

Chrome UX रिपोर्ट (CrUX) का रॉ डेटा, Google Cloud के डेटाबेस BigQuery पर उपलब्ध है. BigQuery का इस्तेमाल करने के लिए, आपके पास GCP प्रोजेक्ट और एसक्यूएल की बुनियादी जानकारी होनी चाहिए.
इस गाइड में, CrUX डेटासेट के लिए क्वेरी लिखने के लिए, BigQuery का इस्तेमाल करने का तरीका जानें. इससे, आपको वेब पर उपयोगकर्ता अनुभव की स्थिति के बारे में अहम नतीजे मिलेंगे:
- डेटा को व्यवस्थित करने का तरीका समझना
- किसी ऑरिजिन की परफ़ॉर्मेंस का आकलन करने के लिए बुनियादी क्वेरी लिखना
- समय के साथ परफ़ॉर्मेंस को ट्रैक करने के लिए, बेहतर क्वेरी लिखना
डेटा को व्यवस्थित करना
सबसे पहले, एक बुनियादी क्वेरी देखें:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
क्वेरी चलाने के लिए, उसे क्वेरी एडिटर में डालें और "क्वेरी चलाएं" बटन दबाएं:
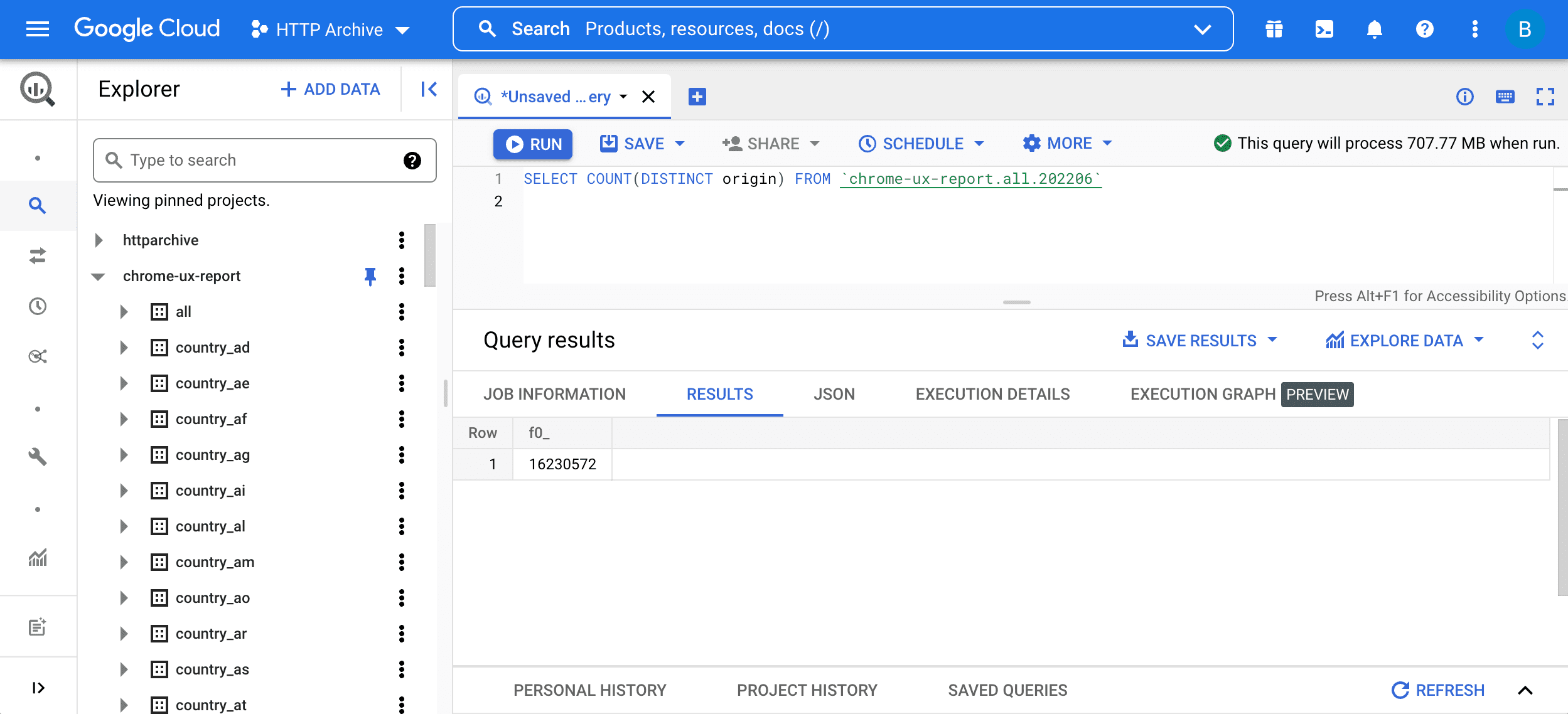
इस क्वेरी के दो हिस्से हैं:
SELECT COUNT(DISTINCT origin)का मतलब है कि टेबल में ऑरिजिन की संख्या के लिए क्वेरी की जा रही है. अगर दो यूआरएल का स्कीम, होस्ट, और पोर्ट एक जैसा है, तो वे एक ही ऑरिजिन के हिस्से हैं.FROM chrome-ux-report.all.202206, सोर्स टेबल का पता बताता है. इसमें तीन हिस्से होते हैं:- क्लाउड प्रोजेक्ट का नाम
chrome-ux-report, जिसमें CrUX का सारा डेटा व्यवस्थित किया गया है - डेटासेट
all, जिसमें सभी देशों का डेटा दिखाया गया है - टेबल
202206, YYYYMM फ़ॉर्मैट में डेटा का साल और महीना
