

公開日: 2025 年 10 月 10 日

クラシックなボードゲームである「Guess Who?」は、演繹的推論の傑作です。各プレーヤーは顔のボードから始め、一連の質問に「はい」または「いいえ」で答えることで、相手の秘密のキャラクターを特定できるまで可能性を絞り込んでいきます。
Google I/O Connect で 組み込み AI のデモを見た後、ブラウザに存在する AI と「Who is it?」ゲームをプレイできたらどうなるだろうかと思いました。クライアントサイド AI を使用すると、写真はローカルで解釈されるため、友人や家族のカスタム Guess Who? はデバイス上で非公開かつ安全に保たれます。
私は主に UI と UX の開発に携わってきたため、ピクセル単位で完璧なエクスペリエンスを構築することに慣れています。私の解釈でまさにそれを実現できればと思っていました。
私のアプリ「AI Guess Who?」は React で構築されており、Prompt API とブラウザの組み込みモデルを使用して、驚くほど有能な対戦相手を作成します。このプロセスで、完璧な結果を得ることはそれほど簡単ではないことがわかりました。ただし、このアプリケーションは、AI を使用して思慮深いゲームロジックを構築する方法と、このロジックを洗練して期待どおりの結果を得るためのプロンプト エンジニアリングの重要性を示しています。
この記事では、組み込みの AI 統合、直面した課題、最終的に採用したソリューションについて説明します。ゲームをプレイしたり、GitHub でソースコードを確認したりできます。
ゲームの基盤: React アプリ
AI の実装を確認する前に、アプリケーションの構造を確認します。TypeScript を使用して標準の React アプリケーションを構築しました。中央の App.tsx ファイルはゲームのコンダクターとして機能します。このファイルには次のものが含まれています。
- ゲームの状態: ゲームの現在のフェーズ(
PLAYER_TURN_ASKING、AI_TURN、GAME_OVERなど)を追跡する列挙型。これは、インターフェースに表示される内容と、プレーヤーが利用できるアクションを決定するため、最も重要な状態です。 - キャラクター リスト: アクティブなキャラクター、各プレーヤーの秘密のキャラクター、ボードから除外されたキャラクターを指定する複数のリストがあります。
- ゲームチャット: 質問、回答、システム メッセージの実行ログ。
インターフェースは、次の論理コンポーネントに分割されます。

ゲームの機能が増えるにつれて、複雑さも増していきました。当初、ゲームのロジック全体は 1 つの大きなカスタム React フック useGameLogic 内で管理されていましたが、すぐにナビゲーションとデバッグが困難になるほど大きくなりました。保守性を高めるため、このフックを複数のフックにリファクタリングしました。各フックは単一の責任を持ちます。次に例を示します。
useGameStateがコア状態を管理するusePlayerActionsはプレーヤーのターンuseAIActionsは AI のロジック用です
メインの useGameLogic フックは、これらの小さなフックをまとめて配置するクリーンなコンポーザーとして機能するようになりました。このアーキテクチャの変更により、ゲームの機能は変更されませんでしたが、コードベースが大幅にクリーンになりました。
