

Nhóm Chrome đã và đang thực hiện một số nội dung cập nhật thú vị cho Speculation Rules API (API Quy tắc suy đoán) được dùng để cải thiện hiệu suất điều hướng bằng cách tìm nạp trước hoặc thậm chí là kết xuất trước các thao tác điều hướng trong tương lai. Tất cả các điểm cải tiến bổ sung này hiện đã có trong Chrome 122 (một số tính năng có trong các phiên bản trước đó).
Những thay đổi này giúp việc triển khai các trang tìm nạp trước và kết xuất trước trở nên dễ dàng hơn đáng kể và ít lãng phí hơn. Chúng tôi hy vọng điều này sẽ khuyến khích việc áp dụng thêm.
Các tính năng khác
Trước tiên, chúng ta sẽ tìm hiểu về những điểm mới mà chúng tôi đã thêm vào Speculation Rules API và cách sử dụng các điểm này. Sau đó, chúng tôi sẽ cho bạn xem một bản minh hoạ để bạn có thể thấy các chỉ số này hoạt động.
Quy tắc về tài liệu
Trước đây, Speculation Rules API hoạt động bằng cách chỉ định một danh sách URL để tìm nạp trước hoặc kết xuất trước:
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next2.html"]
}
]
}
</script>
Các quy tắc suy đoán có tính bán động, tức là có thể thêm các tập lệnh quy tắc suy đoán mới và xoá các tập lệnh cũ để loại bỏ những suy đoán đó (lưu ý rằng việc cập nhật danh sách urls của một tập lệnh quy tắc suy đoán hiện có sẽ không kích hoạt thay đổi trong suy đoán). Tuy nhiên, trang web vẫn có thể chọn URL, bằng cách gửi URL từ máy chủ tại thời điểm yêu cầu trang hoặc bằng cách tạo danh sách này một cách linh hoạt thông qua JavaScript phía máy khách.
Quy tắc danh sách vẫn là một lựa chọn cho các trường hợp sử dụng đơn giản hơn (khi thao tác điều hướng tiếp theo là từ một nhóm nhỏ các thao tác rõ ràng) hoặc các trường hợp sử dụng nâng cao hơn (khi danh sách URL được tính toán linh động dựa trên bất kỳ phương pháp phỏng đoán nào mà chủ sở hữu trang web muốn sử dụng, rồi chèn vào trang).
Ngoài ra, chúng tôi rất vui khi cung cấp một lựa chọn mới để tự động tìm đường liên kết bằng cách sử dụng các quy tắc tài liệu. Tính năng này hoạt động bằng cách lấy URL từ chính tài liệu dựa trên điều kiện where. Điều này có thể dựa trên chính các đường liên kết:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/logout/*"}}
]
},
"eagerness": "moderate"
}]
}
</script>
Bạn cũng có thể sử dụng bộ chọn CSS làm phương án thay thế hoặc kết hợp với các giá trị khớp href để tìm đường liên kết trong trang hiện tại:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "selector_matches": ".prerender" },
{ "not": {"selector_matches": ".do-not-prerender"}}
]
},
"eagerness": "moderate"
}]
}
</script>
Điều này cho phép sử dụng một bộ quy tắc suy đoán duy nhất trên toàn bộ trang web, thay vì có các quy tắc cụ thể cho mỗi trang. Nhờ đó, các trang web có thể dễ dàng triển khai quy tắc suy đoán hơn nhiều.
Tất nhiên, việc kết xuất trước tất cả các đường liên kết trên một trang chắc chắn sẽ rất lãng phí, vì vậy, với khả năng mới này, chúng tôi đã giới thiệu chế độ cài đặt eagerness.
Sự háo hức
Với bất kỳ loại suy đoán nào, đều có sự đánh đổi giữa độ chính xác và khả năng thu hồi, cũng như thời gian dự kiến. Việc kết xuất trước tất cả các đường liên kết khi tải trang có nghĩa là bạn gần như chắc chắn sẽ kết xuất trước một đường liên kết mà người dùng nhấp vào (giả sử họ nhấp vào một đường liên kết trên cùng một trang web), và với thời gian chờ càng lâu càng tốt, nhưng có thể lãng phí băng thông rất lớn.
Mặt khác, chỉ kết xuất trước một lần khi người dùng nhấp vào một đường liên kết sẽ ngăn chặn lãng phí, nhưng phải trả giá bằng việc giảm đáng kể thời gian chờ. Điều này có nghĩa là trang đó khó có thể hoàn tất quá trình kết xuất trước khi trình duyệt chuyển sang trang đó.