- क्लाउड प्रोजेक्ट का नाम
हर देश के लिए डेटासेट भी उपलब्ध हैं. उदाहरण के लिए, chrome-ux-report.country_ca.202206 सिर्फ़ कनाडा से मिले उपयोगकर्ता अनुभव का डेटा दिखाता है.
हर डेटासेट में, 201710 से हर महीने की टेबल होती हैं. पिछले कैलेंडर महीने की नई टेबल, नियमित रूप से पब्लिश की जाती हैं.
डेटा टेबल के स्ट्रक्चर (इसे स्कीमा भी कहा जाता है) में ये शामिल होते हैं:
- ऑरिजिन, उदाहरण के लिए
origin = 'https://www.example.com', जो उस वेबसाइट के सभी पेजों के लिए उपयोगकर्ता अनुभव के कुल डिस्ट्रिब्यूशन को दिखाता है - पेज लोड होने के समय कनेक्शन की स्पीड, उदाहरण के लिए,
effective_connection_type.name = '4G'(फ़रवरी 2025 से हटाया गया) - डिवाइस का टाइप, जैसे कि
form_factor.name = 'desktop' - यूज़र एक्सपीरियंस की मेट्रिक खुद ही
हर मेट्रिक का डेटा, ऑब्जेक्ट के कलेक्शन के तौर पर व्यवस्थित किया जाता है. JSON नोटेशन में, first_contentful_paint.histogram.bin इस तरह दिखेगा:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
हर बाइन में, शुरू और खत्म होने का समय मिलीसेकंड में होता है. साथ ही, उस समयसीमा में उपयोगकर्ता अनुभव के प्रतिशत को दिखाने वाली डेंसिटी भी होती है. दूसरे शब्दों में, इस काल्पनिक ऑरिजिन, कनेक्शन स्पीड, और डिवाइस टाइप के लिए, 12.34% एफ़सीपी अनुभव 100 मिलीसेकंड से कम के हैं. सभी बिन डेंसिटी का कुल योग 100% होता है.
BigQuery में टेबल का स्ट्रक्चर ब्राउज़ करें.
