

ข้อมูลดิบของรายงาน UX ของ Chrome (CrUX) มีอยู่ใน BigQuery ซึ่งเป็นฐานข้อมูลใน Google Cloud การใช้ BigQuery ต้องมีโปรเจ็กต์ GCP และความรู้พื้นฐานเกี่ยวกับ SQL
ในคู่มือนี้ คุณจะดูวิธีใช้ BigQuery เพื่อเขียนการค้นหาชุดข้อมูล CrUX เพื่อดึงข้อมูลเชิงลึกเกี่ยวกับสถานะของประสบการณ์ของผู้ใช้บนเว็บได้
- ทําความเข้าใจวิธีจัดระเบียบข้อมูล
- เขียนคําค้นหาพื้นฐานเพื่อประเมินประสิทธิภาพของต้นทาง
- เขียนการค้นหาขั้นสูงเพื่อติดตามประสิทธิภาพเมื่อเวลาผ่านไป
การจัดระเบียบข้อมูล
เริ่มต้นด้วยการดูการค้นหาพื้นฐาน
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
หากต้องการเรียกใช้คําค้นหา ให้ป้อนคําค้นหานั้นลงในเครื่องมือแก้ไขคําค้นหา แล้วกดปุ่ม "เรียกใช้คําค้นหา"
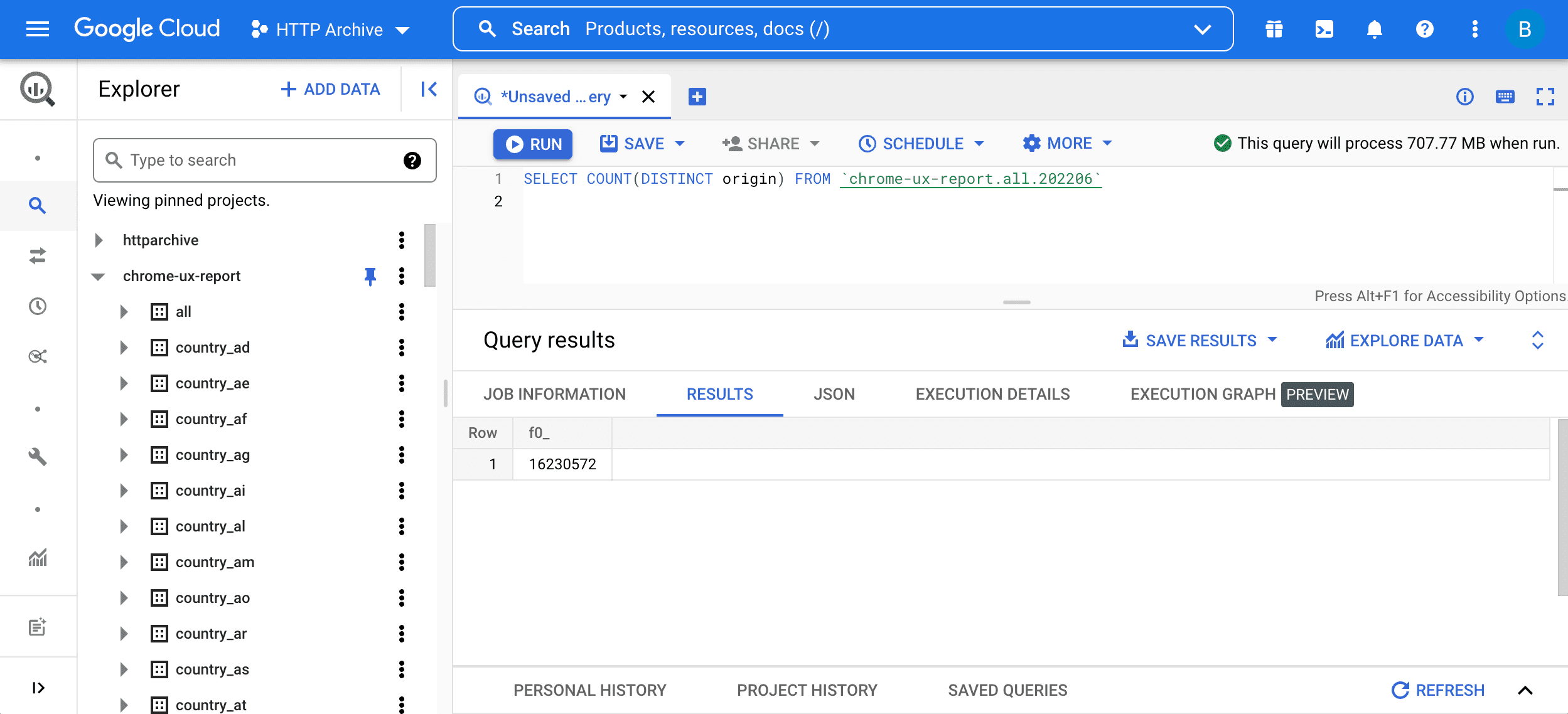
