
מה קורה במהלך הניווט
זהו החלק השני מתוך סדרת 4 חלקים בבלוג שמציגה את האופן שבו פועל Chrome. בפוסט הקודם, התייחסנו לאופן שבו תהליכים וחוטים שונים מטפלים בחלקים שונים בדפדפן. בפוסט הזה נרחיב על האופן שבו כל תהליך ופתיחה בתהליך מתקשרים כדי להציג אתר.
נבחן תרחיש לדוגמה פשוט של גלישה באינטרנט: מקלידים כתובת URL בדפדפן, ואז הדפדפן מאחזר נתונים מהאינטרנט ומציג דף. בפוסט הזה נתמקד בחלק שבו משתמש מבקש אתר והדפדפן מתכונן להצגת דף – שנקרא גם ניווט.
הוא מתחיל בתהליך בדפדפן
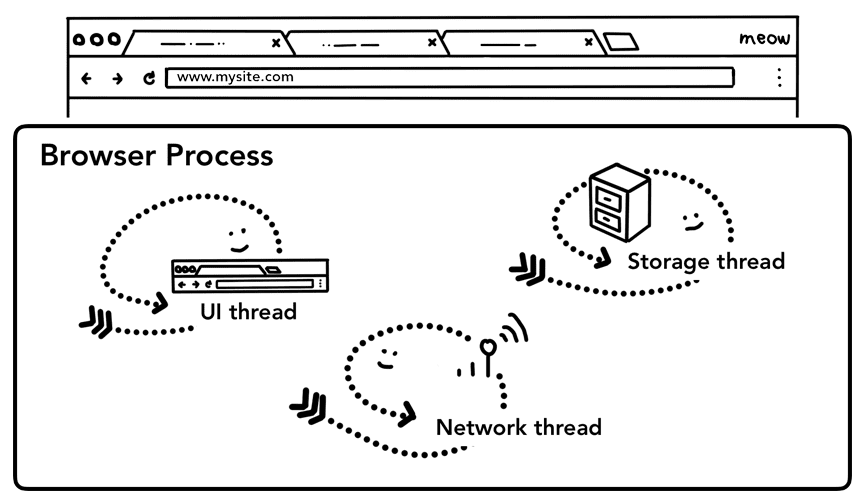
כפי שציינו בחלק 1: מעבד (CPU), מעבד גרפי (GPU), זיכרון וארכיטקטורה של תהליכים מרובים, כל מה שמחוץ לכרטיסייה מטופל על ידי תהליך הדפדפן. לתהליך הדפדפן יש מספר שרשראות, כמו שרשרת ממשק המשתמש שמשרטטת את הלחצנים ואת שדות הקלט של הדפדפן, שרשרת הרשת שמטפלת ב-stack הרשת כדי לקבל נתונים מהאינטרנט, שרשרת האחסון ששולטת בגישה לקבצים ועוד. כשמקלידים כתובת URL בסרגל הכתובות, הקלט מטופל על ידי שרשור ממשק המשתמש של תהליך הדפדפן.
ניווט פשוט
שלב 1: טיפול בקלט
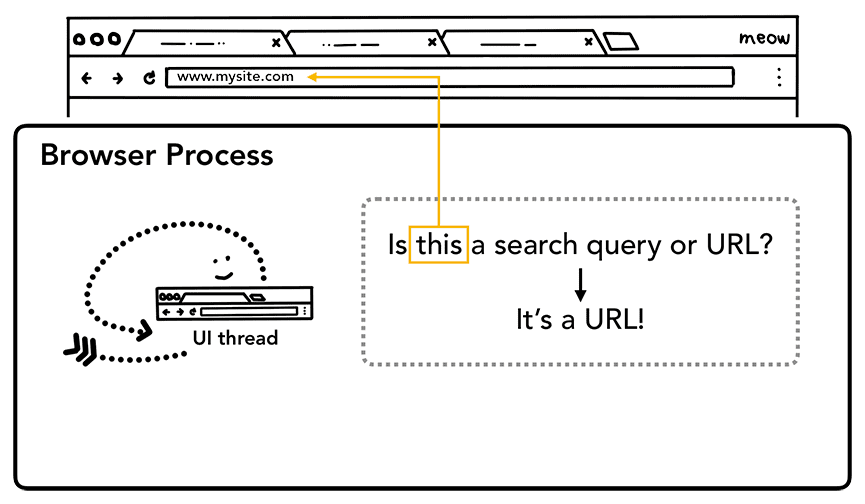
כשמשתמש מתחיל להקליד בסרגל הכתובות, השאלה הראשונה ששרשור ממשק המשתמש שואל היא "האם זו שאילתת חיפוש או כתובת URL?". ב-Chrome, סרגל הכתובות הוא גם שדה קלט לחיפוש, ולכן חוט ממשק המשתמש צריך לנתח את הקלט ולהחליט אם לשלוח אתכם למנוע חיפוש או לאתר שביקשת.
