

প্রকাশিত: ১০ অক্টোবর, ২০২৫

ক্লাসিক বোর্ড গেম, "Gese Who?" , হল অনুমানমূলক যুক্তির একটি মাস্টারক্লাস। প্রতিটি খেলোয়াড় মুখের একটি বোর্ড দিয়ে শুরু করে এবং হ্যাঁ বা না প্রশ্নের একটি সিরিজের মাধ্যমে, সম্ভাবনাগুলিকে সংকুচিত করে যতক্ষণ না আপনি আত্মবিশ্বাসের সাথে আপনার প্রতিপক্ষের গোপন চরিত্র সনাক্ত করতে পারেন।
গুগল আই/ও কানেক্টে বিল্ট-ইন এআই -এর একটি ডেমো দেখার পর, আমি ভাবলাম: যদি আমি ব্রাউজারে থাকা এআই-এর বিরুদ্ধে একটি গেস হু? গেম খেলতে পারি? ক্লায়েন্ট-সাইড এআই-এর মাধ্যমে, ছবিগুলি স্থানীয়ভাবে ব্যাখ্যা করা হবে, তাই বন্ধুবান্ধব এবং পরিবারের একটি কাস্টম গেস হু? আমার ডিভাইসে ব্যক্তিগত এবং সুরক্ষিত থাকবে।
আমার পটভূমি মূলত UI এবং UX ডেভেলপমেন্টের উপর, এবং আমি পিক্সেল-নিখুঁত অভিজ্ঞতা তৈরিতে অভ্যস্ত। আমি আশা করেছিলাম আমার ব্যাখ্যার মাধ্যমে আমি ঠিক সেটাই করতে পারব।
আমার অ্যাপ্লিকেশন, AI Guess Who?, React দিয়ে তৈরি এবং প্রম্পট API এবং একটি ব্রাউজার বিল্ট-ইন মডেল ব্যবহার করে একটি আশ্চর্যজনকভাবে সক্ষম প্রতিপক্ষ তৈরি করে। এই প্রক্রিয়ায়, আমি আবিষ্কার করেছি যে "পিক্সেল-পারফেক্ট" ফলাফল পাওয়া এত সহজ নয়। কিন্তু, এই অ্যাপ্লিকেশনটি দেখায় যে কীভাবে চিন্তাশীল গেম লজিক তৈরিতে AI ব্যবহার করা যেতে পারে, এবং এই লজিককে পরিমার্জিত করতে এবং আপনার প্রত্যাশিত ফলাফল পেতে প্রম্পট ইঞ্জিনিয়ারিংয়ের গুরুত্ব কত।
বিল্ট-ইন এআই ইন্টিগ্রেশন, আমার মুখোমুখি হওয়া চ্যালেঞ্জ এবং আমি যে সমাধানগুলি পেয়েছি সেগুলি সম্পর্কে জানতে পড়তে থাকুন। আপনি গেমটি খেলতে পারেন এবং GitHub-এ সোর্স কোডটি খুঁজে পেতে পারেন।
গেম ফাউন্ডেশন: একটি রিঅ্যাক্ট অ্যাপ
AI বাস্তবায়নের দিকে তাকানোর আগে, আমরা অ্যাপ্লিকেশনটির কাঠামো পর্যালোচনা করব। আমি TypeScript ব্যবহার করে একটি স্ট্যান্ডার্ড React অ্যাপ্লিকেশন তৈরি করেছি, যার কেন্দ্রীয় App.tsx ফাইলটি গেমের কন্ডাক্টর হিসেবে কাজ করবে। এই ফাইলটিতে রয়েছে:
- গেম স্টেট : একটি এনাম যা গেমের বর্তমান পর্যায় ট্র্যাক করে (যেমন
