
En esta entrada, se explora la API experimental de WebGPU a través de ejemplos y se te ayuda a comenzar a realizar cálculos paralelos basados en datos con la GPU.

Fecha de publicación: 28 de agosto de 2019 | Última actualización: 12 de agosto de 2025
Fondo
Como ya sabrás, la unidad de procesamiento gráfico (GPU) es un subsistema electrónico dentro de una computadora que originalmente se especializó en el procesamiento de gráficos. Sin embargo, en los últimos 10 años, evolucionó hacia una arquitectura más flexible que permite a los desarrolladores implementar muchos tipos de algoritmos, no solo renderizar gráficos en 3D, y aprovechar la arquitectura única de la GPU. Estas capacidades se conocen como GPU Compute, y el uso de una GPU como coprocesador para la computación científica de uso general se denomina programación de GPU de uso general (GPGPU).
La computación de GPU contribuyó de manera significativa al reciente auge del aprendizaje automático, ya que las redes neuronales convolucionales y otros modelos pueden aprovechar la arquitectura para ejecutarse de manera más eficiente en las GPUs. Dado que la plataforma web actual carece de capacidades de procesamiento de GPU, el grupo comunitario "GPU para la Web" del W3C está diseñando una API para exponer las APIs de GPU modernas que están disponibles en la mayoría de los dispositivos actuales. Esta API se llama WebGPU.
WebGPU es una API de bajo nivel, como WebGL. Es muy potente y bastante detallado, como verás. Pero está bien. Lo que buscamos es rendimiento.
En este artículo, me enfocaré en la parte de GPU Compute de WebGPU y, para ser honesto, solo estoy arañando la superficie, de modo que puedas comenzar a jugar por tu cuenta. En los próximos artículos, profundizaremos en el tema y abordaremos la renderización de WebGPU (canvas, textura, etc.).
Accede a la GPU
Acceder a la GPU es fácil en WebGPU. La llamada a navigator.gpu.requestAdapter() devuelve una promesa de JavaScript que se resolverá de forma asíncrona con un adaptador de GPU. Piensa en este adaptador como la tarjeta gráfica. Puede ser integrada (en el mismo chip que la CPU) o discreta (por lo general, una tarjeta PCIe que tiene un mejor rendimiento, pero usa más energía).
Una vez que tengas el adaptador de GPU, llama a adapter.requestDevice() para obtener una promesa que se resolverá con un dispositivo de GPU que usarás para realizar algunos cálculos en la GPU.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
Ambas funciones toman opciones que te permiten especificar el tipo de adaptador (preferencia de energía) y dispositivo (extensiones, límites) que deseas. Para simplificar, usaremos las opciones predeterminadas en este artículo.
Memoria de búfer de escritura
Veamos cómo usar JavaScript para escribir datos en la memoria de la GPU. Este proceso no es sencillo debido al modelo de zona de pruebas que se usa en los navegadores web modernos.
En el siguiente ejemplo, se muestra cómo escribir cuatro bytes en la memoria del búfer a la que se puede acceder desde la GPU. Llama a device.createBuffer(), que toma el tamaño del búfer y su uso. Aunque la marca de uso GPUBufferUsage.MAP_WRITE no es obligatoria para esta llamada específica, seamos explícitos en que queremos escribir en este búfer. Esto da como resultado un objeto de búfer de GPU asignado en la creación gracias a que mappedAtCreation se establece en verdadero. Luego, se puede recuperar el búfer de datos binarios sin procesar asociado llamando al método de búfer de GPU getMappedRange().
Escribir bytes es familiar si ya trabajaste con ArrayBuffer; usa un TypedArray y copia los valores en él.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
En este punto, se asigna el búfer de GPU, lo que significa que es propiedad de la CPU y se puede acceder a él para leer y escribir desde JavaScript. Para que la GPU pueda acceder a ella, se debe anular la asignación, lo que es tan simple como llamar a gpuBuffer.unmap().
El concepto de asignado/no asignado es necesario para evitar condiciones de carrera en las que la GPU y la CPU acceden a la memoria al mismo tiempo.
Leer la memoria del búfer
Ahora veamos cómo copiar un búfer de GPU a otro y leerlo.
