的だと感じたアーキテクチャの 1 つを説明します。この記事では、私が下した決定をプログレッシブ ウェブアプリの構築における「私のアプローチ」として説明します。
独自の PWA を構築する際に、私の方法を自由に使用できますが、常に他の有効な代替手段もあります。このドキュメントで、すべての要素がどのように組み合わされているかを確認することで、インスピレーションを得て、ニーズに合わせてカスタマイズできるようになることを願っています。
Stack Overflow PWA
この記事に合わせて、Stack Overflow PWA を作成しました。私は Stack Overflow で多くの時間を費やして contributing を行っています。特定のトピックに関するよくある質問を簡単に閲覧できるウェブアプリを構築したいと考えていました。これは、公開されている Stack Exchange API をベースに構築されています。オープンソースであり、GitHub プロジェクトにアクセスして詳細を確認できます。
マルチページ アプリ(MPA)
詳細に入る前に、いくつかの用語を定義し、基盤となるテクノロジーの一部を説明します。まず、私が「マルチページ アプリ」または「MPA」と呼んでいるものについて説明します。
MPA は、ウェブの初期から使用されている従来のアーキテクチャの名称です。ユーザーが新しい URL に移動するたびに、ブラウザはそのページに固有の HTML を段階的にレンダリングします。ナビゲーション間でページのステートやコンテンツを保持しようとはしません。新しいページにアクセスするたびに、最初からやり直すことになります。
これは、ウェブアプリの構築に使用されるシングルページ アプリ(SPA)モデルとは対照的です。SPA モデルでは、ユーザーが新しいセクションにアクセスすると、ブラウザが JavaScript コードを実行して既存のページを更新します。SPA と MPA はどちらも有効なモデルですが、この記事では、マルチページ アプリのコンテキスト内で PWA のコンセプトを探求したいと考えました。
信頼性に優れた高速
「プログレッシブ ウェブアプリ」、つまり PWA という言葉を、私(や他の多くの人)が使っているのを聞いたことがあるでしょう。背景資料の一部は、このサイトの別の場所ですでにご存じかもしれません。
PWA は、優れたユーザー エクスペリエンスを提供し、ユーザーのホーム画面にふさわしいウェブアプリと考えることができます。「FIRE」という頭字語は、Fast(高速)、Integrated(統合)、Reliable(信頼性)、Engaging(魅力的)の頭文字を取ったもので、PWA を構築する際に考慮すべきすべての属性をまとめたものです。
