
検索エンジンが検索結果に表示させないのは、そのページが検索結果に含まれていない場合 検索エンジンのクローラによるインデックス登録を明示的にブロックする。一部の HTTP ヘッダーとメタ タグは、ページをインデックスに登録してはいけないことをクローラーに伝えます。
検索結果に表示させたくないコンテンツについてのみ、インデックス登録をブロックします。
Lighthouse のインデックス登録監査が失敗する仕組み
Lighthouse でページにフラグを設定 検索エンジンがインデックスに登録できないもの:
Lighthouse では、すべての検索エンジンをブロックしているヘッダーや要素のみがチェックされます。
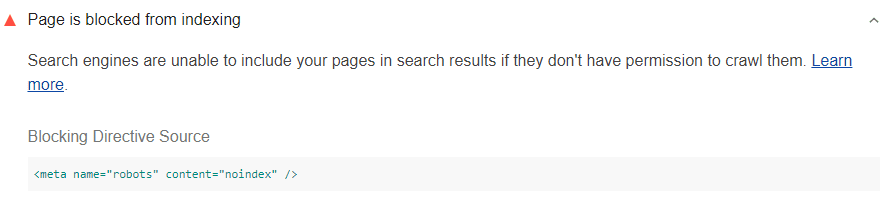
制限します。たとえば、以下の <meta> 要素では、すべての検索エンジンを禁止しています
クローラ(ロボットとも呼ばれます)によるページへのアクセスをブロックする
<meta name="robots" content="noindex"/>
また、この HTTP レスポンス ヘッダーはすべてのクローラーをブロックします。
X-Robots-Tag: noindex
また、次のような特定のクローラーをブロックする <meta> 要素が含まれている場合もあります。
<meta name="Googlebot" content="noindex"/>
Lighthouse では、このようなクローラー固有のディレクティブの監査が不合格になることはありませんが、 ただし、ページが見つかりにくくなるため、使用する際は十分に注意してください。Lighthouse は クローラー固有のディレクティブが一般的なインデックス登録 bot をブロックしている場合に警告が表示されます。
検索エンジンがページをクロールできるようにする方法
まず、検索エンジンがページをインデックス登録するように設定していることを確認します。たとえば サイトマップ 法律上のコンテンツである場合、通常はインデックスに登録すべきではありません。(ブロックは ユーザーがページの URL を知っていれば、インデックス登録によってページにアクセスできなくなることはありません)。
インデックス登録するページの HTTP ヘッダーまたは <meta> 要素をすべて削除します
ブロックしているコンテンツを特定しますサイトの設定方法によっては
以下の手順の一部またはすべてを行う必要があります。
- HTTP を設定する場合は、
X-Robots-TagHTTP レスポンス ヘッダーを削除します。 レスポンス ヘッダー:
X-Robots-Tag: noindex
- ページの head 内に次のメタタグがある場合は、削除します。
<meta name="robots" content="noindex">
- 特定のクローラーをブロックするメタタグが 表示します。例:
<meta name="Googlebot" content="noindex">
管理を強化する(省略可)
検索エンジンによるページのインデックス登録をより詳細に管理したい場合、たとえば Google による画像のインデックス登録は望まないが、ページの残りの部分は必要な場合 表示されます。
<meta> 要素と HTTP の構成方法については、
ヘッダーについては、次のガイドをご覧ください。
リソース
- 「ページのインデックス登録がブロックされています」監査のソースコード
- Google の Robots メタタグと X-Robots-Tag HTTP ヘッダーの仕様
- Bing の Robots メタタグ
- Yandex の HTML 要素の使用