
Co się dzieje w nawigacji
To jest druga część 4-częściowej serii blogów o tym, jak działa Chrome. W poprzednim poście omawialiśmy, jak różne procesy i wątki obsługują różne części przeglądarki. W tym poście przyjrzymy się bliżej temu, jak procesy i wątki komunikują się ze sobą, aby wyświetlić witrynę.
Spójrzmy na prosty przypadek korzystania z przeglądarki internetowej: wpisujesz adres URL w przeglądarce, a ona pobiera dane z internetu i wyświetla stronę. W tym poście skupimy się na części, w której użytkownik wysyła żądanie dotyczące witryny, a przeglądarka przygotowuje się do renderowania strony (zwanego też nawigacją).
Rozpoczyna się od procesu przeglądarki
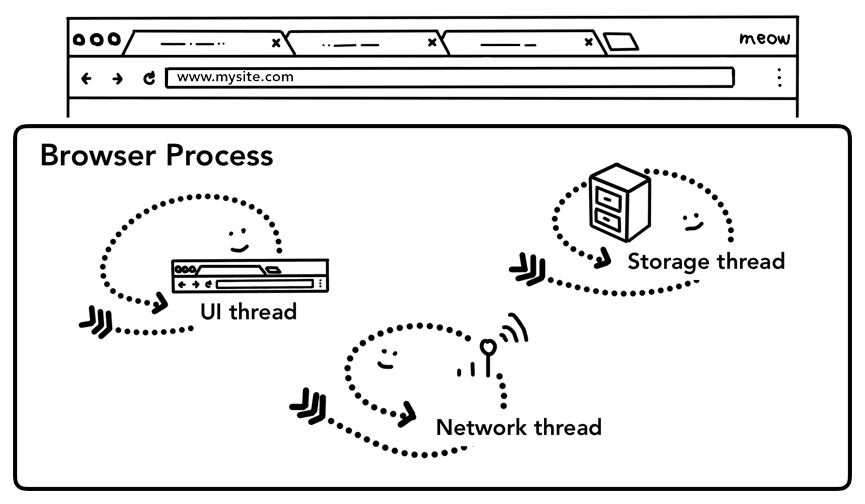
Jak wspomnieliśmy w części 1: procesor, GPU, pamięć i architektura wieloprocesorowa, wszystkim poza kartą zajmuje się proces przeglądarki. Proces przeglądarki zawiera wątki takie jak wątki interfejsu użytkownika, które wyświetlają przyciski i pola wprowadzania danych w przeglądarce, wątki sieciowe, które zajmują się obsługą stosu sieciowego w celu odbierania danych z internetu, wątki pamięci masowej, które kontrolują dostęp do plików, itp. Gdy wpiszesz adres URL na pasku adresu, dane są przetwarzane przez wątek interfejsu procesu przeglądarki.
Prosta nawigacja
Krok 1. Obsługa danych wejściowych
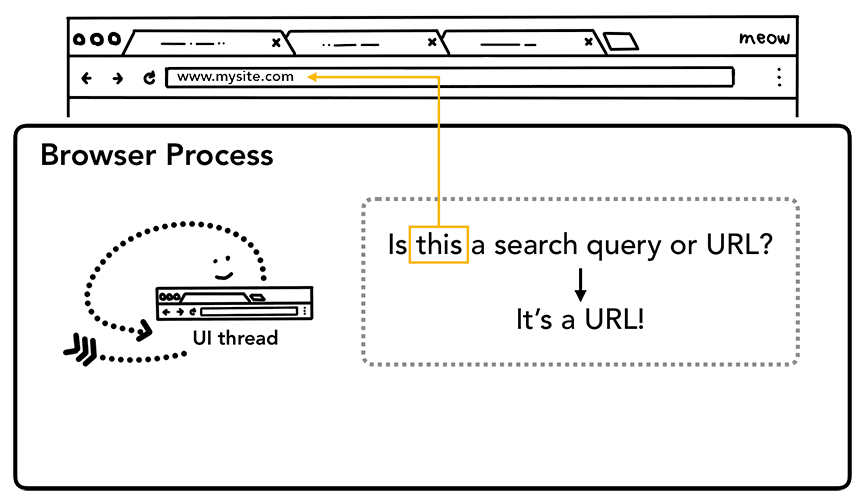
Gdy użytkownik zacznie wpisywać tekst na pasku adresu, pierwszy wątek interfejsu zapyta: „Czy to jest zapytanie wyszukiwania czy adres URL?”. W Chrome pasek adresu jest też polem wyszukiwania, więc wątek interfejsu musi przeanalizować dane i podjąć decyzję, czy wysłać Cię do wyszukiwarki, czy do wybranej witryny.
