

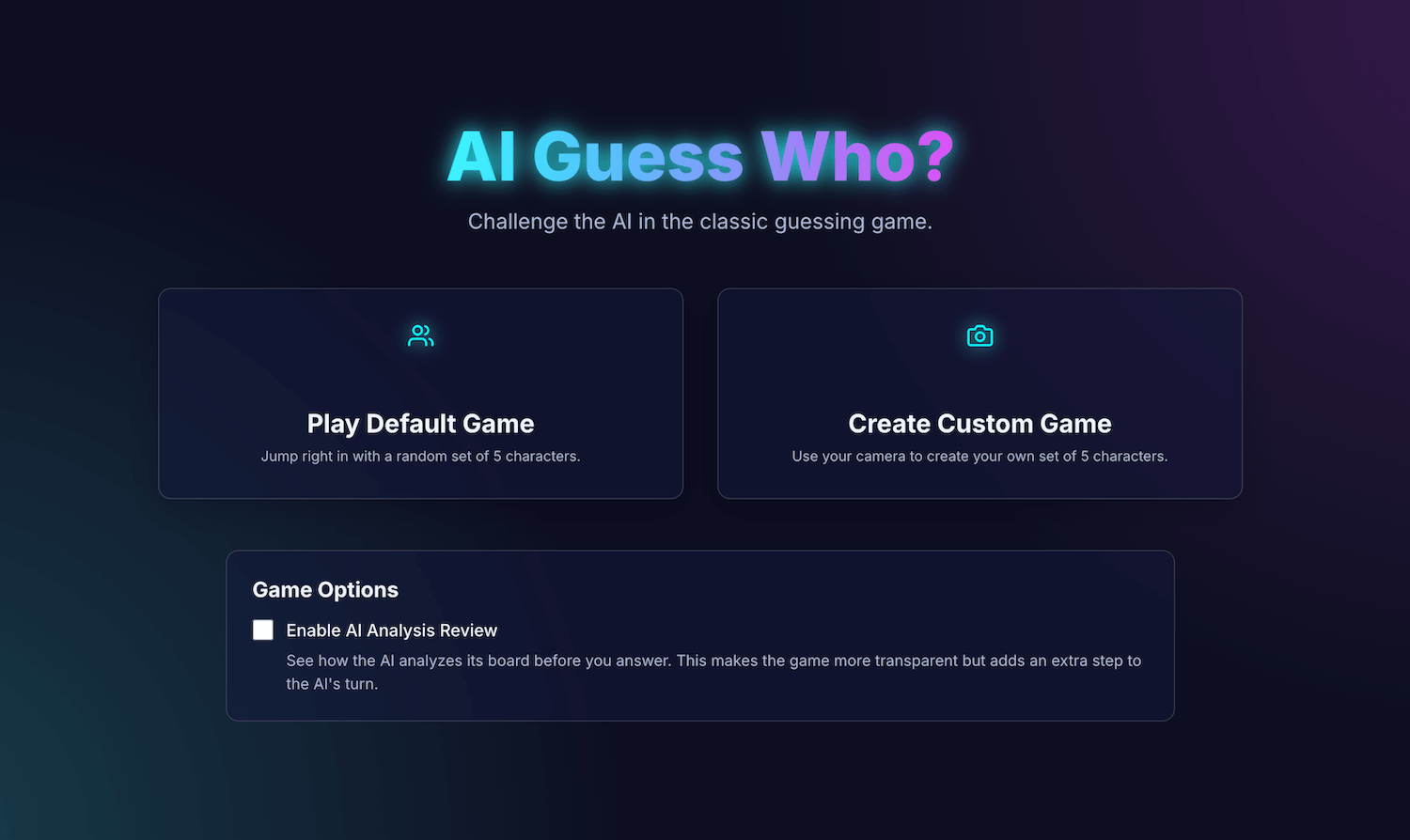
منتشر شده: ۱۰ اکتبر ۲۰۲۵

بازی تختهای کلاسیک « حدس بزن کیه؟ » یک کلاس درس در استدلال قیاسی است. هر بازیکن با یک تخته از چهرهها شروع میکند و از طریق یک سری سوالات بله یا خیر، احتمالات را محدود میکند تا زمانی که بتواند با اطمینان شخصیت مخفی حریف خود را شناسایی کند.
