

Porozmawiajmy o architekturze.
Omówię ważne, ale potencjalnie niezrozumiane zagadnienie: architekturę aplikacji internetowej, a w szczególności to, jak decyzje dotyczące architektury wpływają na tworzenie progresywnej aplikacji internetowej.
„Architektura” może brzmieć niejasno i nie od razu wiadomo, dlaczego ma to znaczenie. Jednym ze sposobów myślenia o architekturze jest zadanie sobie tych pytań: gdy użytkownik odwiedza stronę w mojej witrynie, jaki kod HTML jest wczytywany? Co się wczytuje, gdy użytkownik odwiedza inną stronę?
Odpowiedzi na te pytania nie zawsze są proste, a gdy zaczniesz myśleć o progresywnych aplikacjach internetowych, mogą się one jeszcze bardziej skomplikować. Moim celem jest przedstawienie Ci jednej z możliwych architektur, która moim zdaniem jest skuteczna. W tym artykule będę oznaczać podjęte przeze mnie decyzje jako „moje podejście” do tworzenia progresywnej aplikacji internetowej.
Możesz wykorzystać moje podejście podczas tworzenia własnej progresywnej aplikacji internetowej, ale pamiętaj, że zawsze istnieją inne, równie dobre rozwiązania. Mam nadzieję, że zobaczenie, jak wszystkie elementy pasują do siebie, Cię zainspiruje i zachęci do dostosowania ich do swoich potrzeb.
Aplikacja PWA Stack Overflow
Na potrzeby tego artykułu stworzyłem aplikację PWA Stack Overflow. Dużo czasu poświęcam na czytanie i współtworzenie treści na platformie Stack Overflow. Chciałem stworzyć aplikację internetową, która ułatwi przeglądanie najczęstszych pytań dotyczących danego tematu. Jest on oparty na publicznym interfejsie API Stack Exchange. Jest to projekt open source. Więcej informacji znajdziesz na stronie projektu w GitHubie.
Aplikacje wielostronicowe (MPA)
Zanim przejdziemy do szczegółów, zdefiniujmy kilka terminów i wyjaśnijmy działanie technologii, na których opiera się ta funkcja. Najpierw omówię to, co nazywam „aplikacjami wielostronicowymi” lub „MPA”.
MPA to elegancka nazwa tradycyjnej architektury używanej od początku istnienia internetu. Za każdym razem, gdy użytkownik przechodzi do nowego adresu URL, przeglądarka stopniowo renderuje kod HTML specyficzny dla tej strony. Nie ma próby zachowania stanu strony ani treści między nawigacjami. Za każdym razem, gdy otworzysz nową stronę, zaczynasz od nowa.
Różni się to od modelu aplikacji na jednej stronie (SPA), w którym przeglądarka uruchamia kod JavaScript, aby zaktualizować istniejącą stronę, gdy użytkownik odwiedza nową sekcję. Zarówno aplikacje SPA, jak i MPA są równie przydatne, ale w tym poście chcę omówić koncepcje PWA w kontekście aplikacji wielostronicowej.
Niezawodnie szybkie
Zapewne słyszeliście, jak ja (i wiele innych osób) używam określenia „progresywna aplikacja internetowa” lub PWA. Niektóre informacje podstawowe możesz już znać z innych miejsc w tej witrynie.
PWA to aplikacja internetowa, która zapewnia użytkownikom najwyższą jakość i zasługuje na miejsce na ekranie głównym. Akronim „FIRE” (Fast, Integrated, Reliable, Engaging) podsumowuje wszystkie atrybuty, o których należy pamiętać podczas tworzenia PWA.
W tym artykule skupię się na podzbiorze tych atrybutów: szybkość i niezawodność.
Szybkość: „Szybkość” ma różne znaczenia w różnych kontekstach, ale ja omówię korzyści związane z szybkością wczytywania jak najmniejszej ilości danych z sieci.
Niezawodność: Sama szybkość nie wystarczy. Aby aplikacja internetowa sprawiała wrażenie PWA, powinna być niezawodna. Musi być wystarczająco odporna, aby zawsze coś wczytywać, nawet jeśli jest to tylko dostosowana strona błędu, niezależnie od stanu sieci.
Niezawodnie szybkie: na koniec nieco zmodyfikuję definicję PWA i przyjrzę się temu, co oznacza tworzenie aplikacji, która działa niezawodnie szybko. Szybkość i niezawodność tylko w sieci o niskim czasie oczekiwania to za mało. Niezawodna szybkość oznacza, że aplikacja internetowa działa z równą szybkością niezależnie od warunków sieciowych.
Technologie: Service Worker i Cache Storage API
Aplikacje PWA wyznaczają wysoki standard szybkości i odporności. Na szczęście platforma internetowa oferuje pewne elementy, które umożliwiają osiągnięcie takiej wydajności. Mam na myśli service workerów i interfejs Cache Storage API.
Możesz utworzyć service worker, który nasłuchuje przychodzących żądań, przekazuje niektóre z nich do sieci i przechowuje kopię odpowiedzi do wykorzystania w przyszłości za pomocą interfejsu Cache Storage API.
