
탐색 시 발생하는 상황
이 도움말은 Chrome의 내부 작동 방식을 살펴보는 4부로 구성된 블로그 시리즈 중 2부입니다. 이전 게시물에서는 여러 프로세스와 스레드가 브라우저의 여러 부분을 처리하는 방식을 살펴봤습니다. 이 게시물에서는 웹사이트를 표시하기 위해 각 프로세스와 스레드가 통신하는 방식을 자세히 살펴봅니다.
웹 탐색의 간단한 사용 사례를 살펴보겠습니다. 사용자가 브라우저에 URL을 입력하면 브라우저가 인터넷에서 데이터를 가져와 페이지를 표시합니다. 이 게시물에서는 사용자가 사이트를 요청하고 브라우저가 페이지 렌더링을 준비하는 부분(탐색이라고도 함)에 중점을 둡니다.
브라우저 프로세스로 시작됩니다.
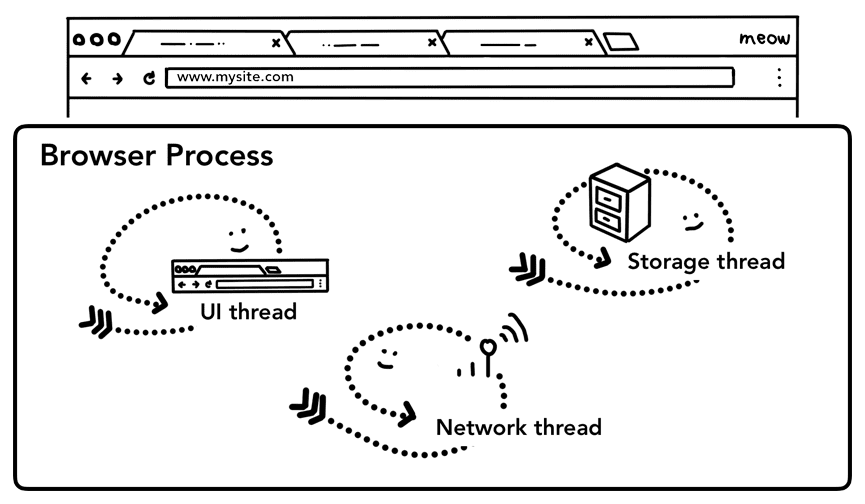
1단계: CPU, GPU, 메모리, 멀티프로세스 아키텍처에서 설명한 대로 탭 외부의 모든 것은 브라우저 프로세스에서 처리합니다. 브라우저 프로세스에는 브라우저의 버튼과 입력란을 그리는 UI 스레드, 인터넷에서 데이터를 수신하기 위해 네트워크 스택을 처리하는 네트워크 스레드, 파일에 대한 액세스를 제어하는 저장소 스레드 등과 같은 스레드가 있습니다. 주소 표시줄에 URL을 입력하면 입력이 브라우저 프로세스의 UI 스레드에서 처리됩니다.
간단한 탐색
1단계: 입력 처리
사용자가 주소 표시줄에 입력하기 시작하면 UI 스레드에서 가장 먼저 '검색어인가요, URL인가요?'라고 묻습니다. Chrome에서 주소 표시줄은 검색 입력란이기도 하므로 UI 스레드는 검색엔진으로 전송할지 아니면 요청한 사이트로 전송할지 파싱하고 결정해야 합니다.
