

Veröffentlichung: 10. Oktober 2025

Das klassische Brettspiel Wer bin ich? ist ein Meisterwerk des deduktiven Denkens. Jeder Spieler beginnt mit einem Brett mit Gesichtern und schränkt durch eine Reihe von Ja- oder Nein-Fragen die Möglichkeiten ein, bis er den geheimen Charakter seines Gegners sicher identifizieren kann.
Nachdem ich auf der Google I/O Connect eine Demo von integrierter KI gesehen hatte, fragte ich mich, was wäre, wenn ich ein „Wer bin ich?“-Spiel gegen eine KI spielen könnte, die im Browser läuft. Mit clientseitiger KI würden die Fotos lokal interpretiert. Ein benutzerdefiniertes „Wer bin ich?“ mit Freunden und Familie bliebe also privat und sicher auf meinem Gerät.
Ich habe hauptsächlich Erfahrung in der UI- und UX-Entwicklung und bin es gewohnt, pixelgenaue Benutzeroberflächen zu erstellen. Genau das wollte ich mit meiner Interpretation erreichen.
Meine Anwendung AI Guess Who? (KI-Ratespiel) basiert auf React und verwendet die Prompt API und ein im Browser integriertes Modell, um einen überraschend leistungsfähigen Gegner zu erstellen. Dabei habe ich festgestellt, dass es gar nicht so einfach ist, „pixelgenaue“ Ergebnisse zu erzielen. Diese Anwendung zeigt jedoch, wie KI verwendet werden kann, um eine durchdachte Spiellogik zu erstellen, und wie wichtig Prompt Engineering ist, um diese Logik zu verfeinern und die gewünschten Ergebnisse zu erzielen.
Lesen Sie weiter, um mehr über die integrierte KI-Integration, die Herausforderungen, denen ich gegenüberstand, und die Lösungen zu erfahren, die ich gefunden habe. Sie können das Spiel spielen und den Quellcode auf GitHub aufrufen.
Grundlage des Spiels: Eine React-App
Bevor wir uns die KI-Implementierung ansehen, wollen wir uns die Struktur der Anwendung ansehen. Ich habe eine Standard-React-Anwendung mit TypeScript erstellt, mit einer zentralen App.tsx-Datei, die als Dirigent des Spiels fungiert. Diese Datei enthält:
- Spielstatus: Eine Enumeration, die die aktuelle Phase des Spiels verfolgt (z. B.
PLAYER_TURN_ASKING,AI_TURN,GAME_OVER). Dies ist der wichtigste Status, da er bestimmt, was auf der Benutzeroberfläche angezeigt wird und welche Aktionen dem Spieler zur Verfügung stehen. - Figurenlisten: Es gibt mehrere Listen, in denen die aktiven Figuren, die geheime Figur jedes Spielers und die Figuren, die vom Brett entfernt wurden, aufgeführt sind.
- Spielchat: Ein fortlaufendes Protokoll von Fragen, Antworten und Systemnachrichten.
Die Benutzeroberfläche ist in logische Komponenten unterteilt:

Mit den Funktionen des Spiels wuchs auch seine Komplexität. Anfangs wurde die gesamte Spiellogik in einem einzigen, großen benutzerdefinierten React-Hook (useGameLogic) verwaltet. Dieser wurde jedoch schnell zu groß, um darin zu navigieren und Fehler zu beheben. Um die Wartbarkeit zu verbessern, habe ich diesen Hook in mehrere Hooks mit jeweils einer einzigen Verantwortung umgestaltet.
Beispiel:
useGameStateverwaltet den HauptstatususePlayerActions– Spieler ist an der ReiheuseAIActionsist für die Logik der KI
Der Haupt-useGameLogic-Hook fungiert jetzt als sauberer Composer, in dem diese kleineren Hooks zusammengefasst werden. Diese architektonische Änderung hat die Funktionalität des Spiels nicht beeinträchtigt, aber die Codebasis erheblich übersichtlicher gemacht.
Spiellogik mit der Prompt API
Das Herzstück dieses Projekts ist die Verwendung der Prompt API.
Ich habe die KI-Spiellogik zu builtInAIService.ts hinzugefügt. Das sind die wichtigsten Aufgaben:
- Restriktive, binäre Antworten zulassen.
- Dem Modell eine Spielstrategie beibringen
- Modellanalyse beibringen
- Geben Sie dem Modell Amnesie.