שלב 2: מתחילים בניווט
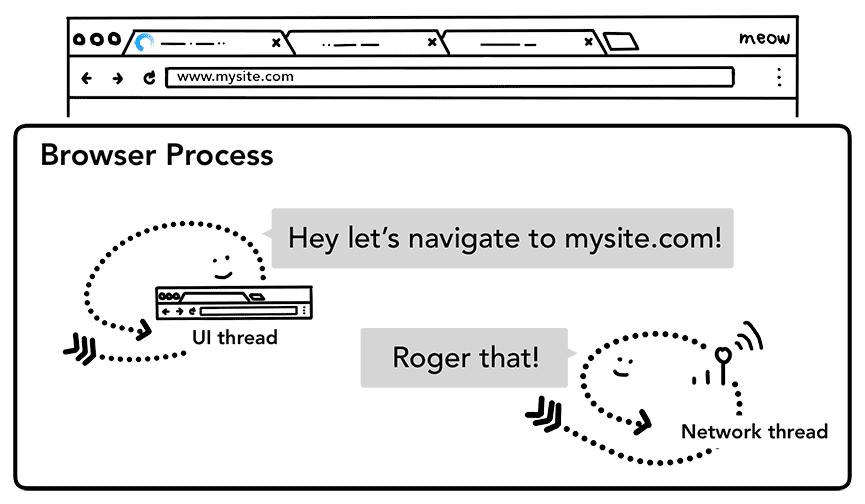
כשמשתמש מקשיב על Enter, שרשור ממשק המשתמש מתחיל קריאה לרשת כדי לקבל את תוכן האתר. ספינר הטעינה מוצג בפינה של הכרטיסייה, ושרשור הרשת עובר פרוטוקולים מתאימים כמו חיפוש DNS ויצירת חיבור TLS לבקשת הטעינה.
בשלב הזה, ייתכן ששרשור הרשת יקבל כותרת של הפניה אוטומטית מהשרת, כמו HTTP 301. במקרה כזה, שרשור הרשת יוצר קשר עם שרשור ממשק המשתמש כדי להודיע לו שהשרת מבקש הפניה אוטומטית. לאחר מכן תישלח בקשה נוספת לכתובת ה-URL.
שלב 3: קוראים את התשובה
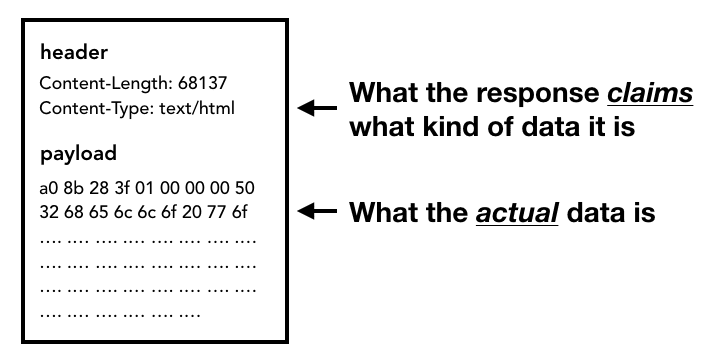
כשגוף התגובה (מטען שימושי) מתחיל להגיע, אם צריך, חוט הרשת בודק את הבייטים הראשונים של הסטרימינג. בכותרת Content-Type של התגובה צריך להופיע סוג הנתונים, אבל יכול להיות שהיא תהיה חסרה או שגויה, ולכן מתבצעת כאן ניפוי של סוג ה-MIME. זוהי 'בעיה מורכבת', כפי שצוין בקוד המקור. אפשר לקרוא את התגובה כדי לראות איך דפדפנים שונים מתייחסים לזוגות של סוג תוכן/מטען שימושי.