Krok 2. Rozpocznij nawigację
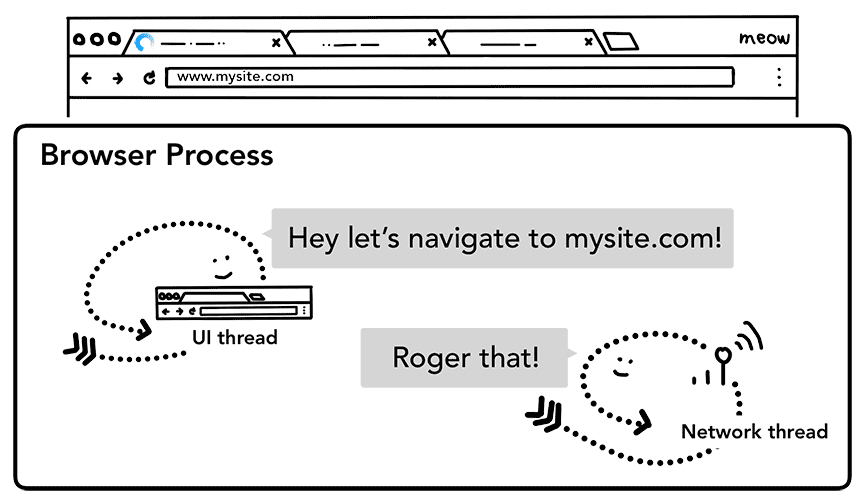
Gdy użytkownik naciśnie klawisz Enter, wątek interfejsu rozpocznie wywołanie sieciowe, aby pobrać zawartość witryny. W rogu karty wyświetla się wskaźnik ładowania, a wątek sieciowy przechodzi przez odpowiednie protokoły, takie jak wyszukiwanie DNS i nawiązywanie połączenia TLS dla żądania.
W tym momencie wątek sieci może otrzymać nagłówek przekierowania serwera, np. HTTP 301. W takim przypadku wątek sieci komunikuje się z wątkiem interfejsu użytkownika, że serwer prosi o przekierowanie. Następnie rozpocznie się kolejna procedura sprawdzania adresu URL.
Krok 3. Przeczytaj odpowiedź
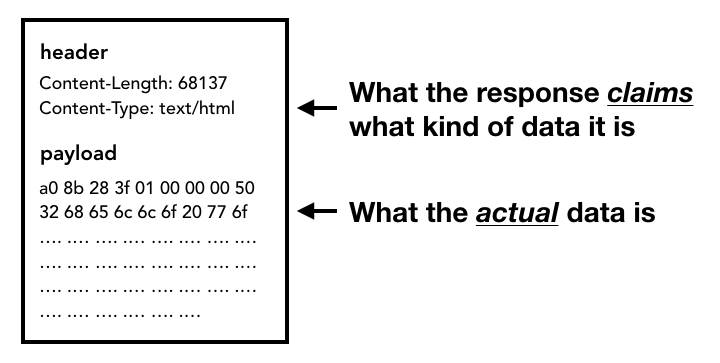
Gdy zaczynają napływać dane odpowiedzi (ładunek), wątek sieciowy sprawdza pierwsze kilka bajtów strumienia (w razie potrzeby). Nagłówek Content-Type odpowiedzi powinien wskazywać typ danych, ale ponieważ może on być nieobecny lub nieprawidłowy, tutaj przeprowadzane jest skanowanie typu MIME. Jak napisano w komentarzu w źródle kodu, jest to „trudna sprawa”. Możesz przeczytać komentarz, aby zobaczyć, jak różne przeglądarki interpretują pary typ treści/dane.
