
Este documento é uma continuação de Melhorias do WebAssembly e do WebGPU para uma IA da Web mais rápida, parte 1. Recomendamos que você leia esta postagem ou assista à palestra no IO 24 antes de continuar.



WebGPU
A WebGPU dá aos aplicativos da Web acesso ao hardware de GPU do cliente para realizar cálculos eficientes e altamente paralelos. Desde o lançamento do WebGPU no Chrome, temos visto demonstrações incríveis de inteligência artificial (IA) e machine learning (ML) na Web.
Por exemplo, o Web Stable Diffusion demonstrou que é possível usar a IA para gerar imagens de texto diretamente no navegador. No início deste ano, a equipe do Mediapipe do Google publicou o suporte experimental para inferência de modelos de linguagem grandes.
A animação a seguir mostra o Gemma, o modelo de linguagem grande (LLM) de código aberto do Google, sendo executado inteiramente no dispositivo no Chrome, em tempo real.
A demonstração do Hugging Face (link em inglês) do modelo Segment Anything da Meta produz máscaras de objetos de alta qualidade inteiramente no cliente.
Estes são apenas alguns dos projetos incríveis que mostram o poder da WebGPU para IA e ML. A WebGPU permite que esses modelos e outros sejam executados de forma significativamente mais rápida do que na CPU.
O comparativo da WebGPU para embedding de texto do Hugging Face demonstra uma grande aceleração em comparação com uma implementação de CPU do mesmo modelo. Em um laptop Apple M1 Max, a WebGPU foi mais de 30 vezes mais rápida. Outros usuários informaram que a WebGPU acelera o comparativo de mercado mais de 120 vezes.
Melhorias nos recursos da WebGPU para IA e ML
A WebGPU é ótima para modelos de IA e ML, que podem ter bilhões de parâmetros, graças ao suporte a shaders de computação. Os shaders de computação são executados na GPU e ajudam a executar operações de matriz paralela em grandes volumes de dados.
Entre as várias melhorias na WebGPU no último ano, continuamos adicionando mais recursos para melhorar o desempenho de ML e IA na Web. Recentemente, lançamos dois novos recursos: ponto flutuante de 16 bits e produtos de ponto inteiro empacotados.
Ponto flutuante de 16 bits
Lembre-se de que as cargas de trabalho de ML não exigem precisão. shader-f16 é um recurso que permite o uso do tipo f16 na linguagem de sombreamento da WebGPU. Esse tipo de ponto flutuante ocupa 16 bits, em vez dos 32 bits habituais. O f16 tem um intervalo menor e é menos preciso, mas isso é suficiente para muitos modelos de ML.
Esse recurso aumenta a eficiência de algumas maneiras:
Memória reduzida: os tensores com elementos f16 ocupam metade do espaço, o que reduz pela metade o uso da memória. As computações da GPU costumam ter um gargalo na largura de banda da memória. Portanto, metade da memória pode significar que os shaders são executados duas vezes mais rápido. Tecnicamente, você não precisa de f16 para economizar na largura de banda da memória. É possível armazenar os dados em um formato de baixa precisão e expandi-los para f32 completo no sombreador para computação. No entanto, a GPU gasta mais capacidade de computação para empacotar e desempacotar os dados.
Conversão de dados reduzida: o f16 usa menos computação ao minimizar a conversão de dados. Os dados de baixa precisão podem ser armazenados e usados diretamente sem conversão.
Paralelismo aumentado: as GPUs modernas podem encaixar mais valores simultaneamente nas unidades de execução, permitindo que elas realizem um número maior de computações paralelas. Por exemplo, uma GPU que oferece suporte a até 5 bilhões de operações de ponto flutuante f32 por segundo pode oferecer suporte a 10 bilhões de operações de ponto flutuante f16 por segundo.
