

הנתונים הגולמיים של דוח חוויית המשתמש ב-Chrome (CrUX) זמינים ב-BigQuery, מסד נתונים ב-Google Cloud. כדי להשתמש ב-BigQuery צריך פרויקט ב-GCP וידע בסיסי ב-SQL.
במדריך הזה תלמדו איך להשתמש ב-BigQuery כדי לכתוב שאילתות על מערך הנתונים של CrUX, וכך לחלץ תובנות לגבי מצב חוויות המשתמשים באינטרנט:
- הסבר על אופן הארגון של הנתונים
- כתיבת שאילתה בסיסית להערכת הביצועים של מקור
- כתיבת שאילתה מתקדמת למעקב אחר הביצועים לאורך זמן
ארגון הנתונים
נתחיל בשאילתה בסיסית:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
כדי להריץ את השאילתה, מזינים אותה בעורך השאילתות ולוחצים על הלחצן Run query (הרצת שאילתה):
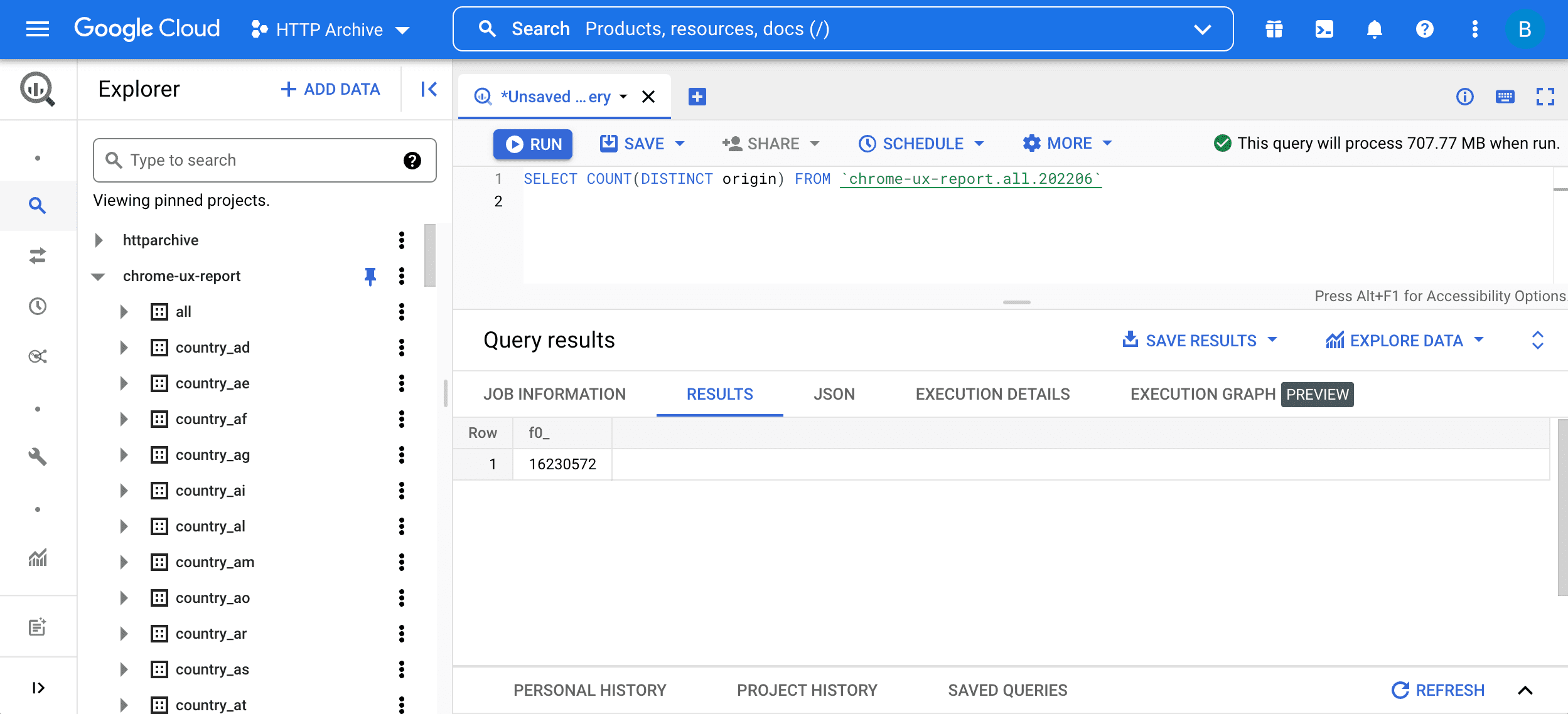
השאילתה הזו מורכבת משני חלקים:
