

El equipo de Chrome ha estado trabajando en algunas actualizaciones interesantes de la API de Speculation Rules, que se usa para mejorar el rendimiento de la navegación a través de la recuperación previa o incluso la renderización previa de navegaciones futuras. Todas estas mejoras adicionales ya están disponibles en Chrome 122 (algunas funciones están disponibles en versiones anteriores).
Estos cambios hacen que las páginas de la recuperación previa y la renderización previa sean mucho más fáciles de implementar y menos derrochadoras, lo que esperamos que fomente una mayor adopción.
Funciones adicionales
Primero, explicaremos las nuevas incorporaciones que agregamos a la API de Speculation Rules y cómo usarlas. Después de esto, te mostraremos una demostración para que puedas verlos en acción.
Reglas de documentos
Anteriormente, la API de Speculation Rules funcionaba especificando una lista de URLs para realizar una recuperación previa o una renderización previa:
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next2.html"]
}
]
}
</script>
Las reglas de especulación eran semidinámicas, ya que se podían agregar nuevos scripts de reglas de especulación y quitar los antiguos para descartar esas especulaciones (ten en cuenta que actualizar la lista de urls de un script de reglas de especulación existente no activa un cambio en las especulaciones). Sin embargo, el sitio seguía teniendo la opción de elegir las URLs, ya sea enviándolas desde el servidor en el momento de la solicitud de la página o creando esta lista de forma dinámica a través de JavaScript del cliente.
Las reglas de lista siguen siendo una opción para casos de uso más simples (en los que la siguiente navegación se realiza desde un pequeño conjunto de opciones obvias) o casos de uso más avanzados (en los que la lista de URLs se calcula de forma dinámica en función de las heurísticas que el propietario del sitio desee usar y, luego, se inserta en la página).
Como alternativa, nos complace ofrecer una nueva opción para la búsqueda automática de vínculos con reglas del documento. Para ello, se obtienen URLs del propio documento según una condición where. Esto puede basarse en los vínculos mismos:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/logout/*"}}
]
},
"eagerness": "moderate"
}]
}
</script>
Los selectores CSS también se pueden usar como alternativa o en conjunto con las coincidencias de href para encontrar vínculos en la página actual:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "selector_matches": ".prerender" },
{ "not": {"selector_matches": ".do-not-prerender"}}
]
},
"eagerness": "moderate"
}]
}
</script>
Esto permite que se use un solo conjunto de reglas de especulación en todo el sitio, en lugar de tener conjuntos específicos para cada página, lo que facilita mucho la implementación de reglas de especulación en los sitios.
Por supuesto, realizar una renderización previa de todos los vínculos de una página sería un desperdicio, por lo que, con esta nueva capacidad, presentamos un parámetro de configuración de eagerness.
Entusiasmo
Con cualquier tipo de especulación, existe una compensación entre la precisión y la recuperación, y el tiempo de anticipación. La renderización previa de todos los vínculos en la carga de la página significa que casi con certeza se realizará la renderización previa de un vínculo en el que haga clic el usuario (suponiendo que haga clic en un vínculo del mismo sitio en la página) y con la mayor anticipación posible, pero con un posible desperdicio enorme de ancho de banda.
Por otro lado, solo realizar la representación previa una vez que el usuario hizo clic en un vínculo evita el desperdicio, pero a costa de un tiempo de anticipación mucho menor. Esto significa que es poco probable que se haya completado la renderización previa antes de que el navegador cambie a esa página.
El parámetro de configuración eagerness te permite definir cuándo se deben ejecutar las especulaciones, separando cuándo especular de las URLs en las que se deben realizar las especulaciones. El parámetro de configuración eagerness está disponible para las reglas de origen list y document, y tiene cuatro parámetros de configuración para los que Chrome tiene las siguientes heurísticas:
immediate: Se utiliza para hacer una especulación lo más pronto posible, es decir, ni bien se observan las reglas de especulación.eager: Actualmente, su comportamiento es idéntico al del parámetro de configuraciónimmediate, pero queremos ubicarlo en algún lugar entreimmediateymoderatemás adelante.moderate: Este parámetro realiza especulaciones cuando se coloca el cursor sobre un vínculo por 200 milisegundos (o en el eventopointerdown, si ocurre antes, y en dispositivos móviles, donde no se puede colocar el cursor sobre un elemento).hoverconservative: Este parámetro realiza una especulación sobre el puntero o el evento de toque.
