

A equipe do Chrome está trabalhando em algumas atualizações interessantes da API Speculation Rules, usada para melhorar o desempenho da navegação fazendo pré-busca ou até mesmo pré-renderização de navegações futuras. Essas melhorias adicionais agora estão disponíveis no Chrome 122 (alguns recursos estão disponíveis em versões anteriores).
Essas mudanças facilitam muito a implantação e reduzem o desperdício de páginas de pré-busca e pré-renderização, o que esperamos que incentive mais adoção.
Outros recursos
Primeiro, vamos explicar as novas adições que fizemos à API Speculation Rules e como usá-las. Depois disso, vamos mostrar uma demonstração para que você possa vê-los em ação.
Regras de documento
Antes, a API Speculation Rules funcionava especificando uma lista de URLs para pré-busca ou pré-renderização:
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next2.html"]
}
]
}
</script>
As regras de especulação eram semidinâmicas, já que novos scripts de regras de especulação podiam ser adicionados, e os antigos, removidos para descartar essas especulações. Atualizar a lista urls de um script de regras de especulação não aciona uma mudança nas especulações. No entanto, ainda deixava a escolha dos URLs para o site, enviando-os do servidor no momento da solicitação da página ou criando dinamicamente essa lista com JavaScript do lado do cliente.
As regras de lista continuam sendo uma opção para casos de uso mais simples (em que a próxima navegação é de um pequeno conjunto de opções óbvias) ou mais avançados (em que a lista de URLs é calculada dinamicamente com base em qualquer heurística que o proprietário do site queira usar e, em seguida, inserida na página).
Como alternativa, temos uma nova opção para encontrar links automaticamente usando regras de documentos. Isso funciona buscando URLs do próprio documento com base em uma condição where. Isso pode ser baseado nos próprios links:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/logout/*"}}
]
},
"eagerness": "moderate"
}]
}
</script>
Os seletores de CSS também podem ser usados como uma alternativa ou em conjunto com correspondências de href para encontrar links na página atual:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "selector_matches": ".prerender" },
{ "not": {"selector_matches": ".do-not-prerender"}}
]
},
"eagerness": "moderate"
}]
}
</script>
Isso permite que um único conjunto de regras de especulação seja usado em todo o site, em vez de ter regras específicas por página, facilitando muito a implantação das regras de especulação.
É claro que a pré-renderização de todos os links em uma página seria um desperdício. Por isso, com essa nova capacidade, introduzimos uma configuração eagerness.
Ansiedade
Em qualquer tipo de especulação, há uma compensação entre precisão e recall e o tempo de antecedência. A pré-renderização de todos os links no carregamento da página significa que você quase certamente vai pré-renderizar um link em que um usuário clica (supondo que ele clique em um link do mesmo site na página) e com o máximo de antecedência possível, mas com um desperdício potencialmente enorme de largura de banda.
Por outro lado, a pré-renderização apenas quando um usuário clica em um link evita o desperdício, mas ao custo de um tempo de espera muito reduzido. Isso significa que é improvável que a pré-renderização tenha sido concluída antes que o navegador mude para essa página.
A configuração eagerness permite definir quando as especulações devem ser executadas, separando quando especular de quais URLs realizar especulações. A configuração eagerness está disponível para regras de origem list e document e tem quatro configurações. Para elas, o Chrome tem as seguintes heurísticas:
immediate:usada para especular o mais rápido possível, isto é, assim que as regras de especulação forem observadas.eager:atualmente, funciona de maneira idêntica à configuraçãoimmediate, mas, no futuro, vamos procurar situar entreimmediateemoderate.moderate:realiza especulações se você passar o cursor sobre um link por 200 milissegundos (ou no eventopointerdownse for antes, e no dispositivo móvel onde não há eventohover).conservative:especula no ponteiro ou no toque.
