
Qué sucede en la navegación
Esta es la segunda parte de una serie de 4 blogs sobre el funcionamiento interno de Chrome. En la publicación anterior, analizamos cómo los diferentes procesos y subprocesos controlan diferentes partes de un navegador. En esta publicación, analizamos en detalle cómo se comunican cada proceso y subproceso para mostrar un sitio web.
Veamos un caso de uso simple de navegación web: escribes una URL en un navegador y, luego, este recupera datos de Internet y muestra una página. En esta publicación, nos enfocaremos en la parte en la que un usuario solicita un sitio y el navegador se prepara para renderizar una página, también conocida como navegación.
Comienza con un proceso del navegador.
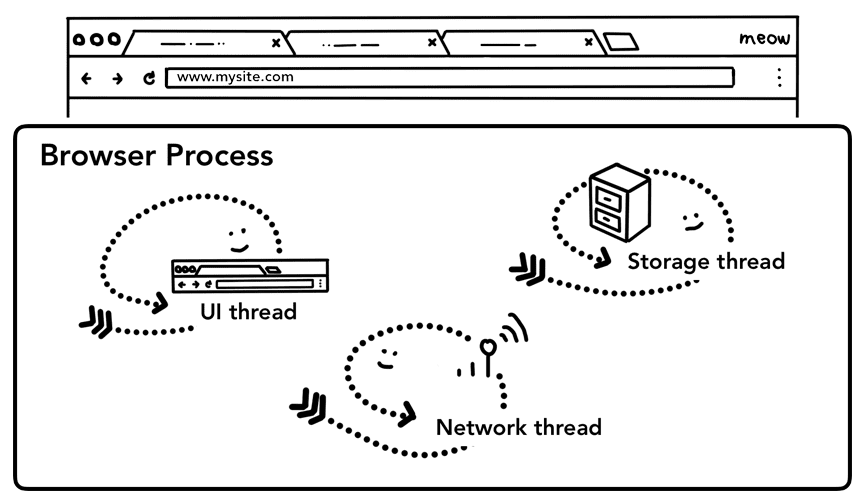
Como explicamos en la parte 1: CPU, GPU, memoria y arquitectura de varios procesos, el proceso del navegador controla todo lo que está fuera de una pestaña. El proceso del navegador tiene subprocesos, como el subproceso de IU que dibuja botones y campos de entrada del navegador, el subproceso de red que se ocupa de la pila de red para recibir datos de Internet, el subproceso de almacenamiento que controla el acceso a los archivos y mucho más. Cuando escribes una URL en la barra de direcciones, el subproceso de IU del proceso del navegador controla tu entrada.
Una navegación simple
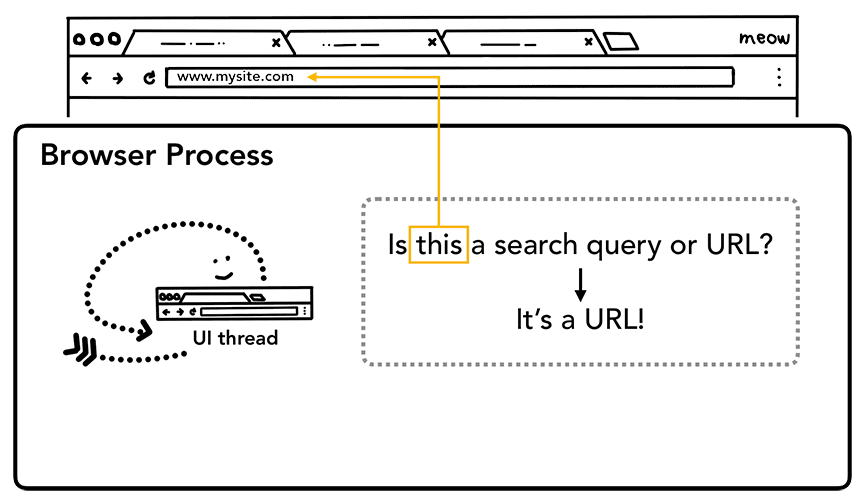
Paso 1: Controla la entrada
Cuando un usuario comienza a escribir en la barra de direcciones, lo primero que pregunta el subproceso de IU es "¿Es una búsqueda o una URL?". En Chrome, la barra de direcciones también es un campo de entrada de búsqueda, por lo que el subproceso de la IU debe analizar y decidir si te dirige a un motor de búsqueda o al sitio que solicitaste.