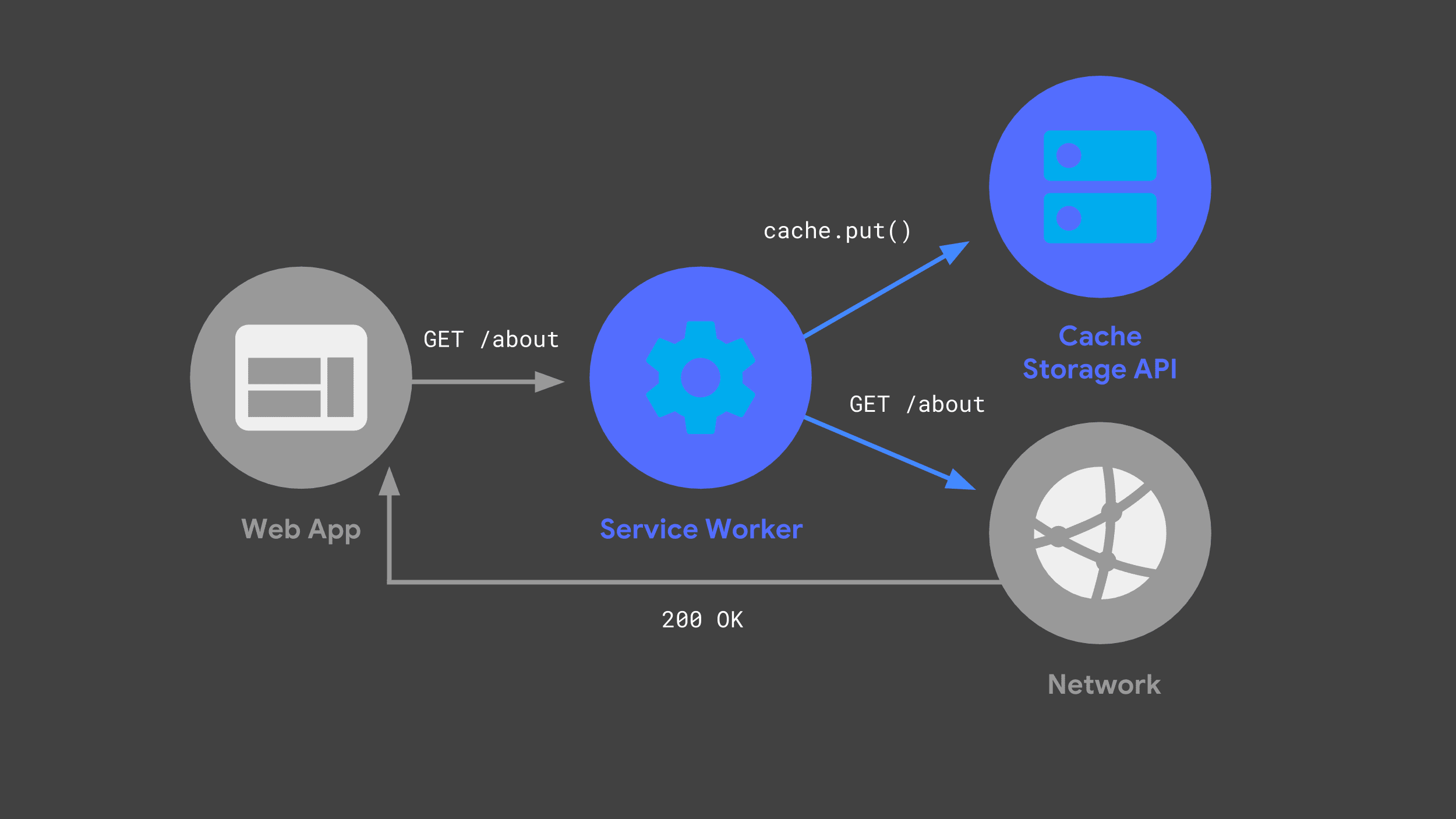
Gdy aplikacja internetowa ponownie wyśle to samo żądanie, skrypt service worker może sprawdzić swoje pamięci podręczne i zwrócić wcześniej zapisane w nich odpowiedzi.
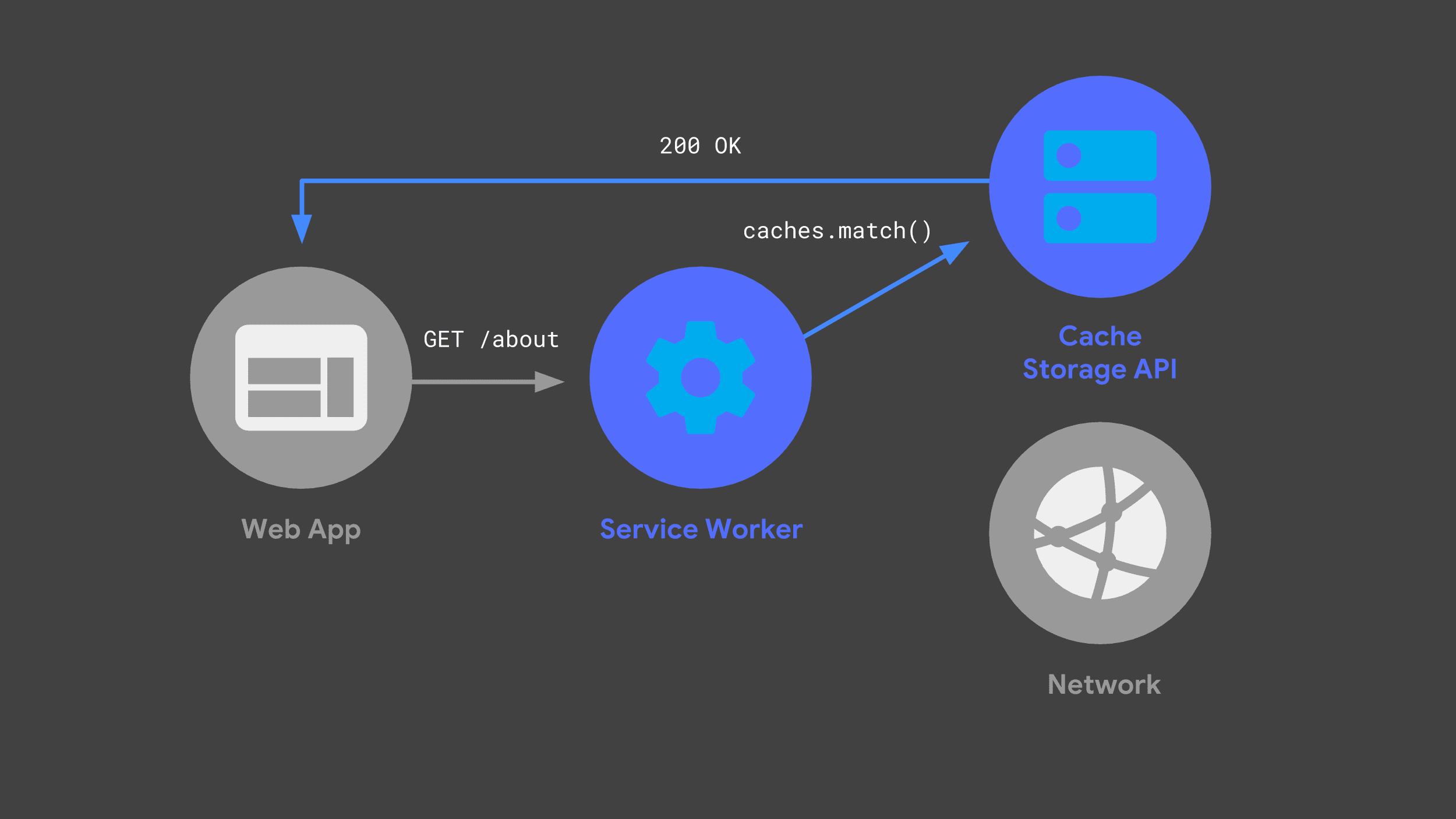
Unikanie sieci, gdy tylko jest to możliwe, jest kluczowym elementem zapewnienia niezawodnej i szybkiej wydajności.