คําค้นหานี้มี 2 ส่วน ดังนี้
SELECT COUNT(DISTINCT origin)หมายถึงการค้นหาจํานวนต้นทางในตาราง กล่าวโดยคร่าวๆ ก็คือ URL 2 รายการเป็นส่วนหนึ่งของต้นทางเดียวกันหากมีรูปแบบ โฮสต์ และพอร์ตเดียวกันFROM chrome-ux-report.all.202206ระบุที่อยู่ของตารางต้นทาง ซึ่งมี 3 ส่วนดังนี้- ชื่อโปรเจ็กต์ในระบบคลาวด์
chrome-ux-reportซึ่งจัดระเบียบข้อมูล CrUX ทั้งหมด - ชุดข้อมูล
allที่แสดงข้อมูลในทุกประเทศ - ตาราง
202206, ปีและเดือนของข้อมูลในรูปแบบ ปปปปดด
- ชื่อโปรเจ็กต์ในระบบคลาวด์
นอกจากนี้ยังมีชุดข้อมูลสำหรับทุกประเทศ เช่น chrome-ux-report.country_ca.202206 แสดงเฉพาะข้อมูลประสบการณ์ของผู้ใช้ที่มาจากแคนาดา
ภายในชุดข้อมูลแต่ละชุดจะมีตารางสำหรับทุกเดือนตั้งแต่เดือนตุลาคม 2017 ระบบจะเผยแพร่ตารางใหม่สำหรับเดือนก่อนหน้าตามปฏิทินเป็นประจำ