O eagerness padrão para regras de list é immediate. As opções moderate e conservative podem ser usadas para limitar as regras list a URLs com que um usuário interage em uma lista específica. No entanto, em muitos casos, as regras de document com uma condição where adequada podem ser mais apropriadas.
O eagerness padrão para regras de document é conservative. Como um documento pode consistir em muitos URLs, o uso de immediate ou eager para regras document precisa ser feito com cuidado. Consulte também a seção Limites do Chrome a seguir.
A configuração de eagerness a ser usada depende do seu site. Para um site estático muito simples, especular com mais avidez pode ter pouco custo e ser benéfico para os usuários. Sites com arquiteturas mais complexas e payloads de página mais pesados podem preferir reduzir o desperdício especulando com menos frequência até receber um sinal mais positivo de intenção dos usuários.
A opção moderate é um meio-termo, e muitos sites podem se beneficiar da seguinte regra de especulação simples, que pré-renderiza todos os links ao passar o cursor ou com o evento pointerdown como uma implementação básica, mas poderosa, das regras de especulação:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
Limites do Chrome
Mesmo com a opção eagerness, o Chrome tem limites para evitar o uso excessivo dessa API:
eagerness |
Pré-busca | Pré-renderização |
|---|---|---|
immediate / eager |
50 | 10 |
moderate / conservative |
2 (FIFO) | 2 (FIFO) |
As configurações moderate e conservative, que dependem da interação do usuário, funcionam de acordo com o princípio First In, First Out (FIFO). Depois de atingir o limite, uma nova especulação fará com que a mais antiga seja cancelada e substituída pela mais recente para economizar memória.
O fato de as especulações moderate e conservative serem acionadas pelos usuários permite que usemos um limite mais modesto de 2 para conservar a memória. As configurações immediate e eager não são acionadas por uma ação do usuário e, portanto, têm um limite maior, já que não é possível para o navegador saber quais são necessárias e quando.
Uma especulação cancelada por ser removida da fila FIFO pode ser acionada novamente, por exemplo, ao passar o cursor sobre o link de novo, o que vai resultar em uma nova especulação do URL. Nesse caso, a especulação anterior provavelmente fez com que o navegador armazenasse em cache alguns recursos no cache HTTP para esse URL. Portanto, repetir a especulação deve reduzir muito os custos de rede e de tempo.
Os limites de immediate e eager também são dinâmicos. Remover um elemento de script de regras de especulação usando esses níveis de ansiedade cria capacidade ao cancelar as especulações removidas. Esses URLs também podem ser especulados novamente se forem incluídos em um novo script de URL e o limite não tiver sido atingido.
O Chrome também impede que especulações sejam usadas em determinadas condições, incluindo:
- Save-Data.
- Economia de energia.
- Restrições de memória.
- Quando a configuração "Pré-carregar páginas" está desativada, o que também é feito explicitamente por extensões do Chrome, como o uBlock Origin.
- Páginas abertas em guias em segundo plano.
Todas essas condições visam reduzir o impacto da especulação excessiva quando ela é prejudicial aos usuários.
Opcional source
O Chrome 122 torna a chave source opcional, já que ela pode ser inferida da presença das chaves url ou where. Portanto, essas duas regras de especulação são idênticas:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
<script type="speculationrules">
{
"prerender": [{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
Cabeçalho HTTP Speculation-Rules
As regras de especulação também podem ser entregues usando um cabeçalho HTTP Speculation-Rules, em vez de serem incluídas diretamente no HTML do documento. Isso facilita a implantação por CDNs sem a necessidade de alterar o conteúdo dos documentos.
O cabeçalho HTTP Speculation-Rules é retornado com o documento e aponta para um local de um arquivo JSON que contém as regras de especulação:
Speculation-Rules: "/speculationrules.json"
Esse recurso precisa usar o tipo MIME correto e, se for de origem cruzada, passar por uma verificação do CORS.