Restriktive, binäre Antworten zulassen
Wie interagiert der Spieler mit der KI? Wenn ein Spieler fragt: „Hat dein Charakter einen Hut?“, muss die KI sich das Bild des geheimen Charakters ansehen und eine klare Antwort geben.
Meine ersten Versuche waren ein Chaos. Die Antwort war dialogorientiert: „Nein, die Figur, an die ich denke, Isabella, trägt anscheinend keinen Hut“, anstatt mit einem einfachen „Ja“ oder „Nein“ zu antworten. Zuerst habe ich das Problem mit einem sehr strengen Prompt gelöst, der dem Modell im Grunde vorschrieb, nur mit „Ja“ oder „Nein“ zu antworten.
Das hat zwar funktioniert, aber ich habe eine noch bessere Methode mit strukturierter Ausgabe kennengelernt. Durch die Bereitstellung des JSON-Schemas für das Modell konnte ich eine Antwort mit „Wahr“ oder „Falsch“ garantieren.
const schema = { type: "boolean" };
const result = session.prompt(prompt, { responseConstraint: schema });
So konnte ich den Prompt vereinfachen und meinen Code die Antwort zuverlässig verarbeiten lassen:
JSON.parse(result) ? "Yes" : "No"
Dem Modell eine Spielstrategie beibringen
Es ist viel einfacher, dem Modell zu sagen, dass es eine Frage beantworten soll, als es Fragen stellen zu lassen. Ein guter „Wer bin ich?“-Spieler stellt keine zufälligen Fragen. Sie stellen Fragen, mit denen möglichst viele Zeichen auf einmal ausgeschlossen werden. Eine ideale Frage halbiert die Anzahl der möglichen verbleibenden Zeichen durch binäre Fragen.
Wie bringen Sie einem Modell diese Strategie bei? Auch hier ist Prompt Engineering gefragt. Der Prompt für generateAIQuestion() ist eigentlich eine kurze Lektion in der Spieltheorie von „Wer bin ich?“.
Zuerst habe ich das Modell gebeten, „eine gute Frage zu stellen“. Die Ergebnisse waren unvorhersehbar. Um die Ergebnisse zu verbessern, habe ich negative Einschränkungen hinzugefügt. Der Prompt enthält jetzt Anweisungen wie:
- „WICHTIG: NUR nach vorhandenen Funktionen fragen“
- „KRITISCH: Erstelle originelle Inhalte. Wiederhole KEINE Frage.“
Diese Einschränkungen verengen den Fokus des Modells und verhindern, dass es irrelevante Fragen stellt. Dadurch wird es zu einem viel angenehmeren Gegner. Sie können die vollständige Prompt-Datei auf GitHub ansehen.
Modellanalyse beibringen
Das war mit Abstand die schwierigste und wichtigste Herausforderung. Wenn das Modell eine Frage stellt, z. B. „Hat deine Figur einen Hut?“, und der Spieler mit „Nein“ antwortet, wie weiß das Modell dann, welche Figuren auf dem Brett des Spielers ausgeschlossen werden?
Das Modell soll alle Personen mit Hut eliminieren. Meine ersten Versuche waren von Logikfehlern geprägt. Manchmal hat das Modell die falschen Zeichen oder gar keine Zeichen entfernt. Was ist ein „Hut“? Zählt eine „Mütze“ als „Hut“? Das kann, seien wir ehrlich, auch in einer Diskussion zwischen Menschen passieren. Natürlich können auch allgemeine Fehler auftreten. Aus Sicht der KI kann Haar wie ein Hut aussehen.
