

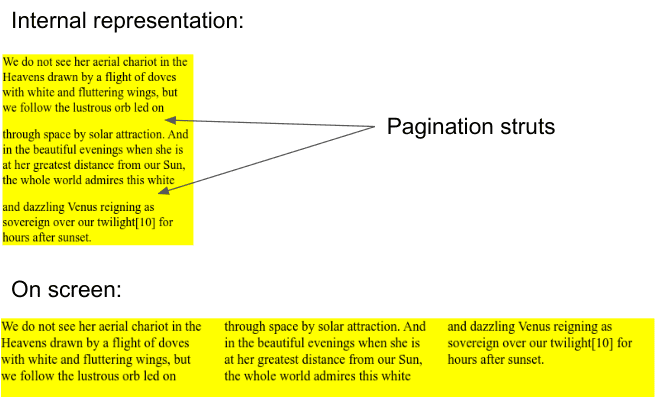
Fragmentacja bloku polega na dzieleniu pudełka na poziomie bloku CSS (np. sekcji lub akapitu) na wiele fragmentów, gdy nie mieści się ono w całości w jednym kontenerze fragmentów, zwanym fragmentainerem. Fragmentainer nie jest elementem, ale reprezentuje kolumnę w układzie z wieloma kolumnami lub stronę w przypadku multimediów z wieloma stronami.
Aby nastąpiła fragmentacja, treści muszą znajdować się w kontekście fragmentacji. Kontekst podziału jest najczęściej określany przez kontener wielokolumnowy (treści są dzielone na kolumny) lub podczas drukowania (treści są dzielone na strony). Długi akapit z wiele wierszami może wymagać podzielenia na kilka fragmentów, tak aby pierwsze wiersze znalazły się w pierwszym fragmencie, a pozostałe w kolejnych.

Fragmentacja bloków jest analogiczną techniką do innego dobrze znanego typu fragmentacji: fragmentacji linii, zwanej też „przerwą w wierszu”. Każdy element wbudowany, który składa się z więcej niż jednego słowa (dowolny węzeł tekstowy, dowolny element <a> itp.) i umożliwia wstawianie znaków końca wiersza, może być podzielony na kilka fragmentów. Każdy fragment jest umieszczany w innym polu linii. Line box to inline fragmentation, czyli odpowiednik fragmentainer w przypadku kolumn i stron.
Rozwiązanie LayoutNG do rozwiązywania problemu z fragmentacją
LayoutNGBlockFragmentation to nowa wersja mechanizmu fragmentacji dla LayoutNG, która została po raz pierwszy udostępniona w Chrome 102. W przypadku struktur danych wiele struktur z czasu przed NG zostało zastąpionych fragmentami NG reprezentowanymi bezpośrednio w drzewie fragmentów.
Obsługujemy teraz na przykład wartość „avoid” (unikaj) w przypadku właściwości CSS „break-before” i „break-after”, co pozwala autorom unikać wcięć bezpośrednio po nagłówku. Często wygląda to nieestetycznie, gdy ostatnią rzeczą na stronie jest nagłówek, a treści sekcji zaczynają się na następnej stronie. Lepiej jest wstawić podział przed nagłówkiem.

Chrome obsługuje też przepełnienie fragmentacji, dzięki czemu monolityczne (nierozłączalne) treści nie są dzielone na wiele kolumn, a efekty malowania, takie jak cienie i przekształcenia, są prawidłowo stosowane.
Blokowanie fragmentacji w LayoutNG zostało zakończone
Fragmentacja podstawowa (kontenery bloków, w tym układ linii, elementy pływające i pozycjonowanie poza przepływem) wprowadzona w Chrome 102. Użytkownicy Chrome 103 mogą korzystać z fragmentacji flex i siatka, a z fragmentacji tabeli – z Chrome 106. W Chrome 108 pojawiła się też funkcja drukowania. Fragmentacja bloków była ostatnią funkcją, która w celu wykonania układu korzystała z starszego silnika.
Od wersji 108 Chrome nie używa już starszego mechanizmu do generowania układu.
Struktury danych LayoutNG obsługują też rysowanie i testowanie trafień, ale korzystamy z niektórych starszych struktur danych w przypadku interfejsów API JavaScript, które odczytują informacje o układzie, takich jak offsetLeft i offsetTop.
