
Que se passe-t-il lors de la navigation ?
Il s'agit de la deuxième partie d'une série de blogs en quatre parties sur le fonctionnement interne de Chrome. Dans l'article précédent, nous avons vu comment différents processus et threads gèrent différentes parties d'un navigateur. Dans cet article, nous allons examiner plus en détail la façon dont chaque processus et thread communiquent pour afficher un site Web.
Prenons un cas d'utilisation simple de la navigation sur le Web: vous saisissez une URL dans un navigateur, puis le navigateur récupère des données sur Internet et affiche une page. Dans cet article, nous allons nous concentrer sur la partie où un utilisateur demande un site et que le navigateur se prépare à afficher une page, également appelée navigation.
Il commence par un processus de navigateur
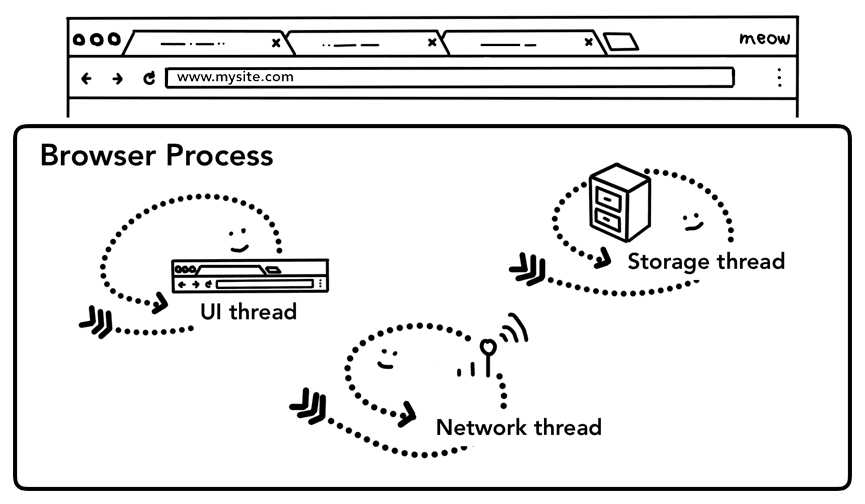
Comme nous l'avons vu dans la partie 1: CPU, GPU, mémoire et architecture multiprocessus, tout ce qui se trouve en dehors d'un onglet est géré par le processus du navigateur. Le processus du navigateur comporte des threads, comme le thread d'interface utilisateur qui dessine les boutons et les champs de saisie du navigateur, le thread réseau qui gère la pile réseau pour recevoir des données d'Internet, le thread de stockage qui contrôle l'accès aux fichiers, etc. Lorsque vous saisissez une URL dans la barre d'adresse, votre saisie est gérée par le thread d'UI du processus du navigateur.
Une navigation simple
Étape 1: Gérer la saisie
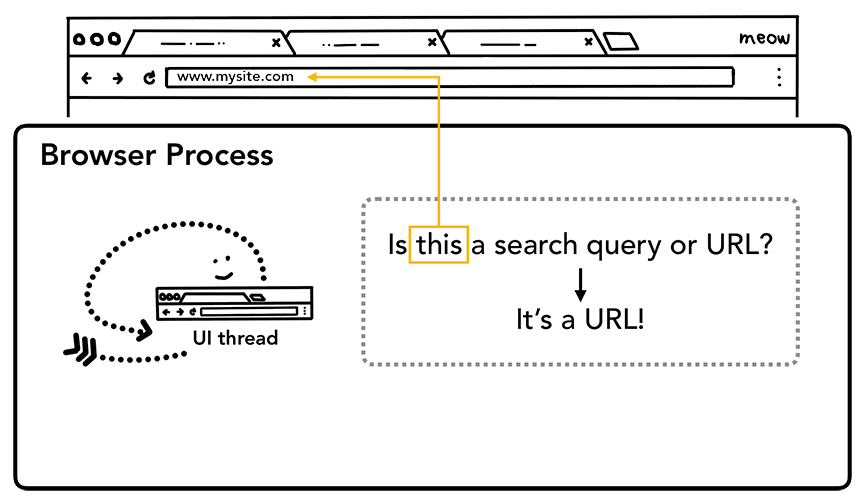
Lorsqu'un utilisateur commence à saisir du texte dans la barre d'adresse, le thread d'UI demande d'abord "S'agit-il d'une requête de recherche ou d'une URL ?". Dans Chrome, la barre d'adresse est également un champ de saisie de recherche. Le thread d'UI doit donc l'analyser et décider s'il doit vous rediriger vers un moteur de recherche ou vers le site que vous avez demandé.