بعد از دیدن نسخه آزمایشی هوش مصنوعی داخلی در کنفرانس Google I/O Connect، با خودم فکر کردم: چه میشود اگر بتوانم یک بازی حدس بزن کی؟ (Guess Who?) را در مقابل هوش مصنوعی که در مرورگر زندگی میکند، بازی کنم؟ با هوش مصنوعی سمت کلاینت، عکسها به صورت محلی تفسیر میشوند، بنابراین یک حدس بزن کی؟ سفارشی از دوستان و خانواده در دستگاه من خصوصی و ایمن باقی میماند.
پیشینه من عمدتاً در توسعه رابط کاربری (UI) و تجربه کاربری (UX) است و به ساخت تجربیات پیکسلی بینقص عادت دارم. امیدوار بودم که بتوانم دقیقاً همین کار را با تفسیر خودم انجام دهم.
برنامه من، AI Guess Who?، با React ساخته شده است و از Prompt API و یک مدل داخلی مرورگر برای ایجاد یک حریف شگفتآور و توانمند استفاده میکند. در این فرآیند، متوجه شدم که رسیدن به نتایج "کاملاً بینقص" چندان ساده نیست. اما، این برنامه نشان میدهد که چگونه میتوان از هوش مصنوعی برای ساخت منطق بازی متفکرانه و اهمیت مهندسی سریع برای اصلاح این منطق و دستیابی به نتایج مورد انتظار استفاده کرد.
برای آشنایی با ادغام هوش مصنوعی داخلی، چالشهایی که با آنها روبرو شدم و راهحلهایی که به آنها رسیدم، به خواندن ادامه دهید. میتوانید بازی را انجام دهید و کد منبع را در گیتهاب پیدا کنید.
پایه بازی: یک برنامه React
قبل از اینکه به پیادهسازی هوش مصنوعی نگاهی بیندازید، ساختار برنامه را بررسی خواهیم کرد. من یک برنامه استاندارد React با TypeScript ساختم، با یک فایل مرکزی App.tsx که به عنوان هادی بازی عمل میکند. این فایل شامل موارد زیر است:
- وضعیت بازی : یک enum که مرحله فعلی بازی را ردیابی میکند (مانند
PLAYER_TURN_ASKING،AI_TURN،GAME_OVER). این مهمترین بخش وضعیت است، زیرا تعیین میکند که رابط کاربری چه چیزی را نمایش دهد و چه اقداماتی برای بازیکن در دسترس باشد. - فهرست شخصیتها : فهرستهای متعددی وجود دارد که شخصیتهای فعال، شخصیت مخفی هر بازیکن و شخصیتهای حذفشده از صفحه را مشخص میکند.
- چت بازی : گزارش در حال اجرا از سوالات، پاسخها و پیامهای سیستم.
رابط کاربری به اجزای منطقی تقسیم میشود:

با افزایش ویژگیهای بازی، پیچیدگی آن نیز افزایش یافت. در ابتدا، کل منطق بازی در یک هوک React سفارشی بزرگ و واحد به useGameLogic مدیریت میشد، اما به سرعت برای پیمایش و اشکالزدایی بیش از حد بزرگ شد. برای بهبود قابلیت نگهداری، این هوک را به چندین هوک، که هر کدام یک مسئولیت واحد داشتند، بازسازی کردم. به عنوان مثال:
-
useGameStateوضعیت اصلی را مدیریت میکند. -
usePlayerActionsبرای نوبت بازیکن است -
useAIActionsبرای منطق هوش مصنوعی است.
قلاب اصلی useGameLogic اکنون به عنوان یک آهنگساز تمیز عمل میکند و این قلابهای کوچکتر را در کنار هم قرار میدهد. این تغییر معماری عملکرد بازی را تغییر نداد، اما کدبیس را بسیار تمیزتر کرد.
منطق بازی با Prompt API
هسته اصلی این پروژه استفاده از Prompt API است.
من منطق بازی هوش مصنوعی را به builtInAIService.ts اضافه کردم. اینها مسئولیتهای کلیدی آن هستند:
- پاسخهای محدود و دوتایی را مجاز بدانید.
- استراتژی بازی الگو را آموزش دهید.
- آموزش تحلیل مدل.
- به مدل فراموشی بدهید.
اجازه دادن به پاسخهای محدود و دودویی
بازیکن چگونه با هوش مصنوعی تعامل میکند؟ وقتی بازیکنی میپرسد: «آیا شخصیت شما کلاه دارد؟»، هوش مصنوعی باید به تصویر شخصیت مخفی خود «نگاه» کند و پاسخ روشنی بدهد.