El valor predeterminado de eagerness para las reglas de list es immediate. Las opciones moderate y conservative se pueden usar para limitar las reglas de list a una lista específica de URLs con las que interactúa un usuario. Sin embargo, en muchos casos, las reglas document con una condición where adecuada pueden ser más apropiadas.
El valor predeterminado de eagerness para las reglas de document es conservative. Dado que un documento puede constar de muchas URLs, el uso de immediate o eager para las reglas de document debe hacerse con precaución (consulta también la siguiente sección sobre los límites de Chrome).
El parámetro de configuración de eagerness que debes usar depende de tu sitio. En el caso de un sitio estático muy simple, especular con más entusiasmo puede tener un costo bajo y ser beneficioso para los usuarios. Los sitios con arquitecturas más complejas y cargas útiles de página más pesadas pueden preferir reducir el desperdicio especulando con menos frecuencia hasta que obtengas más indicadores positivos de intención de los usuarios para limitar el desperdicio.
La opción moderate es un punto medio, y muchos sitios podrían beneficiarse de la siguiente regla de especulación simple que preprocesaría todos los vínculos al pasar el cursor o al hacer clic con el puntero como una implementación básica, pero potente, de las reglas de especulación:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
Límites de Chrome
Incluso con la opción de eagerness, Chrome tiene límites para evitar el uso excesivo de esta API:
eagerness |
Recuperación previa | Renderización previa |
|---|---|---|
immediate/eager |
50 | 10 |
moderate/conservative |
2 (FIFO) | 2 (FIFO) |
Los parámetros de configuración moderate y conservative, que dependen de la interacción del usuario, funcionan según el método primero en entrar, primero en salir (FIFO). Después de alcanzar el límite, una nueva especulación hará que se cancele la más antigua y se reemplace por la más reciente para conservar la memoria.
El hecho de que los usuarios activen las especulaciones de moderate y conservative nos permite usar un umbral más modesto de 2 para conservar la memoria. La configuración de immediate y eager no se activa por una acción del usuario, por lo que tienen un límite más alto, ya que el navegador no puede saber cuáles se necesitan y cuándo.
Una especulación que se cancela porque se saca de la cola FIFO se puede volver a activar, por ejemplo, si se vuelve a colocar el cursor sobre ese vínculo, lo que hará que se vuelva a especular la URL. En ese caso, es probable que la especulación anterior haya provocado que el navegador almacene en caché algunos recursos en la caché HTTP para esa URL, por lo que repetir la especulación debería reducir considerablemente los costos de red y de tiempo.
Los límites de immediate y eager también son dinámicos. Quitar un elemento de secuencia de comandos de reglas de especulación con estos niveles de anticipación creará capacidad, ya que se cancelarán las especulaciones quitadas. Estas URLs también se pueden volver a especular si se incluyen en una secuencia de comandos de URL nueva y no se alcanzó el límite.
Chrome también impedirá que se usen especulaciones en ciertas condiciones, incluidas las siguientes:
- Save-Data.
- Ahorro de energía
- Restricciones de memoria
- Cuando el parámetro de configuración "Precargar páginas" está desactivado (lo que también desactivan explícitamente las extensiones de Chrome, como uBlock Origin)
- Páginas abiertas en pestañas en segundo plano
Todas estas condiciones tienen como objetivo reducir el impacto de la especulación excesiva cuando sería perjudicial para los usuarios.
Opcional source
Chrome 122 hace que la clave source sea opcional, ya que se puede inferir a partir de la presencia de las claves url o where. Por lo tanto, estas dos reglas de especulación son idénticas:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
<script type="speculationrules">
{
"prerender": [{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
Encabezado HTTP Speculation-Rules
Las reglas de especulación también se pueden entregar con un encabezado HTTP Speculation-Rules, en lugar de incluirlas directamente en el código HTML del documento. Esto permite que las CDN realicen implementaciones más fácilmente sin necesidad de alterar el contenido de los documentos.
