
サービス ワーカーを有効にして、オフラインで動作するページをブラウザに通知する

Content Indexing API とは何ですか?
プログレッシブ ウェブアプリを使用すると、ネットワーク接続の現在の状態に関係なく、ユーザーが関心を持つ情報(画像、動画、記事など)にアクセスできます。Service Worker、Cache Storage API、IndexedDB などのテクノロジーは、ユーザーが PWA を直接操作する際にデータを保存して提供するための構成要素を提供します。ただし、高品質のオフライン ファースト PWA を構築するのは、ほんの一部にすぎません。オフラインでもウェブアプリのコンテンツを利用できることをユーザーが認識していないと、その機能を実装するために費やした労力は十分に活用されません。
これは検出の問題です。ユーザーが利用可能なコンテンツを見つけて表示できるように、PWA でオフライン対応コンテンツをユーザーに知らせるにはどうすればよいでしょうか。Content Indexing API は、この問題の解決策です。このソリューションのデベロッパー向け部分は、サービス ワーカーの拡張機能です。これにより、デベロッパーは、オフライン対応ページの URL とメタデータを、ブラウザによって管理されるローカル インデックスに追加できます。この機能強化は Chrome 84 以降で利用できます。
インデックスに PWA のコンテンツと、インストールされている他の PWA のコンテンツが入力されると、次のようにブラウザに表示されます。
![Chrome の新しいタブページの [ダウンロード] メニュー項目のスクリーンショット。](https://developer.chrome.com/static/docs/capabilities/web-apis/content-indexing-api/image/a-screenshot-the-downloa-d4b2c64470b26.png?authuser=7&hl=ja)
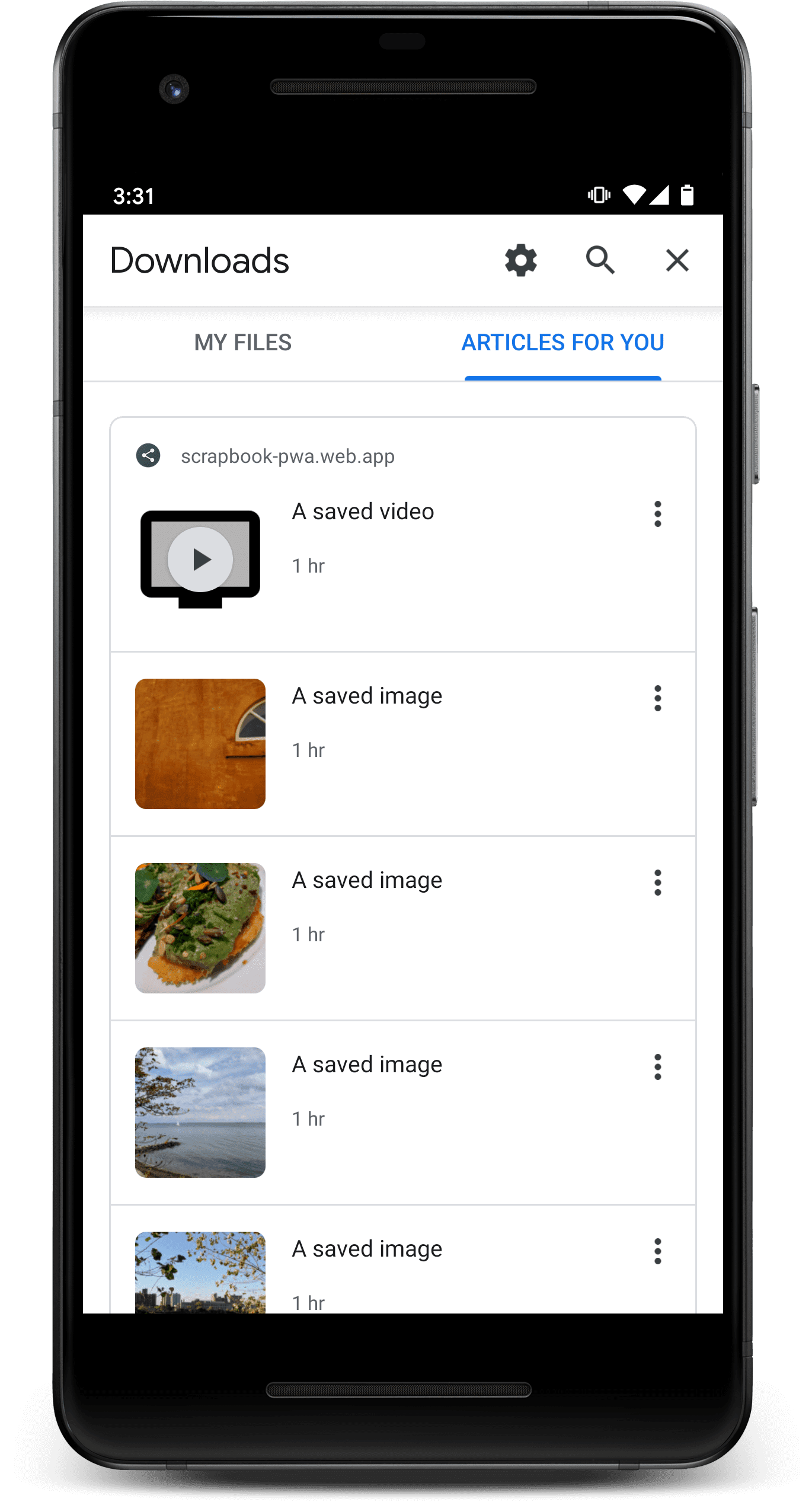
また、ユーザーがオフラインであることを検出すると、Chrome はコンテンツを事前におすすめできます。
Content Indexing API はコンテンツをキャッシュに保存する代替手段ではありません。これは、サービス ワーカーによってすでにキャッシュに保存されているページに関するメタデータを提供する方法です。これにより、ユーザーが閲覧する可能性が高いときに、ブラウザがそれらのページを表示できます。Content Indexing API は、キャッシュに保存されたページの見つけやすさに役立ちます。
実例を見る
Content Indexing API を理解する最善の方法は、サンプル アプリケーションを試すことです。
- サポートされているブラウザとプラットフォームを使用していることを確認します。現在のところ、Android 版 Chrome 84 以降に限定されています。
about://versionに移動して、実行している Chrome のバージョンを確認します。 - https://contentindex.dev にアクセスします。
