


জিপিইউগুলির সাথে একটি সামঞ্জস্যপূর্ণ পরীক্ষার পরিবেশ সেট আপ করা প্রত্যাশার চেয়ে কঠিন হতে পারে। এখানে ক্লায়েন্ট-সাইড, ব্রাউজার-ভিত্তিক এআই মডেলগুলিকে সত্যিকারের ব্রাউজার পরিবেশে পরীক্ষা করার পদক্ষেপগুলি রয়েছে, পাশাপাশি মাপযোগ্য, স্বয়ংক্রিয় এবং একটি পরিচিত প্রমিত হার্ডওয়্যার সেটআপের মধ্যে রয়েছে।
এই উদাহরণে, সফ্টওয়্যার এমুলেশনের বিপরীতে ব্রাউজারটি হার্ডওয়্যার সমর্থন সহ একটি বাস্তব ক্রোম ব্রাউজার।
আপনি ওয়েব AI, ওয়েব গেমিং, বা গ্রাফিক্স ডেভেলপার হোন না কেন, অথবা আপনি ওয়েব AI মডেল টেস্টিংয়ে আগ্রহী হন, এই নির্দেশিকা আপনার জন্য।
ধাপ 1: একটি নতুন Google Colab নোটবুক তৈরি করুন
1. একটি নতুন Colab নোটবুক তৈরি করতে colab.new- এ যান। এটি চিত্র 1 এর মতো দেখতে হবে। 2. আপনার Google অ্যাকাউন্টে সাইন ইন করতে প্রম্পটটি অনুসরণ করুন।
ধাপ 2: একটি T4 GPU-সক্ষম সার্ভারের সাথে সংযোগ করুন
- নোটবুকের উপরের ডানদিকে Connect ক্লিক করুন।
- রানটাইম পরিবর্তন নির্বাচন করুন:
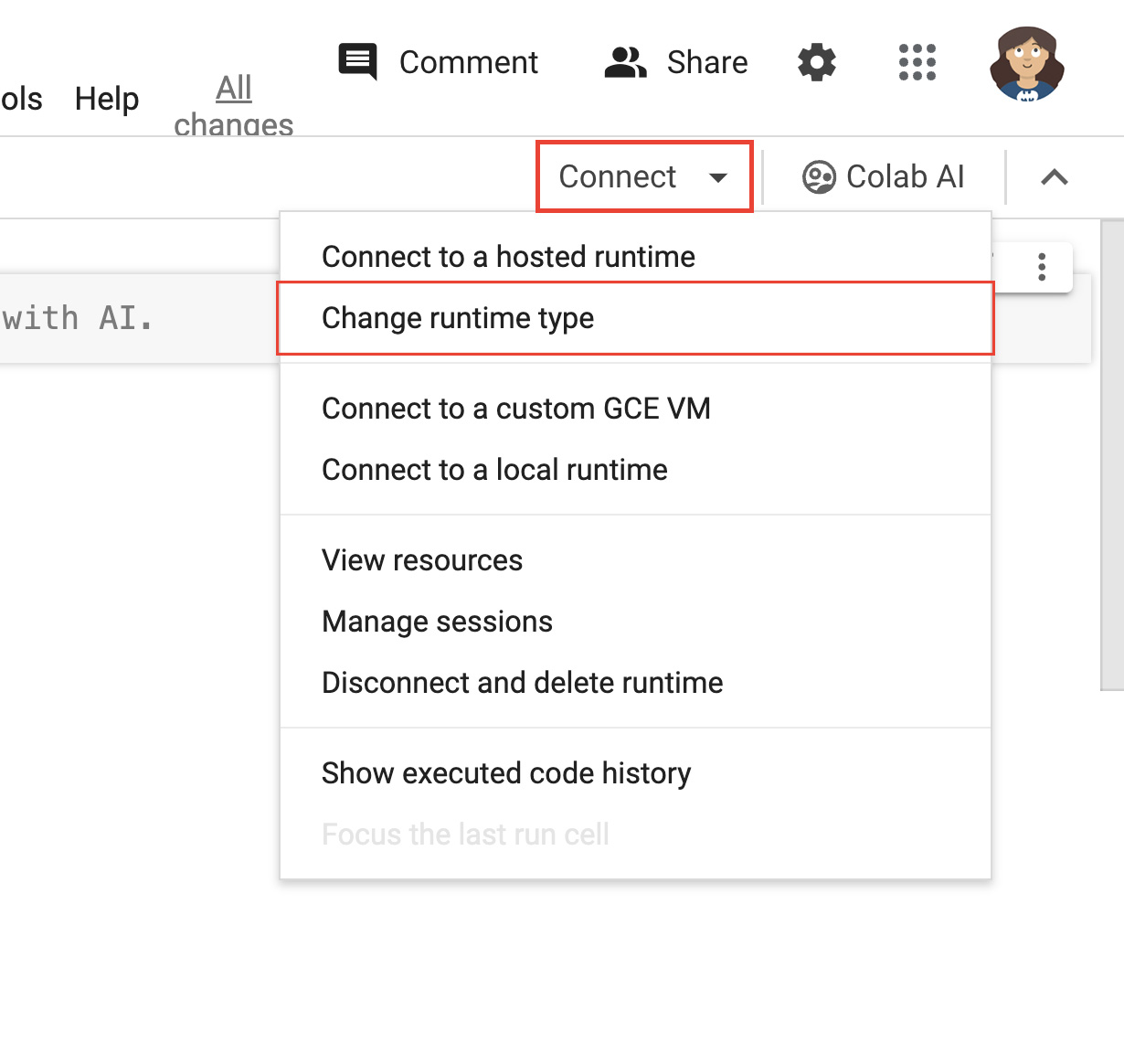
চিত্র 2 । Colab ইন্টারফেসে রানটাইম পরিবর্তন করুন। - মডেল উইন্ডোতে, আপনার হার্ডওয়্যার অ্যাক্সিলারেটর হিসাবে T4 GPU নির্বাচন করুন। আপনি কানেক্ট করলে, Colab একটি NVIDIA T4 GPU যুক্ত একটি Linux ইন্সট্যান্স ব্যবহার করবে।

চিত্র 3 : হার্ডওয়্যার এক্সিলারেটরের অধীনে, T4 GPU নির্বাচন করুন। - Save এ ক্লিক করুন।
- আপনার রানটাইমের সাথে সংযোগ করতে সংযোগ বোতামে ক্লিক করুন। কিছু সময় পরে, বোতামটি RAM এবং ডিস্ক ব্যবহারের গ্রাফ সহ একটি সবুজ চেকমার্ক উপস্থাপন করবে। এটি নির্দেশ করে যে আপনার প্রয়োজনীয় হার্ডওয়্যার দিয়ে একটি সার্ভার সফলভাবে তৈরি করা হয়েছে।
চমৎকার কাজ, আপনি এইমাত্র একটি GPU সংযুক্ত করে একটি সার্ভার তৈরি করেছেন৷
ধাপ 3: সঠিক ড্রাইভার এবং নির্ভরতা ইনস্টল করুন
নোটবুকের প্রথম কোড ঘরে নিচের দুটি লাইন কোড কপি করে পেস্ট করুন। Colab এনভায়রনমেন্টে, কমান্ড লাইন এক্সিকিউশন একটি বিস্ময়বোধক চিহ্ন দিয়ে আগে লেখা হয়।