โครงสร้างของตารางข้อมูล (หรือที่เรียกว่าสคีมา) มีดังนี้
- ต้นทาง เช่น
origin = 'https://www.example.com'ซึ่งแสดงการแจกแจงประสบการณ์ของผู้ใช้โดยรวมสําหรับหน้าเว็บทั้งหมดในเว็บไซต์นั้น - ความเร็วในการเชื่อมต่อ ณ เวลาโหลดหน้าเว็บ เช่น
effective_connection_type.name = '4G'(นําออกตั้งแต่เดือนกุมภาพันธ์ 2025) - ประเภทอุปกรณ์ เช่น
form_factor.name = 'desktop' - เมตริก UX เอง
ข้อมูลของเมตริกแต่ละรายการจะจัดระเบียบเป็นอาร์เรย์ของออบเจ็กต์ ในนิพจน์ JSON first_contentful_paint.histogram.bin จะมีลักษณะดังนี้
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
แต่ละช่องมีเวลาเริ่มต้นและเวลาสิ้นสุดเป็นมิลลิวินาที รวมถึงความหนาแน่นที่แสดงเปอร์เซ็นต์ของประสบการณ์ของผู้ใช้ในช่วงระยะเวลานั้น กล่าวคือ 12.34% ของ FCP สำหรับต้นทาง ความเร็วการเชื่อมต่อ และประเภทอุปกรณ์สมมตินี้ใช้เวลาน้อยกว่า 100 มิลลิวินาที ผลรวมของความหนาแน่นของกล่องทั้งหมดคือ 100%
เรียกดูโครงสร้างของตารางใน BigQuery
ประเมินประสิทธิภาพ
เราสามารถใช้ความรู้เกี่ยวกับสคีมาตารางเพื่อเขียนการค้นหาที่จะดึงข้อมูลประสิทธิภาพนี้
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
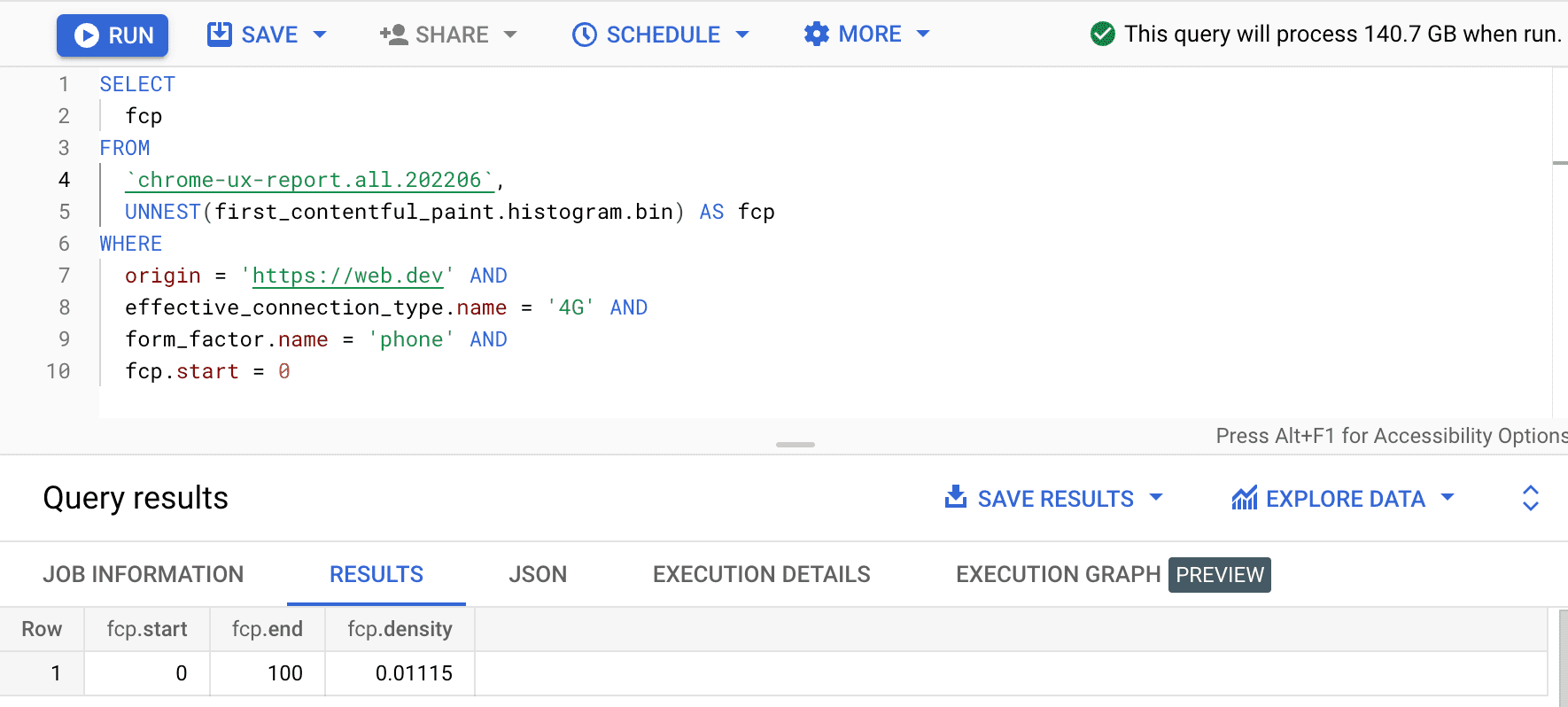
ผลลัพธ์คือ 0.01115 ซึ่งหมายความว่า 1.115% ของประสบการณ์ของผู้ใช้จากต้นทางนี้อยู่ระหว่าง 0 ถึง 100 มิลลิวินาทีใน 4G และบนโทรศัพท์ หากต้องการค้นหาแบบทั่วไปสำหรับการเชื่อมต่อและอุปกรณ์ทุกประเภท ให้ละเว้นการเชื่อมต่อและอุปกรณ์เหล่านั้นจากประโยค WHERE และใช้ฟังก์ชันรวบรวมข้อมูล SUM เพื่อรวมความหนาแน่นของกล่องที่เกี่ยวข้องทั้งหมด ดังนี้