El encabezado HTTP Speculation-Rules se devuelve con el documento y apunta a la ubicación de un archivo JSON que contiene las reglas de especulación:
Speculation-Rules: "/speculationrules.json"
Este recurso debe usar el tipo de MIME correcto y, si es un recurso de origen cruzado, debe pasar una verificación de CORS.
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
Si deseas usar URLs relativas, es posible que quieras incluir la clave "relative_to": "document" en tus reglas de especulación. De lo contrario, las URLs relativas serán relativas a la URL del archivo JSON de reglas de especulación. Esto puede ser especialmente útil si necesitas seleccionar algunos vínculos del mismo origen, o todos.
Mejor reutilización de la caché
Realizamos varias mejoras en el almacenamiento en caché de Chrome para que la recuperación previa (o incluso la renderización previa) de un documento almacene y reutilice recursos en la caché HTTP. Esto significa que especular puede seguir teniendo beneficios en el futuro, incluso si no se usa esa especulación.
Esto también hace que la reespeculación (por ejemplo, para las reglas de documentos con un parámetro de configuración de urgencia moderate) sea mucho más económica, ya que Chrome usará la caché HTTP para los recursos almacenables en caché.
También admitimos la nueva propuesta de No-Vary-Search para mejorar aún más la reutilización de la caché.
Compatibilidad con No-Vary-Search
Cuando se realiza una recuperación previa o una renderización previa de una página, ciertos parámetros de URL (conocidos técnicamente como parámetros de búsqueda) pueden no ser importantes para la página que realmente entrega el servidor y solo se usan en JavaScript del cliente.
Por ejemplo, Google Analytics utiliza los parámetros UTM para medir las campañas, pero, por lo general, no generan la publicación de páginas diferentes desde el servidor. Esto significa que page1.html?utm_content=123 y page1.html?utm_content=456 entregarán la misma página desde el servidor, por lo que la misma página se puede reutilizar desde la caché.
Del mismo modo, las aplicaciones pueden usar otros parámetros de URL que solo se controlan del lado del cliente.
La propuesta No-Vary-Search permite que un servidor especifique parámetros que no generan una diferencia en el recurso entregado y, por lo tanto, permite que un navegador reutilice versiones almacenadas en caché previamente de un documento que solo difiere en estos parámetros. Nota: Actualmente, esta función solo es compatible con Chrome (y los navegadores basados en Chromium) para las especulaciones de navegación de la recuperación previa.
Las reglas de especulación admiten el uso de expects_no_vary_search para indicar dónde se espera que se muestre un encabezado HTTP No-Vary-Search. Esto puede ayudar a evitar aún más las descargas innecesarias.
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
En este ejemplo, el código HTML inicial de la página /products es el mismo para los IDs de producto 123 y 124. Sin embargo, el contenido de la página finalmente difiere según la renderización del cliente que usa JavaScript para recuperar los datos del producto con el parámetro de búsqueda id. Por lo tanto, realizamos una recuperación previa de esa URL de forma anticipada, y debería mostrar un encabezado HTTP No-Vary-Search que indique que la página se puede usar para cualquier parámetro de búsqueda id.
Sin embargo, si el usuario hace clic en alguno de los vínculos antes de que se complete la recuperación previa, es posible que el navegador no haya recibido la página /products. En este caso, el navegador no sabe si contendrá el encabezado HTTP No-Vary-Search. Luego, el navegador debe elegir si recupera el vínculo de nuevo o espera a que se complete la recuperación previa para ver si contiene un encabezado HTTP No-Vary-Search. El parámetro de configuración expects_no_vary_search permite que el navegador sepa que se espera que la respuesta de la página contenga un encabezado HTTP No-Vary-Search y que espere a que se complete la recuperación previa.