Étape 2: Lancer la navigation
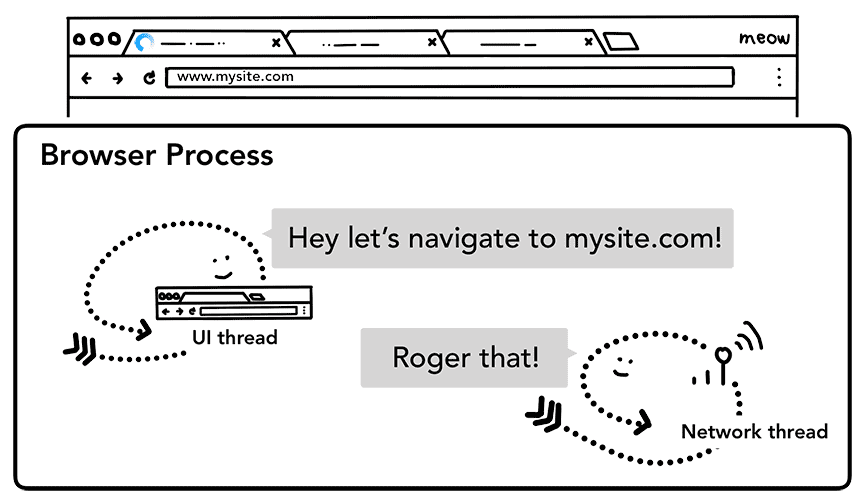
Lorsqu'un utilisateur appuie sur Entrée, le thread d'UI lance un appel réseau pour obtenir le contenu du site. Un voyant de chargement s'affiche dans un coin d'un onglet, et le thread réseau applique les protocoles appropriés, comme la résolution DNS et l'établissement d'une connexion TLS pour la requête.
À ce stade, le thread réseau peut recevoir un en-tête de redirection de serveur tel que HTTP 301. Dans ce cas, le thread réseau communique avec le thread d'interface utilisateur que le serveur demande une redirection. Une autre requête d'URL est alors lancée.
Étape 3: Lire la réponse
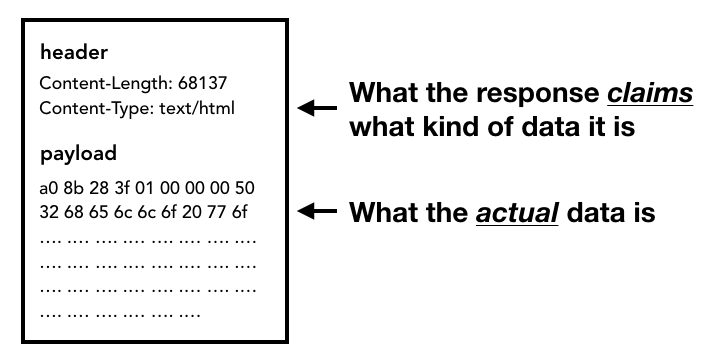
Une fois que le corps de la réponse (charge utile) commence à arriver, le thread réseau examine les premiers octets du flux si nécessaire. L'en-tête Content-Type de la réponse doit indiquer le type de données, mais comme il peut être manquant ou incorrect, une analyse du type MIME est effectuée ici. Il s'agit d'une "affaire délicate", comme indiqué dans le code source. Vous pouvez lire le commentaire pour voir comment les différents navigateurs traitent les paires de type de contenu/charge utile.
Si la réponse est un fichier HTML, l'étape suivante consiste à transmettre les données au processus de rendu. Toutefois, s'il s'agit d'un fichier ZIP ou d'un autre fichier, cela signifie qu'il s'agit d'une requête de téléchargement. Les données doivent donc être transmises au gestionnaire de téléchargement.