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
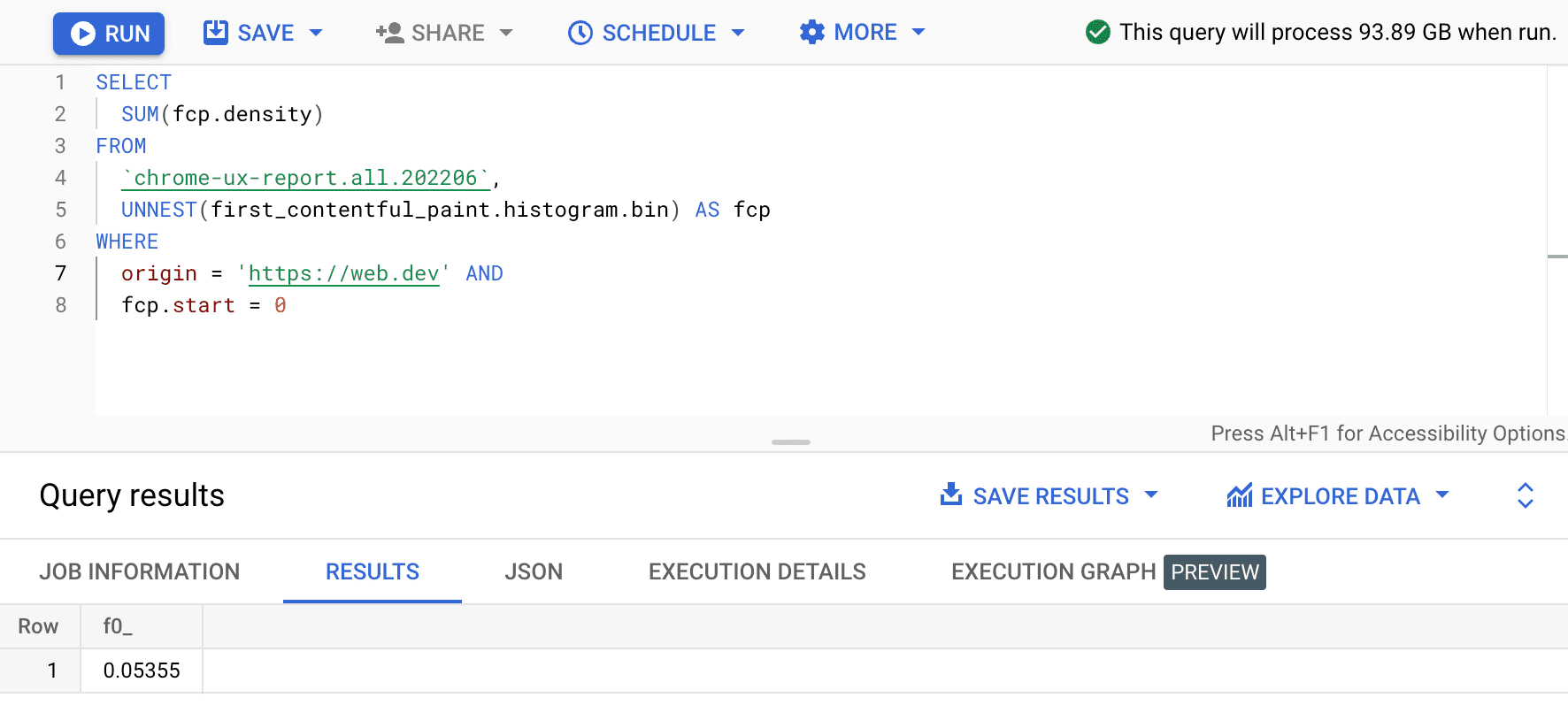
ผลลัพธ์คือ 0.05355 หรือ 5.355% ในอุปกรณ์และการเชื่อมต่อทุกประเภท เราแก้ไขการค้นหาเล็กน้อยและรวมความหนาแน่นของทุกช่องที่อยู่ในช่วง FCP "เร็ว" 0-1,000 มิลลิวินาที ดังนี้
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
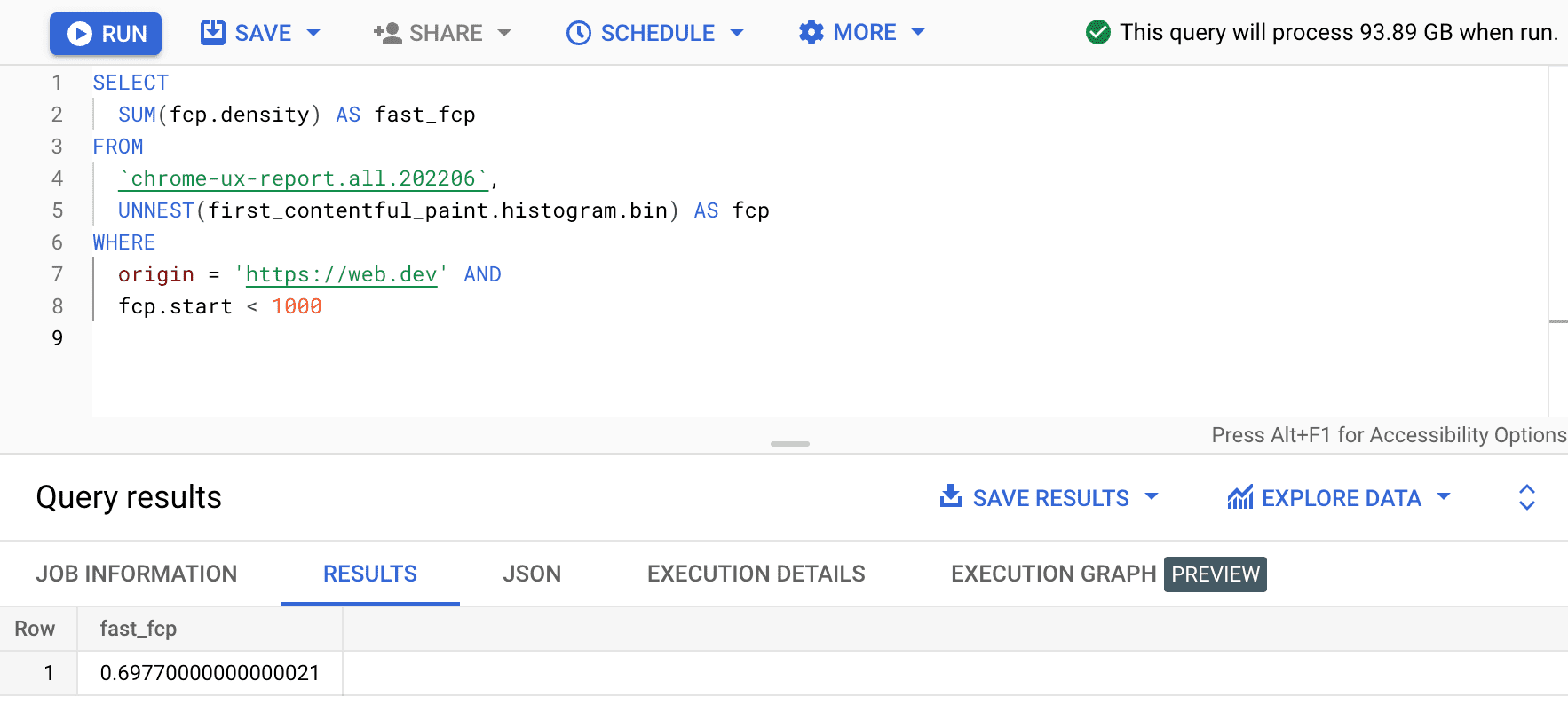
ซึ่งจะให้ 0.6977 กล่าวคือ ประสบการณ์ของผู้ใช้ FCP บน web.dev 69.77% ถือว่า "เร็ว" ตามคำจำกัดความของช่วง FCP
ติดตามประสิทธิภาพ