Układowanie wszystkiego za pomocą NG umożliwi wdrażanie i udostępnianie nowych funkcji, które mają tylko implementacje LayoutNG (a nie ich odpowiedniki w starszych silnikach), takich jak zapytania dotyczące kontenera CSS, pozycjonowanie kotwic, MathML i niestandardowy układ (Houdini). W przypadku zapytań dotyczących kontenerów wprowadziliśmy je nieco wcześniej, ostrzegając deweloperów, że drukowanie nie jest jeszcze obsługiwane.
Pierwsza część LayoutNG została wydana w 2019 r. i obejmowała układ zwykłego bloku kontenera, układ w tekście, układy z przepływem i układy poza przepływem, ale nie obsługowała układów flex, siatek ani tabel. Nie obsługiwała też w ogóle fragmentacji bloków. W przypadku elastycznych elementów, siatek, tabel i innych elementów powodujących podział bloków wrócilibyśmy do starszego mechanizmu układu. Dotyczyło to nawet elementów blokowych, wbudowanych, pływających i poza przepływem w ramach treści podzielonych na fragmenty. Jak widzisz, uaktualnianie tak złożonego mechanizmu układu na miejscu to bardzo delikatny proces.
Ponadto do połowy 2019 roku większość funkcji podstawowych układu blokowego LayoutNG została już zaimplementowana (za pomocą flagi). Dlaczego wysyłka trwała tak długo? Krótko mówiąc: fragmentacja musi prawidłowo współistnieć z różnymi starszymi częściami systemu, których nie można usunąć ani uaktualnić, dopóki nie zaktualizujemy wszystkich zależności.
Interakcja ze starszym mechanizmem
Starsze struktury danych nadal odpowiadają za interfejsy JavaScript API, które odczytują informacje o układzie, więc musimy zapisywać dane w starszym mechanizmie w taki sposób, aby był on w stanie je odczytać. Obejmuje to prawidłowe aktualizowanie starszych struktur danych wielokolumnowych, takich jak LayoutMultiColumnFlowThread.
Wykrywanie i obsługa starszych wersji silnika
Musieliśmy wrócić do starszego silnika układu, gdy znajdowały się w nim treści, których nie można było jeszcze obsłużyć za pomocą fragmentacji bloku LayoutNG. W momencie wysyłania fragmentacji bloku głównego LayoutNG obejmującej elastyczność, siatki, tabele i wszystko, co jest drukowane. Było to szczególnie trudne, ponieważ przed utworzeniem obiektów w drzewie układu musieliśmy wykryć potrzebę użycia starszych rozwiązań zastępczych. Na przykład musieliśmy wykryć, czy istnieje element nadrzędny kontenera wielokolumnowego, zanim dowiedzieliśmy się, które węzły DOM staną się kontekstem formatowania. To problem kury i jajka, na który nie ma idealnego rozwiązania, ale dopóki jedynym błędem jest fałszywie dodatni wynik (powracanie do starszej wersji, gdy nie ma takiej potrzeby), wszystko jest w porządku, ponieważ wszelkie błędy w zachowaniu układu to te, które Chromium już ma, a nie nowe.
Spacer po drzewie przed malowaniem
Wstępną obróbkę graficzną wykonujemy po ułożeniu, ale przed malowaniem. Głównym wyzwaniem jest to, że nadal musimy przejrzeć drzewo obiektów układu, ale teraz mamy fragmenty NG. Jak sobie z tym poradzić? Przechodzimy jednocześnie przez drzewa obiektu układu i fragmentów NG. Jest to dość skomplikowane, ponieważ mapowanie między tymi dwoma drzewami nie jest proste.
Chociaż struktura drzewa obiektów układu jest bardzo podobna do struktury drzewa DOM, drzewo fragmentu jest wyjściem układu, a nie jego wejściem. Oprócz odzwierciedlenia efektu dowolnej fragmentacji, w tym fragmentacji wbudowanej (fragmenty wiersza) i fragmentacji bloku (fragmenty kolumny lub strony), drzewo fragmentów zawiera też bezpośrednią relację nadrzędny-podrzędny między blokiem zawierającym a potomkami DOM, których blokiem jest ten fragment. Na przykład w drzewie fragmentów fragment wygenerowany przez element z pozycji bezwzględnej jest bezpośrednim elementem podrzędnym bloku zawierającego, nawet jeśli w łańcuchu przodków znajdują się inne węzły między potomkiem z pozycją poza przepływem a blokiem zawierającym.
