

Os dados brutos do Relatório de UX do Chrome (CrUX) estão disponíveis no BigQuery, um banco de dados no Google Cloud. O uso do BigQuery requer um projeto do GCP e conhecimento básico de SQL.
Neste guia, você vai aprender a usar o BigQuery para escrever consultas no conjunto de dados do CrUX e extrair resultados úteis sobre o estado das experiências do usuário na Web:
- Entender como os dados são organizados
- Criar uma consulta básica para avaliar a performance de uma origem
- Gravar uma consulta avançada para acompanhar a performance ao longo do tempo
Organização dos dados
Comece com uma consulta básica:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
Para executar a consulta, insira-a no editor de consultas e pressione o botão "Executar consulta":
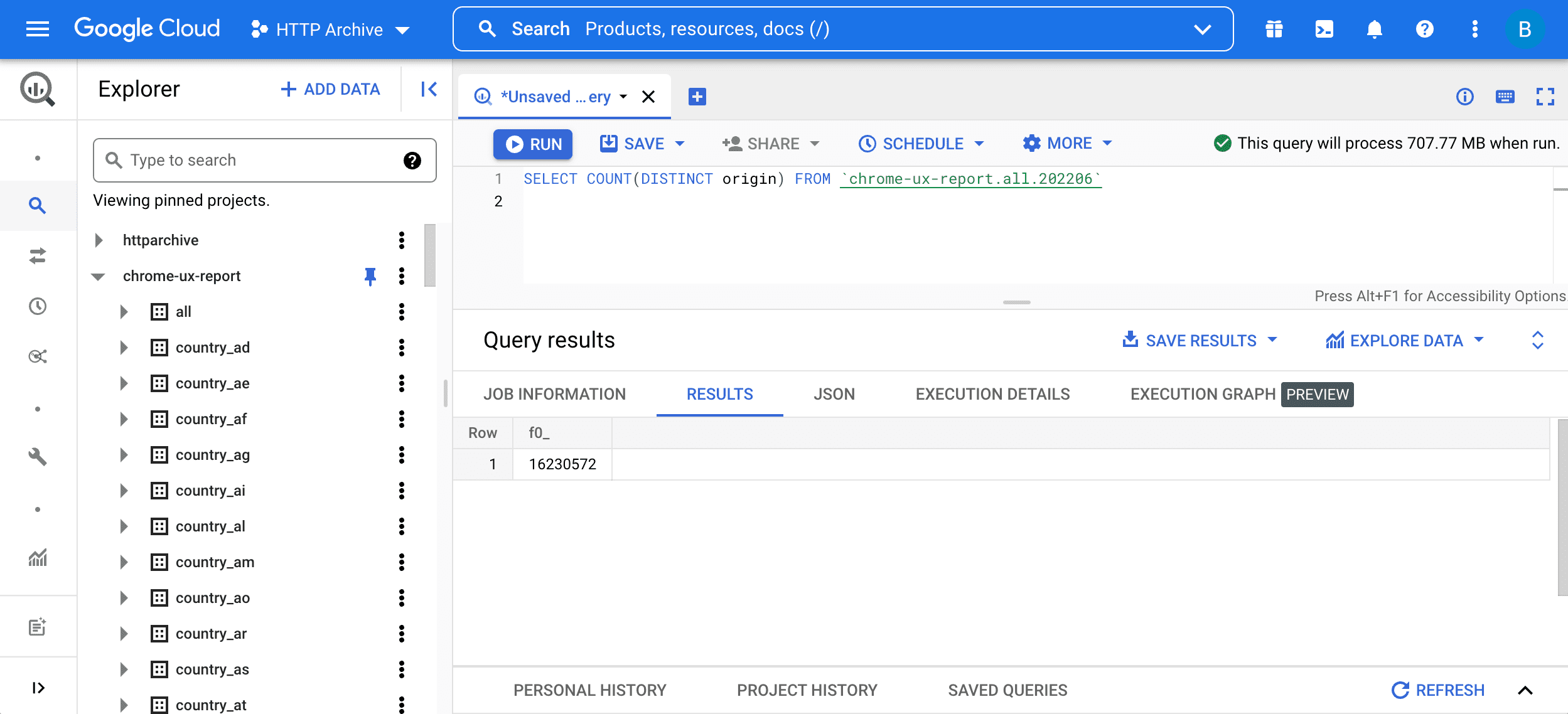
Essa consulta tem duas partes:
SELECT COUNT(DISTINCT origin)significa consultar o número de origens na tabela. De modo geral, dois URLs fazem parte da mesma origem se tiverem o mesmo esquema, host e porta.FROM chrome-ux-report.all.202206especifica o endereço da tabela de origem, que tem três partes:- O nome do projeto do Cloud
chrome-ux-reportem que todos os dados do CrUX são organizados - O conjunto de dados
all, que representa dados de todos os países - A tabela
202206, o ano e o mês dos dados no formato AAAAMM
- O nome do projeto do Cloud
Também há conjuntos de dados para cada país. Por exemplo, chrome-ux-report.country_ca.202206 representa apenas os dados de experiência do usuário originados do Canadá.