Prompt API を使用したゲーム ロジック
このプロジェクトの中核は Prompt API の使用です。
builtInAIService.ts に AI ゲームロジックを追加しました。主な責任は次のとおりです。
- 制限的な二項回答を許可します。
- モデルにゲーム戦略を教えます。
- モデル分析を教える。
- モデルに健忘症を与えます。
制限付きの二項回答を許可する
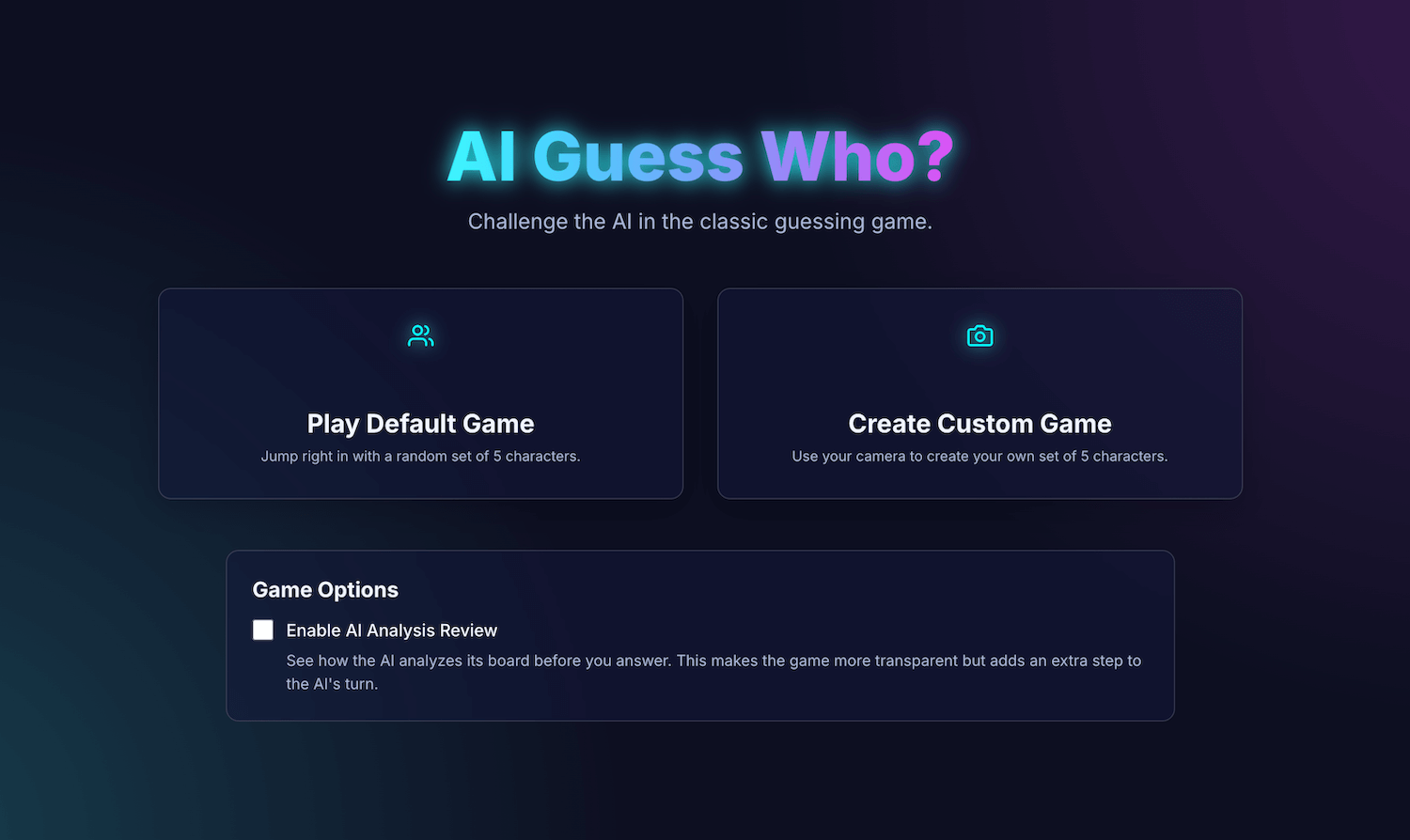
プレイヤーは AI とどのようにやり取りしますか?プレーヤーが「あなたのキャラクターは帽子をかぶっていますか?」と尋ねた場合、AI は秘密のキャラクターの画像を「見て」、明確な答えを返す必要があります。
最初の試みはひどいものでした。回答が会話調だった。「いいえ、私が考えているイザベラというキャラクターは帽子をかぶっていないようです」というように、二者択一の「はい」または「いいえ」を提示するのではなく、会話調で回答していました。当初、私は非常に厳格なプロンプトを使用してこの問題を解決しました。これは、モデルに「はい」または「いいえ」のみで応答するように指示するものでした。
この方法でもうまくいきましたが、構造化された出力を使用するさらに優れた方法があることを知りました。JSON スキーマをモデルに提供することで、true または false のレスポンスを保証できました。
const schema = { type: "boolean" };
const result = session.prompt(prompt, { responseConstraint: schema });
これにより、プロンプトを簡素化し、コードでレスポンスを確実に処理できるようになりました。
JSON.parse(result) ? "Yes" : "No"
モデルにゲーム戦略を教える
モデルに質問に答えるよう指示する方が、モデルに質問を開始して尋ねさせるよりもはるかに簡単です。「Guess Who?」の優れたプレイヤーは、ランダムな質問をしません。一度に最も多くの文字を削除する質問をします。理想的な質問では、二択の質問を使用して、残りの文字の可能性を半分に減らします。
モデルにその戦略をどのように教えますか?プロンプト エンジニアリングも同様です。generateAIQuestion() のプロンプトは、実際には「Guess Who?」ゲーム理論の簡潔なレッスンです。
最初は、「良い質問をして」とモデルに指示しました。結果は予測できませんでした。結果を改善するために、負の制約を追加しました。プロンプトには、次のような手順が含まれるようになりました。
- 「重要: 既存の機能についてのみ質問してください」
- 「重大: オリジナリティのある作品にします。質問を繰り返さないでください。」
これらの制約により、モデルの焦点が絞られ、無関係な質問をすることがなくなるため、より楽しい対戦相手になります。GitHub で完全なプロンプト ファイルを確認できます。
モデル分析を教える
これは、これまでで最も困難で重要な課題でした。モデルが「あなたのキャラクターは帽子をかぶっていますか?」などの質問をし、プレーヤーが「いいえ」と答えた場合、モデルはボード上のどのキャラクターが除外されたかをどのように認識するのですか?