اولین تلاشهای من افتضاح بود. پاسخ به صورت محاورهای بود: «نه، شخصیتی که من به آن فکر میکنم، ایزابلا، به نظر نمیرسد کلاه داشته باشد»، به جای اینکه یک بله یا خیر دوتایی ارائه دهد. در ابتدا، من این مشکل را با یک سوال بسیار دقیق حل کردم، اساساً به مدل دیکته کردم که فقط با «بله» یا «خیر» پاسخ دهد.
در حالی که این روش جواب میداد، من با استفاده از خروجی ساختاریافته ، روش بهتری را یاد گرفتم. با ارائه JSON Schema به مدل، میتوانستم یک پاسخ درست یا غلط را تضمین کنم.
const schema = { type: "boolean" };
const result = session.prompt(prompt, { responseConstraint: schema });
این به من اجازه داد تا اعلان را ساده کنم و اجازه دهم کد من به طور قابل اعتمادی پاسخ را مدیریت کند:
JSON.parse(result) ? "Yes" : "No"
استراتژی بازی مدل را آموزش دهید
اینکه به مدل بگوییم به یک سوال پاسخ دهد بسیار سادهتر از این است که از او بخواهیم خودش شروع به پرسیدن سوال کند. یک بازیکن خوب در بازی حدس بزن چه کسی؟ سوالات تصادفی نمیپرسد. آنها سوالاتی میپرسند که بیشترین تعداد کاراکتر را به طور همزمان حذف میکند. یک سوال ایدهآل، کاراکترهای باقیمانده احتمالی را با استفاده از سوالات دودویی به نصف کاهش میدهد.
چگونه این استراتژی را به یک مدل آموزش میدهید؟ باز هم، مهندسی سریع. دستور generateAIQuestion() در واقع یک درس مختصر در نظریه بازی Guess Who? است.
در ابتدا، از مدل خواستم که «یک سوال خوب بپرسد». نتایج غیرقابل پیشبینی بودند. برای بهبود نتایج، محدودیتهای منفی اضافه کردم. اکنون دستورالعملها شامل موارد زیر است:
- «مهم: فقط در مورد ویژگیهای موجود سوال کنید»
- «نکته مهم: اصیل باشید. یک سوال را تکرار نکنید.»
این محدودیتها تمرکز مدل را محدود میکنند، از پرسیدن سوالات نامربوط جلوگیری میکنند، که آن را به یک رقیب بسیار لذتبخشتر تبدیل میکند. میتوانید فایل کامل prompt را در GitHub بررسی کنید.
آموزش تحلیل مدل
این، تا حد زیادی، سختترین و مهمترین چالش بود. وقتی مدل سوالی میپرسد، مثلاً «آیا شخصیت شما کلاه دارد؟» و بازیکن پاسخ منفی میدهد، مدل از کجا میفهمد کدام شخصیتها از صفحه او حذف شدهاند؟
مدل باید همه کسانی که کلاه دارند را حذف کند. تلاشهای اولیه من با خطاهای منطقی مواجه شد و گاهی اوقات مدل شخصیتهای اشتباه یا هیچ شخصیتی را حذف نمیکرد. همچنین، «کلاه» چیست؟ آیا «کلاه بافتنی» هم «کلاه» محسوب میشود؟ بیایید صادق باشیم، این هم چیزی است که میتواند در یک بحث انسانی اتفاق بیفتد. و البته، اشتباهات عمومی اتفاق میافتد. مو میتواند از دیدگاه هوش مصنوعی شبیه کلاه به نظر برسد.
