

تاريخ النشر: 10 أكتوبر 2025

تُعد لعبة Guess Who? اللوحية الكلاسيكية مثالاً رائعًا على التفكير الاستنتاجي. يبدأ كل لاعب بلوحة وجوه، ومن خلال سلسلة من الأسئلة التي تتطلب إجابات بنعم أو لا، يتم تضييق نطاق الاحتمالات إلى أن تتمكّن من تحديد الشخصية السرية التي اختارها خصمك بثقة.
بعد مشاهدة عرض توضيحي للذكاء الاصطناعي المضمّن في مؤتمر Google I/O Connect، تساءلت: ماذا لو أمكنني لعب لعبة "من هو؟" ضد ذكاء اصطناعي مضمّن في المتصفّح؟ باستخدام الذكاء الاصطناعي من جهة العميل، سيتم تفسير الصور محليًا، وبالتالي ستبقى لعبة "من هو؟" المخصّصة للأصدقاء والعائلة خاصة وآمنة على جهازي.
لديّ خبرة في تطوير واجهات المستخدم وتجربة المستخدم، وأنا معتاد على تقديم تجارب مثالية. كنت آمل أن أتمكّن من فعل ذلك بالضبط في تفسيري.
تطبيق AI Guess Who? الذي أنشأته مبرمَج بلغة React ويستخدم Prompt API ونموذجًا مدمجًا في المتصفّح لإنشاء خصم يتمتع بقدرات مذهلة. خلال هذه العملية، تبيّن لي أنّ الحصول على نتائج "دقيقة للغاية" ليس أمرًا سهلاً. ومع ذلك، يوضّح هذا التطبيق كيف يمكن استخدام الذكاء الاصطناعي لإنشاء منطق ألعاب مدروس، وأهمية هندسة الطلبات لتحسين هذا المنطق والحصول على النتائج المتوقّعة.
يمكنك مواصلة القراءة للتعرّف على عملية دمج الذكاء الاصطناعي المضمّنة والتحديات التي واجهتني والحلول التي توصلت إليها. يمكنك لعب هذه اللعبة والعثور على الرمز المصدر على GitHub.
أساسيات اللعبة: تطبيق React
قبل النظر في عملية تنفيذ الذكاء الاصطناعي، سنراجع بنية التطبيق. لقد أنشأت تطبيق React عاديًا باستخدام TypeScript، مع ملف App.tsx مركزي يعمل كقائد للعبة. يحتوي هذا الملف على ما يلي:
- حالة اللعبة: هي تعداد يتتبّع المرحلة الحالية من اللعبة (مثل
PLAYER_TURN_ASKINGوAI_TURNوGAME_OVER). وهي أهم جزء من الحالة، لأنّها تحدّد ما تعرضه واجهة المستخدم والإجراءات المتاحة للاعب. - قوائم الشخصيات: هناك قوائم متعدّدة تحدّد الشخصيات النشطة، والشخصية السرية لكل لاعب، والشخصيات التي تم استبعادها من اللوحة.
- محادثة الألعاب: سجلّ متواصل للأسئلة والأجوبة ورسائل النظام
تنقسم الواجهة إلى مكوّنات منطقية:

ومع تطوّر ميزات اللعبة، زاد مستوى تعقيدها. في البداية، كانت تتم إدارة منطق اللعبة بالكامل ضمن خطاف React مخصّص واحد كبير useGameLogic، ولكن سرعان ما أصبح حجمه كبيرًا جدًا بحيث يصعب التنقّل فيه وتصحيح الأخطاء. لتحسين إمكانية الصيانة، أعدتُ كتابة هذا الخطاف إلى خطافات متعددة، لكل منها مسؤولية واحدة.
على سبيل المثال:
useGameStateتدير الحالة الأساسيةusePlayerActionsمخصّص لدور اللاعبuseAIActionsهو منطق الذكاء الاصطناعي
يعمل الخطاف الرئيسي useGameLogic الآن كأداة إنشاء نظيفة، حيث يجمع هذه الخطافات الأصغر حجمًا معًا. لم يؤدِّ هذا التغيير في البنية إلى تعديل وظائف اللعبة،
ولكنه جعل قاعدة الرموز البرمجية أكثر وضوحًا.