Chế độ cài đặt eagerness cho phép bạn xác định thời điểm chạy suy đoán, tách thời điểm suy đoán khỏi URL để thực hiện suy đoán. Chế độ cài đặt eagerness có sẵn cho cả quy tắc nguồn list và document, đồng thời có 4 chế độ cài đặt. Chrome có các phương pháp phỏng đoán sau đây cho các chế độ cài đặt này:
immediate: Chế độ cài đặt này dùng để suy đoán càng sớm càng tốt, tức là ngay khi các quy tắc suy đoán được tuân thủ.eager: Chế độ cài đặt này hiện hoạt động giống hệt chế độ cài đặtimmediate, nhưng trong tương lai, chúng tôi sẽ tìm cách bố trí chế độ này vào khoảng giữaimmediatevàmoderate.moderate: Chế độ cài đặt này tiến hành suy đoán nếu bạn di chuột lên một đường liên kết trong 200 mili giây (hoặc trong sự kiệnpointerdownnếu sự kiện đó xảy ra sớm hơn và trên thiết bị di động không có sự kiệnhover).conservative: Chế độ cài đặt này suy đoán dựa trên sự kiện con trỏ hoặc sự kiện chạm.
eagerness mặc định cho các quy tắc list là immediate. Bạn có thể dùng các lựa chọn moderate và conservative để giới hạn các quy tắc list đối với những URL mà người dùng tương tác trong một danh sách cụ thể. Mặc dù trong nhiều trường hợp, các quy tắc document có điều kiện where phù hợp có thể sẽ phù hợp hơn.
eagerness mặc định cho các quy tắc document là conservative. Vì một tài liệu có thể bao gồm nhiều URL, nên bạn cần thận trọng khi sử dụng immediate hoặc eager cho các quy tắc document (xem thêm phần Các giới hạn của Chrome ở phần tiếp theo).
Bạn nên sử dụng chế độ cài đặt eagerness nào tuỳ thuộc vào trang web của bạn. Đối với một trang web tĩnh rất đơn giản, việc suy đoán tích cực hơn có thể ít tốn kém và mang lại lợi ích cho người dùng. Những trang web có cấu trúc phức tạp hơn và tải trọng trang lớn hơn có thể muốn giảm lãng phí bằng cách ít suy đoán hơn cho đến khi bạn nhận được tín hiệu tích cực hơn về ý định của người dùng để hạn chế lãng phí.
Lựa chọn moderate là lựa chọn trung gian và nhiều trang web có thể hưởng lợi từ quy tắc suy đoán đơn giản sau đây. Quy tắc này sẽ kết xuất trước tất cả các đường liên kết khi di chuột hoặc pointerdown dưới dạng một cách triển khai cơ bản nhưng mạnh mẽ của quy tắc suy đoán:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
Giới hạn của Chrome
Ngay cả khi bạn chọn eagerness, Chrome vẫn có các giới hạn để ngăn chặn việc sử dụng quá mức API này:
eagerness |
Tìm nạp trước | Kết xuất trước |
|---|---|---|
immediate/eager |
50 | 10 |
moderate/conservative |
2 (FIFO) | 2 (FIFO) |
Các chế độ cài đặt moderate và conservative (tuỳ thuộc vào hoạt động tương tác của người dùng) hoạt động theo cách thức Vào trước, ra trước (FIFO). Sau khi đạt đến giới hạn, một suy đoán mới sẽ khiến suy đoán cũ nhất bị huỷ và thay thế bằng suy đoán mới hơn để tiết kiệm bộ nhớ.
Việc người dùng kích hoạt các suy đoán moderate và conservative cho phép chúng ta sử dụng ngưỡng khiêm tốn hơn là 2 để tiết kiệm bộ nhớ. Các chế độ cài đặt immediate và eager không được kích hoạt bằng hành động của người dùng, do đó có hạn mức cao hơn vì trình duyệt không thể biết chế độ cài đặt nào cần thiết và thời điểm cần thiết.