この記事では、これらの属性のサブセットである「高速」と「信頼性」に焦点を当てます。
高速: 「高速」という言葉は文脈によって意味が異なりますが、ここではネットワークから読み込む量を最小限に抑えることによる速度のメリットについて説明します。
信頼性: ただし、速度だけでは十分ではありません。PWA のように感じられるようにするには、ウェブアプリが信頼できるものである必要があります。ネットワークの状態に関係なく、カスタマイズされたエラーページであっても、常に何らかのコンテンツを読み込めるように、十分な復元力が必要です。
信頼性の高い高速性: 最後に、PWA の定義を少し言い換えて、信頼性の高い高速性を備えたものを構築するとはどういうことかを見ていきましょう。低レイテンシ ネットワークに接続しているときだけ高速で信頼性が高いのでは十分ではありません。信頼性の高い高速性とは、基盤となるネットワークの状態に関係なく、ウェブアプリの速度が一定であることを意味します。
実現技術: Service Worker と Cache Storage API
PWA は、速度と復元力に関する高い基準を導入しています。幸いなことに、ウェブ プラットフォームには、そのようなパフォーマンスを実現するためのビルディング ブロックがいくつか用意されています。サービス ワーカーと Cache Storage API のことです。
Cache Storage API を使用して、受信リクエストをリッスンし、一部をネットワークに渡し、レスポンスのコピーを将来の使用のために保存するサービス ワーカーを構築できます。

ウェブアプリが次回同じリクエストを行うと、サービス ワーカーはキャッシュをチェックして、以前にキャッシュに保存されたレスポンスを返すことができます。
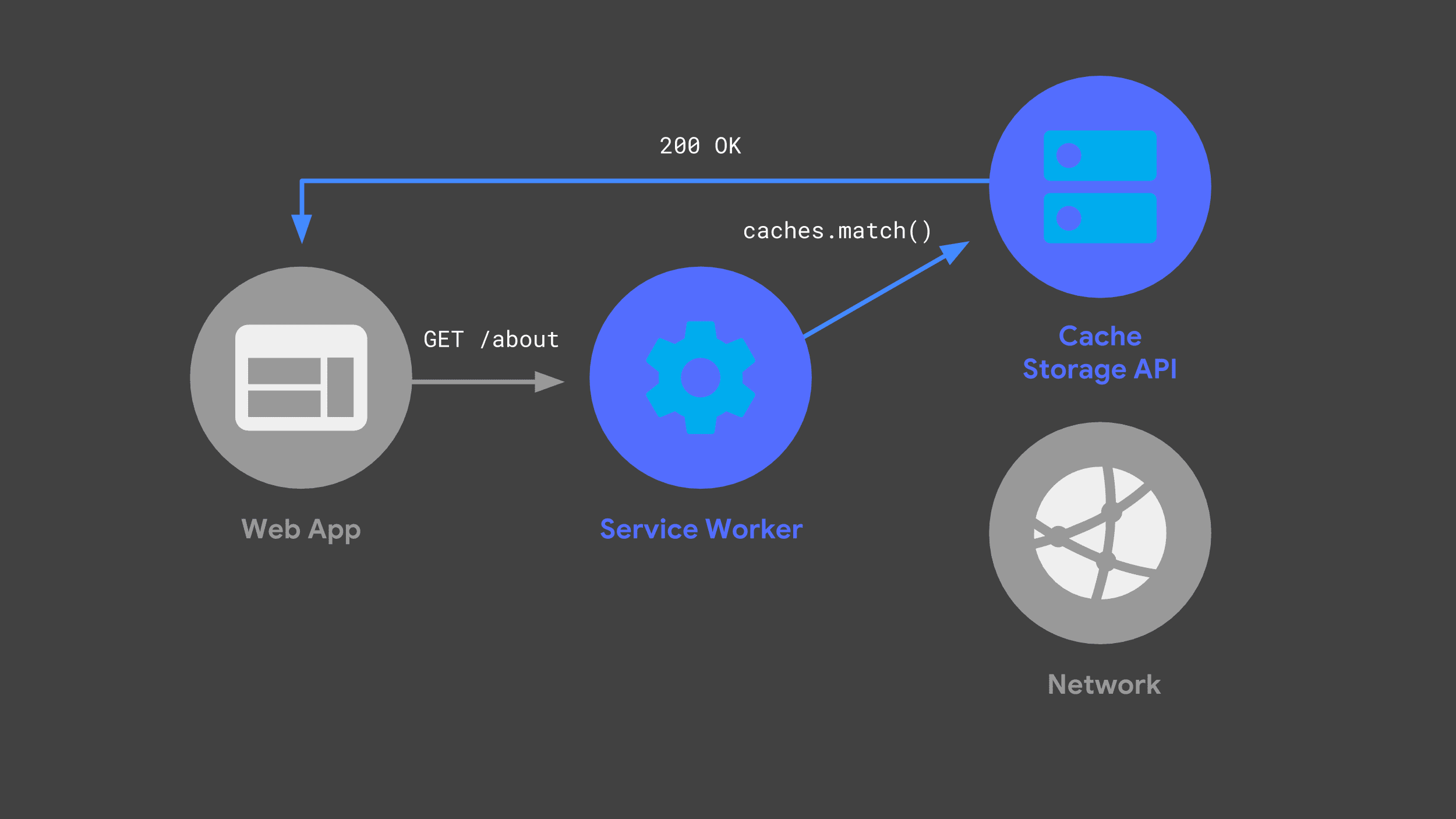
可能な限りネットワークを回避することは、信頼性の高い高速パフォーマンスを実現するうえで重要な要素です。
「同形」JavaScript
もう 1 つ、「同型」または「ユニバーサル」JavaScript と呼ばれるコンセプトについて説明します。簡単に言うと、同じ JavaScript コードを異なるランタイム環境間で共有できるという考え方です。PWA を構築する際、バックエンド サーバーとサービス ワーカー間で JavaScript コードを共有したいと考えました。
この方法でコードを共有する有効なアプローチはたくさんありますが、私のアプローチは、ES モジュールを確定的なソースコードとして使用することでした。次に、Babel と Rollup を組み合わせて、サーバーとサービス ワーカー用にこれらのモジュールをトランスパイルしてバンドルしました。私のプロジェクトでは、.mjs ファイル拡張子のファイルは ES モジュールに存在するコードです。