SELECT COUNT(DISTINCT origin)פירושו שליחת שאילתה לגבי מספר המקוריים בטבלה. באופן כללי, שתי כתובות URL הן חלק מאותו מקור אם יש להן את אותה סכמה, מארח ויציאה.FROM chrome-ux-report.all.202206מציין את הכתובת של טבלת המקור, שכוללת שלושה חלקים:- שם הפרויקט ב-Cloud
chrome-ux-reportשבו מאורגנים כל נתוני CrUX - מערך הנתונים
all, שמייצג נתונים מכל המדינות - הטבלה
202206, השנה והחודש של הנתונים בפורמט YYYYMM
- שם הפרויקט ב-Cloud
יש גם מערכי נתונים לכל מדינה. לדוגמה, chrome-ux-report.country_ca.202206 מייצג רק את נתוני חוויית המשתמש שמקורם בקנדה.
בכל מערך נתונים יש טבלאות לכל חודש מאז 201710. טבלאות חדשות לגבי החודש הקלנדרי הקודם מתפרסמות באופן קבוע.
המבנה של טבלאות הנתונים (שנקרא גם סכימה) מכיל:
- המקור, לדוגמה
origin = 'https://www.example.com', שמייצג את ההפצה המצטברת של חוויית המשתמש בכל הדפים באתר הזה - מהירות החיבור בזמן הטעינה של הדף, לדוגמה,