Como escribimos en el primer búfer de GPU y queremos copiarlo en un segundo búfer de GPU, se requiere una nueva marca de uso GPUBufferUsage.COPY_SRC. El segundo búfer de GPU se crea en un estado sin asignar esta vez con device.createBuffer(). Su marca de uso es GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ, ya que se usará como destino del primer búfer de GPU y se leerá en JavaScript una vez que se ejecuten los comandos de copia de GPU.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
Dado que la GPU es un coprocesador independiente, todos los comandos de la GPU se ejecutan de forma asíncrona. Por eso, se crea una lista de comandos de GPU y se envía en lotes cuando es necesario. En WebGPU, el codificador de comandos de la GPU que devuelve device.createCommandEncoder() es el objeto JavaScript que compila un lote de comandos "almacenados en búfer" que se enviarán a la GPU en algún momento. Por otro lado, los métodos de GPUBuffer no se almacenan en búfer, lo que significa que se ejecutan de forma atómica en el momento en que se los llama.
Una vez que tengas el codificador de comandos de la GPU, llama a copyEncoder.copyBufferToBuffer() como se muestra a continuación para agregar este comando a la cola de comandos para su ejecución posterior.
Por último, llama a copyEncoder.finish() para finalizar los comandos de codificación y envíalos a la cola de comandos del dispositivo de GPU. La cola es responsable de controlar los envíos realizados a través de device.queue.submit() con los comandos de la GPU como argumentos.
Esto ejecutará de forma atómica todos los comandos almacenados en el array en orden.
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
En este punto, se enviaron los comandos de la fila de GPU, pero no necesariamente se ejecutaron.
Para leer el segundo búfer de GPU, llama a gpuReadBuffer.mapAsync() con GPUMapMode.READ. Devuelve una promesa que se resolverá cuando se asigne el búfer de la GPU. Luego, obtén el rango asignado con gpuReadBuffer.getMappedRange() que contiene los mismos valores que el primer búfer de GPU una vez que se hayan ejecutado todos los comandos de GPU en cola.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
Puedes probar este ejemplo.
En resumen, esto es lo que debes recordar sobre las operaciones de memoria del búfer:
- Los búferes de GPU deben desasignarse para poder usarse en el envío de la cola del dispositivo.
- Cuando se asignan, los búferes de GPU se pueden leer y escribir en JavaScript.
- Los búferes de la GPU se asignan cuando se llaman a
mapAsync()ycreateBuffer()conmappedAtCreationestablecido como verdadero.