- リスト内の 1 つ以上のアイテムの横にある
+ボタンをクリックします。 - (省略可)デバイスの Wi-Fi 接続とモバイルデータ接続を無効にするか、機内モードを有効にして、ブラウザをオフラインにすることをシミュレートします。
- Chrome のメニューから [ダウンロード] を選択し、[おすすめの記事] タブに切り替えます。
- 以前に保存したコンテンツを参照します。
GitHub にあるサンプル アプリケーションのソースを確認する。
別のサンプル アプリケーションである Scrapbook PWA は、Content Indexing API と Web Share Target API の使用を示しています。このコードは、Cache Storage API を使用して、Content Indexing API をウェブアプリによって保存されたアイテムと同期させる手法を示しています。
API の使用
この API を使用するには、アプリにサービス ワーカーとオフラインで移動可能な URL が必要です。ウェブアプリに Service Worker がまだない場合は、Workbox ライブラリを使用して簡単に作成できます。
オフライン対応としてインデックスに登録できるのは、どのような種類の URL ですか?
この API は、HTML ドキュメントに対応する URL のインデックス登録をサポートしています。たとえば、キャッシュに保存されたメディア ファイルの URL は直接インデックスに登録できません。代わりに、オフラインで機能するメディアを表示するページの URL を指定する必要があります。
推奨されるパターンは、基盤となるメディア URL をクエリ パラメータとして受け入れ、ファイルの内容を表示する「ビューア」HTML ページを作成することです。必要に応じて、ページにコントロールやコンテンツを追加することもできます。
ウェブアプリは、現在のサービス ワーカーのスコープ内にある URL のみをコンテンツ インデックスに追加できます。つまり、ウェブアプリは、まったく異なるドメインに属する URL をコンテンツ インデックスに追加できませんでした。
概要
Content Indexing API は、メタデータの追加、一覧表示、削除の 3 つのオペレーションをサポートしています。これらのメソッドは、ServiceWorkerRegistration インターフェースに追加された新しいプロパティ index から公開されます。
コンテンツのインデックス登録の最初のステップは、現在の ServiceWorkerRegistration への参照を取得することです。最も簡単な方法は navigator.serviceWorker.ready を使用することです。
const registration = await navigator.serviceWorker.ready;
// Remember to feature-detect before using the API:
if ('index' in registration) {
// Your Content Indexing API code goes here!