effective_connection_type.name = '4G'(התכונה הזו תוסר בפברואר 2025) - סוג המכשיר, למשל
form_factor.name = 'desktop' - מדדי חוויית המשתמש עצמם
הנתונים של כל מדד מאורגנים כמערך של אובייקטים. בסימן JSON, הערך first_contentful_paint.histogram.bin ייראה כך:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
כל קטגוריה מכילה שעה התחלה ושעת סיום באלפיות שנייה וצפיפות שמייצגת את אחוז חוויות המשתמש בטווח הזמן הזה. במילים אחרות, 12.34% מהחוויות של זמן טעינה ראשוני (FCP) במקור, במהירות החיבור ובסוג המכשיר התיאורטיים האלה נמוכים מ-100 אלפיות השנייה. הסכום של כל צפיפות הקטגוריות הוא 100%.
עיון במבנה של הטבלאות ב-BigQuery
הערכת הביצועים
אנחנו יכולים להשתמש בידע שלנו לגבי הסכימה של הטבלה כדי לכתוב שאילתה שמייצרת את נתוני הביצועים האלה.
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
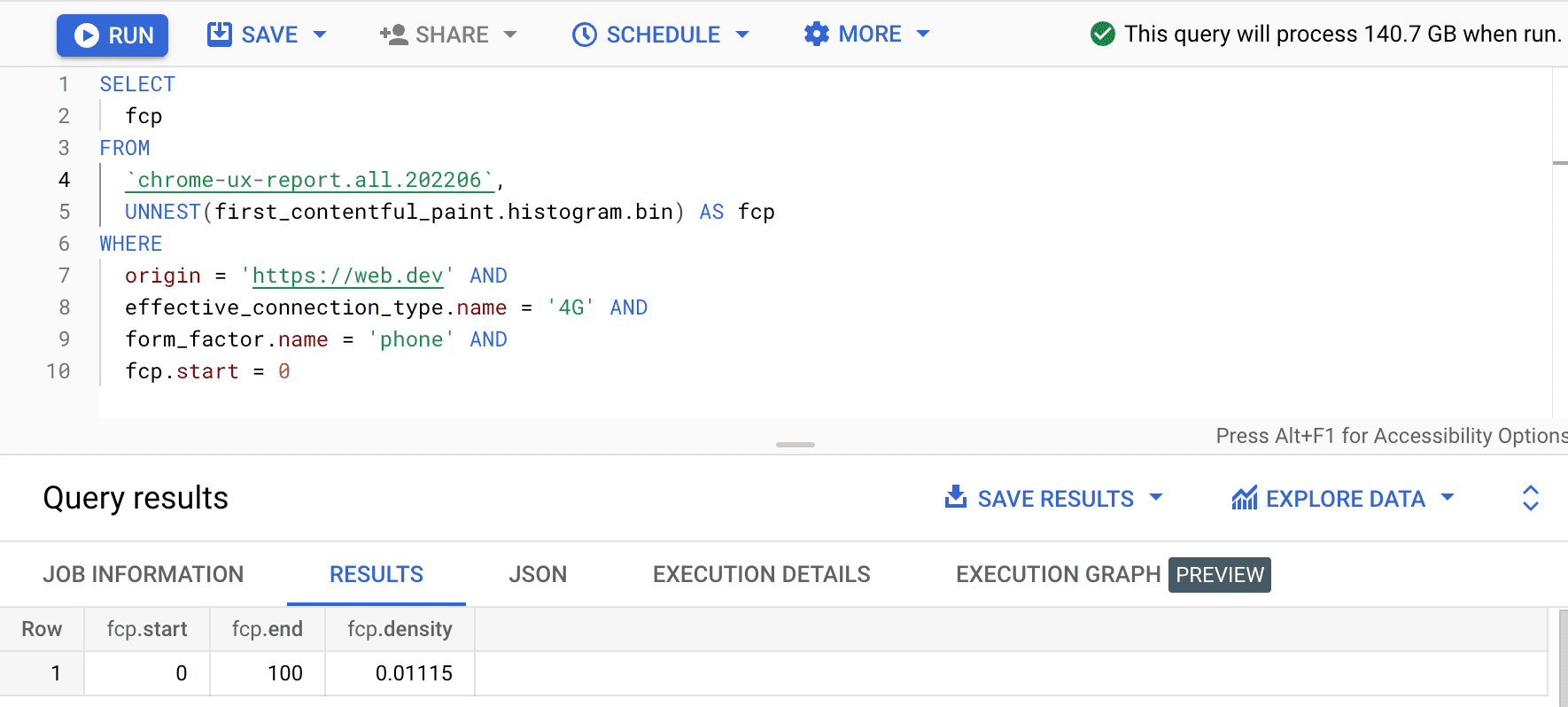
התוצאה היא 0.01115, כלומר 1.115% מחוויית המשתמשים במקור הזה נמשכות בין 0 ל-100 אלפיות השנייה ברשת 4G ובטלפון. אם אנחנו רוצים להכליל את השאילתה לכל חיבור וכל סוג מכשיר, אפשר להשמיט אותם מהקלוזה WHERE ולהשתמש בפונקציית המאגר SUM כדי להוסיף את כל צפיפות הקטגוריות הרלוונטיות:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
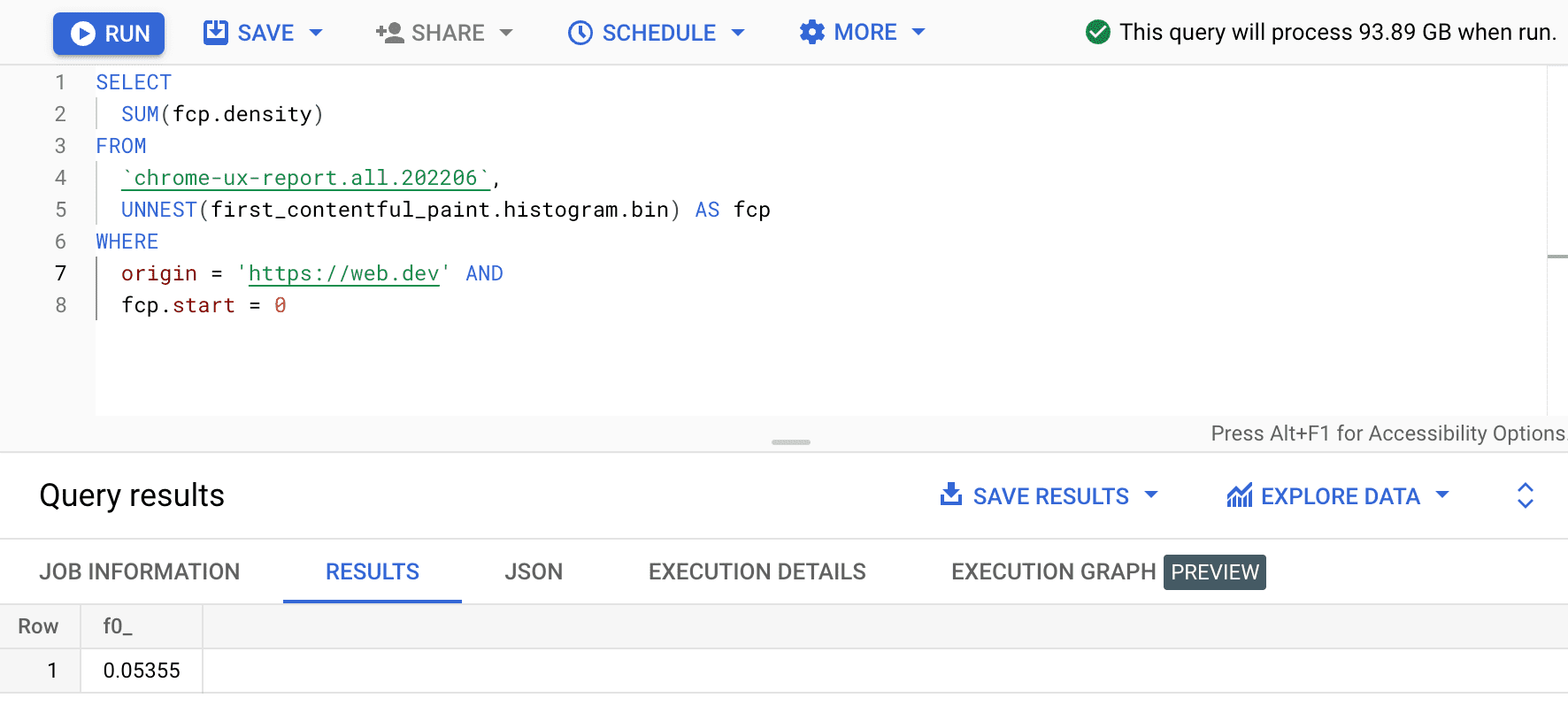
התוצאה היא 0.05355, או 5.355% בכל המכשירים וסוגים של חיבורים. אפשר לשנות את השאילתה במעט ולסכם את הצפיפויות של כל הקטגוריות שנמצאות בטווח ה-FCP 'מהיר' של 0 עד 1,000ms:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
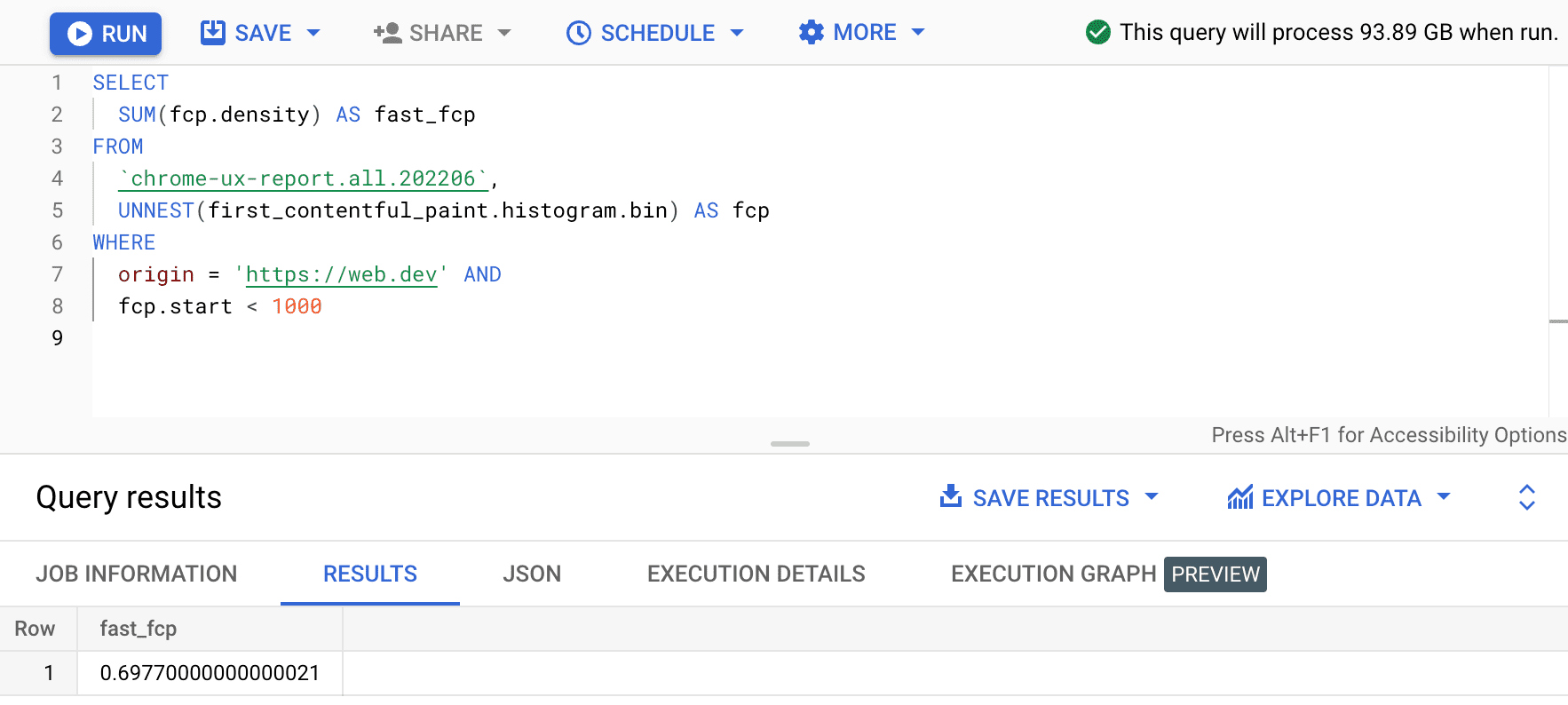
