

Gepubliceerd: 10 oktober 2025

Het klassieke bordspel ' Wie is het? ' is een meesterwerk in deductief redeneren. Elke speler begint met een bord vol gezichten en moet, door middel van een reeks ja/nee-vragen, de mogelijkheden steeds verder beperken totdat hij of zij met zekerheid het geheime personage van de tegenstander kan identificeren.
Na een demonstratie van ingebouwde AI op Google I/O Connect vroeg ik me af: wat als ik een 'Wie is wie?'-spel zou kunnen spelen tegen een AI die in de browser draait? Met client-side AI zouden de foto's lokaal worden geïnterpreteerd, waardoor een gepersonaliseerd 'Wie is wie?'-spel met vrienden en familie privé en veilig op mijn apparaat zou blijven.
Mijn achtergrond ligt voornamelijk in UI- en UX-ontwikkeling, en ik ben gewend om pixelperfecte ervaringen te creëren. Ik hoopte dat ik met mijn interpretatie precies dat zou kunnen bereiken.
Mijn applicatie, AI Guess Who?, is gebouwd met React en maakt gebruik van de Prompt API en een ingebouwd browsermodel om een verrassend capabele tegenstander te creëren. Tijdens dit proces ontdekte ik dat het niet zo eenvoudig is om "pixel-perfecte" resultaten te behalen. Deze applicatie laat echter zien hoe AI kan worden gebruikt om doordachte spelmechanismen te ontwikkelen, en hoe belangrijk prompt engineering is om deze mechanismen te verfijnen en de gewenste resultaten te bereiken.
Lees verder om meer te weten te komen over de ingebouwde AI-integratie, de uitdagingen waar ik voor stond en de oplossingen die ik heb gevonden. Je kunt het spel spelen en de broncode vinden op GitHub .
Game Foundation: een React-app
Voordat we de AI-implementatie bekijken, nemen we eerst de structuur van de applicatie door. Ik heb een standaard React-applicatie gebouwd met TypeScript, met een centraal App.tsx bestand dat als de dirigent van het spel fungeert. Dit bestand bevat:
- Spelstatus : Een enum die de huidige fase van het spel bijhoudt (zoals
PLAYER_TURN_ASKING,AI_TURN,GAME_OVER). Dit is het belangrijkste onderdeel van de status, omdat het bepaalt wat de interface weergeeft en welke acties de speler kan uitvoeren. - Personagelijsten : Er zijn meerdere lijsten die de actieve personages, het geheime personage van elke speler en de personages die van het bord zijn verwijderd, aangeven.