PLAYER_TURN_ASKING,AI_TURN,GAME_OVER)। এটি হল সবচেয়ে গুরুত্বপূর্ণ অবস্থা, কারণ এটি ইন্টারফেসটি কী প্রদর্শন করবে এবং খেলোয়াড়ের জন্য কোন ক্রিয়াগুলি উপলব্ধ তা নির্দেশ করে। - চরিত্র তালিকা : একাধিক তালিকা রয়েছে যা সক্রিয় চরিত্র, প্রতিটি খেলোয়াড়ের গোপন চরিত্র এবং বোর্ড থেকে কোন অক্ষরগুলি বাদ দেওয়া হয়েছে তা নির্দেশ করে।
- গেম চ্যাট : প্রশ্ন, উত্তর এবং সিস্টেম বার্তাগুলির একটি চলমান লগ।
ইন্টারফেসটি লজিক্যাল উপাদানগুলিতে বিভক্ত:

গেমটির বৈশিষ্ট্যগুলি বৃদ্ধির সাথে সাথে এর জটিলতাও বৃদ্ধি পেয়েছিল। প্রাথমিকভাবে, পুরো গেমের লজিকটি একটি একক, বৃহৎ কাস্টম রিঅ্যাক্ট হুক , useGameLogic মধ্যে পরিচালিত হত, কিন্তু দ্রুত এটি নেভিগেট এবং ডিবাগ করার জন্য খুব বড় হয়ে যায়। রক্ষণাবেক্ষণ উন্নত করার জন্য, আমি এই হুকটিকে একাধিক হুকে পুনর্নির্মাণ করেছি, প্রতিটির জন্য একটি একক দায়িত্ব ছিল। উদাহরণস্বরূপ:
-
useGameStateমূল অবস্থা পরিচালনা করে -
usePlayerActionsখেলোয়াড়ের পালা অনুসারে -
useAIActionsহল AI এর লজিকের জন্য
প্রধান useGameLogic হুক এখন একটি পরিষ্কার কম্পোজার হিসেবে কাজ করে, এই ছোট হুকগুলিকে একসাথে স্থাপন করে। এই স্থাপত্য পরিবর্তন গেমটির কার্যকারিতা পরিবর্তন করেনি, তবে এটি কোডবেসকে অনেক বেশি পরিষ্কার করে তুলেছে।
প্রম্পট এপিআই সহ গেম লজিক
এই প্রকল্পের মূল বিষয় হল প্রম্পট এপিআই ব্যবহার।
আমি builtInAIService.ts এ AI গেম লজিক যোগ করেছি। এর মূল দায়িত্বগুলি হল:
- সীমাবদ্ধ, বাইনারি উত্তরের অনুমতি দিন।
- মডেল গেম কৌশল শেখান।
- মডেল বিশ্লেষণ শেখান।
- মডেলটিকে স্মৃতিভ্রংশ দিন।
সীমাবদ্ধ, বাইনারি উত্তরগুলিকে অনুমতি দিন
খেলোয়াড় কীভাবে AI-এর সাথে যোগাযোগ করে? যখন একজন খেলোয়াড় জিজ্ঞাসা করে, "তোমার চরিত্রের কি টুপি আছে?", তখন AI-কে তার গোপন চরিত্রের চিত্র "দেখতে" হবে এবং একটি স্পষ্ট উত্তর দিতে হবে।
আমার প্রথম প্রচেষ্টাগুলো বেশ ঝামেলাপূর্ণ ছিল। উত্তরটি ছিল কথোপকথনের মতো: "না, আমি যে চরিত্রটির কথা ভাবছি, ইসাবেলা, তার মাথায় টুপি আছে বলে মনে হচ্ছে না," হ্যাঁ বা না দ্বিগুণ করার পরিবর্তে। প্রাথমিকভাবে, আমি খুব কঠোরভাবে এই সমস্যাটি সমাধান করেছি, মূলত মডেলটিকে কেবল "হ্যাঁ" বা "না" দিয়ে উত্তর দেওয়ার নির্দেশ দিয়েছি।