Em cada conjunto de dados, há tabelas para cada mês desde 201710. Novas tabelas do mês anterior são publicadas regularmente.
A estrutura das tabelas de dados (também conhecida como esquema) contém:
- A origem, por exemplo,
origin = 'https://www.example.com', que representa a distribuição agregada da experiência do usuário para todas as páginas do site - A velocidade de conexão no momento do carregamento da página, por exemplo,
effective_connection_type.name = '4G'(removido em fevereiro de 2025) - O tipo de dispositivo, por exemplo,
form_factor.name = 'desktop' - As próprias métricas de UX
Os dados de cada métrica são organizados como uma matriz de objetos. Na notação JSON, first_contentful_paint.histogram.bin seria semelhante a este:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
Cada intervalo contém um horário de início e de término em milissegundos e uma densidade que representa a porcentagem de experiências do usuário nesse período. Em outras palavras, 12, 34% das experiências de FCP para essa origem hipotética, velocidade de conexão e tipo de dispositivo são menores que 100 ms. A soma de todas as densidades de bin é 100%.
Procure a estrutura das tabelas no BigQuery.
Avaliar o desempenho
Podemos usar nosso conhecimento do esquema da tabela para escrever uma consulta que extrai esses dados de performance.
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
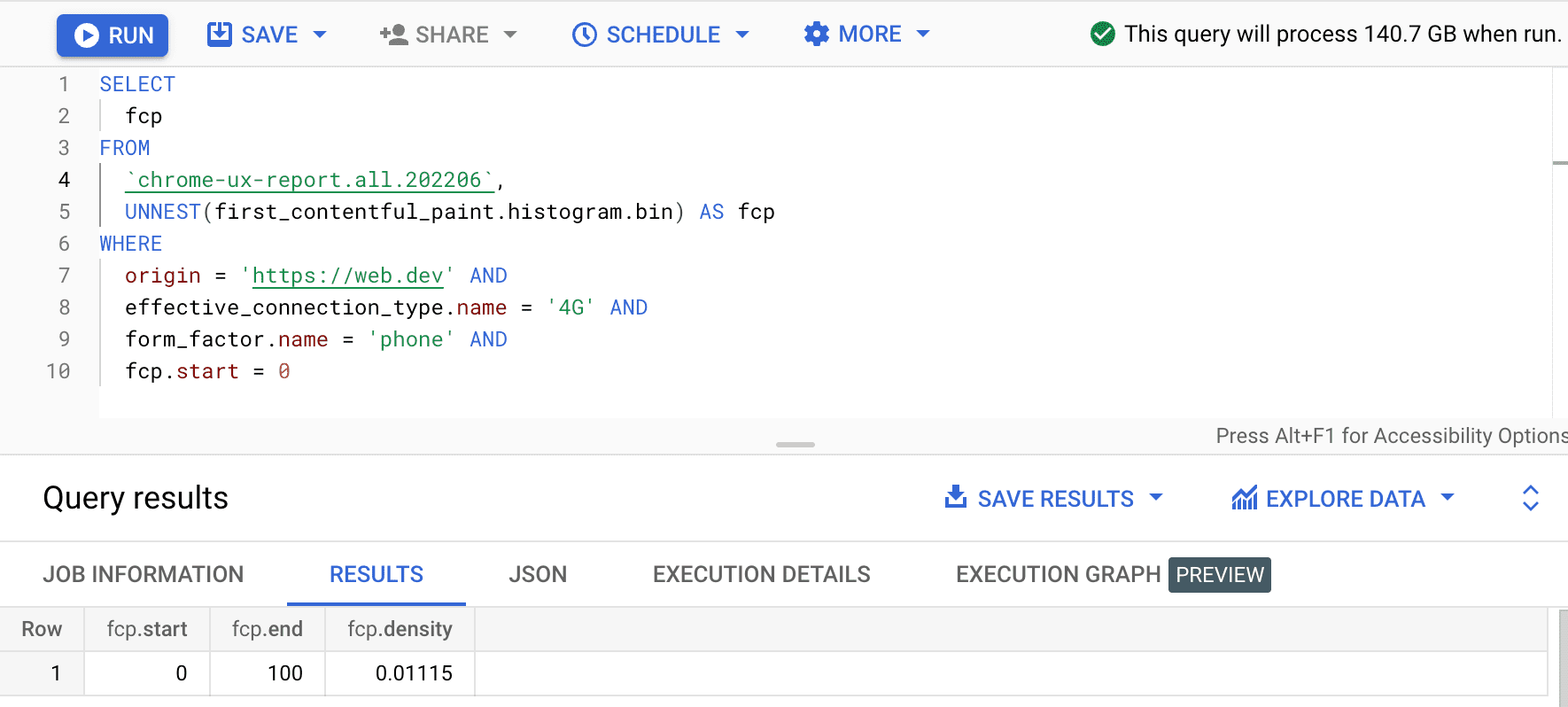
O resultado é 0.01115, o que significa que 1,115% das experiências do usuário nessa origem estão entre 0 e 100 ms em 4G e em um smartphone. Se quisermos generalizar a consulta para qualquer