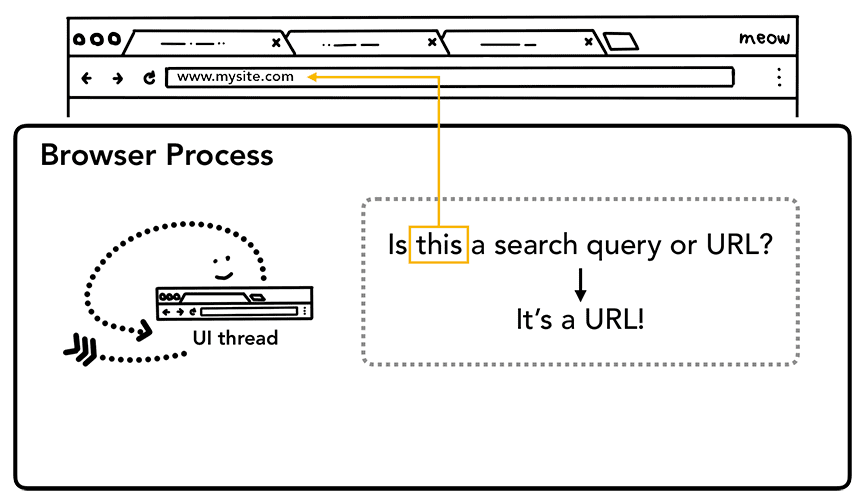
2단계: 내비게이션 시작
사용자가 Enter 키를 누르면 UI 스레드가 네트워크 호출을 시작하여 사이트 콘텐츠를 가져옵니다. 로드 스피너가 탭 모서리에 표시되고 네트워크 스레드는 DNS 조회 및 요청에 대한 TLS 연결 설정과 같은 적절한 프로토콜을 거칩니다.
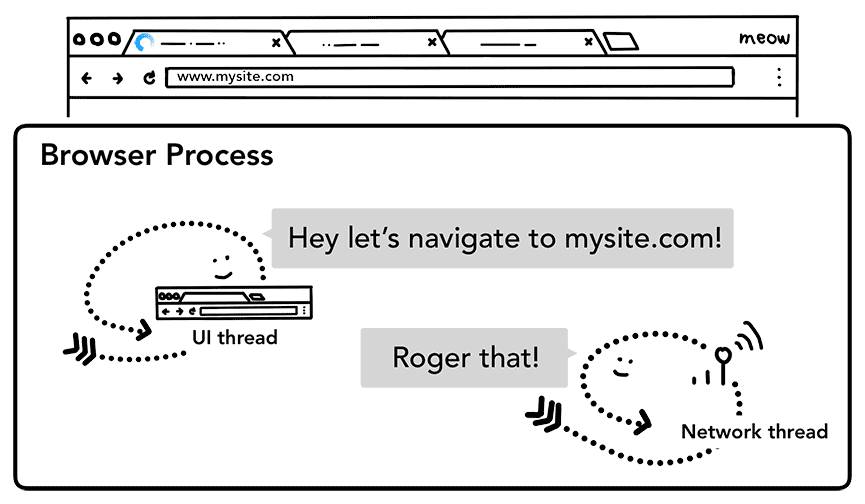
이 시점에서 네트워크 스레드는 HTTP 301과 같은 서버 리디렉션 헤더를 수신할 수 있습니다. 이 경우 네트워크 스레드는 서버가 리디렉션을 요청하고 있다고 UI 스레드에 전달합니다. 그러면 다른 URL 요청이 시작됩니다.
3단계: 응답 읽기
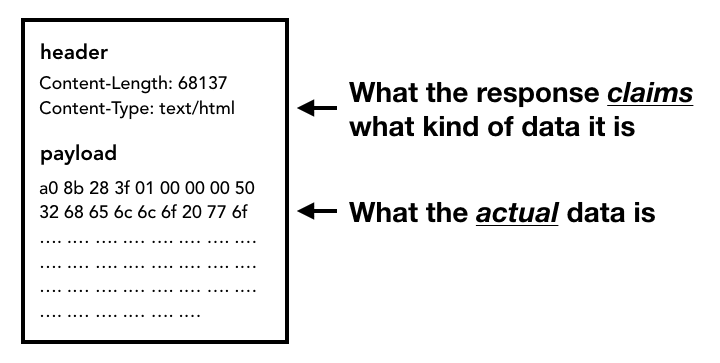
응답 본문 (페이로드)이 수신되기 시작하면 네트워크 스레드는 필요한 경우 스트림의 처음 몇 바이트를 확인합니다. 응답의 Content-Type 헤더에 데이터 유형이 표시되어야 하지만 누락되거나 잘못될 수 있으므로 여기에서 MIME 유형 스니핑이 실행됩니다. 이는 소스 코드에 주석으로 설명된 '까다로운 작업'입니다. 주석을 읽으면 다양한 브라우저에서 콘텐츠 유형/페이로드 쌍을 어떻게 처리하는지 확인할 수 있습니다.