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
Se você quiser usar URLs relativos, inclua a chave "relative_to": "document" nas suas regras de especulação. Caso contrário, os URLs relativos serão relativos ao URL do arquivo JSON de regras de especulação. Isso pode ser especialmente útil se você precisar selecionar alguns ou todos os links de mesma origem.
Melhor reutilização do cache
Fizemos várias melhorias no cache do Chrome para que a pré-busca (ou até mesmo a pré-renderização) de um documento armazene e reutilize recursos no cache HTTP. Isso significa que a especulação ainda pode ter benefícios futuros, mesmo que não seja usada.
Isso também torna a reespeculação (por exemplo, para regras de documentos com uma configuração de ânimo moderate) consideravelmente mais barata, já que o Chrome usa o cache HTTP para recursos armazenáveis em cache.
Também oferecemos suporte à nova proposta No-Vary-Search para melhorar ainda mais a reutilização do cache.
Suporte a No-Vary-Search
Ao pré-buscar ou pré-renderizar uma página, determinados parâmetros de URL (tecnicamente conhecidos como parâmetros de pesquisa) podem ser irrelevantes para a página realmente entregue pelo servidor e usados apenas pelo JavaScript do lado do cliente.
Por exemplo, os parâmetros UTM são usados pelo Google Analytics para medir campanhas, mas geralmente não resultam na entrega de páginas diferentes do servidor. Isso significa que page1.html?utm_content=123 e page1.html?utm_content=456 vão veicular a mesma página do servidor, que pode ser reutilizada do cache.
Da mesma forma, os aplicativos podem usar outros parâmetros de URL que são processados apenas no lado do cliente.
A proposta No-Vary-Search permite que um servidor especifique parâmetros que não resultam em uma diferença no recurso entregue e, portanto, permite que um navegador reutilize versões de um documento armazenadas em cache anteriormente que diferem apenas por esses parâmetros. Observação: no momento, isso só é compatível com o Chrome (e navegadores baseados no Chromium) para especulações de navegação por pré-busca.
As regras de especulação oferecem suporte ao uso de expects_no_vary_search para indicar onde um cabeçalho HTTP No-Vary-Search deve ser retornado. Isso ajuda a evitar downloads desnecessários.
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
Neste exemplo, o HTML da página inicial /products é o mesmo para os dois IDs de produto 123 e 124. No entanto, o conteúdo da página acaba sendo diferente com base na renderização do lado do cliente usando JavaScript para buscar dados de produtos com o parâmetro de pesquisa id. Assim, fazemos a pré-busca desse URL de maneira antecipada, e ele retorna um cabeçalho HTTP No-Vary-Search mostrando que a página pode ser usada para qualquer parâmetro de pesquisa id.
No entanto, se o usuário clicar em um dos links antes da conclusão do pré-busca, o navegador poderá não ter recebido a página /products. Nesse caso, o navegador não sabe se ele vai conter o cabeçalho HTTP No-Vary-Search. O navegador precisa decidir se vai buscar o link novamente ou esperar a conclusão da pré-busca para ver se ele contém um cabeçalho HTTP No-Vary-Search. A configuração expects_no_vary_search permite que o navegador saiba que a resposta da página deve conter um cabeçalho HTTP No-Vary-Search e aguarde a conclusão da pré-busca.