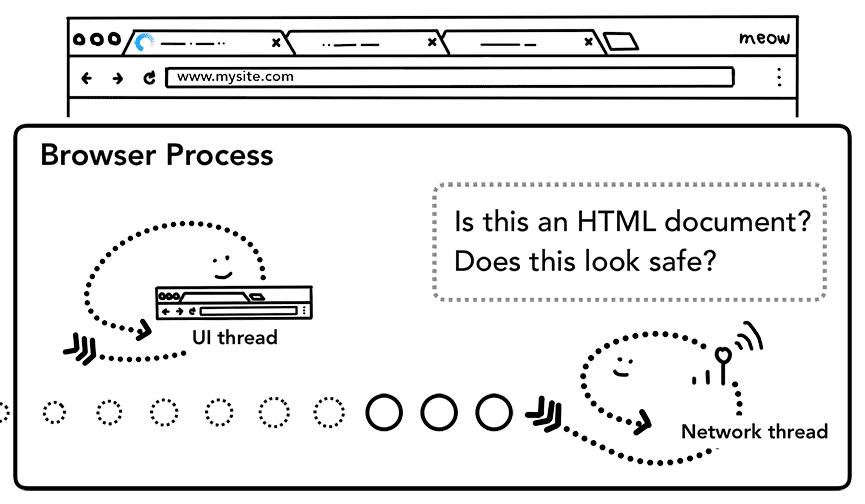
C'est également là que la vérification SafeBrowsing est effectuée. Si le domaine et les données de réponse semblent correspondre à un site malveillant connu, le thread réseau émet une alerte pour afficher une page d'avertissement. De plus, une vérification du Blocage de la Llecture de Données sensibles entre sites (CORB) est effectuée pour s'assurer que les données sensibles entre sites ne parviennent pas au processus de rendu.
Étape 4: Recherchez un processus de rendu
Une fois toutes les vérifications effectuées et que le thread réseau est sûr que le navigateur doit accéder au site demandé, le thread réseau indique au thread UI que les données sont prêtes. Le thread d'UI recherche ensuite un processus de rendu pour poursuivre l'affichage de la page Web.
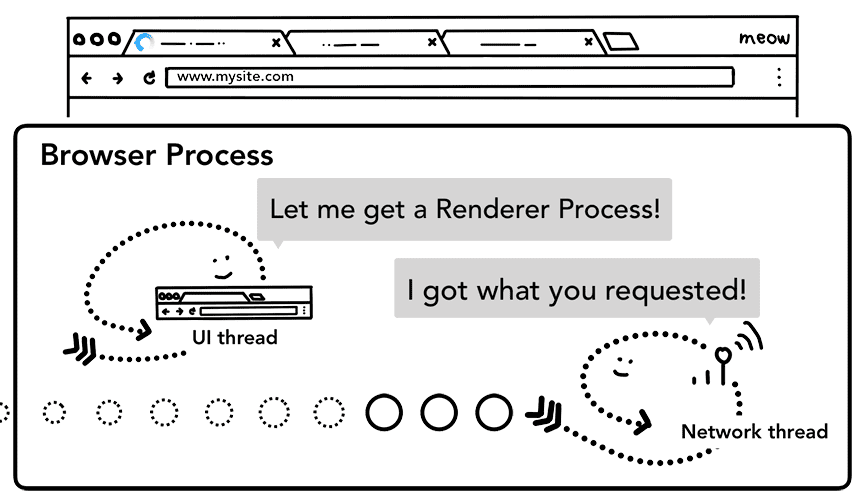
Étant donné que la requête réseau peut prendre plusieurs centaines de millisecondes pour obtenir une réponse, une optimisation est appliquée pour accélérer ce processus. Lorsque le thread d'UI envoie une requête d'URL au thread réseau à l'étape 2, il sait déjà vers quel site il navigue. Le thread d'UI tente de trouver ou de démarrer de manière proactive un processus de rendu en parallèle de la requête réseau. De cette façon, si tout se passe comme prévu, un processus de rendu est déjà en veille lorsque le thread réseau reçoit des données. Ce processus de veille peut ne pas être utilisé si la navigation redirige entre les sites, auquel cas un autre processus peut être nécessaire.
