

Parliamo di... architettura?
Tratterò un argomento importante, ma potenzialmente frainteso: l'architettura che utilizzi per la tua app web e, in particolare, come le tue decisioni architetturali entrano in gioco quando crei un'app web progressiva.
Il termine "architettura" può sembrare vago e potrebbe non essere immediatamente chiaro perché è importante. Un modo per pensare all'architettura è porsi le seguenti domande: quando un utente visita una pagina del mio sito, quale HTML viene caricato? E poi, cosa viene caricato quando visita un'altra pagina?
Le risposte a queste domande non sono sempre semplici e, una volta che inizi a pensare alle PWA, possono diventare ancora più complicate. Il mio obiettivo è quindi quello di illustrarti un'architettura possibile che ho trovato efficace. In questo articolo, etichetterò le decisioni che ho preso come "il mio approccio " alla creazione di un'app web progressiva.
Puoi utilizzare il mio approccio quando crei la tua PWA, ma allo stesso tempo esistono sempre altre alternative valide. Spero che vedere come si incastrano tutti i pezzi ti ispiri e ti dia la possibilità di personalizzare il modello in base alle tue esigenze.
PWA di Stack Overflow
Per accompagnare questo articolo, ho creato una PWA di Stack Overflow. Passo molto tempo a leggere e contribuire a Stack Overflow e volevo creare un'app web che rendesse facile sfogliare le domande frequenti su un determinato argomento. È basato sull'API Stack Exchange pubblica. È open source e puoi saperne di più visitando il progetto GitHub.
App multipagina (MPA)
Prima di entrare nei dettagli, definiamo alcuni termini e spieghiamo alcuni aspetti della tecnologia sottostante. Per prima cosa, parlerò di quelle che mi piace chiamare "app multipagina" o "MPA".
MPA è un nome elegante per l'architettura tradizionale utilizzata fin dagli inizi del web. Ogni volta che un utente passa a un nuovo URL, il browser esegue il rendering progressivo dell'HTML specifico per quella pagina. Non viene effettuato alcun tentativo di preservare lo stato della pagina o i contenuti tra le navigazioni. Ogni volta che visiti una nuova pagina, ricominci da capo.
Ciò è in contrasto con il modello di app a una sola pagina (SPA) per la creazione di app web, in cui il browser esegue il codice JavaScript per aggiornare la pagina esistente quando l'utente visita una nuova sezione. Sia le SPA che le MPA sono modelli ugualmente validi da utilizzare, ma per questo post volevo esplorare i concetti di PWA nel contesto di un'app multipagina.
Affidabile e veloce
Avrai sentito me (e innumerevoli altre persone) usare l'espressione "app web progressiva" o PWA. Potresti già avere familiarità con alcuni dei materiali di base, disponibili altrove su questo sito.
Puoi considerare una PWA come un'app web che offre un'esperienza utente di prima classe e che merita davvero un posto nella schermata Home dell'utente. L'acronimo "FIRE", che sta per Fast, Integrated, Reliable e Engaging, riassume tutti gli attributi da considerare quando crei una PWA.
In questo articolo mi concentrerò su un sottoinsieme di questi attributi: Veloce e Affidabile.
Veloce:sebbene "veloce" abbia significati diversi a seconda dei contesti, mi concentrerò sui vantaggi in termini di velocità del caricamento del minor numero possibile di elementi dalla rete.
Affidabile: ma la velocità pura non è sufficiente. Per essere considerata una PWA, la tua app web deve essere affidabile. Deve essere abbastanza resiliente da caricare sempre qualcosa, anche se si tratta solo di una pagina di errore personalizzata, indipendentemente dallo stato della rete.
Affidabile e veloce:infine, riformulerò leggermente la definizione di PWA e vedremo cosa significa creare qualcosa di affidabile e veloce. Non è sufficiente essere veloci e affidabili solo quando si è su una rete a bassa latenza. Essere affidabilmente veloce significa che la velocità della tua app web è costante, indipendentemente dalle condizioni di rete sottostanti.
Tecnologie abilitanti: service worker + API Cache Storage
Le PWA introducono uno standard elevato per velocità e resilienza. Fortunatamente, la piattaforma web offre alcuni componenti di base per rendere questo tipo di prestazioni una realtà. Mi riferisco ai service worker e all'API Cache Storage.
Puoi creare un service worker che ascolta le richieste in arrivo, passando alcune alla rete e memorizzando una copia della risposta per un utilizzo futuro tramite l'API Cache Storage.
