


Na Chrome Dev Summit 2020, demonstramos pela primeira vez o suporte de depuração do Chrome para aplicativos do WebAssembly na Web. Desde então, a equipe tem investido muito para que a experiência do desenvolvedor seja escalonada para aplicativos grandes e até mesmo enormes. Neste post, vamos mostrar os controles que adicionamos (ou que funcionaram) nas diferentes ferramentas e como usá-los.
Depuração escalonável
Vamos retomar de onde paramos na nossa postagem de 2020. Confira o exemplo que analisamos na época:
#include <SDL2/SDL.h>
#include <complex>
int main() {
// Init SDL.
int width = 600, height = 600;
SDL_Init(SDL_INIT_VIDEO);
SDL_Window* window;
SDL_Renderer* renderer;
SDL_CreateWindowAndRenderer(width, height, SDL_WINDOW_OPENGL, &window,
&renderer);
// Generate a palette with random colors.
enum { MAX_ITER_COUNT = 256 };
SDL_Color palette[MAX_ITER_COUNT];
srand(time(0));
for (int i = 0; i < MAX_ITER_COUNT; ++i) {
palette[i] = {
.r = (uint8_t)rand(),
.g = (uint8_t)rand(),
.b = (uint8_t)rand(),
.a = 255,
};
}
// Calculate and draw the Mandelbrot set.
std::complex<double> center(0.5, 0.5);
double scale = 4.0;
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
std::complex<double> point((double)x / width, (double)y / height);
std::complex<double> c = (point - center) * scale;
std::complex<double> z(0, 0);
int i = 0;
for (; i < MAX_ITER_COUNT - 1; i++) {
z = z * z + c;
if (abs(z) > 2.0)
break;
}
SDL_Color color = palette[i];
SDL_SetRenderDrawColor(renderer, color.r, color.g, color.b, color.a);
SDL_RenderDrawPoint(renderer, x, y);
}
}
// Render everything we've drawn to the canvas.
SDL_RenderPresent(renderer);
// SDL_Quit();
}
Esse é um exemplo bastante pequeno, e provavelmente você não vai encontrar nenhum dos problemas reais que encontraria em um aplicativo muito grande, mas ainda podemos mostrar os novos recursos. É rápido e fácil de configurar e testar.
Na última postagem, discutimos como compilar e depurar esse exemplo. Vamos fazer isso de novo, mas vamos dar uma olhada no //performance//:
$ emcc -sUSE_SDL=2 -g -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH
Esse comando produz um binário wasm de 3 MB. E a maior parte disso, como você pode imaginar, são informações de depuração. Você pode verificar isso com a ferramenta llvm-objdump [1], por exemplo:
$ llvm-objdump -h mandelbrot.wasm
mandelbrot.wasm: file format wasm
Sections:
Idx Name Size VMA Type
0 TYPE 0000026f 00000000
1 IMPORT 00001f03 00000000
2 FUNCTION 0000043e 00000000
3 TABLE 00000007 00000000
4 MEMORY 00000007 00000000
5 GLOBAL 00000021 00000000
6 EXPORT 0000014a 00000000
7 ELEM 00000457 00000000
8 CODE 0009308a 00000000 TEXT
9 DATA 0000e4cc 00000000 DATA
10 name 00007e58 00000000
11 .debug_info 000bb1c9 00000000
12 .debug_loc 0009b407 00000000
13 .debug_ranges 0000ad90 00000000
14 .debug_abbrev 000136e8 00000000
15 .debug_line 000bb3ab 00000000
16 .debug_str 000209bd 00000000
Essa saída mostra todas as seções que estão no arquivo wasm gerado. A maioria delas é uma seção padrão do WebAssembly, mas há também várias seções personalizadas cujo nome começa com .debug_. É aí que o binário contém nossas informações de depuração. Se somarmos todos os tamanhos, veremos que as informações de depuração representam aproximadamente 2,3 MB do nosso arquivo de 3 MB. Se também time o comando emcc, vamos notar que na nossa máquina ele levou cerca de 1,5 segundo para ser executado. Esses números são uma boa referência, mas são tão pequenos que provavelmente ninguém os notaria. No entanto, em aplicativos reais, o binário de depuração pode facilmente alcançar um tamanho em GBs e levar minutos para ser criado.
Ignorar Binaryen
Ao criar um aplicativo wasm com Emscripten, uma das etapas finais de build é executar o otimizador Binaryen. O Binaryen é um kit de ferramentas de compilador que otimiza e legaliza binários do tipo WebAssembly. A execução do Binaryen como parte do build é bastante cara, mas só é necessária em determinadas condições. Para builds de depuração, podemos acelerar significativamente o tempo de build se evitarmos a necessidade de passagens de Binaryen. O uso mais comum do Binaryen é para legalizar assinaturas de função que envolvem valores inteiros de 64 bits. Ao ativar a integração do BigInt da WebAssembly usando -sWASM_BIGINT, podemos evitar isso.