Một suy đoán bị huỷ do bị đẩy ra khỏi hàng đợi FIFO có thể được kích hoạt lại (ví dụ: bằng cách di chuột lại vào đường liên kết đó). Điều này sẽ dẫn đến việc URL đó được suy đoán lại. Trong trường hợp đó, suy đoán trước đó có thể đã khiến trình duyệt lưu vào bộ nhớ đệm một số tài nguyên trong Bộ nhớ đệm HTTP cho URL đó, vì vậy, việc lặp lại suy đoán sẽ giảm đáng kể chi phí mạng và thời gian.
Giới hạn immediate và eager cũng là giới hạn động. Việc xoá một phần tử tập lệnh quy tắc suy đoán bằng các mức độ háo hức này sẽ tạo ra dung lượng bằng cách huỷ các suy đoán đã xoá. Bạn cũng có thể suy đoán lại các URL này nếu chúng có trong một tập lệnh URL mới và chưa đạt đến giới hạn.
Chrome cũng sẽ ngăn chặn việc sử dụng suy đoán trong một số điều kiện nhất định, bao gồm:
- Save-Data.
- Trình tiết kiệm pin.
- Hạn chế về bộ nhớ.
- Khi bạn tắt chế độ cài đặt "Tải trước trang" (cũng có thể do các tiện ích Chrome như uBlock Origin tắt một cách rõ ràng).
- Các trang được mở trong thẻ nền.
Tất cả các điều kiện này đều nhằm mục đích giảm tác động của việc suy đoán quá mức khi điều đó gây bất lợi cho người dùng.
Không bắt buộc source
Chrome 122 cho phép sử dụng khoá source (không bắt buộc) vì khoá này có thể được suy ra từ sự hiện diện của khoá url hoặc where. Do đó, 2 quy tắc suy đoán này giống hệt nhau:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
<script type="speculationrules">
{
"prerender": [{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
Tiêu đề HTTP Speculation-Rules
Bạn cũng có thể phân phối các quy tắc suy đoán bằng cách sử dụng tiêu đề HTTP Speculation-Rules, thay vì đưa trực tiếp các quy tắc đó vào HTML của tài liệu. Điều này giúp CDN triển khai dễ dàng hơn mà không cần phải thay đổi nội dung của chính tài liệu.
Tiêu đề HTTP Speculation-Rules được trả về cùng với tài liệu và trỏ đến vị trí của một tệp JSON chứa các quy tắc suy đoán:
Speculation-Rules: "/speculationrules.json"
Tài nguyên này phải sử dụng đúng loại MIME và nếu là tài nguyên trên nhiều nguồn, thì phải vượt qua quy trình kiểm tra CORS.
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
Nếu muốn sử dụng URL tương đối, bạn có thể thêm khoá "relative_to": "document" vào quy tắc suy đoán. Nếu không, các URL tương đối sẽ tương đối với URL của tệp JSON chứa quy tắc suy đoán. Điều này có thể đặc biệt hữu ích nếu bạn cần chọn một số hoặc tất cả các đường liên kết cùng nguồn.
Sử dụng lại bộ nhớ đệm hiệu quả hơn
Chúng tôi đã thực hiện một số điểm cải tiến đối với hoạt động lưu vào bộ nhớ đệm trong Chrome để việc tìm nạp trước (hoặc thậm chí là kết xuất trước) một tài liệu sẽ lưu trữ và sử dụng lại các tài nguyên trong bộ nhớ đệm HTTP. Điều này có nghĩa là việc suy đoán vẫn có thể mang lại lợi ích trong tương lai, ngay cả khi bạn không sử dụng suy đoán đó.
Điều này cũng giúp việc suy đoán lại (ví dụ: đối với các quy tắc tài liệu có chế độ cài đặt mức độ sẵn sàng moderate) trở nên rẻ hơn đáng kể, vì Chrome sẽ sử dụng bộ nhớ đệm HTTP cho các tài nguyên có thể lưu vào bộ nhớ đệm.
Chúng tôi cũng hỗ trợ đề xuất No-Vary-Search mới để cải thiện hơn nữa khả năng sử dụng lại bộ nhớ đệm.
Hỗ trợ của No-Vary-Search
Khi tìm nạp trước hoặc kết xuất trước một trang, một số tham số URL (về mặt kỹ thuật được gọi là tham số tìm kiếm) có thể không quan trọng đối với trang mà máy chủ thực sự phân phối và chỉ được JavaScript phía máy khách sử dụng.
Ví dụ: Google Analytics sử dụng tham số UTM để đo lường chiến dịch, nhưng thường không dẫn đến việc máy chủ phân phối các trang khác nhau. Điều này có nghĩa là page1.html?utm_content=123 và page1.html?utm_content=456 sẽ phân phối cùng một trang từ máy chủ, vì vậy, bạn có thể sử dụng lại cùng một trang từ bộ nhớ đệm.