モデルは帽子をかぶっている人をすべて除外する必要があります。初期の試みでは論理エラーが頻発し、モデルが誤った文字を削除したり、文字を削除しなかったりすることがありました。また、「帽子」とは何ですか?「ビーニー」は「帽子」としてカウントされますか?これは、正直に言うと、人間同士の議論でも起こりうることです。もちろん、一般的な間違いも発生します。AI の観点から見ると、髪の毛は帽子のように見えることがあります。
認識とコード推論を分離するようにアーキテクチャを再設計しました。
AI が視覚分析を担当します。モデルは視覚分析に優れています。モデルに、質問と詳細な分析を厳密な JSON スキーマで返すよう指示しました。モデルはボード上の各文字を分析し、「この文字にこの特徴があるか?」という質問に答えます。モデルは構造化された JSON オブジェクトを返します。
{ "character_id": "...", "has_feature": true }ここでも、構造化データが成功の鍵となります。
ゲームコードは分析を使用して最終的な判断を行います。アプリケーション コードは、プレーヤーの回答(「はい」または「いいえ」)をチェックし、AI の分析を反復処理します。プレーヤーが「いいえ」と答えた場合、コードは
has_featureがtrueであるすべての文字を削除します。
この分業は、信頼性の高い AI アプリケーションを構築するうえで重要です。AI を分析機能に使用し、バイナリの決定はアプリケーション コードに任せます。
モデルの認識を確認するために、この分析の可視化を構築しました。これにより、モデルの認識が正しいかどうかを簡単に確認できるようになりました。
プロンプト エンジニアリング
しかし、このように分離しても、モデルの認識に欠陥があることに気づきました。キャラクターがメガネをかけているかどうかを誤って判断し、誤った削除につながる可能性があります。この問題を解決するため、私は 2 段階のプロセスを試しました。AI が質問をします。プレーヤーの回答を受け取ると、回答をコンテキストとして使用して、2 回目の新しい分析を実行します。2 回目の確認で 1 回目のエラーを検出できるという考え方です。
このフローの仕組みは次のとおりです。
- AI のターン(API 呼び出し 1): AI が「あなたのキャラクターにはひげがありますか?」と質問します。
- プレーヤーの番: プレーヤーは、ひげを剃った秘密のキャラクターを見て、「いいえ」と答えます。
- AI のターン(API 呼び出し 2): AI は、残りのすべての文字をもう一度確認し、プレーヤーの回答に基づいてどの文字を削除するかを判断します。