응답이 HTML 파일인 경우 다음 단계는 데이터를 렌더러 프로세스에 전달하는 것이지만, zip 파일이나 다른 파일인 경우 다운로드 요청이므로 데이터를 다운로드 관리자에 전달해야 합니다.
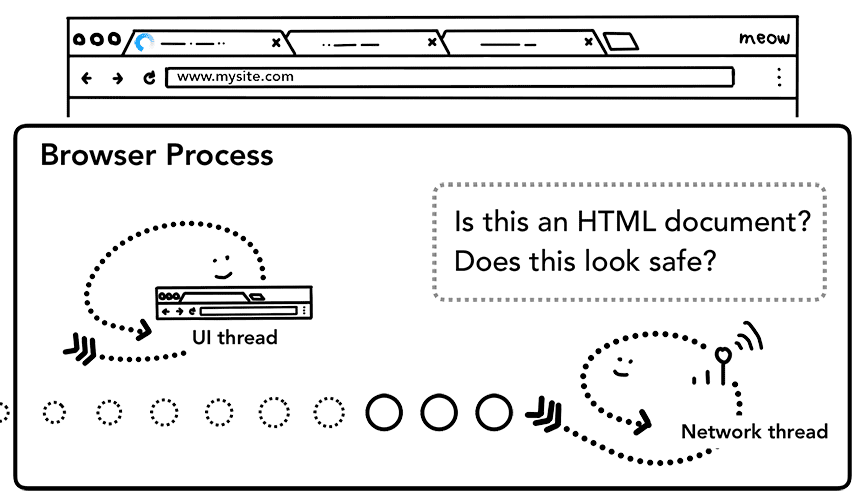
여기에서 SafeBrowsing 확인도 이루어집니다. 도메인과 응답 데이터가 알려진 악성 사이트와 일치하는 것으로 보이면 네트워크 스레드가 경고 페이지를 표시하도록 알립니다. 또한 민감한 교차 사이트 데이터가 렌더러 프로세스로 전송되지 않도록 교차 O리진 Read Blocking (CORB) 확인이 실행됩니다.
4단계: 렌더러 프로세스 찾기
모든 검사가 완료되고 네트워크 스레드가 브라우저가 요청된 사이트로 이동해야 한다고 확신하면 네트워크 스레드는 UI 스레드에 데이터가 준비되었다고 알립니다. 그러면 UI 스레드가 렌더러 프로세스를 찾아 웹페이지 렌더링을 계속합니다.
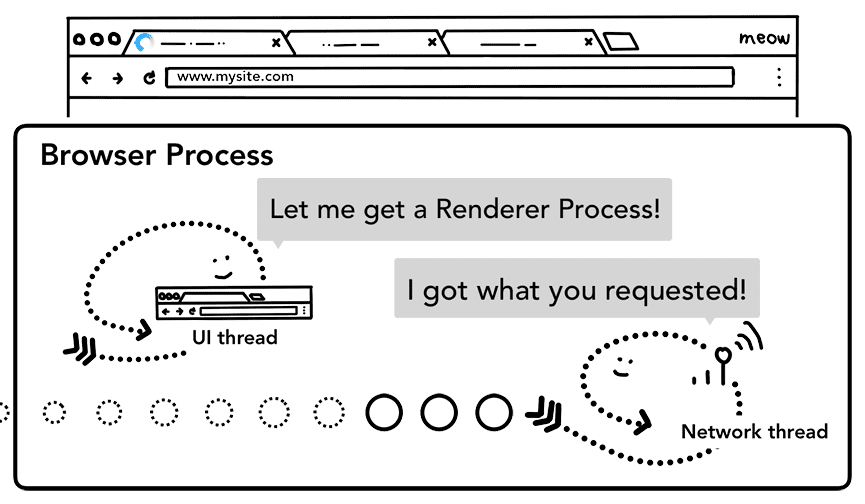
네트워크 요청이 응답을 받기까지 수백 밀리초가 걸릴 수 있으므로 이 프로세스의 속도를 높이는 최적화가 적용됩니다. UI 스레드가 2단계에서 네트워크 스레드에 URL 요청을 전송할 때는 이미 어느 사이트로 이동하는지 알고 있습니다. UI 스레드는 네트워크 요청과 동시에 렌더러 프로세스를 사전에 찾거나 시작하려고 시도합니다. 이렇게 하면 모든 것이 예상대로 진행되면 네트워크 스레드가 데이터를 수신할 때 렌더러 프로세스가 이미 대기 상태입니다. 탐색이 교차 사이트로 리디렉션되는 경우 이 대기 프로세스가 사용되지 않을 수 있으며, 이 경우 다른 프로세스가 필요할 수 있습니다.