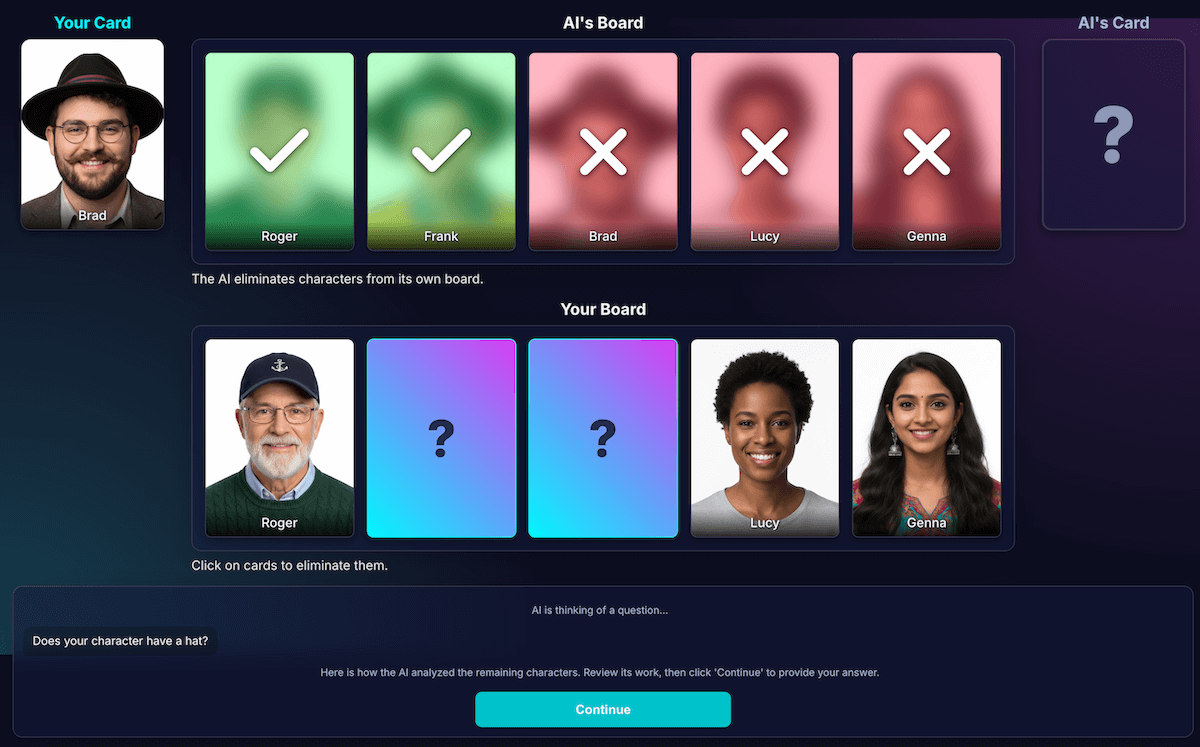
Ich habe die Architektur so umgestaltet, dass die Wahrnehmung von der Codeableitung getrennt ist:
KI ist für die visuelle Analyse verantwortlich. Modelle eignen sich hervorragend für die visuelle Analyse. Ich habe das Modell angewiesen, seine Frage und eine detaillierte Analyse in einem strengen JSON-Schema zurückzugeben. Das Modell analysiert jedes Zeichen auf dem Board und beantwortet die Frage: „Hat dieses Zeichen dieses Merkmal?“ Das Modell gibt ein strukturiertes JSON-Objekt zurück:
{ "character_id": "...", "has_feature": true }Auch hier sind strukturierte Daten der Schlüssel zum Erfolg.
Der Spielcode verwendet die Analyse, um die endgültige Entscheidung zu treffen. Der Anwendungscode prüft die Antwort des Spielers („Ja“ oder „Nein“) und durchläuft die Analyse der KI. Wenn der Spieler „Nein“ gesagt hat, werden alle Zeichen entfernt, bei denen
has_featuregleichtrueist.
Diese Aufteilung der Aufgaben ist entscheidend für die Entwicklung zuverlässiger KI-Anwendungen. Nutzen Sie die KI für ihre Analysefunktionen und überlassen Sie binäre Entscheidungen Ihrem Anwendungscode.
Um die Wahrnehmung des Modells zu überprüfen, habe ich eine Visualisierung dieser Analyse erstellt. So ließ sich leichter bestätigen, ob die Wahrnehmung des Modells korrekt war.
Prompt Engineering
Trotz dieser Trennung habe ich jedoch festgestellt, dass die Wahrnehmung des Modells immer noch fehlerhaft sein kann. Es kann fälschlicherweise annehmen, dass eine Figur eine Brille trägt, was zu einer frustrierenden, falschen Eliminierung führt. Um dem entgegenzuwirken, habe ich einen zweistufigen Prozess ausprobiert: Die KI stellt ihre Frage. Nachdem die Antwort des Spielers eingegangen ist, wird eine zweite, neue Analyse mit der Antwort als Kontext durchgeführt. Die Theorie war, dass bei einer zweiten Überprüfung Fehler aus der ersten gefunden werden könnten.
So hätte der Ablauf funktioniert:
- KI-Antwort (API-Aufruf 1): Die KI fragt: „Hat deine Figur einen Bart?“
- Spieler ist an der Reihe: Der Spieler sieht sich seinen geheimen Charakter an, der glatt rasiert ist, und antwortet mit „Nein“.