„Izomorficzny” JavaScript
Kolejną koncepcją, którą chcę omówić, jest to, co czasami nazywa się „izomorficznym” lub „uniwersalnym” JavaScriptem. Mówiąc wprost, chodzi o to, że ten sam kod JavaScript może być udostępniany w różnych środowiskach wykonawczych. Podczas tworzenia progresywnej aplikacji internetowej chciałem udostępniać kod JavaScript między serwerem backendu a procesem service worker.
Istnieje wiele prawidłowych sposobów udostępniania kodu w ten sposób, ale moje podejście polegało na użyciu modułów ES jako ostatecznego kodu źródłowego. Następnie przekształciłem i spakowałem te moduły na potrzeby serwera i service workera, używając do tego kombinacji Babel i Rollup. W moim projekcie pliki z rozszerzeniem .mjs to kod znajdujący się w module ES.
serwer,
Mając na uwadze te pojęcia i terminologię, zobaczmy, jak powstała moja progresywna aplikacja internetowa Stack Overflow. Zacznę od omówienia naszego serwera backendu i wyjaśnię, jak wpisuje się on w ogólną architekturę.
Szukałem połączenia dynamicznego backendu z hostingiem statycznym i postanowiłem skorzystać z platformy Firebase.
Firebase Cloud Functions automatycznie uruchamia środowisko oparte na Node.js, gdy pojawia się żądanie przychodzące, i integruje się z popularnym frameworkiem HTTP Express, który już znałem. Zapewnia też gotowe hostowanie wszystkich statycznych zasobów mojej witryny. Przyjrzyjmy się, jak serwer obsługuje żądania.
Gdy przeglądarka wysyła do naszego serwera żądanie nawigacji, przechodzi przez następujący proces:
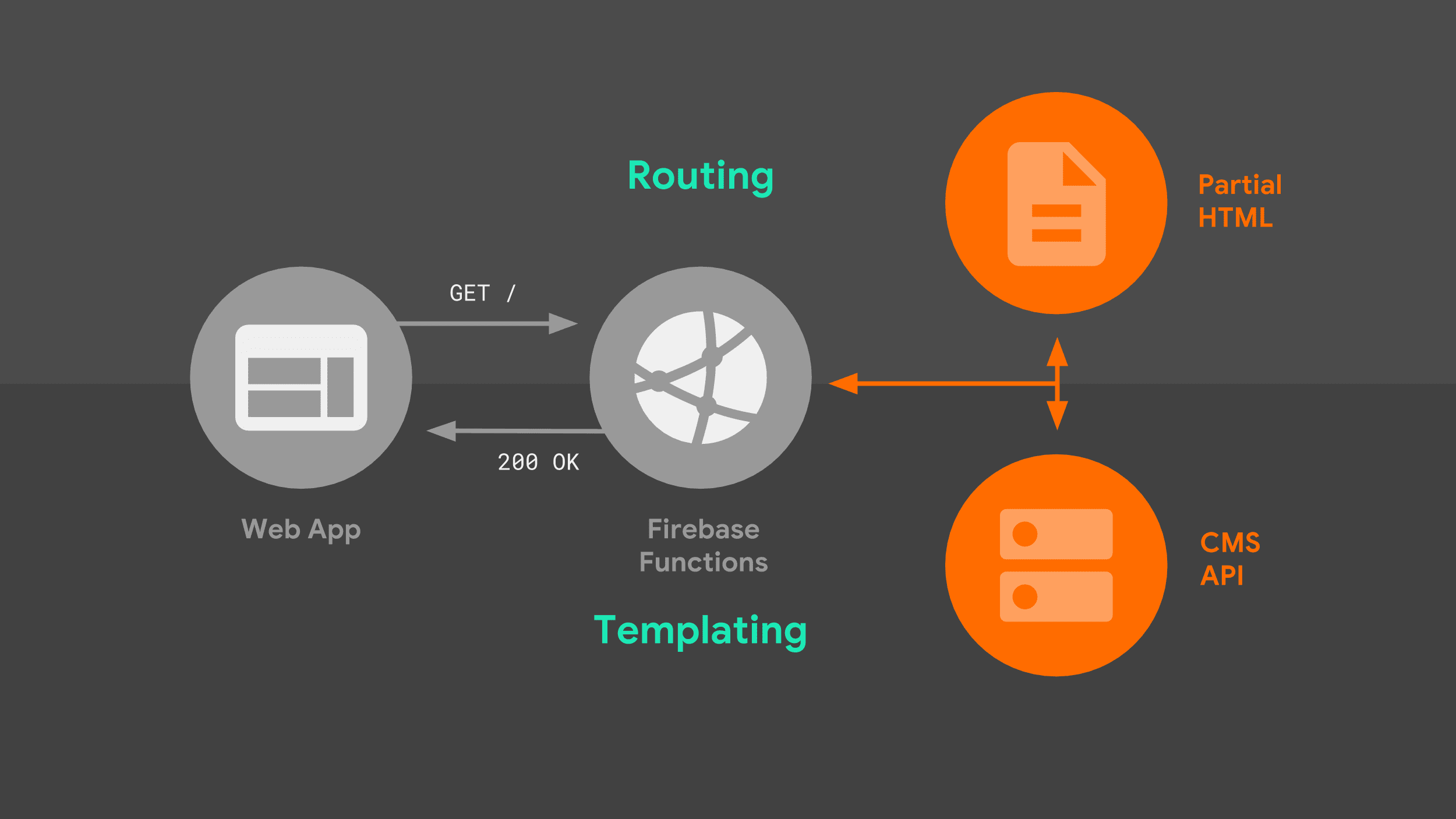
Serwer kieruje żądanie na podstawie adresu URL i używa logiki szablonów do utworzenia pełnego dokumentu HTML. Korzystam z danych z interfejsu Stack Exchange API oraz z fragmentów HTML, które serwer przechowuje lokalnie. Gdy service worker będzie wiedzieć, jak odpowiadać, może zacząć przesyłać strumieniowo kod HTML z powrotem do naszej aplikacji internetowej.
Warto przyjrzeć się bliżej 2 elementom tego obrazu: routingowi i szablonom.
Routing
W przypadku routingu zastosowałem natywną składnię routingu platformy Express. Jest wystarczająco elastyczny, aby dopasowywać proste prefiksy adresów URL, a także adresy URL, które zawierają parametry jako część ścieżki. W tym miejscu tworzę mapowanie między nazwami tras a wzorcem Express, z którym będą porównywane.
const routes = new Map([
['about', '/about'],
['questions', '/questions/:questionId'],
['index', '/'],
]);
export default routes;
Następnie mogę odwołać się do tego mapowania bezpośrednio z kodu serwera. Gdy wzorzec Express zostanie dopasowany, odpowiedni moduł obsługi odpowiada za pomocą logiki szablonu specyficznej dla pasującej ścieżki.
import routes from './lib/routes.mjs';
app.get(routes.get('index'), async (req, res) => {
// Templating logic.
});
Tworzenie szablonów po stronie serwera
Jak wygląda ta logika szablonów? Zastosowałem podejście, które polegało na łączeniu częściowych fragmentów HTML w sekwencji, jeden po drugim. Ten model dobrze sprawdza się w przypadku streamingu.