サーバー
これらのコンセプトと用語を念頭に置いて、Stack Overflow PWA を実際に構築した方法を見ていきましょう。まず、バックエンド サーバーについて説明し、それがアーキテクチャ全体にどのように適合するかを説明します。
動的バックエンドと静的ホスティングの組み合わせを探していたので、Firebase プラットフォームを使用することにしました。
Firebase Cloud Functions は、リクエストが届くと Node ベースの環境を自動的に起動し、私がすでに使い慣れていた一般的な Express HTTP フレームワークと統合されます。また、サイトのすべての静的リソースに対してすぐに使えるホスティングも提供しています。サーバーがリクエストを処理する方法を見てみましょう。
ブラウザが Google のサーバーに対してナビゲーション リクエストを行うと、次のフローが実行されます。
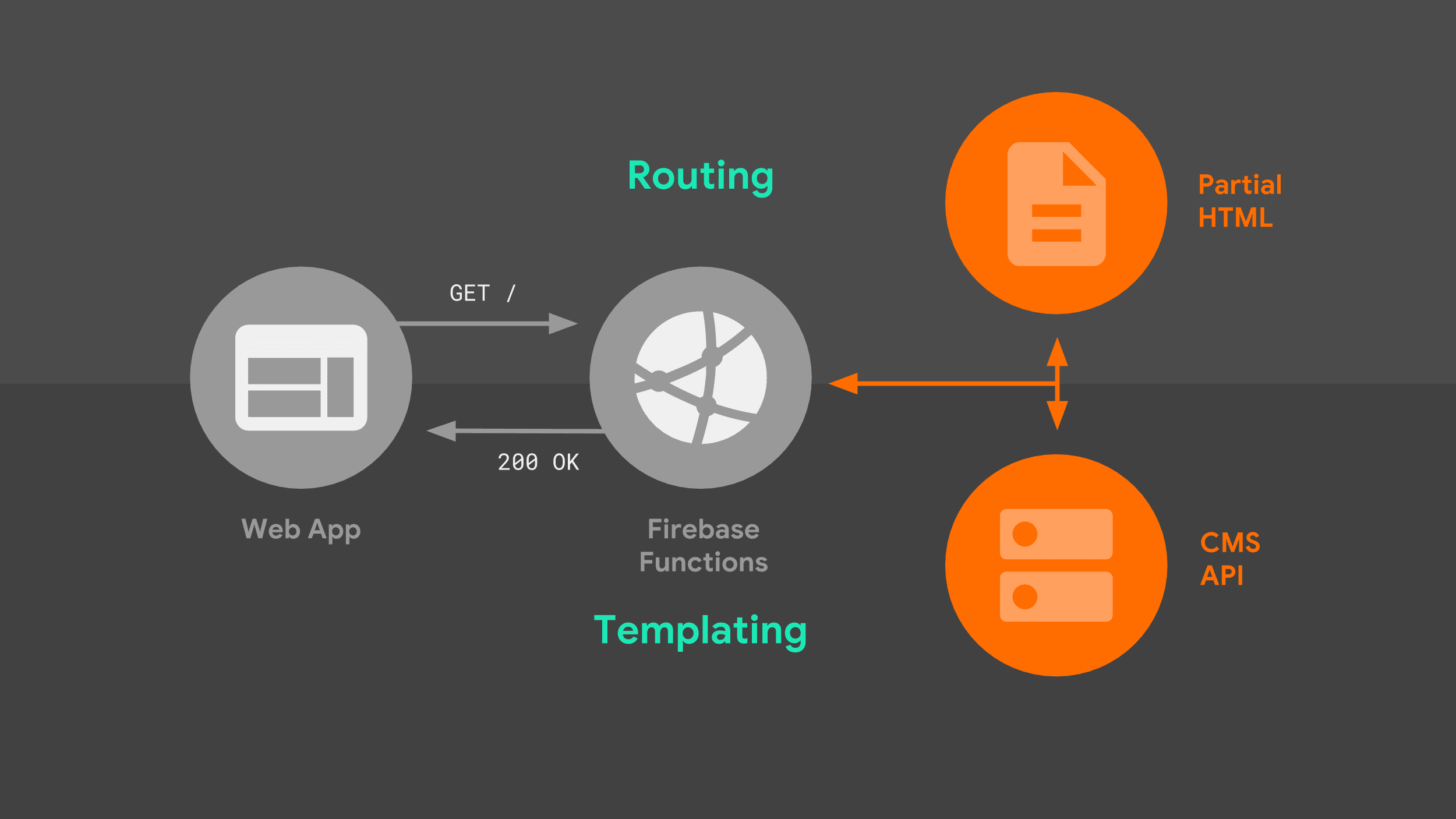
サーバーは URL に基づいてリクエストをルーティングし、テンプレート ロジックを使用して完全な HTML ドキュメントを作成します。Stack Exchange API からのデータと、サーバーがローカルに保存する部分的な HTML フラグメントを組み合わせて使用しています。サービス ワーカーが応答方法を認識すると、HTML のストリーミングをウェブアプリに開始できます。
この図には、ルーティングとテンプレートという 2 つの重要な要素があります。
ルーティング
ルーティングに関しては、Express フレームワークのネイティブ ルーティング構文を使用しました。シンプルな URL 接頭辞だけでなく、パスの一部としてパラメータを含む URL にも一致する柔軟性があります。ここでは、ルート名と照合する基盤となる Express パターンのマッピングを作成します。
const routes = new Map([
['about', '/about'],
['questions', '/questions/:questionId'],
['index', '/'],
]);
export default routes;
このマッピングは、サーバーのコードから直接参照できます。特定の Express パターンに一致するものがある場合、適切なハンドラが一致するルートに固有のテンプレート ロジックで応答します。
import routes from './lib/routes.mjs';
app.get(routes.get('index'), async (req, res) => {
// Templating logic.