Programación de sombreadores
Los programas que se ejecutan en la GPU y solo realizan cálculos (y no dibujan triángulos) se denominan sombreadores de procesamiento. Cientos de núcleos de GPU (que son más pequeños que los núcleos de CPU) los ejecutan en paralelo y operan en conjunto para procesar datos. Su entrada y salida son búferes en WebGPU.
Para ilustrar el uso de sombreadores de procesamiento en WebGPU, trabajaremos con la multiplicación de matrices, un algoritmo común en el aprendizaje automático que se ilustra a continuación.
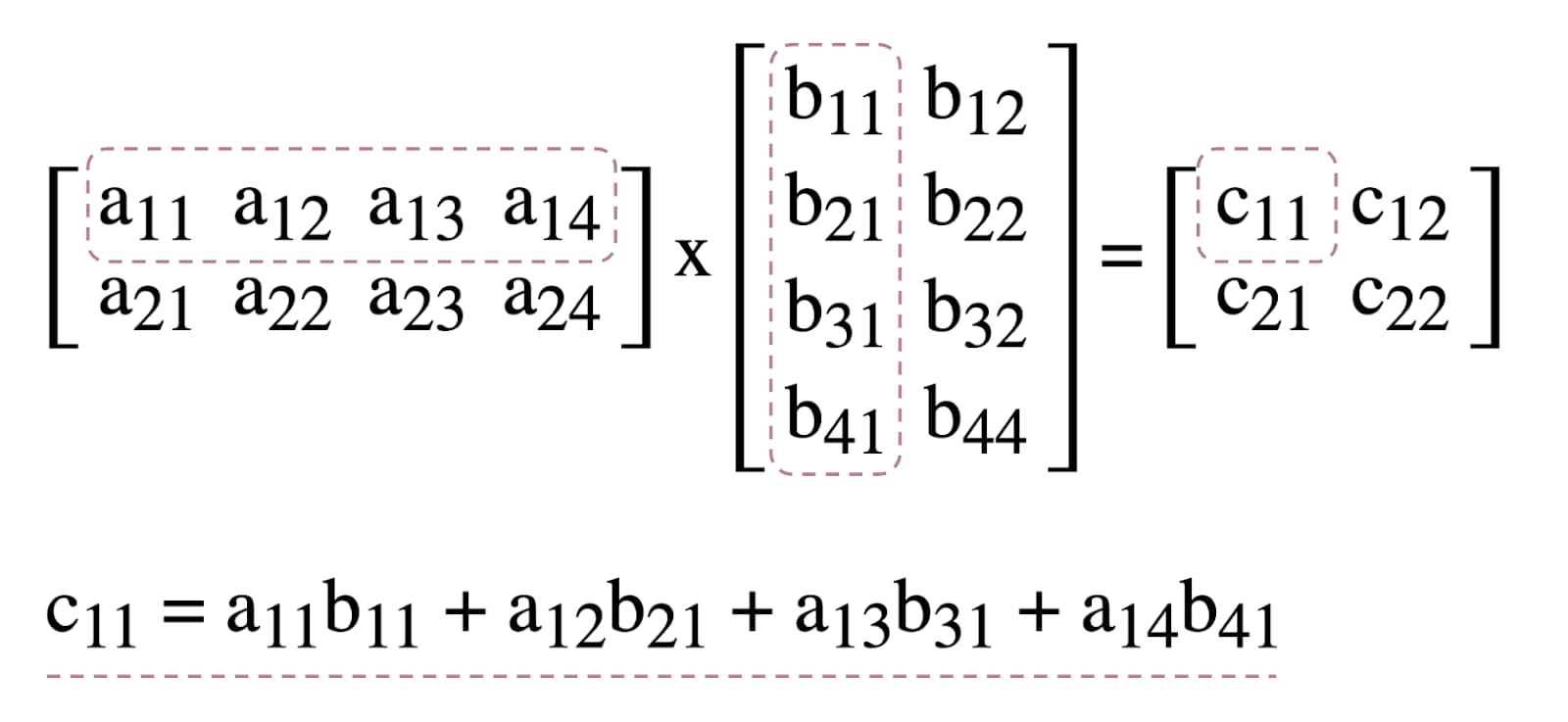
En resumen, esto es lo que haremos:
- Crea tres búferes de GPU (dos para las matrices que se multiplicarán y uno para la matriz de resultados).
- Describe la entrada y la salida del sombreador de procesamiento
- Compila el código del sombreador de cómputos
- Configura una canalización de procesamiento
- Envía por lotes los comandos codificados a la GPU
- Leer el búfer de GPU de la matriz de resultados
Creación de búferes de GPU
Para simplificar, las matrices se representarán como una lista de números de punto flotante. El primer elemento es la cantidad de filas, el segundo es la cantidad de columnas y el resto son los números reales de la matriz.

Los tres búferes de GPU son búferes de almacenamiento, ya que necesitamos almacenar y recuperar datos en el sombreador de procesamiento. Esto explica por qué las marcas de uso del búfer de GPU incluyen GPUBufferUsage.STORAGE para todas ellas. La marca de uso de la matriz de resultados también tiene GPUBufferUsage.COPY_SRC porque se copiará en otro búfer para su lectura una vez que se hayan ejecutado todos los comandos de la cola de la GPU.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
Diseño y grupo de vinculaciones
Los conceptos de diseño de grupo de vinculación y grupo de vinculación son específicos de WebGPU. Un diseño de grupo de vinculación define la interfaz de entrada/salida que espera un sombreador, mientras que un grupo de vinculación representa los datos de entrada/salida reales para un sombreador.
En el siguiente ejemplo, el diseño del grupo de vinculación espera dos búferes de almacenamiento de solo lectura en las vinculaciones de entrada numeradas 0 y 1, y un búfer de almacenamiento en 2 para el sombreador de procesamiento.
Por otro lado, el grupo de vinculación, definido para este diseño de grupo de vinculación, asocia los búferes de la GPU a las entradas: gpuBufferFirstMatrix a la vinculación 0, gpuBufferSecondMatrix a la vinculación 1 y resultMatrixBuffer a la vinculación 2.