যদিও এটি কাজ করেছে, আমি স্ট্রাকচার্ড আউটপুট ব্যবহার করে আরও ভালো একটি উপায় শিখেছি। মডেলটিকে JSON স্কিমা প্রদান করে, আমি একটি সত্য বা মিথ্যা প্রতিক্রিয়ার গ্যারান্টি দিতে পারি।
const schema = { type: "boolean" };
const result = session.prompt(prompt, { responseConstraint: schema });
এটি আমাকে প্রম্পটটি সহজ করার অনুমতি দিয়েছে এবং আমার কোডটি নির্ভরযোগ্যভাবে প্রতিক্রিয়া পরিচালনা করতে দিয়েছে:
JSON.parse(result) ? "Yes" : "No"
মডেল গেম কৌশল শেখান
মডেলকে প্রশ্নের উত্তর দিতে বলা, মডেলকে প্রশ্ন জিজ্ঞাসা করার চেয়ে অনেক সহজ। একজন ভালো Guess Who? খেলোয়াড় এলোমেলো প্রশ্ন জিজ্ঞাসা করে না। তারা এমন প্রশ্ন জিজ্ঞাসা করে যা একসাথে বেশিরভাগ অক্ষর বাদ দেয়। একটি আদর্শ প্রশ্ন বাইনারি প্রশ্ন ব্যবহার করে সম্ভাব্য অবশিষ্ট অক্ষর অর্ধেক করে দেয়।
কিভাবে আপনি একটি মডেলকে সেই কৌশল শেখাবেন? আবার, প্রম্পট ইঞ্জিনিয়ারিং। generateAIQuestion() এর প্রম্পট আসলে Guess Who? গেম তত্ত্বের একটি সংক্ষিপ্ত পাঠ।
প্রাথমিকভাবে, আমি মডেলটিকে "একটি ভালো প্রশ্ন জিজ্ঞাসা করতে" বলেছিলাম। ফলাফলগুলি অপ্রত্যাশিত ছিল। ফলাফল উন্নত করার জন্য, আমি নেতিবাচক সীমাবদ্ধতা যোগ করেছি। প্রম্পটে এখন অনুরূপ নির্দেশাবলী অন্তর্ভুক্ত রয়েছে:
- "গুরুত্বপূর্ণ: শুধুমাত্র বিদ্যমান বৈশিষ্ট্যগুলি সম্পর্কে জিজ্ঞাসা করুন"
- "সমালোচনামূলক: মৌলিক হোন। কোনও প্রশ্ন পুনরাবৃত্তি করবেন না"।
এই সীমাবদ্ধতাগুলি মডেলের ফোকাসকে সংকুচিত করে, অপ্রাসঙ্গিক প্রশ্ন জিজ্ঞাসা করা থেকে বিরত রাখে, যা এটিকে আরও উপভোগ্য প্রতিপক্ষ করে তোলে। আপনি GitHub-এ সম্পূর্ণ প্রম্পট ফাইলটি পর্যালোচনা করতে পারেন।
মডেল বিশ্লেষণ শেখান
এটি ছিল এখন পর্যন্ত সবচেয়ে কঠিন এবং গুরুত্বপূর্ণ চ্যালেঞ্জ। যখন মডেল একটি প্রশ্ন জিজ্ঞাসা করে, যেমন, "তোমার চরিত্রের কি টুপি আছে?" এবং খেলোয়াড় উত্তর দেয় না, তখন মডেল কীভাবে জানবে যে তাদের বোর্ড থেকে কোন চরিত্রগুলি বাদ পড়েছে?
মডেলটির উচিত টুপি দিয়ে সবাইকে বাদ দেওয়া। আমার প্রথম দিকের প্রচেষ্টাগুলো যুক্তিগত ত্রুটির সাথে জর্জরিত ছিল, এবং কখনও কখনও মডেল ভুল অক্ষর বাদ দিত অথবা কোনও অক্ষরই বাদ দিত না। এছাড়াও, "টুপি" কী? "বিনি" কি "টুপি" হিসেবে গণ্য হয়? সত্যি কথা বলতে, এটি এমন কিছু যা মানুষের বিতর্কে ঘটতে পারে। এবং অবশ্যই, সাধারণ ভুলগুলি ঘটে। এআই দৃষ্টিকোণ থেকে চুল দেখতে টুপির মতো হতে পারে।