ステップ 2 では、ユーザーが期待したにもかかわらず、モデルが薄いひげのある人物を「ひげがない」と誤認識し、その人物を削除できないことがあります。根本的な認識エラーは修正されず、追加の手順によって結果が遅れただけでした。人間を相手にプレイする場合は、この点について合意や説明を求めることができますが、現在の AI を相手にする設定では、そうではありません。
このプロセスでは、2 回目の API 呼び出しによるレイテンシが追加されましたが、精度は大幅に向上しませんでした。モデルが最初に間違っていた場合、2 回目も間違っていることがよくありました。プロンプトを 1 回だけ確認するように戻しました。
分析を追加するのではなく改善する
私は UX の原則に頼りました。その原則とは、解決策は分析の量を増やすことではなく、分析の質を高めることであるというものです。
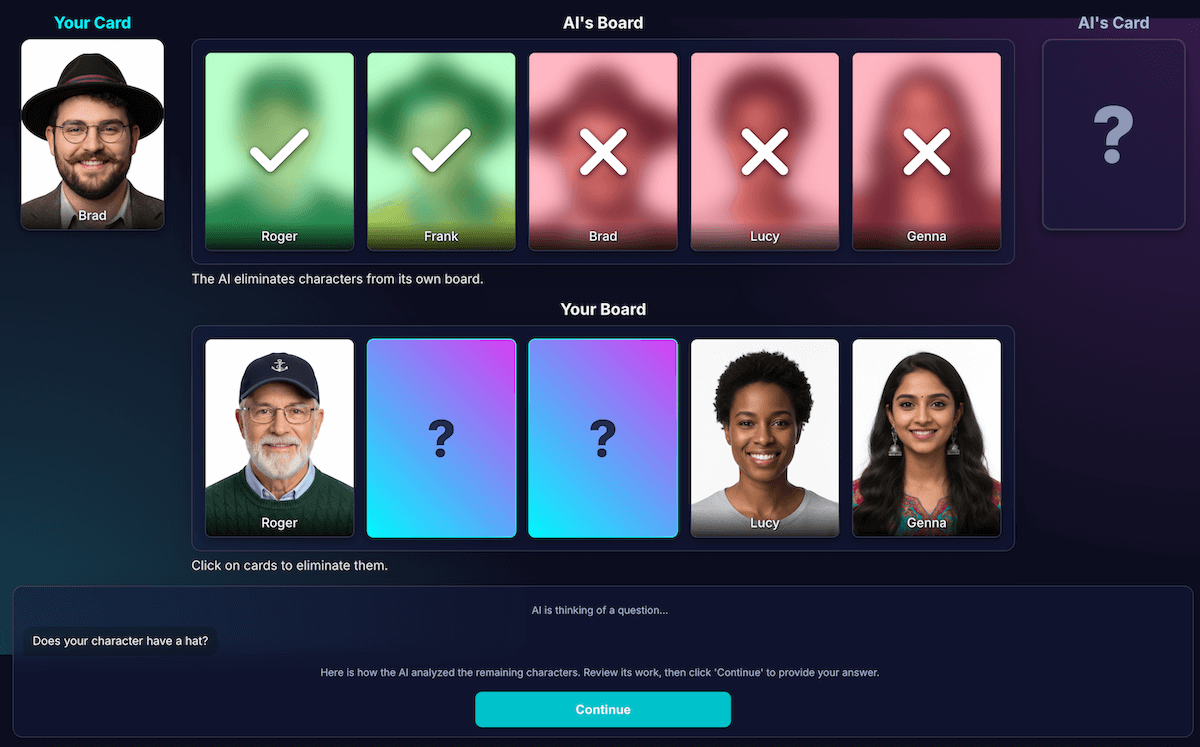
プロンプトの調整に力を入れ、モデルが作業を再確認して明確な特徴に焦点を当てるよう明示的な指示を追加しました。これは、精度を高めるためのより効果的な戦略であることがわかりました。現在の信頼性の高いフローの仕組みは次のとおりです。
AI ターン(API 呼び出し): モデルは、質問と内部分析の両方を同時に生成するように求められ、単一の JSON オブジェクトを返します。
- 質問: 「あなたのキャラクターはメガネをかけていますか?」
- 分析(データ):
[ {character_id: 'brad', has_feature: true}, {character_id: 'alex', has_feature: false}, {character_id: 'gina', has_feature: true}, ... ]プレイヤーの番: プレイヤーの秘密のキャラクターは Alex(メガネなし)なので、「いいえ」と答えます。
ラウンドの終了: アプリケーションの JavaScript コードが引き継ぎます。AI に他のことを尋ねる必要はありません。ステップ 1 の分析データを反復処理します。
- プレーヤーが「いいえ」と答えた場合。
- このコードは、
has_featureが true のすべての文字を検索します。 - ブラッドとジーナが下を向きます。ロジックは決定的で、瞬時に実行されます。
このテストは非常に重要でしたが、多くの試行錯誤が必要でした。良くなるかどうかはわかりませんでした。さらに悪化することもありました。最も一貫した結果を得る方法を特定することは、正確な科学ではありません(まだ、今後もそうかもしれません)。
しかし、新しい AI 対戦相手と数回対戦した後、新たな問題が発生しました。それは、引き分けです。
デッドロックを回避する
非常に類似した文字が 2、3 文字残った場合、モデルはループに陥ります。「あなたのキャラクターは帽子をかぶっていますか?」など、全員が共有する特徴について質問します。
