

Необработанные данные Chrome UX Report ( CrUX ) доступны в BigQuery , базе данных в Google Cloud. Для использования BigQuery требуется проект GCP и базовые знания SQL.
В этом руководстве вы узнаете, как использовать BigQuery для написания запросов к набору данных CrUX с целью извлечения полезных результатов о состоянии пользовательского опыта в Интернете:
- Понять, как организованы данные
- Напишите базовый запрос для оценки производительности источника
- Напишите расширенный запрос для отслеживания производительности с течением времени
Организация данных
Начните с рассмотрения простого запроса:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
Чтобы выполнить запрос, введите его в редактор запросов и нажмите кнопку «Выполнить запрос»:
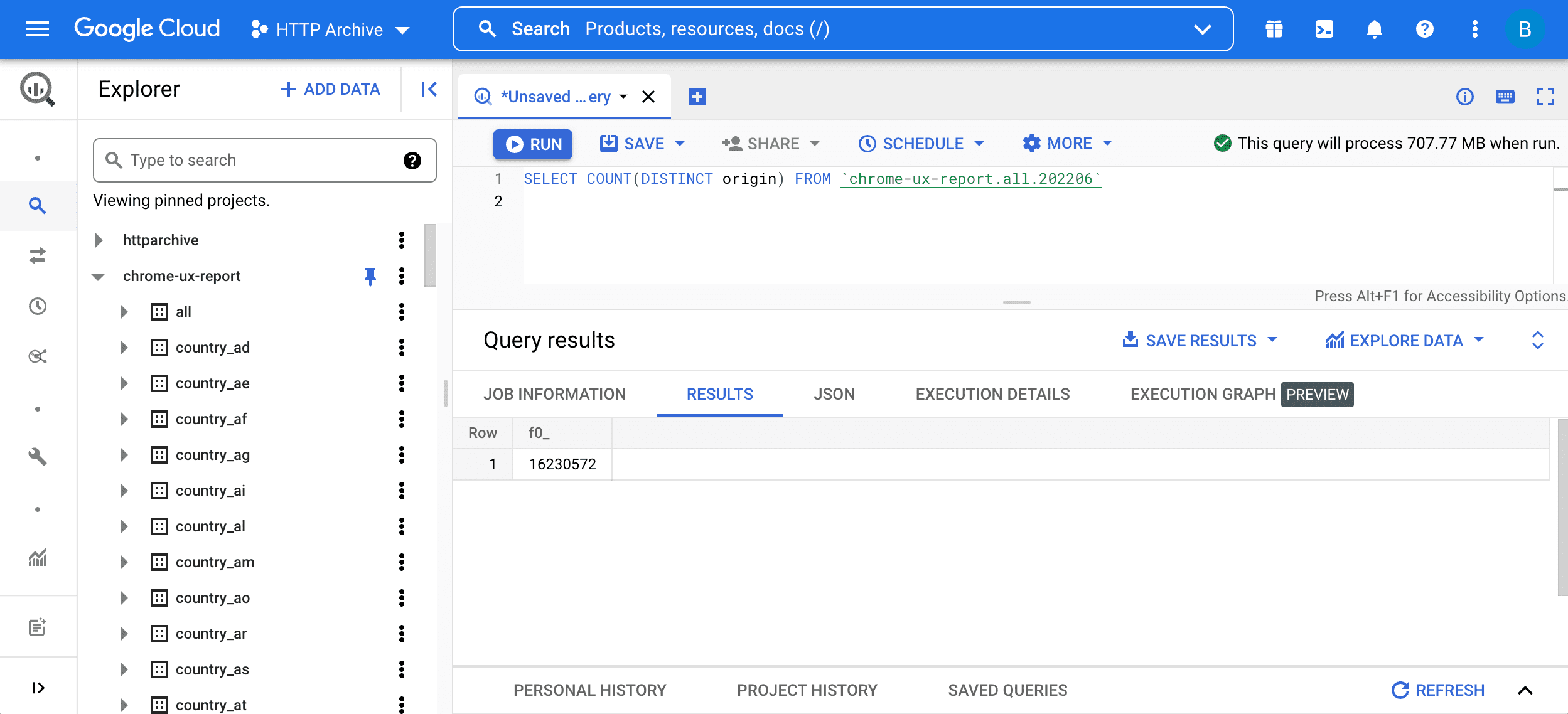
Этот запрос состоит из двух частей:
SELECT COUNT(DISTINCT origin)означает запрос количества источников в таблице. Грубо говоря, два URL являются частью одного источника, если они имеют одинаковую схему, хост и порт.FROM chrome-ux-report.all.202206указывает адрес исходной таблицы, которая состоит из трех частей:- Название облачного проекта
chrome-ux-reportв котором организованы все данные CrUX. - Набор данных
all, представляющий данные по всем странам - Таблица
202206, год и месяц данных в формате ГГГГММ
- Название облачного проекта
Также есть наборы данных для каждой страны. Например, chrome-ux-report.country_ca.202206 представляет только данные о пользовательском опыте из Канады.