Serwer natychmiast odsyła początkowy kod HTML, a przeglądarka może od razu wyrenderować tę częściową stronę. Gdy serwer zbiera pozostałe źródła danych, przesyła je strumieniowo do przeglądarki, dopóki dokument nie zostanie ukończony.
Aby zobaczyć, o co mi chodzi, przyjrzyj się kodowi Express dla jednej z naszych tras:
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
Korzystając z metody write() obiektu response i odwołując się do częściowych szablonów przechowywanych lokalnie, mogę natychmiast rozpocząć strumieniowanie odpowiedzi bez blokowania żadnego zewnętrznego źródła danych. Przeglądarka pobiera początkowy kod HTML i od razu renderuje przydatny interfejs oraz wyświetla komunikat o wczytywaniu.
Kolejna część naszej strony korzysta z danych z interfejsu Stack Exchange API. Aby uzyskać te dane, nasz serwer musi wysłać żądanie sieciowe. Aplikacja internetowa nie może niczego renderować, dopóki nie otrzyma odpowiedzi i jej nie przetworzy, ale przynajmniej użytkownicy nie będą patrzeć na pusty ekran podczas oczekiwania.
Gdy aplikacja internetowa otrzyma odpowiedź z interfejsu Stack Exchange API, wywołuje niestandardową funkcję szablonu, aby przetłumaczyć dane z interfejsu API na odpowiedni kod HTML.
Język szablonów
Szablonowanie może być zaskakująco kontrowersyjnym tematem, a wybrane przeze mnie rozwiązanie to tylko jedno z wielu podejść. Warto zastąpić to rozwiązanie własnym, zwłaszcza jeśli masz powiązania ze starszymi wersjami istniejącego frameworka szablonów.
W moim przypadku najlepiej było po prostu użyć literałów szablonu JavaScriptu, a niektóre elementy logiki wydzielić do funkcji pomocniczych. Jedną z zalet tworzenia aplikacji MPA jest to, że nie musisz śledzić aktualizacji stanu i ponownie renderować kodu HTML, więc podstawowe podejście, które generowało statyczny kod HTML, sprawdziło się w moim przypadku.
Oto przykład szablonu dynamicznej części HTML indeksu mojej aplikacji internetowej. Podobnie jak w przypadku moich tras, logika szablonów jest przechowywana w module ES, który można zaimportować zarówno na serwerze, jak i w usłudze Service Worker.
export function index(tag, items) {
const title = `<h3>Top "${escape(tag)}" Questions</h3>`;
const form = `<form method="GET">...</form>`;
const questionCards = items
.map(item =>
questionCard({
id: item.question_id,
title: item.title,
})
)
.join('');
const questions = `<div id="questions">${questionCards}</div>`;
return title + form + questions;
}
Te funkcje szablonu to czysty JavaScript. W razie potrzeby warto podzielić logikę na mniejsze funkcje pomocnicze. Każdy element zwrócony w odpowiedzi interfejsu API przekazuję do jednej z takich funkcji, która tworzy standardowy element HTML ze wszystkimi odpowiednimi atrybutami.
function questionCard({id, title}) {
return `<a class="card"
href="/questions/${id}"
data-cache-url="${questionUrl(id)}">${title}</a>`;
}
Na szczególną uwagę zasługuje atrybut danych, który dodaję do każdego linku, data-cache-url, ustawiony na adres URL interfejsu Stack Exchange API, który jest mi potrzebny do wyświetlenia odpowiedniego pytania. Pamiętaj o tym. Wrócę do tego później.