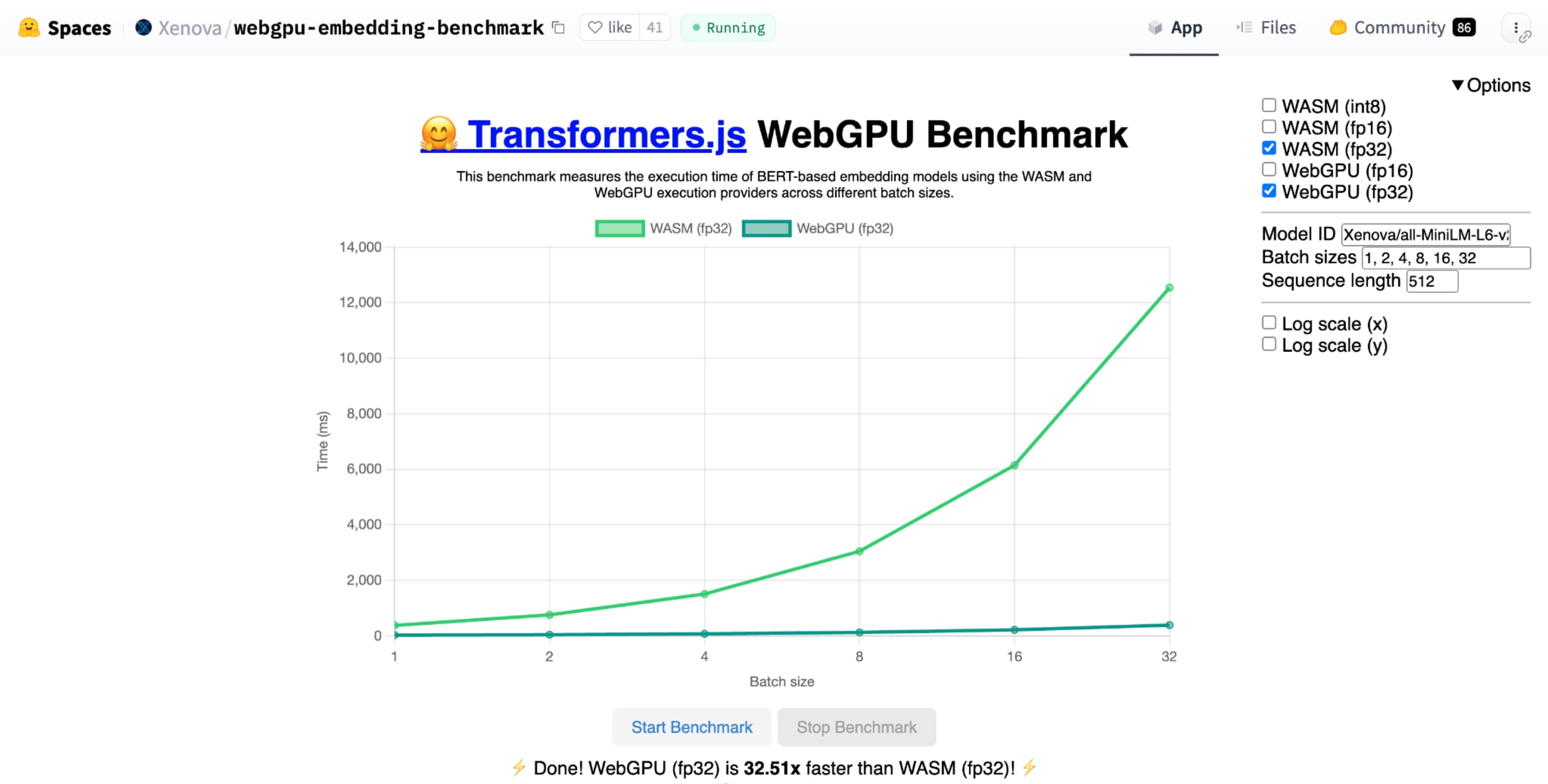
shader-f16, o comparativo de mercado do WebGPU para incorporação de texto do Hugging Face executa o comparativo de mercado três vezes mais rápido que o f32 no laptop Apple M1 Max.
O WebLLM é um projeto que pode executar vários modelos de linguagem grandes. Ele usa o Apache TVM, um framework de compilador de machine learning de código aberto.
Pedi para o WebLLM planejar uma viagem a Paris usando o modelo de oito bilhões de parâmetros do Llama 3. Os resultados mostram que, durante a fase de pré-preenchimento do modelo, o f16 é 2,1 vezes mais rápido que o f32. Durante a fase de decodificação, ele é mais de 1,3 vezes mais rápido.
Os aplicativos precisam primeiro confirmar que o adaptador de GPU oferece suporte a f16 e, se disponível, ativá-lo explicitamente ao solicitar um dispositivo de GPU. Se o f16 não tiver suporte, não será possível solicitá-lo na matriz requiredFeatures.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
Em seguida, nos sombreadores da WebGPU, ative explicitamente o f16 na parte de cima. Depois disso, você pode usá-lo no sombreador como qualquer outro tipo de dados flutuantes.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
Produtos de ponto de número inteiro empacotado
Muitos modelos ainda funcionam bem com apenas 8 bits de precisão (metade de f16). Isso é comum entre LLMs e modelos de imagem para segmentação e reconhecimento de objetos. No entanto, a qualidade de saída dos modelos diminui com menos precisão, então a quantização de 8 bits não é adequada para todas as aplicações.