Jeśli odpowiedź to plik HTML, następnym krokiem będzie przekazanie danych do procesu renderowania, ale jeśli jest to plik ZIP lub inny plik, oznacza to, że jest to żądanie pobierania, więc dane muszą zostać przekazane do menedżera pobierania.
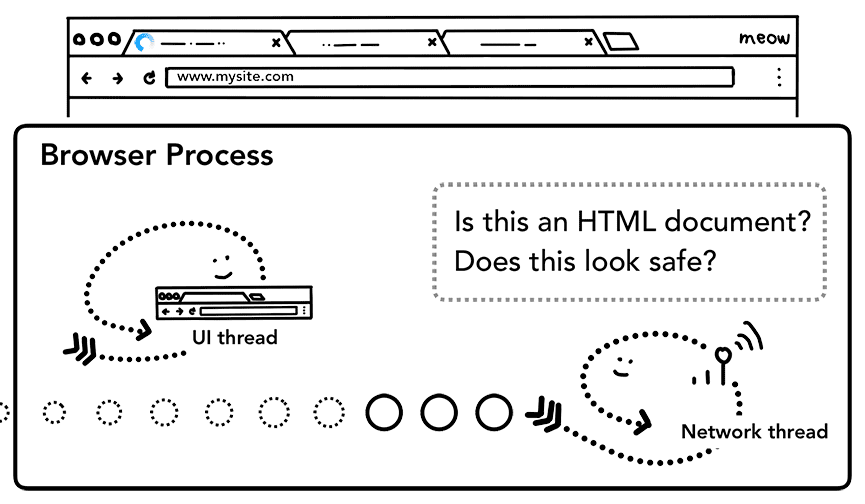
Tutaj też odbywa się sprawdzanie SafeBrowsing. Jeśli domena i dane odpowiedzi pasują do znanej złośliwej witryny, wątek sieci ostrzega o konieczności wyświetlenia strony z ostrzeżeniem. Dodatkowo sprawdzanie Cross Origin Read Blocking (CORB) odbywa się w celu upewnienia się, że poufne dane między witrynami nie trafią do procesu renderowania.
Krok 4. Znajdź proces renderowania
Gdy wszystkie kontrole zostaną wykonane i wątek sieciowy będzie pewny, że przeglądarka powinna przejść do żądanej witryny, wątek sieciowy poinformuje wątek interfejsu użytkownika, że dane są gotowe. Następnie wątek interfejsu użytkownika znajduje proces renderowania, który ma kontynuować renderowanie strony internetowej.