В каждом наборе данных имеются таблицы за каждый месяц с 2017 года10. Регулярно публикуются новые таблицы за предыдущий календарный месяц.
Структура таблиц данных (также известная как схема ) содержит:
- Источник, например
origin = 'https://www.example.com', который представляет собой совокупное распределение пользовательского опыта для всех страниц на этом веб-сайте. - Скорость соединения на момент загрузки страницы, например,
effective_connection_type.name = '4G'( удалено с февраля 2025 г. ) - Тип устройства, например
form_factor.name = 'desktop' - Сами метрики UX
Данные для каждой метрики организованы как массив объектов. В нотации JSON first_contentful_paint.histogram.bin будет выглядеть примерно так:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
Каждый бин содержит начальное и конечное время в миллисекундах и плотность, представляющую процент пользовательских впечатлений в этом временном диапазоне. Другими словами, 12,34% впечатлений FCP для этого гипотетического источника, скорости соединения и типа устройства составляют менее 100 мс. Сумма всех плотностей бинов составляет 100%.
Просмотрите структуру таблиц в BigQuery.
Оценить производительность
Мы можем использовать наши знания схемы таблицы, чтобы написать запрос, который извлекает эти данные о производительности.
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
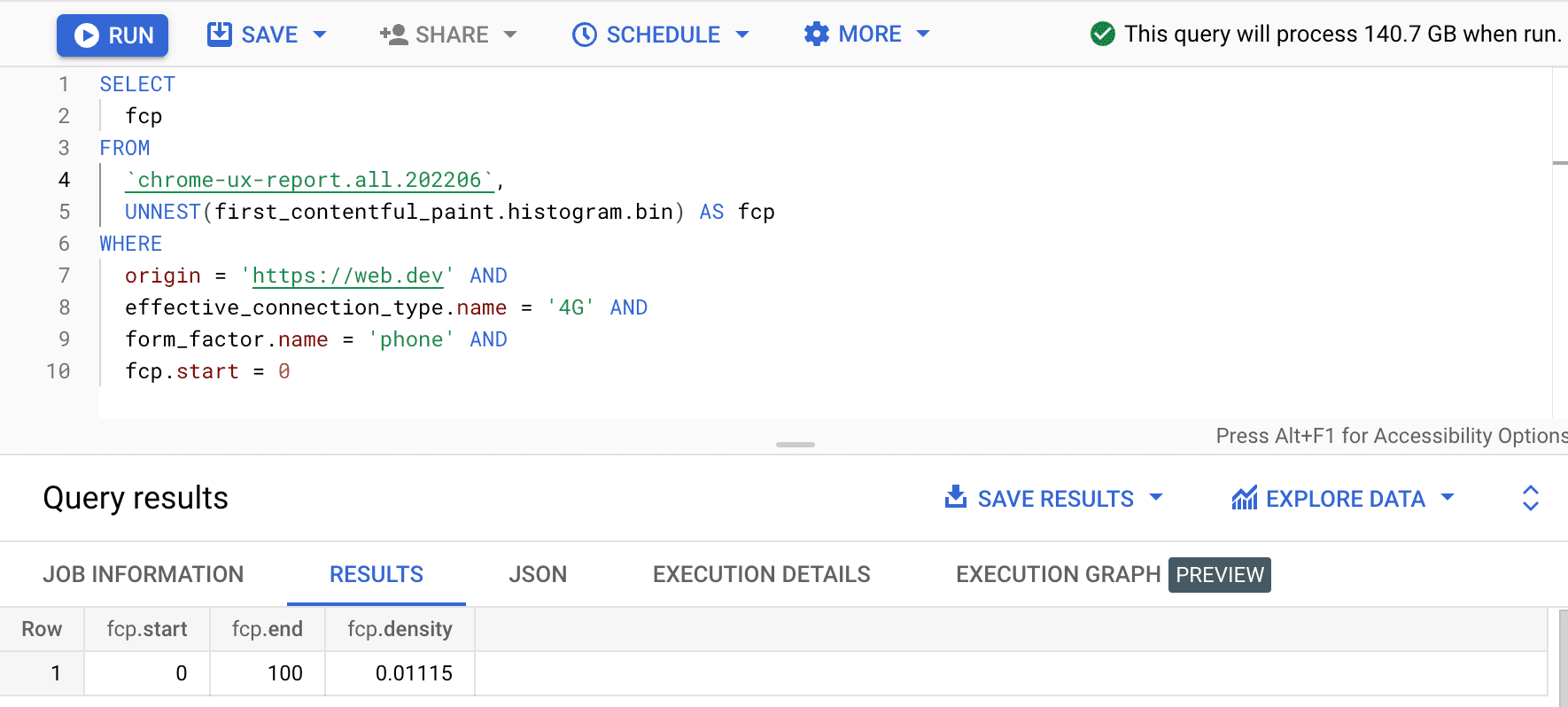
Результат равен 0.01115 , что означает, что 1,115% пользовательских впечатлений на этом источнике находятся в диапазоне от 0 до 100 мс на 4G и на телефоне. Если мы хотим обобщить наш запрос для любого соединения и любого типа устройства, мы можем исключить