- Spelchat : Een doorlopend logboek van vragen, antwoorden en systeemberichten.
De interface is opgedeeld in logische componenten:
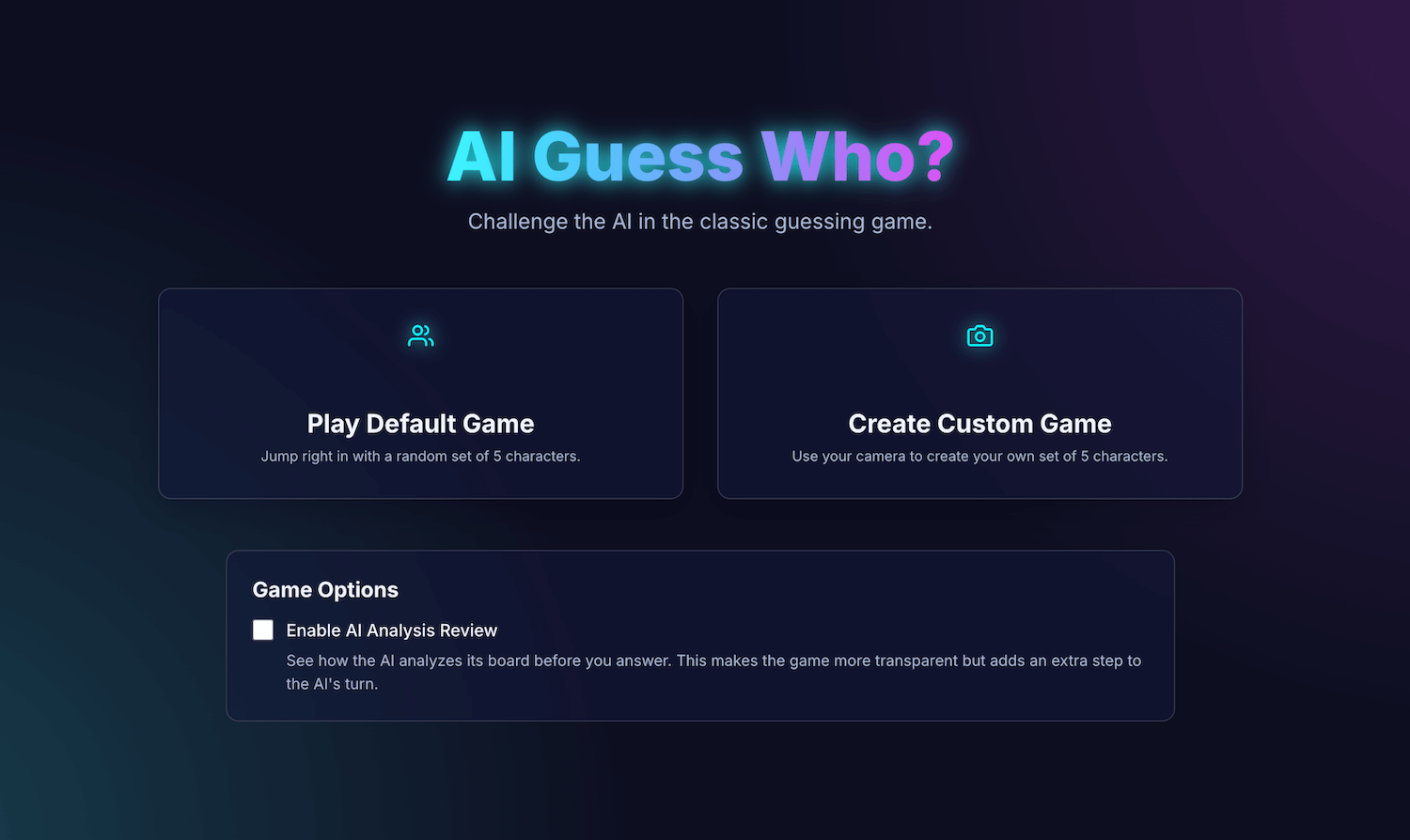

Naarmate de functionaliteiten van het spel toenamen, werd ook de complexiteit ervan groter. Aanvankelijk werd de volledige spellogica beheerd binnen één grote, op maat gemaakte React-hook , useGameLogic , maar deze werd al snel te omvangrijk om te navigeren en te debuggen. Om de onderhoudbaarheid te verbeteren, heb ik deze hook opgesplitst in meerdere hooks, elk met een eigen verantwoordelijkheid. Bijvoorbeeld:
-
useGameStatebeheert de kernstatus. -
usePlayerActionsis voor de beurt van de speler. -
useAIActionsis voor de logica van de AI.
De belangrijkste useGameLogic hook fungeert nu als een overzichtelijke samensteller, die deze kleinere hooks bij elkaar plaatst. Deze architectonische wijziging heeft de functionaliteit van het spel niet veranderd, maar de codebase is er wel een stuk schoner door geworden.
Spellogica met de Prompt API
De kern van dit project is het gebruik van de Prompt API.
Ik heb de AI-spellogica toegevoegd aan builtInAIService.ts . Dit zijn de belangrijkste taken:
- Sta beperkende, binaire antwoorden toe.
- Leer het model de spelstrategie aan.
- Leer modelanalyse.
- Geef het model geheugenverlies.
Sta beperkende, binaire antwoorden toe.
Hoe communiceert de speler met de AI? Wanneer een speler vraagt: "Heeft jouw personage een hoed?", moet de AI naar de afbeelding van zijn geheime personage "kijken" en een duidelijk antwoord geven.
Mijn eerste pogingen waren een puinhoop. Het antwoord was informeel: "Nee, het personage waar ik aan denk, Isabella, lijkt geen hoed te dragen," in plaats van een binair ja of nee. Aanvankelijk loste ik dit op met een zeer strikte instructie, waarbij ik het model in feite opdroeg alleen met "Ja" of "Nee" te antwoorden.
Hoewel dit werkte, ontdekte ik een nog betere manier met behulp van gestructureerde uitvoer . Door het JSON-schema aan het model te verstrekken, kon ik een gegarandeerd waar of onwaar antwoord geven.
const schema = { type: "boolean" };
const result = session.prompt(prompt, { responseConstraint: schema });
Hierdoor kon ik de prompt vereenvoudigen en kon mijn code de reactie betrouwbaar afhandelen:
JSON.parse(result) ? "Yes" : "No"
Leer de modelspelstrategie aan.