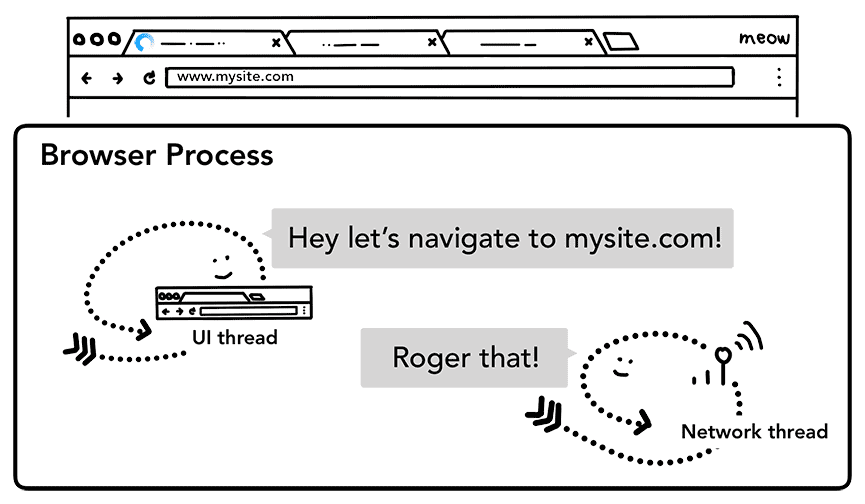
Paso 2: Inicia la navegación
Cuando un usuario presiona Intro, el subproceso de IU inicia una llamada de red para obtener el contenido del sitio. La lista de opciones de carga se muestra en la esquina de una pestaña, y el subproceso de red pasa por los protocolos adecuados, como la búsqueda de DNS y el establecimiento de la conexión TLS para la solicitud.
En este punto, el subproceso de red puede recibir un encabezado de redireccionamiento del servidor, como HTTP 301. En ese caso, el subproceso de red se comunica con el subproceso de IU que el servidor solicita el redireccionamiento. Luego, se iniciará otra solicitud de URL.
Paso 3: Lee la respuesta
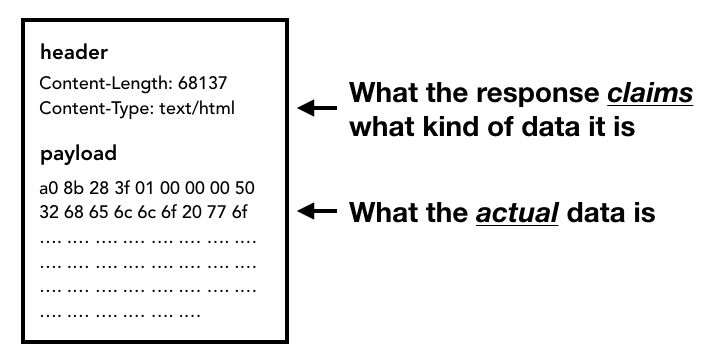
Una vez que comienza a llegar el cuerpo de la respuesta (carga útil), el subproceso de red observa los primeros bytes del flujo si es necesario. El encabezado Content-Type de la respuesta debe indicar qué tipo de datos son, pero, como es posible que falte o sea incorrecto, aquí se realiza el análisis de tipo de MIME. Esta es una "tarea complicada", como se comenta en el código fuente. Puedes leer el comentario para ver cómo los diferentes navegadores tratan los pares de tipo de contenido/carga útil.
Si la respuesta es un archivo HTML, el siguiente paso sería pasar los datos al proceso del renderizador, pero si es un archivo ZIP o algún otro archivo, significa que es una solicitud de descarga, por lo que deben pasar los datos al administrador de descargas.
