


Ongeacht het type applicatie dat u ontwikkelt, is het optimaliseren van de prestaties en het garanderen van een snelle laadtijd en soepele interactie cruciaal voor de gebruikerservaring en het succes van de applicatie. Eén manier om dit te doen, is door de activiteit van een applicatie te inspecteren met behulp van profileringstools. Zo ziet u wat er onder de motorkap gebeurt terwijl de applicatie gedurende een bepaald tijdsbestek draait. Het Performance- paneel in DevTools is een geweldige profileringstool om de prestaties van webapplicaties te analyseren en te optimaliseren. Als uw app in Chrome draait, krijgt u een gedetailleerd visueel overzicht van wat de browser doet terwijl uw applicatie wordt uitgevoerd. Inzicht in deze activiteit kan u helpen patronen, knelpunten en prestatiehotspots te identificeren, die u kunt aanpakken om de prestaties te verbeteren.
Het volgende voorbeeld laat u zien hoe u het paneel Prestaties kunt gebruiken.
Het opzetten en opnieuw creëren van ons profileringsscenario
Onlangs hebben we ons ten doel gesteld om het Performance- paneel performanter te maken. We wilden met name dat het grote hoeveelheden prestatiegegevens sneller zou laden. Dit is bijvoorbeeld het geval bij het profileren van langlopende of complexe processen of het vastleggen van zeer gedetailleerde gegevens. Om dit te bereiken, was eerst inzicht nodig in hoe de applicatie presteerde en waarom . Dit werd bereikt met behulp van een profileringstool.
Zoals u wellicht weet, is DevTools zelf een webapplicatie. U kunt deze dus profileren met behulp van het paneel Prestaties . Om dit paneel zelf te profileren, opent u DevTools en opent u vervolgens een andere DevTools-instantie die eraan is gekoppeld. Bij Google staat deze configuratie bekend als DevTools-on-DevTools .
Zodra de configuratie gereed is, moet het te profileren scenario opnieuw worden gemaakt en vastgelegd. Om verwarring te voorkomen, wordt het oorspronkelijke DevTools-venster aangeduid als de " eerste DevTools-instantie" en het venster dat de eerste instantie inspecteert, wordt de " tweede DevTools-instantie" genoemd.
In het tweede DevTools-exemplaar observeert het paneel Prestaties (dat vanaf nu het paneel Perf wordt genoemd) dat het eerste DevTools-exemplaar het scenario opnieuw maakt, waarna een profiel wordt geladen.
In de tweede DevTools-instantie wordt een live-opname gestart, terwijl in de eerste instantie een profiel wordt geladen vanuit een bestand op schijf. Er wordt een groot bestand geladen om de prestaties bij het verwerken van grote invoer nauwkeurig te profileren. Wanneer beide instanties klaar zijn met laden, worden de prestatieprofielgegevens – ook wel een trace genoemd – weergegeven in de tweede DevTools-instantie van het perf-paneel dat een profiel laadt.
De beginsituatie: het identificeren van verbetermogelijkheden
Nadat het laden was voltooid, werd het volgende waargenomen in ons tweede prestatiepaneel in de volgende schermafbeelding. Focus op de activiteit van de hoofdthread, die zichtbaar is onder het spoor met het label Main . Er zijn vijf grote activiteitsgroepen te zien in de vlamgrafiek. Deze bestaan uit de taken waarbij het laden het langst duurt. De totale tijd van deze taken was ongeveer 10 seconden . In de volgende schermafbeelding wordt het prestatiepaneel gebruikt om te focussen op elk van deze activiteitsgroepen om te zien wat er te vinden is.

Eerste activiteitengroep: onnodig werk
Het werd duidelijk dat de eerste groep activiteiten bestond uit oude code die nog steeds draaide, maar niet echt nodig was. Eigenlijk was alles onder het groene blok met het label processThreadEvents verspilde moeite. Dat was een snelle oplossing. Het verwijderen van die functieaanroep bespaarde ongeveer 1,5 seconde tijd. Geweldig!
Tweede activiteitengroep
In de tweede activiteitsgroep was de oplossing niet zo eenvoudig als in de eerste. De buildProfileCalls duurden ongeveer 0,5 seconde, en die taak was niet te vermijden.