परफ़ॉर्मेंस का आकलन करें
टेबल स्कीमा के बारे में अपनी जानकारी का इस्तेमाल करके, हम ऐसी क्वेरी लिख सकते हैं जो इस परफ़ॉर्मेंस डेटा को निकालती है.
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
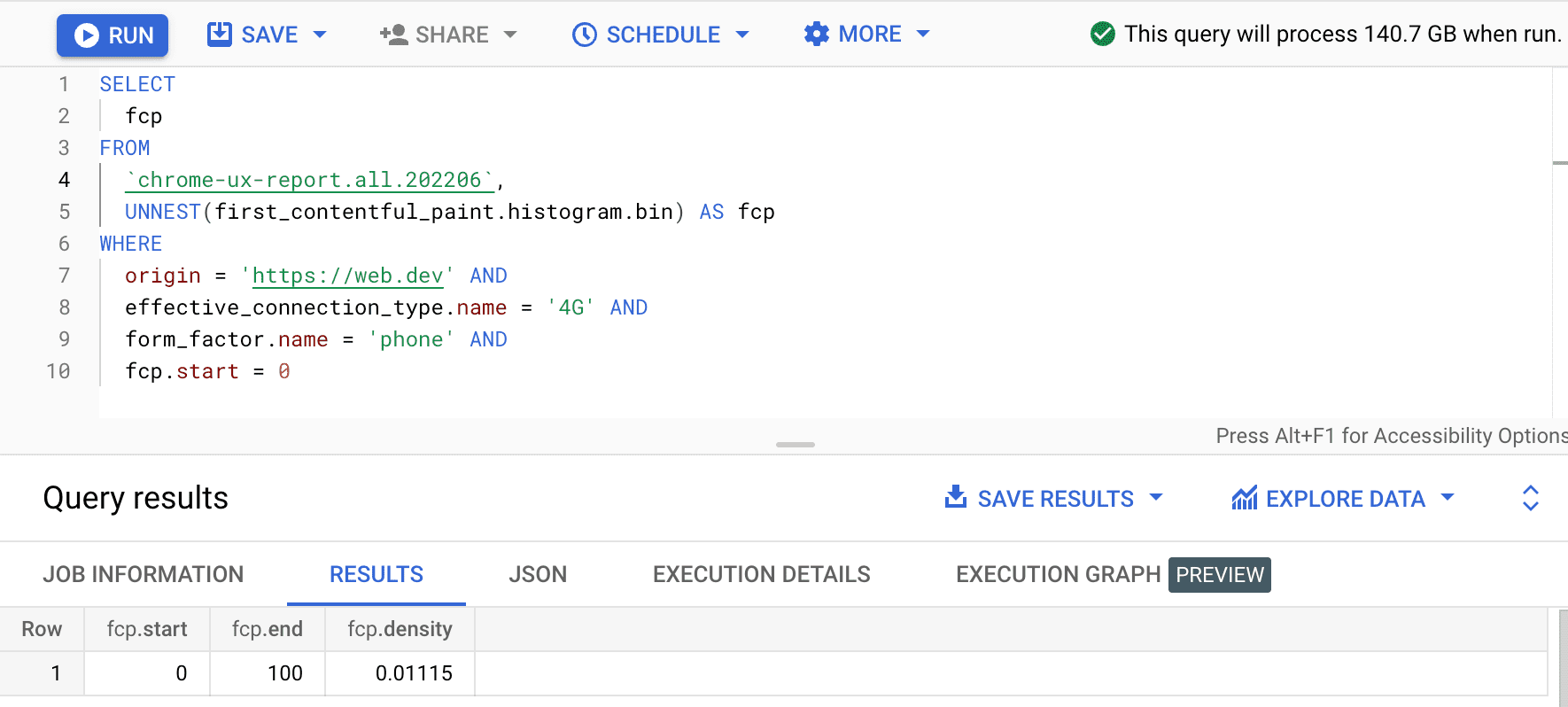
इसका नतीजा 0.01115 है. इसका मतलब है कि इस ऑरिजिन पर, 4G और फ़ोन पर 1.115% उपयोगकर्ताओं के अनुभव 0 से 100 मिलीसेकंड के बीच हैं. अगर हमें