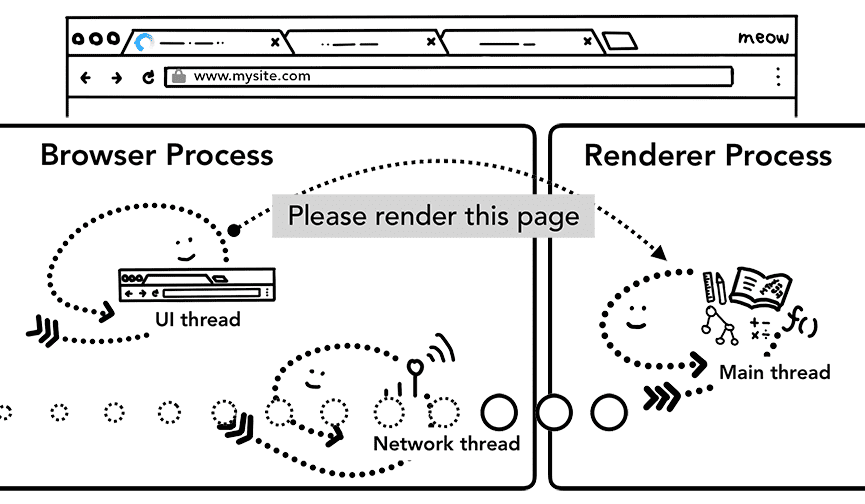
5단계: 탐색 커밋
이제 데이터와 렌더러 프로세스가 준비되었으므로 브라우저 프로세스에서 렌더러 프로세스로 IPC를 전송하여 탐색을 커밋합니다. 또한 렌더러 프로세스가 HTML 데이터를 계속 수신할 수 있도록 데이터 스트림을 전달합니다. 브라우저 프로세스가 렌더러 프로세스에서 커밋이 발생했다는 확인을 받으면 탐색이 완료되고 문서 로드 단계가 시작됩니다.
이 시점에서 주소 표시줄이 업데이트되고 보안 표시기 및 사이트 설정 UI에 새 페이지의 사이트 정보가 반영됩니다. 뒤로/앞으로 버튼이 방금 탐색한 사이트를 단계별로 표시하도록 탭의 세션 기록이 업데이트됩니다. 탭 또는 창을 닫을 때 탭/세션 복원을 쉽게 하기 위해 세션 기록이 디스크에 저장됩니다.