Demonstração
Criamos uma demonstração em https://chrome.dev/speculative-loading/common-fruits.html, que pode ser usada para ver regras de documentos com uma configuração de moderate de prontidão em ação:
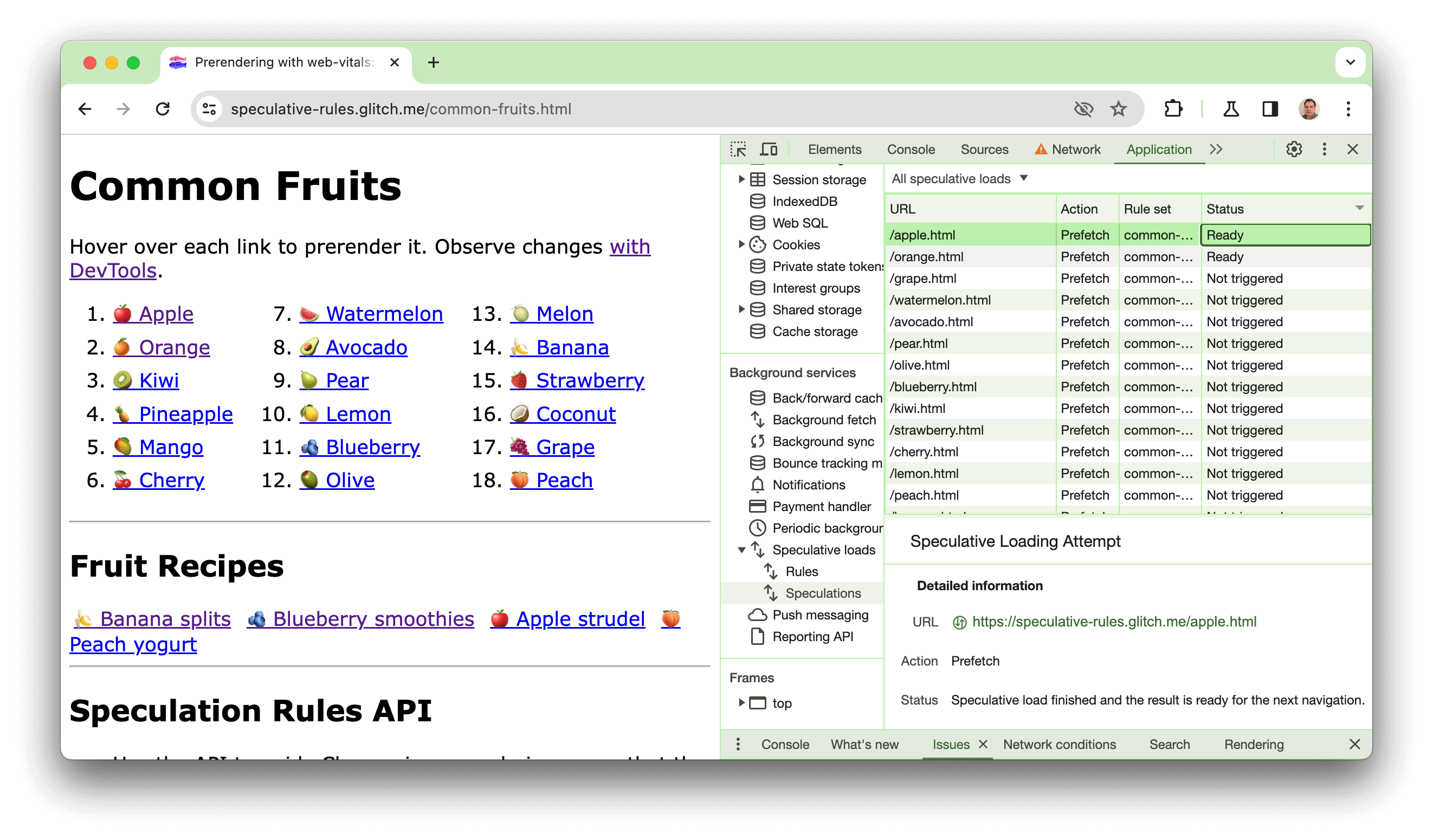
Abra o DevTools e clique no painel Application. Em seguida, na seção Serviços em segundo plano, clique em Carregamentos especulativos, depois no painel Especulações e classifique pela coluna Status.
Ao passar o cursor sobre as frutas, você vai ver as páginas sendo pré-renderizadas. Ao clicar neles, você vai notar um tempo de LCP muito mais rápido do que em uma das receitas, que não são pré-renderizadas. Essa demonstração também é explicada neste vídeo:
Confira também a postagem anterior do blog sobre como depurar regras de especulação para mais informações sobre como usar o DevTools para depurar essas regras.
