

La création de sites Web qui répondent rapidement aux entrées utilisateur est l'un des aspects les plus difficiles des performances Web, et l'équipe Chrome s'efforce d'aider les développeurs Web à y parvenir. Cette année, il a été annoncé que la métrique Interaction to Next Paint (INP) passerait du statut expérimental au statut en attente. Elle est désormais prête à remplacer First Input Delay (FID) en tant que métrique Core Web Vitals en mars 2024.
Dans le cadre de ses efforts continus pour fournir de nouvelles API qui aident les développeurs Web à rendre leurs sites Web aussi rapides que possible, l'équipe Chrome mène actuellement un essai Origin Trial pour scheduler.yield à partir de la version 115 de Chrome. scheduler.yield est une nouvelle proposition d'ajout à l'API Scheduler qui permet de céder le contrôle au thread principal de manière plus simple et plus efficace que les méthodes traditionnellement utilisées.
À propos de la cession
JavaScript utilise le modèle d'exécution jusqu'à la fin pour gérer les tâches. Cela signifie que lorsqu'une tâche s'exécute sur le thread principal, elle s'exécute aussi longtemps que nécessaire pour se terminer. Une fois la tâche terminée, le contrôle est cédé au thread principal, ce qui lui permet de traiter la tâche suivante dans la file d'attente.
Mis à part les cas extrêmes où une tâche ne se termine jamais (comme une boucle infinie, par exemple), la cession est un aspect inévitable de la logique de planification des tâches de JavaScript. Elle se produira, c'est juste une question de moment, et plus tôt est préférable à plus tard. Lorsque les tâches mettent trop de temps à s'exécuter (plus de 50 millisecondes, pour être exact), elles sont considérées comme des tâches longues.
Les tâches longues sont une source de mauvaise réactivité des pages, car elles retardent la capacité du navigateur à répondre aux entrées utilisateur. Plus les tâches longues sont fréquentes et plus elles s'exécutent longtemps, plus les utilisateurs risquent d'avoir l'impression que la page est lente, voire qu'elle est complètement défectueuse.
Toutefois, ce n'est pas parce que votre code lance une tâche dans le navigateur que vous devez attendre qu'elle soit terminée avant que le contrôle ne soit cédé au thread principal. Vous pouvez améliorer la réactivité aux entrées utilisateur sur une page en cédant explicitement le contrôle dans une tâche, ce qui permet de la terminer à la prochaine occasion disponible. Cela permet à d'autres tâches d'obtenir du temps sur le thread principal plus tôt que si elles devaient attendre la fin des tâches longues.
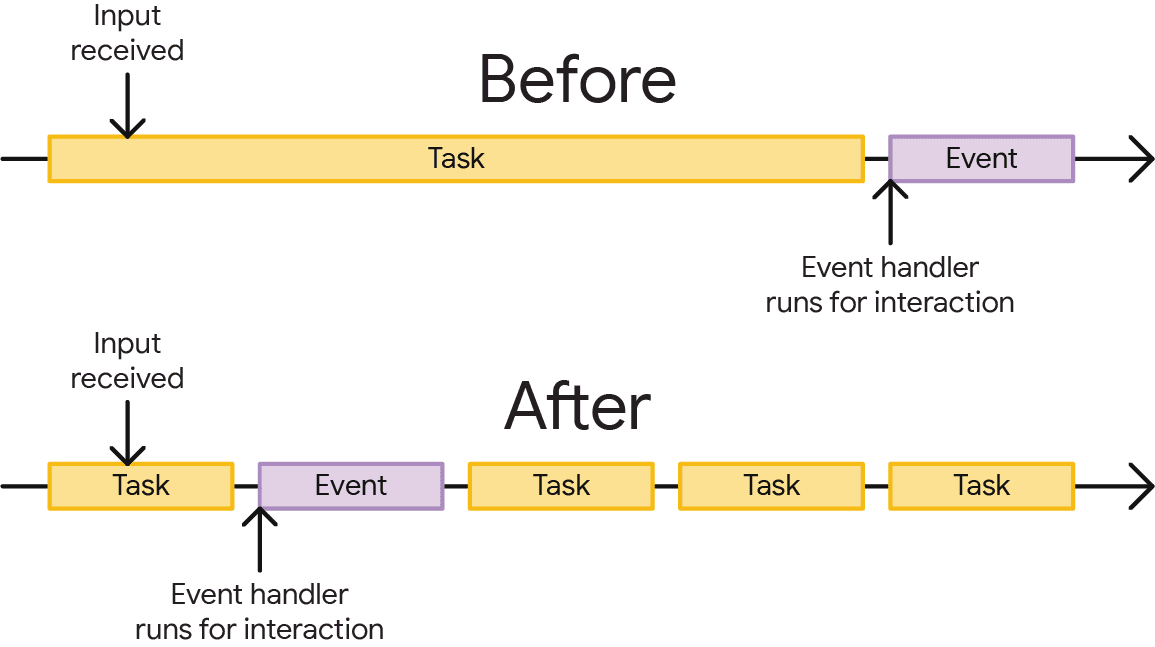
Lorsque vous cédez explicitement le contrôle, vous dites au navigateur : "Je comprends que le travail que je vais effectuer peut prendre un certain temps, et je ne veux pas que vous ayez à effectuer tout ce travail avant de répondre aux entrées utilisateur ou à d'autres tâches qui pourraient également être importantes". Il s'agit d'un outil précieux dans la boîte à outils d'un développeur qui peut grandement améliorer l'expérience utilisateur.