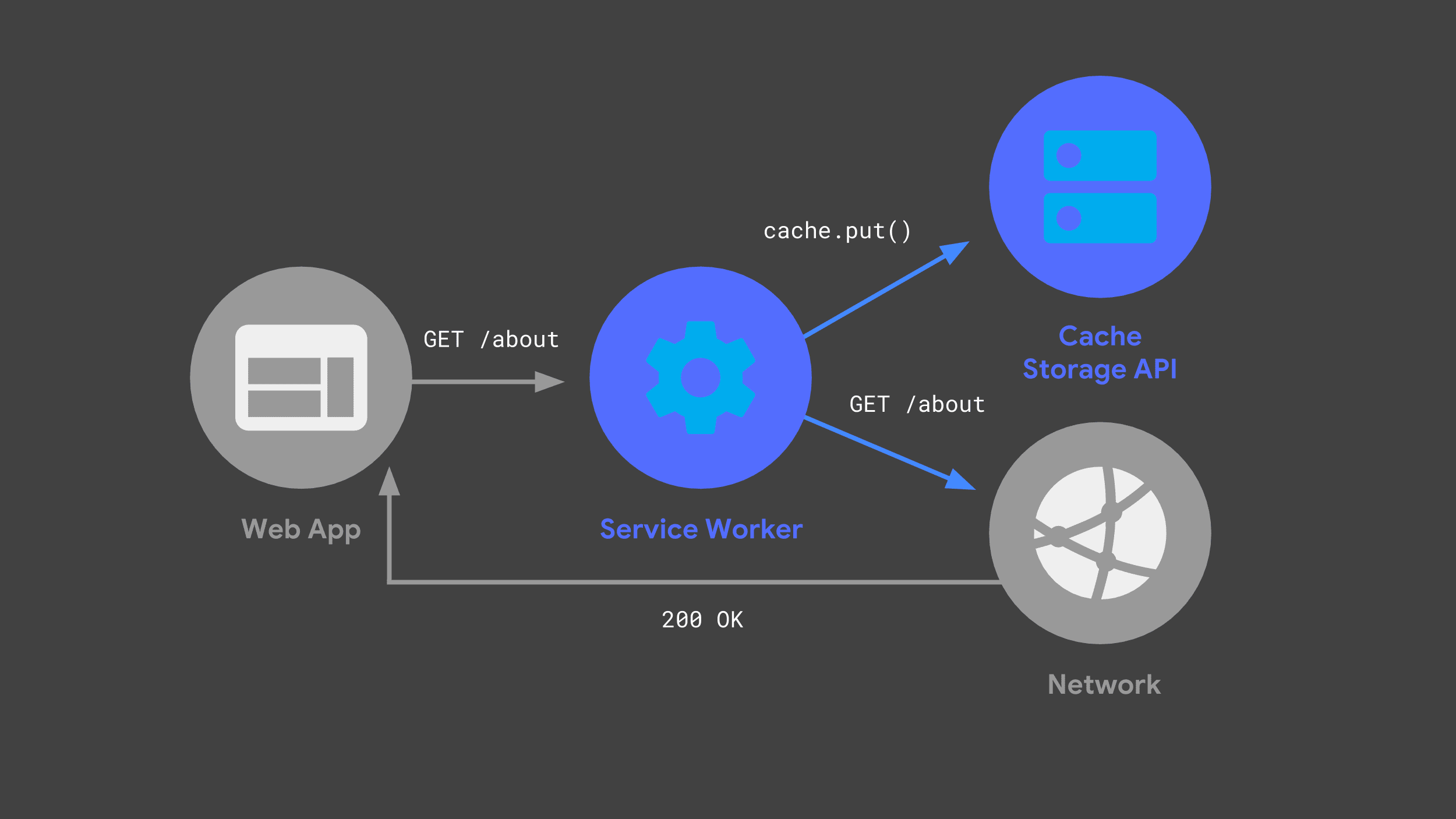
La volta successiva che l'app web effettua la stessa richiesta, il service worker può controllare le sue cache e restituire la risposta memorizzata nella cache in precedenza.
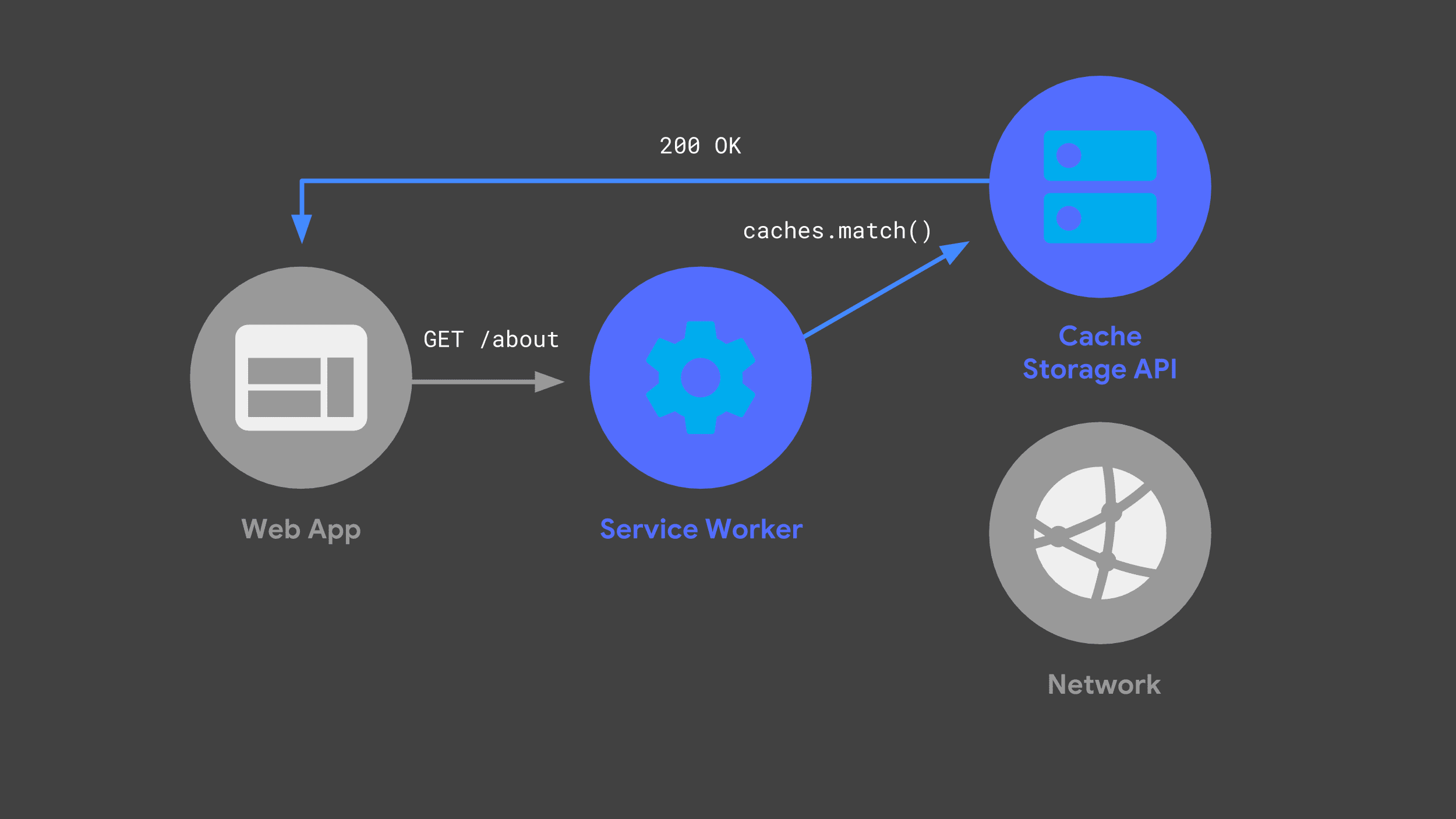
Evitare la rete, quando possibile, è fondamentale per offrire prestazioni affidabili e veloci.
JavaScript "isomorfo"
Un altro concetto che voglio trattare è quello che a volte viene chiamato JavaScript "isomorfo" o "universale". In parole semplici, è l'idea che lo stesso codice JavaScript possa essere condiviso tra diversi ambienti di runtime. Quando ho creato la mia PWA, volevo condividere il codice JavaScript tra il mio server di backend e il service worker.
Esistono molti approcci validi per condividere il codice in questo modo, ma il mio
approccio è stato quello di utilizzare i moduli ES come
codice sorgente definitivo. Poi ho eseguito la transpilazione e il bundling di questi moduli per il server e il service worker utilizzando una combinazione di Babel e Rollup. Nel mio progetto,
i file con estensione .mjs sono codice che si trova in un modulo ES.
Il server
Tenendo a mente questi concetti e questa terminologia, vediamo come ho creato la mia PWA di Stack Overflow. Inizierò parlando del nostro server di backend e spiegherò come si inserisce nell'architettura complessiva.
Stavo cercando una combinazione di un backend dinamico e un hosting statico e il mio approccio è stato quello di utilizzare la piattaforma Firebase.
Firebase Cloud Functions avvia automaticamente un ambiente basato su Node quando riceve una richiesta e si integra con il popolare framework HTTP Express, che già conoscevo. Offre anche hosting preconfigurato per tutte le risorse statiche del mio sito. Vediamo come il server gestisce le richieste.
