


Independientemente del tipo de aplicación que desarrolles, optimizar su rendimiento y garantizar que se cargue rápido y ofrezca interacciones fluidas es fundamental para la experiencia del usuario y el éxito de la aplicación. Una forma de hacerlo es inspeccionar la actividad de una aplicación con herramientas de generación de perfiles para ver qué sucede en segundo plano mientras se ejecuta durante un período. El panel Rendimiento en Herramientas para desarrolladores es una excelente herramienta de generación de perfiles para analizar y optimizar el rendimiento de las aplicaciones web. Si tu app se ejecuta en Chrome, te brinda una descripción general visual detallada de lo que hace el navegador mientras se ejecuta tu aplicación. Comprender esta actividad puede ayudarte a identificar patrones, cuellos de botella y puntos críticos de rendimiento sobre los que puedes actuar para mejorar el rendimiento.
En el siguiente ejemplo, se explica cómo usar el panel Rendimiento.
Cómo configurar y recrear nuestra situación de generación de perfiles
Hace poco, establecimos el objetivo de mejorar el rendimiento del panel Rendimiento. En particular, queríamos que cargara grandes cantidades de datos de rendimiento más rápido. Este es el caso, por ejemplo, cuando se perfilan procesos complejos o de larga duración, o cuando se capturan datos de alta granularidad. Para lograrlo, primero se necesitó comprender cómo se ejecutaba la aplicación y por qué se ejecutaba de esa manera, lo que se logró con una herramienta de generación de perfiles.
Como tal vez sepas, DevTools es una aplicación web. Por lo tanto, se puede crear un perfil con el panel Rendimiento. Para crear un perfil de este panel, puedes abrir Herramientas para desarrolladores y, luego, abrir otra instancia de Herramientas para desarrolladores adjunta a él. En Google, esta configuración se conoce como DevTools-on-DevTools.
Una vez que la configuración esté lista, se debe recrear y registrar la situación que se analizará. Para evitar confusiones, la ventana original de las Herramientas para desarrolladores se denominará "primera instancia de las Herramientas para desarrolladores", y la ventana que inspecciona la primera instancia se denominará "segunda instancia de las Herramientas para desarrolladores".
En la segunda instancia de Herramientas para desarrolladores, el panel Rendimiento (que, de ahora en adelante, se llamará panel de rendimiento) observa la primera instancia de Herramientas para desarrolladores para recrear la situación, que carga un perfil.
En la segunda instancia de DevTools, se inicia una grabación en vivo, mientras que en la primera, se carga un perfil desde un archivo en el disco. Se carga un archivo grande para generar un perfil preciso del rendimiento del procesamiento de entradas grandes. Cuando ambas instancias terminan de cargarse, los datos de generación de perfiles de rendimiento, comúnmente llamados registro, se ven en la segunda instancia de Herramientas para desarrolladores del panel de rendimiento que carga un perfil.
El estado inicial: Identificar oportunidades de mejora
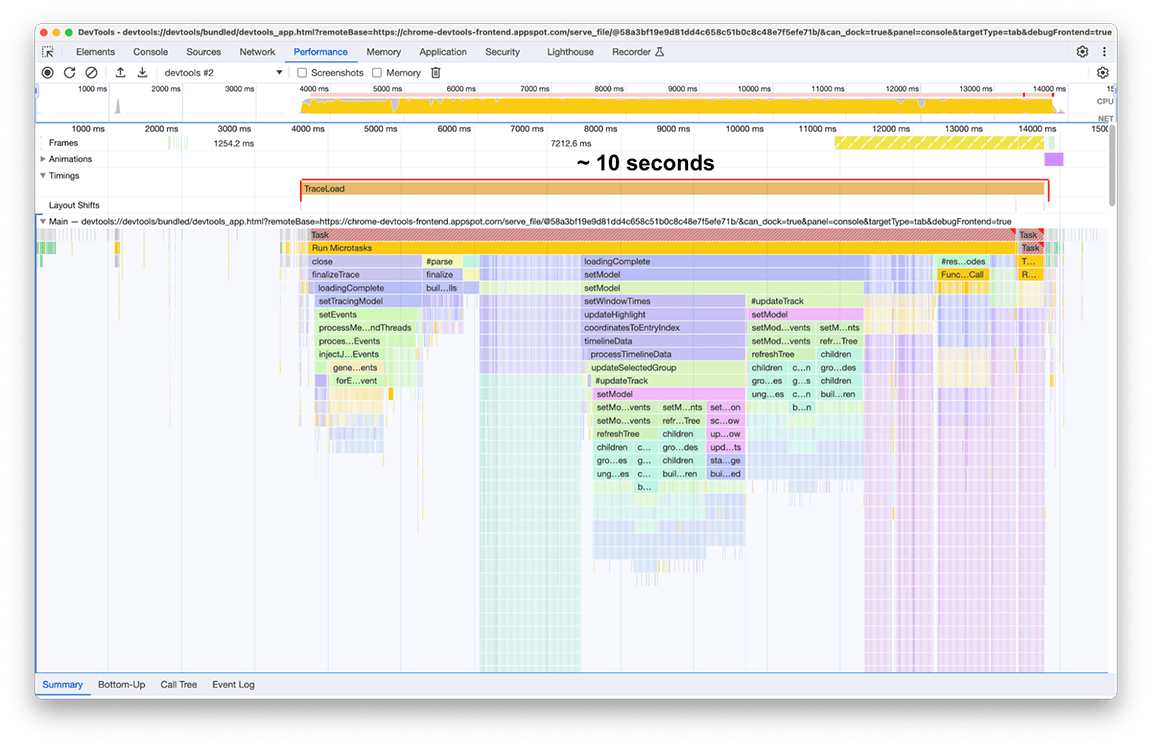
Una vez que finalizó la carga, se observó lo siguiente en nuestra segunda instancia del panel de rendimiento, como se muestra en la siguiente captura de pantalla. Enfócate en la actividad del subproceso principal, que se puede ver en el segmento etiquetado como Principal. Se puede observar que hay cinco grandes grupos de actividad en el gráfico de llamas. Consisten en las tareas en las que la carga tarda más tiempo. El tiempo total de estas tareas fue de aproximadamente 10 segundos. En la siguiente captura de pantalla, se usa el panel de rendimiento para enfocarse en cada uno de estos grupos de actividad y ver qué se puede encontrar.
