
Enabling service workers to tell browsers which pages work offline

What is the Content Indexing API?
Using a progressive web app means having access to information people care about—images, videos, articles, and more—regardless of the current state of your network connection. Technologies like service workers, the Cache Storage API, and IndexedDB provide you with the building blocks for storing and serving data when folks interact directly with a PWA. But building a high-quality, offline-first PWA is only part of the story. If folks don't realize that a web app's content is available while they're offline, they won't take full advantage of the work you put into implementing that functionality.
This is a discovery problem; how can your PWA make users aware of its offline-capable content so that they can discover and view what's available? The Content Indexing API is a solution to this problem. The developer-facing portion of this solution is an extension to service workers, which allows developers to add URLs and metadata of offline-capable pages to a local index maintained by the browser. That enhancement is available in Chrome 84 and later.
Once the index is populated with content from your PWA, as well as any other installed PWAs, it will be surfaced by the browser as shown below.
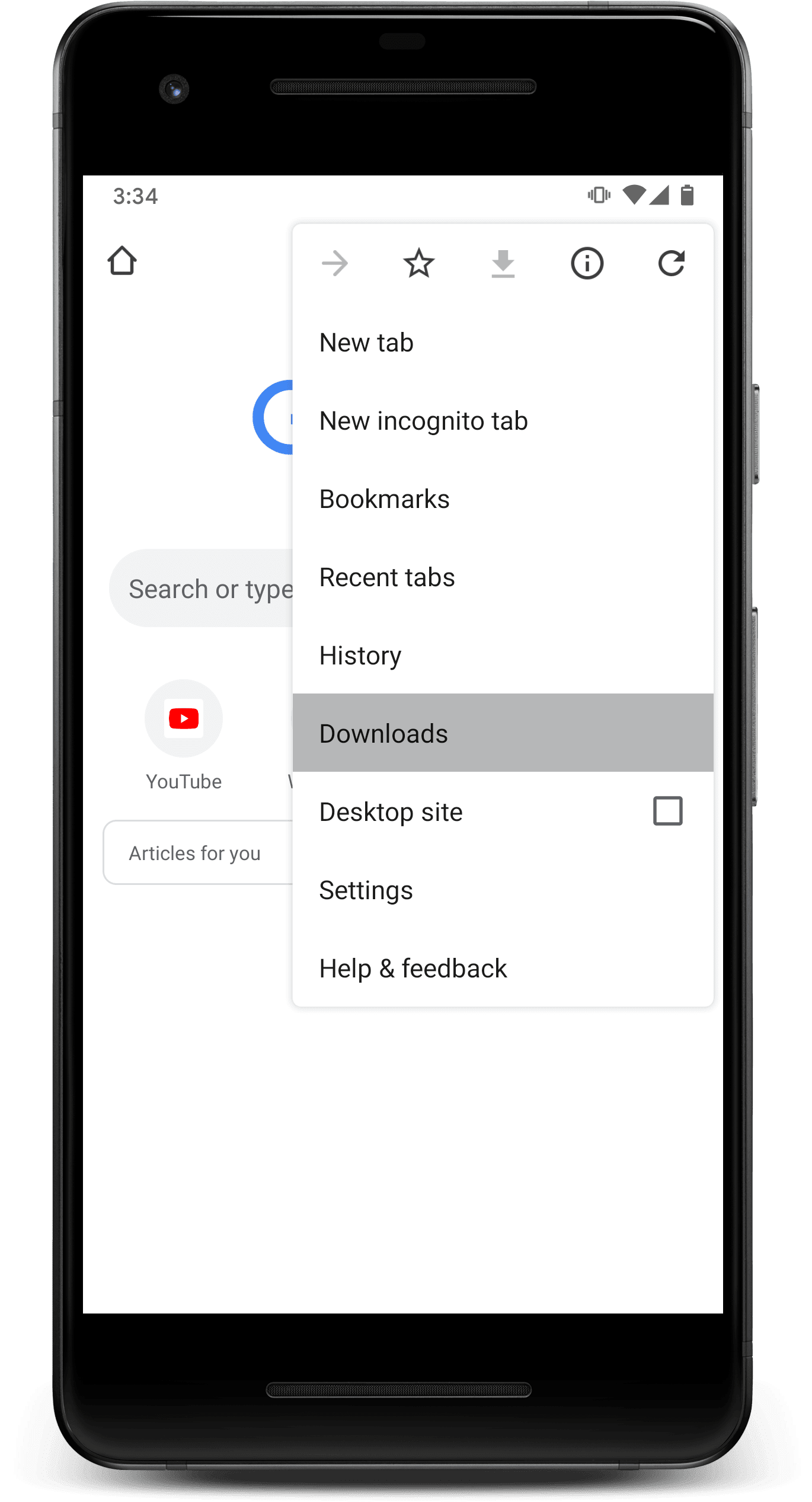
Additionally, Chrome can proactively recommend content when it detects that a user is offline.