$ emcc -sUSE_SDL=2 -g -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Adicionamos a flag -sERROR_ON_WASM_CHANGES_AFTER_LINK para garantir. Ele ajuda a detectar quando o Binaryen está sendo executado e reescrevendo o binário inesperadamente. Assim, podemos garantir que estamos no caminho rápido.
Embora nosso exemplo seja bastante pequeno, ainda podemos notar o efeito de pular o Binaryen. De acordo com time, esse comando é executado em menos de 1 segundo, ou seja, meio segundo mais rápido do que antes.
Ajustes avançados
Como pular a verificação de arquivos de entrada
Normalmente, ao vincular um projeto Emscripten, o emcc verifica todos os arquivos de objeto e as bibliotecas de entrada. Isso é feito para implementar dependências precisas entre funções de biblioteca JavaScript e símbolos nativos no programa. Para projetos maiores, essa verificação extra de arquivos de entrada (usando llvm-nm) pode aumentar significativamente o tempo de vinculação.
É possível executar com -sREVERSE_DEPS=all, que informa a emcc para incluir todas as dependências nativas possíveis de funções JavaScript. Isso tem uma pequena sobrecarga de tamanho de código, mas pode acelerar os tempos de vinculação e ser útil para builds de depuração.
Para um projeto tão pequeno quanto o nosso exemplo, isso não faz diferença, mas se você tiver centenas ou até milhares de arquivos de objeto no projeto, isso pode melhorar significativamente os tempos de vinculação.
Como remover a seção "name"
Em projetos grandes, especialmente aqueles com muito uso de modelos C++, a seção "name" do WebAssembly pode ser muito grande. No nosso exemplo, é apenas uma pequena fração do tamanho geral do arquivo (consulte a saída de llvm-objdump acima), mas, em alguns casos, pode ser muito significativo. Se a seção "name" do seu aplicativo for muito grande e as informações de depuração reduzidas forem suficientes para suas necessidades de depuração, pode ser vantajoso remover a seção "name":
$ emstrip --no-strip-all --remove-section=name mandelbrot.wasm
Isso remove a seção "name" do WebAssembly, preservando as seções de depuração DWARF.
Depurar fissão
Binários com muitos dados de depuração não apenas pressionam o tempo de build, mas também o tempo de depuração. O depurador precisa carregar os dados e criar um índice para eles, de modo que possa responder rapidamente a consultas, como "Qual é o tipo da variável local x?".
A fissão de depuração permite dividir as informações de depuração de um binário em duas partes: uma que permanece no binário e outra que está em um arquivo separado, chamado de objeto DWARF (.dwo). Ele pode ser ativado transmitindo a flag -gsplit-dwarf para o Emscripten:
$ emcc -sUSE_SDL=2 -g -gsplit-dwarf -gdwarf-5 -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Abaixo, mostramos os diferentes comandos e quais arquivos são gerados pela compilação sem dados de depuração, com dados de depuração e, por fim, com dados de depuração e divisão de depuração.
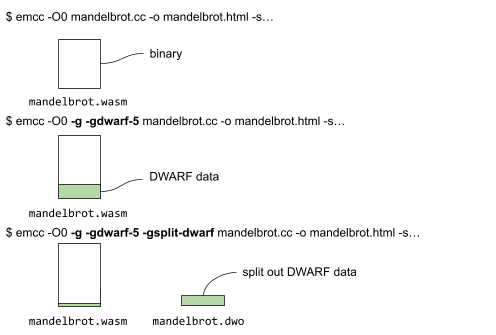
Ao dividir os dados DWARF, uma parte dos dados de depuração fica junto ao binário, enquanto a maior parte é colocada no arquivo mandelbrot.dwo (como ilustrado acima).
Para mandelbrot, temos apenas um arquivo de origem, mas geralmente os projetos são maiores e incluem mais de um arquivo. A depuração de fissão gera um arquivo .dwo para cada um deles. Para que a versão Beta atual do depurador (0.1.6.1615) possa carregar essas informações de depuração divididas, precisamos agrupar todas elas em um pacote chamado DWARF (.dwp), assim:
$ emdwp -e mandelbrot.wasm -o mandelbrot.dwp
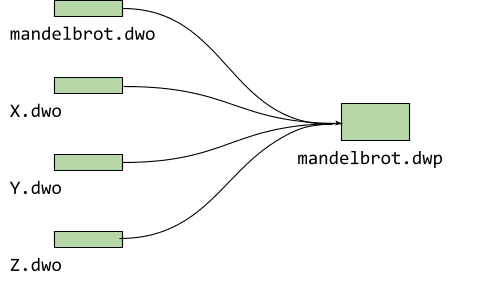
Criar o pacote DWARF com os objetos individuais tem a vantagem de que você só precisa fornecer um arquivo extra. No momento, estamos trabalhando para carregar todos os objetos individuais em uma versão futura.