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: gpuBufferFirstMatrix
},
{
binding: 1,
resource: gpuBufferSecondMatrix
},
{
binding: 2,
resource: resultMatrixBuffer
}
]
});
Código del sombreador de cómputos
El código del sombreador de cómputos para multiplicar matrices se escribe en WGSL, el lenguaje de sombreadores de WebGPU, que se traduce fácilmente a SPIR-V. Sin entrar en detalles, a continuación, encontrarás los tres búferes de almacenamiento identificados con var<storage>. El programa usará firstMatrix y secondMatrix como entradas, y resultMatrix como salida.
Ten en cuenta que cada búfer de almacenamiento tiene una decoración binding que se usa y que corresponde al mismo índice definido en los diseños y grupos de vinculación declarados anteriormente.
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
Configuración de la canalización
La canalización de procesamiento es el objeto que describe realmente la operación de procesamiento que vamos a realizar. Para ello, llama a device.createComputePipeline().
Toma dos argumentos: el diseño del grupo de vinculación que creamos antes y una etapa de procesamiento que define el punto de entrada de nuestro sombreador de procesamiento (la función main de WGSL) y el módulo de sombreador de procesamiento real creado con device.createShaderModule().
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule
}
});
Envío de comandos
Después de crear una instancia de un grupo de vinculaciones con nuestros tres búferes de GPU y una canalización de procesamiento con un diseño de grupo de vinculaciones, es hora de usarlos.
Comencemos un codificador de pase de procesamiento programable con commandEncoder.beginComputePass(). Usaremos esto para codificar los comandos de la GPU que realizarán la multiplicación de matrices. Establece su canalización con passEncoder.setPipeline(computePipeline) y su grupo de vinculación en el índice 0 con passEncoder.setBindGroup(0, bindGroup). El índice 0 corresponde a la decoración group(0) en el código WGSL.