The Content Indexing API is not an alternative way of caching content. It's a way of providing metadata about pages that are already cached by your service worker, so that the browser can surface those pages when folks are likely to want to view them. The Content Indexing API helps with discoverability of cached pages.
See it in action
The best way to get a feel for the Content Indexing API is to try a sample application.
- Make sure that you're using a supported browser and platform. Currently,
that's limited to Chrome 84 or later on Android. Go to
about://versionto see what version of Chrome you're running. - Visit https://contentindex.dev
- Click the
+button next to one or more of the items on the list. - (Optional) Disable your device's Wi-Fi and cellular data connection, or enable airplane mode to simulate taking your browser offline.
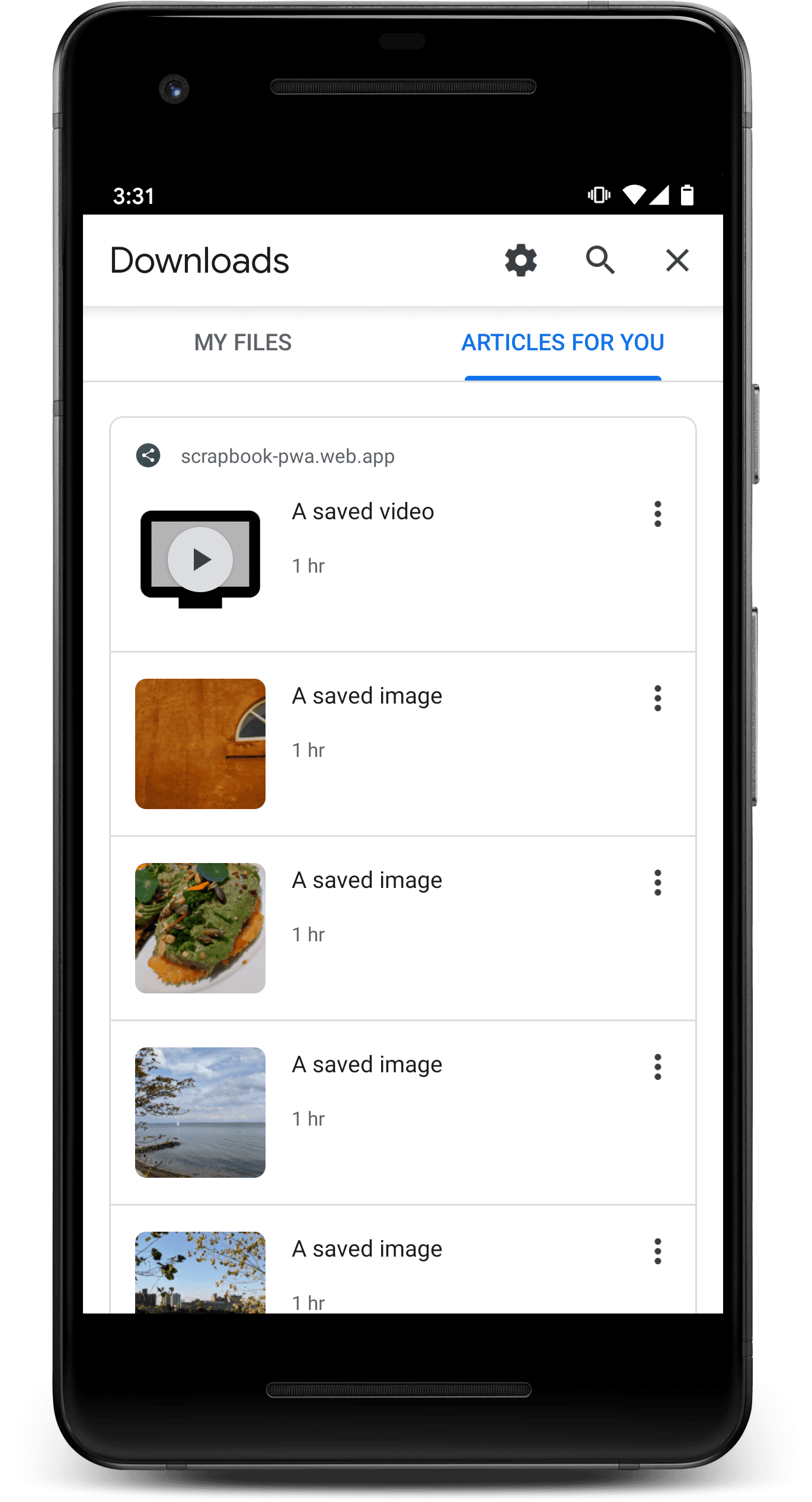
- Choose Downloads from Chrome's menu, and switch to the Articles for You tab.