- KI-Zug (API-Aufruf 2): Die KI fordert sich selbst auf, alle verbleibenden Zeichen noch einmal zu betrachten und anhand der Antwort des Spielers zu entscheiden, welche eliminiert werden sollen.
In Schritt 2 kann es passieren, dass das Modell eine Person mit leichten Stoppeln fälschlicherweise als „ohne Bart“ einstuft und nicht entfernt, obwohl der Nutzer das erwartet hat. Der grundlegende Wahrnehmungsfehler wurde nicht behoben und der zusätzliche Schritt hat die Ergebnisse nur verzögert. Wenn wir gegen einen menschlichen Gegner spielen, können wir eine Vereinbarung oder Klarstellung dazu treffen. In der aktuellen Konfiguration mit unserem KI-Gegner ist das nicht der Fall.
Dieser Prozess führte zu einer zusätzlichen Latenz durch einen zweiten API-Aufruf, ohne dass die Genauigkeit wesentlich gesteigert wurde. Wenn das Modell beim ersten Mal falsch lag, lag es oft auch beim zweiten Mal falsch. Ich habe den Prompt so geändert, dass die Überprüfung nur einmal erfolgt.
Analysen verbessern, anstatt weitere hinzuzufügen
Ich habe mich auf ein UX-Prinzip verlassen: Die Lösung war nicht mehr Analyse, sondern bessere Analyse.
Ich habe viel Zeit in die Optimierung des Prompts investiert und explizite Anweisungen hinzugefügt, damit das Modell seine Arbeit noch einmal überprüft und sich auf bestimmte Funktionen konzentriert. Das hat sich als effektivere Strategie zur Verbesserung der Genauigkeit erwiesen. So funktioniert der aktuelle, zuverlässigere Ablauf:
KI-Turn (API-Aufruf): Das Modell wird aufgefordert, sowohl seine Frage als auch seine interne Analyse gleichzeitig zu generieren und ein einzelnes JSON-Objekt zurückzugeben.
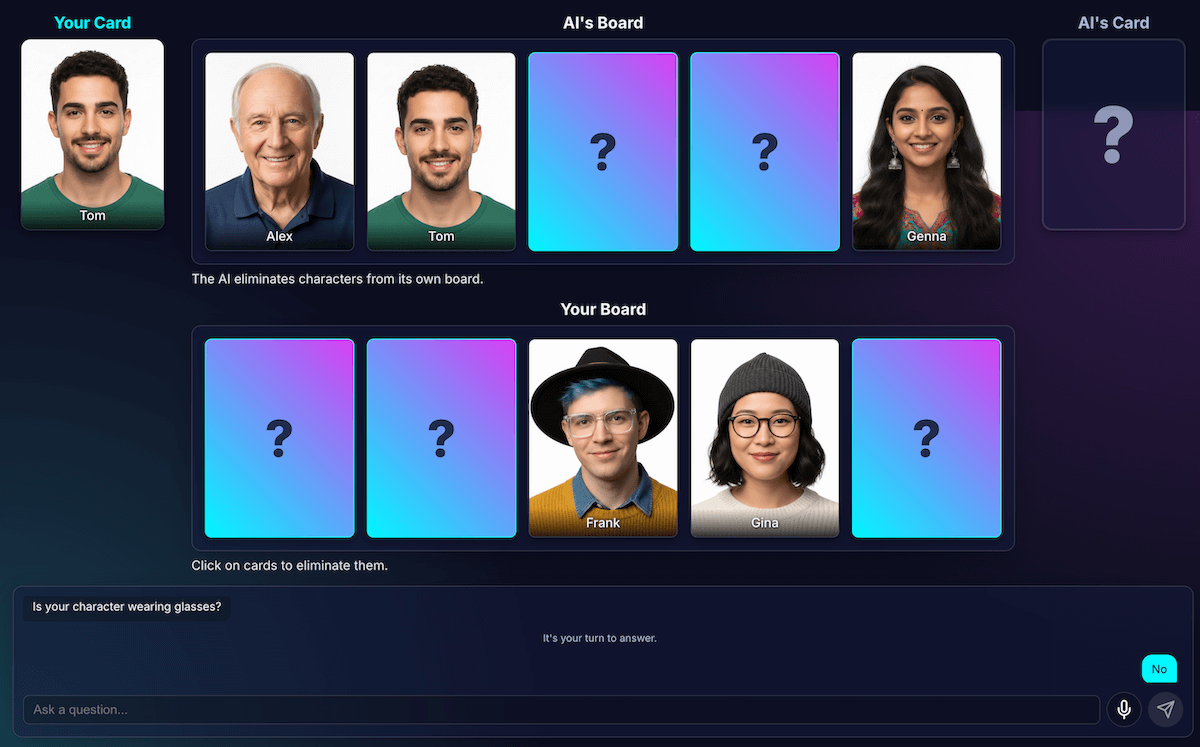
- Frage: „Trägt deine Figur eine Brille?“
- Analyse (Daten):
[ {character_id: 'brad', has_feature: true}, {character_id: 'alex', has_feature: false}, {character_id: 'gina', has_feature: true}, ... ]Spieler ist an der Reihe: Die geheime Figur des Spielers ist Alex (ohne Brille). Er antwortet also mit „Nein“.
