

Los datos sin procesar del informe de UX de Chrome (CrUX) están disponibles en BigQuery, una base de datos de Google Cloud. Para usar BigQuery, necesitas un proyecto de GCP y conocimientos básicos de SQL.
En esta guía, aprenderás a usar BigQuery para escribir consultas en el conjunto de datos de CrUX y extraer resultados valiosos sobre el estado de las experiencias del usuario en la Web:
- Comprende cómo están organizados los datos
- Cómo escribir una consulta básica para evaluar el rendimiento de un origen
- Escribe una consulta avanzada para hacer un seguimiento del rendimiento a lo largo del tiempo
Organización de los datos
Comienza por analizar una consulta básica:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
Para ejecutar la consulta, ingrésala en el editor de consultas y presiona el botón "Ejecutar consulta":
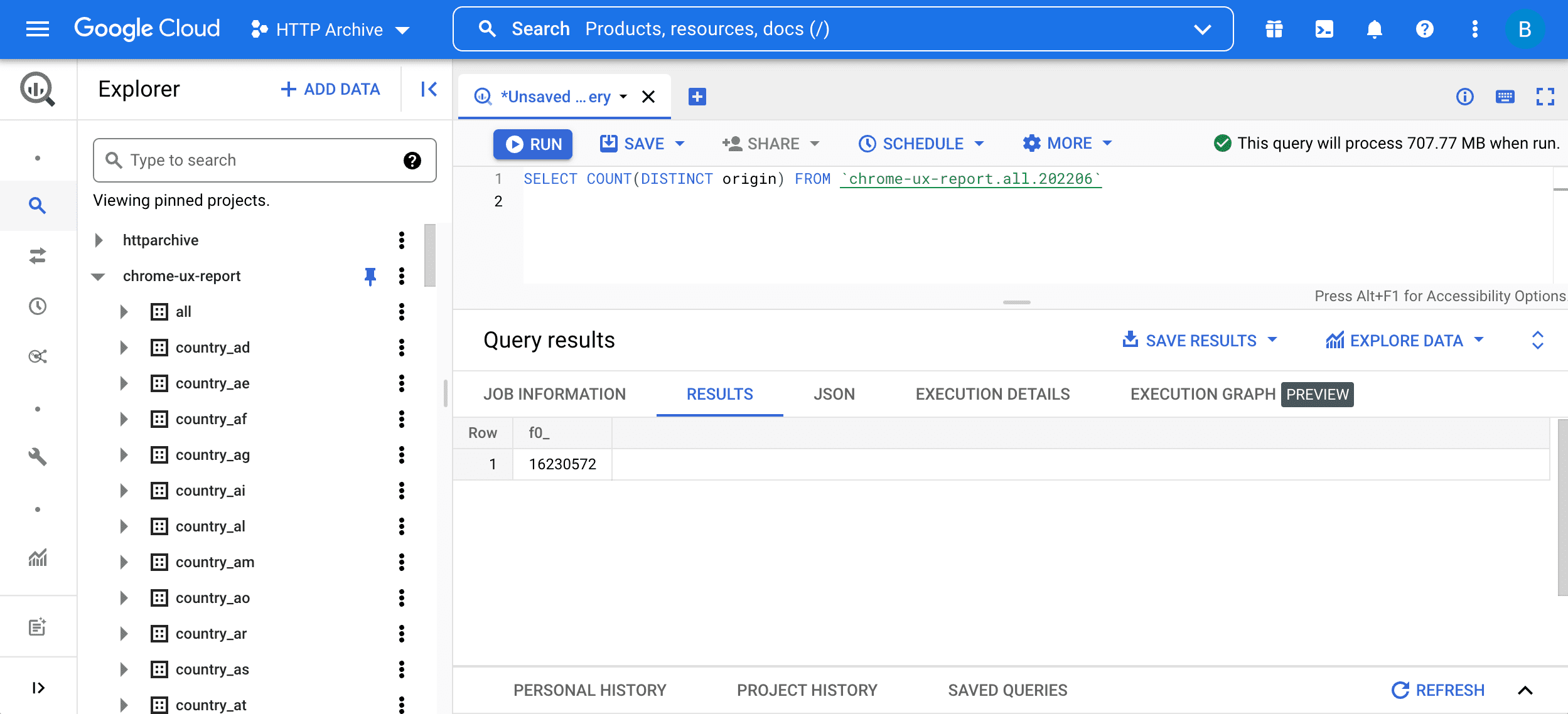
Esta consulta tiene dos partes:
SELECT COUNT(DISTINCT origin)significa consultar la cantidad de orígenes en la tabla. En términos generales, dos URLs forman parte del mismo origen si tienen el mismo esquema, host y puerto.FROM chrome-ux-report.all.202206especifica la dirección de la tabla de origen, que tiene tres partes:- El nombre del proyecto de Cloud
chrome-ux-reportdentro del cual se organizan todos los datos de CrUX - El conjunto de datos
all, que representa los datos de todos los países - La tabla
202206, el año y el mes de los datos en formato AAAAMM
- El nombre del proyecto de Cloud
También hay conjuntos de datos para cada país. Por ejemplo, chrome-ux-report.country_ca.202206 solo representa los datos de la experiencia del usuario que provienen de Canadá.
Dentro de cada conjunto de datos, hay tablas para todos los meses desde 201710. Las tablas nuevas del mes calendario anterior se publican con regularidad.
La estructura de las tablas de datos (también conocida como esquema) contiene lo siguiente:
- El origen, por ejemplo,
origin = 'https://www.example.com', que representa la distribución agregada de la experiencia del usuario para todas las páginas de ese sitio web - La velocidad de conexión en el momento de la carga de la página, por ejemplo,
effective_connection_type.name = '4G'(se quitará en febrero de 2025) - El tipo de dispositivo, por ejemplo,
form_factor.name = 'desktop' - Las métricas de UX en sí
Los datos de cada métrica se organizan como un array de objetos. En la notación JSON, first_contentful_paint.histogram.bin se vería de la siguiente manera:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
Cada intervalo contiene una hora de inicio y una de finalización en milisegundos, y una densidad que representa el porcentaje de experiencias del usuario dentro de ese período. En otras palabras, el 12.34% de las experiencias de FCP para este origen hipotético, la velocidad de conexión y el tipo de dispositivo son inferiores a 100 ms. La suma de todas las densidades de contenedores es 100%.
Explora la estructura de las tablas en BigQuery.
Evaluación del rendimiento