אם התגובה היא קובץ HTML, השלב הבא הוא להעביר את הנתונים לתהליך היצירה של הגרפיקה. אם התגובה היא קובץ ZIP או קובץ אחר, סימן שמדובר בבקשת הורדה, ולכן צריך להעביר את הנתונים למנהל ההורדות.
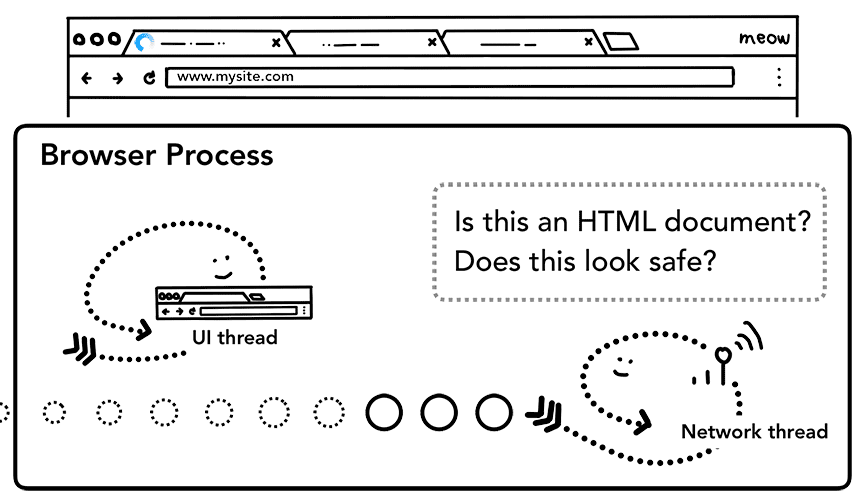
כאן מתבצעת גם בדיקת SafeBrowsing. אם הדומיין ונתוני התגובה נראים תואמים לאתר זדוני ידוע, השרשור ברשת מתריע על כך ומציג דף אזהרה. בנוסף, מתבצעת בדיקה של Cross Origin Read Blocking (CORB) כדי לוודא שנתונים רגישים באתרים שונים לא מגיעים לתהליך העיבוד.
שלב 4: חיפוש תהליך של עיבוד גרפיקה
אחרי שכל הבדיקות מסתיימות וחוטי הרשת בטוחים שהדפדפן צריך לנווט לאתר המבוקש, חוטי הרשת מדווחים לחוטי ממשק המשתמש שהנתונים מוכנים. לאחר מכן, חוט ממשק המשתמש מוצא תהליך עיבוד (renderer) כדי להמשיך את העיבוד של דף האינטרנט.