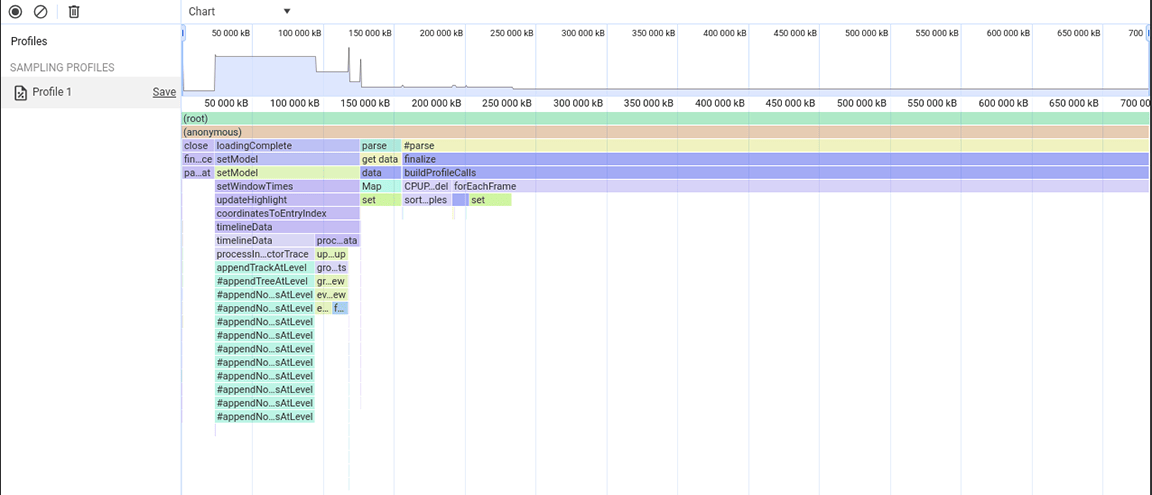
Uit nieuwsgierigheid hebben we de optie Geheugen in het perf-paneel ingeschakeld om dit verder te onderzoeken. We zagen dat de buildProfileCalls -activiteit ook veel geheugen gebruikte. Hier ziet u hoe de blauwe lijn plotseling verspringt tijdens de uitvoering van buildProfileCalls , wat wijst op een mogelijk geheugenlek.

Om dit vermoeden verder te onderzoeken, gebruikten we het paneel Geheugen (een ander paneel in DevTools, anders dan de geheugenlade in het perf-paneel) om het te onderzoeken. In het paneel Geheugen werd het profileringstype "Toewijzingssampling" geselecteerd, waarmee de heap-snapshot werd vastgelegd voor het perf-paneel dat het CPU-profiel laadde.

De onderstaande schermafbeelding toont de heap-snapshot die is gemaakt.