Étape 5: Valider la navigation
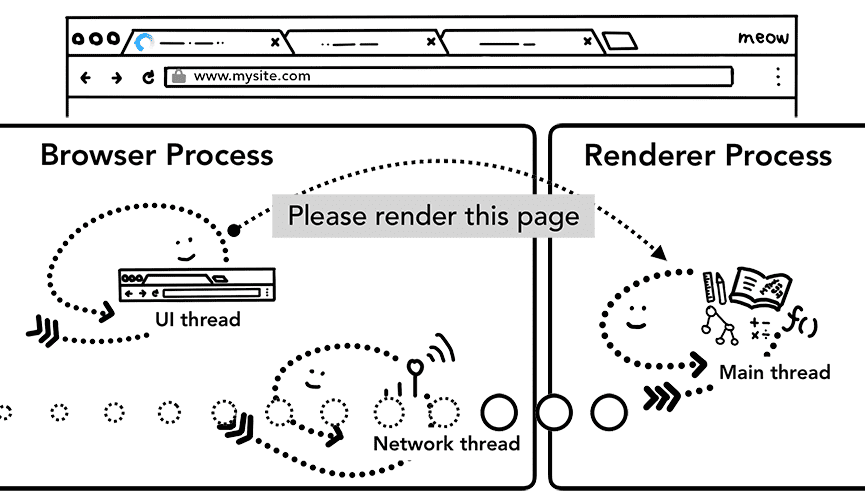
Maintenant que les données et le processus de rendu sont prêts, un IPC est envoyé du processus du navigateur au processus de rendu pour valider la navigation. Il transmet également le flux de données afin que le processus de rendu puisse continuer à recevoir des données HTML. Une fois que le processus du navigateur a reçu la confirmation que le commit s'est produit dans le processus de rendu, la navigation est terminée et la phase de chargement du document commence.
À ce stade, la barre d'adresse est mise à jour, et l'indicateur de sécurité et l'UI des paramètres du site reflètent les informations du site de la nouvelle page. L'historique de la session de l'onglet sera mis à jour afin que les boutons "Retour"/"Avance" permettent de parcourir le site auquel vous venez d'accéder. Pour faciliter la restauration des onglets/sessions lorsque vous fermez un onglet ou une fenêtre, l'historique des sessions est stocké sur le disque.
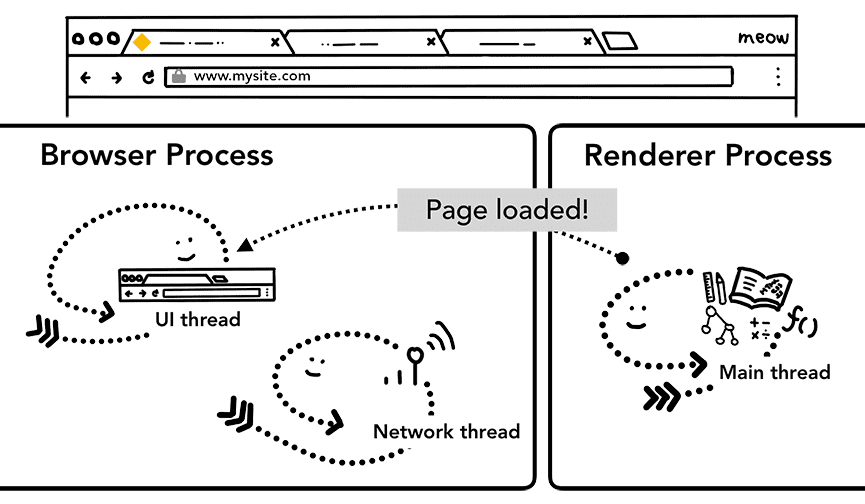
Étape supplémentaire: Chargement initial terminé
Une fois la navigation validée, le processus de rendu continue de charger des ressources et de générer la page. Nous reviendrons plus en détail sur ce qui se passe à cette étape dans le prochain post. Une fois le processus de rendu terminé, il renvoie un IPC au processus du navigateur (après que tous les événements onload ont été déclenchés sur tous les frames de la page et ont terminé leur exécution). À ce stade, le thread d'UI arrête la roue de chargement dans l'onglet.
Je dis "termine", car le code JavaScript côté client peut toujours charger des ressources supplémentaires et afficher de nouvelles vues après ce point.
Accéder à un autre site
La navigation simple est terminée. Mais que se passe-t-il si un utilisateur saisit à nouveau une URL différente dans la barre d'adresse ? Le processus du navigateur suit les mêmes étapes pour accéder à un autre site.
Mais avant de pouvoir le faire, il doit vérifier auprès du site actuellement affiché s'il est concerné par l'événement beforeunload.
beforeunload peut créer une alerte "Quitter ce site ?" lorsque vous essayez de quitter le site ou de fermer l'onglet.
Tout ce qui se trouve dans un onglet, y compris votre code JavaScript, est géré par le processus de rendu. Le processus du navigateur doit donc vérifier auprès du processus de rendu actuel lorsqu'une nouvelle requête de navigation est reçue.