Wracając do mojego obsługi trasy, po zakończeniu tworzenia szablonu przesyłam strumieniowo do przeglądarki ostatnią część kodu HTML strony i kończę strumień. Jest to sygnał dla przeglądarki, że progresywne renderowanie zostało zakończone.
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
To była krótka prezentacja konfiguracji mojego serwera. Użytkownicy, którzy odwiedzają moją aplikację internetową po raz pierwszy, zawsze otrzymują odpowiedź z serwera, ale gdy wracają do niej, zaczyna odpowiadać mój service worker. Zacznijmy od tego.
Skrypt service worker
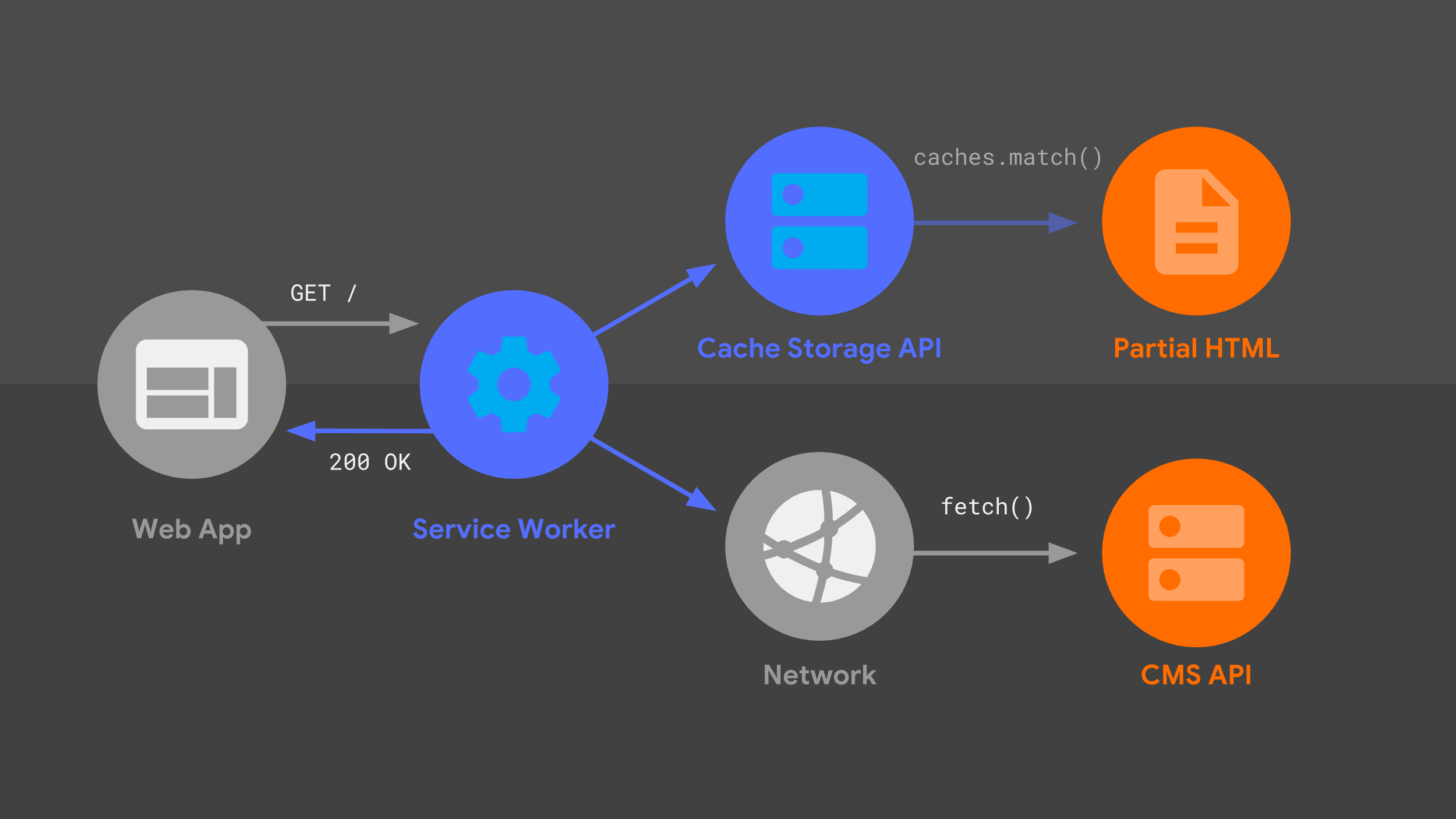
Ten diagram powinien być Ci znany – wiele z omawianych wcześniej elementów znajduje się tutaj w nieco innej konfiguracji. Przyjrzyjmy się przepływowi żądań z uwzględnieniem procesu roboczego usługi.
Nasz service worker obsługuje przychodzące żądanie nawigacji dla danego adresu URL i podobnie jak mój serwer używa kombinacji logiki routingu i szablonów, aby określić, jak odpowiedzieć.
Podejście jest takie samo jak wcześniej, ale z użyciem innych elementów niskiego poziomu, takich jak fetch() i interfejs Cache Storage API. Używam tych źródeł danych do tworzenia odpowiedzi HTML, którą service worker przekazuje z powrotem do aplikacji internetowej.