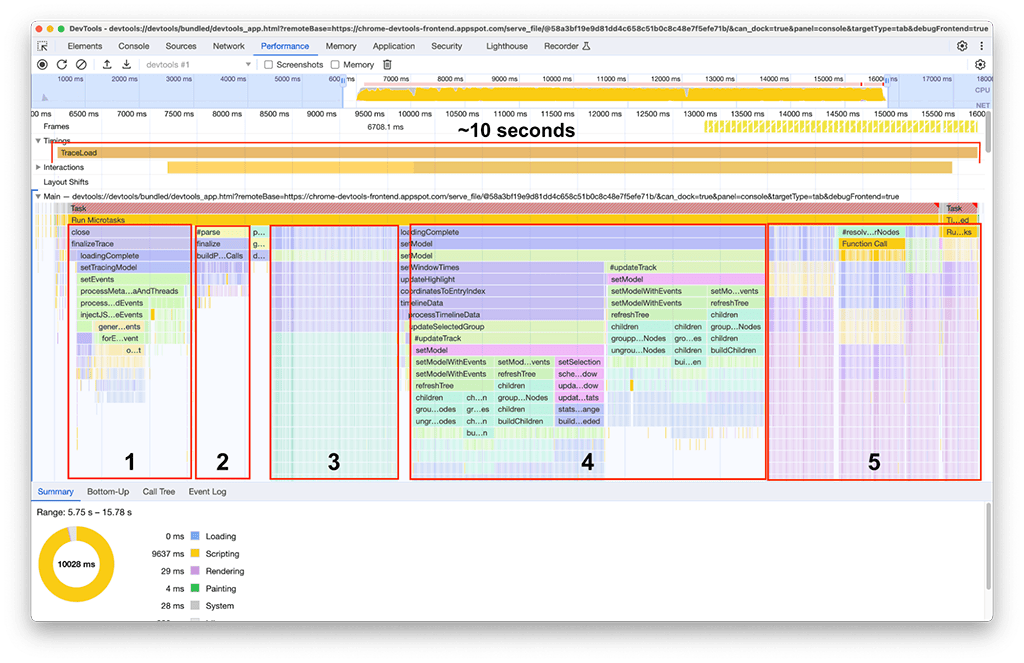
Primer grupo de actividades: Trabajo innecesario
Se hizo evidente que el primer grupo de actividad era código heredado que aún se ejecutaba, pero que no era realmente necesario. Básicamente, todo lo que se encuentra debajo del bloque verde etiquetado como processThreadEvents fue un esfuerzo desperdiciado. Esa fue una victoria rápida. Quitar esa llamada a la función ahorró alrededor de 1.5 segundos. Genial.
Segundo grupo de actividades
En el segundo grupo de actividades, la solución no fue tan simple como en el primero. La tarea buildProfileCalls tardó alrededor de 0.5 segundos y no se pudo evitar.
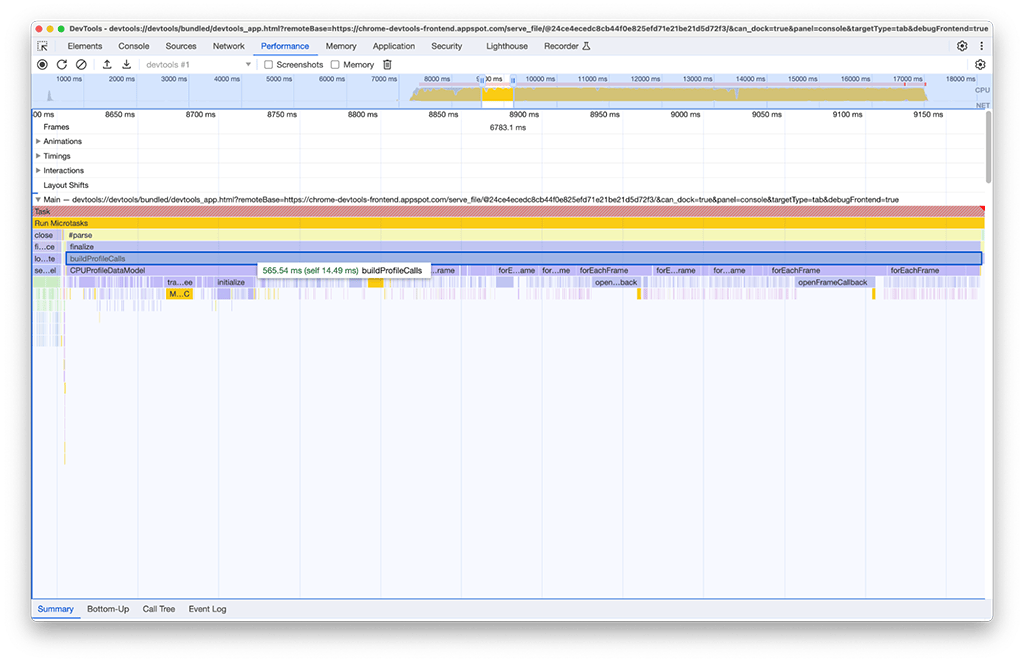
Por curiosidad, habilitamos la opción Memoria en el panel de rendimiento para investigar más a fondo y vimos que la actividad buildProfileCalls también usaba mucha memoria. Aquí, puedes ver cómo el gráfico de líneas azules salta repentinamente alrededor del momento en que se ejecuta buildProfileCalls, lo que sugiere una posible pérdida de memoria.
