
瞭解 WebAssembly 和 WebGPU 強化功能如何改善網頁上的機器學習效能。



網路上的 AI 推論
我們都知道 AI 正在改變世界。網路也不例外。
今年,Chrome 新增了生成式 AI 功能,包括自訂主題建立功能,或協助您撰寫初稿。但 AI 的用途遠不止於此,它還能豐富網路應用程式。
網頁可以嵌入智慧元件,用於視覺功能 (例如挑選臉孔或辨識手勢)、音訊分類或語言偵測。在過去一年,我們看到生成式 AI 技術蓬勃發展,其中包括一些令人驚豔的大型語言模型網頁示範。請務必參閱實用的裝置端 AI 技術,適用於網頁開發人員。
目前,許多裝置都支援網路上的 AI 推論功能,而且 AI 處理作業可在網頁本身執行,充分運用使用者裝置上的硬體。
這項功能的強大之處如下:
- 降低成本:在瀏覽器用戶端上執行推論作業可大幅降低伺服器成本,這對於 GenAI 查詢特別有用,因為這類查詢的成本可能比一般查詢高出好幾個數量級。
- 延遲:對於音訊或視訊應用程式等對延遲特別敏感的應用程式,如果所有處理作業都在裝置上執行,就能縮短延遲時間。
- 隱私權:在用戶端執行作業,也可能會開啟需要更高隱私權的新類型應用程式,因為資料無法傳送至伺服器。
AI 工作負載在目前網路上的運作方式
目前,應用程式開發人員和研究人員會使用框架建構模型,並透過 Tensorflow.js 或 ONNX Runtime Web 等執行階段在瀏覽器中執行模型,而執行階段則會使用 Web API 執行模型。
所有執行階段最終都會透過 JavaScript 或 WebAssembly 在 CPU 上執行,或是透過 WebGL 或 WebGPU 在 GPU 上執行。
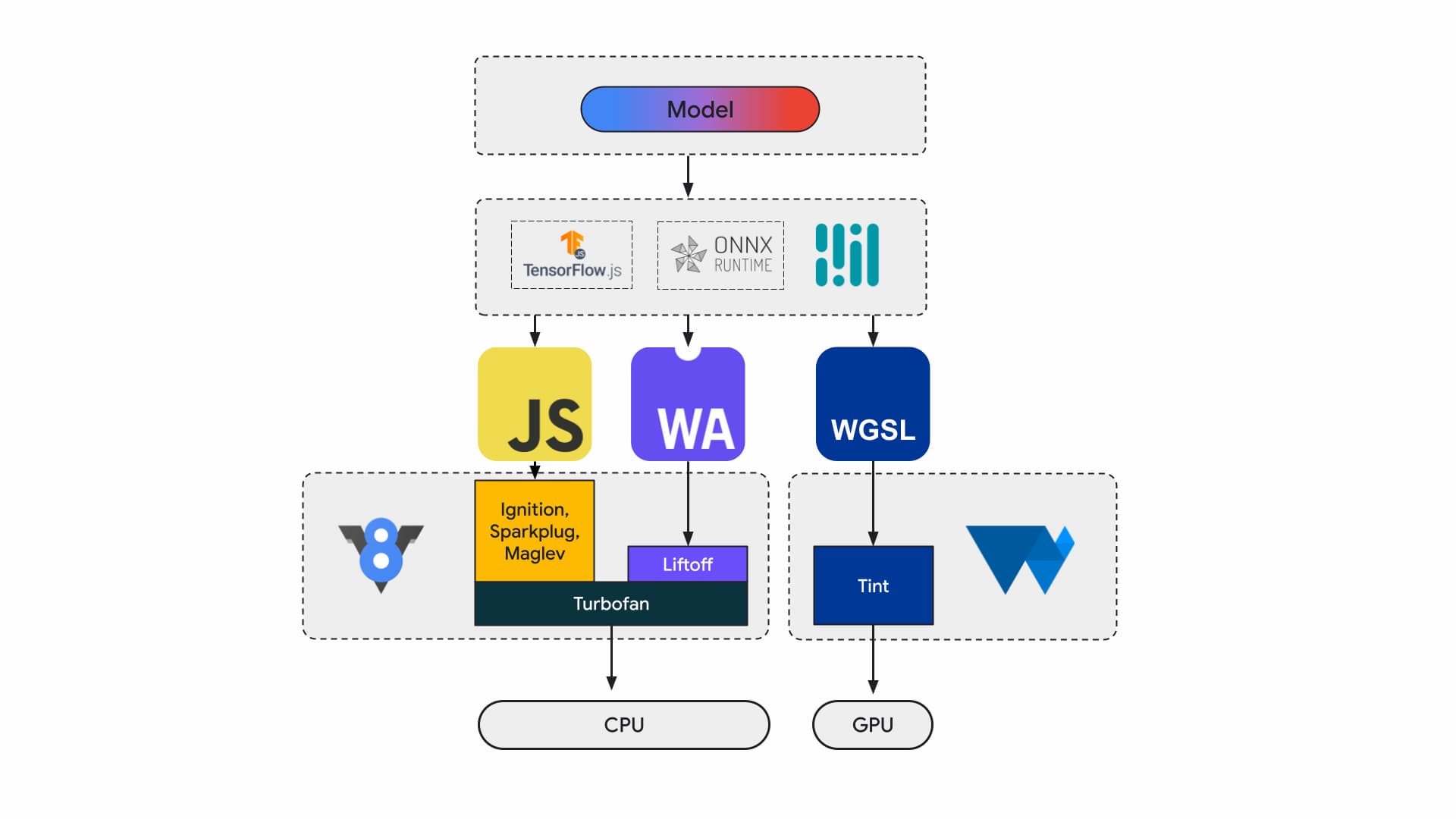
機器學習工作負載
機器學習 (ML) 工作負載會透過運算節點圖表推送張量。張量是這些節點的輸入和輸出,這些節點會對資料執行大量運算。
這點很重要,因為:
- 張量是相當龐大的資料結構,可對模型執行運算,而模型可能含有數十億個權重
- 縮放和推論可能會導致資料平行處理。也就是說,系統會在張量的所有元素上執行相同的作業。
- 機器學習不需要精確度。您可能需要 64 位元浮點數才能登陸月球,但臉部辨識可能只需要 8 位元以下的數字。
所幸,晶片設計人員已加入更多功能,讓模型運作速度更快、溫度更低,甚至可讓模型運作。
同時,WebAssembly 和 WebGPU 團隊也正在努力為網頁開發人員提供這些新功能。如果您是網頁應用程式開發人員,可能不會經常使用這些低階原始元素。我們預期您使用的工具鍊或架構會支援新功能和擴充功能,因此您只需對基礎架構進行最少的變更,就能享有這些好處。不過,如果您想手動調整應用程式以提升效能,這些功能就很實用。
WebAssembly
WebAssembly (Wasm) 是一種精簡且有效率的位元組程式碼格式,執行階段可瞭解及執行這類程式碼。這個功能旨在善用底層硬體功能,因此執行速度幾乎與原生速度相同。程式碼會在記憶體安全的沙箱環境中進行驗證及執行。
Wasm 模組資訊會以密集的二進位編碼表示。相較於文字格式,這表示解碼速度更快、載入速度更快,且記憶體用量較少。這項功能可移植,因為它不會對基礎架構做出假設,這些架構並非現代架構的常見架構。
WebAssembly 規格是迭代式規格,由開放的 W3C 社群團體負責。
二進位格式不會對主機環境做出任何假設,因此也能用於非網頁嵌入。