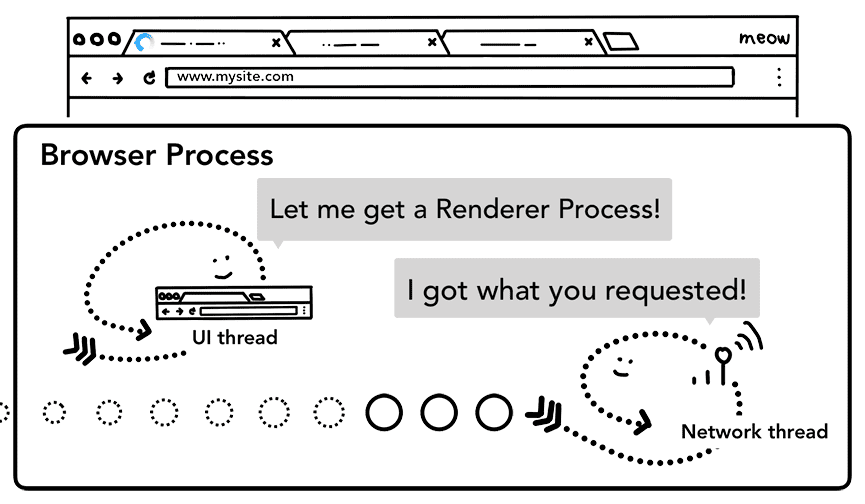
Ponieważ odpowiedź na żądanie sieci może potrwać kilkaset milisekund, stosujemy optymalizację, aby przyspieszyć ten proces. Gdy w kroku 2 wątek interfejsu użytkownika wysyła żądanie adresu URL do wątku sieciowego, wie już, do której witryny się przekierowuje. Wątek interfejsu próbuje aktywnie znaleźć lub uruchomić proces renderowania równolegle z żądaniem sieciowym. W ten sposób, jeśli wszystko przebiega zgodnie z planem, proces renderowania jest już w stanie gotowości, gdy wątek sieciowy otrzyma dane. Ten proces w stanie gotowości może nie zostać użyty, jeśli nawigacja przekierowuje do innej witryny. W takim przypadku może być potrzebny inny proces.
Krok 5. Przejdź do edycji treści
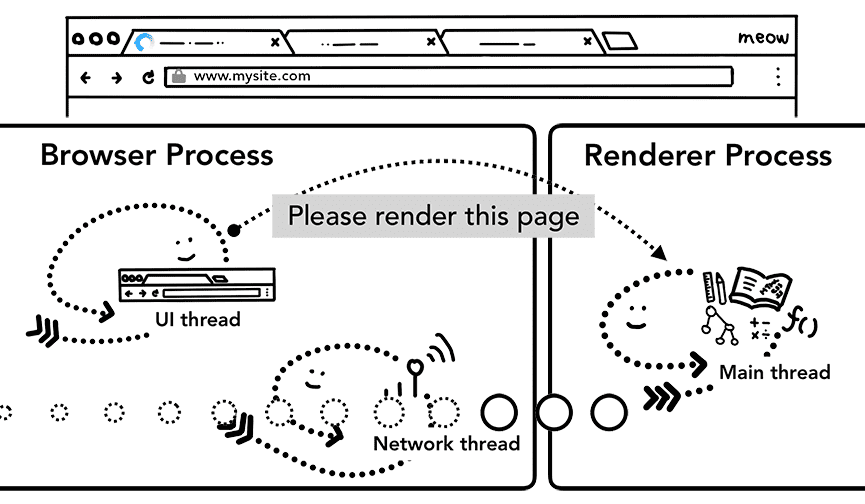
Gdy dane i proces renderowania są gotowe, proces IPC jest wysyłany z procesu przeglądarki do procesu renderowania w celu zatwierdzenia nawigacji. Przekazuje też strumień danych, aby proces renderowania mógł nadal otrzymywać dane HTML. Gdy proces przeglądarki otrzyma potwierdzenie, że w procesie renderowania nastąpiła zmiana, przekierowanie się zakończy i rozpocznie się faza wczytywania dokumentu.
W tym momencie pasek adresu jest aktualizowany, a wskaźnik bezpieczeństwa i interfejs ustawień witryny odzwierciedlają informacje o nowej stronie. Historia sesji na karcie zostanie zaktualizowana, aby przyciski Wstecz i Dalej przewijały stronę, do której użytkownik właśnie przeszedł. Aby ułatwić przywracanie karty lub sesji, gdy zamkniesz kartę lub okno, historia sesji jest zapisywana na dysku.