});
サーバーサイド テンプレート
このテンプレート ロジックはどのようなものですか?そこで、部分的な HTML フラグメントを順番に 1 つずつ組み立てるアプローチを採用しました。このモデルはストリーミングに適しています。
サーバーは初期 HTML ボイラープレートをすぐに返送し、ブラウザはすぐにその部分的なページをレンダリングできます。サーバーが残りのデータソースを組み立てると、ドキュメントが完成するまでブラウザにストリーミングします。
例として、ルートの 1 つの Express コードをご覧ください。
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
response オブジェクトの write() メソッドを使用し、ローカルに保存された部分テンプレートを参照することで、外部データソースをブロックすることなく、レスポンス ストリームをすぐに開始できます。ブラウザはこの初期 HTML を取得し、すぐに意味のあるインターフェースと読み込みメッセージをレンダリングします。
ページの次の部分では、Stack Exchange API のデータを使用します。このデータを取得するには、サーバーがネットワーク リクエストを行う必要があります。ウェブアプリはレスポンスを受け取って処理するまで何もレンダリングできませんが、少なくともユーザーは待機中に空白の画面を見つめることはありません。
ウェブアプリが Stack Exchange API からレスポンスを受け取ると、カスタム テンプレート関数を呼び出して、API からのデータを対応する HTML に変換します。
テンプレート言語
テンプレートは意外と議論の多いトピックであり、私が採用したものは数多くのアプローチの 1 つにすぎません。特に既存のテンプレート フレームワークとのレガシーな関係がある場合は、独自のソリューションに置き換えることをおすすめします。
私のユースケースでは、JavaScript のテンプレート リテラルに依存し、一部のロジックをヘルパー関数に分割するのが適切でした。MPA の構築の利点の 1 つは、状態の更新を追跡して HTML を再レンダリングする必要がないことです。そのため、静的 HTML を生成する基本的なアプローチが有効でした。
ウェブアプリのインデックスの動的 HTML 部分をテンプレート化する方法の例を次に示します。ルートと同様に、テンプレート ロジックはサーバーとサービス ワーカーの両方にインポートできる ES モジュールに保存されます。
export function index(tag, items) {
const title = `<h3>Top "${escape(tag)}" Questions</h3>`;
const form = `<form method="GET">...</form>`;
const questionCards = items
.map(item =>
questionCard({
id: item.question_id,
title: item.title,
})
)
.join('');
const questions = `<div id="questions">${questionCards}</div>`;
return title + form + questions;
}
これらのテンプレート関数は純粋な JavaScript であり、必要に応じてロジックをより小さなヘルパー関数に分割すると便利です。ここでは、API レスポンスで返された各項目をそのような関数の 1 つに渡し、適切な属性がすべて設定された標準の HTML 要素を作成します。