!git clone https://github.com/jasonmayes/headless-chrome-nvidia-t4-gpu-support.git !cd headless-chrome-nvidia-t4-gpu-support && chmod +x scriptyMcScriptFace.sh && ./scriptyMcScriptFace.sh- এই স্ক্রিপ্টটি কার্যকর করে কাঁচা কমান্ড লাইন কোড দেখতে আপনি GitHub-এ স্ক্রিপ্টটি পরিদর্শন করতে পারেন।
# Update, install correct drivers, and remove the old ones. apt-get install -y vulkan-tools libnvidia-gl-525 # Verify NVIDIA drivers can see the T4 GPU and that vulkan is working correctly. nvidia-smi vulkaninfo --summary # Now install latest version of Node.js npm install -g n n lts node --version npm --version # Next install Chrome stable curl -fsSL https://dl.google.com/linux/linux_signing_key.pub | sudo gpg --dearmor -o /usr/share/keyrings/googlechrom-keyring.gpg echo "deb [arch=amd64 signed-by=/usr/share/keyrings/googlechrom-keyring.gpg] http://dl.google.com/linux/chrome/deb/ stable main" | sudo tee /etc/apt/sources.list.d/google-chrome.list sudo apt update sudo apt install -y google-chrome-stable # Start dbus to avoid warnings by Chrome later. export DBUS_SESSION_BUS_ADDRESS="unix:path=/var/run/dbus/system_bus_socket" /etc/init.d/dbus startকোডটি কার্যকর করতে ঘরের পাশে ক্লিক করুন।

চিত্র 4 । কোডটি কার্যকর করা শেষ হয়ে গেলে, নিশ্চিত করুন যে আপনি সত্যিই একটি GPU সংযুক্ত করেছেন এবং এটি আপনার সার্ভারে স্বীকৃত হয়েছে তা নিশ্চিত করতে নিম্নলিখিত স্ক্রিনশটের মতো কিছু প্রিন্ট করা
nvidia-smiযাচাই করুন। এই আউটপুটটি দেখতে আপনাকে লগগুলিতে আগে স্ক্রোল করতে হতে পারে।
চিত্র 5 : "NVIDIA-SMI" দিয়ে শুরু হওয়া আউটপুটটি দেখুন।
ধাপ 4: হেডলেস ক্রোম ব্যবহার করুন এবং স্বয়ংক্রিয় করুন
- একটি নতুন কোড সেল যোগ করতে কোড বোতামে ক্লিক করুন।
- তারপরে আপনি আপনার পছন্দের প্যারামিটার সহ একটি Node.js প্রজেক্টে কল করার জন্য আপনার কাস্টম কোড লিখতে পারেন (বা শুধুমাত্র কমান্ড লাইনে সরাসরি
google-chrome-stableকল করুন)। আমরা উভয় নিম্নলিখিত জন্য উদাহরণ আছে.