Tương tự, các ứng dụng có thể sử dụng những tham số URL khác chỉ được xử lý ở phía máy khách.
Đề xuất No-Vary-Search cho phép máy chủ chỉ định các tham số không dẫn đến sự khác biệt đối với tài nguyên được phân phối, do đó cho phép trình duyệt sử dụng lại các phiên bản đã lưu vào bộ nhớ đệm trước đó của một tài liệu chỉ khác nhau ở các tham số này. Lưu ý: hiện tại, tính năng này chỉ được hỗ trợ trong Chrome (và các trình duyệt dựa trên Chromium) cho các suy đoán điều hướng tìm nạp trước.
Các quy tắc suy đoán hỗ trợ việc sử dụng expects_no_vary_search để cho biết vị trí dự kiến trả về tiêu đề HTTP No-Vary-Search. Việc này có thể giúp bạn tránh tải xuống những nội dung không cần thiết.
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
Trong ví dụ này, HTML trang ban đầu /products giống nhau cho cả mã sản phẩm 123 và 124. Tuy nhiên, nội dung trang cuối cùng sẽ khác nhau dựa trên hoạt động kết xuất phía máy khách bằng JavaScript để tìm nạp dữ liệu sản phẩm bằng tham số tìm kiếm id. Vì vậy, chúng tôi tìm nạp trước URL đó một cách chủ động và URL đó sẽ trả về một tiêu đề HTTP No-Vary-Search cho biết trang có thể dùng cho mọi tham số tìm kiếm id.
Tuy nhiên, nếu người dùng nhấp vào bất kỳ đường liên kết nào trước khi quá trình tìm nạp trước hoàn tất, thì trình duyệt có thể chưa nhận được trang /products. Trong trường hợp này, trình duyệt không biết liệu yêu cầu có chứa tiêu đề HTTP No-Vary-Search hay không. Sau đó, trình duyệt sẽ có lựa chọn tìm nạp lại đường liên kết hoặc đợi quá trình tìm nạp trước hoàn tất để xem đường liên kết đó có chứa tiêu đề HTTP No-Vary-Search hay không. Chế độ cài đặt expects_no_vary_search cho phép trình duyệt biết rằng phản hồi trang dự kiến sẽ chứa tiêu đề HTTP No-Vary-Search và chờ quá trình tìm nạp trước đó hoàn tất.
Bản minh hoạ
Chúng tôi đã tạo một bản minh hoạ tại https://chrome.dev/speculative-loading/common-fruits.html. Bạn có thể dùng bản minh hoạ này để xem các quy tắc về tài liệu với chế độ cài đặt mức độ sẵn sàng moderate đang hoạt động:
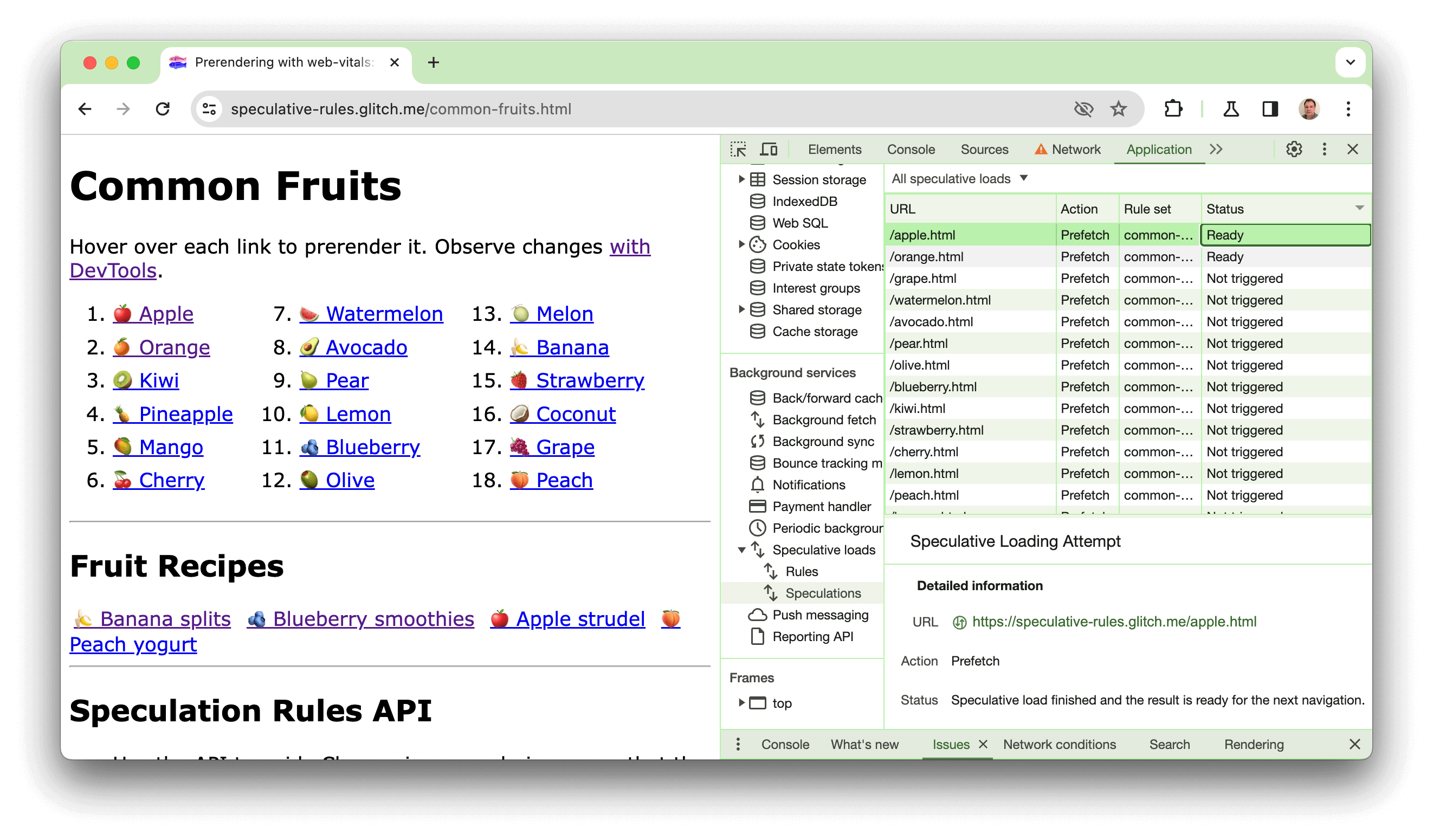
Mở Công cụ cho nhà phát triển, nhấp vào bảng điều khiển Ứng dụng. Sau đó, trong mục Background services (Dịch vụ nền), hãy nhấp vào Speculative loads (Tải suy đoán), sau đó nhấp vào ngăn Speculations (Suy đoán) và sắp xếp theo cột Status (Trạng thái).
Khi di chuột qua các loại trái cây, bạn sẽ thấy các trang được kết xuất trước. Khi nhấp vào các mục này, bạn sẽ thấy thời gian hiển thị LCP nhanh hơn nhiều so với một trong các công thức không được kết xuất trước. Bản minh hoạ này cũng được giải thích trong video sau:
Bạn cũng có thể xem bài đăng trên blog trước đây về gỡ lỗi quy tắc suy đoán để biết thêm thông tin về cách sử dụng Công cụ cho nhà phát triển để gỡ lỗi quy tắc suy đoán.
Hỗ trợ nền tảng cho quy tắc suy đoán
Mặc dù các quy tắc suy đoán tương đối đơn giản để triển khai bằng cách chèn các quy tắc vào một phần tử <script type="speculationrules">, nhưng việc hỗ trợ nền tảng có thể giúp bạn thực hiện việc này chỉ bằng một cú nhấp chuột. Chúng tôi đã làm việc với nhiều nền tảng và đối tác để giúp việc triển khai các quy tắc suy đoán trở nên dễ dàng hơn.
Chúng tôi cũng đang nỗ lực chuẩn hoá API thông qua Nhóm cộng đồng Web Incubator (WICG) để cho phép các trình duyệt khác cũng triển khai API thú vị này nếu họ muốn.
WordPress
Nhóm hiệu suất cốt lõi của WordPress (bao gồm cả các nhà phát triển của Google) đã tạo ra một trình bổ trợ Speculation Rules. Plugin này cho phép bạn dễ dàng thêm tính năng hỗ trợ quy tắc về tài liệu vào bất kỳ trang web WordPress nào chỉ bằng một lần nhấp. Bạn cũng có thể cài đặt trình bổ trợ này thông qua trình bổ trợ WordPress Performance Lab. Bạn cũng nên cân nhắc việc cài đặt trình bổ trợ này vì trình bổ trợ này sẽ giúp bạn nắm bắt thông tin mới nhất về các trình bổ trợ hiệu suất có liên quan của nhóm.