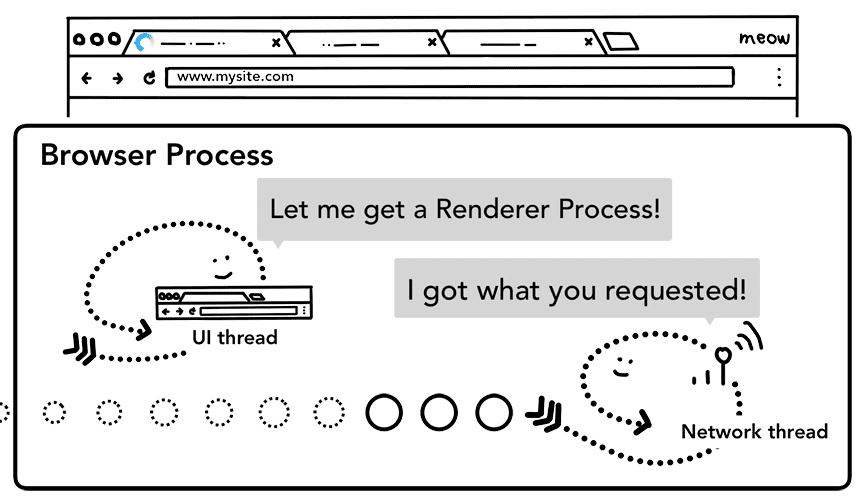
מכיוון שיכול להיות שיחלפו כמה מאות אלפיות השנייה עד לקבלת תשובה לבקשת הרשת, מתבצעת אופטימיזציה כדי לזרז את התהליך. כששרשור ממשק המשתמש שולח בקשת כתובת URL לשרשור הרשת בשלב 2, הוא כבר יודע לאיזה אתר המשתמשים מנווטים. שרשור ממשק המשתמש מנסה למצוא או להפעיל תהליך עיבוד במקביל לבקשת הרשת. כך, אם הכל מתנהל כצפוי, תהליך ה-renderer כבר נמצא במצב המתנה כששרשור הרשת מקבל נתונים. יכול להיות שלא נעשה שימוש בתהליך ההמתנה הזה אם הניווט מפנה לאתר אחר, ובמקרה כזה יכול להיות שיהיה צורך בתהליך אחר.
שלב 5: ביצוע השינויים בתפריט הניווט
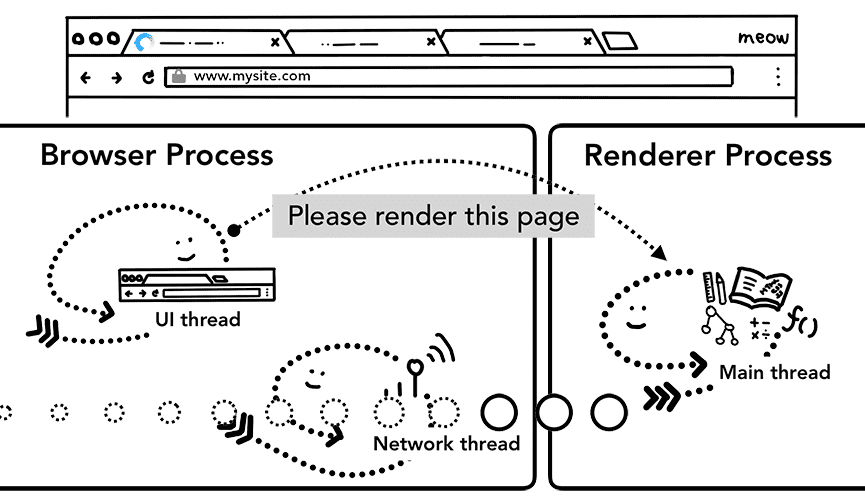
עכשיו, כשהנתונים ותהליך ה-renderer מוכנים, נשלחת בקשה מ-IPC מתהליך הדפדפן לתהליך ה-renderer כדי לאשר את הניווט. הוא גם מעביר את מקור הנתונים כדי שתהליך היצירה יוכל להמשיך לקבל נתוני HTML. אחרי שתהליך הדפדפן מקבל אישור שההתחייבות התרחשה בתהליך ה-renderer, הניווט מסתיים ומתחילה שלב טעינת המסמך.
בשלב הזה, סרגל הכתובות מתעדכן ואינדיקטור האבטחה וממשק המשתמש של הגדרות האתר משקפים את פרטי האתר בדף החדש. היסטוריית הסשן בכרטיסייה תתעדכן, כך שאפשר יהיה להשתמש בלחצני החזרה אחורה/קדימה כדי לעבור לאתר שאליו עברתם. כדי לאפשר שחזור של כרטיסייה או סשן כשסוגרים כרטיסייה או חלון, היסטוריית הסשנים מאוחסנת בדיסק.