Problème avec les stratégies de cession actuelles
Une méthode courante de cession utilise setTimeout avec une valeur de délai d'attente de 0. Cela fonctionne, car le rappel transmis à setTimeout déplace le travail restant vers une tâche distincte qui sera mise en file d'attente pour une exécution ultérieure. Au lieu d'attendre que le navigateur cède le contrôle de lui-même, vous dites "divisez ce gros bloc de travail en plus petits morceaux".
Toutefois, la cession avec setTimeout a un effet secondaire potentiellement indésirable : le travail qui suit le point de cession est placé à la fin de la file d'attente des tâches. Les tâches planifiées par les interactions utilisateur sont toujours placées au début de la file d'attente, comme elles le devraient, mais le travail restant que vous souhaitiez effectuer après la cession explicite pourrait être davantage retardé par d'autres tâches provenant de sources concurrentes qui ont été mises en file d'attente avant lui.
Pour voir comment cela fonctionne, essayez cette démonstration Codepen ou expérimentez avec la version intégrée suivante. La démonstration comporte quelques boutons sur lesquels vous pouvez cliquer et une zone en dessous qui enregistre l'exécution des tâches. Lorsque vous accédez à la page, effectuez les actions suivantes :
- Cliquez sur le bouton en haut intitulé Run tasks periodically (Exécuter les tâches régulièrement), qui planifie l'exécution de tâches bloquantes de temps en temps. Lorsque vous cliquez sur ce bouton, le journal des tâches est rempli de plusieurs messages indiquant Ran blocking task with
setInterval(Exécution de la tâche bloquante avecsetInterval). - Cliquez ensuite sur le bouton intitulé Run loop, yielding with
setTimeouton each iteration (Exécuter la boucle, en cédant le contrôle avecsetTimeoutà chaque itération).
Vous remarquerez que la zone en bas de la démonstration affiche un message semblable à celui-ci :
Processing loop item 1
Processing loop item 2
Ran blocking task via setInterval
Processing loop item 3
Ran blocking task via setInterval
Processing loop item 4
Ran blocking task via setInterval
Processing loop item 5
Ran blocking task via setInterval
Ran blocking task via setInterval
Ce résultat illustre le comportement de "fin de file d'attente des tâches" qui se produit lors de la cession avec setTimeout. La boucle qui s'exécute traite cinq éléments et cède le contrôle avec setTimeout après le traitement de chacun d'eux.
Cela illustre un problème courant sur le Web : il n'est pas rare qu'un script, en particulier un script tiers, enregistre une fonction de minuteur qui exécute le travail à un certain intervalle. Le comportement de "fin de file d'attente des tâches" qui accompagne la cession avec setTimeout signifie que le travail provenant d'autres sources de tâches peut être mis en file d'attente avant le travail restant que la boucle doit effectuer après la cession.
Selon votre application, il peut s'agir ou non d'un résultat souhaitable, mais dans de nombreux cas, ce comportement est la raison pour laquelle les développeurs peuvent hésiter à céder le contrôle du thread principal aussi facilement. La cession est intéressante, car les interactions utilisateur ont la possibilité de s'exécuter plus tôt, mais elle permet également à d'autres tâches qui ne sont pas des interactions utilisateur d'obtenir du temps sur le thread principal. C'est un vrai problème, mais scheduler.yield peut vous aider à le résoudre.
Présentation de scheduler.yield
scheduler.yield est disponible derrière un commutateur en tant que fonctionnalité expérimentale de la plate-forme Web depuis la version 115 de Chrome. Vous vous demandez peut-être pourquoi vous avez besoin d'une fonction spéciale pour céder le contrôle alors que setTimeout le fait déjà.
Il est important de noter que la cession n'était pas un objectif de conception de setTimeout, mais plutôt un effet secondaire intéressant lors de la planification d'un rappel à exécuter ultérieurement, même avec une valeur de délai d'attente de 0 spécifiée. Toutefois, il est plus important de se rappeler que la cession avec setTimeout envoie le travail restant à la fin de la file d'attente des tâches. Par défaut, scheduler.yield envoie le travail restant au début de la file d'attente. Cela signifie que le travail que vous souhaitiez reprendre immédiatement après la cession ne sera pas relégué au second plan par rapport aux tâches provenant d'autres sources (à l'exception notable des interactions utilisateur).
scheduler.yield est une fonction qui cède le contrôle au thread principal et renvoie une Promise lorsqu'elle est appelée. Cela signifie que vous pouvez await dans une fonction async :
async function yieldy () {
// Do some work...
// ...
// Yield!
await scheduler.yield();
// Do some more work...
// ...