Workbox
Zamiast zaczynać od zera z użyciem elementów niskiego poziomu, zbuduję service worker na podstawie zestawu bibliotek wysokiego poziomu o nazwie Workbox. Stanowi solidną podstawę dla logiki buforowania, routingu i generowania odpowiedzi w przypadku każdego komponentu Service Worker.
Routing
Podobnie jak w przypadku kodu po stronie serwera, mój service worker musi wiedzieć, jak dopasować żądanie przychodzące do odpowiedniej logiki odpowiedzi.
Moje podejście polegało na przetłumaczeniu każdej trasy Express na odpowiednie wyrażenie regularne przy użyciu przydatnej biblioteki o nazwie regexparam. Po przetłumaczeniu mogę skorzystać z wbudowanej w Workbox obsługi routingu za pomocą wyrażeń regularnych.
Po zaimportowaniu modułu z wyrażeniami regularnymi rejestruję każde wyrażenie regularne w routerze Workbox. W ramach każdej trasy mogę podać niestandardową logikę szablonu, aby wygenerować odpowiedź. Tworzenie szablonów w usłudze Service Worker jest nieco bardziej skomplikowane niż na serwerze backendu, ale Workbox znacznie ułatwia to zadanie.
import regExpRoutes from './regexp-routes.mjs';
workbox.routing.registerRoute(
regExpRoutes.get('index')
// Templating logic.
);
Przechowywanie w pamięci podręcznej komponentów statycznych
Ważnym elementem szablonów jest zapewnienie, że moje częściowe szablony HTML są dostępne lokalnie za pomocą interfejsu Cache Storage API i są aktualizowane, gdy wdrażam zmiany w aplikacji internetowej. Ręczne utrzymywanie pamięci podręcznej może być podatne na błędy, dlatego korzystam z Workbox, aby w ramach procesu kompilacji obsługiwać wstępne buforowanie.
Wskazuję Workbox, które adresy URL mają być wstępnie buforowane, za pomocą pliku konfiguracyjnego, który wskazuje katalog zawierający wszystkie moje lokalne zasoby wraz z zestawem wzorców do dopasowania. Ten plik jest automatycznie odczytywany przez interfejs wiersza poleceń Workbox, który jest uruchamiany za każdym razem, gdy przebudowuję witrynę.
module.exports = {
globDirectory: 'build',
globPatterns: ['**/*.{html,js,svg}'],
// Other options...
};
Workbox tworzy migawkę zawartości każdego pliku i automatycznie wstawia listę adresów URL i wersji do końcowego pliku service worker. Workbox ma teraz wszystko, czego potrzebuje, aby wstępnie zapisane w pamięci podręcznej pliki były zawsze dostępne i aktualne. Wynikiem jest service-worker.jsplik zawierający informacje podobne do tych:
workbox.precaching.precacheAndRoute([
{
url: 'partials/about.html',
revision: '518747aad9d7e',
},
{
url: 'partials/foot.html',
revision: '69bf746a9ecc6',
},
// etc.
]);
Dla osób, które korzystają z bardziej złożonego procesu kompilacji, Workbox ma webpackwtyczkę i ogólny moduł węzła, a także interfejs wiersza poleceń.
Streaming
Następnie chcę, aby service worker natychmiast przesyłał strumieniowo do aplikacji internetowej wstępnie zapisany w pamięci podręcznej częściowy kod HTML. To kluczowy element „niezawodnej szybkości” – zawsze od razu widzę na ekranie coś przydatnego. Na szczęście dzięki użyciu interfejsu Streams API w naszym procesie roboczym usługi jest to możliwe.
Być może znasz już interfejs Streams API. Mój kolega Jake Archibald od lat zachwala to narzędzie. Wygłosił śmiałą prognozę, że rok 2016 będzie rokiem strumieni internetowych. Interfejs Streams API jest dziś tak samo świetny jak 2 lata temu, ale z jedną kluczową różnicą.
W tamtych czasach tylko Chrome obsługiwał strumienie, ale obecnie interfejs Streams API jest szerzej obsługiwany. Ogólnie rzecz biorąc, sytuacja jest dobra, a dzięki odpowiedniemu kodowi rezerwowemu nic nie stoi na przeszkodzie, aby już dziś używać strumieni w usłudze Service Worker.
Cóż… może być jedna rzecz, która Cię powstrzymuje, a mianowicie zrozumienie, jak działa interfejs Streams API. Udostępnia on bardzo zaawansowany zestaw elementów podstawowych, dzięki czemu deweloperzy, którzy potrafią z niego korzystać, mogą tworzyć złożone przepływy danych, takie jak:
const stream = new ReadableStream({
pull(controller) {
return sources[0]
.then(r => r.read())
.then(result => {
if (result.done) {
sources.shift();
if (sources.length === 0) return controller.close();
return this.pull(controller);
} else {
controller.enqueue(result.value);
}
});
},
});
Jednak zrozumienie pełnych konsekwencji tego kodu może nie być dla wszystkich. Zamiast analizować tę logikę, porozmawiajmy o moim podejściu do przesyłania strumieniowego w przypadku service workerów.
Używam zupełnie nowego kodu wysokiego poziomu,
workbox-streams.
Dzięki temu mogę przekazywać go w różnych źródłach strumieniowych, zarówno z pamięci podręcznych, jak i z danych środowiska wykonawczego, które mogą pochodzić z sieci. Workbox koordynuje poszczególne źródła i łączy je w jedną odpowiedź strumieniową.
Dodatkowo Workbox automatycznie wykrywa, czy interfejs Streams API jest obsługiwany, a jeśli nie, tworzy równoważną odpowiedź bez przesyłania strumieniowego. Oznacza to, że nie musisz się martwić pisaniem funkcji rezerwowych, ponieważ strumienie zbliżają się do 100% obsługi przez przeglądarki.