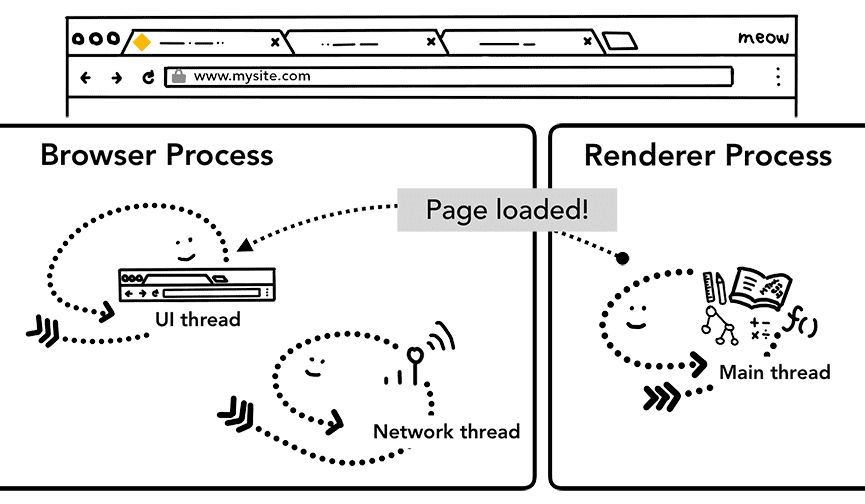
שלב נוסף: הטעינה הראשונית הושלמה
אחרי שהניווט מחויב, תהליך העיבוד ממשיך לטעון משאבים ולעבד את הדף. בפוסט הבא נסביר מה קורה בשלב הזה. אחרי שתהליך ה-renderer 'מסיים' את העיבוד, הוא שולח הודעה של IPC בחזרה לתהליך הדפדפן (זה קורה אחרי שכל אירועי onload מופעלים בכל המסגרות בדף וסיימו את הביצוע). בשלב הזה, שרשור ממשק המשתמש מפסיק את סימן הטעינה בכרטיסייה.
המשפט "מסתיים" מתייחס לכך שקוד JavaScript בצד הלקוח עדיין יכול לטעון משאבים נוספים ולייצר תצוגות חדשות אחרי הנקודה הזו.
ניווט לאתר אחר
הניווט הפשוט הושלם! אבל מה קורה אם משתמש מזין שוב כתובת URL שונה בסרגל הכתובות? תהליך הדפדפן עובר את אותם השלבים כדי לנווט לאתר אחר.
אבל לפני שהוא יכול לעשות זאת, הוא צריך לבדוק עם האתר שמוצג כרגע אם יש לו עניין באירוע beforeunload.
beforeunload יכול ליצור התראה מסוג 'רוצה לצאת מהאתר הזה?' כשמנסים לנווט אל דף אחר או לסגור את הכרטיסייה.
כל מה שנמצא בכרטיסייה, כולל קוד ה-JavaScript, מטופל על ידי תהליך ה-renderer, ולכן תהליך הדפדפן צריך לבדוק עם תהליך ה-renderer הנוכחי כשמגיעה בקשה חדשה לניווט.
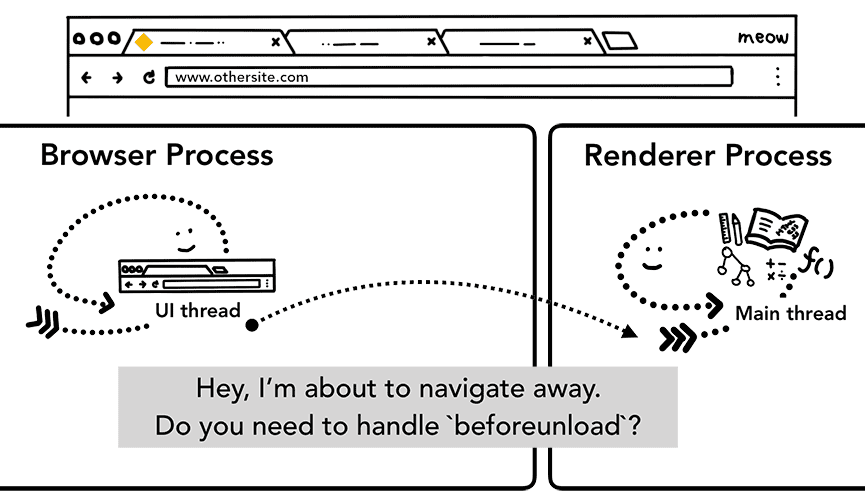
אם הניווט הופעל מתהליך ה-renderer (למשל, המשתמש לחץ על קישור או ש-JavaScript בצד הלקוח הפעיל את window.location = "https://newsite.com"), תהליך ה-renderer בודק קודם את הטיפולים של beforeunload. לאחר מכן, הוא עובר את אותו תהליך כמו ניווט שהופעל על ידי תהליך בדפדפן. ההבדל היחיד הוא שבקשת הניווט מופעלת מתהליך ה-renderer לתהליך הדפדפן.