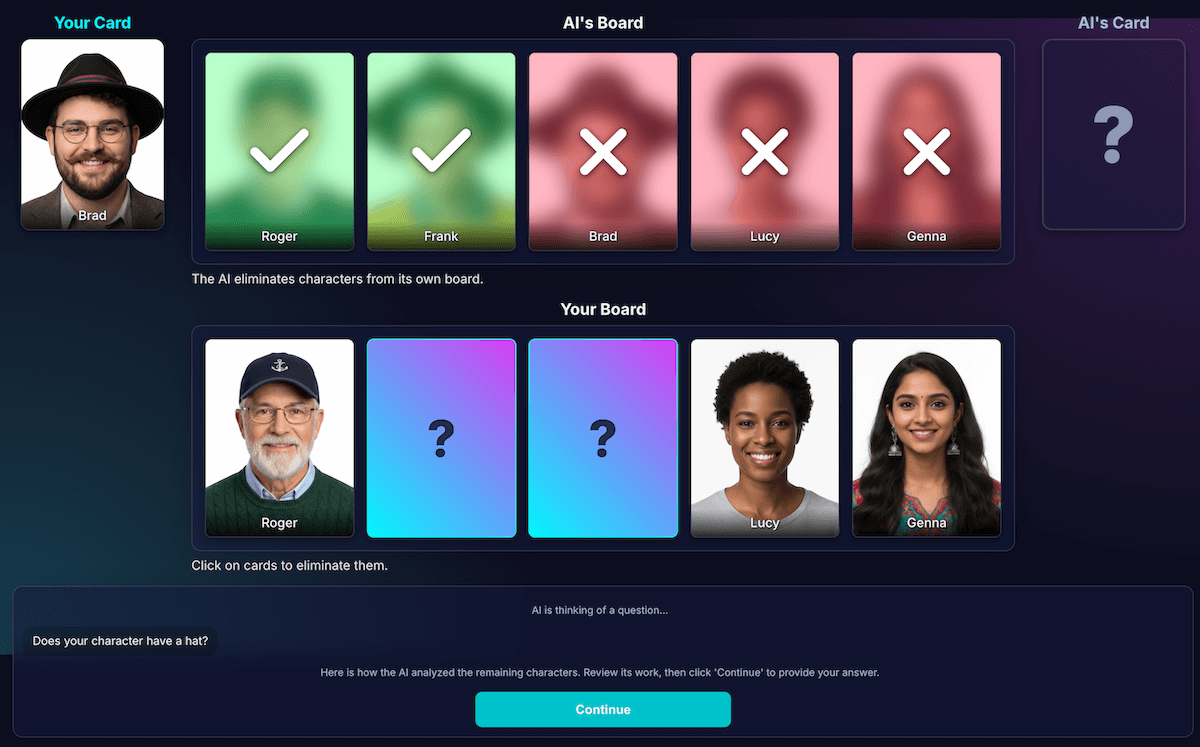
কোড ডিডাকশন থেকে উপলব্ধি আলাদা করার জন্য আমি স্থাপত্যটি পুনরায় ডিজাইন করেছি:
AI ভিজ্যুয়াল বিশ্লেষণের জন্য দায়ী । মডেলগুলি ভিজ্যুয়াল বিশ্লেষণে পারদর্শী। আমি মডেলটিকে তার প্রশ্ন এবং একটি বিস্তারিত বিশ্লেষণ একটি কঠোর JSON স্কিমায় ফেরত দেওয়ার নির্দেশ দিয়েছিলাম। মডেলটি তার বোর্ডের প্রতিটি অক্ষর বিশ্লেষণ করে এবং "এই অক্ষরটির কি এই বৈশিষ্ট্য আছে?" প্রশ্নের উত্তর দেয়। মডেলটি একটি কাঠামোগত JSON অবজেক্ট ফেরত দেয়:
{ "character_id": "...", "has_feature": true }আবারও বলছি, স্ট্রাকচার্ড ডেটা একটি সফল ফলাফলের চাবিকাঠি।
গেম কোড চূড়ান্ত সিদ্ধান্ত নেওয়ার জন্য বিশ্লেষণ ব্যবহার করে । অ্যাপ্লিকেশন কোডটি খেলোয়াড়ের উত্তর ("হ্যাঁ" বা "না") পরীক্ষা করে এবং AI এর বিশ্লেষণের মাধ্যমে পুনরাবৃত্তি করে। যদি খেলোয়াড় "না" বলে, তাহলে কোডটি প্রতিটি অক্ষরকে বাদ দিতে জানে যেখানে
has_featuretrue।
আমি মনে করি নির্ভরযোগ্য AI অ্যাপ্লিকেশন তৈরির জন্য এই শ্রম বিভাজন গুরুত্বপূর্ণ। বিশ্লেষণাত্মক ক্ষমতার জন্য AI ব্যবহার করুন এবং বাইনারি সিদ্ধান্তগুলি আপনার অ্যাপ্লিকেশন কোডের উপর ছেড়ে দিন।
মডেলের উপলব্ধি পরীক্ষা করার জন্য, আমি এই বিশ্লেষণের একটি ভিজ্যুয়ালাইজেশন তৈরি করেছি। এর ফলে মডেলের উপলব্ধি সঠিক কিনা তা নিশ্চিত করা সহজ হয়েছিল।
দ্রুত প্রকৌশল
তবে, এই বিচ্ছেদের পরেও, আমি লক্ষ্য করেছি যে মডেলের ধারণা এখনও ত্রুটিপূর্ণ হতে পারে। এটি কোনও চরিত্র চশমা পরে কিনা তা ভুল বিচার করতে পারে, যার ফলে হতাশাজনক, ভুল নির্মূলের দিকে পরিচালিত হয়। এটি মোকাবেলা করার জন্য, আমি একটি দুই-পদক্ষেপ প্রক্রিয়া নিয়ে পরীক্ষা-নিরীক্ষা করেছি: AI তার প্রশ্ন জিজ্ঞাসা করবে। খেলোয়াড়ের উত্তর পাওয়ার পর, এটি উত্তরটিকে প্রসঙ্গ হিসাবে বিবেচনা করে দ্বিতীয়, নতুন বিশ্লেষণ করবে। তত্ত্বটি ছিল যে দ্বিতীয়বার দেখালে প্রথমটির ত্রুটি ধরা পড়তে পারে।
এই প্রবাহটি কীভাবে কাজ করত তা এখানে:
- এআই টার্ন (এপিআই কল ১) : এআই জিজ্ঞাসা করে, "তোমার চরিত্রের কি দাড়ি আছে?"