應用程式只需編譯一次,即可在所有裝置上執行,包括電腦、筆電、手機或任何其他裝置 (只要有瀏覽器即可)。如要進一步瞭解這項功能,請參閱「一次編寫,隨處執行,WebAssembly 終於實現這項功能」一文。
大多數在網站上執行 AI 推論的正式版應用程式都會使用 WebAssembly,用於 CPU 運算和與特殊用途運算介面。在原生應用程式中,您可以存取通用和特殊用途的運算功能,因為應用程式可以存取裝置功能。
在網頁上,為了確保可攜性和安全性,我們會仔細評估要公開哪些原始元素集。這樣一來,網頁的無障礙性和硬體提供的最佳效能就能取得平衡。
WebAssembly 是 CPU 的可移植抽象概念,因此所有 Wasm 推論都會在 CPU 上執行。雖然這不是效能最佳的選擇,但 CPU 在大多數裝置上都很常見,且可用於大多數工作負載。
對於較小的工作負載 (例如文字或音訊工作負載),GPU 的成本會很高。以下是近期許多適合使用 Wasm 的例子:
- Adobe 使用 Tensorflow.js 強化 Photoshop 網頁版。
- Google Meet 新增背景模糊效果,這是網路上首個採用 Wasm 的影片特效。
- YouTube 提供多種擴增實境效果。
- Google 相簿可讓你在線上編輯相片。
您還可以在開放原始碼示範中發現更多內容,例如:whisper-tiny、llama.cpp 和在瀏覽器中執行的 Gemma2B。
以全方位方式處理應用程式
您應根據特定機器學習模型、應用程式基礎架構,以及使用者預期的整體應用程式體驗,選擇原始元素
舉例來說,在 MediaPipe 的臉部地標偵測中,CPU 推論和 GPU 推論的效能相近 (在 Apple M1 裝置上執行),但有些模型的差異可能會大得多。
在機器學習工作負載方面,我們會從整體應用程式觀點出發,並傾聽架構作者和應用程式合作夥伴的意見,開發並推出最受歡迎的強化功能。這些問題大致分為以下三類:
- 公開對效能至關重要的 CPU 擴充功能
- 啟用較大型模型的執行功能
- 啟用與其他 Web API 的無縫互通功能
加快運算速度
目前,WebAssembly 規格只包含我們向網際網路公開的一組特定指令。但硬體會持續新增較新的指令,導致原生和 WebAssembly 效能之間的差距越來越大。
請注意,機器學習模型不一定需要高精確度。Relaxed SIMD 是一種提案,可減少一些嚴格的非決定性需求,進而加快對某些向量運算的 codegen,而這些運算是效能熱點。此外,Relaxed SIMD 還推出了新的點積積和和 FMA 指令,可將現有工作負載加快 1.5 至 3 倍。這項功能已在 Chrome 114 版中推出。
半精度浮點格式會將 16 位元用於 IEEE FP16,而非單精度值的 32 位元。與單精度值相比,使用半精度值有許多優點,包括減少記憶體需求,可訓練及部署較大的神經網路,以及減少記憶體頻寬。降低精確度可加快資料傳輸和數學運算速度。
大型模型
指向 Wasm 線性記憶體的指標會以 32 位元整數表示。這會導致兩個後果:堆積大小限制為 4GB (如果電腦的實體 RAM 容量大於這個值),且以 Wasm 為目標的應用程式程式碼必須與 32 位元指標大小相容。
尤其是像我們今天所使用的大型模型,將這些模型載入 WebAssembly 時可能會受到限制。Memory64 提案會移除這些限制,讓線性記憶體超過 4 GB,並與原生平台的位址空間相符。