Runde endet: Der JavaScript-Code der Anwendung wird ausgeführt. Die KI muss nichts weiter fragen. Die Analysedaten aus Schritt 1 werden durchlaufen.
- Der Spieler hat „Nein“ gesagt.
- Der Code sucht nach jedem Zeichen, für das
has_featurezutrifft. - Es klappt Brad und Gina nach unten. Die Logik ist deterministisch und sofortig.
Diese Experimente waren entscheidend, erforderten aber viel Ausprobieren. Ich hatte keine Ahnung, ob es besser werden würde. Manchmal wurde es sogar noch schlimmer. Es ist nicht ganz einfach, herauszufinden, wie Sie die konsistentesten Ergebnisse erzielen.
Nach einigen Runden mit meinem neuen KI-Gegner trat jedoch ein fantastisches neues Problem auf: ein Patt.
Deadlock beenden
Wenn nur noch zwei oder drei sehr ähnliche Zeichen übrig waren, blieb das Modell in einer Schleife hängen. Es wurde eine Frage zu einem gemeinsamen Merkmal gestellt, z. B. „Trägt deine Figur einen Hut?“.
Mein Code würde dies korrekt als verschwendeten Zug erkennen und die KI würde eine andere, ebenso allgemeine Funktion ausprobieren, die die Charaktere auch alle gemeinsam haben, z. B. „Trägt deine Figur eine Brille?“
Ich habe den Prompt um eine neue Regel erweitert: Wenn ein Versuch, eine Frage zu generieren, fehlschlägt und noch maximal drei Zeichen übrig sind, ändert sich die Strategie.
Die neue Anleitung ist eindeutig: „Anstatt nach einer allgemeinen Funktion müssen Sie nach einer spezifischeren, einzigartigen oder kombinierten visuellen Funktion fragen, um einen Unterschied zu finden.“ Anstatt zu fragen, ob die Figur einen Hut trägt, wird sie aufgefordert, zu fragen, ob sie eine Baseballkappe trägt.
Dadurch wird das Modell gezwungen, sich die Bilder genauer anzusehen, um das eine kleine Detail zu finden, das schließlich zu einem Durchbruch führen kann. So funktioniert die Late-Game-Strategie meistens etwas besser.
Dem Modell Amnesie geben
Die größte Stärke eines Language Models ist sein Gedächtnis. In diesem Spiel wurde seine größte Stärke jedoch zu einer Schwäche. Wenn ich ein zweites Spiel gestartet habe, wurden verwirrende oder irrelevante Fragen gestellt. Mein KI-Gegner behielt natürlich den gesamten Chatverlauf aus dem vorherigen Spiel bei. Es hat versucht, zwei (oder sogar mehr) Spiele gleichzeitig zu analysieren.
Anstatt dieselbe KI-Sitzung wiederzuverwenden, zerstöre ich sie jetzt explizit am Ende jedes Spiels, wodurch die KI ihr Gedächtnis verliert.
Wenn Sie auf Nochmal spielen klicken, wird das Brett durch die Funktion startNewGameSession() zurückgesetzt und eine neue KI-Sitzung erstellt. Das war eine interessante Lektion im Verwalten des Sitzungsstatus nicht nur in der App, sondern auch im KI-Modell selbst.