O que há de novo no DWARF 5?
Você pode ter notado que inserimos outra flag no comando emcc acima, -gdwarf-5. Ativar a versão 5 dos símbolos DWARF, que atualmente não é o padrão, é outro truque para ajudar a iniciar a depuração mais rapidamente. Com ele, algumas informações são armazenadas no binário principal que a versão 4 padrão não incluiu. Especificamente, podemos determinar o conjunto completo de arquivos de origem apenas pelo binário principal. Isso permite que o depurador realize ações básicas, como mostrar a árvore de origem completa e definir pontos de interrupção sem carregar e analisar os dados de símbolo completos. Isso torna a depuração com símbolos divididos muito mais rápida. Por isso, sempre usamos as flags da linha de comando -gsplit-dwarf e -gdwarf-5 juntas.
Com o formato de depuração DWARF5, também temos acesso a outro recurso útil. Ele introduz um índice de nome nos dados de depuração que serão gerados ao transmitir a flag -gpubnames:
$ emcc -sUSE_SDL=2 -g -gdwarf-5 -gsplit-dwarf -gpubnames -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Durante uma sessão de depuração, as pesquisas de símbolos geralmente acontecem ao procurar uma entidade por nome, por exemplo, ao procurar uma variável ou um tipo. O índice de nomes acelera essa pesquisa apontando diretamente para a unidade de compilação que define esse nome. Sem um índice de nomes, seria necessária uma pesquisa exaustiva de todos os dados de depuração para encontrar a unidade de compilação correta que define a entidade nomeada que estamos procurando.
Para os curiosos: como analisar os dados de depuração
Você pode usar llvm-dwarfdump para conferir os dados DWARF. Vamos tentar o seguinte:
llvm-dwarfdump mandelbrot.wasm
Isso nos dá uma visão geral das "Unidades de compilação" (ou seja, os arquivos de origem) para as quais temos informações de depuração. Neste exemplo, só temos as informações de depuração para mandelbrot.cc. As informações gerais informam que temos uma unidade de esqueleto, o que significa que temos dados incompletos nesse arquivo e que há um arquivo .dwo separado que contém as informações de depuração restantes:

Você também pode conferir outras tabelas neste arquivo, como a tabela de linhas que mostra o mapeamento do bytecode do WASM para linhas C++ (tente usar llvm-dwarfdump -debug-line).
Também podemos conferir as informações de depuração contidas no arquivo .dwo separado:
llvm-dwarfdump mandelbrot.dwo

Resumo: qual é a vantagem de usar a divisão de depuração?
Há várias vantagens em dividir as informações de depuração se você estiver trabalhando com grandes aplicativos:
Vinculações mais rápidas: o vinculador não precisa mais analisar todas as informações de depuração. Os vinculadores geralmente precisam analisar todos os dados DWARF que estão no binário. Ao remover grandes partes das informações de depuração em arquivos separados, os vinculadores lidam com binários menores, o que resulta em tempos de vinculação mais rápidos (especialmente para aplicativos grandes).
Depuração mais rápida: o depurador pode pular a análise de símbolos adicionais em arquivos
.dwo/.dwppara algumas pesquisas de símbolo. Para algumas pesquisas (como solicitações no mapeamento de linha de arquivos wasm para C++), não precisamos analisar os dados de depuração adicionais. Isso economiza tempo, sem precisar carregar e analisar os dados de depuração adicionais.
1: se você não tiver uma versão recente do llvm-objdump no sistema e estiver usando o emsdk, ele estará no diretório emsdk/upstream/bin.
Fazer o download dos canais de visualização
Use o Chrome Canary, Dev ou Beta como navegador de desenvolvimento padrão. Esses canais de visualização dão acesso aos recursos mais recentes do DevTools, permitem testar APIs de plataforma da Web de última geração e ajudam a encontrar problemas no seu site antes dos usuários.
Entre em contato com a equipe do Chrome DevTools
Use as opções a seguir para discutir os novos recursos, atualizações ou qualquer outra coisa relacionada ao DevTools.
- Envie feedback e solicitações de recursos para crbug.com.
- Informe um problema do DevTools usando o Mais opções > Ajuda > Informar um problema do DevTools no DevTools.
- Envie um tweet para @ChromeDevTools.
- Deixe comentários nos vídeos Novidades do DevTools no YouTube ou Dicas do DevTools no YouTube.