Para confirmar esta sospecha, usamos el panel Memoria (otro panel en Herramientas para desarrolladores, diferente del panel Memoria en el panel de rendimiento) para investigar. En el panel Memoria, se seleccionó el tipo de generación de perfiles "Muestreo de asignación", que registró la instantánea del montón para el panel de rendimiento que cargaba el perfil de CPU.
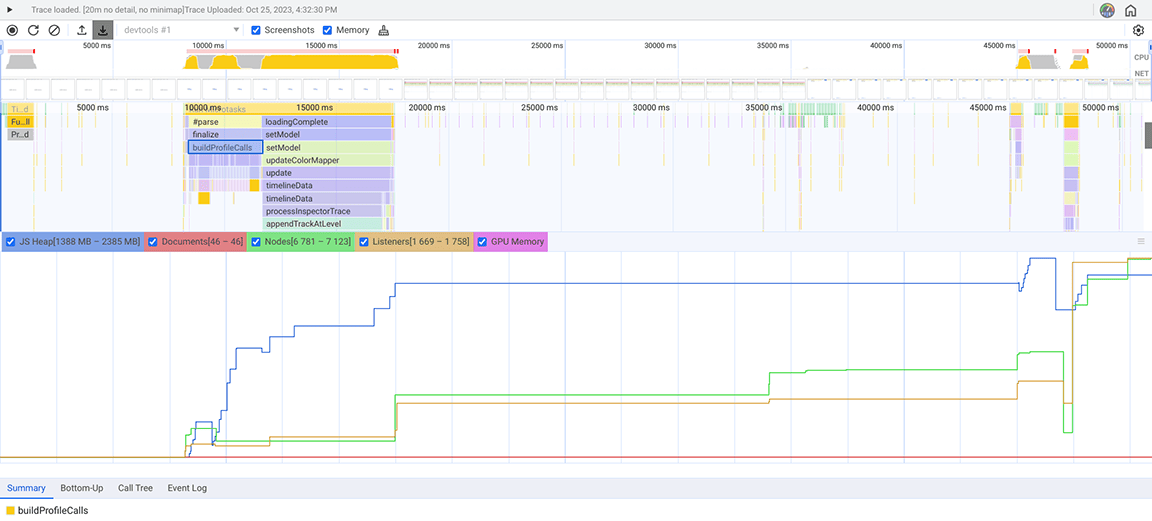
En la siguiente captura de pantalla, se muestra la instantánea del montón recopilada.
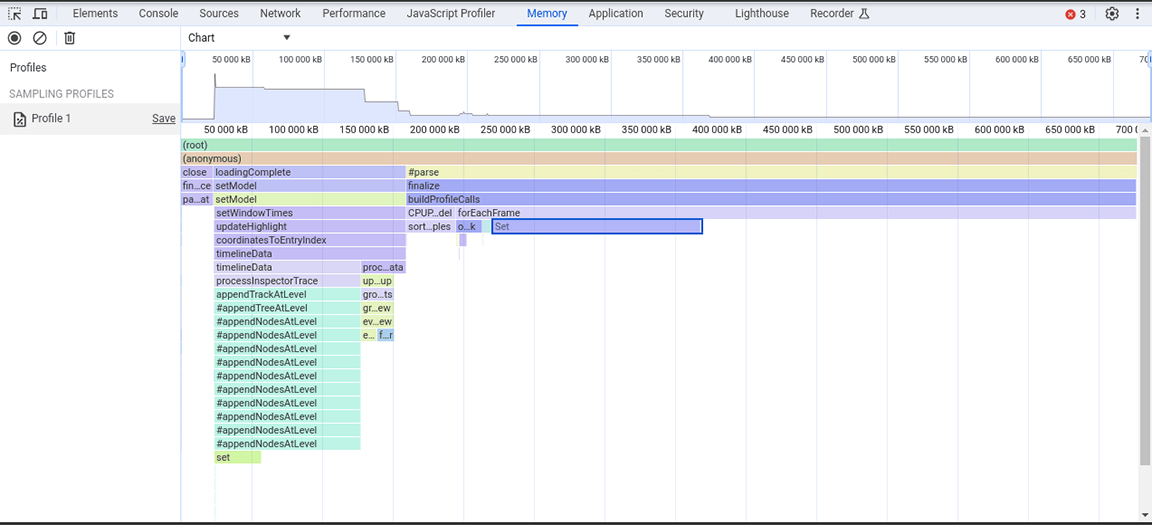
En esta instantánea del montón, se observó que la clase Set consumía mucha memoria. Al verificar los puntos de llamada, se descubrió que estábamos asignando innecesariamente propiedades de tipo Set a objetos que se creaban en grandes cantidades. Este costo se acumulaba y se consumía mucha memoria, hasta el punto de que era común que la aplicación fallara con entradas grandes.
Los conjuntos son útiles para almacenar elementos únicos y proporcionan operaciones que usan la singularidad de su contenido, como la anulación de duplicación de conjuntos de datos y la provisión de búsquedas más eficientes. Sin embargo, esas funciones no eran necesarias, ya que se garantizaba que los datos almacenados eran únicos desde la fuente. Por lo tanto, los conjuntos no eran necesarios en primer lugar. Para mejorar la asignación de memoria, el tipo de propiedad se cambió de Set a un array simple. Después de aplicar este cambio, se tomó otra instantánea del montón y se observó una reducción en la asignación de memoria. A pesar de no lograr mejoras considerables en la velocidad con este cambio, el beneficio secundario fue que la aplicación fallaba con menos frecuencia.