Demostración
Creamos una demostración en https://chrome.dev/speculative-loading/common-fruits.html que se puede usar para ver las reglas del documento con un parámetro de configuración de moderate de anticipación en acción:
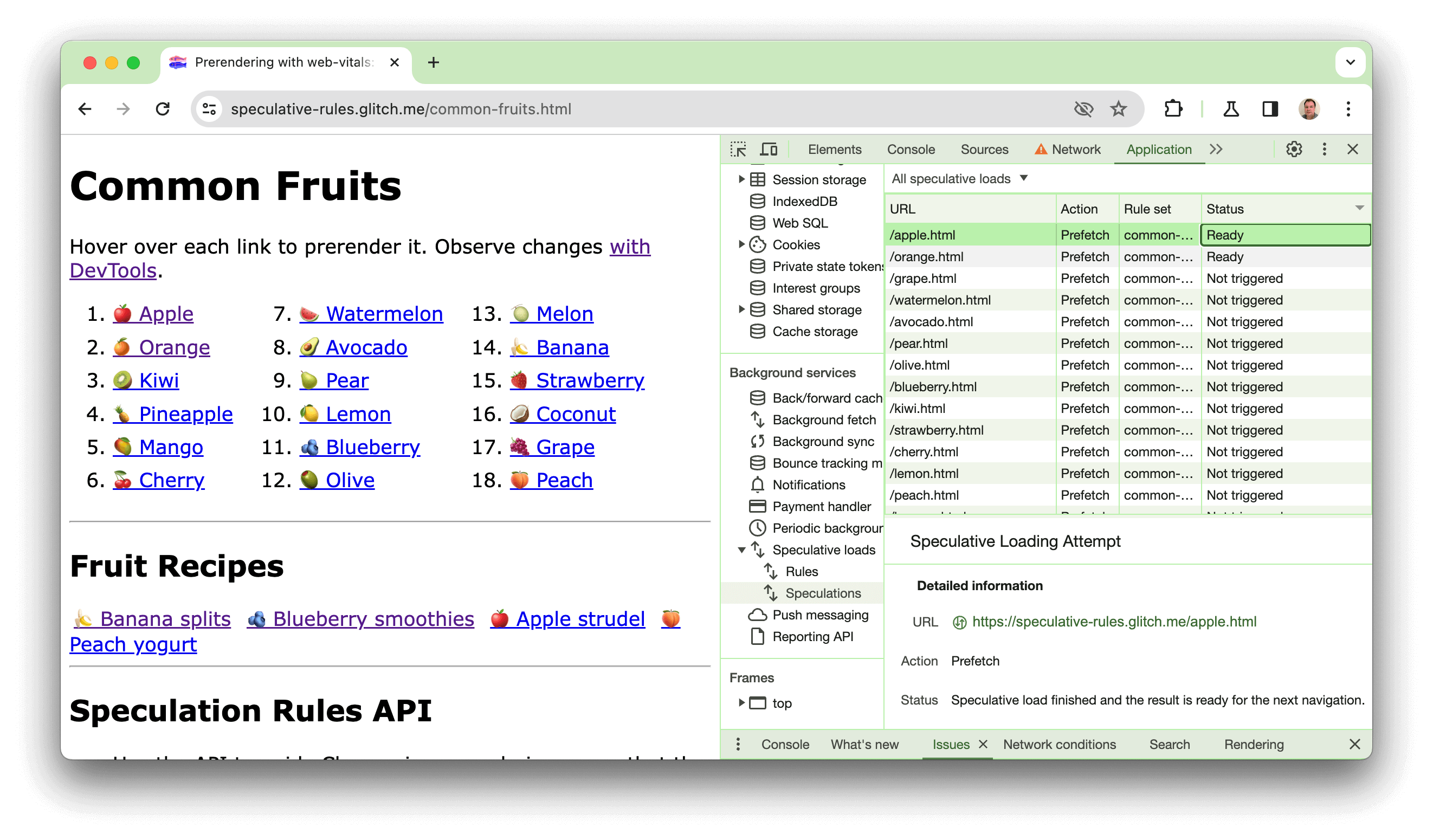
Abre Herramientas para desarrolladores y haz clic en el panel Aplicación. Luego, en la sección Servicios en segundo plano, haz clic en Cargas especulativas, luego en el panel Especulaciones y, por último, ordena por la columna Estado.
A medida que coloques el cursor sobre las frutas, verás cómo se realiza la renderización previa de las páginas. Si haces clic en ellos, se mostrará un tiempo de LCP mucho más rápido que el de una de las recetas, que no se renderizan previamente. Esta demostración también se explica en el siguiente video:
También puedes consultar la entrada de blog anterior sobre la depuración de reglas de especulación para obtener más información sobre cómo usar Herramientas para desarrolladores para depurar reglas de especulación.