Uit deze heap snapshot bleek dat de Set klasse veel geheugen verbruikte. Door de callpoints te controleren, bleek dat we onnodig eigenschappen van het type Set toewezen aan objecten die in grote volumes werden aangemaakt. Deze kosten liepen op en er werd veel geheugen verbruikt, tot het punt dat de applicatie regelmatig crashte bij grote invoer.
Sets zijn handig voor het opslaan van unieke items en bieden bewerkingen die gebruikmaken van de uniciteit van hun inhoud, zoals het dedupliceren van datasets en het bieden van efficiëntere opzoekacties. Deze functies waren echter niet nodig, omdat de opgeslagen gegevens gegarandeerd uniek waren ten opzichte van de bron. Sets waren dus in eerste instantie niet nodig. Om de geheugentoewijzing te verbeteren, werd het eigenschapstype gewijzigd van een Set naar een gewone array. Na het toepassen van deze wijziging werd een nieuwe heap snapshot gemaakt en werd een verminderde geheugentoewijzing waargenomen. Hoewel deze wijziging geen aanzienlijke snelheidsverbetering opleverde, was het secundaire voordeel dat de applicatie minder vaak crashte.
Derde activiteitengroep: afwegingen maken tussen datastructuur en datastructuur
Het derde gedeelte is bijzonder: je kunt in de vlamgrafiek zien dat het bestaat uit smalle maar hoge kolommen, die duiden op diepe functieaanroepen, en in dit geval diepe recursies. In totaal duurde dit gedeelte ongeveer 1,4 seconden. Door naar de onderkant van dit gedeelte te kijken, werd duidelijk dat de breedte van deze kolommen werd bepaald door de duur van één functie: appendEventAtLevel , wat suggereerde dat het een bottleneck zou kunnen zijn.
Binnen de implementatie van de appendEventAtLevel -functie viel één ding op. Voor elke afzonderlijke gegevensinvoer in de invoer (in de code bekend als de "event") werd een item toegevoegd aan een map die de verticale positie van de tijdlijnitems bijhield. Dit was problematisch, omdat het aantal opgeslagen items erg groot was. Mappen zijn snel voor sleutelgebaseerde zoekopdrachten, maar dit voordeel is niet gratis. Naarmate een map groter wordt, kan het toevoegen van gegevens eraan bijvoorbeeld duur worden door rehashing. Deze kosten worden merkbaar wanneer er grote hoeveelheden items achter elkaar aan de map worden toegevoegd.
/**
* Adds an event to the flame chart data at a defined vertical level.
*/
function appendEventAtLevel (event, level) {
// ...
const index = data.length;
data.push(event);
this.indexForEventMap.set(event, index);
// ...
}
We experimenteerden met een andere aanpak, waarbij we niet voor elk item in de vlamgrafiek een item aan een kaart hoefden toe te voegen. De verbetering was significant en bevestigde dat het knelpunt inderdaad verband hield met de overhead die het toevoegen van alle gegevens aan de kaart met zich meebracht. De tijd die de activiteitsgroep nodig had, kromp van ongeveer 1,4 seconde naar ongeveer 200 milliseconden.
Voor:

Na:

Vierde activiteitengroep: het uitstellen van niet-kritiek werk en het cachen van gegevens om dubbel werk te voorkomen
Als je inzoomt op dit venster, zie je dat er twee vrijwel identieke blokken functieaanroepen zijn. Door naar de namen van de aangeroepen functies te kijken, kun je afleiden dat deze blokken bestaan uit code die bomen bouwt (bijvoorbeeld met namen als refreshTree of buildChildren ). Sterker nog, de bijbehorende code is degene die de boomweergaven in de onderste lade van het paneel aanmaakt. Interessant is dat deze boomweergaven niet direct na het laden worden weergegeven. In plaats daarvan moet de gebruiker een boomweergave selecteren (de tabbladen "Bottom-up", "Call Tree" en "Event Log" in de lade) om de bomen weer te geven. Bovendien, zoals je op de schermafbeelding kunt zien, werd het proces van het bouwen van de boom twee keer uitgevoerd.
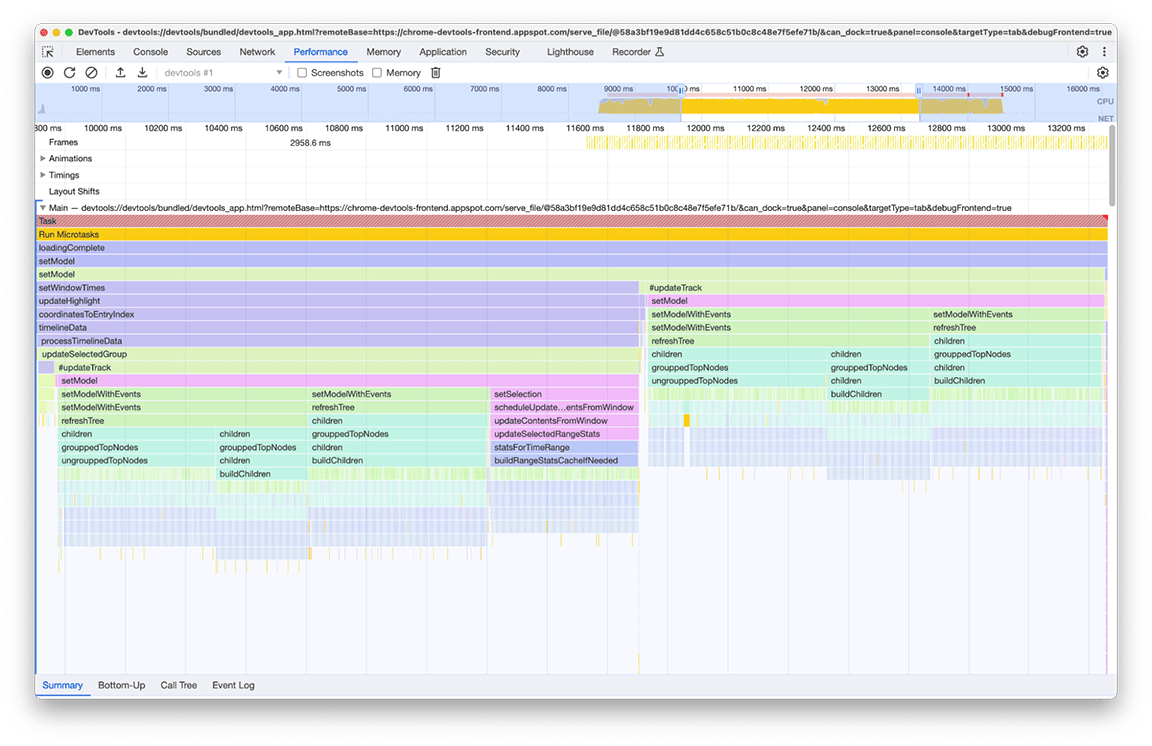
We hebben twee problemen met deze foto geconstateerd:
- Een niet-kritieke taak belemmerde de laadprestaties. Gebruikers hebben de uitvoer ervan niet altijd nodig. De taak is daarom niet kritisch voor het laden van het profiel.
- Het resultaat van deze taken werd niet gecached. Daarom werden de bomen twee keer berekend, ondanks dat de gegevens niet veranderden.
We zijn begonnen met het uitstellen van de boomberekening tot het moment dat de gebruiker de boomweergave handmatig opende. Pas dan is het de moeite waard om de kosten te betalen voor het aanmaken van deze bomen. De totale tijd die nodig was om dit twee keer uit te voeren, was ongeveer 3,4 seconden, dus het uitstellen ervan had een aanzienlijk verschil in de laadtijd. We onderzoeken nog steeds de mogelijkheid om dit soort taken te cachen.
Vijfde activiteitengroep: vermijd complexe oproephiërarchieën waar mogelijk
Bij nadere beschouwing van deze groep was het duidelijk dat een bepaalde reeks oproepen herhaaldelijk werd aangeroepen. Hetzelfde patroon verscheen zes keer op verschillende plaatsen in de vlamgrafiek, en de totale duur van dit venster was ongeveer 2,4 seconden!