- খেলোয়াড়ের পালা : খেলোয়াড় তাদের গোপন চরিত্রের দিকে তাকায়, যে ক্লিন-শেভন, এবং উত্তর দেয়, "না।"
- এআই টার্ন (এপিআই কল ২) : এআই কার্যকরভাবে নিজেকে তার বাকি সমস্ত অক্ষরগুলি আবার দেখতে বলে এবং খেলোয়াড়ের উত্তরের উপর ভিত্তি করে কোনগুলি বাদ দিতে হবে তা নির্ধারণ করে।
দ্বিতীয় ধাপে, মডেলটি হালকা দাড়িওয়ালা চরিত্রটিকে "দাড়ি নেই" বলে ভুল বুঝতে পারে এবং ব্যবহারকারীর প্রত্যাশা থাকলেও সেগুলি বাদ দিতে ব্যর্থ হতে পারে। মূল উপলব্ধি ত্রুটিটি ঠিক করা হয়নি, এবং অতিরিক্ত পদক্ষেপটি ফলাফল বিলম্বিত করেছে। কোনও মানব প্রতিপক্ষের বিরুদ্ধে খেলার সময়, আমরা এই বিষয়ে একটি চুক্তি বা স্পষ্টীকরণ নির্দিষ্ট করতে পারি; আমাদের AI প্রতিপক্ষের সাথে বর্তমান সেটআপে, এটি এমন নয়।
এই প্রক্রিয়াটি দ্বিতীয় API কল থেকে ল্যাটেন্সি যোগ করেছে, কিন্তু নির্ভুলতা উল্লেখযোগ্যভাবে বৃদ্ধি পায়নি। যদি মডেলটি প্রথমবার ভুল ছিল, তবে দ্বিতীয়বারও প্রায়শই ভুল হত। আমি কেবল একবার পর্যালোচনা করার প্রম্পটটি ফিরিয়ে দিয়েছি।
আরও বিশ্লেষণ যোগ করার পরিবর্তে উন্নতি করুন
আমি একটি UX নীতির উপর নির্ভর করেছিলাম: সমাধান ছিল আরও বিশ্লেষণ নয়, বরং আরও ভাল বিশ্লেষণ।
আমি প্রম্পটটি পরিমার্জন করার জন্য প্রচুর বিনিয়োগ করেছি, মডেলটির কাজ দুবার পরীক্ষা করার জন্য এবং স্বতন্ত্র বৈশিষ্ট্যগুলির উপর ফোকাস করার জন্য স্পষ্ট নির্দেশাবলী যুক্ত করেছি, যা নির্ভুলতা উন্নত করার জন্য আরও কার্যকর কৌশল হিসাবে প্রমাণিত হয়েছে। বর্তমান, আরও নির্ভরযোগ্য প্রবাহ কীভাবে কাজ করে তা এখানে:
AI টার্ন (API কল) : মডেলটিকে একই সাথে তার প্রশ্ন এবং অভ্যন্তরীণ বিশ্লেষণ উভয়ই তৈরি করতে বলা হয়, যা একটি একক JSON অবজেক্ট ফেরত দেয়।
- প্রশ্ন : "তোমার চরিত্র কি চশমা পরে?"
- বিশ্লেষণ (তথ্য) :
[ {character_id: 'brad', has_feature: true}, {character_id: 'alex', has_feature: false}, {character_id: 'gina', has_feature: true}, ... ]খেলোয়াড়ের পালা : খেলোয়াড়ের গোপন চরিত্র হল অ্যালেক্স (চশমা ছাড়াই), তাই তারা উত্তর দেয়, "না।"
রাউন্ড এন্ডস : অ্যাপ্লিকেশনের জাভাস্ক্রিপ্ট কোডটি কাজ করে। এটির জন্য AI কে আর কিছু জিজ্ঞাসা করার প্রয়োজন হয় না। এটি ধাপ ১ থেকে বিশ্লেষণ ডেটার মাধ্যমে পুনরাবৃত্তি করে।
- খেলোয়াড় বলল "না।"
- কোডটি প্রতিটি অক্ষর অনুসন্ধান করে যেখানে
has_featureসত্য। - এটি ব্র্যাড এবং জিনার কথা উল্টে দেয়। যুক্তিটি নির্ণায়ক এবং তাৎক্ষণিক।
এই পরীক্ষাটি অত্যন্ত গুরুত্বপূর্ণ ছিল, কিন্তু এর জন্য অনেক চেষ্টা-তদবির করতে হয়েছিল। আমার কোনও ধারণা ছিল না যে এটি আরও ভালো হবে কিনা। কখনও কখনও, এটি আরও খারাপ হয়ে যায়। কীভাবে সবচেয়ে সামঞ্জস্যপূর্ণ ফলাফল পাওয়া যায় তা নির্ধারণ করা কোনও সঠিক বিজ্ঞান নয় (তবুও, যদি কখনও হয়...)।
কিন্তু আমার নতুন এআই প্রতিপক্ষের সাথে কয়েক রাউন্ডের পর, একটি দুর্দান্ত নতুন সমস্যা দেখা দিল: একটি অচলাবস্থা।
অচলাবস্থা থেকে মুক্তি
যখন মাত্র দুটি বা তিনটি খুব একই রকম চরিত্র অবশিষ্ট থাকত, তখন মডেলটি একটি লুপে আটকে যেত। এটি তাদের সকলের ভাগ করা বৈশিষ্ট্য সম্পর্কে একটি প্রশ্ন জিজ্ঞাসা করত, যেমন, "তোমার চরিত্র কি টুপি পরে?"