Buforowanie w środowisku wykonawczym
Sprawdźmy, jak mój service worker radzi sobie z danymi w czasie działania, korzystając z interfejsu API Stack Exchange. Korzystam z wbudowanej w Workbox obsługi strategii buforowania stale-while-revalidate oraz wygasania, aby mieć pewność, że pamięć aplikacji internetowej nie będzie się nieograniczenie powiększać.
W Workboxie skonfigurowałem 2 strategie do obsługi różnych źródeł, które będą składać się na odpowiedź przesyłaną strumieniowo. Dzięki kilku wywołaniom funkcji i konfiguracji Workbox pozwala nam wykonać zadania, które w inny sposób wymagałyby setek wierszy ręcznie napisanego kodu.
const cacheStrategy = workbox.strategies.cacheFirst({
cacheName: workbox.core.cacheNames.precache,
});
const apiStrategy = workbox.strategies.staleWhileRevalidate({
cacheName: API_CACHE_NAME,
plugins: [new workbox.expiration.Plugin({maxEntries: 50})],
});
Pierwsza strategia odczytuje dane, które zostały wstępnie zapisane w pamięci podręcznej, np. nasze częściowe szablony HTML.
Druga strategia implementuje logikę buforowania stale-while-revalidate, a także wygasanie pamięci podręcznej w przypadku najrzadziej używanych wpisów po osiągnięciu 50 wpisów.
Teraz, gdy mam już te strategie, muszę tylko powiedzieć Workboxowi, jak ich używać do tworzenia pełnej odpowiedzi strumieniowej. Przekazuję tablicę źródeł jako funkcje, a każda z tych funkcji zostanie wykonana natychmiast. Workbox pobiera wynik z każdego źródła i przesyła go strumieniowo do aplikacji internetowej w kolejności, opóźniając tylko wtedy, gdy następna funkcja w tablicy nie została jeszcze ukończona.
workbox.streams.strategy([
() => cacheStrategy.makeRequest({request: '/head.html'}),
() => cacheStrategy.makeRequest({request: '/navbar.html'}),
async ({event, url}) => {
const tag = url.searchParams.get('tag') || DEFAULT_TAG;
const listResponse = await apiStrategy.makeRequest(...);
const data = await listResponse.json();
return templates.index(tag, data.items);
},
() => cacheStrategy.makeRequest({request: '/foot.html'}),
]);
Pierwsze 2 źródła to wstępnie zapisane w pamięci podręcznej częściowe szablony odczytywane bezpośrednio z interfejsu Cache Storage API, więc są one zawsze dostępne od razu. Dzięki temu implementacja service workera będzie niezawodnie szybko odpowiadać na żądania, tak samo jak kod po stronie serwera.
Nasza kolejna funkcja źródłowa pobiera dane z interfejsu Stack Exchange API i przetwarza odpowiedź na kod HTML, którego oczekuje aplikacja internetowa.
Strategia „nieaktualne podczas ponownej weryfikacji” oznacza, że jeśli mam wcześniej zapisany w pamięci podręcznej odpowiedź na to wywołanie interfejsu API, mogę natychmiast przesłać ją strumieniowo na stronę, a jednocześnie zaktualizować wpis w pamięci podręcznej „w tle” na wypadek, gdyby został ponownie wywołany.
Na koniec przesyłam strumieniowo kopię stopki z pamięci podręcznej i zamykam ostatnie tagi HTML, aby zakończyć odpowiedź.
Kod udostępniania zapewnia synchronizację
Zauważysz, że niektóre fragmenty kodu service workera wyglądają znajomo. Częściowy kod HTML i logika szablonów używane przez mój service worker są identyczne z tymi, których używa mój moduł obsługi po stronie serwera. Dzięki temu udostępnianiu kodu użytkownicy mają spójne wrażenia niezależnie od tego, czy odwiedzają moją aplikację internetową po raz pierwszy, czy wracają na stronę renderowaną przez service worker. To właśnie zaleta izomorficznego JavaScriptu.
Dynamiczne, progresywne ulepszenia
Omówiłem już serwer i service worker w przypadku mojej progresywnej aplikacji internetowej, ale pozostał jeszcze jeden element logiki: na każdej stronie po pełnym przesłaniu strumieniowym działa niewielka ilość kodu JavaScript.
Ten kod stopniowo poprawia komfort użytkowania, ale nie jest kluczowy – aplikacja internetowa będzie działać nawet wtedy, gdy nie zostanie uruchomiony.
Metadane strony
Moja aplikacja używa JavaScriptu po stronie klienta do aktualizowania metadanych strony na podstawie odpowiedzi interfejsu API. Ponieważ używam tego samego początkowego fragmentu HTML z pamięci podręcznej na każdej stronie, aplikacja internetowa umieszcza w nagłówku dokumentu ogólne tagi. Dzięki koordynacji między szablonem a kodem po stronie klienta mogę jednak aktualizować tytuł okna za pomocą metadanych konkretnej strony.
W ramach kodu szablonu umieszczam tag skryptu zawierający prawidłowo zmieniony ciąg znaków.
const metadataScript = `<script>
self._title = '${escape(item.title)}';
</script>`;
Gdy strona się załaduje, odczytuję ten ciąg znaków i aktualizuję tytuł dokumentu.
if (self._title) {
document.title = unescape(self._title);
}
Jeśli chcesz zaktualizować w swojej aplikacji internetowej inne metadane dotyczące strony, możesz zastosować to samo podejście.
Wrażenia użytkownika w trybie offline
Kolejne ulepszenie progresywne, które dodałem, ma na celu zwrócenie uwagi na nasze funkcje offline. Mam niezawodną aplikację PWA i chcę, aby użytkownicy wiedzieli, że w trybie offline mogą nadal wczytywać wcześniej odwiedzone strony.