function questionCard({id, title}) {
return `<a class="card"
href="/questions/${id}"
data-cache-url="${questionUrl(id)}">${title}</a>`;
}
特に注目すべき点は、各リンクに追加するデータ属性 data-cache-url です。これは、対応する質問を表示するために必要な Stack Exchange API URL に設定されています。この点に注意してください。後で確認します。
ルート ハンドラに戻ると、テンプレートの作成が完了したら、ページの HTML の最後の部分をブラウザにストリーミングして、ストリームを終了します。これは、プログレッシブ レンダリングが完了したことをブラウザに伝える合図です。
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
以上がサーバー設定の簡単な概要です。ウェブアプリに初めてアクセスしたユーザーには、常にサーバーからレスポンスが返されますが、リピーターがウェブアプリにアクセスした場合は、サービス ワーカーがレスポンスを返します。詳しく見ていきましょう。
Service Worker
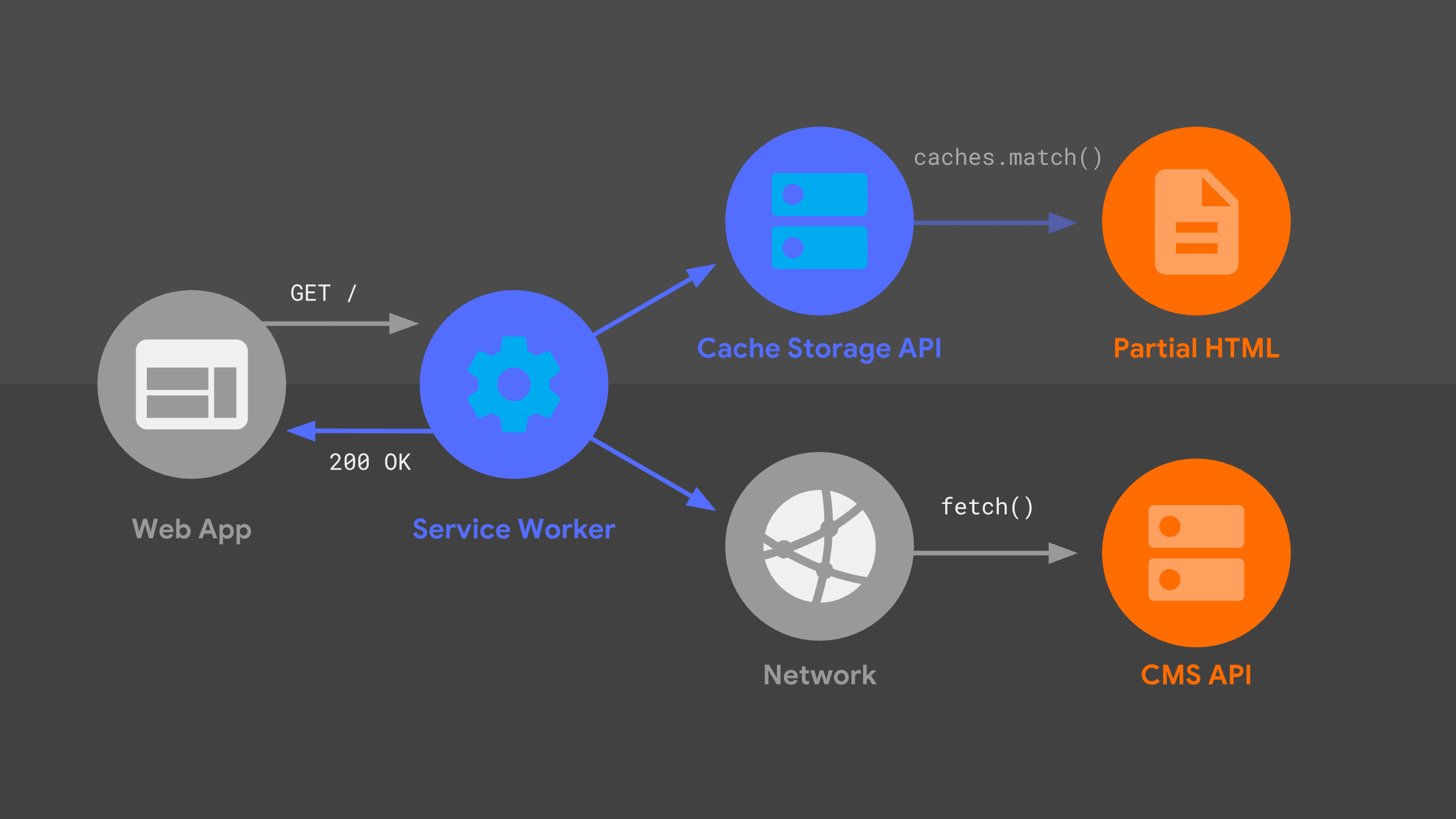
この図は、以前に説明した多くの要素が少し異なる配置で示されているため、見覚えがあるはずです。サービス ワーカーを考慮して、リクエスト フローを見てみましょう。
サービス ワーカーは、特定の URL へのナビゲーション リクエストを処理します。サーバーと同様に、ルーティングとテンプレート ロジックを組み合わせて、レスポンスの方法を判断します。
アプローチは以前と同じですが、fetch() や Cache Storage API などの低レベルのプリミティブが異なります。これらのデータソースを使用して HTML レスポンスを構築し、サービス ワーカーがウェブアプリに渡します。
Workbox
低レベルのプリミティブからゼロから始めるのではなく、Workbox と呼ばれる一連の高レベル ライブラリの上にサービス ワーカーを構築します。サービス ワーカーのキャッシュ保存、ルーティング、レスポンス生成ロジックの確固たる基盤を提供します。
ルーティング
サーバーサイド コードと同様に、サービス ワーカーは受信リクエストを適切なレスポンス ロジックと照合する方法を知る必要があります。
私の方法は、regexparam という便利なライブラリを使用して、各 Express ルートを対応する正規表現に変換することでした。この変換が完了すると、Workbox の 正規表現ルーティングの組み込みサポートを利用できます。
正規表現を含むモジュールをインポートしたら、各正規表現を Workbox のルーターに登録します。各ルート内で、カスタム テンプレート ロジックを指定してレスポンスを生成できます。サービス ワーカーでのテンプレート処理は、バックエンド サーバーでのテンプレート処理よりも少し複雑ですが、Workbox が多くの作業をサポートしてくれます。
import regExpRoutes from './regexp-routes.mjs';
workbox.routing.registerRoute(
regExpRoutes.get('index')
// Templating logic.