De gerelateerde code die meerdere keren wordt aangeroepen, is het onderdeel dat de data verwerkt die moet worden weergegeven op de "minimap" (het overzicht van de tijdlijnactiviteit bovenaan het paneel). Het was niet duidelijk waarom dit meerdere keren gebeurde, maar het hoefde zeker niet zes keer te gebeuren! Sterker nog, de uitvoer van de code zou actueel moeten blijven als er geen ander profiel wordt geladen. In theorie zou de code slechts één keer moeten worden uitgevoerd.
Na onderzoek bleek dat de gerelateerde code werd aangeroepen als gevolg van het feit dat meerdere onderdelen in de laadpijplijn direct of indirect de functie aanriepen die de minimap berekent. Dit komt doordat de complexiteit van de call graph van het programma in de loop der tijd is geëvolueerd en er onbewust meer afhankelijkheden aan deze code zijn toegevoegd. Er is geen snelle oplossing voor dit probleem. De oplossing hangt af van de architectuur van de betreffende codebase. In ons geval moesten we de complexiteit van de call-hiërarchie enigszins verminderen en een controle toevoegen om te voorkomen dat de code werd uitgevoerd als de invoergegevens ongewijzigd bleven. Na implementatie hiervan kregen we dit beeld van de tijdlijn:
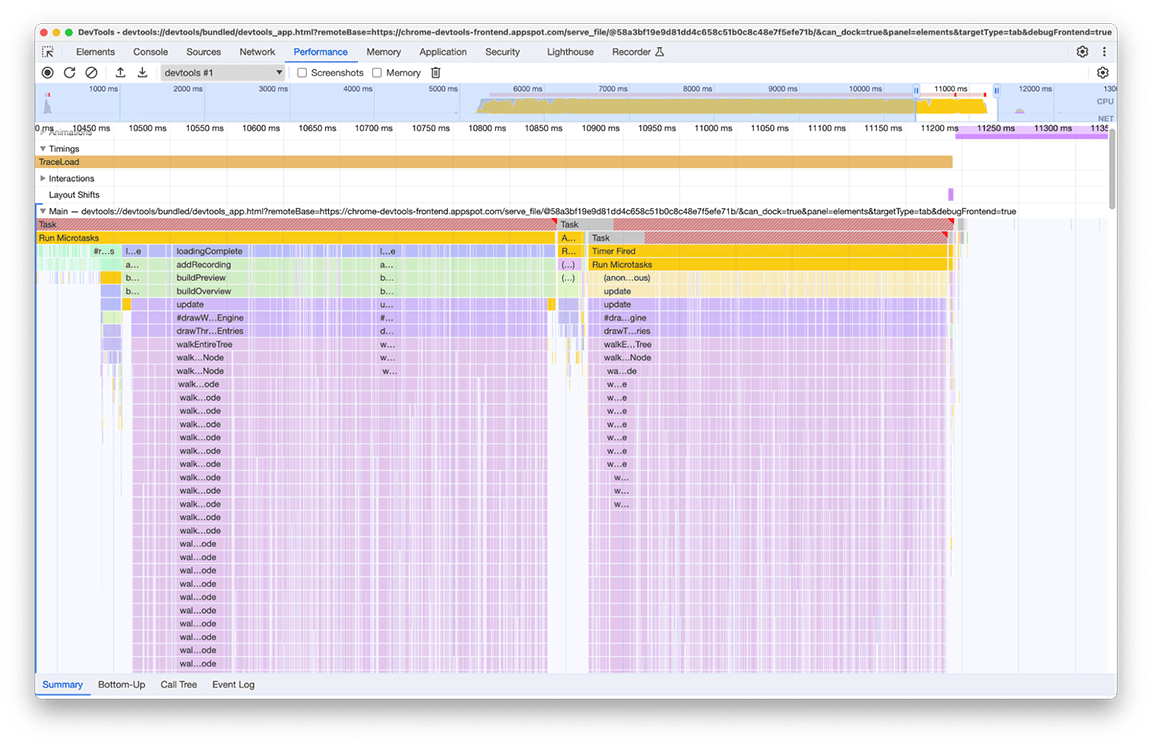
Houd er rekening mee dat de minimap-rendering twee keer wordt uitgevoerd, niet één keer. Dit komt doordat er voor elk profiel twee minimaps worden getekend: één voor het overzicht bovenaan het paneel en één voor het dropdownmenu dat het momenteel zichtbare profiel uit de geschiedenis selecteert (elk item in dit menu bevat een overzicht van het geselecteerde profiel). Niettemin hebben deze twee exact dezelfde inhoud, dus de ene zou voor de andere hergebruikt moeten kunnen worden.
Omdat deze minimaps beide afbeeldingen op een canvas zijn, was het een kwestie van het drawImage canvas-hulpprogramma gebruiken en de code vervolgens slechts één keer uitvoeren om wat extra tijd te besparen. Hierdoor werd de tijd die de groep nodig had, teruggebracht van 2,4 seconden naar 140 milliseconden.
Conclusie
Nadat al deze oplossingen (en nog een paar kleinere hier en daar) waren toegepast, zag de verandering in de tijdlijn voor het laden van profielen er als volgt uit:
Voor:

