


Lors du Chrome Dev Summit 2020, nous avons présenté pour la première fois la prise en charge du débogage par Chrome pour les applications WebAssembly sur le Web. Depuis, l'équipe a consacré beaucoup d'efforts à adapter l'expérience des développeurs aux applications volumineuses, voire très volumineuses. Dans cet article, nous allons vous présenter les boutons que nous avons ajoutés (ou activés) dans les différents outils, et vous expliquer comment les utiliser.
Débogage évolutif
Reprenons là où nous en étions dans notre post de 2020. Voici l'exemple que nous examinions à l'époque:
#include <SDL2/SDL.h>
#include <complex>
int main() {
// Init SDL.
int width = 600, height = 600;
SDL_Init(SDL_INIT_VIDEO);
SDL_Window* window;
SDL_Renderer* renderer;
SDL_CreateWindowAndRenderer(width, height, SDL_WINDOW_OPENGL, &window,
&renderer);
// Generate a palette with random colors.
enum { MAX_ITER_COUNT = 256 };
SDL_Color palette[MAX_ITER_COUNT];
srand(time(0));
for (int i = 0; i < MAX_ITER_COUNT; ++i) {
palette[i] = {
.r = (uint8_t)rand(),
.g = (uint8_t)rand(),
.b = (uint8_t)rand(),
.a = 255,
};
}
// Calculate and draw the Mandelbrot set.
std::complex<double> center(0.5, 0.5);
double scale = 4.0;
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
std::complex<double> point((double)x / width, (double)y / height);
std::complex<double> c = (point - center) * scale;
std::complex<double> z(0, 0);
int i = 0;
for (; i < MAX_ITER_COUNT - 1; i++) {
z = z * z + c;
if (abs(z) > 2.0)
break;
}
SDL_Color color = palette[i];
SDL_SetRenderDrawColor(renderer, color.r, color.g, color.b, color.a);
SDL_RenderDrawPoint(renderer, x, y);
}
}
// Render everything we've drawn to the canvas.
SDL_RenderPresent(renderer);
// SDL_Quit();
}
Il s'agit d'un exemple assez petit. Vous ne verrez probablement aucun des problèmes réels que vous pourriez rencontrer dans une application très volumineuse, mais nous pouvons tout de même vous montrer les nouvelles fonctionnalités. Il est rapide et facile à configurer et à essayer !
Dans le dernier article, nous avons vu comment compiler et déboguer cet exemple. Réessayons, mais examinons également //performance//:
$ emcc -sUSE_SDL=2 -g -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH
Cette commande produit un binaire wasm de 3 Mo. La majeure partie de ces informations sont des informations de débogage. Pour ce faire, vous pouvez utiliser l'outil llvm-objdump [1], par exemple:
$ llvm-objdump -h mandelbrot.wasm
mandelbrot.wasm: file format wasm
Sections:
Idx Name Size VMA Type
0 TYPE 0000026f 00000000
1 IMPORT 00001f03 00000000
2 FUNCTION 0000043e 00000000
3 TABLE 00000007 00000000
4 MEMORY 00000007 00000000
5 GLOBAL 00000021 00000000
6 EXPORT 0000014a 00000000
7 ELEM 00000457 00000000
8 CODE 0009308a 00000000 TEXT
9 DATA 0000e4cc 00000000 DATA
10 name 00007e58 00000000
11 .debug_info 000bb1c9 00000000
12 .debug_loc 0009b407 00000000
13 .debug_ranges 0000ad90 00000000
14 .debug_abbrev 000136e8 00000000
15 .debug_line 000bb3ab 00000000
16 .debug_str 000209bd 00000000
Cette sortie affiche toutes les sections du fichier wasm généré. La plupart d'entre elles sont des sections WebAssembly standards, mais il existe également plusieurs sections personnalisées dont le nom commence par .debug_. C'est là que le binaire contient nos informations de débogage. Si nous additionnons toutes les tailles, nous constatons que les informations de débogage représentent environ 2,3 Mo de notre fichier de 3 Mo. Si nous time également la commande emcc, nous constatons que son exécution a pris environ 1,5 s sur notre machine. Ces chiffres constituent une bonne référence, mais ils sont si faibles que personne ne les remarquera probablement. Dans les applications réelles, cependant, le binaire de débogage peut facilement atteindre une taille de plusieurs gigaoctets et prendre plusieurs minutes à compiler.
Ignorer Binaryen
Lorsque vous créez une application wasm avec Emscripten, l'une des dernières étapes de compilation consiste à exécuter l'optimiseur Binaryen. Binaryen est un kit d'outils de compilation qui optimise et légalise les binaires WebAssembly. L'exécution de Binaryen dans le cadre de la compilation est assez coûteuse, mais elle n'est requise que dans certaines conditions. Pour les builds de débogage, nous pouvons accélérer considérablement le temps de compilation si nous évitons les passes Binaryen. L'étape Binaryen la plus courante est destinée à légaliser les signatures de fonction impliquant des valeurs d'entier 64 bits. En activant l'intégration de BigInt WebAssembly à l'aide de -sWASM_BIGINT, nous pouvons éviter cela.