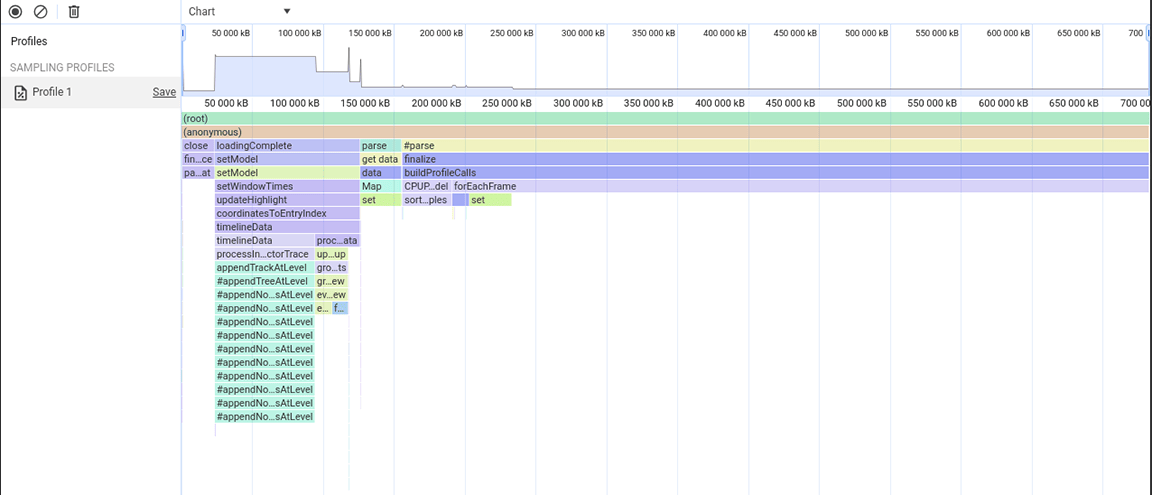
Tercer grupo de actividades: Sopesar las ventajas y desventajas de la estructura de datos
La tercera sección es peculiar: en el gráfico de llamas, se puede ver que consta de columnas estrechas pero altas, que denotan llamadas a funciones profundas y recursiones profundas en este caso. En total, esta sección duró alrededor de 1.4 segundos. Al observar la parte inferior de esta sección, se hizo evidente que el ancho de estas columnas estaba determinado por la duración de una función: appendEventAtLevel, lo que sugirió que podría ser un cuello de botella.
Dentro de la implementación de la función appendEventAtLevel, se destacó una cosa. Para cada entrada de datos en la entrada (que se conoce en el código como "evento"), se agregó un elemento a un mapa que realizaba un seguimiento de la posición vertical de las entradas del cronograma. Esto era problemático porque la cantidad de elementos almacenados era muy grande. Los mapas son rápidos para las búsquedas basadas en claves, pero esta ventaja no es gratuita. A medida que un mapa crece, agregarle datos puede, por ejemplo, volverse costoso debido al rehashing. Este costo se hace evidente cuando se agregan grandes cantidades de elementos al mapa de forma sucesiva.
/**
* Adds an event to the flame chart data at a defined vertical level.
*/
function appendEventAtLevel (event, level) {
// ...
const index = data.length;
data.push(event);