Zusatzfunktionen: Benutzerdefinierte Spiele und Spracheingabe
Um die Nutzung noch ansprechender zu gestalten, habe ich zwei zusätzliche Funktionen hinzugefügt:
Benutzerdefinierte Charaktere: Mit
getUserMedia()können Spieler mit ihrer Kamera einen eigenen Satz aus fünf Zeichen erstellen. Ich habe IndexedDB verwendet, um die Zeichen zu speichern. Das ist eine Browserdatenbank, die sich perfekt zum Speichern von Binärdaten wie Image-Blobs eignet. Wenn Sie ein benutzerdefiniertes Set erstellen, wird es in Ihrem Browser gespeichert und im Hauptmenü wird eine Option zum Wiederholen angezeigt.Spracheingabe: Das clientseitige Modell ist multimodal. Das Modell kann Text, Bilder und Audio verarbeiten. Mit der MediaRecorder API konnte ich Mikrofoneingaben erfassen und den resultierenden Audio-Blob mit einem Prompt an das Modell senden: „Transkribiere das folgende Audio…“. So macht das Spielen noch mehr Spaß – und es ist auch lustig zu sehen, wie meine flämische Aussprache interpretiert wird. Ich habe diese Funktion hauptsächlich entwickelt, um die Vielseitigkeit dieser neuen Webfunktion zu demonstrieren. Aber ehrlich gesagt hatte ich es auch satt, Fragen immer wieder neu einzugeben.
Demo
Sie können das Spiel direkt hier testen oder in einem neuen Fenster spielen. Den Quellcode finden Sie auf GitHub.
Schlussgedanken
Die Entwicklung von „KI-Wer bin ich?“ war definitiv eine Herausforderung. Aber mit ein wenig Hilfe aus der Dokumentation und etwas KI, um KI zu debuggen (ja, Ich habe das gemacht und es hat sich als lustiges Experiment herausgestellt. Es hat das immense Potenzial eines Modells im Browser für eine private, schnelle und internetunabhängige Nutzung aufgezeigt. Dies ist noch ein Experiment und manchmal spielt der Gegner einfach nicht perfekt. Es ist nicht pixel- oder logikperfekt. Bei generativer KI sind die Ergebnisse modellabhängig.
Anstatt nach Perfektion zu streben, versuche ich, das Ergebnis zu verbessern.
Dieses Projekt hat auch die ständigen Herausforderungen des Prompt-Engineerings unterstrichen. Das Prompting wurde zu einem wichtigen Teil des Prozesses, aber nicht immer zum angenehmsten. Die wichtigste Lektion, die ich gelernt habe, war jedoch, die Anwendung so zu konzipieren, dass Wahrnehmung und Schlussfolgerung getrennt werden und die Funktionen von KI und Code aufgeteilt werden. Trotz dieser Trennung habe ich festgestellt, dass die KI immer noch (für einen Menschen) offensichtliche Fehler machen kann, z. B. Tattoos mit Make-up verwechseln oder den Überblick darüber verlieren, wessen geheimer Charakter gerade diskutiert wird.
Jedes Mal bestand die Lösung darin, die Prompts noch expliziter zu formulieren und Anweisungen hinzuzufügen, die für einen Menschen offensichtlich sind, aber für das Modell unerlässlich sind.
Manchmal fühlte sich das Spiel unfair an. Manchmal hatte ich das Gefühl, dass die KI die geheime Figur schon kannte, obwohl diese Information im Code nie explizit weitergegeben wurde. Hier sehen Sie einen wichtigen Unterschied zwischen Mensch und Maschine:
Das Verhalten einer KI muss nicht nur korrekt sein, sondern sich auch fair anfühlen.
Deshalb habe ich die Prompts mit direkten Anweisungen wie „Du weißt NICHT, welche Figur ich ausgewählt habe“ und „Kein Schummeln“ aktualisiert. Ich habe gelernt, dass man beim Erstellen von KI-Agenten mehr Zeit für die Definition von Einschränkungen als für Anweisungen aufwenden sollte.
Die Interaktion mit dem Modell könnte weiter verbessert werden. Wenn Sie mit einem integrierten Modell arbeiten, verlieren Sie zwar etwas von der Leistungsfähigkeit und Zuverlässigkeit eines großen serverseitigen Modells, gewinnen aber an Datenschutz, Geschwindigkeit und Offline-Funktionen. Für ein Spiel wie dieses war es wirklich lohnenswert, damit zu experimentieren. Die Zukunft der clientseitigen KI wird von Tag zu Tag besser, die Modelle werden auch immer kleiner und ich bin gespannt, was wir als Nächstes entwickeln können.