
Cosa succede durante la navigazione
Questa è la seconda parte di una serie di 4 post del blog che esaminano il funzionamento interno di Chrome. Nel post precedente, abbiamo esaminato in che modo diversi processi e thread gestiscono parti diverse di un browser. In questo post, analizziamo più in dettaglio il modo in cui ogni processo e thread comunicano per visualizzare un sito web.
Esamineremo un semplice caso d'uso di navigazione web: digiti un URL in un browser, che recupera i dati da internet e mostra una pagina. In questo post ci concentreremo sulla parte in cui un utente richiede un sito e il browser si prepara a eseguire il rendering di una pagina, nota anche come navigazione.
Inizia con un processo del browser
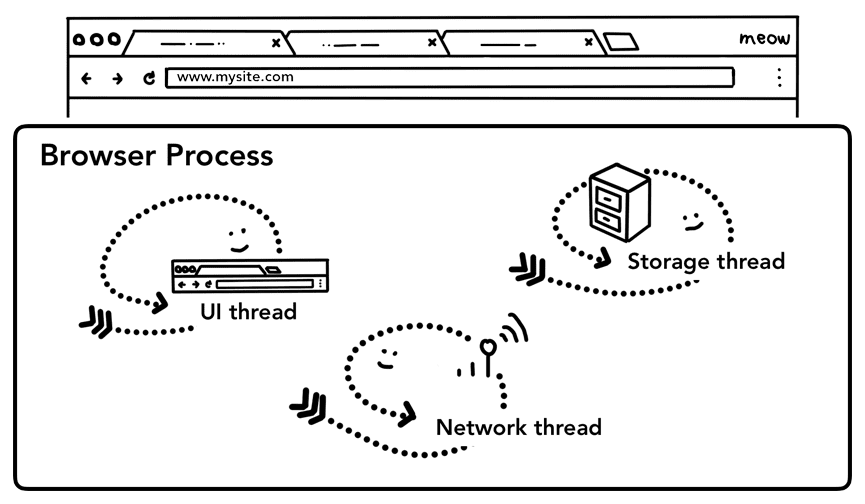
Come spiegato nella parte 1: CPU, GPU, memoria e architettura multiprocesso, tutto ciò che non si trova in una scheda viene gestito dal processo del browser. Il processo del browser ha thread come il thread dell'interfaccia utente che disegna i pulsanti e i campi di immissione del browser, il thread di rete che gestisce lo stack di rete per ricevere dati da internet, il thread di archiviazione che controlla l'accesso ai file e altro ancora. Quando digiti un URL nella barra degli indirizzi, l'input viene gestito dal thread dell'interfaccia utente del processo del browser.
Una navigazione semplice
Passaggio 1: gestione dell'input
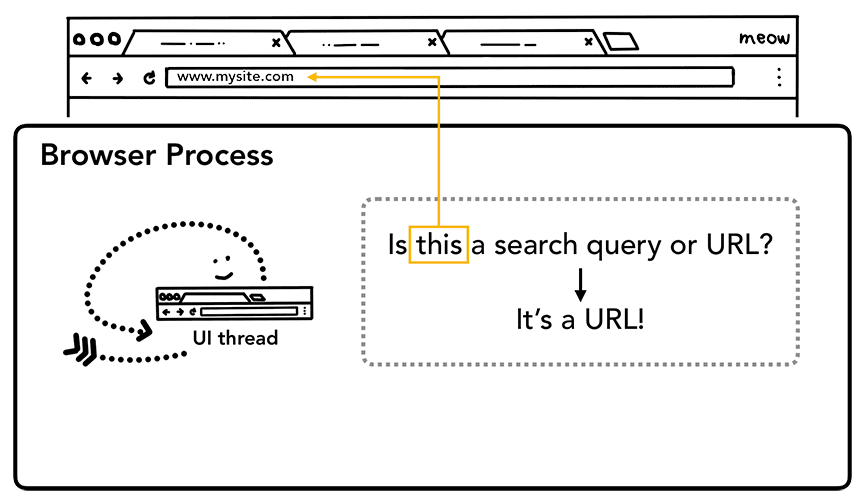
Quando un utente inizia a digitare nella barra degli indirizzi, la prima cosa che chiede il thread dell'interfaccia utente è "Si tratta di una query di ricerca o di un URL?". In Chrome, la barra degli indirizzi è anche un campo di immissione della ricerca, pertanto il thread dell'interfaccia utente deve analizzare e decidere se indirizzarti a un motore di ricerca o al sito che hai richiesto.