अपनी क्वेरी को किसी भी कनेक्शन और किसी भी तरह के डिवाइस के लिए सामान्य बनाना है, तो हम उन्हें WHERE क्लॉज़ से हटा सकते हैं. साथ ही, उनके सभी बाइन डेंसिटी को जोड़ने के लिए, SUM एग्रीगेटर फ़ंक्शन का इस्तेमाल कर सकते हैं:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
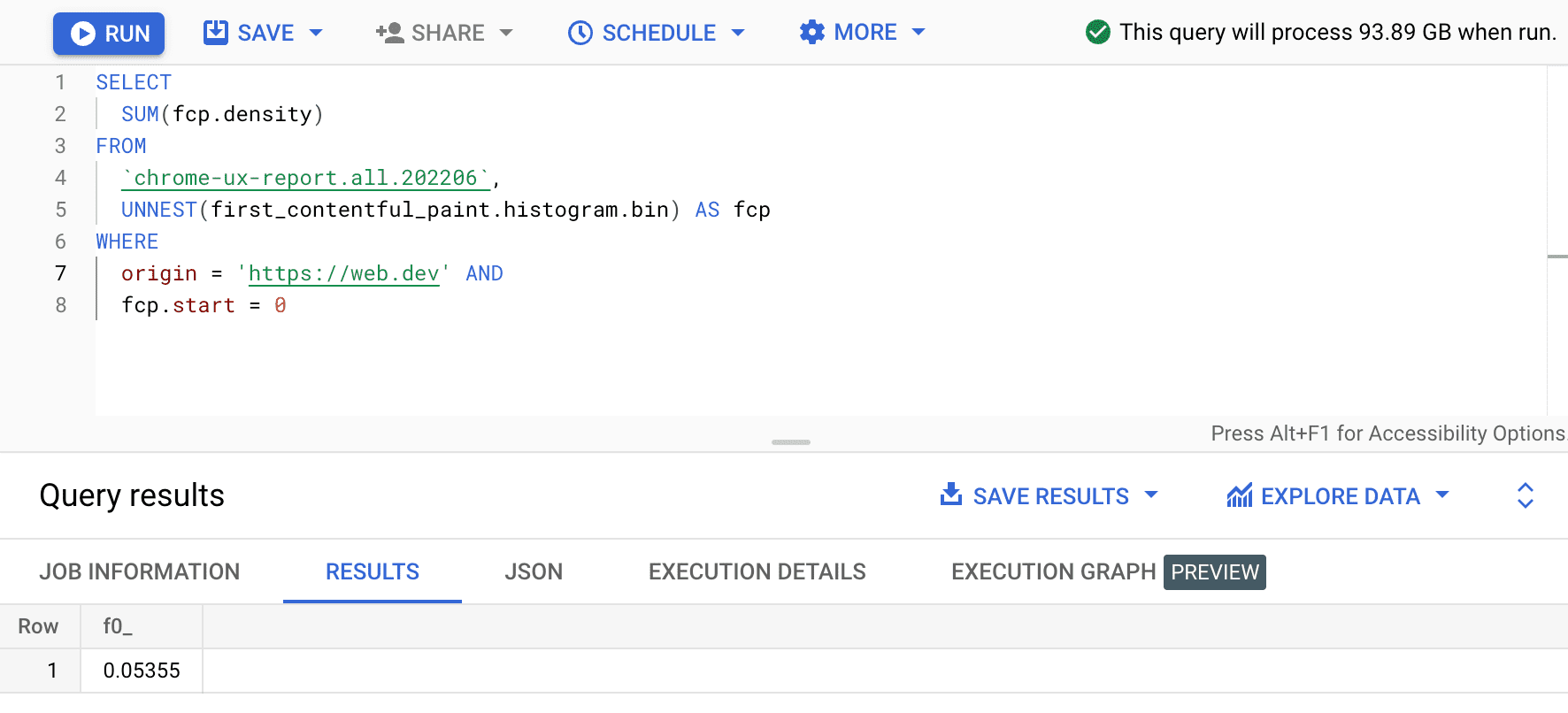
इसका नतीजा 0.05355 या सभी डिवाइसों और कनेक्शन टाइप के लिए 