Sprawa może się jeszcze bardziej skomplikować, gdy wewnątrz fragmentacji znajduje się element umieszczony poza przepływem, ponieważ wtedy fragmenty poza przepływem stają się bezpośrednimi podrzędnymi fragmentainer (a nie podrzędnymi tego, co według CSS jest blokiem zawierającym). Ten problem musiał zostać rozwiązany, aby umożliwić współistnienie z starszą wersją silnika. W przyszłości będziemy mogli uprościć ten kod, ponieważ LayoutNG jest zaprojektowany tak, aby elastycznie obsługiwać wszystkie nowoczesne tryby układu.
Problemy ze starszym mechanizmem podziału
Starszy mechanizm, zaprojektowany w dawnej erze internetu, nie ma pojęcia o fragmentacji, nawet jeśli technicznie istniała ona już wtedy (aby umożliwić drukowanie). Obsługa fragmentacji została dodana jako dodatek (drukowanie) lub dodana w ramach wstecznej kompatybilności (wielokolumnowość).
Podczas układania treści podzielnych na fragmenty starsza wersja silnika układa wszystko w wysokim pasku, którego szerokość odpowiada rozmiarowi kolumny lub strony, a wysokość jest tak duża, jak to konieczne, aby pomieścić zawartość. Ten wysoki pas nie jest renderowany na stronie. Można go traktować jako renderowanie na stronie wirtualnej, która jest następnie przearanżowana na potrzeby wyświetlenia końcowego. Pod względem koncepcyjnym jest to podobne do wydrukowania całego artykułu z gazety na jednej kolumnie, a potem wycięcia go nożyczkami na kilka części. (w tamtych czasach niektóre gazety używały podobnych technik)
Starszy mechanizm śledzi na pasku granicę wyimaginowanej strony lub kolumny. Dzięki temu może przesunąć treści, które nie mieszczą się w ramach, na następną stronę lub kolumnę. Jeśli na przykład tylko górna połowa linii mieści się na stronie, którą silnik uważa za bieżącą, wstawia on „element strony”, aby przesunąć ją w dół do pozycji, którą silnik uznaje za górną część następnej strony. Następnie większość rzeczywistej pracy związanej z fragmentacją (czyli „cięcie nożyczkami i umieszczanie”) odbywa się po ułożeniu podczas wstępnego i dokładnego renderowania, polegając na pocięciu wysokiego paska treści na strony lub kolumny (poprzez przycinanie i przesuwanie fragmentów). To uniemożliwiło kilka rzeczy, takich jak stosowanie przekształceń i względnego pozycjonowania po fragmentacji (co wymaga specyfikacji). Co więcej, chociaż w starszym mechanizmie jest pewna obsługa fragmentacji tabel, to nie ma jej w przypadku fragmentacji flex i kratki.
Oto ilustracja pokazująca, jak układ z 3 kolumnami jest reprezentowany wewnętrznie w starszej wersji silnika przed użyciem nożyczek, umieszczeniem i klejem (mamy określoną wysokość, więc mieszczą się tylko 4 wiersze, ale na dole jest jeszcze trochę miejsca):
Stary mechanizm generowania układu nie dzieli treści na fragmenty podczas generowania układu, dlatego pojawia się wiele dziwnych artefaktów, takich jak nieprawidłowe stosowanie względnego pozycjonowania i przekształceń oraz przycinanie cieni krawędzi kolumny.
Oto przykład użycia atrybutu text-shadow:
Starszy mechanizm nie radzi sobie z tym dobrze:

Widzisz, że cień tekstu z wiersza w pierwszej kolumnie jest przycięty i zamiast tego znajduje się u góry drugiej kolumny? Dzieje się tak, ponieważ starszy mechanizm układu nie rozumie pojęcia fragmentacji.