Dodatkowy krok: wczytywanie początkowe zakończone
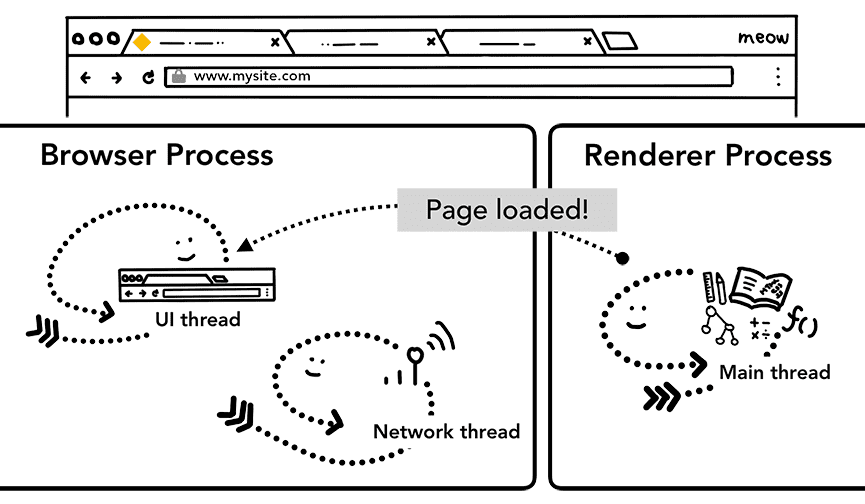
Gdy nawigacja zostanie zaakceptowana, proces renderowania będzie kontynuował wczytywanie zasobów i renderowanie strony. Więcej informacji o tym, co dzieje się na tym etapie, znajdziesz w następnym poście. Gdy proces renderowania „zakończy” renderowanie, wysyła do procesu przeglądarki komunikat IPC (zdarza się to po tym, jak wszystkie zdarzenia onload zostały wywołane we wszystkich ramkach na stronie i zakończyły wykonywanie). W tym momencie wątek interfejsu użytkownika zatrzymuje ładowanie na karcie.
Mówię „kończy”, ponieważ po tym etapie kod JavaScript po stronie klienta może nadal wczytywać dodatkowe zasoby i renderować nowe widoki.
Przechodzenie do innej witryny
Uproszczona nawigacja została ukończona. Co się stanie, jeśli użytkownik wprowadzi inny adres URL na pasku adresu? Przejście do innej witryny odbywa się w taki sam sposób.
Zanim to zrobi, musi sprawdzić w bieżąco renderowanej witrynie, czy jest to zdarzenie beforeunload.
beforeunload może wyświetlić alert „Opuścić tę stronę?”, gdy spróbujesz przejść do innej strony lub zamknąć kartę.
Wszystko na karcie, w tym kod JavaScript, jest obsługiwane przez proces renderowania, więc proces przeglądarki musi sprawdzić bieżący proces renderowania, gdy pojawi się nowe żądanie nawigacji.
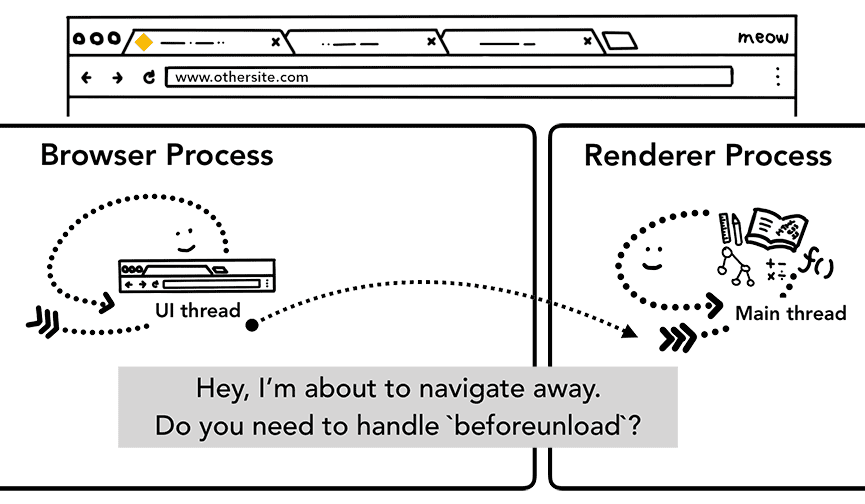
Jeśli nawigacja została zainicjowana przez proces renderowania (np. użytkownik kliknął link lub został wykonany kod JavaScript po stronie klienta window.location = "https://newsite.com"), proces renderowania najpierw sprawdza beforeunload. Następnie przechodzi przez ten sam proces co w przypadku nawigacji inicjowanej przez przeglądarkę. Jedyna różnica polega na tym, że żądanie nawigacji jest przekazywane z procesu renderera do procesu przeglądarki.