منطق اللعبة باستخدام Prompt API
يتمحور هذا المشروع حول استخدام Prompt API.
أضفتُ منطق اللعبة المستند إلى الذكاء الاصطناعي إلى builtInAIService.ts. وفي ما يلي مسؤولياته الرئيسية:
- السماح بالإجابات الثنائية المقيّدة
- تعليم النموذج استراتيجية اللعبة
- تعليم النموذج كيفية إجراء التحليل
- إصابة النموذج بفقدان الذاكرة
السماح بالإجابات الثنائية المقيّدة
كيف يتفاعل اللاعب مع الذكاء الاصطناعي؟ عندما يسأل أحد اللاعبين: "هل يرتدي شخصيتك قبعة؟"، على الذكاء الاصطناعي أن "ينظر" إلى صورة الشخصية السرية ويقدّم إجابة واضحة.
كانت محاولاتي الأولى فاشلة. كان الردّ عبارة عن محادثة: "لا، الشخصية التي أفكر فيها، إيزابيلا، لا يبدو أنها ترتدي قبعة"، بدلاً من تقديم إجابة ثنائية بنعم أو لا. في البداية، حللتُ هذه المشكلة باستخدام طلب صارم جدًا، حيث أمليتُ على النموذج بشكل أساسي أن يردّ بـ "نعم" أو "لا" فقط.
على الرغم من أنّ هذه الطريقة كانت فعّالة، تعرّفتُ على طريقة أفضل باستخدام الناتج المنظَّم. من خلال تقديم مخطط JSON إلى النموذج، يمكنني ضمان الحصول على استجابة صحيحة أو خاطئة.
const schema = { type: "boolean" };
const result = session.prompt(prompt, { responseConstraint: schema });
وقد سمح لي ذلك بتبسيط الطلب والسماح للرمز البرمجي بالتعامل مع الرد بشكل موثوق:
JSON.parse(result) ? "Yes" : "No"
تعليم النموذج استراتيجية اللعبة
إنّ الطلب من النموذج الإجابة عن سؤال أسهل بكثير من الطلب منه طرح الأسئلة. لا يطرح اللاعب الجيد في لعبة "من هو؟" أسئلة عشوائية. يطرحون أسئلة تؤدي إلى استبعاد أكبر عدد من الأحرف في المرة الواحدة. يقلّل السؤال المثالي عدد الأحرف المتبقية إلى النصف باستخدام أسئلة ثنائية الخيار.
كيف يمكن تعليم النموذج هذه الاستراتيجية؟ مرة أخرى، هندسة الطلبات. إنّ الطلب الخاص بلعبة generateAIQuestion() هو في الواقع درس موجز في نظرية لعبة Guess Who?.
في البداية، طلبتُ من النموذج "طرح سؤال جيد". وكانت النتائج غير متوقّعة. لتحسين النتائج، أضفتُ قيودًا سلبية. يتضمّن الطلب الآن تعليمات مشابهة لما يلي:
- "CRITICAL: Ask about existing features ONLY"
- "مهم جدًا: يجب أن يكون المحتوى أصليًا. لا تكرِّر السؤال".
تضيّق هذه القيود نطاق تركيز النموذج وتمنعه من طرح أسئلة غير ذات صلة، ما يجعله منافسًا أكثر متعة. يمكنك مراجعة ملف الطلب الكامل على GitHub.
تعليم النموذج التحليل
كان هذا التحدي هو الأصعب والأهم على الإطلاق. عندما يطرح النموذج سؤالاً، مثل "هل يرتدي شخصيتك قبعة؟"، ويجيب اللاعب بـ "لا"، كيف يعرف النموذج الشخصيات التي تم استبعادها من اللوحة؟
يجب أن يستبعد النموذج كل شخص يرتدي قبعة. في محاولاتي الأولى، واجهتُ أخطاءً منطقية، وفي بعض الأحيان، كان النموذج يزيل الأحرف الخاطئة أو لا يزيل أي أحرف. وما المقصود بكلمة "قبعة"؟ هل تُعدّ "قبعة صغيرة" من "القبعات"؟ وهذا، لنكن صريحين، هو أيضًا أمر يمكن أن يحدث في مناظرة بين البشر. وبالطبع، تحدث أخطاء عامة. قد يبدو الشعر كقبعة من منظور الذكاء الاصطناعي.