Có hai nhóm chế độ cài đặt: Chế độ suy đoán và chế độ cài đặt Mức độ mong muốn:

Đối với các chế độ thiết lập phức tạp hơn (ví dụ: để loại trừ một số URL khỏi việc được tìm nạp trước hoặc kết xuất trước), hãy đọc tài liệu này.
Akamai
Akamai là một trong những nhà cung cấp CDN hàng đầu thế giới và họ đã tích cực thử nghiệm Speculation Rules API trong một thời gian. Akamai đã phát hành tài liệu về cách khách hàng có thể bật API này trong chế độ cài đặt CDN của họ. Họ cũng từng chia sẻ những kết quả ấn tượng có thể đạt được nhờ API mới này.
Uxify
Uxify (trước đây là một phần của Nitropack) là một giải pháp tối ưu hoá hiệu suất sử dụng AI điều hướng tuỳ chỉnh của họ để dự đoán những trang cần thêm vào quy tắc suy đoán. Mục tiêu là cung cấp thời gian chờ lâu hơn so với việc di chuột qua một đường liên kết, nhưng không lãng phí thời gian suy đoán không cần thiết trên tất cả các đường liên kết đã quan sát được. Hãy xem tài liệu về API Quy tắc suy đoán Uxify để biết thêm thông tin. Giải pháp cải tiến này cho thấy các quy tắc cũ trong danh sách vẫn còn nhiều điều để cung cấp khi kết hợp với thông tin chi tiết dành riêng cho từng trang web.
Nhóm Chrome cũng đã hợp tác với nhóm tổ chức một hội thảo trực tuyến về Speculation Rules API cho những người muốn biết thêm thông tin, bao gồm cả một cuộc thảo luận hữu ích về những điều cần cân nhắc giữa việc suy đoán sớm và thường xuyên, cũng như suy đoán muộn và ít thường xuyên hơn.
Chụp ảnh thiên văn
Astro đã thêm các trang kết xuất trước bằng Speculation Rules API trong phiên bản 4.2 trên cơ sở thử nghiệm, cho phép các nhà phát triển sử dụng Astro dễ dàng bật tính năng này, đồng thời quay lại chế độ tìm nạp trước tiêu chuẩn cho những trình duyệt không hỗ trợ Speculation Rules API. Hãy đọc tài liệu kết xuất trước phía máy khách của họ để biết thêm thông tin.
Kết luận
Những điểm bổ sung này cho Speculation Rules API giúp các trang web sử dụng tính năng hiệu suất mới thú vị này một cách đơn giản hơn nhiều, đồng thời giảm nguy cơ lãng phí tài nguyên với những suy đoán không được sử dụng. Thật vui khi thấy các nền tảng đã sử dụng API này. Chúng tôi hy vọng sẽ thấy API này được áp dụng rộng rãi hơn vào năm 2024 và cuối cùng là mang lại hiệu suất tốt hơn cho người dùng cuối.
Ngoài những lợi ích về hiệu suất mà Speculation Rules API mang lại, chúng tôi cũng rất vui khi thấy những cơ hội mới mà API này mang lại. View Transitions là một API mới giúp nhà phát triển dễ dàng chỉ định các hiệu ứng chuyển đổi giữa các thành phần điều hướng. Tính năng này hiện có sẵn cho Ứng dụng một trang (SPA), nhưng phiên bản nhiều trang đang được triển khai (và có sẵn sau một cờ trong Chrome). Kết xuất trước là một tiện ích bổ sung tự nhiên cho tính năng đó để đảm bảo không có độ trễ. Nếu không, độ trễ sẽ ngăn chặn việc cải thiện trải nghiệm người dùng mà quá trình chuyển đổi này hướng đến. Chúng tôi đã thấy các trang web thử nghiệm với sự kết hợp này.
Chúng tôi mong rằng Speculation Rules API sẽ được áp dụng rộng rãi hơn nữa trong năm 2024 và sẽ thông báo cho bạn về mọi điểm cải tiến khác đối với API này.
Lời cảm ơn
Hình thu nhỏ của Robbie Down trên Unsplash