Na:

De laadtijd na de verbeteringen bedroeg 2 seconden, wat betekent dat een verbetering van ongeveer 80% met relatief weinig moeite werd bereikt, aangezien het grootste deel van de verbeteringen bestond uit snelle oplossingen. Natuurlijk was het belangrijk om goed te identificeren wat er in eerste instantie moest gebeuren, en het perf-paneel was hiervoor de juiste tool.
Het is ook belangrijk om te benadrukken dat deze cijfers specifiek zijn voor een profiel dat als onderzoeksonderwerp wordt gebruikt. Het profiel was voor ons interessant omdat het bijzonder groot was. Omdat de verwerkingspijplijn voor elk profiel hetzelfde is, geldt de significante verbetering echter voor elk profiel dat in het perf-paneel is geladen.
Afhaalmaaltijden
Deze resultaten bieden een aantal lessen die u kunt leren met betrekking tot de prestatie-optimalisatie van uw applicatie:
1. Gebruik profileringshulpmiddelen om runtime-prestatiepatronen te identificeren
Profileringstools zijn ontzettend handig om te begrijpen wat er in je applicatie gebeurt terwijl deze draait, met name om mogelijkheden te identificeren om de prestaties te verbeteren. Het Prestatiepaneel in Chrome DevTools is een geweldige optie voor webapplicaties, omdat het de ingebouwde webprofileringstool in de browser is en actief wordt onderhouden om up-to-date te blijven met de nieuwste functies van het webplatform. Bovendien is het nu aanzienlijk sneller! 😉
Gebruik voorbeelden die als representatieve werklasten kunnen worden gebruikt en kijk wat u kunt vinden!
2. Vermijd complexe oproephiërarchieën
Vermijd indien mogelijk om je call graph te complex te maken. Met complexe call-hiërarchieën is het gemakkelijk om prestatieregressies te introduceren en is het moeilijk te begrijpen waarom je code werkt zoals hij werkt, waardoor het lastig is om verbeteringen door te voeren.
3. Identificeer onnodig werk
Het komt vaak voor dat verouderde codebases code bevatten die niet langer nodig is. In ons geval nam verouderde en onnodige code een aanzienlijk deel van de totale laadtijd in beslag. Het verwijderen hiervan was het laagst hangende fruit.
4. Gebruik datastructuren op de juiste manier
Gebruik datastructuren om de prestaties te optimaliseren, maar begrijp ook de kosten en afwegingen die elk type datastructuur met zich meebrengt bij het kiezen van de juiste. Dit geldt niet alleen voor de ruimtelijke complexiteit van de datastructuur zelf, maar ook voor de tijdscomplexiteit van de betreffende bewerkingen.
5. Cacheresultaten om dubbel werk voor complexe of repetitieve bewerkingen te voorkomen
Als de bewerking kostbaar is, is het zinvol om de resultaten op te slaan voor de volgende keer dat deze nodig is. Het is ook zinvol om dit te doen als de bewerking meerdere keren wordt uitgevoerd, zelfs als elke keer afzonderlijk niet bijzonder kostbaar is.
6. Stel niet-kritiek werk uit
Als de uitvoer van een taak niet meteen nodig is en de uitvoering ervan het kritieke pad verlengt, kunt u overwegen de taak uit te stellen door deze langzaam aan te roepen op het moment dat de uitvoer daadwerkelijk nodig is.
7. Gebruik efficiënte algoritmen op grote invoer
Voor grote inputs worden algoritmen met optimale tijdcomplexiteit cruciaal. We hebben deze categorie in dit voorbeeld niet behandeld, maar hun belang kan nauwelijks worden overschat.
8. Bonus: benchmark uw pijpleidingen
Om ervoor te zorgen dat je evoluerende code snel blijft, is het verstandig om het gedrag te monitoren en te vergelijken met standaarden. Zo identificeer je proactief regressies en verbeter je de algehele betrouwbaarheid, wat je op weg helpt naar succes op de lange termijn.