$ emcc -sUSE_SDL=2 -g -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Nous avons ajouté l'indicateur -sERROR_ON_WASM_CHANGES_AFTER_LINK pour faire bonne mesure. Il permet de détecter quand Binaryen s'exécute et réécrit le binaire de manière inattendue. Nous pouvons ainsi nous assurer de rester sur la bonne voie.
Même si notre exemple est assez petit, nous pouvons toujours voir l'effet de l'élagage de Binaryen. Selon time, cette commande s'exécute en un peu moins d'une seconde, soit une demi-seconde plus vite qu'auparavant.
Réglages avancés
Ignorer l'analyse des fichiers d'entrée
Normalement, lors de l'association d'un projet Emscripten, emcc analyse tous les fichiers et bibliothèques d'objets d'entrée. Il le fait afin d'implémenter des dépendances précises entre les fonctions de la bibliothèque JavaScript et les symboles natifs de votre programme. Pour les projets plus importants, cette analyse supplémentaire des fichiers d'entrée (à l'aide de llvm-nm) peut augmenter considérablement le temps d'association.
Vous pouvez exécuter avec -sREVERSE_DEPS=all, ce qui indique à emcc d'inclure toutes les dépendances natives possibles des fonctions JavaScript. Cela entraîne un léger surcoût de taille de code, mais peut accélérer les temps d'association et être utile pour les builds de débogage.
Pour un projet aussi petit que notre exemple, cela n'a aucune incidence, mais si votre projet contient des centaines, voire des milliers de fichiers d'objets, cela peut améliorer de manière significative les temps d'association.
Suppression de la section "name"
Dans les grands projets, en particulier ceux qui utilisent beaucoup de modèles C++, la section "name" du WebAssembly peut être très volumineuse. Dans notre exemple, il ne s'agit que d'une infime partie de la taille totale du fichier (voir la sortie de llvm-objdump ci-dessus), mais dans certains cas, il peut être très important. Si la section "name" de votre application est très volumineuse et que les informations de débogage de dwarf sont suffisantes pour vos besoins de débogage, il peut être avantageux de supprimer la section "name" :
$ emstrip --no-strip-all --remove-section=name mandelbrot.wasm
La section "name" du WebAssembly sera supprimée, mais les sections de débogage DWARF seront conservées.
Déboguer la fission
Les binaires contenant de nombreuses données de débogage ne mettent pas seulement à rude épreuve le temps de compilation, mais aussi le temps de débogage. Le débogueur doit charger les données et créer un indice pour elles afin de pouvoir répondre rapidement aux requêtes, par exemple "Quel est le type de la variable locale x ?".
La fission de débogage permet de diviser les informations de débogage d'un binaire en deux parties: l'une qui reste dans le binaire et l'autre qui est contenue dans un fichier d'objet DWARF (.dwo) distinct. Vous pouvez l'activer en transmettant l'indicateur -gsplit-dwarf à Emscripten:
$ emcc -sUSE_SDL=2 -g -gsplit-dwarf -gdwarf-5 -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Vous trouverez ci-dessous les différentes commandes et les fichiers générés par la compilation sans données de débogage, avec des données de débogage et enfin avec des données de débogage et une fission de débogage.
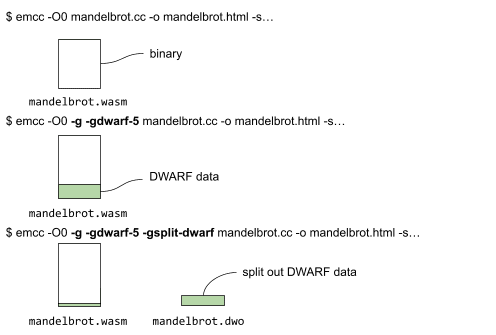
Lors du fractionnement des données DWARF, une partie des données de débogage réside avec le binaire, tandis que la majeure partie est placée dans le fichier mandelbrot.dwo (comme illustré ci-dessus).
Pour mandelbrot, nous n'avons qu'un seul fichier source, mais les projets sont généralement plus volumineux et incluent plusieurs fichiers. La fission de débogage génère un fichier .dwo pour chacun d'eux. Pour que la version bêta actuelle du débogueur (0.1.6.1615) puisse charger ces informations de débogage fractionnées, nous devons les regrouper dans un package DWARF (.dwp) comme suit:
$ emdwp -e mandelbrot.wasm -o mandelbrot.dwp
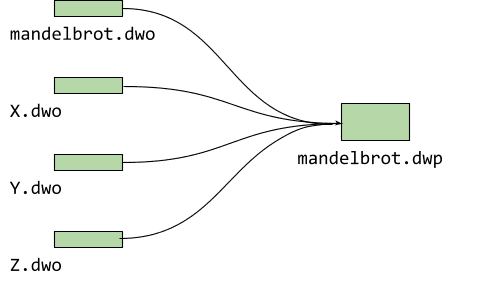
L'avantage de créer le package DWARF à partir des objets individuels est que vous n'avez besoin de diffuser qu'un seul fichier supplémentaire. Nous mettons actuellement tout en œuvre pour charger tous les objets individuels dans une prochaine version.