Het is veel eenvoudiger om een model een vraag te laten beantwoorden dan om het model zelf vragen te laten stellen. Een goede Guess Who?-speler stelt geen willekeurige vragen. Hij stelt vragen die zoveel mogelijk personages tegelijk elimineren. Een ideale vraag halveert het aantal mogelijke overgebleven personages door binaire vragen te stellen.
Hoe leer je een model die strategie aan? Wederom: prompt engineering. De prompt voor generateAIQuestion() is in feite een beknopte les in de speltheorie van Guess Who?.
Aanvankelijk vroeg ik het model om "een goede vraag te stellen". De resultaten waren onvoorspelbaar. Om de resultaten te verbeteren, voegde ik negatieve beperkingen toe. De prompt bevat nu instructies die lijken op:
- "BELANGRIJK: Vraag ALLEEN naar bestaande functies"
- "BELANGRIJK: Wees origineel. Herhaal geen vraag."
Deze beperkingen vernauwen de focus van het model, voorkomen dat het irrelevante vragen stelt, waardoor het een veel leukere tegenstander wordt. Je kunt het volledige promptbestand bekijken op GitHub .
Leer de modelanalyse
Dit was verreweg de moeilijkste en belangrijkste uitdaging. Als het model een vraag stelt, zoals: "Heeft je personage een hoed?", en de speler antwoordt nee, hoe weet het model dan welke personages op hun speelbord zijn uitgeschakeld?
Het model zou iedereen met een hoed moeten elimineren. Mijn eerste pogingen zaten vol logische fouten, en soms elimineerde het model de verkeerde personages of helemaal geen personages. En wat is een "hoed" eigenlijk? Telt een "muts" als een "hoed"? Laten we eerlijk zijn, dit kan ook gebeuren in een menselijke discussie. En natuurlijk gebeuren er algemene fouten. Haar kan er vanuit het perspectief van een AI uitzien als een hoed.
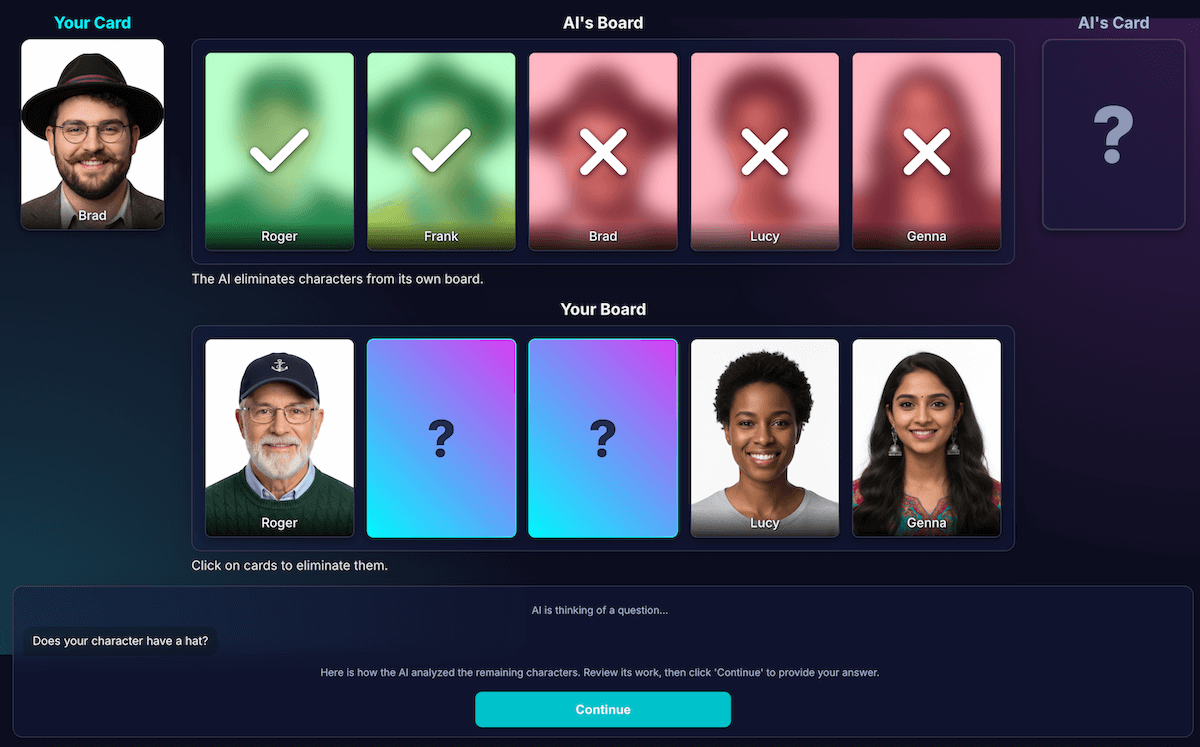
Ik heb de architectuur opnieuw ontworpen om perceptie en code-afleiding van elkaar te scheiden:
AI is verantwoordelijk voor visuele analyse . Modellen blinken uit in visuele analyse. Ik heb het model de opdracht gegeven om de vraag en een gedetailleerde analyse in een strikt JSON-schema terug te geven. Het model analyseert elk personage op het bord en beantwoordt de vraag: "Heeft dit personage deze eigenschap?" Het model retourneert een gestructureerd JSON-object:
{ "character_id": "...", "has_feature": true }Wederom is gestructureerde data essentieel voor een succesvol resultaat.
