


Al Chrome Dev Summit 2020, abbiamo mostrato per la prima volta sul web il supporto di Chrome per il debug delle applicazioni WebAssembly. Da allora, il team ha investito molte energie per far sì che l'esperienza dello sviluppatore sia scalabile per applicazioni di grandi dimensioni e anche molto grandi. In questo post ti mostreremo i controlli che abbiamo aggiunto (o reso disponibili) nei diversi strumenti e come utilizzarli.
Debug scalabile
Riprendiamo da dove abbiamo interrotto nel nostro post del 2020. Ecco l'esempio che stavamo esaminando all'epoca:
#include <SDL2/SDL.h>
#include <complex>
int main() {
// Init SDL.
int width = 600, height = 600;
SDL_Init(SDL_INIT_VIDEO);
SDL_Window* window;
SDL_Renderer* renderer;
SDL_CreateWindowAndRenderer(width, height, SDL_WINDOW_OPENGL, &window,
&renderer);
// Generate a palette with random colors.
enum { MAX_ITER_COUNT = 256 };
SDL_Color palette[MAX_ITER_COUNT];
srand(time(0));
for (int i = 0; i < MAX_ITER_COUNT; ++i) {
palette[i] = {
.r = (uint8_t)rand(),
.g = (uint8_t)rand(),
.b = (uint8_t)rand(),
.a = 255,
};
}
// Calculate and draw the Mandelbrot set.
std::complex<double> center(0.5, 0.5);
double scale = 4.0;
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
std::complex<double> point((double)x / width, (double)y / height);
std::complex<double> c = (point - center) * scale;
std::complex<double> z(0, 0);
int i = 0;
for (; i < MAX_ITER_COUNT - 1; i++) {
z = z * z + c;
if (abs(z) > 2.0)
break;
}
SDL_Color color = palette[i];
SDL_SetRenderDrawColor(renderer, color.r, color.g, color.b, color.a);
SDL_RenderDrawPoint(renderer, x, y);
}
}
// Render everything we've drawn to the canvas.
SDL_RenderPresent(renderer);
// SDL_Quit();
}
Si tratta ancora di un esempio abbastanza piccolo e probabilmente non riscontrerai i problemi reali che potresti riscontrare in un'applicazione di grandi dimensioni, ma possiamo comunque mostrarti quali sono le nuove funzionalità. È facile e veloce da configurare e provare.
Nell'ultimo post abbiamo discusso di come compilare e eseguire il debug di questo esempio. Ripetiamo l'operazione, ma diamo un'occhiata anche a //performance//:
$ emcc -sUSE_SDL=2 -g -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH
Questo comando produce un file binario wasm di 3 MB. La maggior parte, come è facile immaginare, è costituita da informazioni di debug. Puoi verificarlo con lo strumento llvm-objdump [1], ad esempio:
$ llvm-objdump -h mandelbrot.wasm
mandelbrot.wasm: file format wasm
Sections:
Idx Name Size VMA Type
0 TYPE 0000026f 00000000
1 IMPORT 00001f03 00000000
2 FUNCTION 0000043e 00000000
3 TABLE 00000007 00000000
4 MEMORY 00000007 00000000
5 GLOBAL 00000021 00000000
6 EXPORT 0000014a 00000000
7 ELEM 00000457 00000000
8 CODE 0009308a 00000000 TEXT
9 DATA 0000e4cc 00000000 DATA
10 name 00007e58 00000000
11 .debug_info 000bb1c9 00000000
12 .debug_loc 0009b407 00000000
13 .debug_ranges 0000ad90 00000000
14 .debug_abbrev 000136e8 00000000
15 .debug_line 000bb3ab 00000000
16 .debug_str 000209bd 00000000
Questo output mostra tutte le sezioni del file wasm generato, la maggior parte delle quali sono sezioni WebAssembly standard, ma sono presenti anche diverse sezioni personalizzate il cui nome inizia con .debug_. È qui che il file binario contiene le nostre informazioni di debug. Se sommiamo tutte le dimensioni, vediamo che le informazioni di debug occupano circa 2,3 MB del nostro file di 3 MB. Se time anche il comando emcc, vediamo che sulla nostra macchina l'esecuzione ha richiesto circa 1,5 secondi. Questi numeri costituiscono una buona base di riferimento, ma sono così piccoli che probabilmente nessuno ci farebbe caso. Nelle applicazioni reali, però, il file binario di debug può raggiungere facilmente una dimensione in GB e richiedere minuti per la compilazione.
Ignora Binaryen
Quando crei un'applicazione wasm con Emscripten, uno dei passaggi finali della compilazione è l'esecuzione dell'ottimizzatore Binaryen. Binaryen è un toolkit del compilatore che ottimizza e legalizza i binari WebAssembly(-like). L'esecuzione di Binaryen nell'ambito della compilazione è piuttosto costosa, ma è obbligatoria solo in determinate condizioni. Per le build di debug, possiamo velocizzare notevolmente il tempo di compilazione se evitiamo la necessità di passaggi Binaryen. Il passaggio Binaryen più comune richiesto è per la legalizzazione delle firme delle funzioni che coinvolgono valori interi a 64 bit. Attivando l'integrazione di BigInt di WebAssembly utilizzando -sWASM_BIGINT possiamo evitarlo.