Najpierw używam interfejsu Cache Storage API, aby uzyskać listę wszystkich wcześniej zapisanych w pamięci podręcznej żądań API, i przekształcam ją w listę adresów URL.
Pamiętasz te specjalne atrybuty danych, o których mówiłem? Każdy z nich zawiera adres URL żądania interfejsu API potrzebnego do wyświetlenia pytania. Mogę porównać te atrybuty danych z listą adresów URL w pamięci podręcznej i utworzyć tablicę wszystkich linków do pytań, które nie pasują.
Gdy przeglądarka przejdzie w tryb offline, przechodzę w pętli przez listę linków bez pamięci podręcznej i przyciemniam te, które nie będą działać. Pamiętaj, że jest to tylko wizualna wskazówka dla użytkownika, czego może się spodziewać na tych stronach. Nie wyłączam linków ani nie uniemożliwiam użytkownikowi nawigacji.
const apiCache = await caches.open(API_CACHE_NAME);
const cachedRequests = await apiCache.keys();
const cachedUrls = cachedRequests.map(request => request.url);
const cards = document.querySelectorAll('.card');
const uncachedCards = [...cards].filter(card => {
return !cachedUrls.includes(card.dataset.cacheUrl);
});
const offlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '0.3';
}
};
const onlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '1.0';
}
};
window.addEventListener('online', onlineHandler);
window.addEventListener('offline', offlineHandler);
Typowe problemy
Przedstawiłem Ci już moje podejście do tworzenia wielostronicowej progresywnej aplikacji internetowej. Przy opracowywaniu własnego podejścia musisz wziąć pod uwagę wiele czynników i możesz podjąć inne decyzje niż ja. Ta elastyczność to jedna z największych zalet tworzenia aplikacji internetowych.
Podczas podejmowania własnych decyzji architektonicznych możesz napotkać kilka typowych pułapek. Chcę Cię przed nimi uchronić.
Nie buforuj pełnego kodu HTML
Nie zalecam przechowywania w pamięci podręcznej pełnych dokumentów HTML. Po pierwsze, to marnowanie miejsca. Jeśli Twoja aplikacja internetowa używa tej samej podstawowej struktury HTML dla każdej ze swoich stron, będziesz wielokrotnie przechowywać kopie tego samego kodu.
Co ważniejsze, jeśli wdrożysz zmianę w udostępnionej strukturze HTML witryny, każda z tych wcześniej zapisanych w pamięci podręcznej stron nadal będzie miała stary układ. Wyobraź sobie frustrację powracającego użytkownika, który widzi mieszankę starych i nowych stron.
Odchylenie serwera lub service workera
Kolejnym problemem, którego należy unikać, jest rozsynchronizowanie serwera i procesu roboczego usługi. Moje podejście polegało na użyciu izomorficznego JavaScriptu, dzięki czemu ten sam kod był uruchamiany w obu miejscach. W zależności od istniejącej architektury serwera nie zawsze jest to możliwe.
Niezależnie od podjętych decyzji dotyczących architektury musisz mieć strategię uruchamiania równoważnego kodu routingu i szablonów na serwerze i w usłudze Service Worker.
Scenariusze najgorszego przypadku
Niespójny układ lub projekt
Co się stanie, jeśli zignorujesz te pułapki? Możliwe są różne rodzaje awarii, ale najgorszy scenariusz to sytuacja, w której powracający użytkownik odwiedza stronę z pamięci podręcznej o bardzo przestarzałym układzie – być może z nieaktualnym tekstem nagłówka lub z nazwami klas CSS, które nie są już prawidłowe.
Najgorszy scenariusz: uszkodzony routing
Użytkownik może też natrafić na adres URL obsługiwany przez serwer, ale nie przez service worker. Witryna pełna nieużywanych układów i ślepych zaułków nie jest wiarygodną progresywną aplikacją internetową.
Wskazówki zapewniające sukces
Ale nie musisz tego robić sam. Te wskazówki pomogą Ci uniknąć tych pułapek:
Korzystaj z bibliotek szablonów i routingu, które mają implementacje w wielu językach
Staraj się używać bibliotek szablonów i routingu, które mają implementacje w JavaScript. Wiem, że nie każdy deweloper może sobie pozwolić na migrację z obecnego serwera internetowego i języka szablonów.
Jednak wiele popularnych frameworków do tworzenia szablonów i routingu ma implementacje w wielu językach. Jeśli znajdziesz taką, która działa zarówno z JavaScriptem, jak i z językiem obecnego serwera, będziesz o krok bliżej do synchronizacji serwera i procesu roboczego usługi.
Preferuj szablony sekwencyjne zamiast zagnieżdżonych
Następnie zalecam użycie serii kolejnych szablonów, które można przesyłać strumieniowo jeden po drugim. Nie ma problemu, jeśli dalsze części strony korzystają z bardziej skomplikowanej logiki szablonów, o ile początkową część kodu HTML można przesyłać strumieniowo tak szybko, jak to możliwe.
Przechowywanie w pamięci podręcznej skryptu service worker zarówno treści statycznych, jak i dynamicznych
Aby uzyskać jak najlepszą wydajność, wstępnie zapisz w pamięci podręcznej wszystkie najważniejsze statyczne zasoby witryny. Warto też skonfigurować logikę buforowania w czasie działania, aby obsługiwać treści dynamiczne, takie jak żądania interfejsu API. Korzystanie z Workbox oznacza, że możesz budować na sprawdzonych i gotowych do wdrożenia strategiach, zamiast implementować wszystko od zera.
Blokuj w sieci tylko wtedy, gdy jest to bezwzględnie konieczne
W związku z tym blokuj sieć tylko wtedy, gdy nie można przesyłać strumieniowo odpowiedzi z pamięci podręcznej. Wyświetlanie buforowanej odpowiedzi interfejsu API od razu może często zapewnić lepsze wrażenia użytkownikom niż czekanie na nowe dane.