this.indexForEventMap.set(event, index);
// ...
}
Experimentamos con otro enfoque que no requería que agregáramos un elemento en un mapa para cada entrada del gráfico de llamas. La mejora fue significativa, lo que confirmó que el cuello de botella estaba relacionado con la sobrecarga que generaba agregar todos los datos al mapa. El tiempo que tardaba el grupo de actividades se redujo de alrededor de 1.4 segundos a alrededor de 200 milisegundos.
Antes:
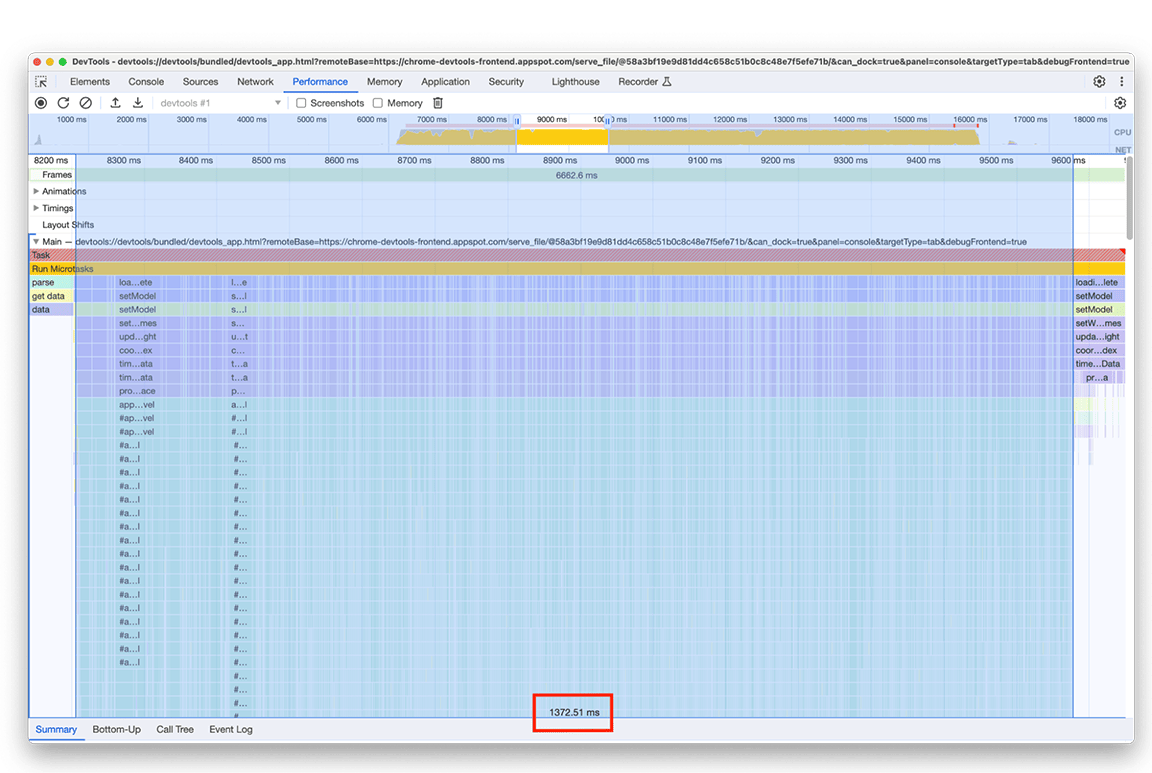
Después:
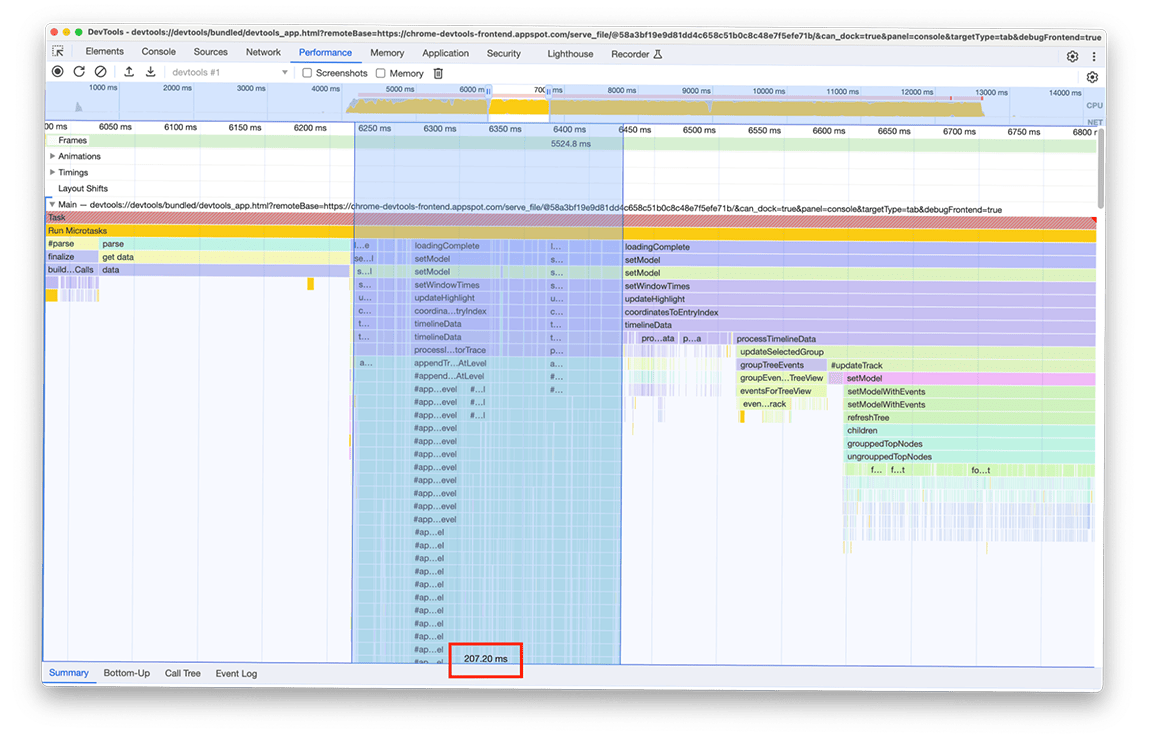
Cuarto grupo de actividades: Aplazar el trabajo no crítico y almacenar en caché los datos para evitar el trabajo duplicado
Si acercamos la imagen en esta ventana, se puede ver que hay dos bloques casi idénticos de llamadas a funciones. Si observas el nombre de las funciones llamadas, puedes inferir que estos bloques constan de código que crea árboles (por ejemplo, con nombres como refreshTree o buildChildren). De hecho, el código relacionado es el que crea las vistas de árbol en el panel inferior. Lo interesante es que estas vistas de árbol no se muestran inmediatamente después de la carga. En su lugar, el usuario debe seleccionar una vista de árbol (las pestañas "De abajo hacia arriba", "Árbol de llamadas" y "Registro de eventos" en el panel lateral) para que se muestren los árboles. Además, como se puede ver en la captura de pantalla, el proceso de creación del árbol se ejecutó dos veces.