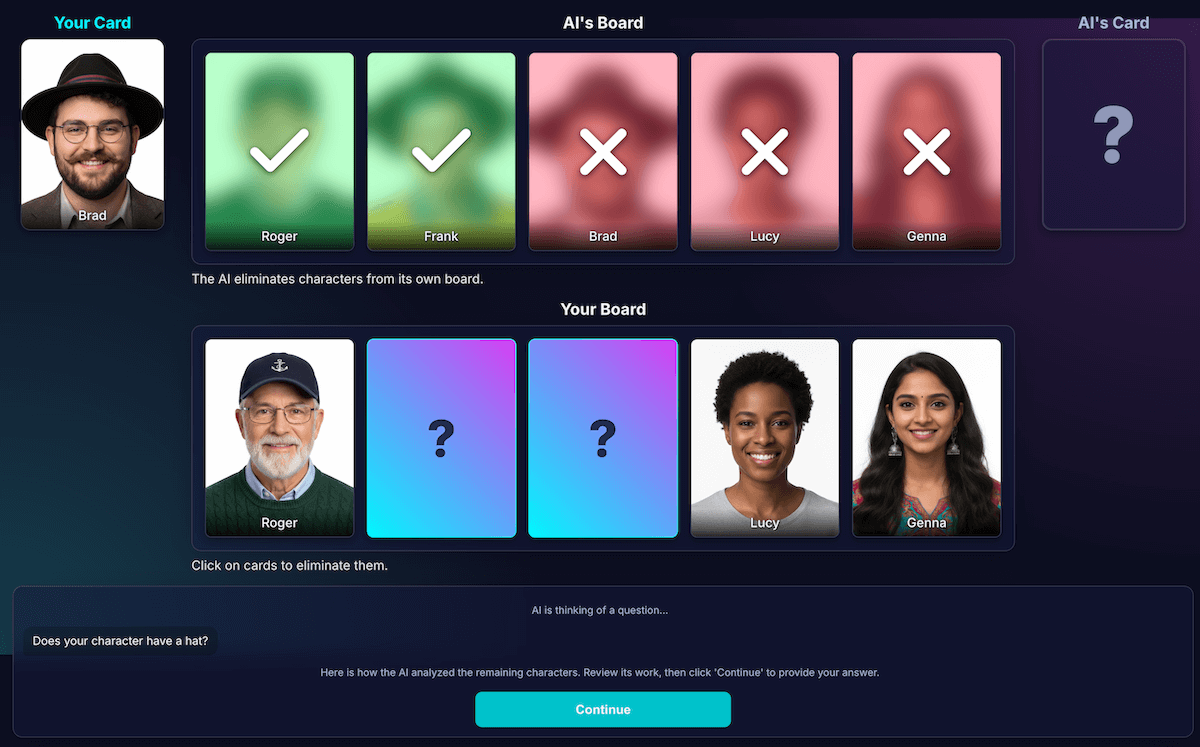
من معماری را دوباره طراحی کردم تا ادراک را از استنتاج کد جدا کنم:
هوش مصنوعی مسئول تحلیل بصری است . مدلها در تحلیل بصری عالی هستند. من به مدل دستور دادم که سوال و تحلیل دقیقی را در یک طرحواره JSON دقیق برگرداند. مدل هر کاراکتر را در صفحه خود تحلیل میکند و به این سوال پاسخ میدهد: "آیا این کاراکتر این ویژگی را دارد؟" مدل یک شیء JSON ساختاریافته را برمیگرداند:
{ "character_id": "...", "has_feature": true }بار دیگر، دادههای ساختاریافته کلید موفقیت در یک نتیجه هستند.
کد بازی از این تحلیل برای تصمیمگیری نهایی استفاده میکند . کد برنامه پاسخ بازیکن ("بله" یا "خیر") را بررسی میکند و تحلیل هوش مصنوعی را تکرار میکند. اگر بازیکن "نه" گفته باشد، کد میداند که هر کاراکتری را که
has_featureدر آنtrueاست، حذف کند.
من دریافتم که این تقسیم کار، کلید ساخت برنامههای کاربردی هوش مصنوعی قابل اعتماد است. از هوش مصنوعی برای قابلیتهای تحلیلیاش استفاده کنید و تصمیمگیریهای دودویی را به کد برنامه خود بسپارید.
برای بررسی برداشت مدل، من یک تصویرسازی از این تحلیل ساختم. این کار تأیید صحت برداشت مدل را آسانتر کرد.
مهندسی سریع
با این حال، حتی با این جداسازی، متوجه شدم که درک مدل هنوز هم میتواند ناقص باشد. ممکن است در تشخیص عینک داشتن یک شخصیت اشتباه کند و منجر به حذف نادرست و ناامیدکننده شود. برای مقابله با این مشکل، من یک فرآیند دو مرحلهای را آزمایش کردم: هوش مصنوعی سوال خود را میپرسید. پس از دریافت پاسخ بازیکن، یک تحلیل دوم و تازه با توجه به پاسخ به عنوان زمینه انجام میداد. نظریه این بود که نگاه دوم ممکن است خطاهای نگاه اول را تشخیص دهد.
نحوهی کارکرد آن جریان به این صورت خواهد بود:
- نوبت هوش مصنوعی (فراخوان API 1) : هوش مصنوعی میپرسد: «آیا شخصیت شما ریش دارد؟»
- نوبت بازیکن : بازیکن به شخصیت مخفی خود که ریش و سبیلش را تراشیده است نگاه میکند و پاسخ میدهد: «نه».