Compatibilidad de la plataforma con las reglas de especulación
Si bien las reglas de especulación son relativamente sencillas de implementar, ya que se insertan en un elemento <script type="speculationrules">, la compatibilidad con la plataforma puede hacer que esto se realice con un solo clic. Trabajamos con varias plataformas y socios para facilitar la implementación de las reglas sobre especulaciones.
También trabajamos arduamente para estandarizar la API a través del Web Incubator Community Group (WICG) para permitir que otros navegadores también implementen esta emocionante API si así lo desean.
WordPress
El equipo de rendimiento del núcleo de WordPress (que incluye desarrolladores de Google) creó un complemento de Speculation Rules. Este complemento permite agregar con un solo clic la compatibilidad con reglas de documentos a cualquier sitio de WordPress. Este complemento también está disponible para su instalación a través del complemento WordPress Performance Lab, que también deberías considerar instalar, ya que te mantendrá al tanto de los complementos de rendimiento relacionados del equipo.
Hay dos grupos de parámetros de configuración disponibles: el modo de especulación y el parámetro de configuración de entusiasmo:

Para configuraciones más complejas (por ejemplo, para excluir ciertas URLs de la recuperación previa o la renderización previa), consulta la documentación.
Akamai
Akamai es uno de los principales proveedores de CDN del mundo y ha estado experimentando activamente con la API de Speculation Rules durante algún tiempo. Akamai publicó documentación sobre cómo los clientes pueden habilitar esta API en la configuración de su CDN. También compartieron anteriormente los impresionantes resultados que se pueden obtener con esta nueva API.
Uxify
Uxify (anteriormente parte de Nitropack) es una solución de optimización del rendimiento que utiliza su IA de navegación personalizada para predecir qué páginas agregar a las reglas de especulación, lo que tiene como objetivo proporcionar un tiempo de anticipación más largo que el de pasar el cursor sobre un vínculo, pero sin el desperdicio de especular innecesariamente sobre todos los vínculos observados. Consulta la documentación de la API de Uxify Speculation Rules para obtener más información. Esta innovadora solución demuestra que las reglas de la lista más antiguas aún tienen mucho que ofrecer cuando se combinan con estadísticas específicas del sitio.
El equipo de Chrome también trabajó con el equipo en un seminario web sobre la API de Speculation Rules para quienes buscan más información, que incluye un buen debate sobre las consideraciones necesarias entre especular de forma temprana y frecuente, así como de forma tardía y con menos frecuencia.
Astrofotografía
Astro agregó páginas de renderización previa con la API de Speculation Rules en la versión 4.2 de forma experimental, lo que permite que los desarrolladores que usan Astro habiliten esta función con facilidad y, al mismo tiempo, recurran a una recuperación previa estándar para los navegadores que no admiten la API de Speculation Rules. Lee su documentación sobre la renderización previa del cliente para obtener más información.
Conclusión
Estas incorporaciones a la API de Speculation Rules permiten usar de forma mucho más sencilla esta nueva y emocionante función de rendimiento para los sitios, con menos riesgo de desperdiciar recursos con especulaciones no utilizadas. Es emocionante ver que las plataformas ya se inclinan por esta API. Esperamos que esta API se adopte más ampliamente en 2024 y, en última instancia, que los usuarios finales disfruten de un mejor rendimiento como resultado.
Además de las mejoras en el rendimiento que proporciona la API de Speculation Rules, nos entusiasma ver las nuevas oportunidades que ofrece. View Transitions es una nueva API que permite a los desarrolladores especificar transiciones entre navegaciones con mayor facilidad. Actualmente, está disponible para las aplicaciones de una sola página (SPA), pero la versión de varias páginas está en desarrollo (y disponible detrás de una marca en Chrome). La función de renderización previa es un complemento natural de esa función para garantizar que no haya demoras, lo que, de lo contrario, impediría la mejora de la experiencia del usuario que se pretende proporcionar con la transición. Ya vimos sitios que experimentan con esta combinación.
Esperamos que la API de Speculation Rules se adopte aún más a lo largo del 2024 y te mantendremos al tanto de las mejoras que realicemos en ella.
Agradecimientos
Miniatura de Robbie Down en Unsplash