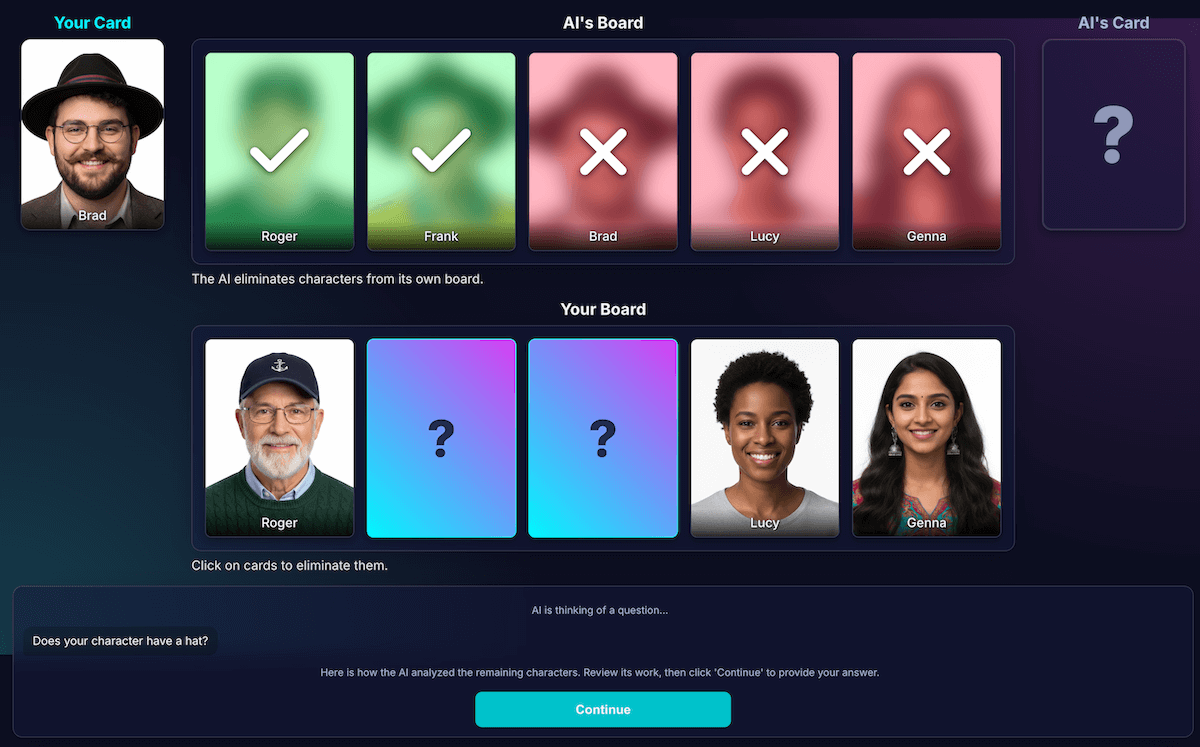
أعدتُ تصميم البنية لفصل الإدراك عن استنتاج الرمز:
الذكاء الاصطناعي مسؤول عن تحليل المرئيات. تتفوق النماذج في التحليل المرئي. طلبتُ من النموذج عرض السؤال وتحليل مفصّل بتنسيق JSON صارم. يحلّل النموذج كل حرف على لوحته ويجيب عن السؤال "هل يتضمّن هذا الحرف هذه الميزة؟". تعرض النماذج كائن JSON منظَّمًا:
{ "character_id": "...", "has_feature": true }مرة أخرى، البيانات المنظَّمة هي المفتاح لتحقيق نتيجة ناجحة.
تستخدم رموز اللعبة التحليل لاتخاذ القرار النهائي. يتحقّق رمز التطبيق من إجابة اللاعب ("نعم" أو "لا") ويتكرّر خلال تحليل الذكاء الاصطناعي. إذا أجاب اللاعب بـ "لا"، سيعرف الرمز البرمجي أنّه يجب حذف كل حرف حيث
has_featureهوtrue.