São poucas as GPUs que oferecem suporte nativo a valores de 8 bits. É aqui que entram os produtos de ponto inteiros compactados. Enviamos o DP4a no Chrome 123.
As GPUs modernas têm instruções especiais para receber dois números inteiros de 32 bits, interpretá-los como quatro números inteiros de 8 bits empacotados consecutivamente e calcular o produto escalar entre os componentes.
Isso é particularmente útil para IA e aprendizado de máquina, porque os kernels de multiplicação de matrizes são compostos por muitos produtos de ponto.
Por exemplo, vamos multiplicar uma matriz 4 x 8 por um vetor 8 x 1. Para calcular isso, é preciso usar quatro produtos escalares para calcular cada um dos valores no vetor de saída: A, B, C e D.

O processo para calcular cada uma dessas saídas é o mesmo. Vamos analisar as etapas envolvidas no cálculo de uma delas. Antes de qualquer cálculo, primeiro precisamos converter os dados inteiros de 8 bits em um tipo com o qual podemos realizar operações aritméticas, como f16. Em seguida, executamos uma multiplicação elementar e, por fim, somamos todos os produtos. No total, para toda a multiplicação de matriz-vetor, realizamos 40 conversões de número inteiro para flutuante para descompactar os dados, 32 multiplicações de flutuante e 28 adições de flutuante.
Para matrizes maiores com mais operações, os produtos de ponto inteiros compactados podem ajudar a reduzir a quantidade de trabalho.
Para cada uma das saídas no vetor de resultado, realizamos duas operações de produto de pontos agrupados usando o dot4U8Packed integrado da linguagem de sombreamento do WebGPU e, em seguida, somamos os resultados. No total, para toda a multiplicação de matriz-vetor, não realizamos nenhuma conversão de dados. Executamos oito produtos de pontos agrupados e quatro adições de números inteiros.
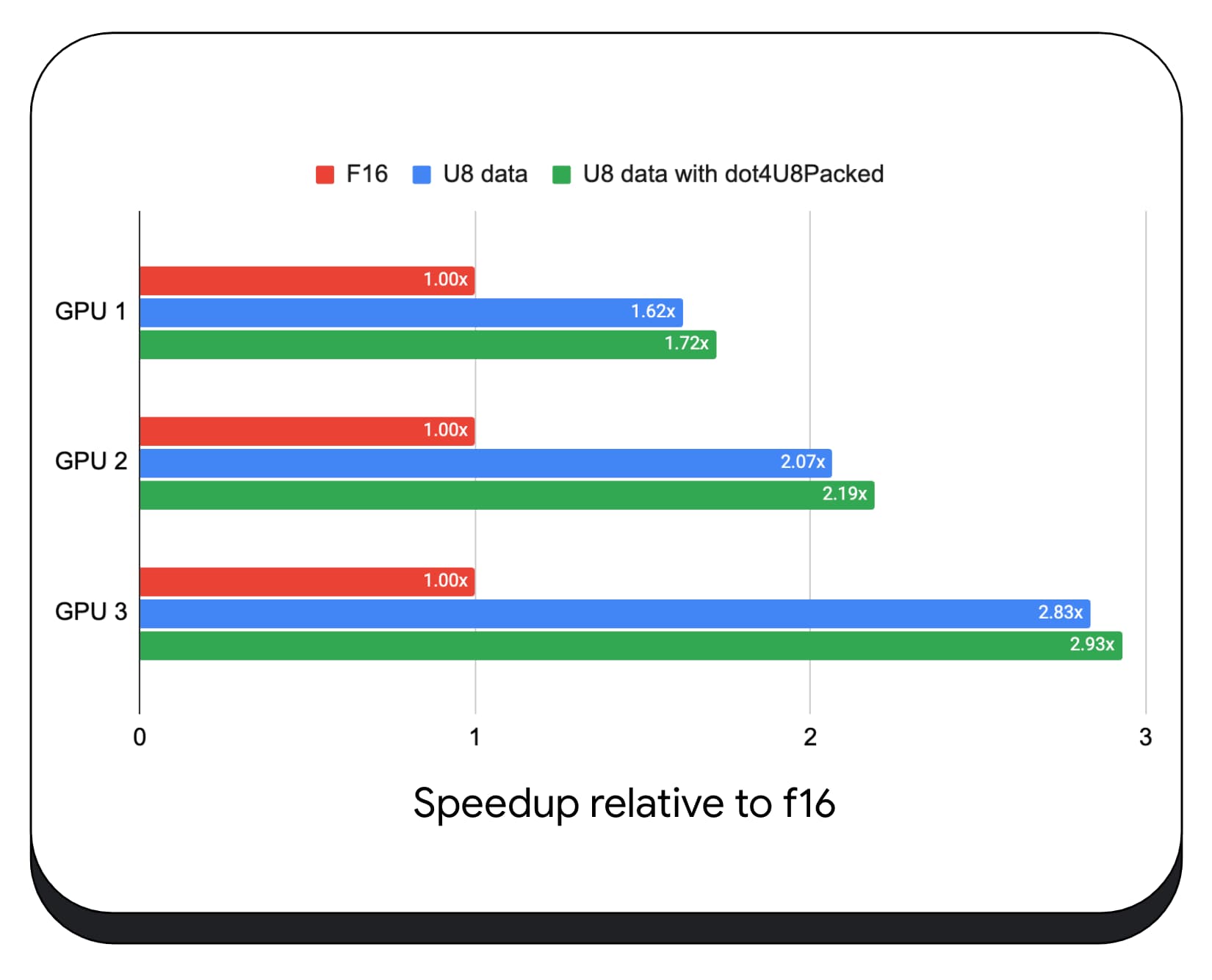
Testamos produtos de ponto inteiro compactado com dados de 8 bits em várias GPUs de consumo. Em comparação com o ponto flutuante de 16 bits, o de 8 bits é de 1,6 a 2,8 vezes mais rápido. Quando usamos produtos de ponto de inteiros agrupados, o desempenho é ainda melhor. É de 1,7 a 2,9 vezes mais rápida.
Verifique o suporte do navegador com a propriedade wgslLanguageFeatures. Se a GPU não oferecer suporte nativo a produtos de pontos agrupados, o navegador vai polyfillar a própria implementação.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
O snippet de código a seguir destaca as diferenças necessárias para usar produtos inteiros compactados em um sombreador da WebGPU.
Antes: um sombreador da WebGPU que acumula produtos escalares parciais na variável "sum". No final do loop, "sum" contém o produto escalar completo entre um vetor e uma linha da matriz de entrada.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