}
Pour voir scheduler.yield en action, procédez comme suit :
- Accédez à
chrome://flags. - Activez l'expérience Experimental Web Platform features (Fonctionnalités expérimentales de la plate-forme Web). Vous devrez peut-être redémarrer Chrome après cela.
- Accédez à la page de démonstration ou utilisez la version intégrée suivante après cette liste.
- Cliquez sur le bouton en haut intitulé Run tasks periodically (Exécuter les tâches régulièrement).
- Enfin, cliquez sur le bouton intitulé Run loop, yielding with
scheduler.yieldon each iteration (Exécuter la boucle, en cédant le contrôle avecscheduler.yieldà chaque itération).
Le résultat dans la zone en bas de la page se présente comme suit :
Processing loop item 1
Processing loop item 2
Processing loop item 3
Processing loop item 4
Processing loop item 5
Ran blocking task via setInterval
Ran blocking task via setInterval
Ran blocking task via setInterval
Ran blocking task via setInterval
Ran blocking task via setInterval
Contrairement à la démonstration qui cède le contrôle à l'aide de setTimeout, vous pouvez voir que la boucle, même si elle cède le contrôle après chaque itération, n'envoie pas le travail restant à la fin de la file d'attente, mais plutôt au début. Vous bénéficiez ainsi du meilleur des deux mondes : vous pouvez céder le contrôle pour améliorer la réactivité aux entrées sur votre site Web, mais aussi vous assurer que le travail que vous souhaitiez terminer après la cession n'est pas retardé.
Faites le test !
Si scheduler.yield vous intéresse et que vous souhaitez l'essayer, vous pouvez le faire de deux manières à partir de la version 115 de Chrome :
- Si vous souhaitez tester
scheduler.yieldlocalement, saisissezchrome://flagsdans la barre d'adresse de Chrome, puis appuyez sur Entrée et sélectionnez Activer dans le menu déroulant de la section Experimental Web Platform Features (Fonctionnalités expérimentales de la plate-forme Web).scheduler.yield(et toutes les autres fonctionnalités expérimentales) ne seront alors disponibles que dans votre instance de Chrome. - Si vous souhaitez activer
scheduler.yieldpour de vrais utilisateurs de Chromium sur une origine accessible au public, vous devez vous inscrire à l'essai Origin Trialscheduler.yield. Cela vous permet de tester en toute sécurité les fonctionnalités proposées pendant une période donnée et fournit à l'équipe Chrome des informations précieuses sur la façon dont ces fonctionnalités sont utilisées sur le terrain. Pour en savoir plus sur le fonctionnement des phases d'évaluation de l'origine, consultez ce guide.
La façon dont vous utilisez scheduler.yield, tout en prenant en charge les navigateurs qui ne l'implémentent pas, dépend de vos objectifs. Vous pouvez utiliser le polyfill officiel. Le polyfill est utile si les conditions suivantes s'appliquent à votre situation :
- Vous utilisez déjà
scheduler.postTaskdans votre application pour planifier des tâches. - Vous souhaitez pouvoir définir des priorités pour les tâches et la cession.
- Vous souhaitez pouvoir annuler ou redéfinir la priorité des tâches à l'aide de la classe
TaskControllerproposée par l'APIscheduler.postTask.
Si cela ne correspond pas à votre situation, le polyfill n'est peut-être pas fait pour vous. Dans ce cas, vous pouvez créer votre propre solution de secours de deux manières. La première approche utilise scheduler.yield s'il est disponible, mais revient à setTimeout s'il ne l'est pas :
// A function for shimming scheduler.yield and setTimeout:
function yieldToMain () {
// Use scheduler.yield if it exists:
if ('scheduler' in window && 'yield' in scheduler) {
return scheduler.yield();
}
// Fall back to setTimeout:
return new Promise(resolve => {
setTimeout(resolve, 0);
});
}
// Example usage:
async function doWork () {
// Do some work:
// ...
await yieldToMain();
// Do some other work:
// ...
}
Cela peut fonctionner, mais comme vous pouvez l'imaginer, les navigateurs qui ne sont pas compatibles avec scheduler.yield cèderont le contrôle sans le comportement "début de file d'attente". Si vous préférez ne pas céder le contrôle du tout, vous pouvez essayer une autre approche qui utilise scheduler.yield s'il est disponible, mais ne cède pas le contrôle du tout s'il ne l'est pas :
// A function for shimming scheduler.yield with no fallback:
function yieldToMain () {
// Use scheduler.yield if it exists:
if ('scheduler' in window && 'yield' in scheduler) {
return scheduler.yield();
}
// Fall back to nothing:
return;
}
// Example usage:
async function doWork () {
// Do some work:
// ...
await yieldToMain();
// Do some other work:
// ...
}
scheduler.yield est un ajout intéressant à l'API Scheduler, qui, espérons-le, permettra aux développeurs d'améliorer plus facilement la réactivité que les stratégies de cession actuelles. Si scheduler.yield vous semble être une API utile, veuillez participer à notre étude pour nous aider à l'améliorer et nous faire part de vos commentaires sur la façon dont elle pourrait être améliorée.
Image héros d' Unsplash, par Jonathan Allison.