Passaggio 2: avvia la navigazione
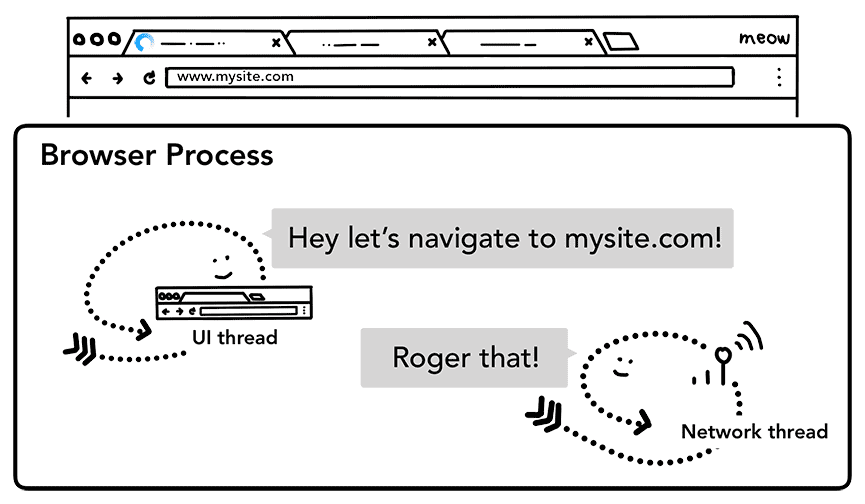
Quando un utente preme Invio, il thread dell'interfaccia utente avvia una chiamata di rete per recuperare i contenuti del sito. L'indicatore di caricamento viene visualizzato nell'angolo di una scheda e il thread di rete passa attraverso i protocolli appropriati, come la ricerca DNS e l'impostazione della connessione TLS per la richiesta.
A questo punto, il thread di rete potrebbe ricevere un'intestazione di reindirizzamento del server come HTTP 301. In questo caso, il thread di rete comunica al thread dell'interfaccia utente che il server sta richiedendo il reindirizzamento. A questo punto verrà avviata un'altra richiesta di URL.
Passaggio 3: leggi la risposta
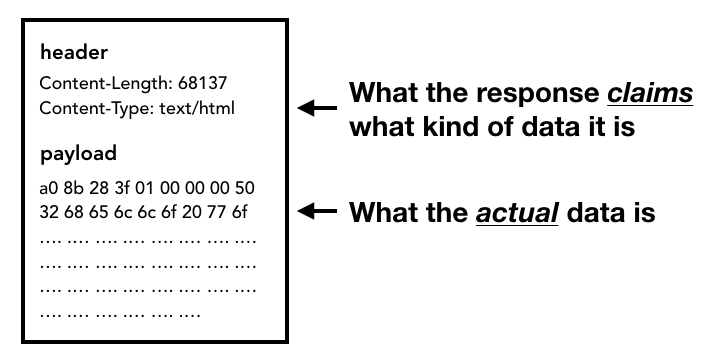
Quando inizia a essere visualizzato il corpo della risposta (payload), il thread di rete esamina i primi byte dello stream, se necessario. L'intestazione Content-Type della risposta dovrebbe indicare il tipo di dati, ma poiché potrebbe essere mancante o errata, viene eseguito qui lo sniffing del tipo MIME. Si tratta di una "questione complicata", come indicato nel codice sorgente. Puoi leggere il commento per vedere come i diversi browser trattano le coppie content-type/payload.
Se la risposta è un file HTML, il passaggio successivo consiste nel passare i dati al processo di rendering, ma se si tratta di un file ZIP o di un altro file, significa che si tratta di una richiesta di download, quindi i dati devono essere passati al gestore dei download.