Ahora, hablemos sobre cómo se ejecutará este sombreador de procesamiento en la GPU. Nuestro objetivo es ejecutar este programa en paralelo para cada celda de la matriz de resultados, paso a paso. Por ejemplo, para una matriz de resultados de tamaño 16 x 32, para codificar el comando de ejecución en un @workgroup_size(8, 8), llamaríamos a passEncoder.dispatchWorkgroups(2, 4) o passEncoder.dispatchWorkgroups(16 / 8, 32 / 8).
El primer argumento "x" es la primera dimensión, el segundo "y" es la segunda dimensión y el último "z" es la tercera dimensión que, de forma predeterminada, es 1, ya que no la necesitamos aquí.
En el mundo del procesamiento de GPU, codificar un comando para ejecutar una función de kernel en un conjunto de datos se denomina envío.
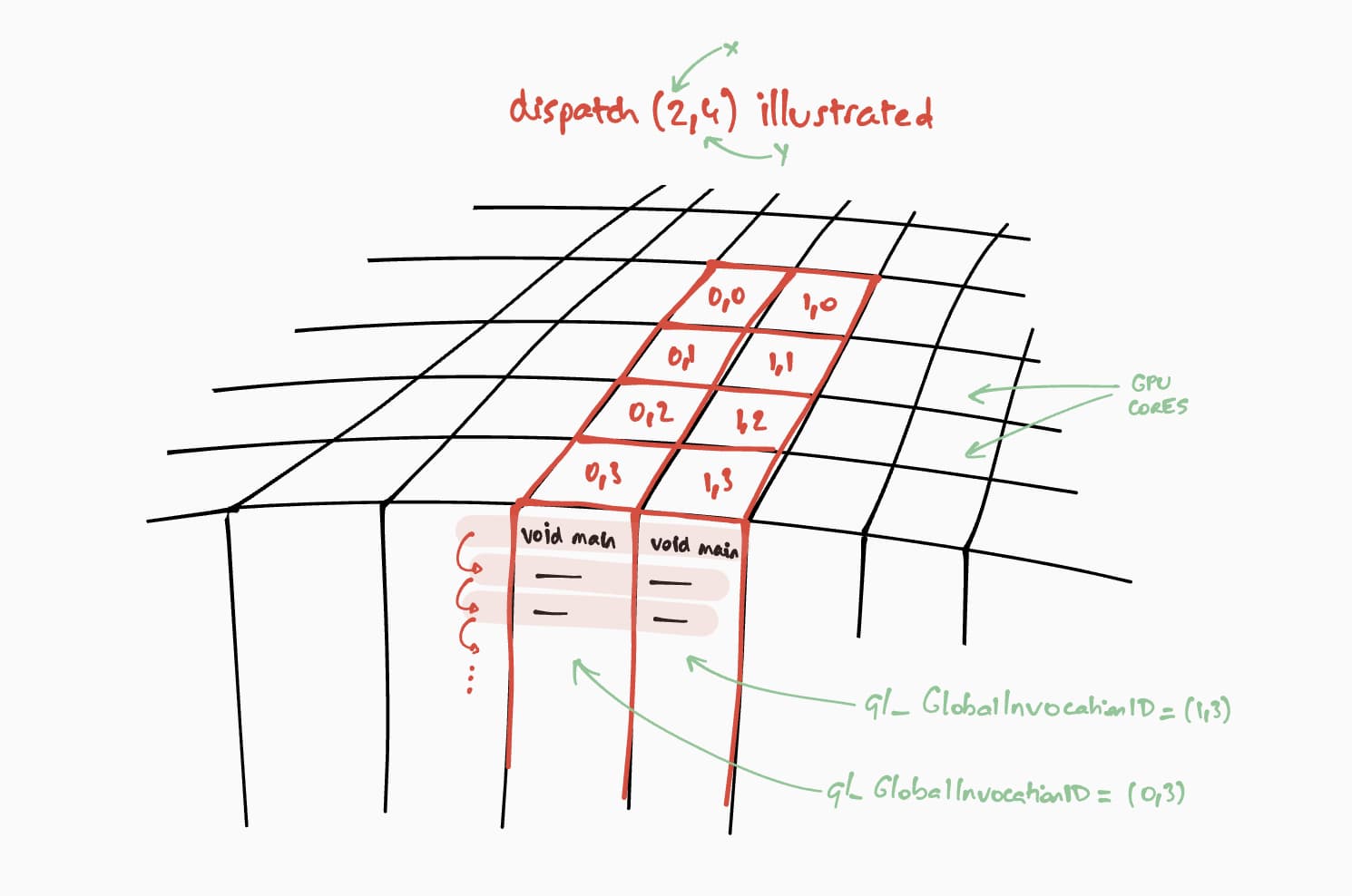
El tamaño de la cuadrícula del grupo de trabajo para nuestro sombreador de cómputos es (8, 8) en nuestro código WGSL. Por lo tanto, "x" e "y", que son respectivamente la cantidad de filas de la primera matriz y la cantidad de columnas de la segunda matriz, se dividirán por 8. Con eso, ahora podemos enviar una llamada de procesamiento con passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8). La cantidad de cuadrículas de grupos de trabajo que se ejecutarán son los argumentos dispatchWorkgroups().
Como se ve en el dibujo anterior, cada sombreador tendrá acceso a un objeto builtin(global_invocation_id) único que se usará para saber qué celda de la matriz de resultados se debe calcular.
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
Para finalizar el codificador de pase de procesamiento, llama a passEncoder.end(). Luego, crea un búfer de GPU para usarlo como destino para copiar el búfer de la matriz de resultados con copyBufferToBuffer. Por último, finaliza los comandos de codificación con copyEncoder.finish() y envíalos a la cola del dispositivo de GPU llamando a device.queue.submit() con los comandos de GPU.
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
Matriz de resultados de lectura
Leer la matriz de resultados es tan fácil como llamar a gpuReadBuffer.mapAsync() con GPUMapMode.READ y esperar a que se resuelva la promesa de devolución, lo que indica que el búfer de la GPU ahora está asignado. En este punto, es posible obtener el rango asignado con gpuReadBuffer.getMappedRange().