Podemos usar nuestro conocimiento del esquema de la tabla para escribir una consulta que extraiga estos datos de rendimiento.
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
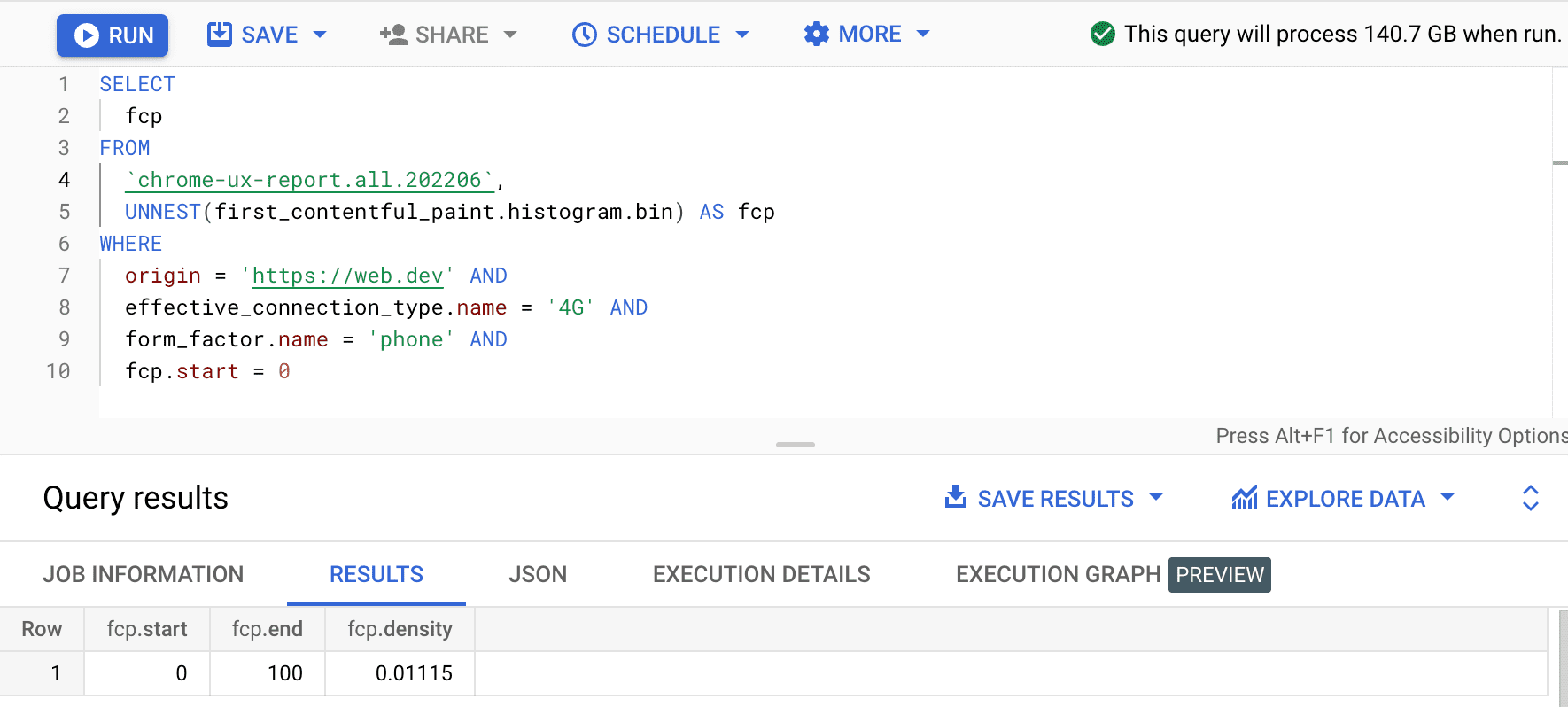
El resultado es 0.01115, lo que significa que el 1.115% de las experiencias del usuario en este origen se encuentran entre 0 y 100 ms en 4G y en un teléfono. Si queremos generalizar nuestra consulta a cualquier conexión y cualquier tipo de dispositivo, podemos omitirlas de la cláusula WHERE y usar la función de agregador SUM para sumar todas sus densidades de intervalos correspondientes:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
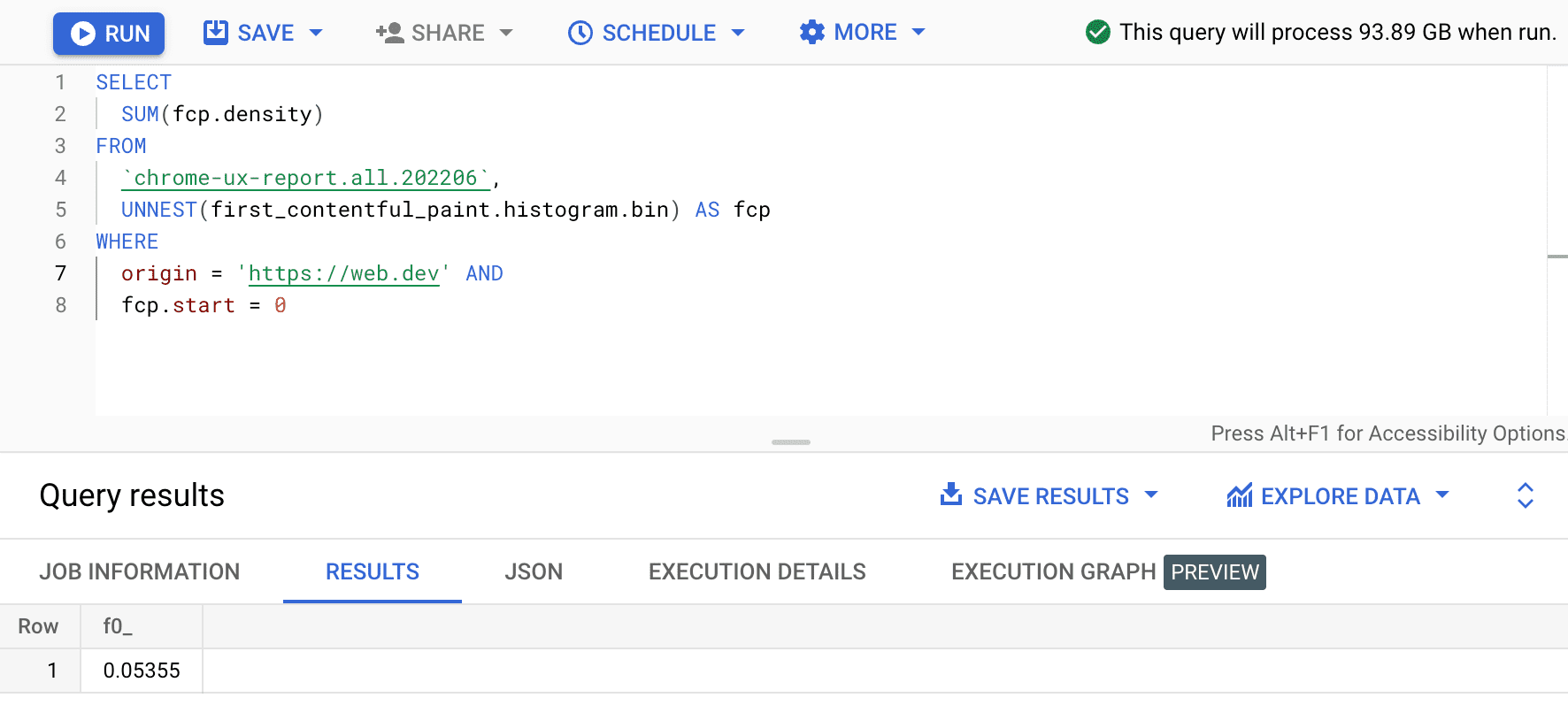
El resultado es 0.05355, o el 5.355% en todos los dispositivos y tipos de conexión. Podemos modificar ligeramente la consulta y sumar las densidades de todos los intervalos que se encuentran en el rango de FCP "rápido" de 0 a 1,000 ms:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