);
静的アセットのキャッシュ保存
テンプレートの重要な部分の 1 つは、部分 HTML テンプレートが Cache Storage API を介してローカルで利用可能であり、ウェブアプリへの変更のデプロイ時に最新の状態に保たれるようにすることです。キャッシュのメンテナンスを手動で行うとエラーが発生しやすいため、ビルドプロセスの一部として プリキャッシュを処理するために Workbox を使用します。
構成ファイルを使用して、プリキャッシュする URL を Workbox に伝えます。このファイルでは、すべてのローカル アセットを含むディレクトリと、照合する一連のパターンを指定します。このファイルは、サイトを再構築するたびに実行される Workbox の CLI によって自動的に読み取られます。
module.exports = {
globDirectory: 'build',
globPatterns: ['**/*.{html,js,svg}'],
// Other options...
};
Workbox は各ファイルの内容のスナップショットを取得し、その URL とリビジョンのリストを最終的なサービス ワーカー ファイルに自動的に挿入します。Workbox には、プリキャッシュされたファイルを常に利用可能にし、最新の状態に保つために必要なものがすべて揃っています。結果として、次のような内容を含む service-worker.js ファイルが生成されます。
workbox.precaching.precacheAndRoute([
{
url: 'partials/about.html',
revision: '518747aad9d7e',
},
{
url: 'partials/foot.html',
revision: '69bf746a9ecc6',
},
// etc.
]);
より複雑なビルドプロセスを使用するユーザー向けに、Workbox には コマンドライン インターフェースに加えて、webpack プラグインと汎用ノード モジュールの両方が用意されています。
ストリーミング
次に、サービス ワーカーがプリキャッシュされた部分 HTML をウェブアプリにすぐにストリーミングで返すようにします。これは「確実に速い」ための重要な要素です。常に意味のあるものがすぐに画面に表示されます。幸いなことに、サービス ワーカー内で Streams API を使用することで、それが可能になります。
Streams API については、以前からご存じの方もいらっしゃるかもしれません。同僚の Jake Archibald は、何年も前からこの機能を絶賛しています。彼は、2016 年がウェブ ストリームの年になると大胆な予測をしました。Streams API は 2 年前と同じくらい優れていますが、重要な違いがあります。
当時、Streams をサポートしていたのは Chrome のみでしたが、現在では Streams API のサポートが広がっています。全体的に見ると、ストリームはポジティブなものであり、適切なフォールバック コードを使用すれば、今日からサービス ワーカーでストリームを使用できます。
ただし、Streams API の実際の仕組みを理解することが難しい場合があります。非常に強力なプリミティブのセットが公開されており、これらを使い慣れているデベロッパーは、次のような複雑なデータフローを作成できます。
const stream = new ReadableStream({
pull(controller) {
return sources[0]
.then(r => r.read())
.then(result => {
if (result.done) {
sources.shift();
if (sources.length === 0) return controller.close();
return this.pull(controller);
} else {
controller.enqueue(result.value);
}
});
},
});
ただし、このコードの完全な意味を理解することは、すべての人にとって必要ではないかもしれません。このロジックを解析するのではなく、サービス ワーカーのストリーミングに対するアプローチについて説明します。
新しい高レベル ラッパー workbox-streams を使用しています。これにより、ネットワークから取得される可能性のあるキャッシュとランタイム データの両方から、ストリーミング ソースのミックスで渡すことができます。Workbox は、個々のソースの調整と、それらを 1 つのストリーミング レスポンスに結合する処理を行います。
また、Workbox は Streams API がサポートされているかどうかを自動的に検出し、サポートされていない場合は同等の非ストリーミング レスポンスを作成します。つまり、ストリームのブラウザ サポートが 100% に近づくにつれて、フォールバックの作成を心配する必要がなくなります。
ランタイム キャッシュ保存
Stack Exchange API からのランタイム データを サービス ワーカーがどのように処理するかを見てみましょう。Workbox の stale-while-revalidate キャッシュ保存戦略の組み込みサポートと有効期限を利用して、ウェブアプリのストレージが際限なく増大しないようにしています。
Workbox で 2 つの戦略を設定し、ストリーミング レスポンスを構成するさまざまなソースを処理します。Workbox を使用すると、数回の関数呼び出しと構成で、手書きのコードを何百行も記述しなければならない処理を実行できます。
const cacheStrategy = workbox.strategies.cacheFirst({
cacheName: workbox.core.cacheNames.precache,
});