$ emcc -sUSE_SDL=2 -g -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Abbiamo aggiunto il flag -sERROR_ON_WASM_CHANGES_AFTER_LINK per sicurezza. Consente di rilevare quando Binaryen è in esecuzione e riscrivere il file binario in modo imprevisto. In questo modo, possiamo assicurarci di seguire la strada più rapida.
Anche se il nostro esempio è piuttosto piccolo, possiamo comunque vedere l'effetto dell'omissione di Binaryen. Secondo time, questo comando viene eseguito in poco meno di 1 secondo, quindi mezzo secondo più velocemente di prima.
Modifiche avanzate
Ignorare la scansione dei file di input
Normalmente, quando esegui il linking di un progetto Emscripten, emcc esegue la scansione di tutte le librerie e i file oggetto di input. Lo fa per implementare dipendenze precise tra le funzioni della libreria JavaScript e i simboli nativi nel programma. Per i progetti più grandi, questa scansione aggiuntiva dei file di input (utilizzando llvm-nm) può aumentare notevolmente il tempo di collegamento.
È possibile eseguire il codice con -sREVERSE_DEPS=all, che indica a emcc di includere tutte le possibili dipendenze native delle funzioni JavaScript. Ha un piccolo overhead per le dimensioni del codice, ma può velocizzare i tempi di collegamento ed essere utile per le build di debug.
Per un progetto piccolo come il nostro esempio, non fa alcuna differenza, ma se il progetto contiene centinaia o addirittura migliaia di file oggetto, può migliorare in modo significativo i tempi di collegamento.
Rimuovere la sezione "name"
Nei progetti di grandi dimensioni, in particolare quelli che utilizzano molto i modelli C++, la sezione "name" di WebAssembly può essere molto grande. Nel nostro esempio, si tratta solo di una piccola parte delle dimensioni complessive del file (vedi l'output di llvm-objdump sopra), ma in alcuni casi può essere molto significativa. Se la sezione "name" della tua applicazione è molto grande e le informazioni di debug in DWARF sono sufficienti per le tue esigenze di debug, può essere vantaggioso rimuovere la sezione "name":
$ emstrip --no-strip-all --remove-section=name mandelbrot.wasm
In questo modo, la sezione "name" di WebAssembly verrà rimossa, mantenendo al contempo le sezioni di debug DWARF.
Eseguire il debug della scissione
I file binari con molti dati di debug non solo influiscono sul tempo di compilazione, ma anche sul tempo di debug. Il debugger deve caricare i dati e creare un indice per poter rispondere rapidamente alle query, ad esempio "Qual è il tipo della variabile locale x?".
La fissione del debug ci consente di suddividere le informazioni di debug per un file binario in due parti: una che rimane nel file binario e una contenuta in un file separato, chiamato oggetto DWARF (.dwo). Può essere attivato passando il flag -gsplit-dwarf a Emscripten:
$ emcc -sUSE_SDL=2 -g -gsplit-dwarf -gdwarf-5 -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Di seguito sono riportati i diversi comandi e i file generati dalla compilazione senza dati di debug, con dati di debug e infine con dati di debug e fissione di debug.
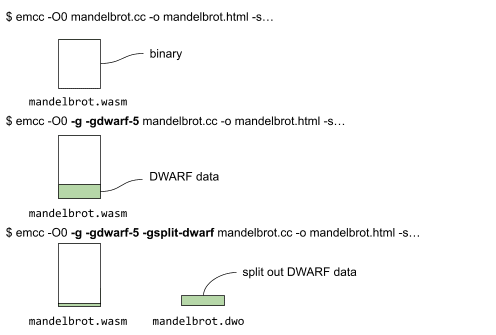
Quando dividi i dati DWARF, una parte dei dati di debug risiede insieme al file binario, mentre la parte più grande viene inserita nel file mandelbrot.dwo (come illustrato sopra).
Per mandelbrot abbiamo un solo file di origine, ma in genere i progetti sono più grandi e includono più di un file. La fissione di debug genera un file .dwo per ogni processo. Affinché l'attuale versione beta del debugger (0.1.6.1615) possa caricare queste informazioni di debug suddivise, dobbiamo raggrupparle tutte in un cosiddetto pacchetto DWARF (.dwp) come questo:
$ emdwp -e mandelbrot.wasm -o mandelbrot.dwp
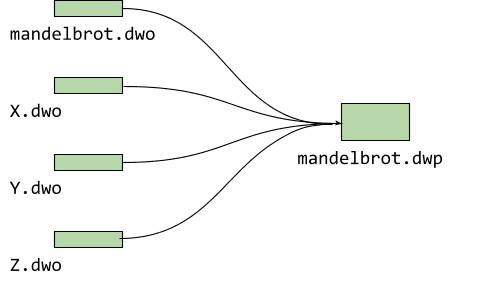
La creazione del pacchetto DWARF dai singoli oggetti ha il vantaggio di dover pubblicare un solo file aggiuntivo. Stiamo lavorando per caricare anche tutti i singoli oggetti in una release futura.