私のコードはこれを無駄なターンとして正しく識別し、AI は「あなたのキャラクターはメガネをかけていますか?」など、キャラクターがすべて共有する同様に幅広い別の特徴を試します。
質問の生成試行が失敗し、残りの文字数が 3 文字以下になった場合、戦略を変更するという新しいルールを追加して、プロンプトを強化しました。
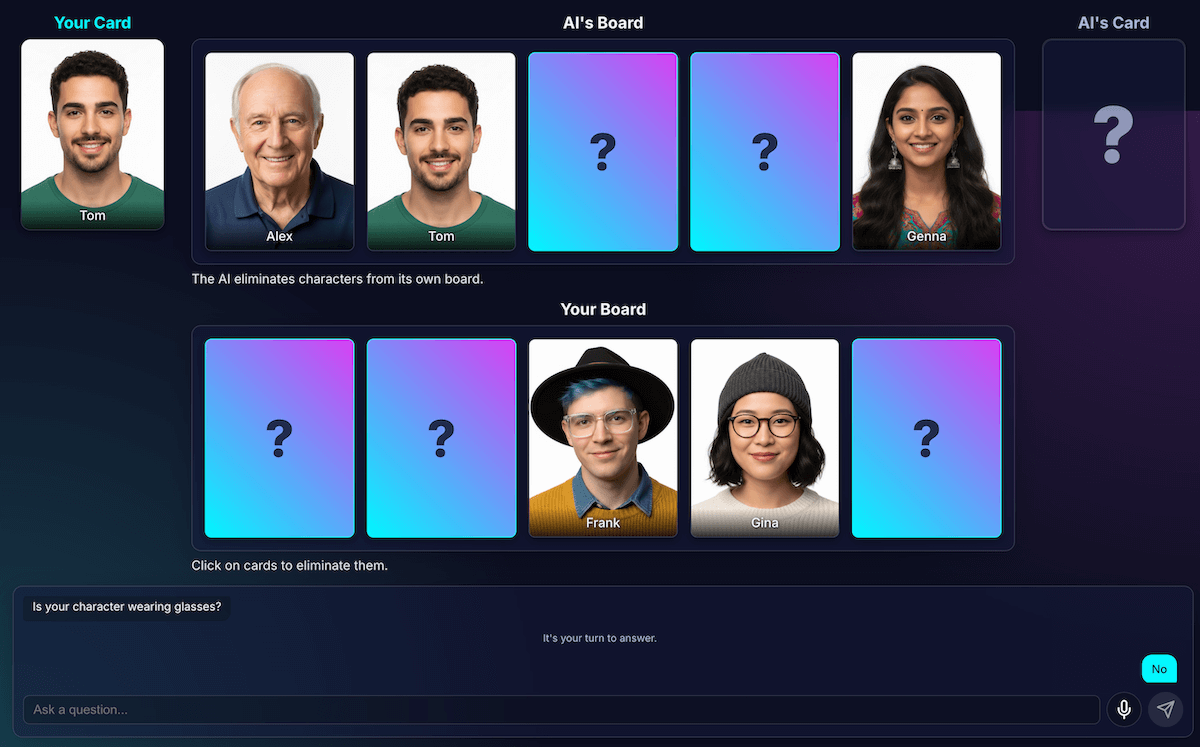
新しい指示は明確です。「広範な特徴ではなく、より具体的でユニークな、または複合的な視覚的特徴について尋ね、違いを見つける必要があります。」たとえば、人物が帽子をかぶっているかどうかを尋ねるのではなく、野球帽をかぶっているかどうかを尋ねるように促されます。
これにより、モデルは画像をより詳細に調べて、最終的にブレークスルーにつながる小さな詳細を見つける必要があり、ほとんどの場合、終盤の戦略が少しうまく機能します。
モデルに健忘症を与える
言語モデルの最大の強みは、その記憶力です。しかし、このゲームでは、その最大の強みが弱点になってしまいました。2 回目のゲームを開始すると、混乱を招く質問や無関係な質問が返ってきました。もちろん、スマート AI の対戦相手は前回のゲームのチャット履歴全体を保持していました。2 つ(またはそれ以上)のゲームを同時に理解しようとしていました。
同じ AI セッションを再利用する代わりに、各ゲームの終了時に明示的に破棄し、AI に健忘症を発生させています。
[もう一度プレイ] をクリックすると、startNewGameSession() 関数がボードをリセットし、新しい AI セッションを作成します。これは、アプリ内だけでなく、AI モデル自体でセッションの状態を管理するうえで興味深い教訓となりました。
便利な機能: カスタムゲームと音声入力
より魅力的な体験を提供するために、次の 2 つの機能を追加しました。
カスタム キャラクター:
getUserMedia()を使用すると、カメラを使って独自の 5 文字セットを作成できます。IndexedDB を使用して文字を保存しました。これは、画像 blob などのバイナリデータの保存に最適なブラウザ データベースです。カスタム セットを作成すると、ブラウザに保存され、メインメニューにリプレイ オプションが表示されます。音声入力: クライアントサイド モデルはマルチモーダルです。テキスト、画像、音声も処理できます。MediaRecorder API を使用してマイク入力をキャプチャし、「次の音声を文字起こしして...」というプロンプトで、結果の音声 BLOB をモデルに渡すことができました。これにより、楽しい遊び方が追加されます(また、私のフラマン語のアクセントがどのように解釈されるかを確認する楽しい方法も追加されます)。このデモは、主にこの新しいウェブ機能の汎用性を示すために作成しましたが、正直なところ、質問を何度も入力するのにうんざりしていました。