เมื่อดึงข้อมูลประสิทธิภาพเกี่ยวกับต้นทางแล้ว เราจะเปรียบเทียบข้อมูลดังกล่าวกับข้อมูลย้อนหลังที่มีอยู่ในตารางเก่าได้ ซึ่งทำได้โดยเขียนที่อยู่ตารางเป็นเดือนก่อนหน้า หรือจะใช้ไวลด์การ์ดเพื่อค้นหาทุกเดือนก็ได้ ดังนี้
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
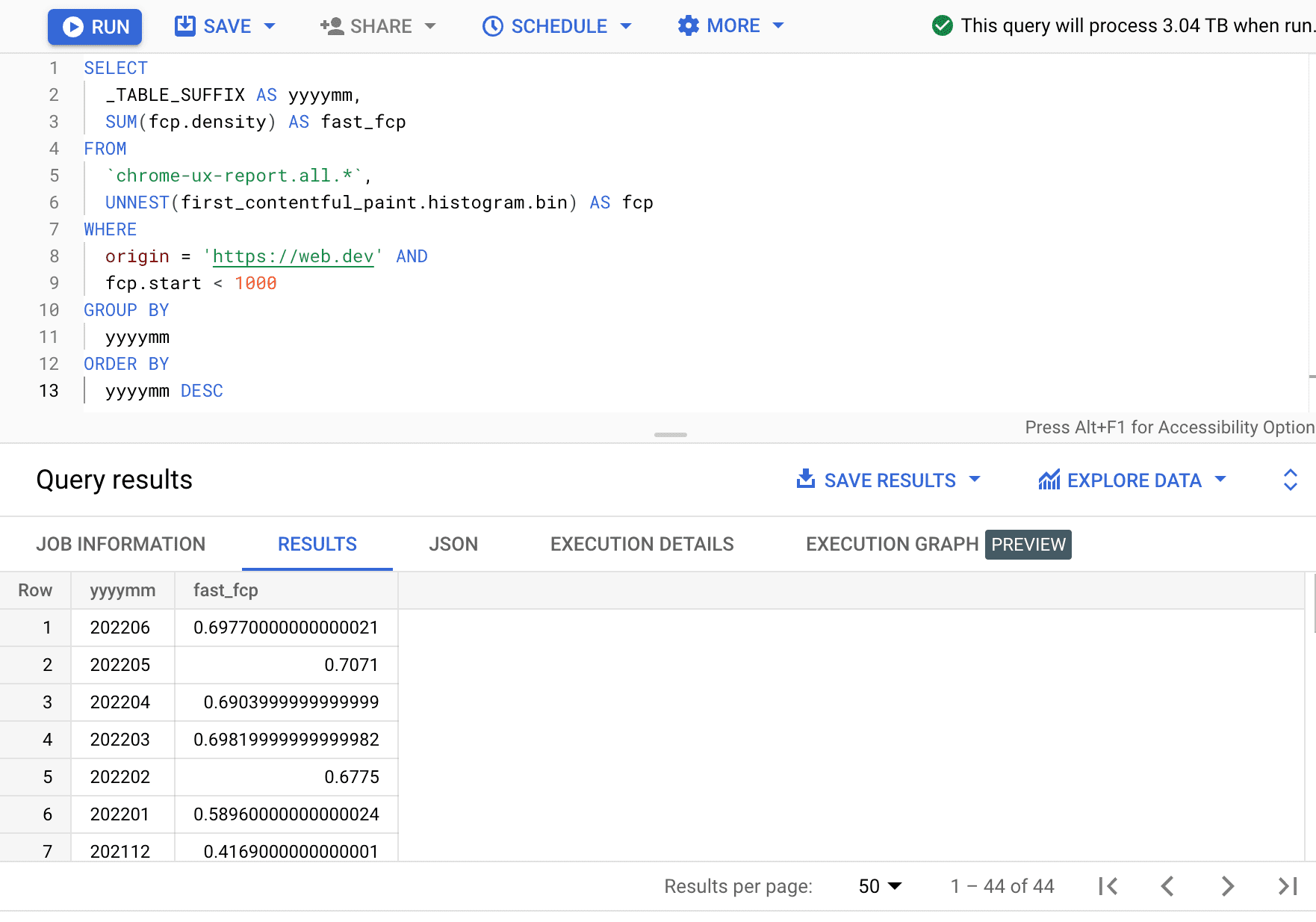
เราพบว่าเปอร์เซ็นต์ของประสบการณ์ FCP ที่รวดเร็วจะแตกต่างกันไป 2-3 เปอร์เซ็นต์ในแต่ละเดือน
| yyyymm | fast_fcp |
|---|---|
| 202206 | 69.77% |
| 202205 | 70.71% |
| 202204 | 69.04% |
| 202203 | 69.82% |
| 202202 | 67.75% |
| 202201 | 58.96% |
| 202112 | 41.69% |
| ... | ... |
เทคนิคเหล่านี้จะช่วยให้คุณดูประสิทธิภาพของต้นทาง คํานวณเปอร์เซ็นต์ของประสบการณ์ที่รวดเร็ว และติดตามประสิทธิภาพเมื่อเวลาผ่านไปได้ ในขั้นตอนถัดไป ให้ลองค้นหาแหล่งที่มาอย่างน้อย 2 แห่งและเปรียบเทียบประสิทธิภาพ