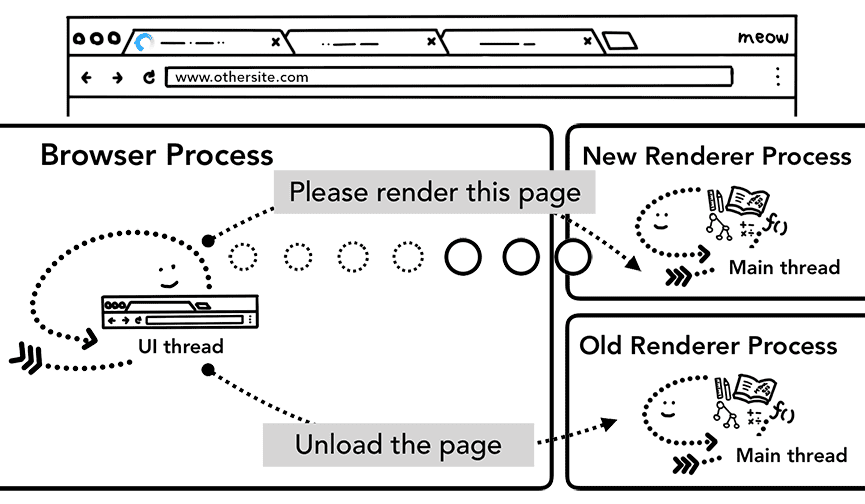
Gdy nowa nawigacja jest tworzona dla innej witryny niż renderowana obecnie, wywoływany jest osobny proces renderowania, który obsługuje nową nawigację, a obecny proces renderowania jest utrzymany, aby obsługiwać zdarzenia takie jak unload. Więcej informacji znajdziesz w artykule Przegląd stanów cyklu życia strony oraz w artykule o tym, jak można podłączać zdarzenia za pomocą interfejsu Page Lifecycle API.
W przypadku skryptu service worker
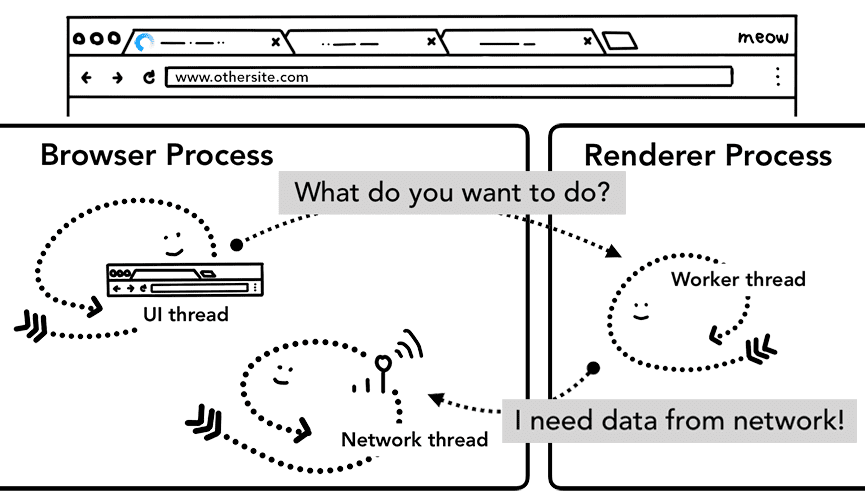
Jedną z niedawnych zmian w tym procesie nawigacji jest wprowadzenie usług workera. Skrypt service worker to sposób na napisanie sieciowego serwera proxy w kodzie aplikacji. Pozwala on deweloperom łatwiej kontrolować, co przechowywać w pamięci podręcznej i kiedy pobierać nowe dane z sieci. Jeśli usługa robocza jest skonfigurowana tak, aby wczytywać stronę z pamięci podręcznej, nie trzeba wysyłać żądania danych z sieci.