আমার কোডটি সঠিকভাবে এটিকে একটি নষ্ট পালা হিসেবে চিহ্নিত করবে, এবং AI আরেকটি, সমানভাবে বিস্তৃত বৈশিষ্ট্য চেষ্টা করবে যেখানে অক্ষরগুলিও ভাগ করা হয়েছে, যেমন, "আপনার চরিত্র কি চশমা পরে?"
আমি একটি নতুন নিয়ম দিয়ে প্রম্পটটি উন্নত করেছি: যদি প্রশ্ন তৈরির প্রচেষ্টা ব্যর্থ হয় এবং তিন বা তার কম অক্ষর বাকি থাকে, তাহলে কৌশলটি পরিবর্তিত হয়।
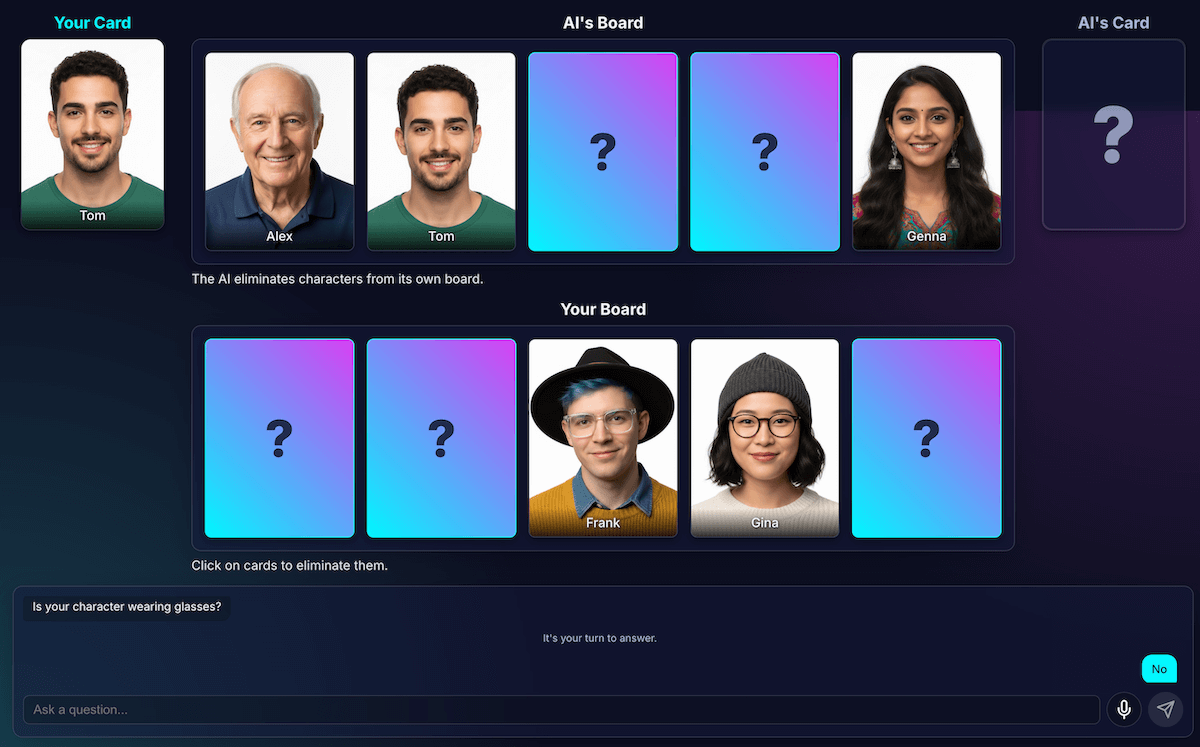
নতুন নির্দেশনাটি স্পষ্ট: "একটি বিস্তৃত বৈশিষ্ট্যের পরিবর্তে, পার্থক্য খুঁজে পেতে আপনাকে আরও নির্দিষ্ট, অনন্য, বা সম্মিলিত দৃশ্যমান বৈশিষ্ট্য সম্পর্কে জিজ্ঞাসা করতে হবে।" উদাহরণস্বরূপ, চরিত্রটি টুপি পরে কিনা তা জিজ্ঞাসা করার পরিবর্তে, তারা বেসবল ক্যাপ পরেছে কিনা তা জিজ্ঞাসা করতে বলা হয়।
এর ফলে মডেলটিকে ছবিগুলো আরও ঘনিষ্ঠভাবে দেখতে হয় এবং সেই ছোট্ট বিশদটি খুঁজে বের করতে হয় যা অবশেষে একটি অগ্রগতির দিকে নিয়ে যেতে পারে, যার ফলে তাদের দেরী-খেলার কৌশলটি বেশিরভাগ সময়ই কিছুটা ভালোভাবে কাজ করে।
মডেলটিকে স্মৃতিভ্রংশ দিন।
একটি ভাষা মডেলের সবচেয়ে বড় শক্তি হল এর স্মৃতিশক্তি। কিন্তু এই গেমটিতে, এর সবচেয়ে বড় শক্তি দুর্বলতা হয়ে ওঠে। যখন আমি দ্বিতীয় গেম শুরু করতাম, তখন এটি বিভ্রান্তিকর বা অপ্রাসঙ্গিক প্রশ্ন জিজ্ঞাসা করত। অবশ্যই, আমার বুদ্ধিমান AI প্রতিপক্ষ আগের গেমের পুরো চ্যাট ইতিহাস ধরে রাখছিল। এটি একসাথে দুটি (বা তারও বেশি) গেমের অর্থ বোঝার চেষ্টা করছিল।
একই AI সেশন পুনঃব্যবহার করার পরিবর্তে, আমি এখন প্রতিটি খেলার শেষে এটি স্পষ্টভাবে ধ্বংস করে ফেলি , যা মূলত AI স্মৃতিভ্রংশের কারণ হয়ে দাঁড়ায়।
যখন আপনি Play Again এ ক্লিক করেন, তখন startNewGameSession() ফাংশন বোর্ডটিকে রিসেট করে এবং একটি নতুন AI সেশন তৈরি করে। এটি কেবল অ্যাপেই নয়, বরং AI মডেলের মধ্যেই সেশন স্টেট পরিচালনা করার একটি আকর্ষণীয় পাঠ ছিল।
ঘণ্টা এবং বাঁশি: কাস্টম গেম এবং ভয়েস ইনপুট