คำถามที่พบบ่อย
ต่อไปนี้คือคําถามที่พบบ่อยเกี่ยวกับชุดข้อมูล CrUX ใน BigQuery
ฉันควรใช้ BigQuery แทนเครื่องมืออื่นๆ เมื่อใด
คุณต้องใช้ BigQuery เฉพาะในกรณีที่ไม่สามารถรับข้อมูลเดียวกันจากเครื่องมืออื่นๆ เช่น แดชบอร์ด CrUX และ PageSpeed Insights ตัวอย่างเช่น BigQuery ช่วยให้คุณแบ่งข้อมูลในลักษณะที่สื่อความหมายได้ และยังสามารถรวมข้อมูลเข้ากับชุดข้อมูลสาธารณะอื่นๆ เช่น HTTP Archive เพื่อทำการค้นหาข้อมูลขั้นสูงได้
การใช้ BigQuery มีข้อจํากัดไหม
ใช่ ข้อจำกัดที่สำคัญที่สุดคือโดยค่าเริ่มต้น ผู้ใช้จะค้นหาข้อมูลได้เพียง 1 TB ต่อเดือน เกินกว่านั้น ระบบจะใช้อัตรามาตรฐาน $5/TB
ฉันจะดูข้อมูลเพิ่มเติมเกี่ยวกับ BigQuery ได้จากที่ใด
ดูข้อมูลเพิ่มเติมได้ที่เอกสารประกอบของ BigQuery