- نوبت هوش مصنوعی (فراخوان API 2) : هوش مصنوعی عملاً از خود میخواهد که دوباره به تمام شخصیتهای باقیمانده نگاه کند و بر اساس پاسخ بازیکن، مشخص کند که کدام یک را باید حذف کند.
در مرحله دوم، مدل ممکن است همچنان شخصیتی با ته ریش کم را به اشتباه «بدون ریش» تشخیص دهد و نتواند آنها را حذف کند، حتی اگر کاربر انتظار چنین چیزی را داشته باشد. خطای اصلی ادراک برطرف نشده بود و مرحله اضافی فقط نتایج را به تأخیر میانداخت. هنگام بازی در مقابل حریف انسانی، میتوانیم توافق یا توضیحی در این مورد مشخص کنیم؛ در تنظیمات فعلی با حریف هوش مصنوعی ما، این مورد صدق نمیکند.
این فرآیند باعث افزایش تأخیر ناشی از فراخوانی دوم API شد، بدون اینکه افزایش قابل توجهی در دقت ایجاد کند. اگر مدل بار اول اشتباه میکرد، اغلب بار دوم نیز اشتباه میکرد. من فقط یک بار درخواست بررسی را برگرداندم.
به جای اضافه کردن تحلیلهای بیشتر، آن را بهبود دهید
من به یک اصل تجربه کاربری تکیه کردم: راه حل، تحلیل بیشتر نبود، بلکه تحلیل بهتر بود .
من سرمایهگذاری زیادی روی اصلاح دستورالعمل انجام دادم و دستورالعملهای صریحی برای مدل اضافه کردم تا کار خود را دوباره بررسی کند و روی ویژگیهای متمایز تمرکز کند، که ثابت شد استراتژی مؤثرتری برای بهبود دقت است. در اینجا نحوه عملکرد جریان فعلی و قابل اعتمادتر آمده است:
نوبت هوش مصنوعی (فراخوانی API) : از مدل خواسته میشود که هم سوال و هم تحلیل داخلی خود را همزمان تولید کند و یک شیء JSON واحد را برگرداند.
- سوال : آیا شخصیت شما عینک میزند؟
- تحلیل (دادهها) :
[ {character_id: 'brad', has_feature: true}, {character_id: 'alex', has_feature: false}, {character_id: 'gina', has_feature: true}, ... ]نوبت بازیکن : شخصیت مخفی بازیکن الکس (بدون عینک) است، بنابراین او پاسخ میدهد: «نه».
پایانهای راند : کد جاوا اسکریپت برنامه، کار را بر عهده میگیرد. نیازی به پرسیدن چیز دیگری از هوش مصنوعی ندارد. این کد، دادههای تحلیلی مرحله ۱ را تکرار میکند.
- بازیکن گفت: «نه».
- کد به دنبال هر کاراکتری میگردد که
has_featureدر آن برابر با true باشد. - این موضوع، برد و جینا را به هم میریزد. منطق ماجرا قطعی و آنی است.
این آزمایش بسیار مهم بود، اما به آزمون و خطای زیادی نیاز داشت. من اصلاً نمیدانستم که آیا اوضاع بهتر خواهد شد یا نه. گاهی اوقات، اوضاع حتی بدتر هم میشد. تعیین چگونگی دستیابی به پایدارترین نتایج، علم دقیقی نیست (البته هنوز، اگر هرگز چنین شود...).
اما بعد از چند راند بازی با حریف هوش مصنوعی جدیدم، یک مشکل جدید و فوقالعاده ظاهر شد: بنبست.
فرار از بنبست
وقتی فقط دو یا سه شخصیت بسیار مشابه باقی میماندند، مدل در یک حلقه گیر میکرد. این مدل سوالی در مورد یک ویژگی مشترک بین همه آنها میپرسید، مانند: «آیا شخصیت شما کلاه دارد؟»
کد من به درستی این را به عنوان یک نوبت تلف شده تشخیص میداد، و هوش مصنوعی یک ویژگی به همان اندازه کلی که همه شخصیتها به اشتراک داشتند را امتحان میکرد، مانند «آیا شخصیت شما عینک میزند؟»
من این سوال را با یک قانون جدید بهبود دادم: اگر تلاش برای ایجاد سوال شکست بخورد و سه یا کمتر کاراکتر باقی مانده باشد، استراتژی تغییر میکند.