لقد تبيّن لي أنّ تقسيم العمل هذا هو المفتاح لإنشاء تطبيقات ذكاء اصطناعي موثوقة. استخدِم الذكاء الاصطناعي للاستفادة من إمكاناته التحليلية، واترك القرارات الثنائية لرمز تطبيقك.
للتحقّق من إدراك النموذج، أنشأتُ تصورًا لهذا التحليل. وقد سهّل ذلك عملية التأكّد مما إذا كان إدراك النموذج صحيحًا.
هندسة الطلبات
ومع ذلك، لاحظتُ أنّه حتى مع هذا الفصل، قد تظل إدراك النموذج معيبًا. وقد تخطئ في تحديد ما إذا كانت إحدى الشخصيات ترتدي نظارات، ما يؤدي إلى استبعادها بشكل خاطئ ومحبط. ولمكافحة ذلك، جرّبتُ عملية من خطوتَين: يطرح الذكاء الاصطناعي السؤال. بعد تلقّي إجابة اللاعب، سيتم إجراء تحليل ثانٍ جديد مع استخدام الإجابة كسياق. كانت الفكرة هي أنّ إعادة النظر قد تكشف أخطاءً لم يتم رصدها في المرة الأولى.
إليك طريقة عمل هذا المسار:
- دور الذكاء الاصطناعي (طلب البيانات من واجهة برمجة التطبيقات 1): يطرح الذكاء الاصطناعي السؤال التالي: "هل لدى شخصيتك لحية؟"
- دور اللاعب: ينظر اللاعب إلى شخصيته السرية، وهي شخصية حليقة الذقن، ويجيب بـ "لا".
- دور الذكاء الاصطناعي (طلب البيانات من واجهة برمجة التطبيقات 2): يطلب الذكاء الاصطناعي من نفسه بشكل فعّال أن ينظر إلى جميع الأحرف المتبقية، مرة أخرى، ويحدّد الأحرف التي يجب إزالتها استنادًا إلى إجابة اللاعب.
في الخطوة الثانية، قد يخطئ النموذج في فهم شخصية ذات لحية خفيفة على أنّها "لا تملك لحية"، وبالتالي لا يزيلها، على الرغم من أنّ المستخدم توقّع أن يزيلها. لم يتم إصلاح الخطأ الأساسي في الإدراك، وقد أدّت الخطوة الإضافية إلى تأخير النتائج فقط. عند اللعب ضد خصم بشري، يمكننا تحديد اتفاق أو توضيح بشأن ذلك، ولكن هذا لا ينطبق على الإعداد الحالي مع خصم الذكاء الاصطناعي.
أدت هذه العملية إلى زيادة وقت الاستجابة من خلال طلب بيانات آخر من واجهة برمجة التطبيقات، بدون تحسين الدقة بشكل ملحوظ. وإذا كان النموذج مخطئًا في المرة الأولى، كان غالبًا ما يرتكب الخطأ نفسه في المرة الثانية أيضًا. لقد أعدتُ ضبط الإعدادات لكي يتم عرض الطلب مرة واحدة فقط.
التحسين بدلاً من إضافة المزيد من التحليلات
استندتُ إلى أحد مبادئ تجربة المستخدم، وهو أنّ الحلّ لا يكمن في إجراء المزيد من التحليلات، بل في إجراء تحليلات أفضل.
استثمرتُ وقتًا طويلاً في تحسين الطلب، وأضفتُ تعليمات واضحة للنموذج كي يتحقّق من عمله ويركّز على الميزات المميّزة، وقد تبيّن أنّ هذه الاستراتيجية أكثر فعالية في تحسين الدقة. في ما يلي طريقة عمل المسار الحالي الأكثر موثوقية:
دور الذكاء الاصطناعي (طلب بيانات من واجهة برمجة التطبيقات): يُطلب من النموذج إنشاء كلّ من السؤال والتحليل الداخلي في الوقت نفسه، ما يؤدي إلى عرض عنصر JSON واحد.