Depois: um sombreador da WebGPU criado para usar produtos de ponto inteiros compactados. A principal diferença é que, em vez de carregar quatro valores de ponto flutuante do vetor e da matriz, esse sombreador carrega um único número inteiro de 32 bits. Esse número inteiro de 32 bits armazena os dados de quatro valores inteiros de 8 bits. Em seguida, chamamos dot4U8Packed para calcular o produto escalar dos dois valores.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
Os produtos de ponto flutuante de 16 bits e de ponto inteiro compactado são os recursos enviados no Chrome que aceleram a IA e o ML. O ponto flutuante de 16 bits fica disponível quando o hardware oferece suporte a ele, e o Chrome implementa produtos de ponto inteiros compactados em todos os dispositivos.
Você pode usar esses recursos no Chrome Stable hoje mesmo para ter um desempenho melhor.
Recursos propostos
No futuro, vamos investigar mais dois recursos: subgrupos e multiplicação de matriz cooperativa.
O recurso de subgrupos permite que o paralelismo no nível SIMD se comunique ou realize operações matemáticas coletivas, como uma soma de mais de 16 números. Isso permite o compartilhamento eficiente de dados entre linhas de execução. Os subgrupos têm suporte em APIs de GPUs modernas, com nomes e formas ligeiramente diferentes.
Refinamos o conjunto comum em uma proposta que apresentamos ao grupo de padronização da WebGPU. Além disso, criamos protótipos de subgrupos no Chrome com uma flag experimental e trouxemos nossos resultados iniciais para a discussão. O principal problema é como garantir o comportamento portátil.
A multiplicação de matriz cooperativa é uma adição mais recente às GPUs. Uma multiplicação de matriz grande pode ser dividida em várias multiplicações de matriz menores. A multiplicação de matriz cooperativa realiza multiplicações nesses blocos menores de tamanho fixo em uma única etapa lógica. Nessa etapa, um grupo de linhas de execução coopera de maneira eficiente para calcular o resultado.
Realizamos uma pesquisa sobre o suporte a APIs de GPU e planejamos apresentar uma proposta ao grupo de padronização da WebGPU. Assim como nos subgrupos, esperamos que a maior parte da discussão se concentre na portabilidade.
Para avaliar o desempenho das operações de subgrupo, em um aplicativo real, integramos o suporte experimental a subgrupos ao MediaPipe e testamos com o protótipo do Chrome para operações de subgrupo.
Usamos subgrupos em núcleos de GPU da fase de pré-preenchimento do modelo de linguagem grande. Por isso, estou informando apenas o aumento de velocidade da fase de pré-preenchimento. Em uma GPU Intel, os subgrupos têm desempenho duas vezes e meia mais rápido do que a média. No entanto, essas melhorias não são consistentes em diferentes GPUs.