De spelcode gebruikt de analyse om de uiteindelijke beslissing te nemen . De applicatiecode controleert het antwoord van de speler ("Ja" of "Nee") en doorloopt de analyse van de AI. Als de speler "Nee" heeft gezegd, weet de code dat alle personages met
has_featuretruemoeten worden verwijderd.
Ik heb ontdekt dat deze taakverdeling essentieel is voor het bouwen van betrouwbare AI-toepassingen. Gebruik de AI voor zijn analytische mogelijkheden en laat binaire beslissingen over aan je applicatiecode.
Om de waarneming van het model te controleren, heb ik een visualisatie van deze analyse gemaakt. Dit maakte het gemakkelijker om te bevestigen of de waarneming van het model correct was.
Snelle engineering
Zelfs met deze scheiding merkte ik echter dat de perceptie van het model nog steeds gebrekkig kon zijn. Het kon bijvoorbeeld verkeerd inschatten of een personage een bril droeg, wat leidde tot een frustrerende, onjuiste eliminatie. Om dit te verhelpen, experimenteerde ik met een tweestappenproces: de AI stelde eerst een vraag. Na het antwoord van de speler voerde de AI een tweede, nieuwe analyse uit met het antwoord als context. De theorie was dat een tweede analyse fouten uit de eerste analyse zou kunnen opsporen.
Zo zou dat proces hebben gewerkt:
- AI-reactie (API-aanroep 1) : De AI vraagt: "Heeft je personage een baard?"
- Aan de beurt van de speler : De speler kijkt naar zijn geheime personage, dat gladgeschoren is, en antwoordt: "Nee."
- AI-beurt (API-aanroep 2) : De AI vraagt zichzelf in feite om alle overgebleven personages opnieuw te bekijken en te bepalen welke personages geëlimineerd moeten worden op basis van het antwoord van de speler.
In stap twee kan het model een personage met lichte stoppels nog steeds verkeerd interpreteren als "geen baard hebbend" en deze niet verwijderen, ook al verwacht de gebruiker dit wel. De kernfout in de perceptie is niet verholpen en de extra stap heeft de resultaten alleen maar vertraagd. Bij een wedstrijd tegen een menselijke tegenstander kunnen we hierover afspraken maken of verduidelijken; in de huidige situatie met onze AI-tegenstander is dat niet mogelijk.
Dit proces zorgde voor extra vertraging door een tweede API-aanroep, zonder dat de nauwkeurigheid significant verbeterde. Als het model de eerste keer fout zat, zat het vaak de tweede keer ook fout. Ik heb de prompt daarom teruggezet naar slechts één beoordeling.
Verbeteren in plaats van meer analyses toe te voegen.
Ik heb me gebaseerd op een UX-principe: de oplossing was niet meer analyse, maar betere analyse.
Ik heb flink geïnvesteerd in het verfijnen van de prompt, door expliciete instructies toe te voegen zodat het model zijn werk dubbel controleert en zich concentreert op specifieke kenmerken. Dit bleek een effectievere strategie te zijn om de nauwkeurigheid te verbeteren. Zo werkt de huidige, betrouwbaardere workflow:
AI-aanroep (API-aanroep) : Het model wordt gevraagd om tegelijkertijd de vraag en de interne analyse te genereren, waarna één JSON-object wordt geretourneerd.
- Vraag : "Draagt jouw personage een bril?"
- Analyse (gegevens) :
[ {character_id: 'brad', has_feature: true}, {character_id: 'alex', has_feature: false}, {character_id: 'gina', has_feature: true}, ... ]Aan de beurt van de speler : Het geheime personage van de speler is Alex (zonder bril), dus antwoordt hij: "Nee."
Ronde eindigt : De JavaScript-code van de applicatie neemt het over. Deze hoeft de AI verder niets meer te vragen. De code doorloopt de analysegegevens uit stap 1.
- De speler zei "Nee."