5.355% है. हम क्वेरी में थोड़ा बदलाव करके, उन सभी बाइन के लिए डेंसिटी जोड़ सकते हैं जो 0 से 1000 मिलीसेकंड की "फ़ास्ट" एफ़सीपी रेंज में हैं:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
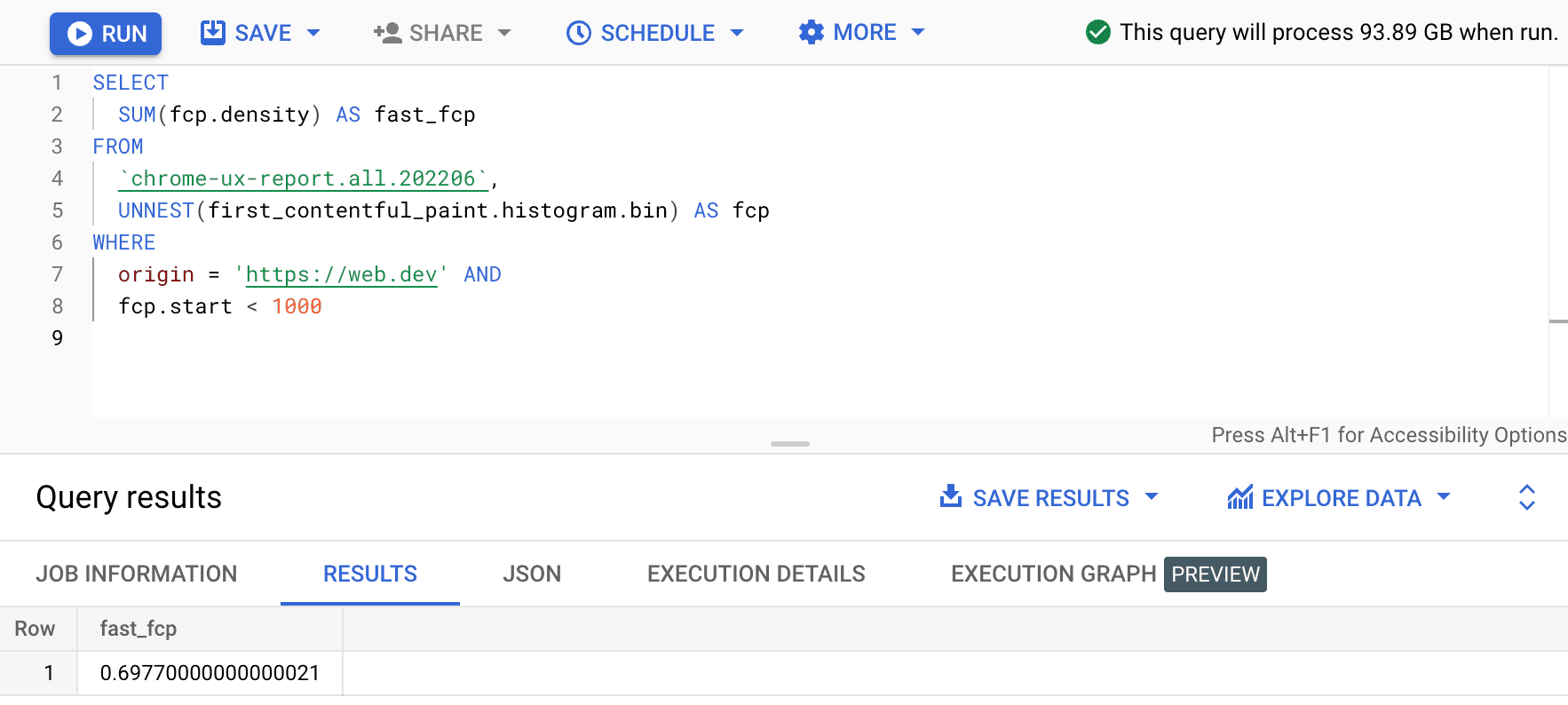
इससे हमें 0.6977 मिलता है. दूसरे शब्दों में, FCP रेंज की परिभाषा के मुताबिक, web.dev पर 69.77% एफ़सीपी उपयोगकर्ता अनुभव को "तेज़" माना जाता है.