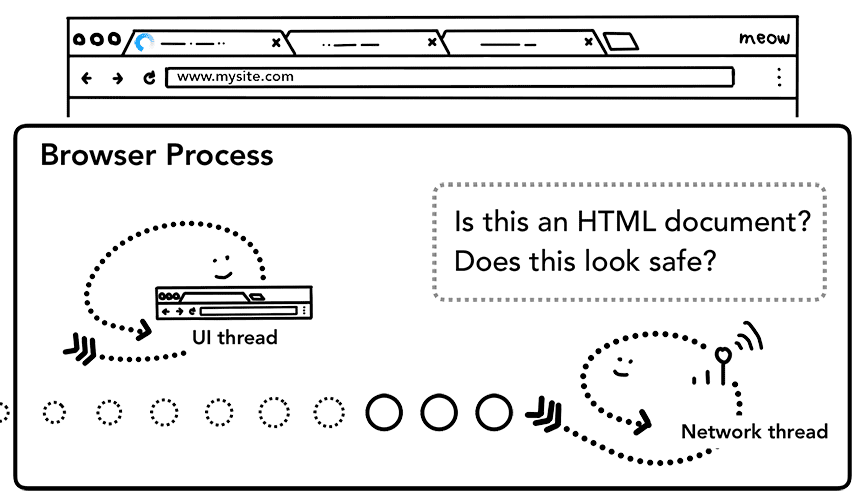
È qui che viene eseguito anche il controllo SafeBrowsing. Se il dominio e i dati di risposta sembrano corrispondere a un sito dannoso noto, il thread di rete avvisa di visualizzare una pagina di avviso. Inoltre, viene eseguito il controllo Block di Redazione di Browser tra Origini (CORB) per assicurarsi che i dati sensibili tra siti non raggiungano il processo di rendering.
Passaggio 4: trova un processo di rendering
Una volta completati tutti i controlli e quando il thread di rete è certo che il browser debba passare al sito richiesto, il thread di rete comunica al thread dell'interfaccia utente che i dati sono pronti. Il thread dell'interfaccia utente trova quindi un processo di rendering per continuare il rendering della pagina web.
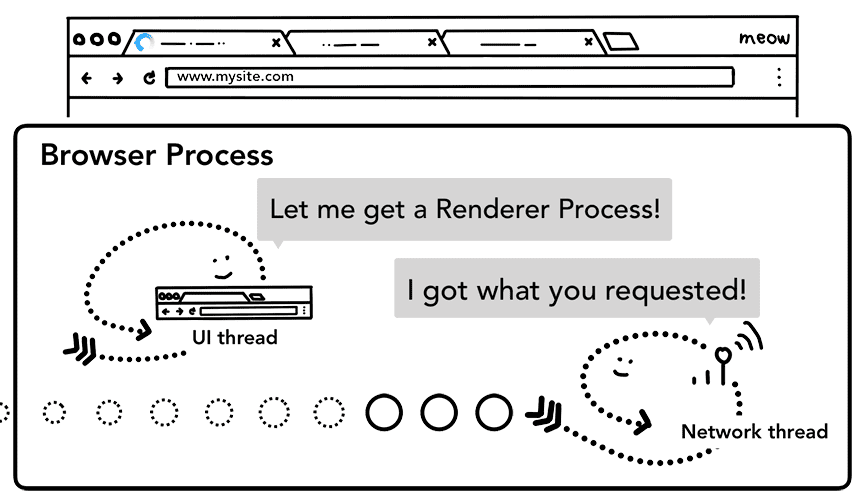
Poiché la richiesta di rete potrebbe richiedere diverse centinaia di millisecondi per ricevere una risposta, viene applicata un'ottimizzazione per velocizzare questo processo. Quando il thread dell'interfaccia utente invia una richiesta di URL al thread di rete nel passaggio 2, sa già a quale sito si sta accedendo. Il thread dell'interfaccia utente cerca di trovare o avviare in modo proattivo un processo di rendering in parallelo alla richiesta di rete. In questo modo, se tutto procede come previsto, un processo di rendering è già in posizione di standby quando il thread di rete ha ricevuto i dati. Questa procedura di attesa potrebbe non essere utilizzata se la navigazione reindirizza tra siti, nel qual caso potrebbe essere necessaria una procedura diversa.