Quando un browser effettua una richiesta di navigazione al nostro server, segue il seguente flusso:
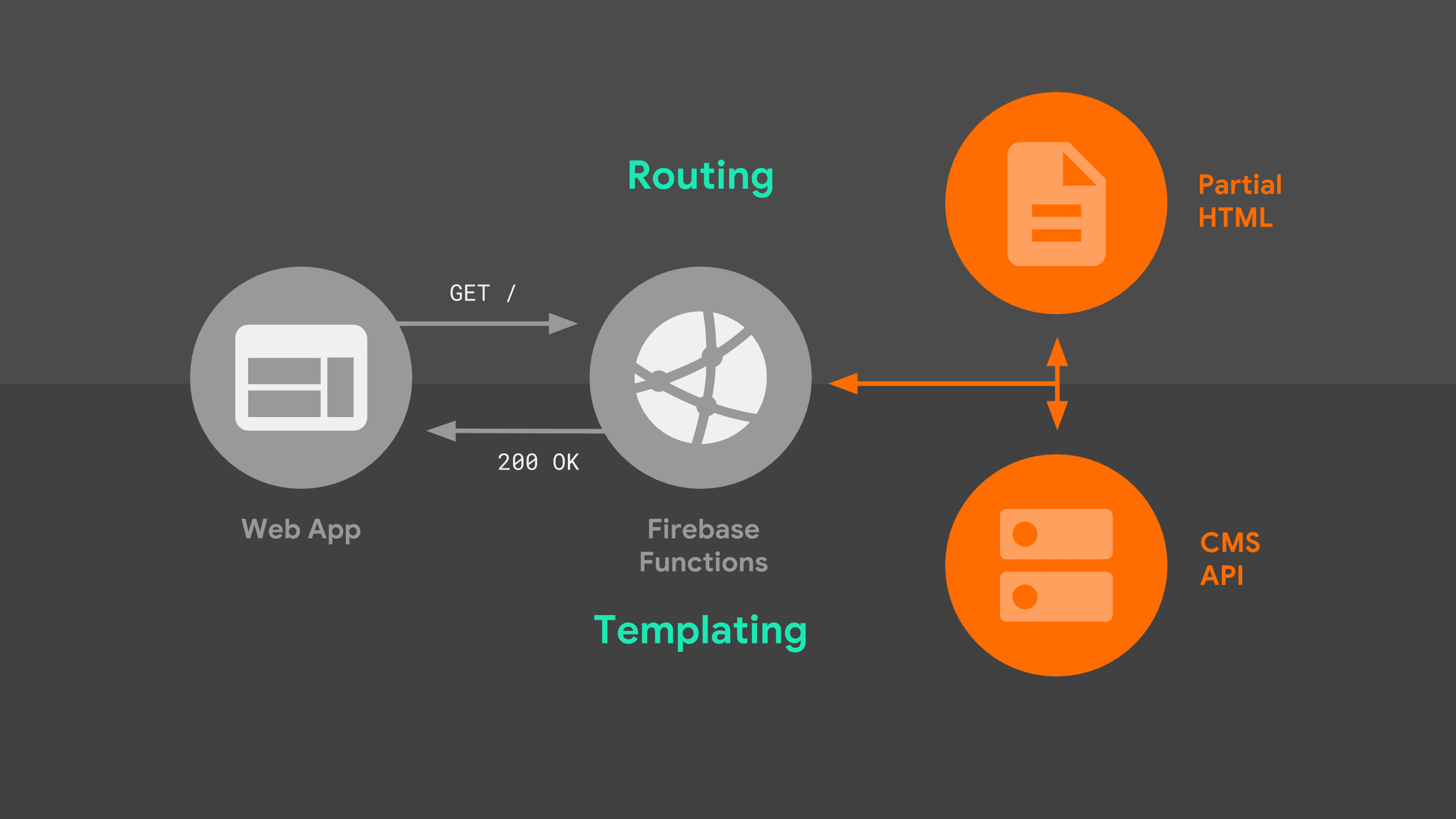
Il server indirizza la richiesta in base all'URL e utilizza la logica dei modelli per creare un documento HTML completo. Utilizzo una combinazione di dati dell'API Stack Exchange e frammenti HTML parziali che il server archivia localmente. Una volta che il service worker sa come rispondere, può iniziare a trasmettere in streaming l'HTML alla nostra app web.
Ci sono due aspetti di questa immagine che meritano di essere esplorati in modo più dettagliato: il routing e i modelli.
Routing
Per quanto riguarda il routing, il mio approccio è stato quello di utilizzare la sintassi di routing nativa del framework Express. È abbastanza flessibile da corrispondere a prefissi URL semplici, nonché a URL che includono parametri come parte del percorso. Qui creo una mappatura tra i nomi delle route e il pattern Express sottostante da confrontare.
const routes = new Map([
['about', '/about'],
['questions', '/questions/:questionId'],
['index', '/'],
]);
export default routes;
Posso quindi fare riferimento a questa mappatura direttamente dal codice del server. Quando viene trovata una corrispondenza per un determinato pattern Express, il gestore appropriato risponde con una logica di creazione di modelli specifica per la route corrispondente.
import routes from './lib/routes.mjs';
app.get(routes.get('index'), async (req, res) => {
// Templating logic.
});
Modelli lato server
E che aspetto ha questa logica di creazione dei modelli? Ho scelto un approccio che assemblava frammenti HTML parziali in sequenza, uno dopo l'altro. Questo modello si presta bene allo streaming.