Suporte de plataforma para regras de especulação
Embora as regras de especulação sejam relativamente simples de implementar injetando as regras em um elemento <script type="speculationrules">, o suporte da plataforma pode tornar isso uma ação com um clique. Estamos trabalhando com várias plataformas e parceiros para facilitar a implantação das regras de especulação.
Também estamos trabalhando para padronizar a API pelo Web Incubator Community Group (WICG), permitindo que outros navegadores também implementem essa API incrível, se quiserem.
WordPress
A equipe de performance do WordPress Core (incluindo desenvolvedores do Google) criou um plug-in de regras de especulação. Com esse plug-in, é possível adicionar suporte a regras de documentos a qualquer site do WordPress com um clique. Ele também pode ser instalado pelo plug-in WordPress Performance Lab, que recomendamos instalar para ficar por dentro dos plug-ins de performance relacionados da equipe.
Há dois grupos de configurações disponíveis: o Modo de especulação e a configuração Disposição:

Para configurações mais complicadas, por exemplo, para excluir determinados URLs da pré-busca ou pré-renderização, leia a documentação.
Akamai
A Akamai é um dos principais provedores de CDN do mundo e está testando ativamente a API Speculation Rules há algum tempo. A Akamai lançou uma documentação sobre como os clientes podem ativar essa API nas configurações de CDN. Eles também já compartilharam os resultados impressionantes possíveis com essa nova API.
Uxify
O Uxify (antes parte do Nitropack) é uma solução de otimização de desempenho que usa a IA de navegação personalizada para prever quais páginas adicionar às regras de especulação. O objetivo é oferecer um tempo de espera maior do que passar o cursor sobre um link, mas sem o desperdício de especular desnecessariamente sobre todos os links observados. Consulte a documentação da API Uxify Speculation Rules para mais informações. Essa solução inovadora mostra que as regras de lista mais antigas ainda têm muito a oferecer quando combinadas com insights específicos do site.
A equipe do Chrome também trabalhou com a equipe em um webinar sobre a API Speculation Rules para quem busca mais informações, incluindo uma boa discussão sobre as considerações necessárias entre especular cedo e com frequência, bem como tarde e com menos frequência.
Astrofotografia
O Astro adicionou pré-renderização de páginas usando a API Speculation Rules na versão 4.2 de forma experimental, permitindo que os desenvolvedores que usam o Astro ativem esse recurso com facilidade, enquanto voltam a um pré-busca padrão para navegadores que não oferecem suporte à API Speculation Rules. Leia a documentação de pré-renderização do cliente para mais informações.
Conclusão
Essas adições à API Speculation Rules permitem um uso muito mais simples desse novo recurso de desempenho para sites, com menos risco de desperdiçar recursos com especulações não utilizadas. É incrível ver plataformas já usando essa API. Esperamos ver uma adoção mais ampla dessa API em 2024 e, como resultado, um desempenho melhor para os usuários finais.
Além dos ganhos de performance que a API Speculation Rules oferece, também estamos animados para ver as novas oportunidades que ela abre. As transições de visualização são uma nova API que permite aos desenvolvedores especificar transições entre navegações com mais facilidade. Atualmente, isso está disponível para aplicativos de página única (SPAs), mas a versão de várias páginas está em andamento (e disponível por trás de uma flag no Chrome). A pré-renderização é um complemento natural desse recurso para garantir que não haja atraso, o que impediria a melhoria da experiência do usuário que a transição pretende oferecer. Já vimos sites testando essa combinação.
Esperamos que a API Speculation Rules seja mais adotada ao longo de 2024 e vamos manter você atualizado sobre as melhorias que fizermos nela.
Agradecimentos
Miniatura de Robbie Down no Unsplash