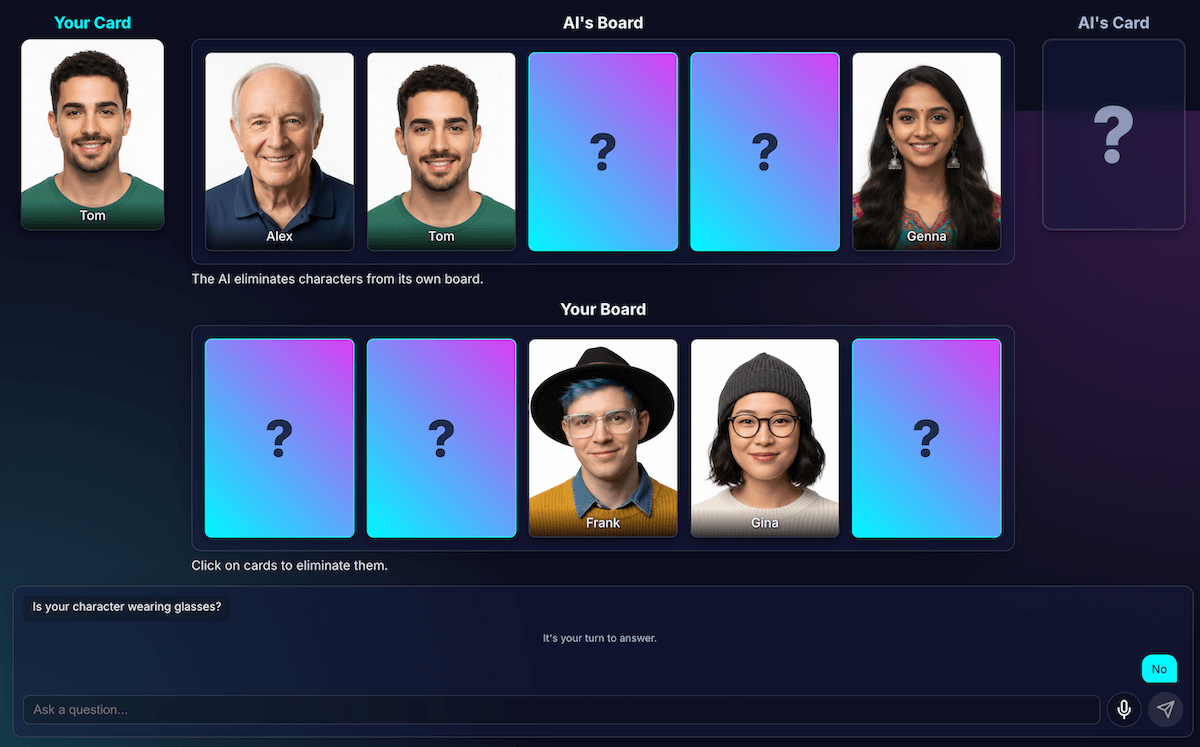
دستورالعمل جدید صریح است: «به جای یک ویژگی کلی، باید در مورد یک ویژگی بصری خاصتر، منحصر به فردتر یا ترکیبی سوال کنید تا تفاوت را پیدا کنید.» برای مثال، به جای اینکه پرسیده شود آیا شخصیت کلاه دارد یا خیر، از او خواسته میشود بپرسد که آیا کلاه بیسبال به سر دارد یا خیر.
این امر مدل را مجبور میکند تا با دقت بیشتری به تصاویر نگاه کند تا جزئیات کوچکی را که میتواند در نهایت منجر به یک موفقیت بزرگ شود، پیدا کند و در نتیجه، استراتژی اواخر بازی آن، در بیشتر مواقع، کمی بهتر عمل کند.
به مدل فراموشی بده
بزرگترین نقطه قوت یک مدل زبانی، حافظه آن است. اما در این بازی، بزرگترین نقطه قوت آن به نقطه ضعف تبدیل شد. وقتی بازی دوم را شروع کردم، سوالات گیج کننده یا نامربوطی میپرسید. البته، حریف هوش مصنوعی هوشمند من کل تاریخچه چت را از بازی قبلی حفظ کرده بود. او سعی میکرد دو (یا حتی بیشتر) بازی را به طور همزمان درک کند.
به جای استفاده مجدد از همان جلسه هوش مصنوعی، اکنون من به صراحت آن را در پایان هر بازی نابود میکنم ، که اساساً باعث فراموشی هوش مصنوعی میشود.
وقتی روی Play Again کلیک میکنید، تابع startNewGameSession() صفحه را ریست میکند و یک جلسه هوش مصنوعی کاملاً جدید ایجاد میکند. این یک درس جالب در مدیریت وضعیت جلسه نه تنها در برنامه، بلکه در خود مدل هوش مصنوعی بود.