- Browse through the content that you previously saved.
You can view the source of the sample application on GitHub.
Another sample application, a Scrapbook PWA, illustrates the use of the Content Indexing API with the Web Share Target API. The code demonstrates a technique for keeping the Content Indexing API in sync with items stored by a web app using the Cache Storage API.
Using the API
To use the API your app must have a service worker and URLs that are navigable offline. If your web app does not currently have a service worker, the Workbox libraries can simplify creating one.
What type of URLs can be indexed as offline-capable?
The API supports indexing URLs corresponding to HTML documents. A URL for a cached media file, for example, can't be indexed directly. Instead, you need to provide a URL for a page that displays media, and which works offline.
A recommended pattern is to create a "viewer" HTML page that could accept the underlying media URL as a query parameter and then display the contents of the file, potentially with additional controls or content on the page.
Web apps can only add URLs to the content index that are under the scope of the current service worker. In other words, a web app could not add a URL belonging to a completely different domain into the content index.
Overview
The Content Indexing API supports three operations: adding, listing, and
removing metadata. These methods are exposed from a new property, index, that
has been added to the
ServiceWorkerRegistration
interface.
The first step in indexing content is getting a reference to the current
ServiceWorkerRegistration. Using navigator.serviceWorker.ready is the most straightforward way:
const registration = await navigator.serviceWorker.ready;
// Remember to feature-detect before using the API:
if ('index' in registration) {
// Your Content Indexing API code goes here!
}
If you're making calls to the Content Indexing API from within a service worker,
rather than inside a web page, you can refer to the ServiceWorkerRegistration
directly via registration. It will already be defined
as part of the ServiceWorkerGlobalScope.
Adding to the index
Use the add() method to index URLs and their associated metadata. It's up to
you to choose when items are added to the index. You might want to add to the
index in response to an input, like clicking a "save offline" button. Or you
might add items automatically each time cached data is updated via a mechanism
like periodic background sync.
await registration.index.add({
// Required; set to something unique within your web app.
id: 'article-123',
// Required; url needs to be an offline-capable HTML page.
url: '/articles/123',
// Required; used in user-visible lists of content.
title: 'Article title',
// Required; used in user-visible lists of content.
description: 'Amazing article about things!',
// Required; used in user-visible lists of content.
icons: [{
src: '/img/article-123.png',
sizes: '64x64',
type: 'image/png',
}],
// Optional; valid categories are currently:
// 'homepage', 'article', 'video', 'audio', or '' (default).
category: 'article',
});
Adding an entry only affects the content index; it does not add anything to the cache.
Edge case: Call add() from window context if your icons rely on a fetch handler
When you call add(), Chrome will make a request for
each icon's URL to ensure that it has a copy of the icon to use when
displaying a list of indexed content.
If you call
add()from thewindowcontext (in other words, from your web page), this request will trigger afetchevent on your service worker.If you call
add()within your service worker (perhaps inside another event handler), the request will not trigger the service worker'sfetchhandler. The icons will be fetched directly, without any service worker involvement. Keep this in mind if your icons rely on yourfetchhandler, perhaps because they only exist in the local cache and not on the network. If they do, make sure that you only calladd()from thewindowcontext.
Listing the index's contents
The getAll() method returns a promise for an iterable list of indexed entries
and their metadata. Returned entries will contain all of the data saved with
add().
const entries = await registration.index.getAll();
for (const entry of entries) {
// entry.id, entry.launchUrl, etc. are all exposed.
}
Removing items from the index
To remove an item from the index, call delete() with the id of the item to
remove:
await registration.index.delete('article-123');
Calling delete() only affects the index. It does not delete anything from the
cache.