- السؤال: "هل ترتدي الشخصية نظارات؟"
- التحليل (البيانات):
[ {character_id: 'brad', has_feature: true}, {character_id: 'alex', has_feature: false}, {character_id: 'gina', has_feature: true}, ... ]دور اللاعب: الشخصية السرية التي اختارها اللاعب هي "أليكس" (بدون نظارات)، لذا يجيب بـ "لا".
انتهاء الجولة: يتولّى رمز JavaScript الخاص بالتطبيق تنفيذ الإجراءات. ولا يحتاج إلى طرح أي أسئلة أخرى على الذكاء الاصطناعي. تتكرر هذه العملية على بيانات التحليل من الخطوة 1.
- قال اللاعب "لا".
- يبحث الرمز عن كل حرف يكون فيه
has_featureصحيحًا. - يقلب هذا التطبيق صورة "براد" و"جينا" إلى الأسفل. المنطق حتمي وفوري.
كانت هذه التجربة ضرورية، ولكنّها تطلّبت الكثير من المحاولات والأخطاء. لم أكن أعرف ما إذا كان سيتحسّن. وفي بعض الأحيان، كان الوضع يزداد سوءًا. إنّ تحديد الطريقة الأفضل للحصول على نتائج متسقة ليس علمًا دقيقًا (حتى الآن، وربما لن يكون كذلك أبدًا).
ولكن بعد بضع جولات مع خصمي الجديد من الذكاء الاصطناعي، ظهرت مشكلة جديدة رائعة: تعادل.
الخروج من حالة التوقف التام
وعندما يتبقى حرفان أو ثلاثة أحرف متشابهة جدًا، كان النموذج يعلق في حلقة مفرغة. سيتم طرح سؤال حول إحدى الميزات المشتركة بين الشخصيات، مثل "هل ترتدي شخصيتك قبّعة؟".
سيتعرّف الرمز البرمجي بشكل صحيح على أنّ هذه محاولة غير مجدية، وسيحاول الذكاء الاصطناعي التخمين من خلال ميزة أخرى عامة أيضًا يشترك فيها جميع الشخصيات، مثل "هل ترتدي شخصيتك نظارات؟".
لقد حسّنتُ الطلب بإضافة قاعدة جديدة: إذا تعذّر إنشاء سؤال وتبقى ثلاثة أحرف أو أقل، تتغير الاستراتيجية.
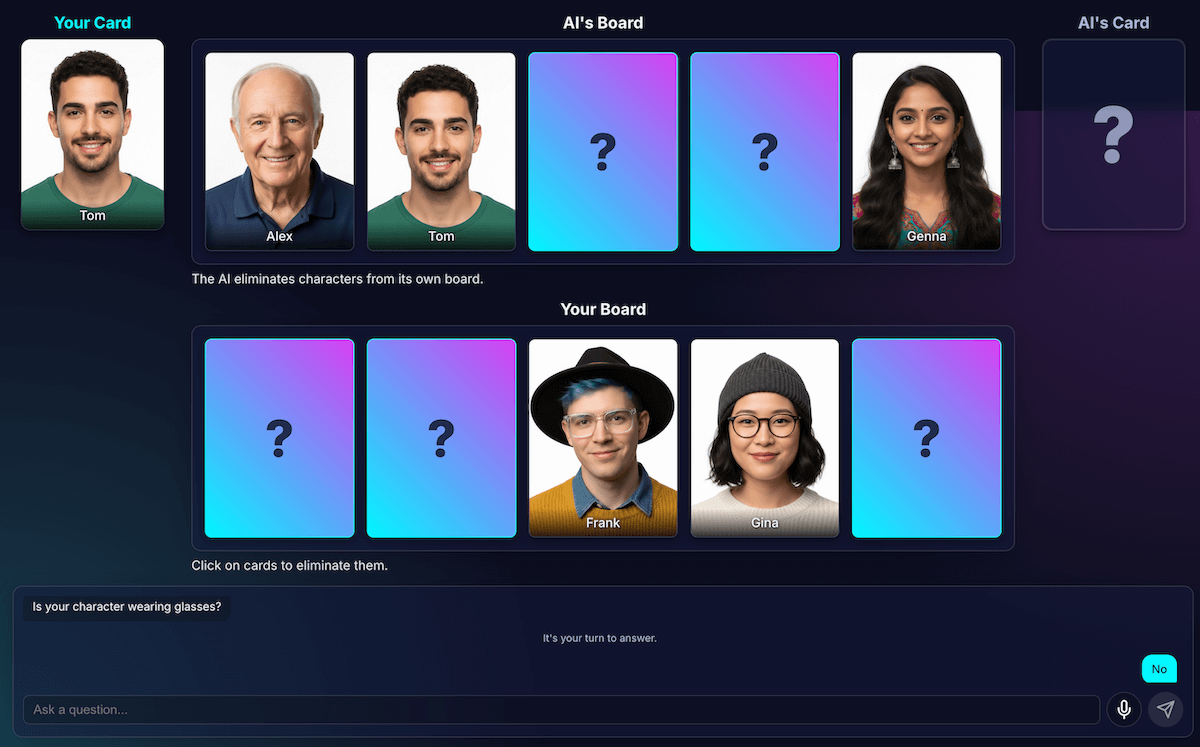
التعليمات الجديدة واضحة: "بدلاً من ميزة عامة، يجب أن تسأل عن ميزة مرئية أكثر تحديدًا أو فريدة أو مجمّعة للعثور على اختلاف". على سبيل المثال، بدلاً من السؤال عمّا إذا كانت الشخصية ترتدي قبّعة، يتم توجيه السؤال عمّا إذا كانت ترتدي قبّعة بيسبول.