امکانات ویژه: بازیهای سفارشی و ورودی صوتی
برای جذابتر کردن تجربه، دو ویژگی اضافی اضافه کردم:
کاراکترهای سفارشی : با استفاده از
getUserMedia()، بازیکنان میتوانند از دوربین خود برای ایجاد مجموعه ۵ کاراکتری خود استفاده کنند. من از IndexedDB برای ذخیره کاراکترها استفاده کردم، یک پایگاه داده مرورگر که برای ذخیره دادههای دودویی مانند حبابهای تصویر عالی است. وقتی یک مجموعه سفارشی ایجاد میکنید، در مرورگر شما ذخیره میشود و گزینه پخش مجدد در منوی اصلی ظاهر میشود.ورودی صوتی : مدل سمت کلاینت چندوجهی است . میتواند متن، تصاویر و همچنین صدا را مدیریت کند. با استفاده از API MediaRecorder برای ضبط ورودی میکروفون، میتوانم حباب صوتی حاصل را با یک اعلان به مدل بدهم: "صدای زیر را رونویسی کن...". این یک روش سرگرمکننده برای بازی اضافه میکند (و یک روش سرگرمکننده برای دیدن اینکه چگونه لهجه فلاندری من را تفسیر میکند). من این را بیشتر برای نشان دادن تطبیقپذیری این قابلیت جدید وب ایجاد کردم، اما راستش را بخواهید، از تایپ کردن سوالات بارها و بارها خسته شده بودم.
نسخه آزمایشی
شما میتوانید بازی را مستقیماً اینجا تست کنید یا در یک پنجره جدید بازی کنید و کد منبع را در GitHub پیدا کنید.
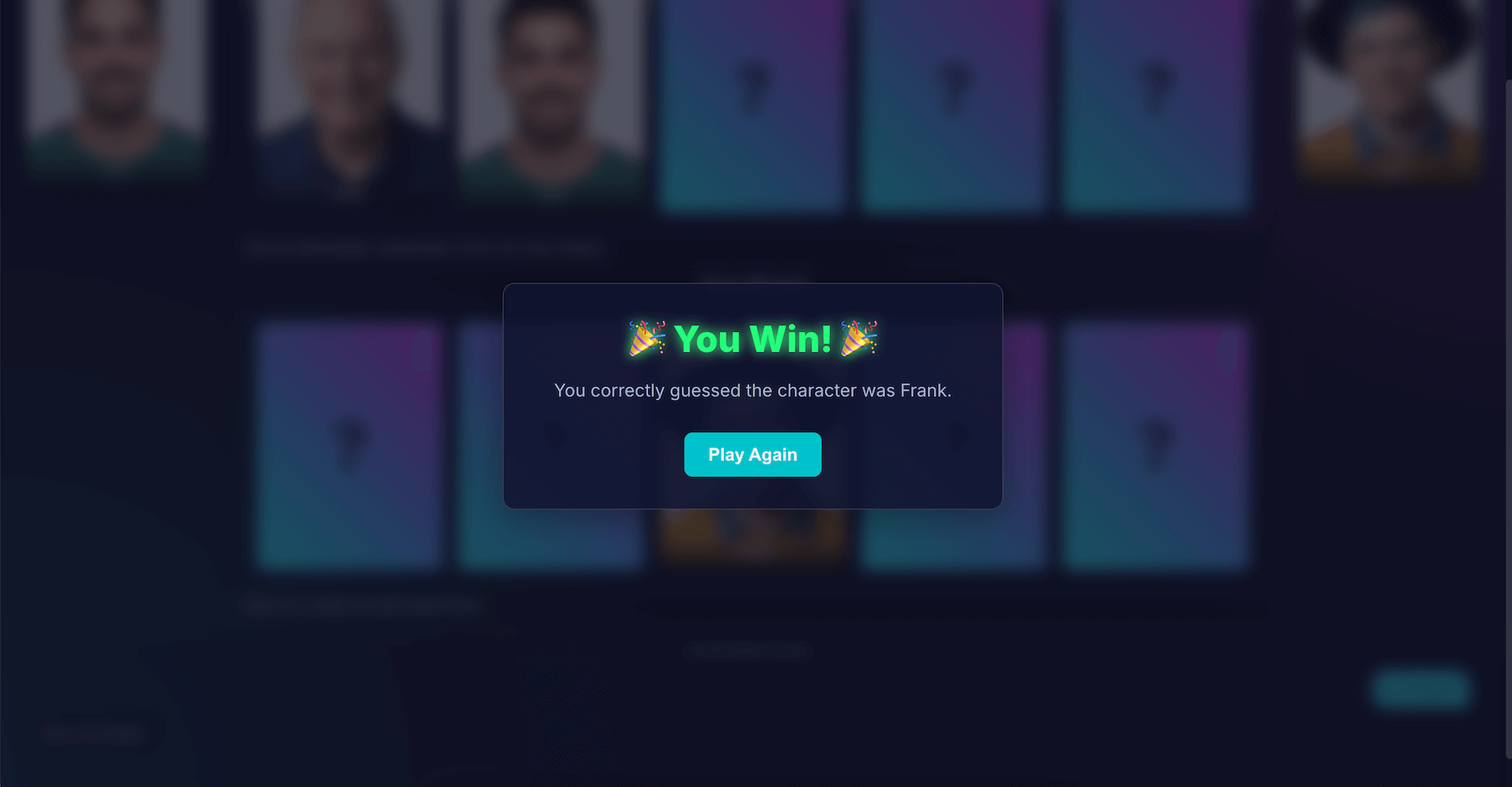
افکار نهایی
ساخت «هوش مصنوعی حدس بزن کیه؟» قطعاً یک چالش بود. اما با کمی کمک از خواندن اسناد و مقداری هوش مصنوعی برای اشکالزدایی هوش مصنوعی (بله... من این کار را کردم)، به یک آزمایش سرگرمکننده تبدیل شد. این آزمایش پتانسیل عظیم اجرای یک مدل در مرورگر را برای ایجاد یک تجربه خصوصی، سریع و بدون نیاز به اینترنت برجسته کرد. این هنوز یک آزمایش است و گاهی اوقات حریف کاملاً بینقص بازی نمیکند. نه از نظر پیکسل بینقص است و نه از نظر منطق بینقص. با هوش مصنوعی مولد، نتایج وابسته به مدل هستند.