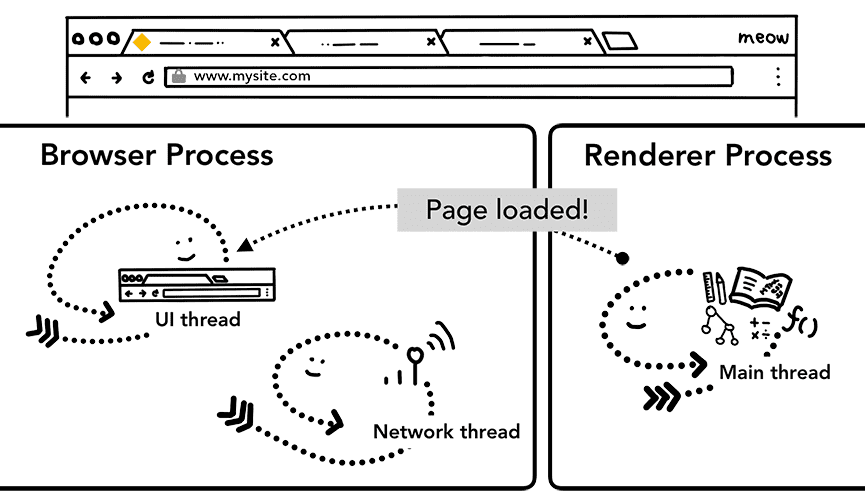
추가 단계: 초기 로드 완료
탐색이 커밋되면 렌더러 프로세스가 리소스 로드를 계속하고 페이지를 렌더링합니다. 이 단계에서 어떤 일이 일어나는지 자세한 내용은 다음 게시물에서 다룹니다. 렌더러 프로세스가 렌더링을 '완료'하면 브라우저 프로세스로 IPC를 다시 전송합니다. 이는 페이지의 모든 프레임에서 모든 onload 이벤트가 실행되고 실행이 완료된 후에 이루어집니다. 이 시점에서 UI 스레드는 탭에서 로드 스피너를 중지합니다.
클라이언트 측 JavaScript가 이 시점 이후에도 추가 리소스를 로드하고 새 뷰를 렌더링할 수 있으므로 '완료'라고 말합니다.
다른 사이트로 이동
간단한 탐색이 완료되었습니다. 하지만 사용자가 주소 표시줄에 다른 URL을 다시 입력하면 어떻게 되나요? 브라우저 프로세스는 다른 사이트로 이동하기 위해 동일한 단계를 거칩니다.
하지만 이를 실행하기 전에 현재 렌더링된 사이트에서 beforeunload 이벤트에 관심이 있는지 확인해야 합니다.
beforeunload는 사용자가 탭을 닫거나 다른 페이지로 이동하려고 할 때 '이 사이트를 나가시겠어요?' 알림을 만들 수 있습니다.
JavaScript 코드를 비롯한 탭 내의 모든 항목은 렌더러 프로세스에서 처리하므로 새 탐색 요청이 들어올 때 브라우저 프로세스는 현재 렌더러 프로세스와 확인해야 합니다.
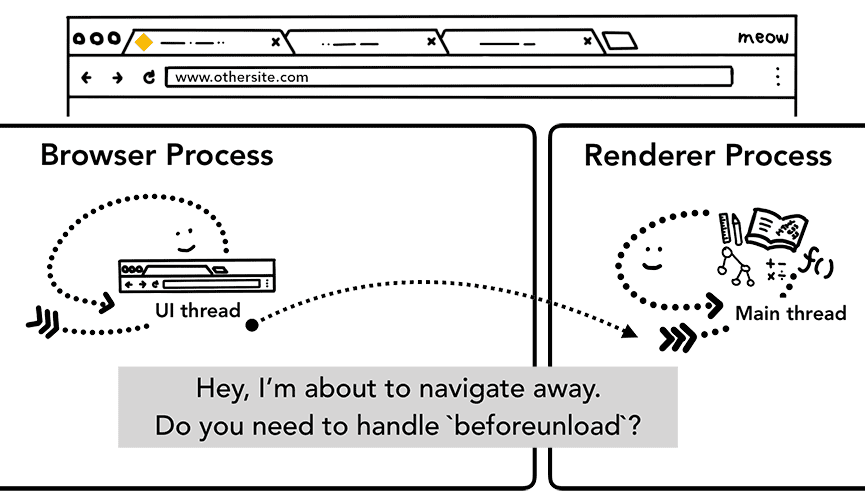
탐색이 렌더러 프로세스에서 시작된 경우 (예: 사용자가 링크를 클릭했거나 클라이언트 측 JavaScript가 window.location = "https://newsite.com"를 실행한 경우) 렌더러 프로세스는 먼저 beforeunload 핸들러를 확인합니다. 그런 다음 브라우저 프로세스에서 시작한 탐색과 동일한 프로세스를 거칩니다. 유일한 차이점은 탐색 요청이 렌더러 프로세스에서 브라우저 프로세스로 시작된다는 점입니다.