デモ
ここで直接ゲームをテストするか、新しいウィンドウでプレイして、GitHub でソースコードを確認できます。
最後に
「AI Guess Who?」の構築は間違いなく困難なものでした。ただし、ドキュメントを読み、AI をデバッグする AI(はい... 楽しい実験になりました。ブラウザでモデルを実行して、プライベートで高速な、インターネット接続を必要としないエクスペリエンスを作成する大きな可能性が示されました。これはまだ試験運用中であり、対戦相手が常に完璧なプレイをするとは限りません。ピクセル単位で完璧でも、論理的に完璧でもありません。生成 AI の場合、結果はモデルに依存します。
完璧を目指すのではなく、結果の改善を目指します。
このプロジェクトでは、プロンプト エンジニアリングの課題が常に存在することも浮き彫りになりました。プロンプトが大きな部分を占めるようになり、必ずしも楽しい部分とは言えなくなりました。しかし、私が学んだ最も重要な教訓は、認識と推論を分離し、AI とコードの機能を分割するようにアプリケーションを設計することでした。分離しても、AI は(人間にとって)明らかな間違いを犯すことがわかりました。たとえば、タトゥーをメイクと混同したり、誰の秘密のキャラクターが議論されているのかを把握できなくなったりします。
そのたびに、プロンプトをさらに明確にし、人間にとっては当たり前のように思えるものの、モデルにとっては不可欠な指示を追加することで解決しました。
不公平だと感じられることもありました。コードでその情報が明示的に共有されていないにもかかわらず、AI が秘密の文字を事前に「知っている」ように感じることがありました。これは、人間と機械の重要な部分を示しています。
AI の動作は正しいだけでなく、公平であると感じられる必要があります。
そのため、「私が選んだキャラクターはわかりません」や「ズルはしないでください」など、率直な指示を含むようにプロンプトを更新しました。AI エージェントを構築する際は、指示よりも制限事項の定義に時間をかけるべきだと学びました。
モデルとのやり取りは引き続き改善される可能性があります。組み込みモデルを使用すると、大規模なサーバーサイド モデルの能力と信頼性は低下しますが、プライバシー、速度、オフライン機能が向上します。このようなゲームでは、このトレードオフを試す価値は十分にありました。クライアントサイド AI の未来は日々進化しており、モデルも小型化が進んでいます。今後、どのようなものが構築されるのかが楽しみです。