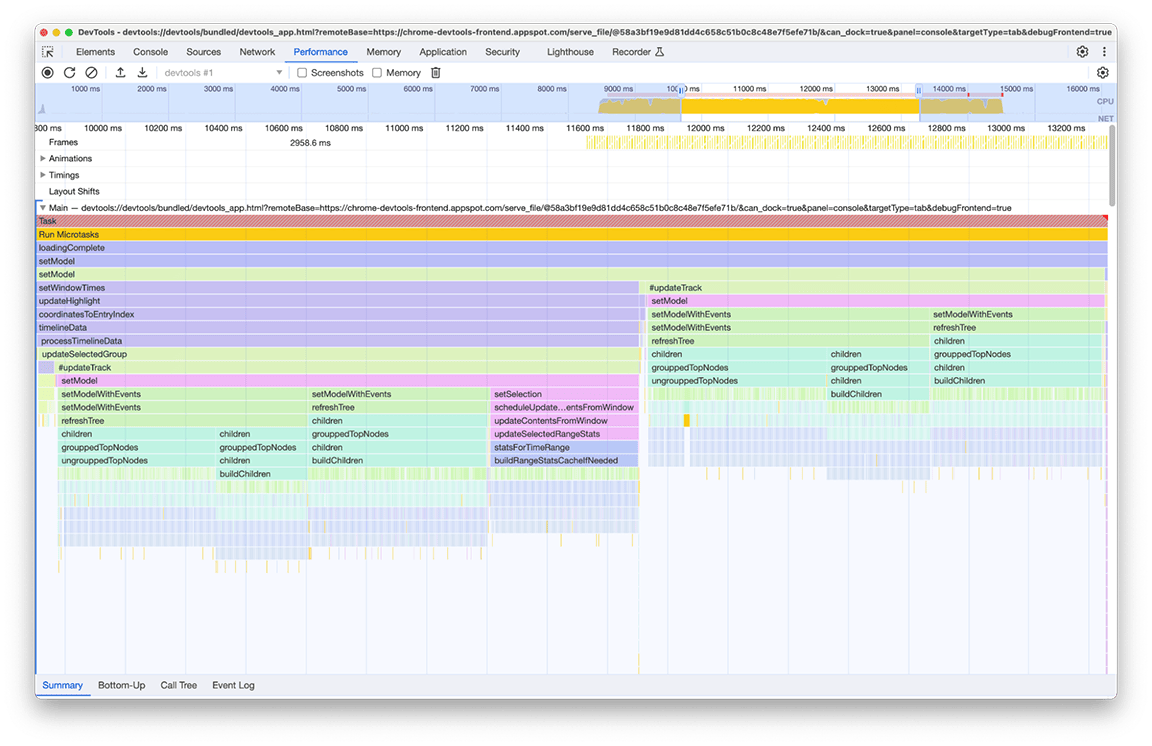
Identificamos dos problemas con esta imagen:
- Una tarea no crítica estaba obstaculizando el rendimiento del tiempo de carga. Los usuarios no siempre necesitan su resultado. Por lo tanto, la tarea no es fundamental para la carga del perfil.
- El resultado de estas tareas no se almacenó en caché. Por eso, los árboles se calcularon dos veces, a pesar de que los datos no cambiaron.
Comenzamos por aplazar el cálculo del árbol hasta que el usuario abriera manualmente la vista de árbol. Solo entonces vale la pena pagar el precio de crear estos árboles. El tiempo total de ejecución de esta acción dos veces fue de alrededor de 3.4 segundos, por lo que diferirla generó una diferencia significativa en el tiempo de carga. También estamos investigando el almacenamiento en caché de este tipo de tareas.
Quinto grupo de actividades: Evita las jerarquías de llamadas complejas siempre que sea posible
Al observar este grupo de cerca, quedó claro que se invocaba una cadena de llamadas en particular de forma repetida. El mismo patrón apareció 6 veces en diferentes lugares del gráfico de llamas, y la duración total de esta ventana fue de aproximadamente 2.4 segundos.
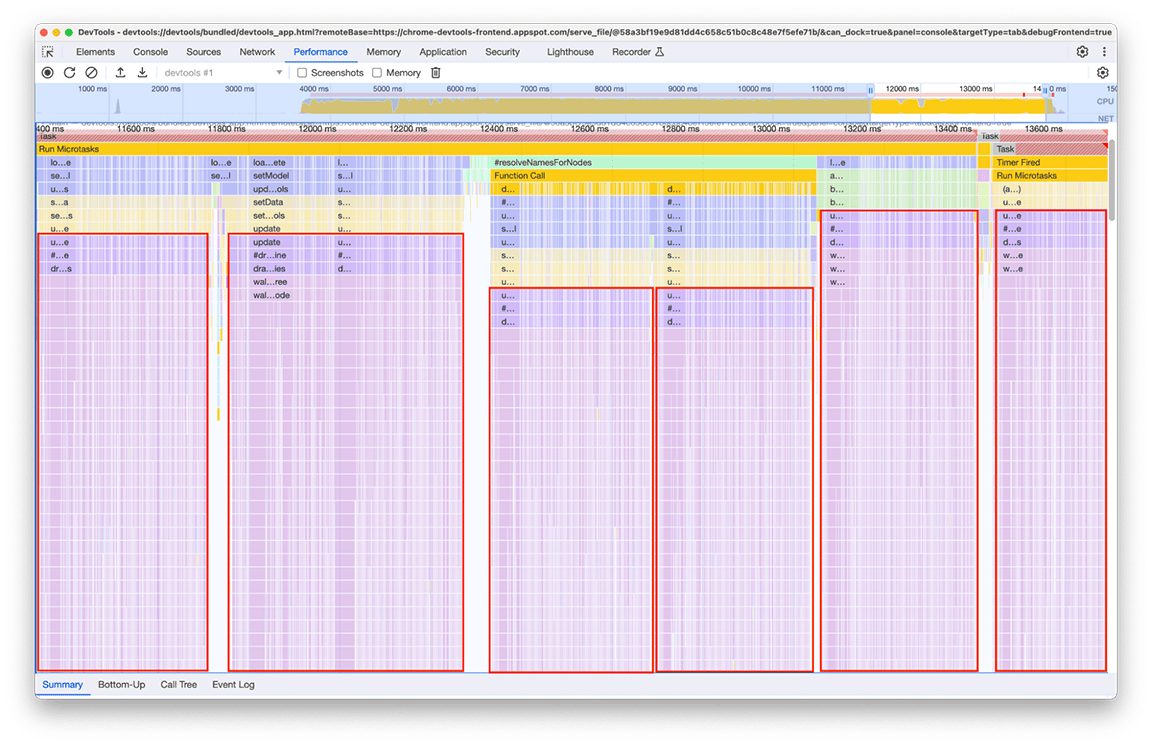
El código relacionado que se llama varias veces es la parte que procesa los datos que se renderizarán en el "minimapa" (el resumen de la actividad de la línea de tiempo en la parte superior del panel). No estaba claro por qué sucedía varias veces, pero, sin duda, no tenía que suceder 6 veces. De hecho, el resultado del código debería permanecer actual si no se carga ningún otro perfil. En teoría, el código solo debería ejecutarse una vez.