כך מקבלים את 0.6977. במילים אחרות, 69.77% מחוויית המשתמש של FCP ב-web.dev נחשבות 'מהירות' בהתאם להגדרה של טווח ה-FCP.
מעקב אחרי ביצועים
עכשיו, אחרי שחולצו נתוני הביצועים של מקור מסוים, אפשר להשוות אותם לנתונים ההיסטוריים שזמינים בטבלאות ישנות יותר. כדי לעשות זאת, אפשר לכתוב מחדש את כתובת הטבלה לחודש קודם, או להשתמש בתחביר של תווים כלליים כדי לשלוח שאילתה לכל החודשים:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
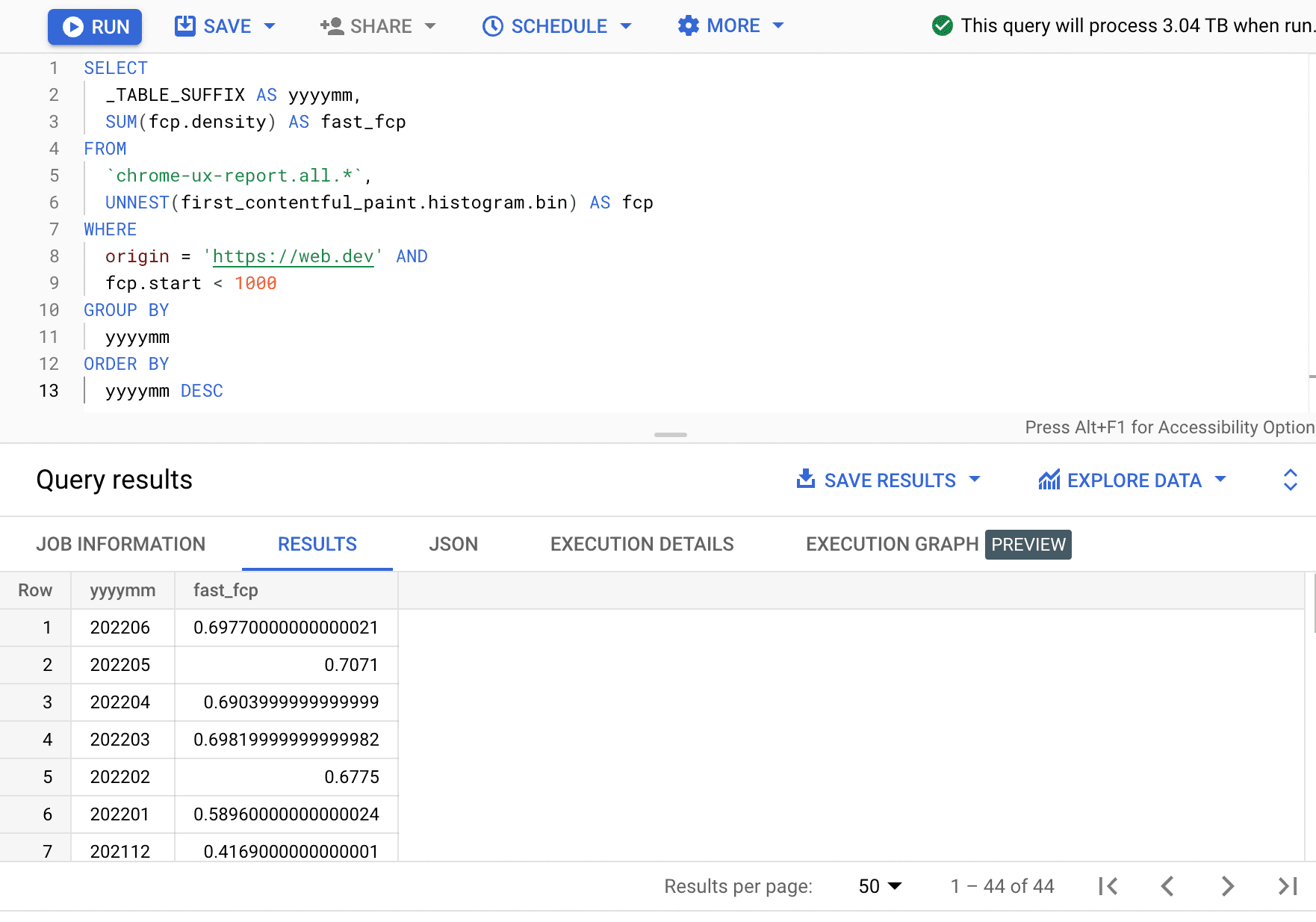
כאן רואים שהאחוז של חוויות צפייה מהירות ב-FCP משתנה בכמה נקודות אחוז בכל חודש.
| yyyymm | fast_fcp |
|---|---|
| 202206 | 69.77% |
| 202205 | 70.71% |
| 202204 | 69.04% |
| 202203 | 69.82% |
| 202202 | 67.75% |
| 202201 | 58.96% |
| 202112 | 41.69% |
| ... | ... |