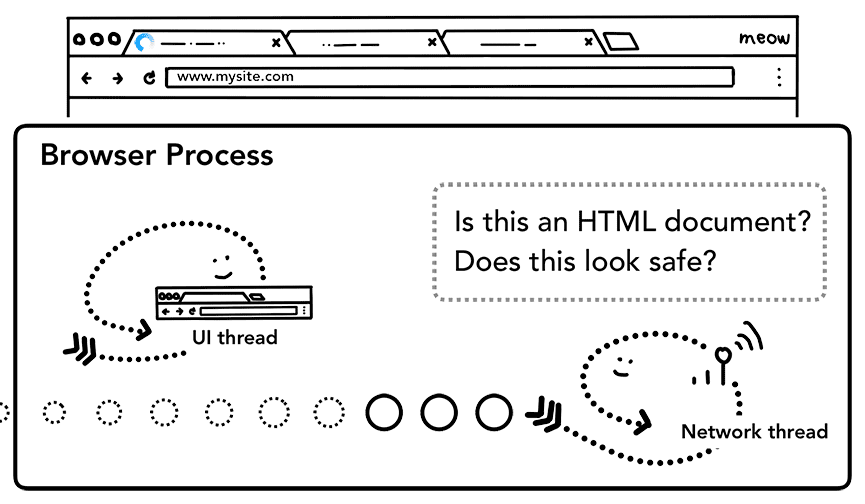
Aquí también se realiza la verificación de SafeBrowsing. Si el dominio y los datos de respuesta parecen coincidir con un sitio malicioso conocido, el subproceso de red alerta para mostrar una página de advertencia. Además, se realiza la verificación de Cross Origin Read Blocking (CORB) para garantizar que los datos sensibles entre sitios no lleguen al proceso del renderizador.
Paso 4: Busca un proceso de renderización
Una vez que se realizan todas las verificaciones y el subproceso de red tiene la certeza de que el navegador debe navegar al sitio solicitado, le indica al subproceso de IU que los datos están listos. Luego, el subproceso de la IU encuentra un proceso de renderización para continuar con la renderización de la página web.
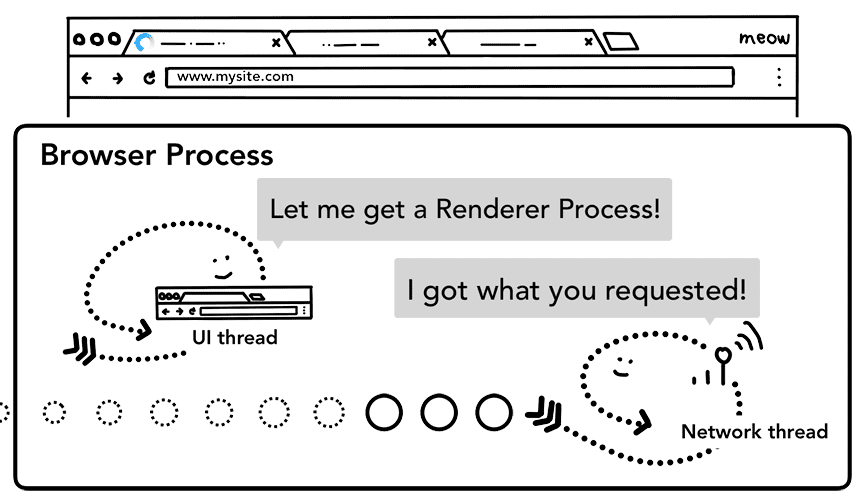
Dado que la solicitud de red puede tardar varios cientos de milisegundos en recibir una respuesta, se aplica una optimización para acelerar este proceso. Cuando el subproceso de IU envía una solicitud de URL al subproceso de red en el paso 2, ya sabe a qué sitio se está navegando. El subproceso de la IU intenta encontrar o iniciar de forma proactiva un proceso de renderización en paralelo con la solicitud de red. De esta manera, si todo va según lo esperado, un proceso de renderización ya está en modo de espera cuando el subproceso de red recibe datos. Es posible que este proceso en espera no se use si la navegación redirecciona entre sitios, en cuyo caso es posible que se necesite un proceso diferente.