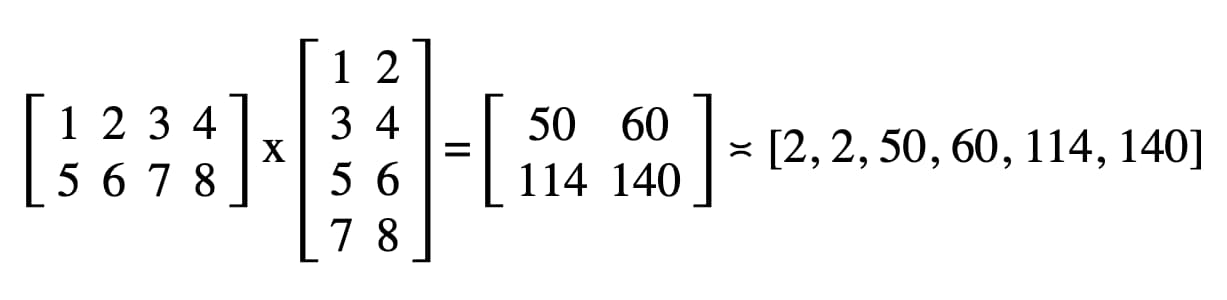
En nuestro código, el resultado registrado en la consola de JavaScript de Herramientas para desarrolladores es "2, 2, 50, 60, 114, 140".
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
¡Felicitaciones! Lo lograste. Puedes probar la muestra.
Un último truco
Una forma de facilitar la lectura de tu código es usar el práctico método getBindGroupLayout de la canalización de procesamiento para inferir el diseño del grupo de vinculación del módulo de sombreador. Este truco elimina la necesidad de crear un diseño de grupo de vinculación personalizado y especificar un diseño de canalización en tu canalización de procesamiento, como puedes ver a continuación.
Aquí puedes ver una ilustración de getBindGroupLayout para la muestra anterior.
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
Resultados de rendimiento
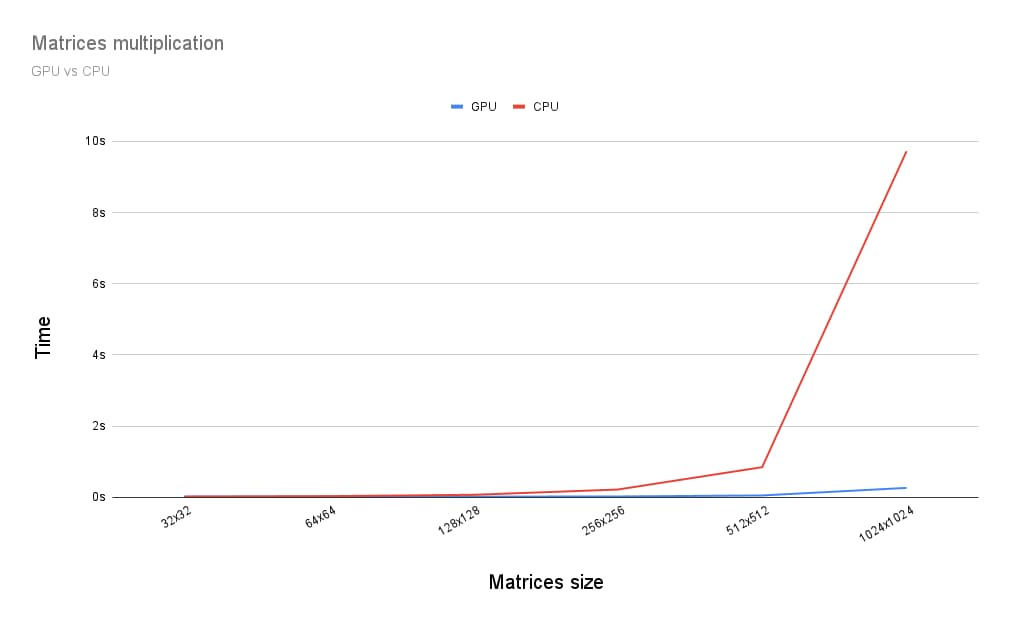
Entonces, ¿cómo se compara la ejecución de la multiplicación de matrices en una GPU con la ejecución en una CPU? Para averiguarlo, escribí el programa que acabo de describir para una CPU. Como puedes ver en el siguiente gráfico, usar toda la potencia de la GPU parece una opción obvia cuando el tamaño de las matrices es superior a 256 por 256.
Este artículo fue solo el comienzo de mi recorrido explorando WebGPU. Pronto publicaremos más artículos con análisis detallados sobre el procesamiento con GPU y cómo funciona la renderización (canvas, textura, muestreador) en WebGPU.