const apiStrategy = workbox.strategies.staleWhileRevalidate({
cacheName: API_CACHE_NAME,
plugins: [new workbox.expiration.Plugin({maxEntries: 50})],
});
最初の戦略では、部分 HTML テンプレートなど、事前にキャッシュに保存されたデータを読み取ります。
もう一方の戦略では、50 個のエントリに達すると、LRU キャッシュの有効期限とともに、stale-while-revalidate キャッシュ ロジックが実装されます。
これらの戦略が整ったので、あとはそれらを使用して完全なストリーミング レスポンスを構築する方法を Workbox に伝えるだけです。ソースの配列を関数として渡すと、これらの関数はそれぞれすぐに実行されます。Workbox は各ソースの結果を取得し、順番にウェブアプリにストリーミングします。配列内の次の関数がまだ完了していない場合にのみ遅延します。
workbox.streams.strategy([
() => cacheStrategy.makeRequest({request: '/head.html'}),
() => cacheStrategy.makeRequest({request: '/navbar.html'}),
async ({event, url}) => {
const tag = url.searchParams.get('tag') || DEFAULT_TAG;
const listResponse = await apiStrategy.makeRequest(...);
const data = await listResponse.json();
return templates.index(tag, data.items);
},
() => cacheStrategy.makeRequest({request: '/foot.html'}),
]);
最初の 2 つのソースは、Cache Storage API から直接読み取られるプリキャッシュされた部分テンプレートであるため、常にすぐに使用できます。これにより、サーバーサイド コードと同様に、サービス ワーカーの実装がリクエストに確実に迅速に応答できるようになります。
次のソース関数は、Stack Exchange API からデータを取得し、ウェブアプリが想定する HTML にレスポンスを処理します。
stale-while-revalidate 戦略では、この API 呼び出しのレスポンスが以前にキャッシュに保存されている場合、そのレスポンスをすぐにページにストリーミングできます。同時に、次回リクエストされたときに使用できるように、キャッシュ エントリを「バックグラウンド」で更新します。
最後に、フッターのキャッシュ コピーをストリーミングし、最後の HTML タグを閉じてレスポンスを完了します。
コードを共有して同期を維持する
サービス ワーカーのコードの一部が、以前見たものと似ていることに気づくでしょう。サービス ワーカーで使用される部分的な HTML とテンプレート ロジックは、サーバーサイド ハンドラで使用されるものと同じです。このコード共有により、ユーザーが初めてウェブアプリにアクセスする場合でも、サービス ワーカーによってレンダリングされたページに戻る場合でも、一貫したエクスペリエンスが提供されます。これが同型 JavaScript の優れた点です。
動的でプログレッシブな拡張機能
PWA のサーバーとサービス ワーカーの両方について説明しましたが、最後に説明するロジックが 1 つあります。各ページが完全にストリーミングされた後に実行される少量の JavaScript があります。
このコードはユーザー エクスペリエンスを段階的に向上させますが、必須ではありません。実行されなくてもウェブアプリは動作します。
ページ メタデータ
私のアプリは、クライアントサイドの JavaScript を使用して、API レスポンスに基づいてページのメタデータを更新しています。各ページで同じ初期ビットのキャッシュ保存された HTML を使用しているため、ウェブアプリではドキュメントの head に汎用タグが追加されます。しかし、テンプレートとクライアントサイド コードの連携により、ページ固有のメタデータを使用してウィンドウのタイトルを更新できます。
テンプレート コードの一部として、適切にエスケープされた文字列を含むスクリプトタグを含める方法をおすすめします。
const metadataScript = `<script>
self._title = '${escape(item.title)}';
</script>`;
次に、ページが読み込まれたら、その文字列を読み取ってドキュメントのタイトルを更新します。
if (self._title) {
document.title = unescape(self._title);
}
独自のウェブアプリで更新したいページ固有のメタデータが他にもある場合は、同じ方法で対応できます。
オフライン UX
追加したもう 1 つのプログレッシブ エンハンスメントは、オフライン機能に注目を集めるために使用されます。信頼性の高い PWA を構築しました。オフラインでも以前にアクセスしたページを読み込めることをユーザーに知らせたいです。
まず、Cache Storage API を使用して、以前にキャッシュに保存されたすべての API リクエストのリストを取得し、それを URL のリストに変換します。
前述した特別なデータ属性を思い出してください。各属性には、質問を表示するために必要な API リクエストの URL が含まれています。これらのデータ属性をキャッシュに保存された URL のリストと照合し、一致しない質問リンクの配列を作成できます。