conexão e qualquer tipo de dispositivo, podemos omití-los da cláusula WHERE e usar a função agregadora SUM para somar todas as densidades de bin:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
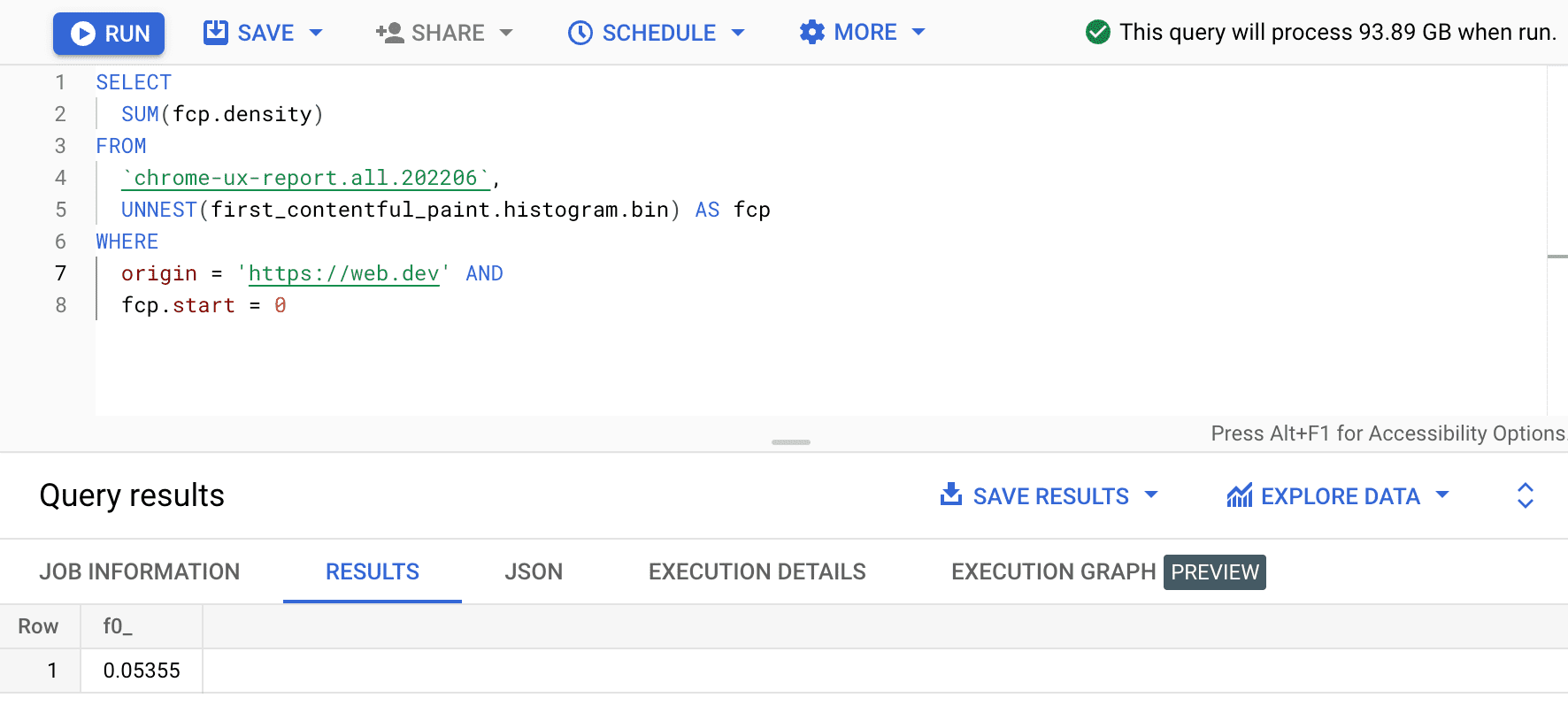
O resultado é 0.05355, ou 5,355% em todos os dispositivos e tipos de conexão. Podemos modificar um pouco a consulta e somar as densidades de todos os intervalos que estão no intervalo de FCP "rápido" de 0 a 1.000 ms:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
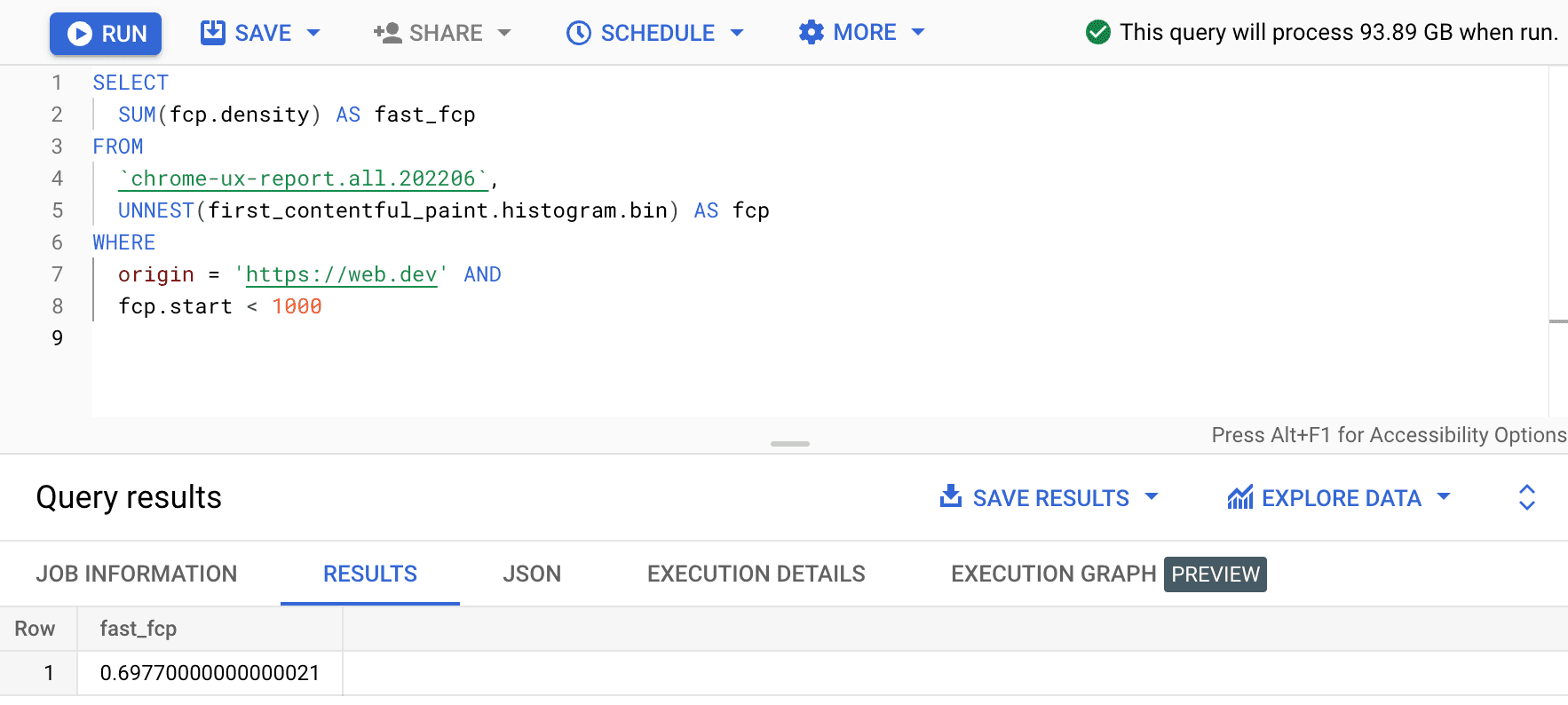
Isso nos dá 0.6977. Em outras palavras, 69,77% das experiências do usuário com FCP no web.dev são consideradas "rápidas" de acordo com a definição de intervalo de FCP.
Acompanhar o desempenho