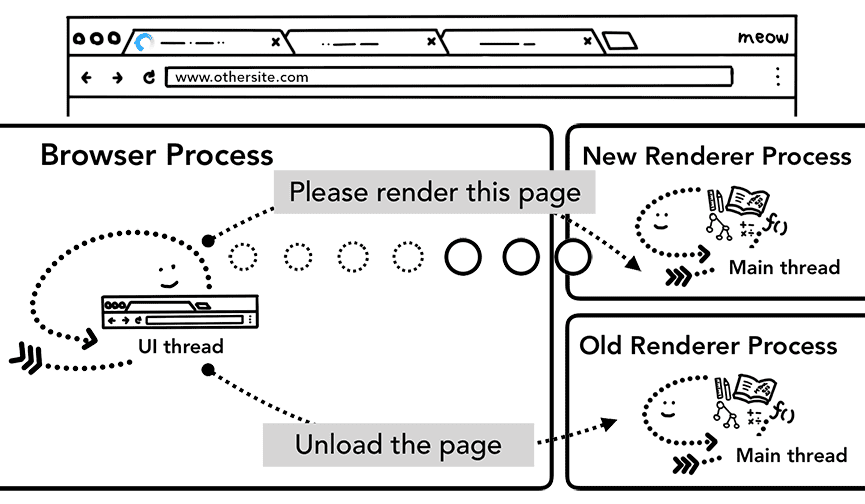
כשהניווט החדש מוביל לאתר אחר מזה שעבר עיבוד, נקרא תהליך עיבוד נפרד כדי לטפל בניווט החדש, בעוד שתהליך העיבוד הנוכחי נשאר כדי לטפל באירועים כמו unload. מידע נוסף זמין בסקירה כללית של מצבי מחזור החיים של דפים ובמאמר בנושא ה-API של מחזור החיים של דפים.
במקרה של Service Worker
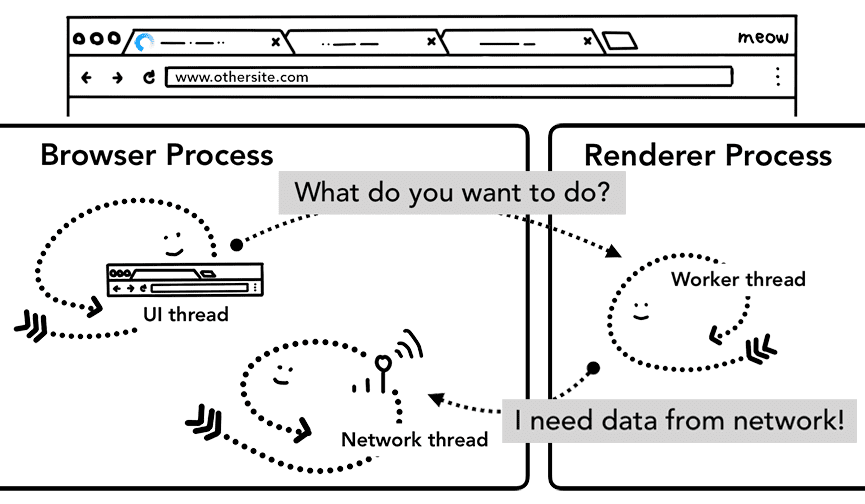
אחד השינויים האחרונים בתהליך הניווט הזה הוא ההשקה של service worker. קובץ שירות (service worker) הוא דרך לכתוב שרת proxy ברשת בקוד האפליקציה. כך למפתחי האינטרנט יש יותר שליטה על מה ששמור במטמון באופן מקומי ומתי לקבל נתונים חדשים מהרשת. אם ה-service worker מוגדר לטעון את הדף מהמטמון, אין צורך לבקש את הנתונים מהרשת.