Pamiętaj, że usługa to kod JavaScriptu, który działa w procesie renderowania. Ale gdy przychodzi żądanie nawigacji, jak proces przeglądarki wie, że witryna ma workera?

Gdy usługa robocza zostanie zarejestrowana, jej zakres jest przechowywany jako odwołanie (więcej informacji o zakresie znajdziesz w artykule Cykl życia usługi roboczej). Gdy nastąpi nawigacja, wątek sieciowy sprawdza domenę pod kątem zarejestrowanych zakresów skryptu service worker. Jeśli skrypt service worker jest zarejestrowany dla tego adresu URL, wątek interfejsu użytkownika znajduje proces renderowania, aby wykonać kod skryptu service worker. Worker może wczytywać dane z pamięci podręcznej, co eliminuje konieczność wysyłania żądania danych z sieci, lub może żądać nowych zasobów z sieci.
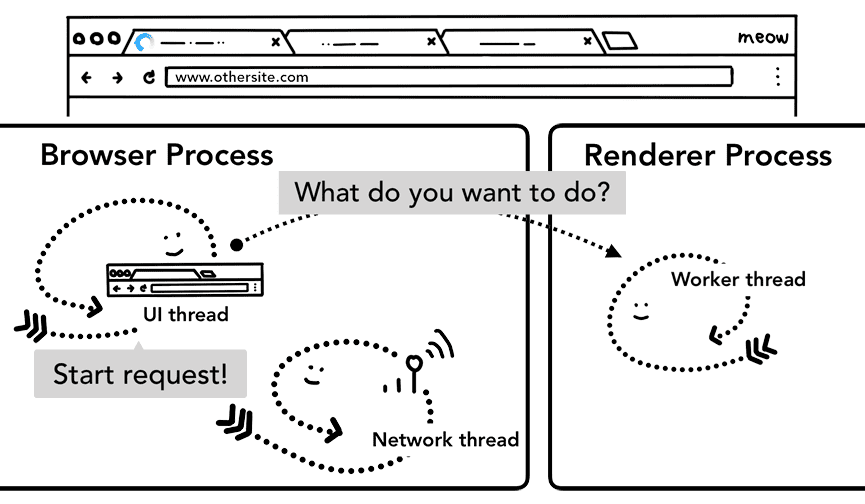
Wczytywanie z wyprzedzeniem nawigacji
Jak widać, ten proces wymiany informacji między procesem przeglądarki a procesorem renderowania może spowodować opóźnienia, jeśli pracownik usługi zdecyduje się poprosić o dane z sieci. Wczytywanie wstępne nawigacji to mechanizm, który przyspiesza ten proces przez wczytywanie zasobów równolegle z uruchamianiem pracownika usługi. Oznacza te żądania nagłówkiem, który pozwala serwerom zdecydować, czy wysłać w odpowiedzi na nie inną treść, np. tylko zaktualizowane dane zamiast pełnego dokumentu.
Podsumowanie
W tym poście omówiliśmy, co dzieje się podczas nawigacji i jak kod aplikacji internetowej, np. nagłówki odpowiedzi i skrypt JavaScript po stronie klienta, współdziała z przeglądarką. Znajomość kroków, które wykonuje przeglądarka, aby pobrać dane z sieci, ułatwia zrozumienie, dlaczego opracowano interfejsy API, takie jak wstępny ładowanie nawigacji. W następnym wpisie omówimy, jak przeglądarka ocenia kod HTML/CSS/JavaScript, aby renderować strony.
Czy spodobał Ci się ten post? Jeśli masz pytania lub sugestie dotyczące przyszłego wpisu, podziel się nimi w sekcji komentarzy poniżej lub napisz do mnie na Twitterze: @kosamari.