অভিজ্ঞতা আরও আকর্ষণীয় করার জন্য, আমি দুটি অতিরিক্ত বৈশিষ্ট্য যুক্ত করেছি:
কাস্টম অক্ষর :
getUserMedia()ব্যবহার করে, খেলোয়াড়রা তাদের ক্যামেরা ব্যবহার করে তাদের নিজস্ব 5-অক্ষরের সেট তৈরি করতে পারে। আমি অক্ষরগুলি সংরক্ষণ করার জন্য IndexedDB ব্যবহার করেছি, এটি একটি ব্রাউজার ডাটাবেস যা ইমেজ ব্লবের মতো বাইনারি ডেটা সংরক্ষণের জন্য উপযুক্ত। আপনি যখন একটি কাস্টম সেট তৈরি করেন, তখন এটি আপনার ব্রাউজারে সংরক্ষণ করা হয় এবং প্রধান মেনুতে একটি রিপ্লে বিকল্প প্রদর্শিত হয়।ভয়েস ইনপুট : ক্লায়েন্ট-সাইড মডেলটি মাল্টি-মডাল । এটি টেক্সট, ছবি এবং অডিওও পরিচালনা করতে পারে। মাইক্রোফোন ইনপুট ক্যাপচার করার জন্য MediaRecorder API ব্যবহার করে, আমি "নিম্নলিখিত অডিওটি ট্রান্সক্রাইব করুন..." প্রম্পট দিয়ে মডেলটিতে অডিও ব্লব ফিড করতে পারি। এটি খেলার একটি মজাদার উপায় যোগ করে (এবং এটি আমার ফ্লেমিশ উচ্চারণকে কীভাবে ব্যাখ্যা করে তা দেখার একটি মজাদার উপায়)। আমি মূলত এই নতুন ওয়েব ক্ষমতার বহুমুখীতা দেখানোর জন্য এটি তৈরি করেছি, কিন্তু সত্যি বলতে, আমি বারবার প্রশ্ন টাইপ করতে করতে ক্লান্ত হয়ে পড়েছিলাম।
ডেমো
আপনি এখানে সরাসরি গেমটি পরীক্ষা করতে পারেন অথবা একটি নতুন উইন্ডোতে খেলতে পারেন এবং GitHub-এ সোর্স কোডটি খুঁজে পেতে পারেন।
শেষ ভাবনা
"AI Guess Who?" তৈরি করা অবশ্যই একটি চ্যালেঞ্জ ছিল। কিন্তু ডকুমেন্ট পড়ার সাহায্যে এবং AI ডিবাগ করার জন্য কিছু AI (হ্যাঁ... আমি এটা করেছি), এটি একটি মজার পরীক্ষায় পরিণত হয়েছে। এটি ব্রাউজারে একটি মডেল চালানোর মাধ্যমে একটি ব্যক্তিগত, দ্রুত, ইন্টারনেট-প্রয়োজনীয় অভিজ্ঞতা তৈরির বিশাল সম্ভাবনা তুলে ধরেছে। এটি এখনও একটি পরীক্ষা, এবং কখনও কখনও প্রতিপক্ষ পুরোপুরি খেলতে পারে না। এটি পিক্সেল-নিখুঁত বা লজিক-নিখুঁত নয়। জেনারেটিভ AI এর সাথে, ফলাফল মডেল-নির্ভর।
পরিপূর্ণতার জন্য চেষ্টা করার পরিবর্তে, আমি ফলাফল উন্নত করার লক্ষ্য রাখব।