ブラウザがオフライン状態になると、キャッシュに保存されていないリンクのリストをループ処理し、機能しないリンクを暗くします。これは、ユーザーがページに期待する内容を視覚的に示すヒントにすぎません。リンクを実際に無効にしたり、ユーザーが移動できないようにしたりしているわけではありません。
const apiCache = await caches.open(API_CACHE_NAME);
const cachedRequests = await apiCache.keys();
const cachedUrls = cachedRequests.map(request => request.url);
const cards = document.querySelectorAll('.card');
const uncachedCards = [...cards].filter(card => {
return !cachedUrls.includes(card.dataset.cacheUrl);
});
const offlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '0.3';
}
};
const onlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '1.0';
}
};
window.addEventListener('online', onlineHandler);
window.addEventListener('offline', offlineHandler);
主な注意点
これで、マルチページ PWA を構築するアプローチのツアーは終了です。独自のアプローチを考案する際には、多くの要素を考慮する必要があります。そのため、私とは異なる選択をする可能性もあります。この柔軟性は、ウェブ向けに構築する際の大きなメリットの 1 つです。
独自のアーキテクチャの決定を行う際に陥りやすい落とし穴がいくつかあります。ここでは、そうした落とし穴を回避する方法について説明します。
HTML 全体をキャッシュに保存しない
完全な HTML ドキュメントをキャッシュに保存することはおすすめしません。まず、スペースの無駄です。ウェブアプリの各ページで同じ基本的な HTML 構造を使用している場合、同じマークアップのコピーが何度も保存されることになります。
さらに重要なのは、サイトの共有 HTML 構造に変更をデプロイした場合、以前にキャッシュに保存されたページはすべて古いレイアウトのままになることです。リピーターが古いページと新しいページが混在しているのを見たときの不満を想像してみてください。
サーバー / サービス ワーカーのドリフト
もう 1 つの落とし穴は、サーバーとサービス ワーカーの同期が取れなくなることです。私のアプローチは、アイソモーフィック JavaScript を使用して、同じコードが両方の場所で実行されるようにすることでした。既存のサーバー アーキテクチャによっては、必ずしも可能とは限りません。
どのようなアーキテクチャ上の決定を下すにしても、サーバーとサービス ワーカーで同等のルーティング コードとテンプレート コードを実行するための戦略が必要です。
最悪のシナリオ
レイアウト / デザインの一貫性がない
これらの落とし穴を無視するとどうなるでしょうか?さまざまな障害が発生する可能性がありますが、最悪のシナリオは、リピーターが非常に古いレイアウトのキャッシュにアクセスすることです。たとえば、ヘッダー テキストが古くなっていたり、無効になった CSS クラス名が使用されていたりする可能性があります。
最悪のシナリオ: ルーティングの破損
また、ユーザーがサーバーで処理される URL を見つけても、Service Worker で処理されないこともあります。ゾンビ レイアウトや行き止まりだらけのサイトは、信頼できる PWA とは言えません。
成功のためのヒント
しかし、この状況はあなただけのものではありません。次のヒントは、そのような落とし穴を回避するのに役立ちます。
多言語実装を備えたテンプレート ライブラリとルーティング ライブラリを使用する
JavaScript 実装のあるテンプレート ライブラリとルーティング ライブラリを使用してみてください。すべてのデベロッパーが、現在のウェブサーバーとテンプレート言語から移行できるわけではないことは承知しています。
ただし、一般的なテンプレート フレームワークやルーティング フレームワークの多くは、複数の言語で実装されています。JavaScript と現在のサーバーの言語の両方で動作するライブラリが見つかれば、サービス ワーカーとサーバーの同期を維持するのに一歩近づきます。
ネストされたテンプレートではなく、シーケンシャル テンプレートを優先する
次に、連続した一連のテンプレートを次々とストリーミングすることをおすすめします。HTML の最初の部分をできるだけ早くストリーミングできる限り、ページの後半でより複雑なテンプレート ロジックを使用しても問題ありません。
Service Worker で静的コンテンツと動的コンテンツの両方をキャッシュに保存する
パフォーマンスを最大限に高めるには、サイトの重要な静的リソースをすべてプリキャッシュする必要があります。API リクエストなどの動的コンテンツを処理するために、ランタイム キャッシュ保存ロジックも設定する必要があります。Workbox を使用すると、すべてをゼロから実装するのではなく、十分にテストされた本番環境対応の戦略を基盤として構築できます。
ネットワークでのブロックは、どうしても必要な場合にのみ行う
また、キャッシュからレスポンスをストリーミングできない場合にのみ、ネットワークをブロックする必要があります。キャッシュに保存された API レスポンスをすぐに表示するほうが、新しいデータを待つよりもユーザー エクスペリエンスが向上することがよくあります。