ويجبر هذا الإجراء النموذج على التدقيق بشكل أكبر في الصور للعثور على التفاصيل الصغيرة التي يمكن أن تؤدي في النهاية إلى تحقيق إنجاز، ما يجعل استراتيجيته في المراحل الأخيرة من اللعبة تعمل بشكل أفضل في معظم الأحيان.
إصابة النموذج بفقدان الذاكرة
تتمثّل أكبر مزايا النموذج اللغوي في الذاكرة. ولكن في هذه اللعبة، تحوّلت نقطة القوة هذه إلى نقطة ضعف. وعندما بدأت لعبة ثانية، طرحت عليّ أسئلة مربكة أو غير ذات صلة. بالطبع، كان خصمي الذكي الذي يعمل بالذكاء الاصطناعي يحتفظ بسجلّ المحادثة الكامل من المباراة السابقة. كانت تحاول فهم مباراتين (أو أكثر) في الوقت نفسه.
بدلاً من إعادة استخدام جلسة الذكاء الاصطناعي نفسها، أصبحت الآن أوقفها بشكل صريح في نهاية كل مباراة، ما يمنح الذكاء الاصطناعي حالة فقدان ذاكرة.
عند النقر على تشغيل مرة أخرى، تعيد الدالة startNewGameSession() ضبط اللوحة وتنشئ جلسة جديدة تمامًا مع الذكاء الاصطناعي. كان هذا درسًا مهمًا في
إدارة حالة الجلسة ليس فقط في التطبيق، بل
داخل نموذج الذكاء الاصطناعي نفسه.
ميزات إضافية: ألعاب مخصّصة وإدخال صوتي
لجعل التجربة أكثر جاذبية، أضفتُ ميزتَين إضافيتَين:
الشخصيات المخصّصة: باستخدام
getUserMedia()، يمكن للاعبين استخدام الكاميرا لإنشاء مجموعة من 5 أحرف. استخدمت IndexedDB لحفظ الأحرف، وهي قاعدة بيانات متصفّح مثالية لتخزين البيانات الثنائية مثل كائنات الصور الثنائية الكبيرة. عند إنشاء مجموعة مخصّصة، يتم حفظها في متصفّحك، ويظهر خيار إعادة التشغيل في القائمة الرئيسية.الإدخال الصوتي: النموذج من جهة العميل متعدّد الوسائط. يمكنه التعامل مع النصوص والصور والمقاطع الصوتية. باستخدام MediaRecorder API لتسجيل الإدخال من الميكروفون، يمكنني إدخال البيانات الصوتية الناتجة إلى النموذج مع طلب: "اكتب نصًا من الصوت التالي...". توفّر هذه الميزة طريقة ممتعة للعب (وطريقة ممتعة لمعرفة كيف تفسّر لهجتي الفلمنكية). لقد أنشأتُ هذا التطبيق في الغالب لإظهار تنوّع استخدامات هذه الميزة الجديدة على الويب، ولكن في الواقع، كنتُ أملّ من كتابة الأسئلة مرارًا وتكرارًا.