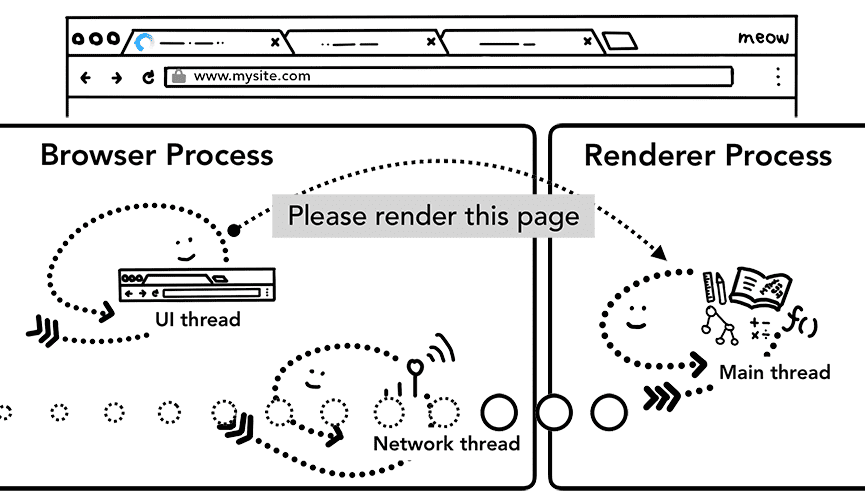
Paso 5: Confirma la navegación
Ahora que los datos y el proceso del renderizador están listos, se envía un IPC del proceso del navegador al proceso del renderizador para confirmar la navegación. También pasa la transmisión de datos para que el proceso del renderizador pueda seguir recibiendo datos HTML. Una vez que el proceso del navegador recibe la confirmación de que se realizó la confirmación en el proceso del renderizador, se completa la navegación y comienza la fase de carga del documento.
En este punto, se actualiza la barra de direcciones, y el indicador de seguridad y la IU de configuración del sitio reflejan la información del sitio de la página nueva. Se actualizará el historial de la sesión de la pestaña para que los botones Atrás/Adelante muestren el sitio al que se acaba de navegar. Para facilitar el restablecimiento de pestañas o sesiones cuando cierras una pestaña o ventana, el historial de la sesión se almacena en el disco.
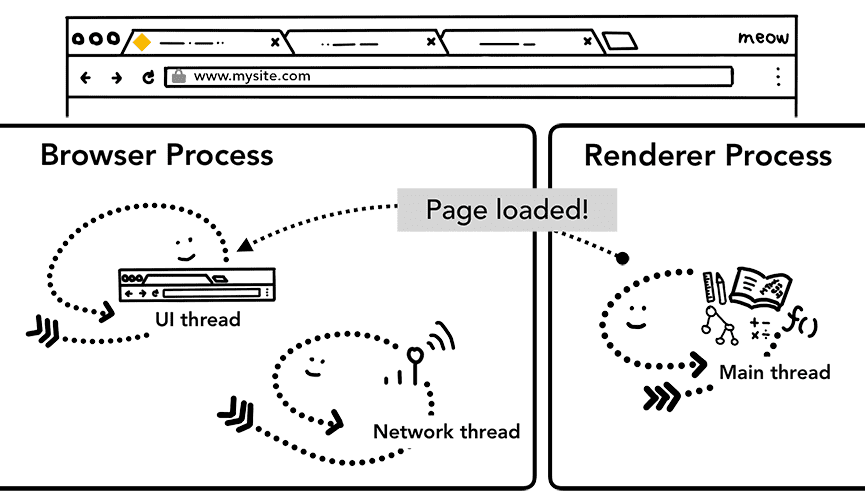
Paso adicional: Se completó la carga inicial
Una vez que se confirma la navegación, el proceso del renderizador continúa cargando recursos y renderiza la página. En la próxima publicación, analizaremos los detalles de lo que sucede en esta etapa. Una vez que el proceso del renderizador "finaliza" la renderización, envía un IPC al proceso del navegador (esto ocurre después de que se activan todos los eventos onload en todos los fotogramas de la página y se terminan de ejecutar). En este punto, el subproceso de IU detiene la lista de opciones de carga en la pestaña.
Digo "finaliza" porque el código JavaScript del cliente aún podría cargar recursos adicionales y renderizar vistas nuevas después de este punto.
Navegar a otro sitio
Se completó la navegación simple. Pero, ¿qué sucede si un usuario vuelve a ingresar una URL diferente en la barra de direcciones? Bueno, el proceso del navegador sigue los mismos pasos para navegar a los diferentes sitios.
Sin embargo, antes de poder hacerlo, debe verificar con el sitio renderizado actualmente si le importa el evento beforeunload.
beforeunload puede crear la alerta "¿Quieres salir de este sitio?" cuando intentes salir de la pestaña o cerrarla.
El proceso del renderizador controla todo el contenido de una pestaña, incluido tu código JavaScript, por lo que el proceso del navegador debe verificar con el proceso del renderizador actual cuando llega una nueva solicitud de navegación.