Tras la investigación, se descubrió que el código relacionado se llamaba como consecuencia de que varias partes de la canalización de carga llamaban directa o indirectamente a la función que calcula el mapa en miniatura. Esto se debe a que la complejidad del gráfico de llamadas del programa evolucionó con el tiempo y se agregaron más dependencias a este código sin saberlo. No hay una solución rápida para este problema. La forma de resolverlo depende de la arquitectura de la base de código en cuestión. En nuestro caso, tuvimos que reducir un poco la complejidad de la jerarquía de llamadas y agregar una verificación para evitar la ejecución del código si los datos de entrada permanecían sin cambios. Después de implementar esto, obtuvimos la siguiente perspectiva del cronograma:
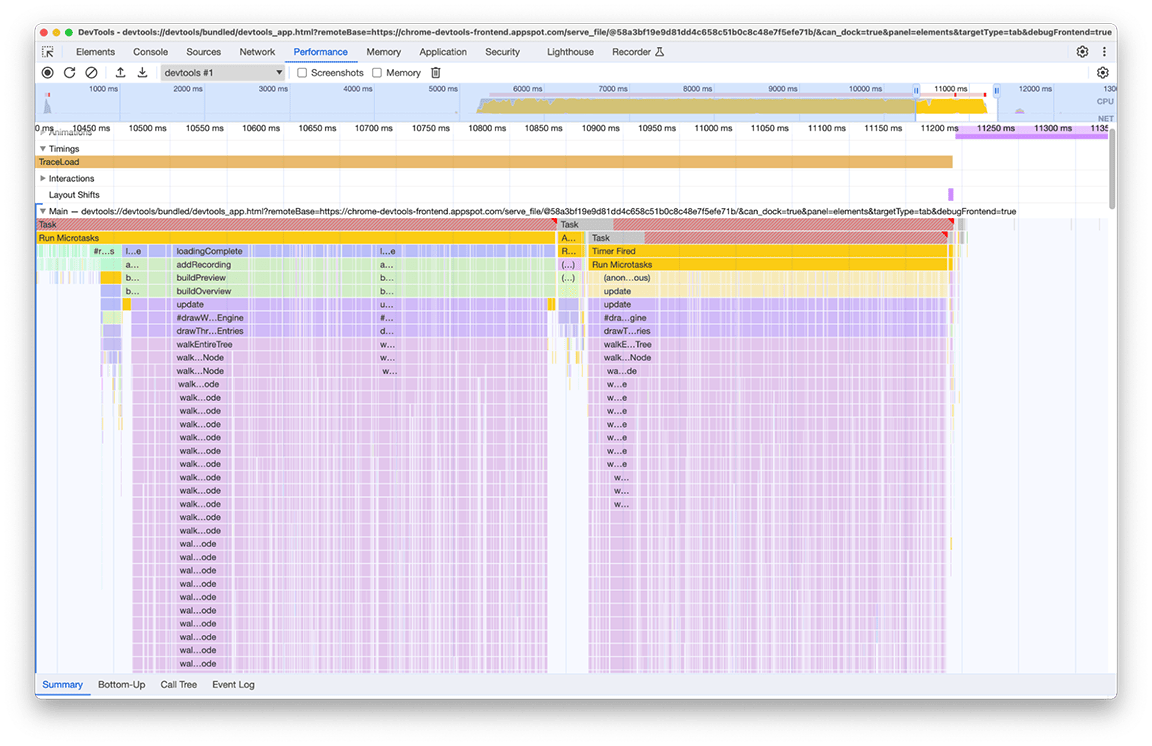
Ten en cuenta que la ejecución de la renderización del mapa en miniatura se produce dos veces, no una. Esto se debe a que se dibujan dos mapas en miniatura para cada perfil: uno para el resumen en la parte superior del panel y otro para el menú desplegable que selecciona el perfil visible actualmente del historial (cada elemento de este menú contiene un resumen del perfil que selecciona). Sin embargo, ambos tienen exactamente el mismo contenido, por lo que uno debería poder reutilizarse para el otro.
Dado que estos mapas en miniatura son imágenes dibujadas en un lienzo, solo se necesitó usar la utilidad de lienzo de drawImage y, luego, ejecutar el código una sola vez para ahorrar tiempo. Como resultado de este esfuerzo, la duración del grupo se redujo de 2.4 segundos a 140 milisegundos.