Powinien on wyglądać tak:
![]()
Teraz spróbujmy skomplikować ten efekt, dodając do niego transformacje i cienie. Zwróć uwagę, że w starszej wersji mechanizmu występują nieprawidłowe przycinanie i przenikanie kolumn. Dzieje się tak, ponieważ zgodnie ze specyfikacją transformacje powinny być stosowane po ułożeniu i po pofragmentowaniu. W przypadku fragmentacji LayoutNG oba rozwiązania działają prawidłowo. Zwiększa to interoperacyjność z Firefoksem, który od jakiegoś czasu ma dobrą obsługę fragmentacji i przechodzi większość testów w tym zakresie.
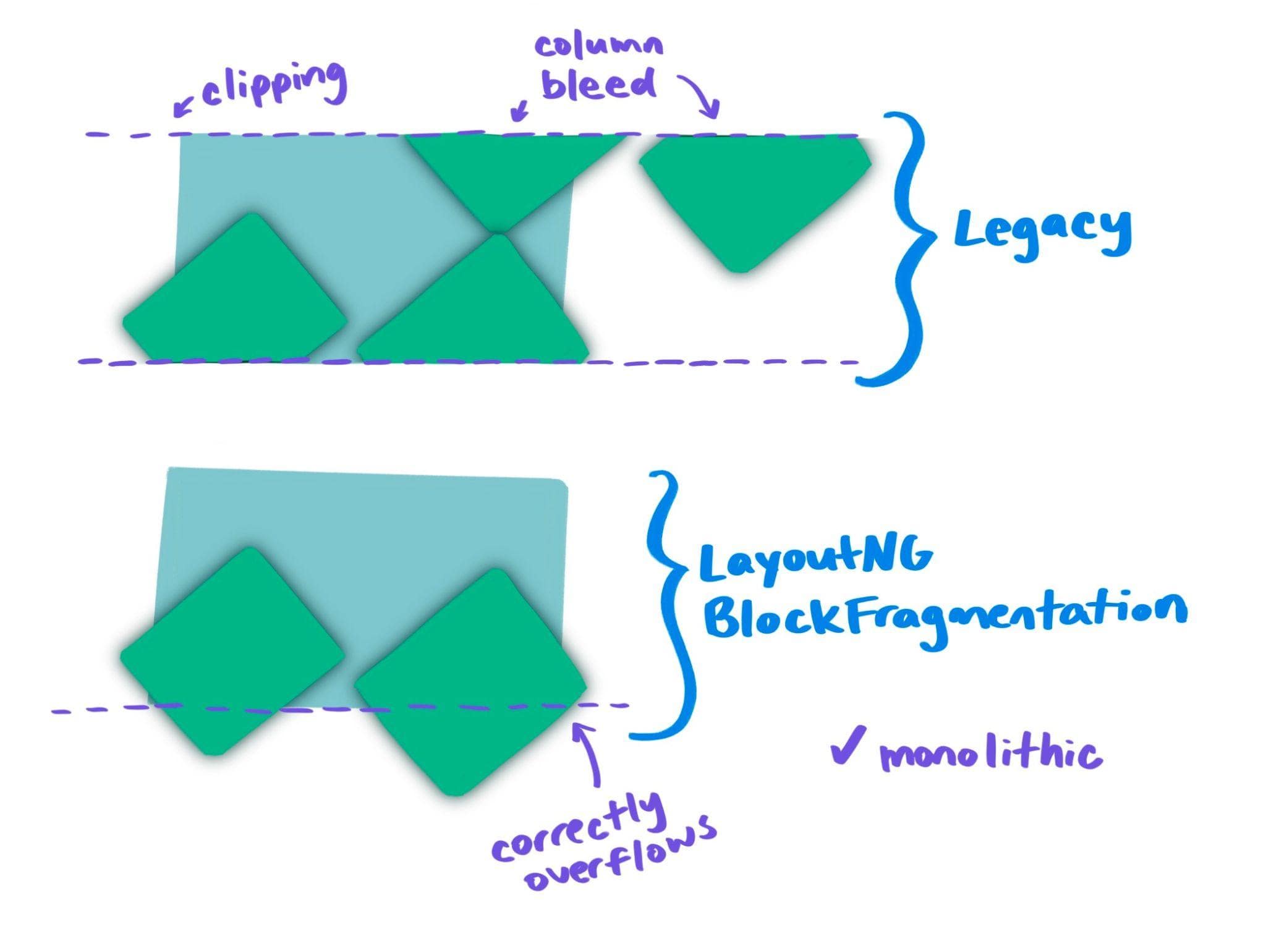
Starszy mechanizm ma też problemy z wysokimi monolitycznymi treściami. Treści są monolityczne, jeśli nie można ich podzielić na kilka fragmentów. Elementy z przewijaniem przepełnienia są monolityczne, ponieważ przewijanie w obszarze nieprostokątnym nie ma sensu dla użytkowników. Innymi przykładami monolitycznych treści są ramki wiersza i obrazy. Oto przykład:
Jeśli monolityczna treść jest zbyt wysoka, aby zmieścić się w kolumnie, starszy mechanizm brutalnie ją podzieli (co spowoduje bardzo „ciekawe” zachowanie podczas próby przewijania przewijalnego kontenera):
Zamiast pozwalać na przepełnienie pierwszej kolumny (jak to ma miejsce w przypadku fragmentacji bloku LayoutNG):

Starszy silnik obsługuje przymusowe przerwy. Na przykład <div style="break-before:page;"> wstawia podział strony przed tagiem DIV. Ma on jednak ograniczone możliwości znajdowania optymalnych niewymuszonych podziałów. Obsługuje break-inside:avoid i dzieci oraz bloki na końcu i na początku strony, ale nie obsługuje unikania przerw między blokami, jeśli jest to wymagane na przykład przez break-before:avoid. Przeanalizuj ten przykład:
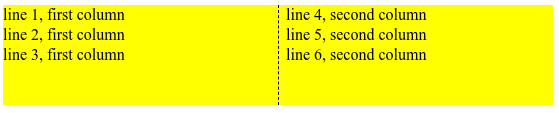