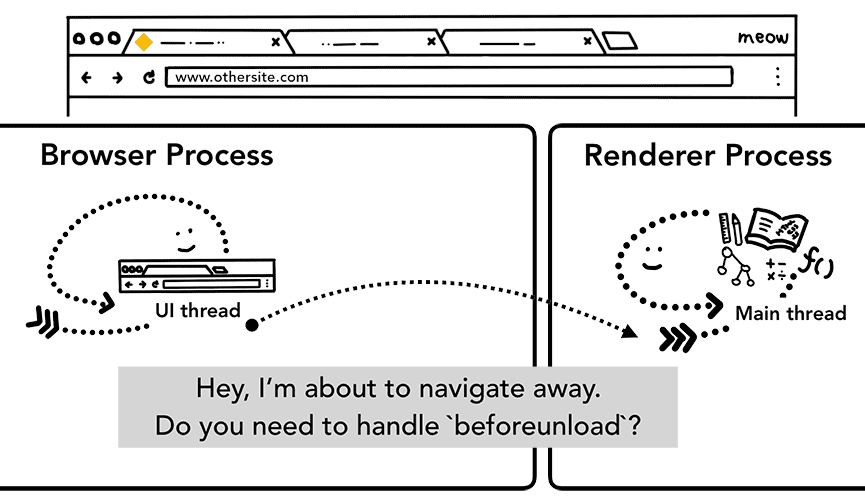
Si la navegación se inició desde el proceso del renderizador (por ejemplo, el usuario hizo clic en un vínculo o el JavaScript del cliente ejecutó window.location = "https://newsite.com"), el proceso del renderizador primero verifica los controladores beforeunload. Luego, pasa por el mismo proceso que el proceso del navegador inició la navegación. La única diferencia es que la solicitud de navegación se inicia desde el proceso del renderizador hasta el proceso del navegador.
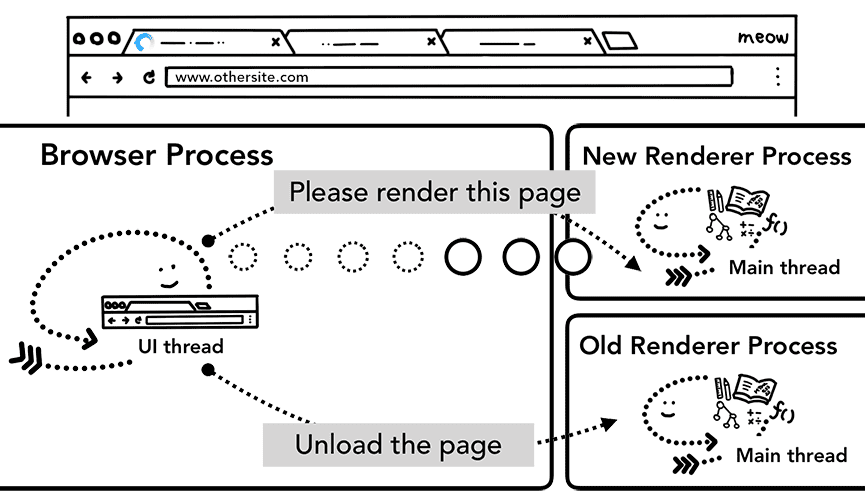
Cuando la nueva navegación se realiza a un sitio diferente del que se renderiza actualmente, se llama a un proceso de renderización independiente para controlar la nueva navegación, mientras que el proceso de renderización actual se mantiene para controlar eventos como unload. Para obtener más información, consulta una descripción general de los estados del ciclo de vida de la página y cómo puedes conectar eventos con la API de Page Lifecycle.
En el caso de Service Worker
Un cambio reciente en este proceso de navegación es la introducción del trabajador de servicio. El trabajador de servicio es una forma de escribir un proxy de red en el código de tu aplicación, lo que permite que los desarrolladores web tengan más control sobre qué almacenar en caché de forma local y cuándo obtener datos nuevos de la red. Si el service worker está configurado para cargar la página desde la caché, no es necesario solicitar los datos a la red.