অংশ A: সরাসরি কমান্ড লাইনে হেডলেস ক্রোম ব্যবহার করুন
# Directly call Chrome to dump a PDF of WebGPU testing page
# and store it in /content/gpu.pdf
!google-chrome-stable \
--no-sandbox \
--headless=new \
--use-angle=vulkan \
--enable-features=Vulkan \
--disable-vulkan-surface \
--enable-unsafe-webgpu \
--print-to-pdf=/content/gpu.pdf https://webgpureport.org
উদাহরণে, আমরা /content/gpu.pdf এ ফলিত PDF ক্যাপচার সংরক্ষণ করেছি। সেই ফাইলটি দেখতে, বিষয়বস্তু প্রসারিত করুন। তারপর আপনার স্থানীয় মেশিনে PDF ফাইলটি ডাউনলোড করতে ক্লিক করুন।

পার্ট বি: পাপেটিয়ারের সাথে ক্রোম কমান্ড করুন
আমরা হেডলেস ক্রোম নিয়ন্ত্রণ করতে পাপেটিয়ার ব্যবহার করে একটি ন্যূনতম উদাহরণ প্রদান করেছি যা নিম্নরূপ চালানো যেতে পারে:
# Call example node.js project to perform any task you want by passing
# a URL as a parameter
!node headless-chrome-nvidia-t4-gpu-support/examples/puppeteer/jPuppet.js chrome://gpu
jPuppet উদাহরণে, আমরা একটি স্ক্রিনশট তৈরি করতে একটি Node.js স্ক্রিপ্ট কল করতে পারি। কিন্তু কিভাবে এই কাজ করে? jPuppet.js- এ Node.js কোডের এই পথটি দেখুন।
jPuppet.js নোড কোড ব্রেকডাউন
প্রথমত, Puppeteer আমদানি করুন। এটি আপনাকে Node.js এর সাথে দূরবর্তীভাবে Chrome নিয়ন্ত্রণ করতে দেয়:
import puppeteer from 'puppeteer';
এরপরে, নোড অ্যাপ্লিকেশনে কোন কমান্ড লাইন আর্গুমেন্ট পাস করা হয়েছে তা পরীক্ষা করুন। নিশ্চিত করুন যে তৃতীয় আর্গুমেন্ট সেট করা আছে—যা নেভিগেট করার জন্য একটি URL উপস্থাপন করে। আপনাকে এখানে তৃতীয় আর্গুমেন্ট পরিদর্শন করতে হবে কারণ প্রথম দুটি আর্গুমেন্ট নোডকে কল করে এবং আমরা যে স্ক্রিপ্টটি চালাচ্ছি। 3য় উপাদান আসলে নোড প্রোগ্রামে পাস করা 1 ম প্যারামিটার রয়েছে:
const url = process.argv[2];
if (!url) {
throw "Please provide a URL as the first argument";
}
এখন runWebpage() নামে একটি অ্যাসিঙ্ক্রোনাস ফাংশন সংজ্ঞায়িত করুন। এটি একটি ব্রাউজার অবজেক্ট তৈরি করে যা ক্রোম বাইনারি চালানোর জন্য কমান্ড লাইন আর্গুমেন্টের সাথে কনফিগার করা হয়েছে যেভাবে WebGL এবং WebGPU-কে WebGPU এবং WebGL সমর্থন সক্ষম করুন -এ বর্ণিত হিসাবে কাজ করতে হবে।
async function runWebpage() {
const browser = await puppeteer.launch({
headless: 'new',
args: [
'--no-sandbox',
'--headless=new',
'--use-angle=vulkan',
'--enable-features=Vulkan',
'--disable-vulkan-surface',
'--enable-unsafe-webgpu'
]
});
একটি নতুন ব্রাউজার পৃষ্ঠা অবজেক্ট তৈরি করুন যা আপনি পরে যেকোনো URL দেখার জন্য ব্যবহার করতে পারেন:
const page = await browser.newPage();
তারপরে, যখন ওয়েব পৃষ্ঠা জাভাস্ক্রিপ্ট চালায় তখন console.log ইভেন্টগুলি শুনতে একটি ইভেন্ট লিসেনার যোগ করুন। এটি আপনাকে নোড কমান্ড লাইনে বার্তাগুলি লগ করতে এবং একটি বিশেষ বাক্যাংশের জন্য কনসোল পাঠ্য পরিদর্শন করতে দেয় (এই ক্ষেত্রে, captureAndEnd ) যা একটি স্ক্রিনশট ট্রিগার করে এবং তারপরে নোডে ব্রাউজার প্রক্রিয়াটি শেষ করে। এটি এমন ওয়েব পৃষ্ঠাগুলির জন্য দরকারী যেগুলি একটি স্ক্রিনশট নেওয়ার আগে কিছু পরিমাণ কাজ করতে হবে এবং কার্যকর করার সময় একটি অ-নির্ধারিত পরিমাণ রয়েছে৷
page.on('console', async function(msg) {
console.log(msg.text());
if (msg.text() === 'captureAndEnd') {
await page.screenshot({ path: '/content/screenshotEnd.png' });
await browser.close();
}
});
অবশেষে, পৃষ্ঠাটিকে নির্দেশ করুন নির্দিষ্ট URL-এ যেতে এবং পৃষ্ঠাটি লোড হয়ে গেলে একটি প্রাথমিক স্ক্রিনশট নিন।
আপনি যদি chrome://gpu এর একটি স্ক্রিনশট নিতে চান, তাহলে আপনি যেকোনো কনসোল আউটপুটের জন্য অপেক্ষা না করে অবিলম্বে ব্রাউজার সেশন বন্ধ করতে পারেন, কারণ এই পৃষ্ঠাটি আপনার নিজের কোড দ্বারা নিয়ন্ত্রিত নয়৷
await page.goto(url, { waitUntil: 'networkidle2' });
await page.screenshot({path: '/content/screenshot.png'});
if (url === 'chrome://gpu') {
await browser.close();
}
}
runWebpage();
package.json পরিবর্তন করুন
আপনি হয়তো লক্ষ্য করেছেন যে আমরা jPuppet.js ফাইলের শুরুতে একটি আমদানি বিবৃতি ব্যবহার করেছি। আপনার package.json অবশ্যই টাইপ মানগুলি module হিসাবে সেট করতে হবে, অথবা আপনি একটি ত্রুটি পাবেন যে মডিউলটি অবৈধ।
{
"dependencies": {
"puppeteer": "*"
},
"name": "content",
"version": "1.0.0",
"main": "jPuppet.js",
"devDependencies": {},
"keywords": [],
"type": "module",
"description": "Node.js Puppeteer application to interface with headless Chrome with GPU support to capture screenshots and get console output from target webpage"
}
যে এটা আছে সব. Puppeteer ব্যবহার করে প্রোগ্রামগতভাবে Chrome এর সাথে ইন্টারফেস করা সহজ করে তোলে।
সফলতা
আমরা এখন যাচাই করতে পারি যে TensorFlow.js ফ্যাশন MNIST ক্লাসিফায়ার GPU ব্যবহার করে ব্রাউজারে ক্লায়েন্ট-সাইড প্রসেসিং সহ একটি ছবিতে এক জোড়া ট্রাউজার্স সঠিকভাবে চিনতে পারে।
আপনি মেশিন লার্নিং মডেল থেকে শুরু করে গ্রাফিক্স এবং গেম টেস্টিং পর্যন্ত যেকোনো ক্লায়েন্ট-সাইড GPU-ভিত্তিক কাজের চাপের জন্য এটি ব্যবহার করতে পারেন।

সম্পদ
ভবিষ্যতের আপডেট পেতে GitHub রেপোতে একটি তারকা যোগ করুন ।