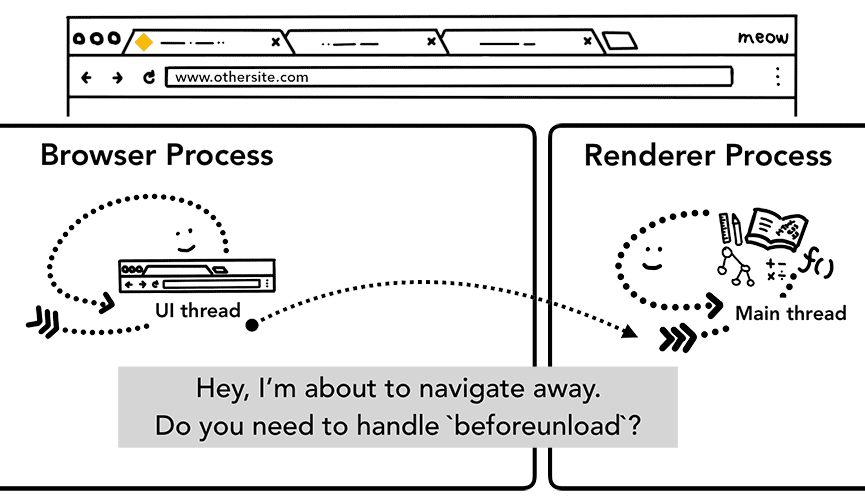
Si la navigation a été lancée à partir du processus de rendu (par exemple, si l'utilisateur a cliqué sur un lien ou si le code JavaScript côté client a exécuté window.location = "https://newsite.com"), le processus de rendu vérifie d'abord les gestionnaires beforeunload. Ensuite, il suit le même processus que la navigation lancée par le processus du navigateur. La seule différence est que la requête de navigation est lancée du processus de rendu au processus du navigateur.
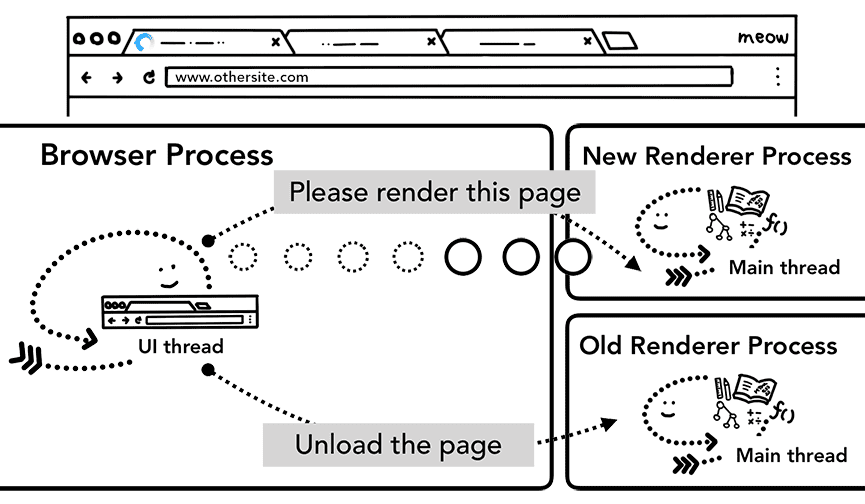
Lorsqu'une nouvelle navigation est effectuée vers un site différent de celui actuellement affiché, un processus de rendu distinct est appelé pour gérer la nouvelle navigation, tandis que le processus de rendu actuel est conservé pour gérer des événements tels que unload. Pour en savoir plus, consultez une présentation des états du cycle de vie des pages et découvrez comment vous pouvez vous connecter aux événements avec l'API Page Lifecycle.
Dans le cas d'un service worker
L'introduction des service workers a récemment modifié ce processus de navigation. Un service worker permet d'écrire un proxy réseau dans le code de votre application. Cela permet aux développeurs Web de mieux contrôler ce qu'il faut mettre en cache localement et quand obtenir de nouvelles données du réseau. Si le service worker est configuré pour charger la page à partir du cache, il n'est pas nécessaire de demander les données au réseau.