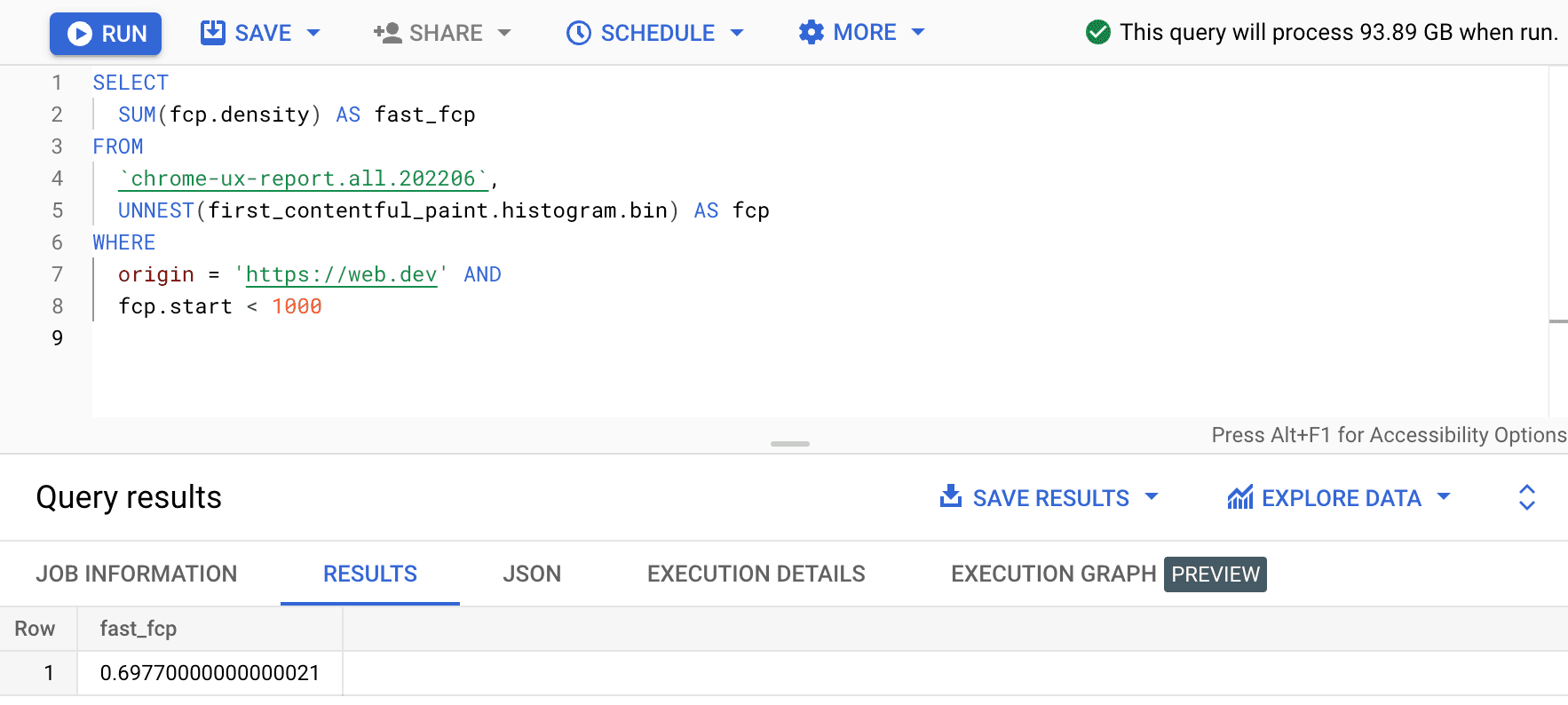
Esto nos da 0.6977. En otras palabras, el 69.77% de las experiencias del usuario de FCP en web.dev se consideran "rápidas" según la definición del rango de FCP.
Hacer un seguimiento del rendimiento
Ahora que extrajimos datos de rendimiento sobre un origen, podemos compararlos con los datos históricos disponibles en tablas anteriores. Para ello, podríamos volver a escribir la dirección de la tabla en un mes anterior o usar la sintaxis de comodín para consultar todos los meses:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
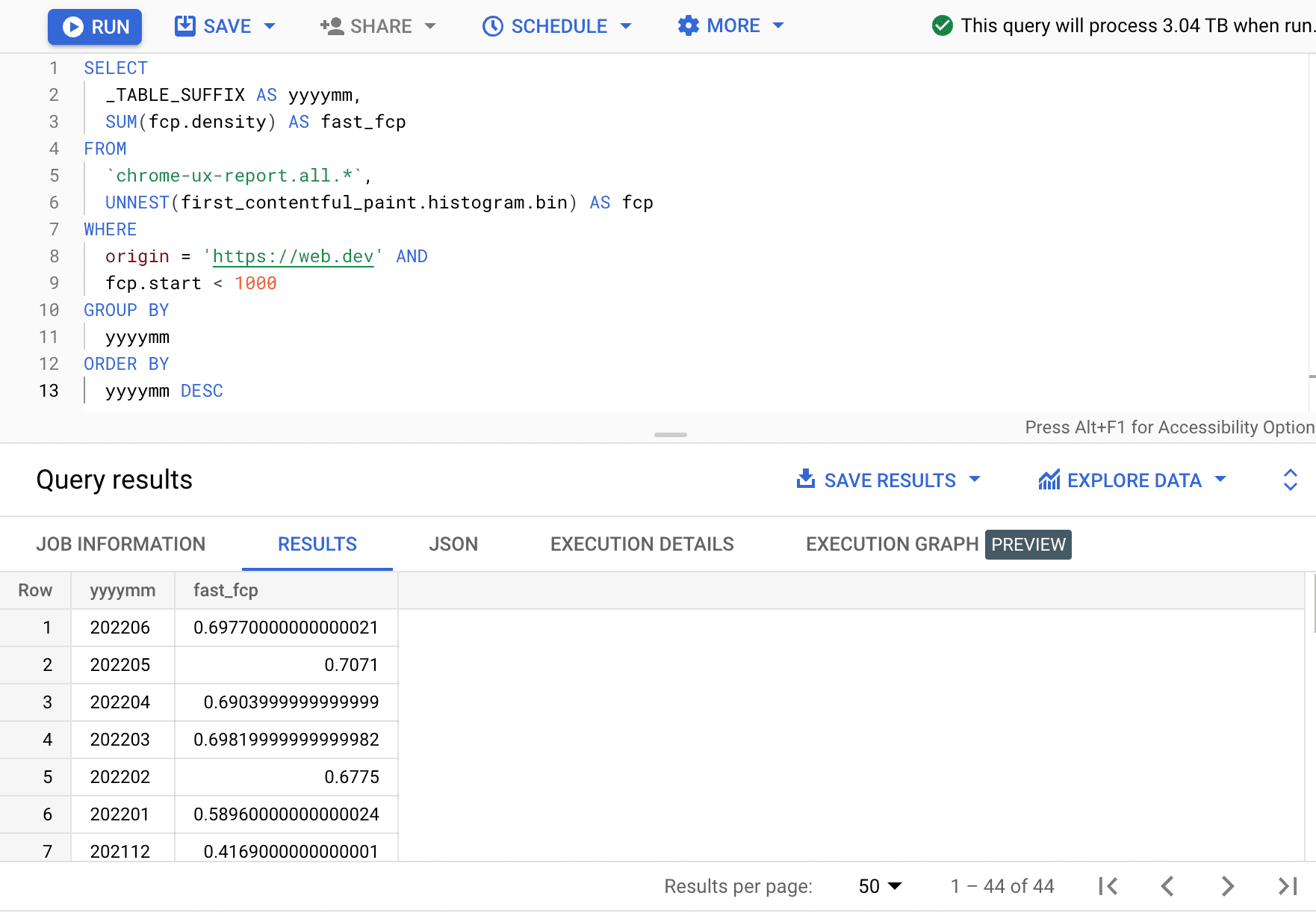
Aquí, vemos que el porcentaje de experiencias de FCP rápidas varía en unos pocos puntos porcentuales cada mes.
| aaaamm | fast_fcp |
|---|---|
| 202206 | 69.77% |
| 202205 | 70.71% |
| 202204 | 69.04% |
| 202203 | 69.82% |
| 202202 | 67.75% |
| 202201 | 58.96% |
| 202112 | 41.69% |
| … | … |
Con estas técnicas, puedes buscar el rendimiento de un origen, calcular el porcentaje de experiencias rápidas y hacerle un seguimiento a lo largo del tiempo. Como siguiente paso, intenta consultar dos o más orígenes y compara su rendimiento.
Preguntas frecuentes
Estas son algunas de las preguntas frecuentes sobre el conjunto de datos de BigQuery de CrUX:
¿Cuándo debería usar BigQuery en lugar de otras herramientas?
BigQuery solo es necesario cuando no puedes obtener la misma información de otras herramientas, como el panel de CrUX y PageSpeed Insights. Por ejemplo, BigQuery te permite segmentar los datos de manera significativa y, además, unirlos con otros conjuntos de datos públicos, como el Archivo HTTP, para realizar un análisis de datos avanzado.
¿Hay alguna limitación para usar BigQuery?
Sí, la limitación más importante es que, de forma predeterminada, los usuarios solo pueden consultar 1 TB de datos por mes. Después de eso, se aplica la tarifa estándar de USD 5 por TB.
¿Dónde puedo obtener más información sobre BigQuery?
Consulta la documentación de BigQuery para obtener más información.