их из предложения WHERE и использовать функцию-агрегатор SUM для сложения всех их соответствующих плотностей ячеек:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
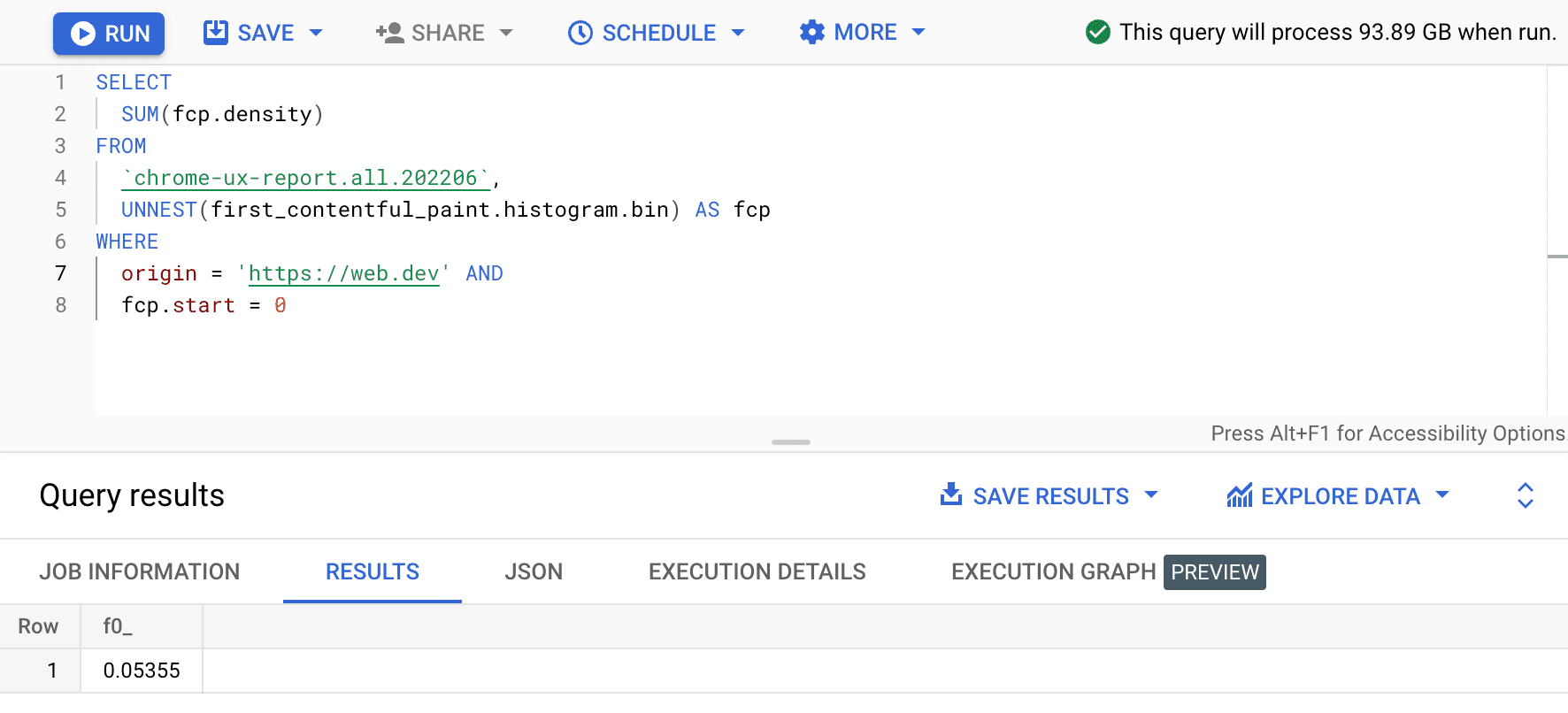
Результат — 0.05355 или 5,355% по всем устройствам и типам подключения. Мы можем немного изменить запрос и сложить плотности для всех бинов, которые находятся в «быстром» диапазоне FCP 0–1000 мс:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
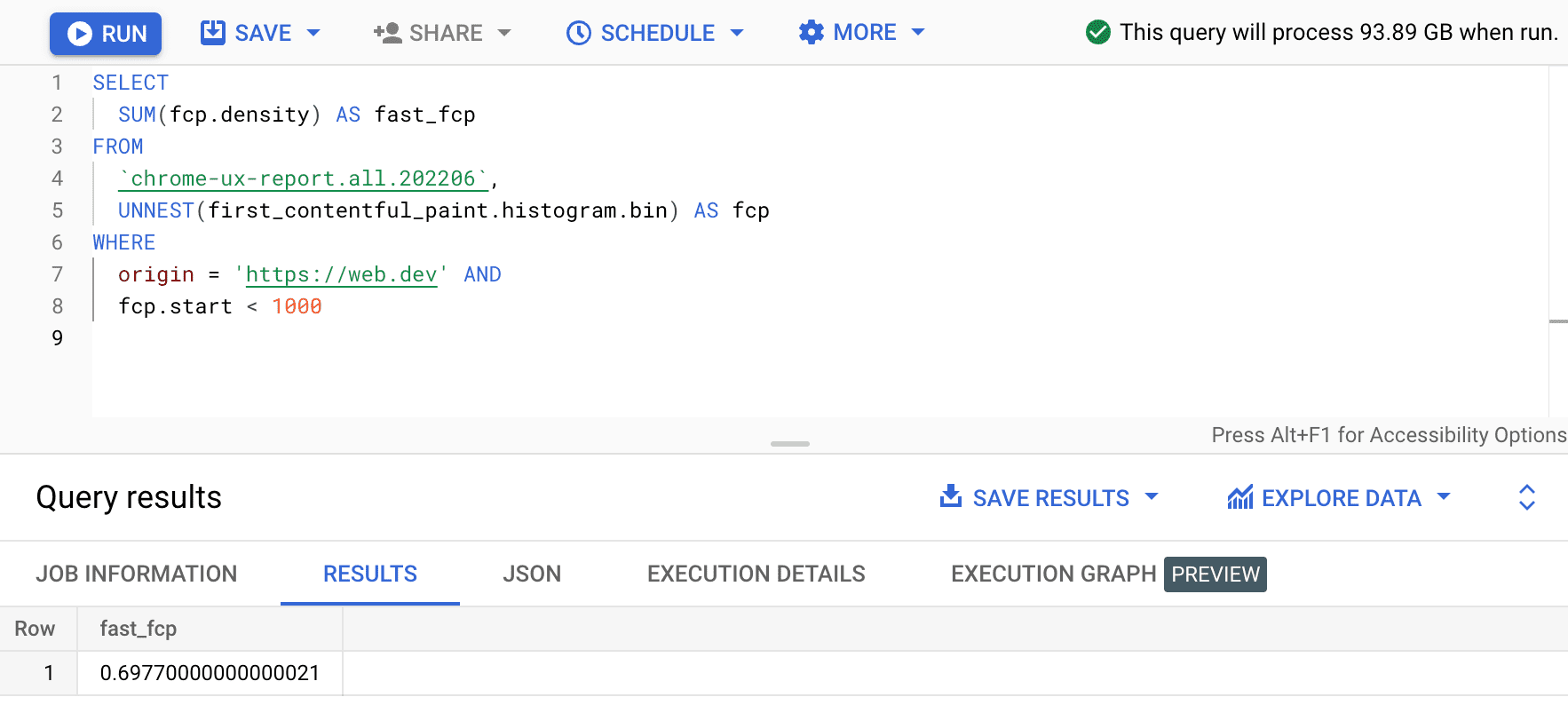
Это дает нам 0.6977 . Другими словами, 69,77% пользовательских впечатлений FCP на web.dev считаются «быстрыми» согласно определению диапазона FCP.
Отслеживать производительность
Теперь, когда мы извлекли данные о производительности источника, мы можем сравнить их с историческими данными, доступными в старых таблицах. Чтобы