Il server invia immediatamente un boilerplate HTML iniziale e il browser è in grado di eseguire il rendering della pagina parziale immediatamente. Man mano che il server assembla il resto delle origini dati, le trasmette in streaming al browser fino al completamento del documento.
Per capire cosa intendo, dai un'occhiata al codice Express per uno dei nostri itinerari:
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
Utilizzando il metodo write() dell'oggetto response
e facendo riferimento a modelli parziali archiviati localmente, posso avviare immediatamente lo
stream di risposta,
senza bloccare alcuna origine dati esterna. Il browser prende questo HTML iniziale e visualizza immediatamente un'interfaccia significativa e un messaggio di caricamento.
La parte successiva della pagina utilizza i dati dell'API Stack Exchange. Per ottenere questi dati, il nostro server deve effettuare una richiesta di rete. L'app web non può eseguire il rendering di altro finché non riceve una risposta e la elabora, ma almeno gli utenti non fissano uno schermo vuoto mentre aspettano.
Una volta ricevuta la risposta dall'API Stack Exchange, l'app web chiama una funzione di modelli personalizzata per tradurre i dati dell'API nel corrispondente HTML.
Linguaggio dei modelli
La creazione di modelli può essere un argomento sorprendentemente controverso e l'approccio che ho scelto è solo uno dei tanti. Ti consigliamo di sostituire la soluzione con una tua, soprattutto se hai legami pregressi con un framework di modelli esistente.
Per il mio caso d'uso, la cosa più sensata era fare affidamento solo sui template letterali di JavaScript, con alcune logiche suddivise in funzioni di supporto. Uno dei vantaggi della creazione di un'app multipagina è che non devi tenere traccia degli aggiornamenti dello stato e del rendering dell'HTML, quindi un approccio di base che produceva HTML statico ha funzionato per me.