Conclusión
Después de aplicar todas estas correcciones (y algunas otras más pequeñas aquí y allá), el cambio en la línea de tiempo de carga del perfil se veía de la siguiente manera:
Antes:
Después:
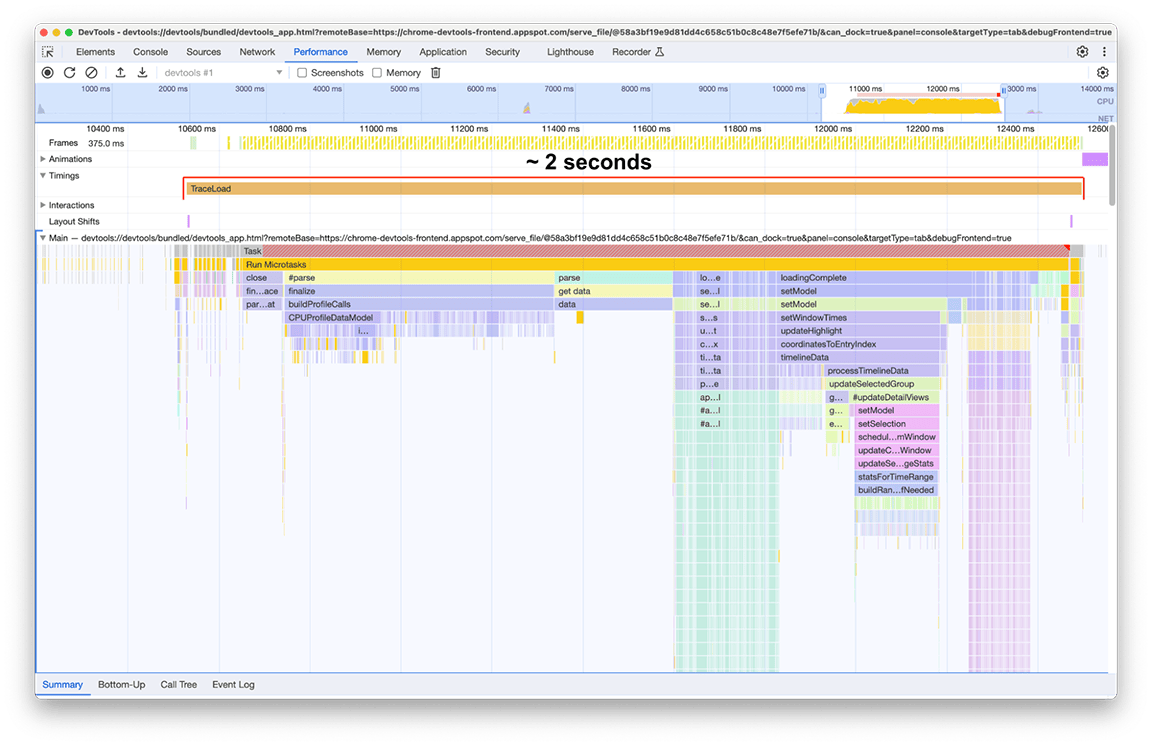
El tiempo de carga después de las mejoras fue de 2 segundos, lo que significa que se logró una mejora de alrededor del 80% con un esfuerzo relativamente bajo, ya que la mayoría de las acciones realizadas consistieron en correcciones rápidas. Por supuesto, identificar correctamente qué hacer inicialmente fue clave, y el panel de rendimiento fue la herramienta adecuada para ello.
También es importante destacar que estas cifras son específicas de un perfil que se usa como sujeto de estudio. El perfil nos interesó porque era particularmente grande. Sin embargo, dado que la canalización de procesamiento es la misma para todos los perfiles, la mejora significativa que se logró se aplica a todos los perfiles cargados en el panel de rendimiento.
Conclusiones
Estos resultados nos dejan algunas lecciones sobre la optimización del rendimiento de tu aplicación:
1. Usa herramientas de generación de perfiles para identificar patrones de rendimiento del tiempo de ejecución
Las herramientas de generación de perfiles son muy útiles para comprender lo que sucede en tu aplicación mientras se ejecuta, en especial para identificar oportunidades de mejorar el rendimiento. El panel Rendimiento de las Herramientas para desarrolladores de Chrome es una excelente opción para las aplicaciones web, ya que es la herramienta nativa de generación de perfiles web en el navegador y se mantiene activa para estar al día con las funciones más recientes de la plataforma web. Además, ahora es mucho más rápido. 😉
Usa muestras que se puedan usar como cargas de trabajo representativas y descubre lo que puedes encontrar.
2. Evita las jerarquías de llamadas complejas
Cuando sea posible, evita que tu gráfico de llamadas sea demasiado complicado. Con jerarquías de llamadas complejas, es fácil introducir regresiones de rendimiento y difícil comprender por qué tu código se ejecuta de la manera en que lo hace, lo que dificulta la implementación de mejoras.
3. Identifica el trabajo innecesario
Es común que las bases de código antiguas contengan código que ya no es necesario. En nuestro caso, el código heredado e innecesario ocupaba una parte importante del tiempo de carga total. Quitarlo era la opción más sencilla.
4. Usa estructuras de datos de forma adecuada
Usa estructuras de datos para optimizar el rendimiento, pero también comprende los costos y las compensaciones que cada tipo de estructura de datos aporta cuando decides cuáles usar. Esto no solo se refiere a la complejidad espacial de la estructura de datos en sí, sino también a la complejidad temporal de las operaciones aplicables.
5. Almacena en caché los resultados para evitar el trabajo duplicado en operaciones complejas o repetitivas.
Si la operación es costosa de ejecutar, tiene sentido almacenar sus resultados para la próxima vez que se necesiten. También tiene sentido hacerlo si la operación se realiza muchas veces, incluso si cada vez no es particularmente costosa.
6. Posponer el trabajo que no sea fundamental
Si el resultado de una tarea no se necesita de inmediato y la ejecución de la tarea extiende la ruta crítica, considera aplazarla llamándola de forma diferida cuando realmente se necesite su resultado.
7. Usa algoritmos eficientes en entradas grandes
Para las entradas grandes, los algoritmos de complejidad temporal óptima son fundamentales. En este ejemplo, no analizamos esta categoría, pero su importancia es innegable.
8. Contenido adicional: Compara tus canalizaciones
Para asegurarte de que tu código en evolución siga siendo rápido, es recomendable supervisar su comportamiento y compararlo con los estándares. De esta manera, puedes identificar de forma proactiva las regresiones y mejorar la confiabilidad general, lo que te prepara para el éxito a largo plazo.