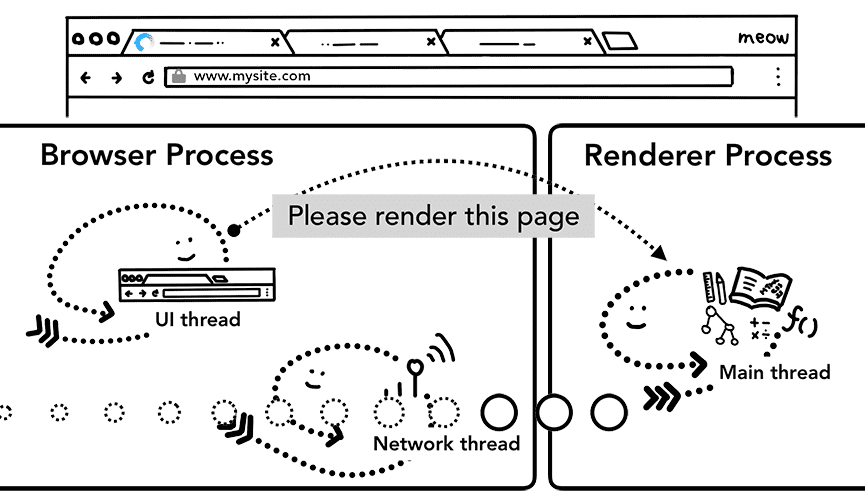
Passaggio 5: esegui il commit della navigazione
Ora che i dati e il processo di rendering sono pronti, viene inviato un IPC dal processo del browser al processo di rendering per confermare la navigazione. Inoltre, trasmette lo stream di dati in modo che il processo di rendering possa continuare a ricevere dati HTML. Una volta che il processo del browser riceve la conferma che il commit è avvenuto nel processo di rendering, la navigazione è completata e inizia la fase di caricamento del documento.
A questo punto, la barra degli indirizzi viene aggiornata e l'indicatore di sicurezza e l'interfaccia utente delle impostazioni del sito riflettono le informazioni sul sito della nuova pagina. La cronologia della sessione per la scheda verrà aggiornata in modo che i pulsanti Indietro/Avanti esaminino il sito a cui è stata appena eseguita la navigazione. Per facilitare il ripristino delle schede/sessioni quando chiudi una scheda o una finestra, la cronologia delle sessioni viene memorizzata su disco.
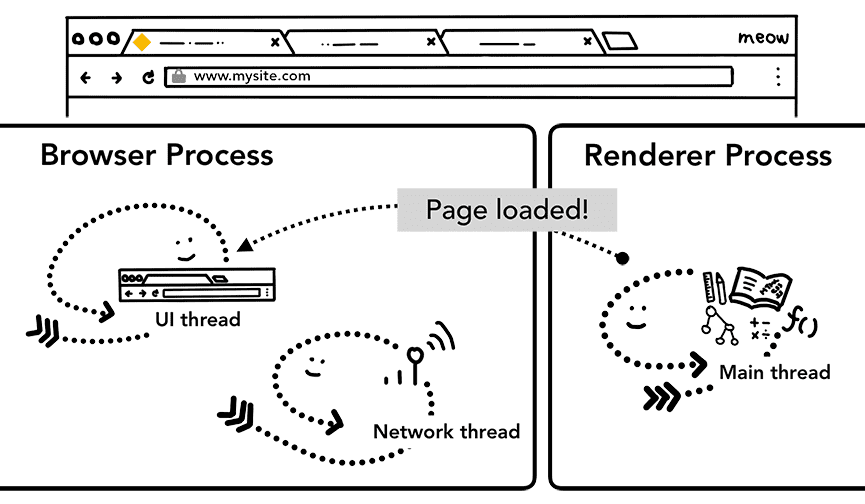
Passaggio extra: caricamento iniziale completato
Una volta confermata la navigazione, il processo di rendering continua a caricare le risorse e a eseguire il rendering della pagina. Nel prossimo post esamineremo i dettagli di cosa succede in questa fase. Una volta che il processo di
rendering del motore di rendering "termina", invia un IPC al processo del browser (dopo che tutti gli eventi onload sono stati attivati su tutti i frame della pagina e l'esecuzione è terminata). A questo punto, il thread dell'interfaccia utente interrompe la rotellina di caricamento nella scheda.
Dico "termina" perché JavaScript lato client potrebbe comunque caricare risorse aggiuntive e visualizzare nuove visualizzazioni dopo questo punto.
Navigazione verso un altro sito
La navigazione semplice è stata completata. Ma cosa succede se un utente inserisce di nuovo un URL diverso nella barra degli indirizzi? Il processo del browser segue gli stessi passaggi per passare a un sito diverso.
Tuttavia, prima di poterlo fare, deve verificare con il sito attualmente visualizzato se è interessato all'evento beforeunload.
beforeunload può creare l'avviso "Vuoi uscire da questo sito?" quando cerchi di uscire dalla pagina o chiudere la scheda.
Tutto ciò che si trova all'interno di una scheda, incluso il codice JavaScript, viene gestito dal processo di rendering, pertanto il processo del browser deve verificare il processo di rendering corrente quando arriva una nuova richiesta di navigazione.