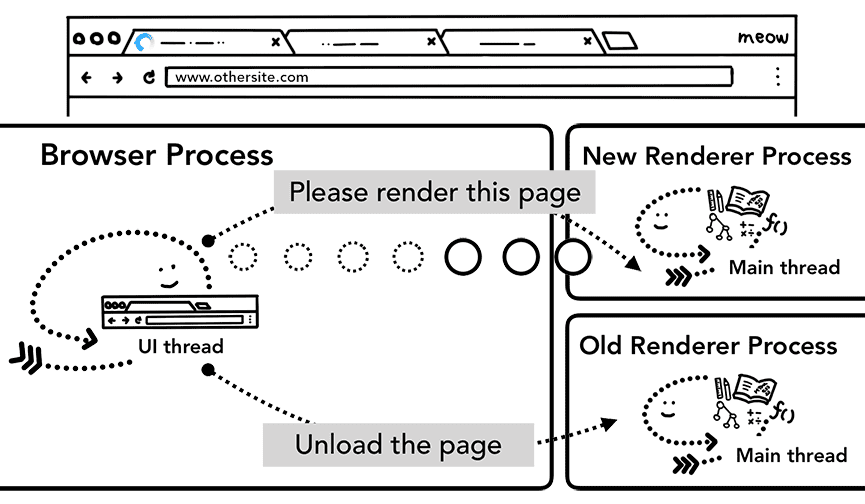
새 탐색이 현재 렌더링된 사이트와 다른 사이트로 이루어지면 별도의 렌더링 프로세스가 호출되어 새 탐색을 처리하는 동안 현재 렌더링 프로세스는 unload와 같은 이벤트를 처리하기 위해 유지됩니다. 자세한 내용은 페이지 수명 주기 상태 개요와 Page Lifecycle API를 사용하여 이벤트에 연결하는 방법을 참고하세요.
서비스 워커의 경우
이 탐색 프로세스에 최근에 적용된 변경사항 중 하나는 서비스 워커의 도입입니다. 서비스 워커는 애플리케이션 코드에 네트워크 프록시를 작성하는 방법입니다. 이를 통해 웹 개발자는 로컬에 캐시할 항목과 네트워크에서 새 데이터를 가져올 시기를 더 세부적으로 제어할 수 있습니다. 서비스 워커가 캐시에서 페이지를 로드하도록 설정된 경우 네트워크에서 데이터를 요청할 필요가 없습니다.
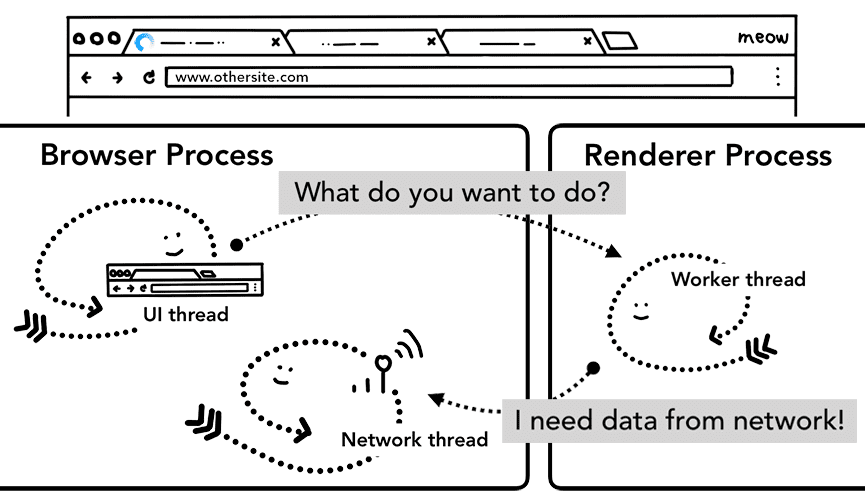
중요한 점은 서비스 워커가 렌더러 프로세스에서 실행되는 JavaScript 코드라는 것입니다. 하지만 탐색 요청이 들어오면 브라우저 프로세스는 사이트에 서비스 워커가 있는지 어떻게 알 수 있나요?