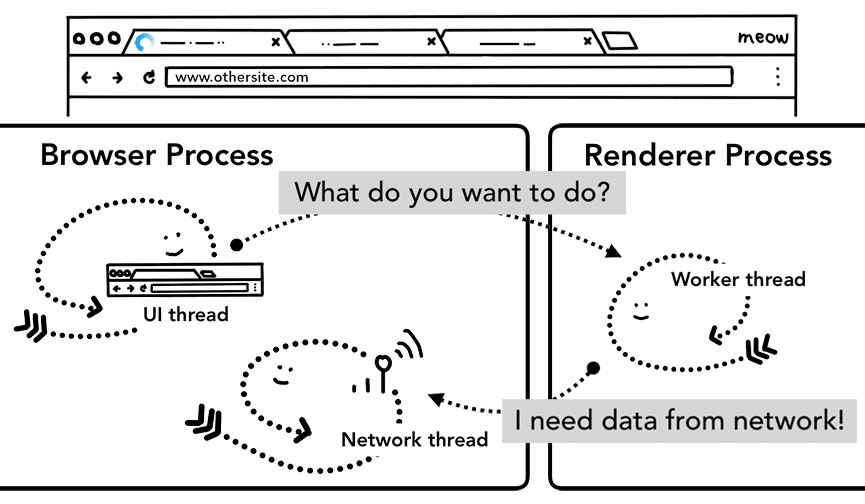
Lo importante que debes recordar es que el servicio de trabajo es un código JavaScript que se ejecuta en un proceso de renderización. Pero, cuando llega la solicitud de navegación, ¿cómo sabe un proceso del navegador que el sitio tiene un trabajador de servicio?

Cuando se registra un trabajador de servicio, su alcance se mantiene como referencia (puedes obtener más información sobre el alcance en este artículo sobre el ciclo de vida del trabajador de servicio). Cuando se produce una navegación, el subproceso de red verifica el dominio en función de los alcances registrados del trabajador de servicio. Si se registra un trabajador de servicio para esa URL, el subproceso de IU encuentra un proceso de renderización para ejecutar el código del trabajador de servicio. El trabajador del servicio puede cargar datos de la caché, lo que elimina la necesidad de solicitar datos a la red, o puede solicitar recursos nuevos a la red.
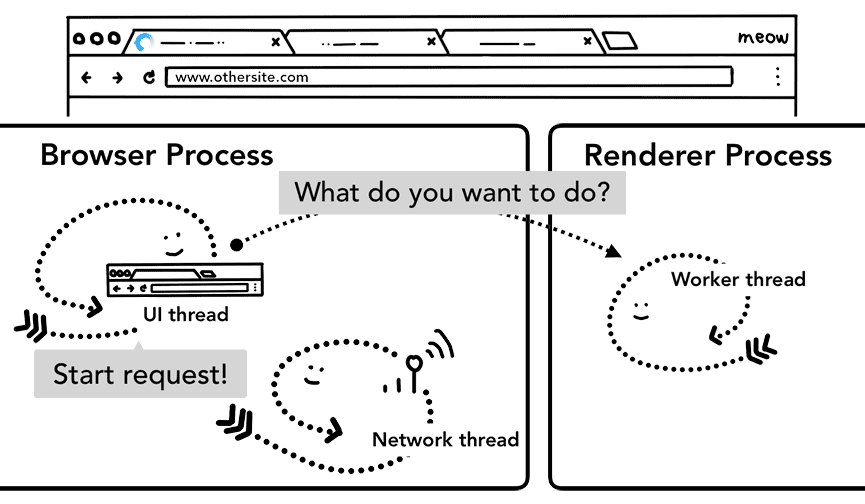
Carga previa de navegación
Puedes ver que este recorrido entre el proceso del navegador y el proceso del renderizador podría generar demoras si el trabajador de servicio decide solicitar datos a la red. La carga previa de navegación es un mecanismo para acelerar este proceso cargando recursos en paralelo con el inicio del trabajador de servicio. Marca estas solicitudes con un encabezado, lo que permite que los servidores decidan enviar contenido diferente para estas solicitudes; por ejemplo, solo datos actualizados en lugar de un documento completo.
Conclusión
En esta publicación, analizamos qué sucede durante una navegación y cómo el código de tu aplicación web, como los encabezados de respuesta y el código JavaScript del cliente, interactúa con el navegador. Conocer los pasos que realiza el navegador para obtener datos de la red facilita la comprensión de por qué se desarrollaron APIs como la carga previa de navegación. En la próxima publicación, analizaremos cómo el navegador evalúa nuestro código HTML/CSS/JavaScript para renderizar páginas.
¿Te gustó la publicación? Si tienes alguna pregunta o sugerencia para una próxima publicación, nos encantaría que nos escribieras en la sección de comentarios a continuación o en @kosamari en Twitter.
Siguiente: Funcionamiento interno de un proceso de renderización