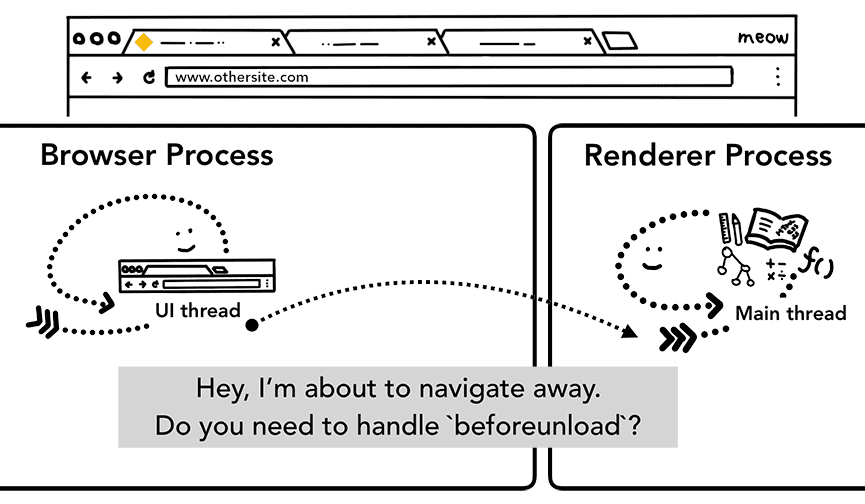
Se la navigazione è stata avviata dal processo di rendering (ad esempio se l'utente ha fatto clic su un link o se è stato eseguito JavaScript lato client window.location = "https://newsite.com"), il processo di rendering controlla prima gli handler beforeunload. Poi, viene eseguita la stessa procedura del processo del browser che ha avviato la navigazione. L'unica differenza è che la richiesta di navigazione viene avviata dal processo del visualizzatore al processo del browser.
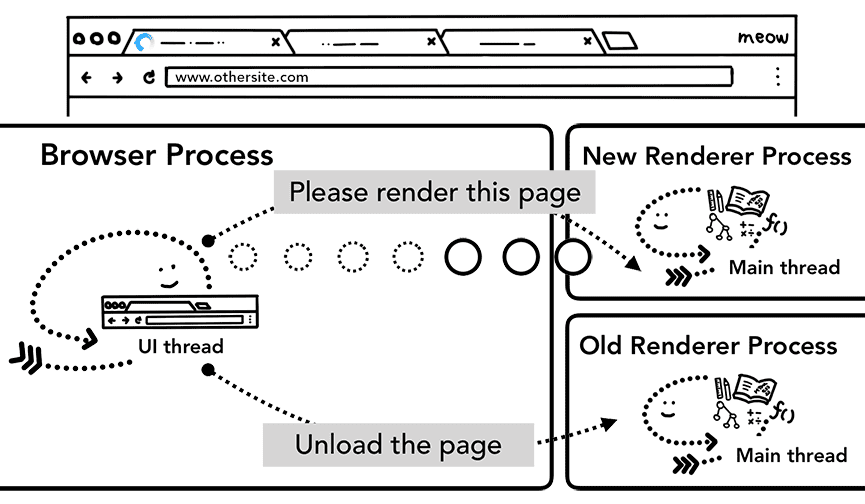
Quando la nuova navigazione viene eseguita su un sito diverso da quello attualmente visualizzato, viene chiamato un processo di rendering separato per gestire la nuova navigazione, mentre il processo di rendering corrente viene mantenuto per gestire eventi come unload. Per saperne di più, consulta la panoramica degli stati del ciclo di vita della pagina e scopri come eseguire il collegamento agli eventi con l'API Page Lifecycle.