Che cos'è DWARF 5?
Probabilmente avrai notato che abbiamo inserito un altro flag nel comando emcc riportato sopra, -gdwarf-5. L'attivazione della versione 5 dei simboli DWARF, che al momento non è predefinita, è un altro trucco che ci aiuta ad avviare il debug più velocemente. Con questo, alcune informazioni vengono memorizzate nel file binario principale che la versione 4 predefinita non includeva. Nello specifico, possiamo determinare l'insieme completo dei file di origine solo dal file binario principale. In questo modo, il debugger può eseguire azioni di base come mostrare l'albero di origine completo e impostare i breakpoint senza caricare e analizzare i dati completi dei simboli. In questo modo, il debug con i simboli suddivisi è molto più veloce, quindi utilizziamo sempre insieme i flag della riga di comando -gsplit-dwarf e -gdwarf-5.
Con il formato di debug DWARF5 abbiamo anche accesso a un'altra funzionalità utile. Introduce un indice dei nomi nei dati di debug che verranno generati quando viene passato il flag -gpubnames:
$ emcc -sUSE_SDL=2 -g -gdwarf-5 -gsplit-dwarf -gpubnames -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Durante una sessione di debug, le ricerche di simboli avvengono spesso cercando un'entità per nome, ad esempio quando si cerca una variabile o un tipo. L'indice dei nomi accelera questa ricerca facendo riferimento direttamente all'unità di compilazione che definisce il nome. Senza un indice dei nomi, sarebbe necessaria una ricerca esaustiva dell'intero set di dati di debug per trovare l'unità di compilazione corretta che definisce l'entità denominata che stiamo cercando.
Per i curiosi: esaminare i dati di debug
Puoi utilizzare llvm-dwarfdump per dare un'occhiata ai dati DWARF. Proviamo:
llvm-dwarfdump mandelbrot.wasm
Questo ci fornisce una panoramica delle "Unità di compilazione" (grosso modo, i file di origine) per le quali abbiamo informazioni di debug. In questo esempio, abbiamo solo le informazioni di debug per mandelbrot.cc. Le informazioni generali ci comunicano che abbiamo un'unità scheletro, il che significa semplicemente che abbiamo dati incompleti su questo file e che esiste un file .dwo separato contenente le restanti informazioni di debug:

Puoi dare un'occhiata anche ad altre tabelle all'interno di questo file, ad esempio alla tabella delle righe che mostra la mappatura del bytecode wasm alle righe C++ (prova a utilizzare llvm-dwarfdump -debug-line).
Possiamo anche dare un'occhiata alle informazioni di debug contenute nel file .dwo separato:
llvm-dwarfdump mandelbrot.dwo

TL;DR: qual è il vantaggio dell'utilizzo della fissione per il debug?
La suddivisione delle informazioni di debug offre diversi vantaggi se si lavora con applicazioni di grandi dimensioni:
Collegamento più rapido: il linker non deve più analizzare l'intera informazione di debug. In genere, i linker devono analizzare l'intero set di dati DWARF presente nel file binario. Separando parti significative delle informazioni di debug in file distinti, i linker gestiscono file binari più piccoli, il che si traduce in tempi di collegamento più rapidi (in particolare per le applicazioni di grandi dimensioni).
Debug più rapido: il debugger può saltare l'analisi dei simboli aggiuntivi nei file
.dwo/.dwpper alcune ricerche di simboli. Per alcune ricerche (ad esempio le richieste relative alla mappatura delle righe dei file da wasm a C++), non è necessario esaminare i dati di debug aggiuntivi. In questo modo, risparmiamo tempo perché non dobbiamo caricare e analizzare i dati di debug aggiuntivi.
1: se non hai una versione recente di llvm-objdump sul tuo sistema e utilizzi emsdk, puoi trovarla nella directory emsdk/upstream/bin.
Scaricare i canali di anteprima
Valuta la possibilità di utilizzare Chrome Canary, Dev o Beta come browser di sviluppo predefinito. Questi canali di anteprima ti consentono di accedere alle funzionalità più recenti di DevTools, di testare API di piattaforme web all'avanguardia e di trovare i problemi sul tuo sito prima che lo facciano gli utenti.
Contatta il team di Chrome DevTools
Utilizza le seguenti opzioni per discutere di nuove funzionalità, aggiornamenti o qualsiasi altro argomento relativo a DevTools.
- Inviaci feedback e richieste di funzionalità all'indirizzo crbug.com.
- Segnala un problema DevTools utilizzando Altre opzioni > Guida > Segnala un problema DevTools in DevTools.
- Invia un tweet all'account @ChromeDevTools.
- Lascia un commento sui video di YouTube Novità di DevTools o sui video di YouTube Suggerimenti per DevTools.