חשוב לזכור ש-service worker הוא קוד JavaScript שפועל בתהליך רינדור. אבל כשמגיעה בקשת הניווט, איך תהליך בתוך הדפדפן יודע שלאתר יש שירות עובד?

כשרושמים עובד שירות, ההיקף שלו נשמר כמידע עזר (מידע נוסף על ההיקף זמין במאמר מחזור החיים של עובד השירות). כשמתרחשת ניווט, חוט הרשת בודק את הדומיין מול היקפי השירות הרשומים של ה-service worker. אם ה-service worker רשום לכתובת ה-URL הזו, חוט ממשק המשתמש מוצא תהליך עיבוד כדי להריץ את הקוד של ה-service worker. ה-service worker עשוי לטעון נתונים מהמטמון, וכך למנוע את הצורך לבקש נתונים מהרשת, או לבקש משאבים חדשים מהרשת.
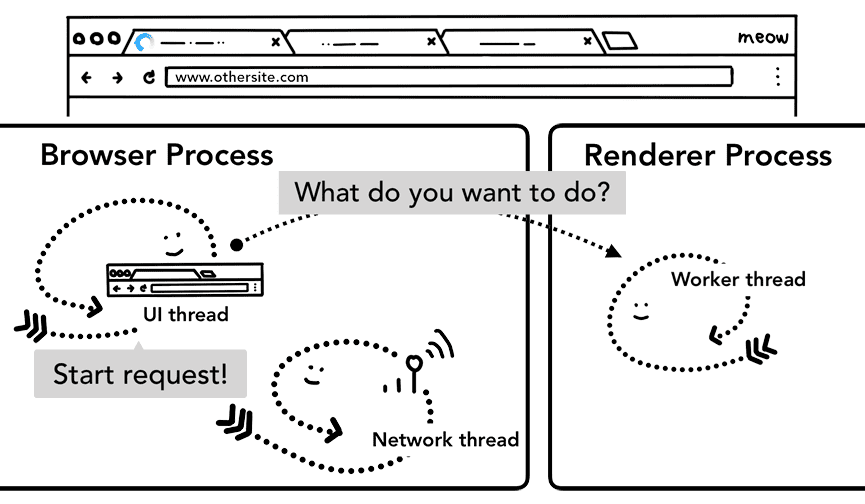
טעינה מראש של מסלולי ניווט
אפשר לראות שהנסיעה הלוך ושוב בין תהליך הדפדפן לתהליך ה-renderer עלולה לגרום לעיכובים אם עובד השירות יחליט לבקש נתונים מהרשת. טעינה מראש של ניווט היא מנגנון להאצת התהליך הזה, באמצעות טעינה של משאבים במקביל להפעלה של ה-service worker. המערכת מסמנת את הבקשות האלה בכותרת, ומאפשרת לשרתים להחליט לשלוח תוכן שונה עבור הבקשות האלה. לדוגמה, רק נתונים מעודכנים במקום מסמך מלא.
סיכום
בפוסט הזה התייחסנו למה שקורה במהלך ניווט, ואיך הקוד של אפליקציית האינטרנט, כמו כותרות התגובה ו-JavaScript בצד הלקוח, יוצר אינטראקציה עם הדפדפן. כשמבינים את השלבים שבהם הדפדפן עובר כדי לקבל נתונים מהרשת, קל יותר להבין למה פיתחו ממשקי API כמו טעינה מראש של ניווט. בפוסט הבא נסביר איך הדפדפן מעריך את ה-HTML, ה-CSS וה-JavaScript שלנו כדי להציג דפים.
הפוסט מצא חן בעיניך? אם יש לכם שאלות או הצעות לפוסט עתידי, אשמח לשמוע מכם בקטע התגובות שבהמשך או ב-@kosamari ב-Twitter.