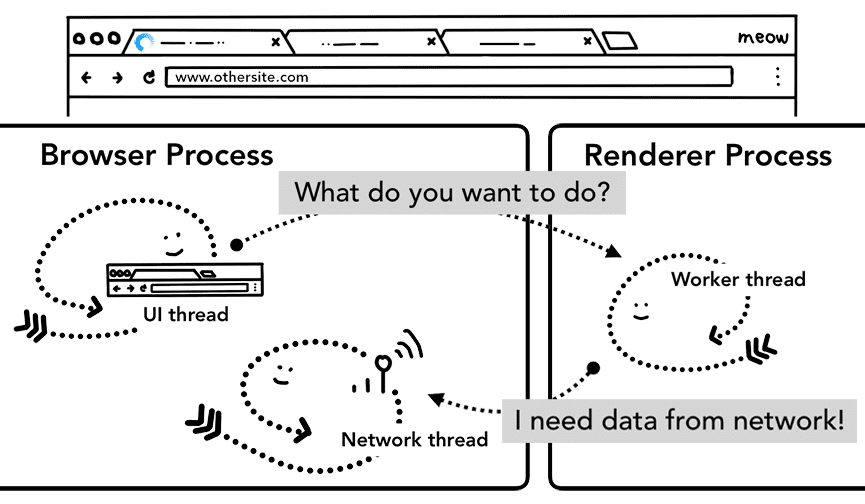
Il est important de se rappeler qu'un service worker est un code JavaScript exécuté dans un processus de rendu. Mais lorsqu'une requête de navigation arrive, comment un processus de navigateur sait-il que le site dispose d'un service worker ?

Lorsqu'un service worker est enregistré, son champ d'application est conservé à titre de référence (pour en savoir plus sur le champ d'application, consultez l'article Cycle de vie du service worker). Lors d'une navigation, le thread réseau vérifie le domaine par rapport aux portées de service worker enregistrées. Si un service worker est enregistré pour cette URL, le thread d'interface utilisateur trouve un processus de rendu pour exécuter le code du service worker. Le service worker peut charger des données à partir du cache, ce qui élimine la nécessité de demander des données au réseau, ou il peut demander de nouvelles ressources au réseau.
Précharge de la navigation
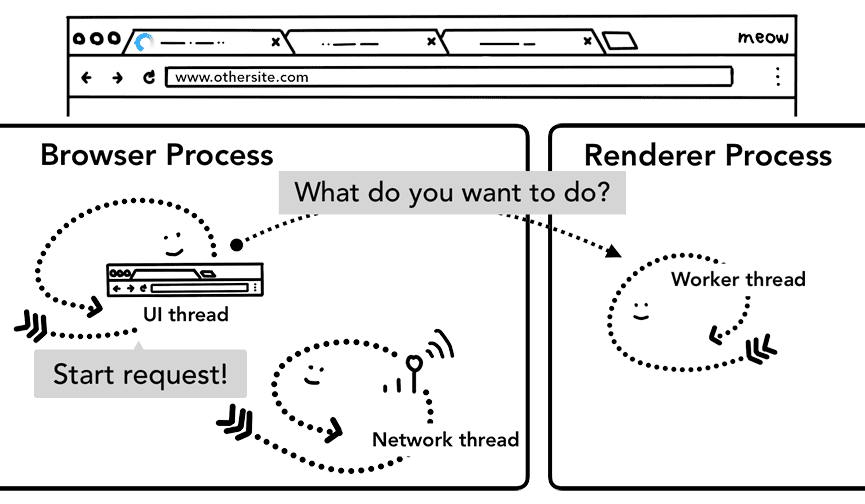
Vous pouvez constater que cet aller-retour entre le processus du navigateur et le processus du moteur de rendu peut entraîner des retards si le service worker décide finalement de demander des données au réseau. Le préchargement de navigation est un mécanisme permettant d'accélérer ce processus en chargeant des ressources en parallèle du démarrage du service worker. Il marque ces requêtes avec un en-tête, ce qui permet aux serveurs de décider d'envoyer un contenu différent pour ces requêtes (par exemple, uniquement des données mises à jour au lieu d'un document complet).
Conclusion
Dans cet article, nous avons examiné ce qui se passe lors d'une navigation et comment le code de votre application Web, comme les en-têtes de réponse et le code JavaScript côté client, interagit avec le navigateur. Connaître les étapes suivies par le navigateur pour obtenir des données du réseau permet de comprendre plus facilement pourquoi des API telles que le préchargement de navigation ont été développées. Dans le prochain article, nous verrons comment le navigateur évalue notre code HTML/CSS/JavaScript pour afficher les pages.
Avez-vous aimé cet article ? Si vous avez des questions ou des suggestions pour un prochain post, n'hésitez pas à me contacter dans la section des commentaires ci-dessous ou sur Twitter en suivant le compte @kosamari.