परफ़ॉर्मेंस ट्रैक करना
अब हमने किसी ऑरिजिन की परफ़ॉर्मेंस का डेटा निकाल लिया है. अब हम इसकी तुलना पुरानी टेबल में मौजूद पुराने डेटा से कर सकते हैं. ऐसा करने के लिए, हम टेबल के पते को किसी पिछले महीने में फिर से लिख सकते हैं. इसके अलावा, सभी महीनों के लिए क्वेरी करने के लिए, वाइल्डकार्ड सिंटैक्स का इस्तेमाल किया जा सकता है:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
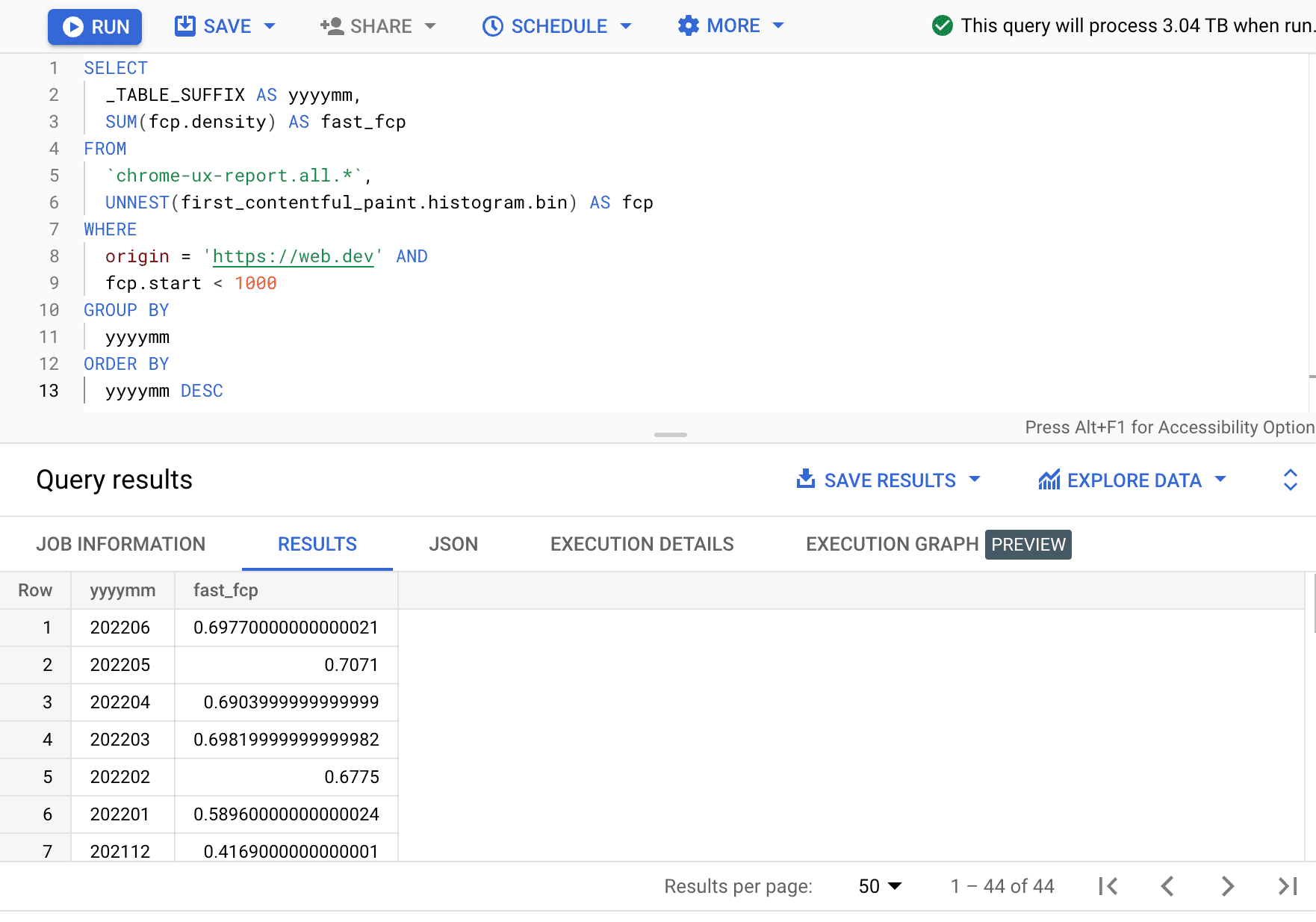
यहां हम देखते हैं कि फ़ास्ट एफ़सीपी के अनुभव का प्रतिशत, हर महीने कुछ प्रतिशत पॉइंट तक बदलता रहता है.
| yyyymm | fast_fcp |
|---|---|
| 202206 | 69.77% |
| 202205 | 70.71% |
| 202204 | 69.04% |
| 202203 | 69.82% |
| 202202 | 67.75% |
| 202201 | 58.96% |
| 202112 | 41.69% |
| ... | ... |
इन तकनीकों की मदद से, किसी ऑरिजिन की परफ़ॉर्मेंस देखी जा सकती है. साथ ही, तेज़ी से लोड होने वाले अनुभवों का प्रतिशत कैलकुलेट किया जा सकता है और समय के साथ उसे ट्रैक किया जा सकता है. अगले चरण के तौर पर, दो या उससे ज़्यादा ऑरिजिन के लिए क्वेरी करने और उनकी परफ़ॉर्मेंस की तुलना करने की कोशिश करें.