এই প্রকল্পটি প্রম্পট ইঞ্জিনিয়ারিংয়ের ক্রমাগত চ্যালেঞ্জগুলিকেও তুলে ধরেছে। সেই প্রম্পটিং সত্যিই এর একটি বিশাল অংশ হয়ে ওঠে, এবং সর্বদা সবচেয়ে মজার অংশ নয়। কিন্তু আমি যে সবচেয়ে গুরুত্বপূর্ণ শিক্ষাটি শিখেছি তা হল ধারণাকে বাদ থেকে আলাদা করার জন্য অ্যাপ্লিকেশন তৈরি করা, AI এবং কোডের ক্ষমতা ভাগ করা। এমনকি এই বিচ্ছেদের পরেও, আমি দেখেছি যে AI এখনও (মানুষের কাছে) স্পষ্ট ভুল করতে পারে, যেমন মেকআপের জন্য ট্যাটু বিভ্রান্ত করা বা কার গোপন চরিত্র নিয়ে আলোচনা করা হচ্ছে তা ভুলে যাওয়া।
প্রতিবার, সমাধান ছিল প্রম্পটগুলিকে আরও স্পষ্ট করে তোলা, এমন নির্দেশাবলী যুক্ত করা যা মানুষের কাছে স্পষ্ট মনে হয় কিন্তু মডেলের জন্য অপরিহার্য।
মাঝে মাঝে, খেলাটি অন্যায্য বলে মনে হত। মাঝে মাঝে, আমার মনে হত যেন AI গোপন চরিত্রটি আগে থেকেই "জানত", যদিও কোডটি কখনও স্পষ্টভাবে সেই তথ্য ভাগ করে নিত না। এটি মানুষ বনাম মেশিনের একটি গুরুত্বপূর্ণ অংশ দেখায়:
একজন AI-এর আচরণ কেবল সঠিক হতে হবে না; এটি ন্যায্য বোধ করাও প্রয়োজন।
এই কারণেই আমি প্রম্পটগুলিকে স্পষ্ট নির্দেশাবলী দিয়ে আপডেট করেছি, যেমন, "তুমি জানো না আমি কোন চরিত্রটি বেছে নিয়েছি," এবং "কোন প্রতারণা নেই।" আমি শিখেছি যে AI এজেন্ট তৈরি করার সময়, আপনার সীমাবদ্ধতা নির্ধারণে সময় ব্যয় করা উচিত, সম্ভবত নির্দেশাবলীর চেয়েও বেশি।
মডেলটির সাথে মিথস্ক্রিয়া আরও উন্নত করা যেতে পারে। একটি বিল্ট-ইন মডেলের সাথে কাজ করার মাধ্যমে, আপনি একটি বিশাল সার্ভার-সাইড মডেলের শক্তি এবং নির্ভরযোগ্যতা কিছুটা হারাবেন, তবে আপনি গোপনীয়তা, গতি এবং অফলাইন ক্ষমতা অর্জন করবেন। এই ধরণের গেমের জন্য, সেই বিনিময়টি সত্যিই পরীক্ষা-নিরীক্ষার যোগ্য ছিল। ক্লায়েন্ট-সাইড এআই-এর ভবিষ্যত দিন দিন উন্নত হচ্ছে, মডেলগুলিও ছোট হচ্ছে, এবং আমরা পরবর্তীতে কী তৈরি করতে পারব তা দেখার জন্য আমি অধীর আগ্রহে অপেক্ষা করতে পারছি না।