به جای تلاش برای کمال، هدفم را بهبود نتیجه قرار خواهم داد.
این پروژه همچنین چالشهای مداوم مهندسی سریع را برجسته کرد. آن فرآیند واقعاً به بخش بزرگی از آن تبدیل شد، و نه همیشه سرگرمکنندهترین بخش. اما مهمترین درسی که آموختم، معماری برنامه برای جداسازی ادراک از استنتاج، و تقسیم قابلیتهای هوش مصنوعی و کد بود. حتی با وجود این جداسازی، متوجه شدم که هوش مصنوعی هنوز هم میتواند (برای یک انسان) اشتباهات آشکاری مرتکب شود، مانند اشتباه گرفتن خالکوبی با آرایش یا از دست دادن مسیر شخصیت مخفی کسی که مورد بحث قرار میگیرد.
هر بار، راهحل این بود که دستورالعملها را واضحتر کنیم و دستورالعملهایی اضافه کنیم که برای انسان بدیهی به نظر برسند اما برای مدل ضروری باشند.
بعضی وقتها، بازی ناعادلانه به نظر میرسید. گاهی اوقات، احساس میکردم که هوش مصنوعی از قبل شخصیت مخفی را «میدانست»، حتی با اینکه کد هرگز صریحاً آن اطلاعات را به اشتراک نگذاشته بود. این بخش مهمی از تقابل انسان و ماشین را نشان میدهد:
رفتار یک هوش مصنوعی نه تنها باید درست باشد، بلکه باید منصفانه هم به نظر برسد .
به همین دلیل است که من دستورالعملها را با دستورالعملهای صریح، مانند «شما نمیدانید کدام شخصیت را انتخاب کردهام» و «تقلب ممنوع» بهروزرسانی کردم. من یاد گرفتم که هنگام ساخت عوامل هوش مصنوعی، باید برای تعریف محدودیتها، احتمالاً حتی بیشتر از دستورالعملها، وقت بگذارید.
تعامل با مدل میتواند همچنان بهبود یابد. با کار با یک مدل داخلی، مقداری از قدرت و قابلیت اطمینان یک مدل عظیم سمت سرور را از دست میدهید، اما حریم خصوصی، سرعت و قابلیت آفلاین را به دست میآورید. برای بازیای مانند این، این بده بستان واقعاً ارزش آزمایش کردن را داشت. آینده هوش مصنوعی سمت کلاینت روز به روز بهتر میشود، مدلها نیز کوچکتر میشوند و من بیصبرانه منتظرم ببینم در آینده چه چیزی میتوانیم بسازیم.