W tym przykładzie element #multicol ma miejsce na 5 wierszy w każdej kolumnie (ponieważ ma wysokość 100 pikseli, a wysokość linii to 20 pikseli), więc wszystkie elementy #firstchild mieszczą się w pierwszej kolumnie. Jednak jego element nadrzędny #secondchild ma atrybut break-before:avoid, co oznacza, że treści nie mogą zawierać przerwy między tymi elementami. Ponieważ wartość widows wynosi 2, musimy przesłać 2 wiersze #firstchild do drugiej kolumny, aby uwzględnić wszystkie żądania unikania przerw. Chromium to pierwszy silnik przeglądarki, który w pełni obsługuje tę kombinację funkcji.
Jak działa podział na wersje NG
Silnik układu NG zazwyczaj układa dokument, przechodząc po drzewie pudeł CSS od góry do dołu. Gdy wszystkie potomki węzła zostaną rozmieszczone, można zakończyć rozmieszczanie tego węzła, tworząc NGPhysicalFragment i wracając do algorytmu rozmieszczania nadrzędnego. Dodaje on ten fragment do listy fragmentów podrzędnych, a gdy wszystkie fragmenty podrzędne zostaną utworzone, generuje fragment zawierający wszystkie fragmenty podrzędne. W ten sposób tworzy drzewo fragmentów dla całego dokumentu. Jest to jednak duże uproszczenie: na przykład elementy umieszczone poza obszarem widoku muszą się przemieszczać w drzewie DOM od miejsca, w którym się znajdują, do bloku zawierającego, zanim zostaną rozmieszczone. W tym celu pomijam zaawansowane szczegóły.
Oprócz samego pudełka CSS LayoutNG udostępnia ograniczoną przestrzeń algorytmowi układu. Dzięki temu algorytm ma dostęp do takich informacji jak dostępna przestrzeń na układ, czy został utworzony nowy kontekst formatowania oraz czy wyniki z poprzednich treści zostały wstępnie złożone. Przestrzeń ograniczeń zna też rozmiar bloku w fragmentainerze i bieżący przesunięcie bloku w nim. Wskazuje, gdzie należy wstawić przerwę.