Ecco un esempio di come sto creando un modello per la parte HTML dinamica dell'indice della mia app web. Come per i miei percorsi, la logica di creazione dei modelli è memorizzata in un modulo ES che può essere importato sia nel server che nel service worker.
export function index(tag, items) {
const title = `<h3>Top "${escape(tag)}" Questions</h3>`;
const form = `<form method="GET">...</form>`;
const questionCards = items
.map(item =>
questionCard({
id: item.question_id,
title: item.title,
})
)
.join('');
const questions = `<div id="questions">${questionCards}</div>`;
return title + form + questions;
}
Queste funzioni modello sono JavaScript puro ed è utile suddividere la logica in funzioni helper più piccole, se opportuno. Qui, passo ciascuno degli elementi restituiti nella risposta dell'API in una di queste funzioni, che crea un elemento HTML standard con tutti gli attributi appropriati impostati.
function questionCard({id, title}) {
return `<a class="card"
href="/questions/${id}"
data-cache-url="${questionUrl(id)}">${title}</a>`;
}
Particolarmente degno di nota è un attributo dati
che aggiungo a ogni link, data-cache-url, impostato sull'URL dell'API Stack Exchange
che mi serve per visualizzare la domanda corrispondente. Tieni presente
questo. Lo rivedrò in un secondo momento.
Tornando al mio gestore di route, una volta completata la creazione dei modelli, trasmetto in streaming la parte finale dell'HTML della mia pagina al browser e termino lo streaming. Questo è il segnale per il browser che il rendering progressivo è completato.
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
Questo è un breve tour della configurazione del mio server. Gli utenti che visitano la mia app web per la prima volta riceveranno sempre una risposta dal server, ma quando un visitatore torna alla mia app web, inizierà a rispondere il mio service worker. Vediamo cosa c'è.
Il service worker
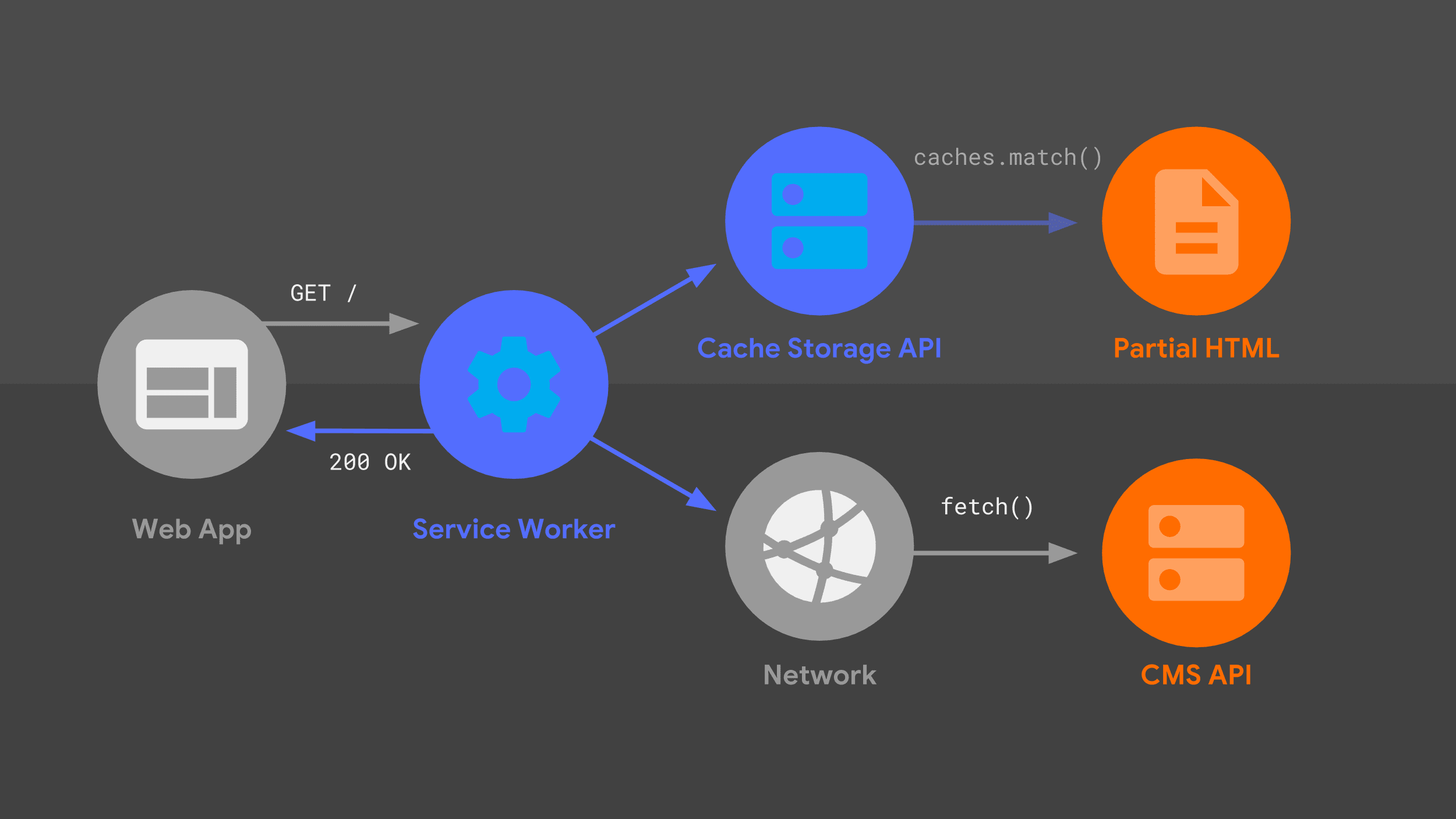
Questo diagramma dovrebbe esserti familiare: molti degli stessi elementi che ho trattato in precedenza sono qui in una disposizione leggermente diversa. Vediamo il flusso della richiesta, tenendo conto del service worker.