בעזרת השיטות האלה תוכלו לחפש את הביצועים של מקור, לחשב את אחוז החוויה המהירה ולעקוב אחריו לאורך זמן. בשלב הבא, נסו להריץ שאילתות לגבי שני מקורות או יותר ולהשוות את הביצועים שלהם.
שאלות נפוצות
ריכזנו כאן כמה מהשאלות הנפוצות לגבי מערך הנתונים של CrUX ב-BigQuery:
מתי כדאי להשתמש ב-BigQuery במקום בכלים אחרים?
צריך להשתמש ב-BigQuery רק אם אי אפשר לקבל את אותו מידע מכלים אחרים, כמו לוח הבקרה של CrUX ו-PageSpeed Insights. לדוגמה, BigQuery מאפשר לכם לחתוך את הנתונים בדרכים משמעותיות ואפילו לאחד אותם עם מערכי נתונים ציבוריים אחרים, כמו HTTP Archive, כדי לבצע כריית מידע מתקדמת.
האם יש מגבלות על השימוש ב-BigQuery?
כן, ההגבלה החשובה ביותר היא שבברירת המחדל, משתמשים יכולים להריץ שאילתות רק על נתונים בסך 1TB בחודש. מעבר לכך, יחול התעריף הרגיל של 5 $לטרה-בייט.
איפה אפשר לקבל מידע נוסף על BigQuery?
מידע נוסף זמין במסמכי התיעוד של BigQuery.