W przypadku fragmentacji bloku układ potomków musi się kończyć na przerwie. Przyczyny przerwania to m.in. brak miejsca na stronie lub w kolumnie albo wymuszony podział. Następnie generujemy fragmenty dla odwiedzonych węzłów i zwracamy je aż do katalogu głównego kontekstu podziału (kontenera wielokolumnowego lub, w przypadku drukowania, katalogu głównego dokumentu). Następnie w korzeniach kontekstu podziału przygotowujemy nowy fragmentator i ponownie schodzimy w dół drzewa, kontynuując od miejsca, w którym przerwaliśmy.
Kluczowa struktura danych umożliwiająca wznowienie układu po przerwie to NGBlockBreakToken. Zawiera on wszystkie informacje potrzebne do prawidłowego wznowienia układu w następnym kontenerze fragmentów. Element NGBlockBreakToken jest powiązany z węzłem i tworzy drzewo NGBlockBreakToken, tak aby każdy węzeł, który wymaga wznowienia, był reprezentowany. Do NGPhysicalBoxFragment wygenerowanego dla węzłów, które mają przerwę wewnątrz, jest dołączany token NGBlockBreakToken. Tokeny przerw są propagowane do elementów nadrzędnych, tworząc drzewo tokenów przerw. Jeśli musimy przerwać przed węzłem (zamiast w jego wnętrzu), nie zostanie wygenerowany żaden fragment, ale węzeł nadrzędny musi utworzyć dla tego węzła token przerwy „break-before”, abyśmy mogli rozpocząć jego układanie, gdy dotrzemy do tej samej pozycji w drzewie węzłów w następnym kontenerze fragmentów.
Przerwy są wstawiane, gdy zabraknie miejsca w kontenerze (nieprzymusowa przerwa) lub gdy zostanie poproszone o wstawienie przymusowej przerwy.
W specyfikacji znajdują się reguły dotyczące optymalnych niewymuszonych przerw, a wstawianie przerwy dokładnie w miejscu, w którym zabraknie miejsca, nie zawsze jest właściwym rozwiązaniem. Na przykład różne właściwości CSS, takie jak break-before, wpływają na wybór miejsca przerwy.
Aby podczas układania prawidłowo zastosować sekcję specyfikacji niewymuszonych przerw, musimy śledzić potencjalnie odpowiednie punkty przełamania. Ten rekord oznacza, że możemy wrócić i użyć ostatniego znalezionego najlepszego punktu przełamania, jeśli zabraknie nam miejsca w miejscu, w którym naruszyliśmy prośby o uniknięcie przerwy (np. break-before:avoid lub orphans:7). Każdy możliwy punkt przełamania ma przypisany wynik, który może się wahać od „użyj tego tylko w ekstremalnej sytuacji” do „idealnego miejsca na przerwę”, z kilkoma wartościami pośrednimi. Jeśli lokalizacja przerwy ma ocenę „doskonała”, oznacza to, że nie zostaną naruszone żadne zasady, jeśli przerwa nastąpi w tym miejscu (a jeśli uzyskamy tę ocenę dokładnie w miejscu, w którym zabrakło miejsca, nie trzeba szukać lepszego rozwiązania). Jeśli wynik to „ostatnia deska ratunku”, punkt przecięcia nie jest nawet prawidłowy, ale możemy go użyć, jeśli nie znajdziemy nic lepszego, aby uniknąć przepełnienia fragmentainer.
Prawidłowe punkty przełamania występują zwykle tylko między elementami braćmi (elementami linii lub blokami), a nie na przykład między elementem nadrzędnym a jego pierwszym elementem podrzędnym (wyjątkiem są punkty przełamania klasy C, ale nie będziemy ich tutaj omawiać). Istnieje prawidłowy punkt przerwania przed blokiem nadrzędnym z break-before:avoid, ale jest on gdzieś pomiędzy „idealnym” a „ostatnim środkiem”.