Il service worker gestisce una richiesta di navigazione in entrata per un determinato URL e, proprio come il mio server, utilizza una combinazione di logica di routing e di modelli per capire come rispondere.
L'approccio è lo stesso di prima, ma con primitive di basso livello diverse, come fetch() e l'API Cache Storage. Utilizzo queste origini dati per costruire la risposta HTML, che il service worker
restituisce all'app web.
Workbox
Anziché partire da zero con primitive di basso livello, creerò il mio service worker sulla base di un insieme di librerie di alto livello chiamate Workbox. Fornisce una base solida per la logica di memorizzazione nella cache, routing e generazione di risposte di qualsiasi service worker.
Routing
Proprio come per il mio codice lato server, il mio service worker deve sapere come abbinare una richiesta in entrata alla logica di risposta appropriata.
Il mio approccio è stato quello di
tradurre
ogni route Express in una espressione regolare corrispondente,
utilizzando una libreria utile chiamata
regexparam. Una volta eseguita la traduzione, posso sfruttare il supporto integrato di Workbox per il routing delle espressioni regolari.
Dopo aver importato il modulo che contiene le espressioni regolari, registro ogni espressione regolare con il router di Workbox. All'interno di ogni percorso posso fornire una logica di creazione di modelli personalizzata per generare una risposta. La creazione di modelli nel service worker è un po' più complessa rispetto al server di backend, ma Workbox aiuta a semplificare molte operazioni.
import regExpRoutes from './regexp-routes.mjs';
workbox.routing.registerRoute(
regExpRoutes.get('index')
// Templating logic.
);
Memorizzazione nella cache degli asset statici
Una parte fondamentale della storia dei modelli è assicurarsi che i miei modelli HTML parziali siano disponibili localmente tramite l'API Cache Storage e che vengano aggiornati quando implemento le modifiche all'app web. La manutenzione della cache può essere soggetta a errori se eseguita manualmente, quindi mi rivolgo a Workbox per gestire il precaching nell'ambito del mio processo di build.
Dico a Workbox quali URL precaricare utilizzando un file di configurazione, che punta alla directory contenente tutte le mie risorse locali insieme a un insieme di pattern da abbinare. Questo file viene letto automaticamente dalla CLI di Workbox, che viene eseguita ogni volta che ricompilo il sito.
module.exports = {
globDirectory: 'build',
globPatterns: ['**/*.{html,js,svg}'],
// Other options...
};
Workbox acquisisce uno snapshot dei contenuti di ogni file e inserisce automaticamente l'elenco di URL e revisioni nel file service worker finale. Workbox ora ha tutto ciò che serve per rendere i file prememorizzati nella cache sempre disponibili e aggiornati. Il risultato è un service-worker.js file che contiene qualcosa
di simile a quanto segue:
workbox.precaching.precacheAndRoute([
{
url: 'partials/about.html',
revision: '518747aad9d7e',
},
{
url: 'partials/foot.html',
revision: '69bf746a9ecc6',
},
// etc.
]);
Per chi utilizza un processo di compilazione più complesso, Workbox offre un plug-in webpack e un modulo nodo generico, oltre alla sua interfaccia a riga di comando.
Streaming
Poi, voglio che il service worker trasmetta in streaming l'HTML parziale memorizzato nella cache all'app web immediatamente. È una parte fondamentale dell'essere "affidabilmente veloce": ottengo sempre qualcosa di significativo sullo schermo immediatamente. Fortunatamente, l'utilizzo dell'API Streams all'interno del nostro service worker lo rende possibile.
Ora, forse avrai già sentito parlare dell'API Streams. Il mio collega Jake Archibald ne tesse le lodi da anni. Ha fatto la previsione audace che il 2016 sarebbe stato l'anno degli stream web. L'API Streams è fantastica oggi come lo era due anni fa, ma con una differenza fondamentale.
All'epoca, solo Chrome supportava gli stream, ma ora l'API Streams è supportata più ampiamente. Il quadro generale è positivo e, con un codice di riserva appropriato, non c'è nulla che ti impedisca di utilizzare gli stream nel service worker oggi stesso.
Beh... c'è una cosa che potrebbe fermarti: capire come funziona l'API Streams. Espone un insieme molto potente di primitive e gli sviluppatori che si sentono a loro agio nell'utilizzarlo possono creare flussi di dati complessi, come i seguenti:
const stream = new ReadableStream({
pull(controller) {
return sources[0]
.then(r => r.read())
.then(result => {
if (result.done) {
sources.shift();
if (sources.length === 0) return controller.close();
return this.pull(controller);
} else {
controller.enqueue(result.value);
}
});
},
});
Tuttavia, comprendere le implicazioni complete di questo codice potrebbe non essere alla portata di tutti. Invece di analizzare questa logica, parliamo del mio approccio allo streaming dei service worker.
Sto utilizzando un wrapper di alto livello nuovo di zecca,
workbox-streams.