}
ウェブページ内ではなく、サービス ワーカー内から Content Indexing API を呼び出す場合は、registration を介して ServiceWorkerRegistration を直接参照できます。ServiceWorkerGlobalScope. の一部としてすでに定義されています
インデックスへの追加
URL とそれに関連するメタデータをインデックスに登録するには、add() メソッドを使用します。アイテムをインデックスに追加するタイミングは任意で選択できます。入力([オフラインに保存] ボタンのクリックなど)に応じてインデックスに追加することもできます。また、定期的なバックグラウンド同期などのメカニズムによってキャッシュに保存されたデータが更新されるたびに、アイテムを自動的に追加することもできます。
await registration.index.add({
// Required; set to something unique within your web app.
id: 'article-123',
// Required; url needs to be an offline-capable HTML page.
url: '/articles/123',
// Required; used in user-visible lists of content.
title: 'Article title',
// Required; used in user-visible lists of content.
description: 'Amazing article about things!',
// Required; used in user-visible lists of content.
icons: [{
src: '/img/article-123.png',
sizes: '64x64',
type: 'image/png',
}],
// Optional; valid categories are currently:
// 'homepage', 'article', 'video', 'audio', or '' (default).
category: 'article',
});
エントリを追加しても、コンテンツ インデックスにのみ影響し、キャッシュには何も追加されません。
エッジケース: アイコンが fetch ハンドラに依存している場合は、window コンテキストから add() を呼び出します。
add() を呼び出すと、Chrome は各アイコンの URL をリクエストし、インデックスに登録されたコンテンツのリストを表示する際に使用するアイコンのコピーを確実に取得します。
windowコンテキスト(つまりウェブページ)からadd()を呼び出すと、このリクエストによって Service Worker でfetchイベントがトリガーされます。サービス ワーカー内で(別のイベント ハンドラ内など)
add()を呼び出すと、リクエストによってサービス ワーカーのfetchハンドラがトリガーされることはありません。アイコンは、サービス ワーカーを介さずに直接取得されます。アイコンがfetchハンドラに依存している場合は、この点に注意してください。アイコンがローカル キャッシュにのみ存在し、ネットワークに存在しない場合があります。呼び出す場合は、windowコンテキストからのみadd()を呼び出すようにしてください。
インデックスの内容を一覧表示する
getAll() メソッドは、インデックス登録されたエントリとそのメタデータの反復可能なリストの Promise を返します。返されるエントリには、add() で保存されたすべてのデータが含まれます。
const entries = await registration.index.getAll();