сделать это, мы могли бы переписать адрес таблицы на более ранний месяц или использовать синтаксис подстановочных знаков для запроса всех месяцев:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
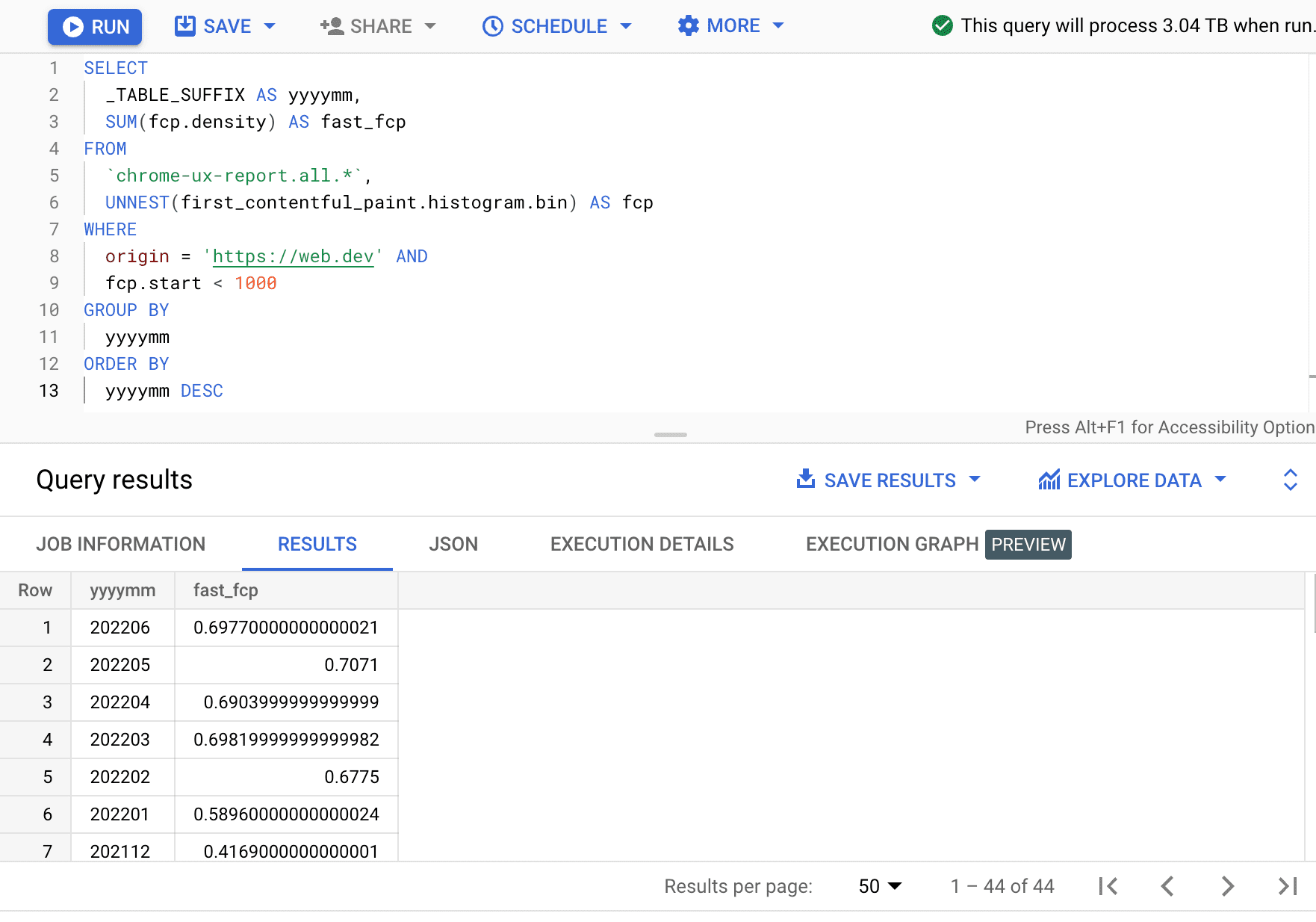
Здесь мы видим, что процент быстрых FCP-случаев меняется на несколько процентных пунктов каждый месяц.
| ггггмм | fast_fcp |
|---|---|
| 202206 | 69,77% |
| 202205 | 70,71% |
| 202204 | 69.04% |
| 202203 | 69,82% |
| 202202 | 67,75% |
| 202201 | 58,96% |
| 202112 | 41,69% |
| ... | ... |
С помощью этих методов вы можете найти производительность для источника, вычислить процент быстрых впечатлений и отслеживать его с течением времени. В качестве следующего шага попробуйте запросить два или более источника и сравнить их производительность.
Часто задаваемые вопросы
Вот некоторые из часто задаваемых вопросов о наборе данных CrUX BigQuery:
Когда следует использовать BigQuery, а не другие инструменты?
BigQuery нужен только тогда, когда вы не можете получить ту же информацию из других инструментов, таких как CrUX Dashboard и PageSpeed Insights. Например, BigQuery позволяет вам нарезать данные осмысленными способами и даже объединять их с другими общедоступными наборами данных, такими как HTTP Archive, для выполнения расширенного анализа данных.
Существуют ли какие-либо ограничения при использовании BigQuery?
Да, самое важное ограничение заключается в том, что по умолчанию пользователи могут запрашивать только 1 ТБ данных в месяц. За пределами этого применяется стандартная ставка $5/ТБ.
Где я могу узнать больше о BigQuery?
Более подробную информацию можно найти в документации BigQuery .