Qu'est-ce que DWARF 5 ?
Vous avez peut-être remarqué que nous avons ajouté une autre option à la commande emcc ci-dessus, -gdwarf-5. L'activation de la version 5 des symboles DWARF, qui n'est actuellement pas la valeur par défaut, est un autre moyen de démarrer le débogage plus rapidement. Grâce à elle, certaines informations sont stockées dans le binaire principal que la version 4 par défaut a laissées de côté. Plus précisément, nous pouvons déterminer l'ensemble complet des fichiers sources à partir du binaire principal. Cela permet au débogueur d'effectuer des actions de base telles que l'affichage de l'arborescence source complète et la définition de points d'arrêt sans charger et analyser l'intégralité des données de symbole. Le débogage avec des symboles de fractionnement est ainsi beaucoup plus rapide. Nous utilisons donc toujours les options de ligne de commande -gsplit-dwarf et -gdwarf-5 ensemble.
Le format de débogage DWARF5 nous permet également d'accéder à une autre fonctionnalité utile. Il introduit un index de nom dans les données de débogage qui seront générées lors de la transmission du flag -gpubnames:
$ emcc -sUSE_SDL=2 -g -gdwarf-5 -gsplit-dwarf -gpubnames -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Lors d'une session de débogage, les recherches de symboles se font souvent en recherchant une entité par nom, par exemple lorsque vous recherchez une variable ou un type. L'index de noms accélère cette recherche en pointant directement vers l'unité de compilation qui définit ce nom. Sans index de noms, une recherche exhaustive de l'ensemble des données de débogage serait nécessaire pour trouver l'unité de compilation appropriée qui définit l'entité nommée recherchée.
Pour les curieux: examiner les données de débogage
Vous pouvez utiliser llvm-dwarfdump pour consulter les données DWARF. Essayons:
llvm-dwarfdump mandelbrot.wasm
Cela nous donne un aperçu des "unités de compilation" (en gros, les fichiers sources) pour lesquelles nous disposons d'informations de débogage. Dans cet exemple, nous n'avons que les informations de débogage pour mandelbrot.cc. Les informations générales nous indiquent que nous disposons d'une unité squelette, ce qui signifie simplement que les données de ce fichier sont incomplètes et qu'un fichier .dwo distinct contient les informations de débogage restantes:

Vous pouvez également consulter d'autres tableaux de ce fichier, par exemple le tableau des lignes qui montre le mappage du bytecode wasm sur les lignes C++ (essayez d'utiliser llvm-dwarfdump -debug-line).
Nous pouvons également consulter les informations de débogage contenues dans le fichier .dwo distinct:
llvm-dwarfdump mandelbrot.dwo

Résumé: Quel est l'avantage d'utiliser la fission de débogage ?
La division des informations de débogage présente plusieurs avantages si vous travaillez avec de grandes applications:
Liaison plus rapide: le lisseur n'a plus besoin d'analyser l'intégralité des informations de débogage. Les outils de liaison doivent généralement analyser l'ensemble des données DWARF contenues dans le binaire. En extrayant de grandes parties des informations de débogage dans des fichiers distincts, les éditeurs de liens traitent des binaires plus petits, ce qui accélère les temps d'association (en particulier pour les applications volumineuses).
Débogage plus rapide: le débogueur peut ignorer l'analyse des symboles supplémentaires dans les fichiers
.dwo/.dwppour certaines recherches de symboles. Pour certaines recherches (telles que les requêtes sur le mappage des lignes des fichiers wasm-to-C++), nous n'avons pas besoin d'examiner les données de débogage supplémentaires. Cela nous fait gagner du temps, car nous n'avons pas besoin de charger et d'analyser les données de débogage supplémentaires.
1: Si vous ne disposez pas d'une version récente de llvm-objdump sur votre système et que vous utilisez emsdk, vous pouvez le trouver dans le répertoire emsdk/upstream/bin.
Télécharger les canaux de prévisualisation
Envisagez d'utiliser Chrome Canary, Dev ou Bêta comme navigateur de développement par défaut. Ces canaux de prévisualisation vous donnent accès aux dernières fonctionnalités de DevTools, vous permettent de tester les API de plate-forme Web de pointe et vous aident à détecter les problèmes sur votre site avant vos utilisateurs.
Contacter l'équipe des outils pour les développeurs Chrome
Utilisez les options suivantes pour discuter des nouvelles fonctionnalités, des mises à jour ou de tout autre élément lié aux outils pour les développeurs.
- Envoyez-nous vos commentaires et vos demandes de fonctionnalités sur crbug.com.
- Signalez un problème dans les outils de développement à l'aide de l'icône Plus d'options > Aide > Signaler un problème dans les outils de développement dans les outils de développement.
- Envoyez un tweet à @ChromeDevTools.
- Laissez des commentaires sur les vidéos YouTube sur les nouveautés des outils pour les développeurs ou sur les vidéos YouTube sur les conseils concernant les outils pour les développeurs.