Con questo, posso trasmetterlo in un mix di origini di streaming, sia da cache che da dati di runtime che potrebbero provenire dalla rete. Workbox si occupa di
coordinare le singole fonti e unirle in un'unica
risposta in streaming.
Inoltre, Workbox rileva automaticamente se l'API Streams è supportata e, in caso contrario, crea una risposta equivalente non in streaming. Ciò significa che non devi preoccuparti di scrivere fallback, poiché i flussi si avvicinano sempre di più al supporto del 100% dei browser.
Memorizzazione nella cache di runtime
Vediamo come il mio service worker gestisce i dati di runtime dall'API Stack Exchange. Utilizzo il supporto integrato di Workbox per una strategia di memorizzazione nella cache stale-while-revalidate, insieme alla scadenza, per garantire che lo spazio di archiviazione dell'app web non aumenti senza limiti.
Ho configurato due strategie in Workbox per gestire le diverse fonti che compongono la risposta di streaming. Con poche chiamate di funzioni e configurazioni, Workbox ci consente di fare ciò che altrimenti richiederebbe centinaia di righe di codice scritto a mano.
const cacheStrategy = workbox.strategies.cacheFirst({
cacheName: workbox.core.cacheNames.precache,
});
const apiStrategy = workbox.strategies.staleWhileRevalidate({
cacheName: API_CACHE_NAME,
plugins: [new workbox.expiration.Plugin({maxEntries: 50})],
});
La prima strategia legge i dati memorizzati nella cache, come i nostri modelli HTML parziali.
L'altra strategia implementa la logica di memorizzazione nella cache stale-while-revalidate, insieme alla scadenza della cache utilizzata meno di recente una volta raggiunte 50 voci.
Ora che ho implementato queste strategie, non mi resta che indicare a Workbox come utilizzarle per creare una risposta completa in streaming. Passo un array di origini come funzioni e ognuna di queste funzioni verrà eseguita immediatamente. Workbox prende il risultato di ogni origine e lo trasmette in streaming all'app web, in sequenza, ritardando solo se la funzione successiva nell'array non è ancora stata completata.
workbox.streams.strategy([
() => cacheStrategy.makeRequest({request: '/head.html'}),
() => cacheStrategy.makeRequest({request: '/navbar.html'}),
async ({event, url}) => {
const tag = url.searchParams.get('tag') || DEFAULT_TAG;
const listResponse = await apiStrategy.makeRequest(...);
const data = await listResponse.json();
return templates.index(tag, data.items);
},
() => cacheStrategy.makeRequest({request: '/foot.html'}),
]);
Le prime due origini sono modelli parziali memorizzati nella cache letti direttamente dall'API Cache Storage, pertanto saranno sempre disponibili immediatamente. In questo modo, la nostra implementazione del service worker risponderà alle richieste in modo affidabile e rapido, proprio come il mio codice lato server.
La nostra prossima funzione di origine recupera i dati dall'API Stack Exchange ed elabora la risposta nel codice HTML previsto dall'app web.
La strategia stale-while-revalidate significa che se ho una risposta precedentemente memorizzata nella cache per questa chiamata API, potrò trasmetterla in streaming alla pagina immediatamente, aggiornando la voce della cache "in background" per la volta successiva in cui viene richiesta.
Infine, trasmetto in streaming una copia memorizzata nella cache del piè di pagina e chiudo i tag HTML finali, per completare la risposta.
Il codice di condivisione mantiene tutto sincronizzato
Noterai che alcuni bit del codice del service worker ti sembrano familiari. La logica HTML parziale e di templating utilizzata dal service worker è identica a quella utilizzata dal gestore lato server. Questa condivisione del codice garantisce agli utenti un'esperienza coerente, sia che visitino la mia app web per la prima volta sia che tornino a una pagina visualizzata dal service worker. È questo l'aspetto più vantaggioso di JavaScript isomorfo.
Miglioramenti dinamici e progressivi
Ho esaminato sia il server che il service worker della mia PWA, ma c'è un'ultima parte di logica da trattare: c'è una piccola quantità di JavaScript che viene eseguita su ogni pagina, dopo che sono state trasmesse in streaming.
Questo codice migliora progressivamente l'esperienza utente, ma non è fondamentale: la web app funzionerà comunque se non viene eseguito.
Metadati di pagina
La mia app utilizza JavaScript lato client per aggiornare i metadati di una pagina in base alla risposta dell'API. Poiché utilizzo lo stesso bit iniziale di HTML memorizzato nella cache per ogni pagina, l'app web finisce per avere tag generici nell'intestazione del mio documento. Ma grazie al coordinamento tra il mio codice lato client e i modelli, posso aggiornare il titolo della finestra utilizzando i metadati specifici della pagina.
Nell'ambito del codice di creazione dei modelli, il mio approccio consiste nell'includere un tag script contenente la stringa con escape corretto.
const metadataScript = `<script>
self._title = '${escape(item.title)}';
</script>`;
Poi, una volta caricata la mia pagina, leggo la stringa e aggiorno il titolo del documento.
if (self._title) {
document.title = unescape(self._title);
}
Se ci sono altri metadati specifici della pagina che vuoi aggiornare nella tua app web, puoi seguire lo stesso approccio.