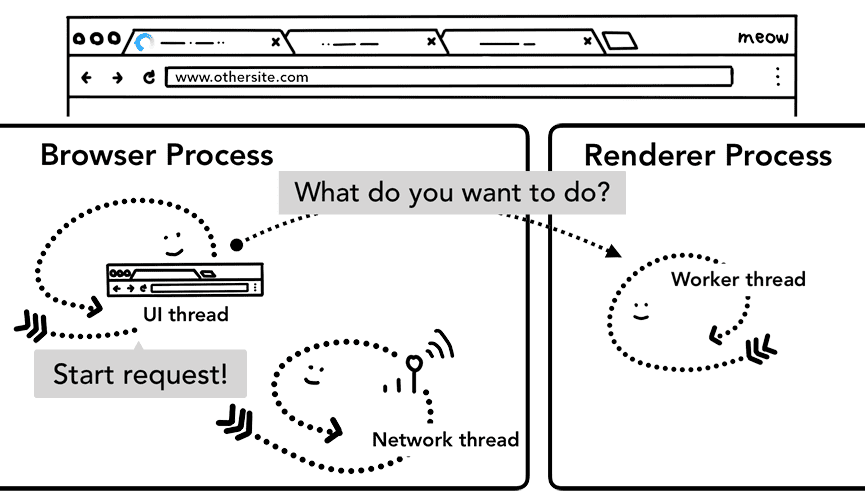
서비스 워커가 등록되면 서비스 워커의 범위가 참조로 유지됩니다(이 서비스 워커 수명 주기 도움말에서 범위에 관해 자세히 알아보세요). 탐색이 발생하면 네트워크 스레드가 등록된 서비스 워커 범위와 비교하여 도메인을 확인합니다. 서비스 워커가 해당 URL에 등록된 경우 UI 스레드는 서비스 워커 코드를 실행하기 위해 렌더러 프로세스를 찾습니다. 서비스 워커는 캐시에서 데이터를 로드하여 네트워크에서 데이터를 요청할 필요가 없게 만들거나 네트워크에서 새 리소스를 요청할 수 있습니다.
내비게이션 미리 로드
브라우저 프로세스와 렌더러 프로세스 간의 왕복이 서비스 워커가 결국 네트워크에서 데이터를 요청하기로 결정하면 지연될 수 있음을 알 수 있습니다. 탐색 미리 로드는 서비스 워커 시작과 동시에 리소스를 로드하여 이 프로세스의 속도를 높이는 메커니즘입니다. 이러한 요청을 헤더로 표시하여 서버가 이러한 요청에 대해 다른 콘텐츠를 전송하도록 결정할 수 있습니다. 예를 들어 전체 문서 대신 업데이트된 데이터만 전송할 수 있습니다.
요약 정리
이 게시물에서는 탐색 중에 어떤 일이 일어나고 응답 헤더 및 클라이언트 측 JavaScript와 같은 웹 애플리케이션 코드가 브라우저와 상호작용하는 방식을 살펴봤습니다. 브라우저가 네트워크에서 데이터를 가져오는 단계를 알면 탐색 미리 로드와 같은 API가 개발된 이유를 더 쉽게 이해할 수 있습니다. 다음 게시물에서는 브라우저가 HTML/CSS/JavaScript를 평가하여 페이지를 렌더링하는 방법을 자세히 살펴봅니다.
게시물이 마음에 드셨나요? 향후 게시물에 관해 질문이나 제안이 있으면 아래 댓글 섹션이나 트위터의 @kosamari를 통해 알려주세요.