Agora que extraímos os dados de performance de uma origem, podemos compará-los com os dados históricos disponíveis em tabelas mais antigas. Para isso, podemos reescrever o endereço da tabela para um mês anterior ou usar a sintaxe de curinga para consultar todos os meses:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
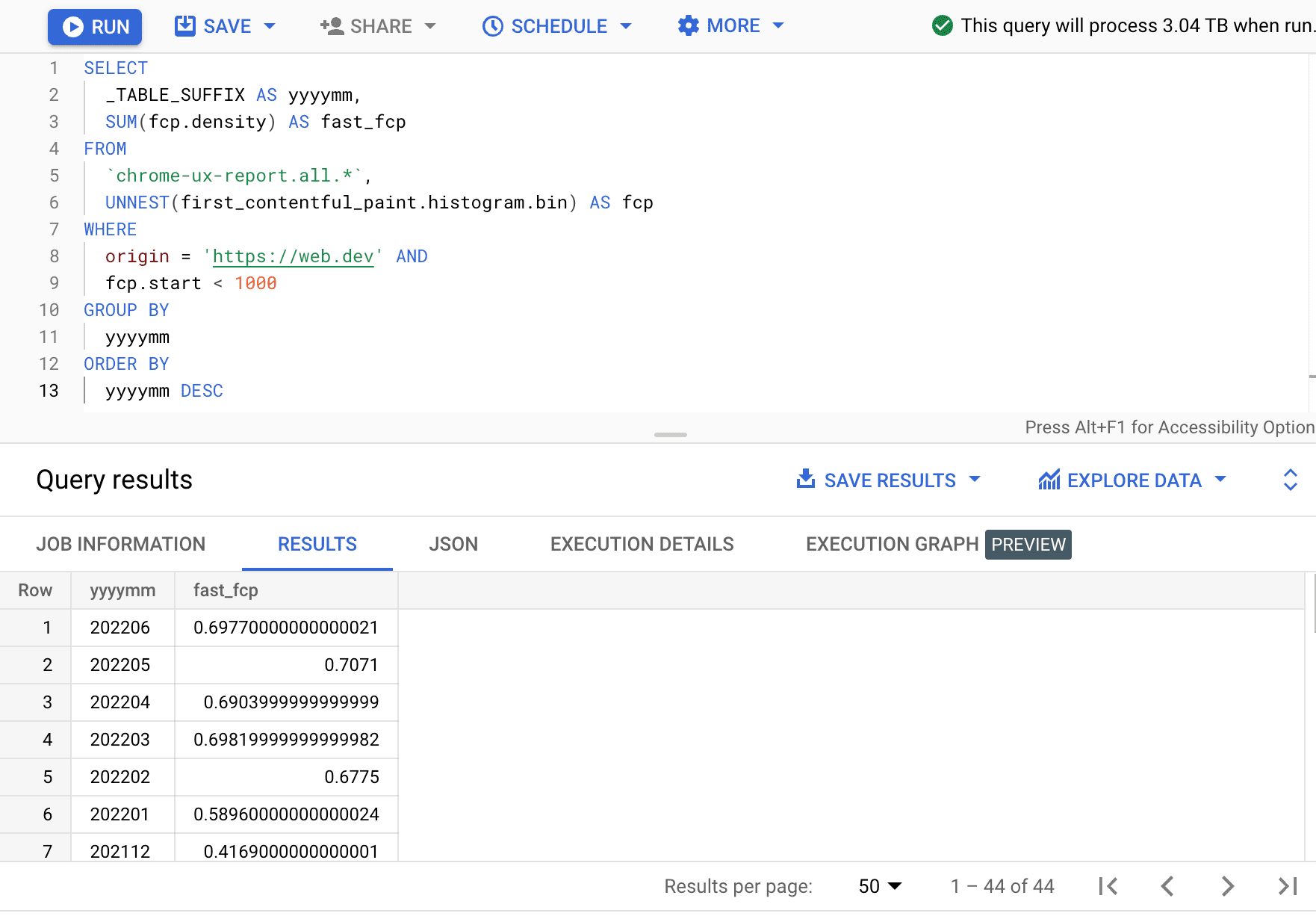
Aqui, vemos que a porcentagem de experiências de FCP rápidas varia alguns pontos percentuais a cada mês.
| aaaamm | fast_fcp |
|---|---|
| 202206 | 69,77% |
| 202205 | 70,71% |
| 202204 | 69,04% |
| 202203 | 69,82% |
| 202202 | 67,75% |
| 202201 | 58,96% |
| 202112 | 41,69% |
| … | … |
Com essas técnicas, você pode consultar a performance de uma origem, calcular a porcentagem de experiências rápidas e acompanhar ao longo do tempo. Na próxima etapa, tente consultar duas ou mais origens e comparar a performance delas.
Perguntas frequentes
Confira algumas perguntas frequentes sobre o conjunto de dados do BigQuery do CrUX:
Quando devo usar o BigQuery em vez de outras ferramentas?
O BigQuery só é necessário quando você não consegue acessar as mesmas informações em outras ferramentas, como o painel do CrUX e o PageSpeed Insights. Por exemplo, o BigQuery permite dividir os dados de maneiras significativas e até mesmo mesclar com outros conjuntos de dados públicos, como o HTTP Archive, para fazer mineração de dados avançada.
Há alguma limitação no uso do BigQuery?
Sim, a limitação mais importante é que, por padrão, os usuários só podem consultar 1 TB de dados por mês. Além disso, a taxa padrão de US $5/TB será aplicada.
Onde posso saber mais sobre o BigQuery?
Confira a documentação do BigQuery para mais informações.