Esperienza utente offline
L'altro miglioramento progressivo che ho aggiunto serve ad attirare l'attenzione sulle nostre funzionalità offline. Ho creato una PWA affidabile e voglio che gli utenti sappiano che quando sono offline possono comunque caricare le pagine visitate in precedenza.
Innanzitutto, utilizzo l'API Cache Storage per ottenere un elenco di tutte le richieste API memorizzate nella cache in precedenza e lo traduco in un elenco di URL.
Ricordi gli attributi speciali dei dati di cui ho parlato, ognuno dei quali contiene l'URL della richiesta API necessaria per visualizzare una domanda? Posso confrontare questi attributi dei dati con l'elenco degli URL memorizzati nella cache e creare un array di tutti i link alle domande che non corrispondono.
Quando il browser entra in stato offline, scorro l'elenco dei link non memorizzati nella cache e disattivo quelli che non funzioneranno. Tieni presente che si tratta solo di un suggerimento visivo per l'utente su cosa aspettarsi da queste pagine. Non disattivo i link né impedisco all'utente di navigare.
const apiCache = await caches.open(API_CACHE_NAME);
const cachedRequests = await apiCache.keys();
const cachedUrls = cachedRequests.map(request => request.url);
const cards = document.querySelectorAll('.card');
const uncachedCards = [...cards].filter(card => {
return !cachedUrls.includes(card.dataset.cacheUrl);
});
const offlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '0.3';
}
};
const onlineHandler = () => {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '1.0';
}
};
window.addEventListener('online', onlineHandler);
window.addEventListener('offline', offlineHandler);
Errori comuni
Ho completato il tour del mio approccio alla creazione di una PWA multipagina. Ci sono molti fattori da considerare quando si elabora il proprio approccio e potresti finire per fare scelte diverse dalle mie. Questa flessibilità è uno dei grandi vantaggi dello sviluppo per il web.
Esistono alcuni errori comuni che potresti riscontrare quando prendi le tue decisioni architetturali e voglio evitarti qualche problema.
Non memorizzare nella cache l'HTML completo
Sconsiglio di archiviare documenti HTML completi nella cache. Innanzitutto, è uno spreco di spazio. Se la tua app web utilizza la stessa struttura HTML di base per ogni pagina, finirai per memorizzare copie dello stesso markup più e più volte.
Ancora più importante, se implementi una modifica alla struttura HTML condivisa del tuo sito, ognuna di queste pagine memorizzate nella cache in precedenza è ancora bloccata con il vecchio layout. Immagina la frustrazione di un visitatore di ritorno che vede un mix di pagine vecchie e nuove.
Server / service worker drift
L'altro problema da evitare riguarda la mancata sincronizzazione del server e del service worker. Il mio approccio è stato quello di utilizzare JavaScript isomorfo, in modo che lo stesso codice venisse eseguito in entrambi i casi. A seconda dell'architettura del server esistente, non è sempre possibile.
Qualunque decisione architettonica tu prenda, devi avere una strategia per eseguire il codice di routing e di modelli equivalente nel server e nel service worker.
Scenari peggiori
Layout / design incoerente
Cosa succede se ignori questi problemi? Beh, sono possibili tutti i tipi di errori, ma lo scenario peggiore è che un utente di ritorno visiti una pagina memorizzata nella cache con un layout molto obsoleto, ad esempio una pagina con un testo dell'intestazione obsoleto o che utilizza nomi di classi CSS non più validi.
Scenario peggiore: routing interrotto
In alternativa, un utente potrebbe imbattersi in un URL gestito dal tuo server, ma non dal tuo service worker. Un sito pieno di layout zombie e vicoli ciechi non è una PWA affidabile.
Suggerimenti per il successo
Ma non sei solo in questa situazione. I seguenti suggerimenti possono aiutarti a evitare questi inconvenienti:
Utilizzare librerie di modelli e routing con implementazioni multilingue
Prova a utilizzare librerie di modelli e routing con implementazioni JavaScript. So che non tutti gli sviluppatori possono permettersi di eseguire la migrazione dal server web e dal linguaggio di templating attuali.
Tuttavia, diversi framework di routing e modelli popolari hanno implementazioni in più lingue. Se riesci a trovarne uno che funzioni con JavaScript e con la lingua del tuo server attuale, sei un passo più vicino a mantenere sincronizzati il service worker e il server.
Preferisci modelli sequenziali anziché nidificati
Successivamente, ti consiglio di utilizzare una serie di modelli sequenziali che possono essere riprodotti in streaming uno dopo l'altro. È accettabile che le parti successive della pagina utilizzino una logica di modelli più complessa, a condizione che tu possa trasmettere in streaming la parte iniziale del codice HTML il più rapidamente possibile.
Memorizzare nella cache i contenuti statici e dinamici nel service worker
Per un rendimento ottimale, devi prememorizzare nella cache tutte le risorse statiche critiche del tuo sito. Devi anche configurare la logica di memorizzazione nella cache in fase di runtime per gestire i contenuti dinamici, come le richieste API. L'utilizzo di Workbox ti consente di basarti su strategie ben testate e pronte per la produzione anziché implementarle da zero.
Blocca sulla rete solo quando è assolutamente necessario
Inoltre, dovresti bloccare la rete solo quando non è possibile riprodurre in streaming una risposta dalla cache. La visualizzazione immediata di una risposta API memorizzata nella cache può spesso portare a un'esperienza utente migliore rispetto all'attesa di dati aggiornati.