for (const entry of entries) {
// entry.id, entry.launchUrl, etc. are all exposed.
}
インデックスからアイテムを削除する
インデックスからアイテムを削除するには、削除するアイテムの id を指定して delete() を呼び出します。
await registration.index.delete('article-123');
delete() の呼び出しはインデックスにのみ影響します。キャッシュから何も削除されません。
ユーザー削除イベントの処理
ブラウザにインデックス登録されたコンテンツが表示される場合、[削除] メニュー アイテムを含む独自のユーザー インターフェースが含まれ、以前にインデックス登録されたコンテンツの表示を終了したことをユーザーが示すことができます。Chrome 80 の削除インターフェースは次のとおりです。
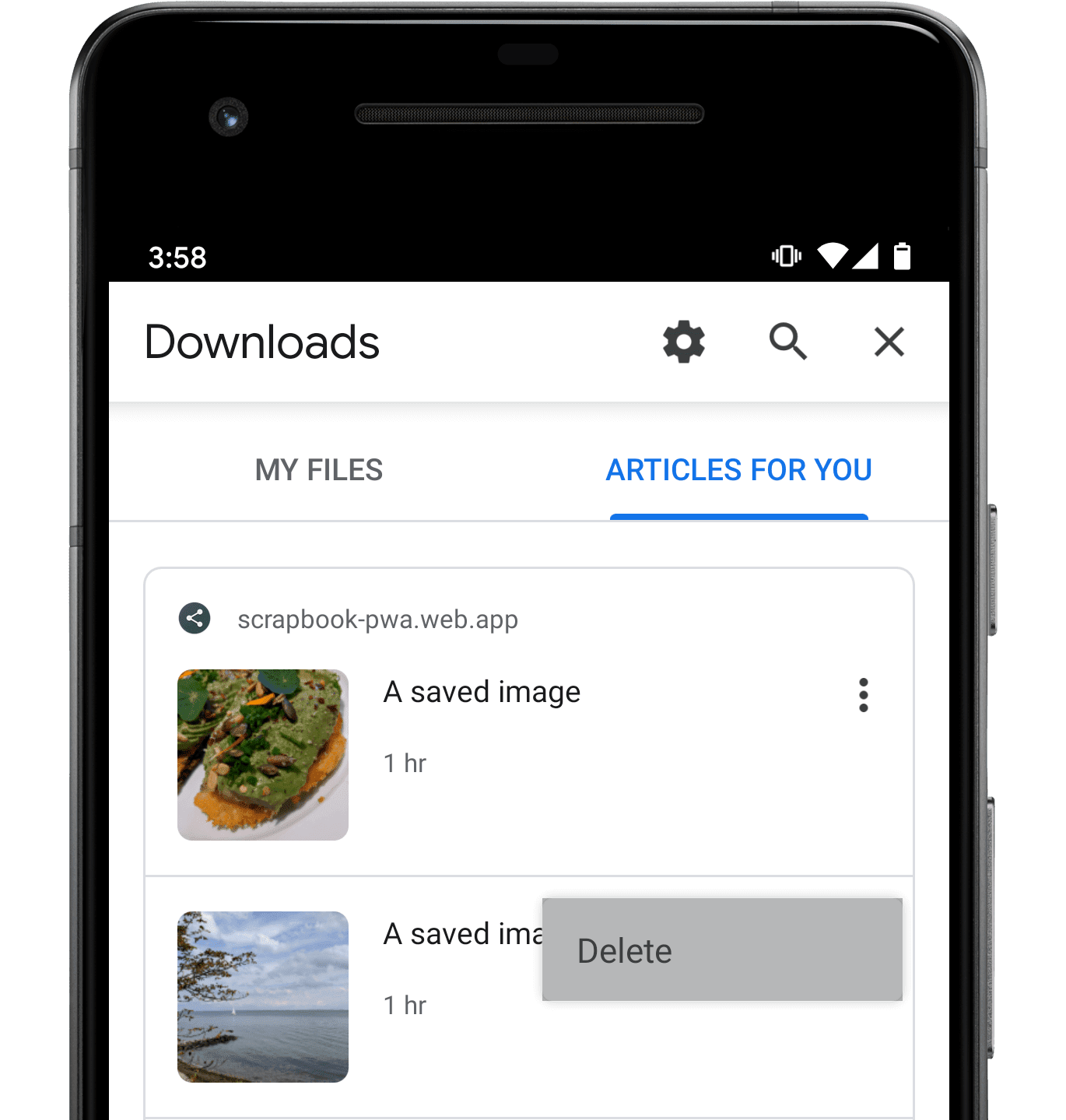
ユーザーがそのメニュー項目を選択すると、ウェブアプリのサービス ワーカーは contentdelete イベントを受信します。このイベントの処理は任意ですが、ユーザーが使用を終了したことを示すコンテンツ(ローカルにキャッシュに保存されたメディア ファイルなど)をサービス ワーカーが「クリーンアップ」する機会となります。
contentdelete ハンドラ内で registration.index.delete() を呼び出す必要はありません。イベントがトリガーされた場合、関連するインデックスの削除はブラウザによってすでに実行されています。
self.addEventListener('contentdelete', (event) => {
// event.id will correspond to the id value used
// when the indexed content was added.
// Use that value to determine what content, if any,
// to delete from wherever your app stores it—usually
// the Cache Storage API or perhaps IndexedDB.
});
API 設計に関するフィードバック
API に不便な点や、想定どおりに動作しない点はありますか?または、アイデアを実装するために必要な要素が不足しているでしょうか。
Content Indexing API の説明用 GitHub リポジトリで問題を報告するか、既存の問題にコメントを追加してください。
実装に関する問題
Chrome の実装にバグが見つかりましたか?
https://new.crbug.com でバグを報告します。できるだけ詳細な情報を含め、再現手順を簡単に説明します。[コンポーネント] を Blink>ContentIndexing に設定します。
API を使用する予定ですか?
ウェブアプリで Content Indexing API を使用する予定ですか?公開サポートは、Chrome が機能を優先付けするうえで役立ちます。また、他のブラウザ ベンダーに、これらの機能をサポートすることがいかに重要であるかを示します。
- ハッシュタグ
#ContentIndexingAPIを使用して、@ChromiumDev にツイートを送信し、使用場所と使用方法の詳細を記載します。
コンテンツのインデックス作成は、セキュリティとプライバシーにどのような影響を与えますか?
W3C のセキュリティとプライバシーに関するアンケートに対する回答を確認してください。他にご不明な点がございましたら、プロジェクトの GitHub リポジトリでディスカッションをお気軽に開始してください。
ヒーロー画像: Unsplash の Maksym Kaharlytskyi 氏