O próximo gráfico mostra os resultados da aplicação de subgrupos para otimizar um microbenchmark de multiplicação de matrizes em várias GPUs de consumo. A multiplicação de matrizes é uma das operações mais pesadas em modelos de linguagem grandes. Os dados mostram que, em muitas GPUs, os subgrupos aumentam a velocidade duas, cinco e até 13 vezes o valor de referência. No entanto, observe que, na primeira GPU, os subgrupos não são muito melhores.

A otimização da GPU é difícil
A melhor maneira de otimizar a GPU depende da GPU oferecida pelo cliente. O uso de novos recursos sofisticados de GPU nem sempre vale a pena, porque pode haver muitos fatores complexos envolvidos. A melhor estratégia de otimização em uma GPU pode não ser a melhor estratégia em outra.
Você quer minimizar a largura de banda da memória, usando totalmente as linhas de execução de computação da GPU.
Os padrões de acesso à memória também podem ser muito importantes. As GPUs tendem a ter um desempenho muito melhor quando as linhas de execução de computação acessam a memória em um padrão ideal para o hardware. Importante: características de desempenho diferentes são esperadas em hardwares de GPU diferentes. Talvez seja necessário executar otimizações diferentes dependendo da GPU.
No gráfico a seguir, usamos o mesmo algoritmo de multiplicação de matriz, mas adicionamos outra dimensão para demonstrar o impacto de várias estratégias de otimização e a complexidade e a variação em diferentes GPUs. Apresentamos uma nova técnica, que chamamos de "Swizzle". O Swizzle otimiza os padrões de acesso à memória para que sejam mais otimizados para o hardware.
Você pode notar que a troca de memória tem um impacto significativo, às vezes até maior do que os subgrupos. Na GPU 6, o swizzle oferece uma aceleração de 12 vezes, enquanto os subgrupos oferecem uma aceleração de 13 vezes. Juntos, eles têm uma aceleração incrível de 26 vezes. Para outras GPUs, às vezes, a combinação de swizzle e subgrupos tem um desempenho melhor do que cada um sozinho. E em outras GPUs, o uso exclusivo de swizzle tem a melhor performance.

Ajustar e otimizar algoritmos de GPU para que funcionem bem em cada peça de hardware pode exigir muita experiência. Mas, felizmente, há uma quantidade enorme de trabalho talentoso sendo feito em frameworks de bibliotecas de nível superior, como Mediapipe, Transformers.js, Apache TVM, ONNX Runtime Web e muito mais.
As bibliotecas e os frameworks estão bem posicionados para lidar com a complexidade do gerenciamento de diversas arquiteturas de GPU e gerar código específico da plataforma que será executado bem no cliente.
Aprendizados
A equipe do Chrome continua a ajudar a evoluir os padrões WebAssembly e WebGPU para melhorar a plataforma da Web para cargas de trabalho de machine learning. Estamos investindo em primitivas de computação mais rápidas, melhor interoperabilidade entre os padrões da Web e garantindo que modelos grandes e pequenos possam ser executados de forma eficiente em todos os dispositivos.
Nosso objetivo é maximizar os recursos da plataforma e manter o melhor da Web: alcance, usabilidade e portabilidade. E não estamos sozinhos. Estamos trabalhando em colaboração com os outros fornecedores de navegadores do W3C e com muitos parceiros de desenvolvimento.
Esperamos que você se lembre do seguinte ao trabalhar com o WebAssembly e o WebGPU:
- A inferência de IA já está disponível na Web e em todos os dispositivos. Isso traz a vantagem de ser executado em dispositivos clientes, como custo reduzido do servidor, baixa latência e maior privacidade.
- Embora muitos recursos discutidos sejam relevantes principalmente para os autores do framework, seus aplicativos podem se beneficiar sem muita sobrecarga.
- Os padrões da Web são fluidos e estão sempre evoluindo, e estamos sempre em busca de feedback. Compartilhe as suas para o WebAssembly e a WebGPU.
Agradecimentos
Gostaríamos de agradecer à equipe de gráficos da Web da Intel, que foi fundamental para impulsionar os recursos do produto dot do WebGPU f16 e empacotado. Gostaríamos de agradecer aos outros membros dos grupos de trabalho do WebAssembly e WebGPU no W3C, incluindo os outros fornecedores de navegadores.
Agradecemos às equipes de IA e ML do Google e da comunidade de código aberto por serem parceiros incríveis. E, claro, a todos os nossos colegas de equipe que tornam tudo isso possível.