अक्सर पूछे जाने वाले सवाल
CrUX के BigQuery डेटासेट के बारे में अक्सर पूछे जाने वाले कुछ सवाल यहां दिए गए हैं:
मुझे अन्य टूल के बजाय, BigQuery का इस्तेमाल कब करना चाहिए?
BigQuery की ज़रूरत सिर्फ़ तब होती है, जब आपको CrUX डैशबोर्ड और PageSpeed Insights जैसे अन्य टूल से वही जानकारी नहीं मिल पाती. उदाहरण के लिए, BigQuery की मदद से डेटा को काम के तरीके से काटा जा सकता है. साथ ही, डेटा माइनिंग के बेहतर तरीके अपनाने के लिए, HTTP Archive जैसे अन्य सार्वजनिक डेटासेट के साथ भी डेटा को जोड़ा जा सकता है.
क्या BigQuery का इस्तेमाल करने की कोई सीमा है?
हां, सबसे अहम सीमा यह है कि डिफ़ॉल्ट रूप से, उपयोगकर्ता हर महीने सिर्फ़ 1 टीबी डेटा के लिए क्वेरी कर सकते हैं. इसके बाद, 5 डॉलर/टीबी की स्टैंडर्ड दर लागू होगी.
मुझे BigQuery के बारे में ज़्यादा जानकारी कहां मिलेगी?
ज़्यादा जानकारी के लिए, BigQuery दस्तावेज़ देखें.