Podczas tworzenia układu śledzimy najlepszy znaleziony do tej pory punkt przełamania w strukturze o nazwie NGEarlyBreak. Wczesna przerwa to możliwy punkt przerwy przed węzłem bloku lub wewnątrz niego albo przed linią (linią kontenera bloku lub linią elastycznego). Możemy utworzyć łańcuch lub ścieżkę obiektów NGEarlyBreak, jeśli najlepszy punkt przełamania znajduje się gdzieś głęboko w czymś, co przeoczyliśmy wcześniej, gdy zabrakło nam miejsca. Oto przykład:
W tym przypadku brakuje miejsca tuż przed #second, ale jest tam „break-before:avoid”, co oznacza, że lokalizacja przerwy ma wynik „violating break avoid”. W tym miejscu mamy łańcuch NGEarlyBreak „inside #outer > inside #middle > inside #inner > before "line 3"' z wartością „perfect”, więc wolimy przerwać na tym etapie. Musimy więc wrócić i ponownie uruchomić układ od początku bloku #outer (tym razem pomijając znaleziony przez nas blok NGEarlyBreak), aby móc przerwać przed „wierszem 3” w bloku #inner. (Przerwa następuje przed „wierszem 3”, aby pozostałe 4 wiersze znalazły się w kolejnych fragmentach i aby zachować zgodność z wartością widows:4).
Algorytm jest tak zaprojektowany, aby zawsze stosować najlepszy możliwy punkt przecięcia (zdefiniowany w specyfikacji), odrzucając reguły w odpowiedniej kolejności, jeśli nie wszystkie z nich mogą być spełnione. Pamiętaj, że na potrzeby procesu podziału na fragmenty musimy ponownie ustawić układ maksymalnie raz. Gdy rozpoczynamy drugi etap układu, najlepszy punkt przerwy został już przekazany algorytmom układu. Jest to punkt przerwy, który został wykryty w ramach pierwszego etapu układu i podany jako część danych wyjściowych układu w tym etapie. Podczas drugiego układania nie układamy, dopóki nie zabraknie miejsca. W zasadzie nie powinno zabraknąć miejsca (byłoby to błędem), ponieważ mamy do dyspozycji świetne miejsce na wstawienie przerwy, aby uniknąć niepotrzebnego naruszenia zasad. Tutaj kończymy.
Czasami musimy naruszyć niektóre żądania dotyczące unikania przerw, jeśli pomoże to uniknąć przepełnienia fragmentatorów. Na przykład:
Tutaj brakuje miejsca tuż przed #second, ale ma ono wartość „break-before:avoid”. Zostało to przetłumaczone na „avoid violating break”, podobnie jak w ostatnim przykładzie. Mamy też NGEarlyBreak z „naruszeniem reguły o dzieciach i wdówach” (w #first > przed „line 2”), która nadal nie jest idealna, ale lepsza niż „violating break avoid”. Przerwiemy więc przed „wierszem 2”, co narusza prośbę o dzieci i wdowy. Specyfikacja zawiera informacje na ten temat w sekcji 4.4. Unforced Breaks, w którym określa się, które reguły są ignorowane jako pierwsze, jeśli nie ma wystarczającej liczby punktów podziału, aby uniknąć przepełnienia fragmenta.
Podsumowanie
Celem funkcjonalnym projektu dotyczącego fragmentacji bloków LayoutNG było zapewnienie implementacji obsługującej architekturę LayoutNG we wszystkich aspektach obsługiwanych przez starszą wersję silnika i z jak najmniejszą liczbą innych zmian (z wyjątkiem poprawek błędów). Głównym wyjątkiem jest lepsza obsługa unikania przerw (np. break-before:avoid), ponieważ jest to kluczowy element mechanizmu podziału, więc musiał on być obecny od samego początku, ponieważ dodanie go później oznaczałoby konieczność ponownego przepisania.
Teraz, gdy zakończyliśmy pracę nad fragmentacją bloków w LayoutNG, możemy zacząć dodawać nowe funkcje, takie jak obsługa mieszanych rozmiarów stron podczas drukowania, @page marginesów podczas drukowania, box-decoration-break:clone i inne. Podobnie jak w przypadku LayoutNG, spodziewamy się, że z czasem liczba błędów i obciążenie związane z konserwacją nowego systemu będą znacznie mniejsze.
Podziękowania
- Una Kravets za piękny „zrzut ekranu wykonany ręcznie”.
- Chris Harrelson – za korektę, opinie i sugestie.
- Philip Jägenstedt za opinie i sugestie.
- Rachel Andrew za edycję i pierwszą ilustrację przykładową z wieloma kolumnami.