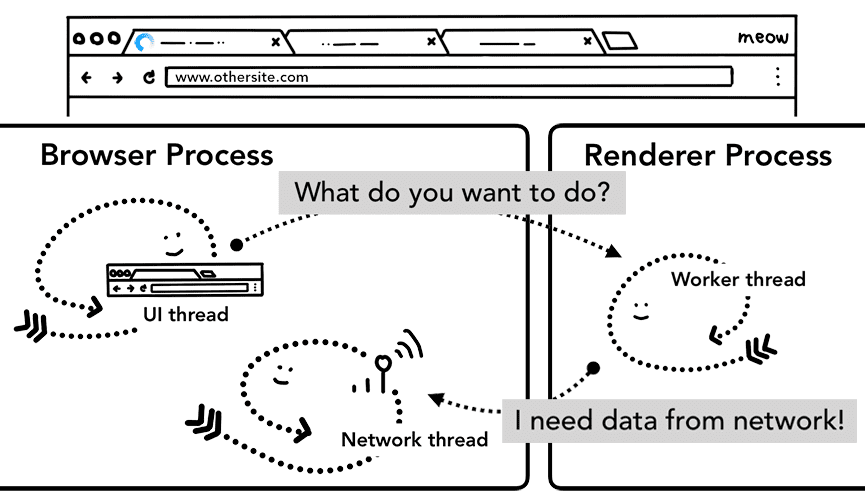
In caso di service worker
Una recente modifica a questo processo di navigazione è l'introduzione dei service worker. Il service worker è un modo per scrivere un proxy di rete nel codice dell'applicazione, consentendo agli sviluppatori web di avere un maggiore controllo su cosa memorizzare nella cache localmente e su quando ricevere nuovi dati dalla rete. Se il worker del servizio è impostato per caricare la pagina dalla cache, non è necessario richiedere i dati dalla rete.
L'aspetto importante da ricordare è che il worker del servizio è un codice JavaScript che viene eseguito in un processo di rendering. Ma quando arriva la richiesta di navigazione, come fa un processo del browser a sapere che il sito ha un service worker?

Quando un worker di servizio viene registrato, il relativo ambito viene mantenuto come riferimento (puoi scoprire di più sull'ambito in questo articolo Il ciclo di vita del worker di servizio). Quando si verifica una navigazione, il thread di rete controlla il dominio rispetto agli ambiti dei service worker registrati. Se è registrato un service worker per quell'URL, il thread dell'interfaccia utente trova un processo di rendering per eseguire il codice del service worker. Il worker di servizio può caricare i dati dalla cache, eliminando la necessità di richiederli dalla rete, oppure può richiedere nuove risorse dalla rete.
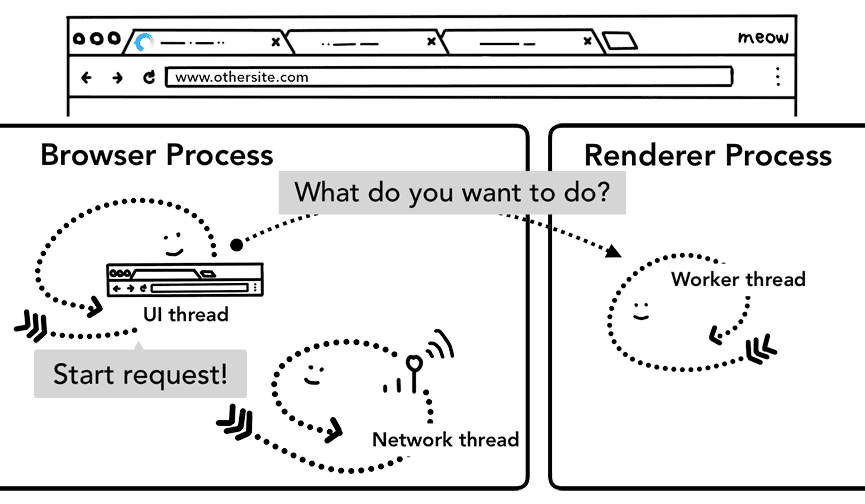
Precaricamento della navigazione
Puoi notare che questo round trip tra il processo del browser e il processo del renderer potrebbe comportare ritardi se il worker del servizio decide di richiedere dati dalla rete. Il precaricamento della navigazione è un meccanismo per velocizzare questo processo caricando le risorse in parallelo all'avvio del servizio worker. Contrassegni queste richieste con un'intestazione, consentendo ai server di decidere di inviare contenuti diversi per queste richieste, ad esempio solo i dati aggiornati anziché un documento completo.
Conclusione
In questo post abbiamo esaminato cosa succede durante una navigazione e in che modo il codice dell'applicazione web, ad esempio le intestazioni di risposta e JavaScript lato client, interagisce con il browser. Conoscere i passaggi che il browser segue per recuperare i dati dalla rete consente di capire più facilmente perché sono state sviluppate API come il precaricamento della navigazione. Nel prossimo post, analizzeremo in dettaglio il modo in cui il browser valuta il codice HTML/CSS/JavaScript per eseguire il rendering delle pagine.
Ti è piaciuto il post? Se hai domande o suggerimenti per i post futuri, non esitare a contattarmi nella sezione dei commenti di seguito o su Twitter all'indirizzo @kosamari.
Passaggio successivo: funzionamento interno di un processo di rendering