Handling a user delete event
When the browser displays the indexed content, it may include its own user interface with a Delete menu item, giving people a chance to indicate that they're done viewing previously indexed content. This is how the deletion interface looks in Chrome 80:
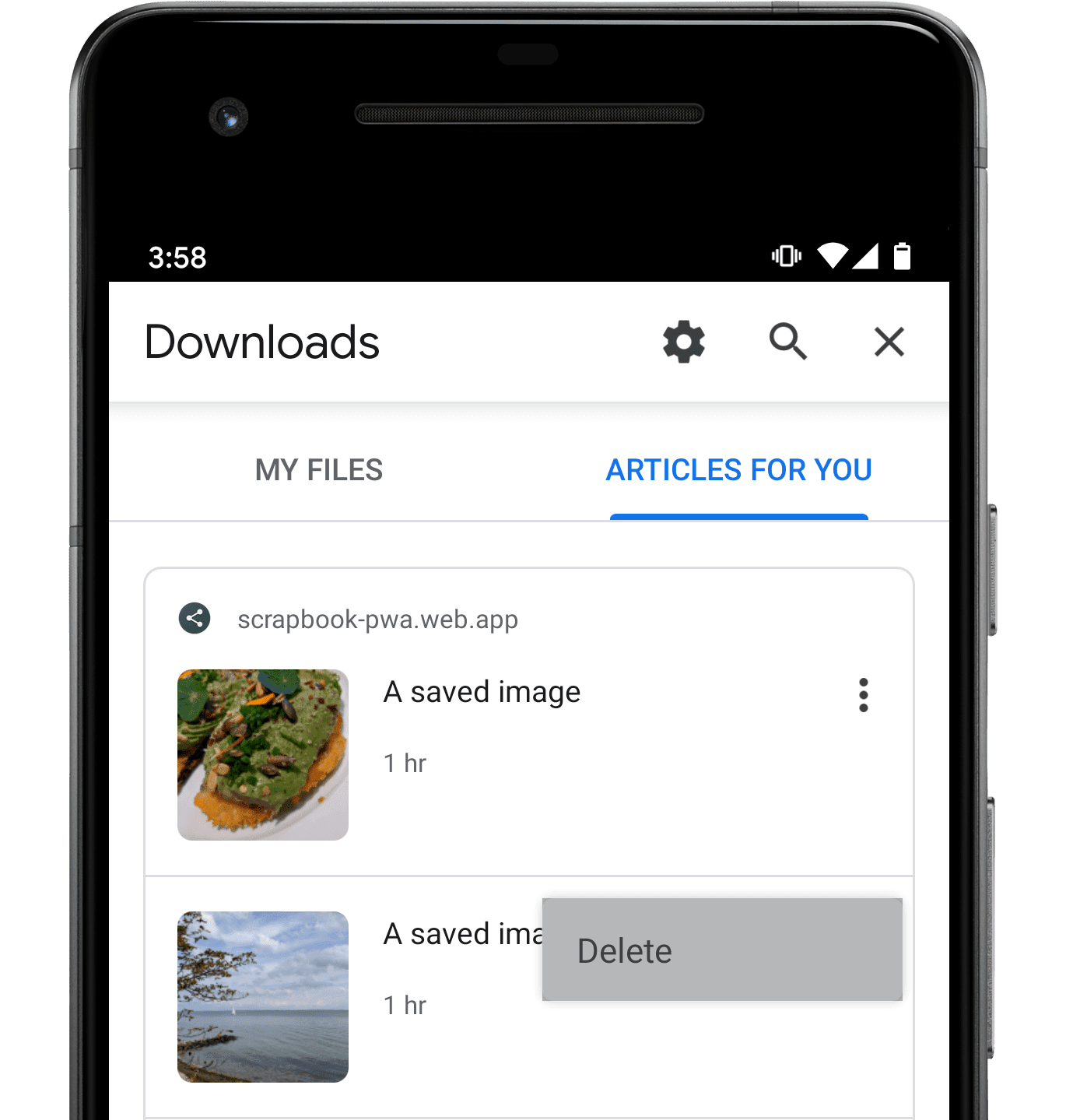
When someone selects that menu item, your web app's service worker will receive
a contentdelete event. While handling this event is optional, it provides a
chance for your service worker to "clean up" content, like locally cached media
files, that someone has indicated they are done with.
You do not need to call registration.index.delete() inside your
contentdelete handler; if the event has been fired, the relevant index
deletion has already been performed by the browser.
self.addEventListener('contentdelete', (event) => {
// event.id will correspond to the id value used
// when the indexed content was added.
// Use that value to determine what content, if any,
// to delete from wherever your app stores it—usually
// the Cache Storage API or perhaps IndexedDB.
});
Feedback about the API design
Is there something about the API that's awkward or doesn't work as expected? Or are there missing pieces that you need to implement your idea?
File an issue on the Content Indexing API explainer GitHub repo, or add your thoughts to an existing issue.
Problem with the implementation?
Did you find a bug with Chrome's implementation?
File a bug at https://new.crbug.com. Include as much
detail as you can, simple instructions for reproducing, and set Components
to Blink>ContentIndexing.
Planning to use the API?
Planning to use the Content Indexing API in your web app? Your public support helps Chrome prioritize features, and shows other browser vendors how critical it is to support them.
- Send a tweet to @ChromiumDev using the hashtag
#ContentIndexingAPIand details on where and how you're using it.
What are some security and privacy implications of content indexing?
Check out the answers provided in response to the W3C's Security and Privacy questionnaire. If you have further questions, please start a discussion via the project's GitHub repo.
Hero image by Maksym Kaharlytskyi on Unsplash.