عرض توضيحي
يمكنك تجربة اللعبة مباشرةً هنا أو اللعب في نافذة جديدة والعثور على الرمز المصدري على GitHub.
نصائح أخيرة
كانت عملية إنشاء لعبة "من أنا؟" باستخدام الذكاء الاصطناعي صعبة بالتأكيد. ولكن بمساعدة بسيطة من قراءة المستندات وبعض أدوات الذكاء الاصطناعي لتصحيح أخطاء الذكاء الاصطناعي (نعم... وقد كانت تجربة ممتعة. وقد سلّط الضوء على الإمكانات الهائلة لتشغيل نموذج في المتصفّح من أجل توفير تجربة خاصة وسريعة لا تتطلّب الاتصال بالإنترنت. هذه الميزة لا تزال تجريبية، وقد لا يلعب الخصم بشكل مثالي في بعض الأحيان. فهي ليست مثالية من الناحية البصرية أو المنطقية. باستخدام الذكاء الاصطناعي التوليدي، تعتمد النتائج على النموذج.
بدلاً من السعي إلى الكمال، سأركّز على تحسين النتيجة.
أكّد هذا المشروع أيضًا على التحديات المستمرة التي تواجه هندسة الطلبات. أصبح هذا التوجيه جزءًا كبيرًا من عملي، ولم يكن دائمًا الجزء الأكثر متعة. لكنّ الدرس الأهم الذي تعلّمته هو تصميم التطبيق لفصل الإدراك عن الاستنتاج، وتقسيم إمكانات الذكاء الاصطناعي والرموز البرمجية. مع ذلك، لاحظتُ أنّ الذكاء الاصطناعي كان يرتكب أخطاء واضحة (بالنسبة إلى الإنسان)، مثل الخلط بين الوشوم والمكياج أو عدم تتبُّع الشخصية السرية التي يتم التحدث عنها.
في كل مرة، كان الحلّ هو جعل الطلبات أكثر وضوحًا، وذلك من خلال إضافة تعليمات تبدو بديهية بالنسبة إلى الإنسان ولكنّها ضرورية للنموذج.
في بعض الأحيان، شعرت بأنّ اللعبة غير عادلة. في بعض الأحيان، شعرتُ أنّ الذكاء الاصطناعي "يعرف" الحرف السري مسبقًا، مع أنّ الرمز لم يشارك هذه المعلومات بشكل صريح. يوضّح هذا القسم جزءًا مهمًا من الفرق بين الإنسان والآلة:
لا يجب أن يكون سلوك الذكاء الاصطناعي صحيحًا فحسب، بل يجب أن يبدو عادلاً.
لهذا السبب، عدّلتُ الطلبات بإضافة تعليمات مباشرة، مثل "لا يمكنك معرفة الشخصية التي اخترتها" و "لا تغشّ". لقد تبيّن لي أنّه عند إنشاء وكلاء يعملون بالذكاء الاصطناعي، يجب تخصيص وقت لتحديد القيود، وربما أكثر من الوقت المخصّص للتعليمات.
يمكن مواصلة تحسين التفاعل مع النموذج. عند استخدام نموذج مدمج، ستفقد بعضًا من قوة النموذج الضخم المستند إلى الخادم وموثوقيته، ولكن ستستفيد من الخصوصية والسرعة وإمكانية الاستخدام بلا إنترنت. بالنسبة إلى لعبة من هذا النوع، كان من المفيد جدًا تجربة هذا التوازن. إنّ مستقبل الذكاء الاصطناعي من جهة العميل يتحسّن يومًا بعد يوم، كما أنّ النماذج أصبحت أصغر حجمًا، وأنا متحمّس لمعرفة ما سنتمكّن من إنشائه في المستقبل.