我們已在 Chrome 中完成完整的實作,預計於今年稍晚推出。目前,您可以使用標記 chrome://flags/#enable-experimental-webassembly-features 執行實驗,並向我們提供意見回饋。
改善網頁互通性
WebAssembly 可能是網站上特殊用途運算的入口點。
WebAssembly 可用於將 GPU 應用程式帶入網頁。也就是說,只要稍微修改,在裝置上執行的 C++ 應用程式也可以在網路上執行。
Emscripten (Wasm 編譯器工具鍊) 已提供 WebGPU 繫結。這是網路上 AI 推論的進入點,因此 Wasm 必須能夠與其他網路平台無縫互動。我們正在這個領域中進行幾項不同的提案。
JavaScript Promise 整合 (JSPI)
一般 C 和 C++ (以及許多其他語言) 應用程式通常是針對同步 API 編寫。也就是說,應用程式會在作業完成前停止執行。相較於支援非同步作業的應用程式,這類阻斷應用程式通常更容易編寫。
耗時的作業會阻斷主執行緒,進而阻斷 I/O,使用者就會看到卡頓情形。原生應用程式的同步程式設計模式與網頁的非同步模式不相容。這對需要大量移植成本的舊版應用程式來說特別有問題。Emscripten 提供一種透過 Asyncify 執行此操作的方式,但這不一定是最佳做法,因為程式碼大小會變大,效率也會降低。
以下範例會使用 JavaScript 承諾來計算費波那契數列。
long promiseFib(long x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return promiseAdd(promiseFib(x - 1), promiseFib(x - 2));
}
// promise an addition
EM_ASYNC_JS(long, promiseAdd, (long x, long y), {
return Promise.resolve(x+y);
});
emcc -O3 fib.c -o b.html -s ASYNCIFY=2
在本例中,請留意以下事項:
EM_ASYNC_JS巨集會產生所有必要的黏合程式碼,讓我們可以使用 JSPI 存取承諾的結果,就像使用一般函式一樣。- 特殊指令列選項
-s ASYNCIFY=2。這會叫用產生程式碼的選項,該程式碼會使用 JSPI 與傳回承諾的 JavaScript 匯入內容進行介面。
如要進一步瞭解 JSPI、使用方式和優點,請參閱「在 v8.dev 推出 WebAssembly JavaScript Promise Integration API」。瞭解目前的來源測試。
記憶體控制
開發人員對 Wasm 記憶體的控制權非常有限,因為模組擁有自己的記憶體。任何需要存取此記憶體的 API 都必須複製進出,而這類用法可能會累積。舉例來說,圖像應用程式可能需要為每個影格進行複製和匯出作業。
記憶體控制提案旨在提供更精細的 Wasm 線性記憶體控制選項,並減少應用程式管道中的複本數量。這項提案目前處於第 1 階段,我們會在 V8 (Chrome 的 JavaScript 引擎) 中製作原型,以便根據標準的演進調整。
決定適合的後端
雖然 CPU 無所不在,但不一定是最佳選擇。在 GPU 或加速器上執行特殊用途運算,可提供數量級更高的效能,特別適用於大型模型和高階裝置。這適用於原生應用程式和網頁應用程式。
您選擇的後端取決於應用程式、架構或工具鍊,以及影響效能的其他因素。不過,我們會持續投入相關提案,讓核心 Wasm 能與其他網路平台 (特別是 WebGPU) 搭配使用。