- De code zoekt naar elk teken waar
has_featurewaar is. - Het klapt Brad en Gina om. De logica is deterministisch en onmiddellijk.
Dit experiment was cruciaal, maar vergde veel vallen en opstaan. Ik had geen idee of het beter zou worden. Soms werd het zelfs erger. Bepalen hoe je de meest consistente resultaten krijgt, is geen exacte wetenschap (nog niet, en misschien wordt het dat wel ooit...).
Maar na een paar rondes met mijn nieuwe AI-tegenstander dook er een fantastisch nieuw probleem op: een patstelling.
Ontsnap aan de impasse
Als er nog maar twee of drie zeer vergelijkbare personages overbleven, raakte het model in een oneindige lus. Het stelde dan een vraag over een kenmerk dat ze allemaal deelden, zoals: "Draagt jouw personage een hoed?"
Mijn code zou dit correct identificeren als een verspilde beurt, en de AI zou een ander, even algemeen kenmerk proberen dat de personages ook gemeen hebben, zoals: "Draagt je personage een bril?"
Ik heb de prompt uitgebreid met een nieuwe regel: als een poging tot het genereren van een vraag mislukt en er nog drie of minder tekens over zijn, verandert de strategie.
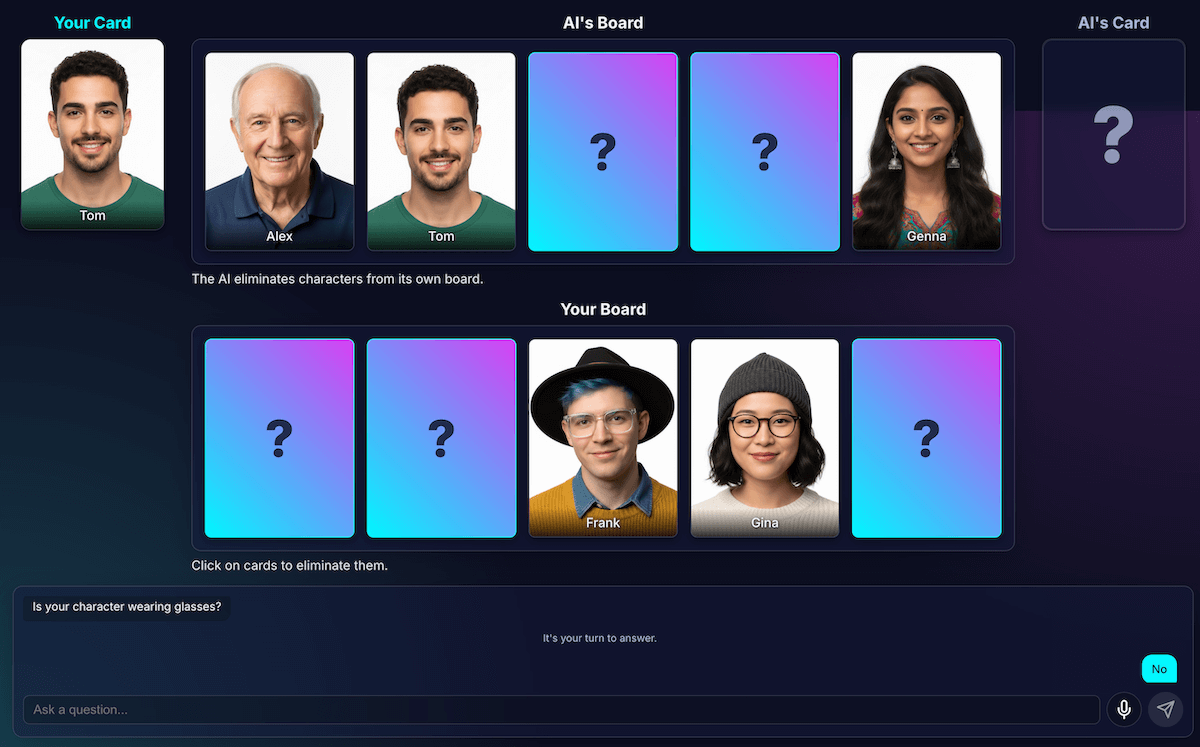
De nieuwe instructie is expliciet: "In plaats van een algemeen kenmerk, moet je vragen naar een specifiekere, unieke of gecombineerde visuele eigenschap om een verschil te vinden." In plaats van bijvoorbeeld te vragen of het personage een hoed draagt, wordt er gevraagd of ze een baseballpet dragen.
Dit dwingt het model om veel nauwkeuriger naar de beelden te kijken om dat ene kleine detail te vinden dat uiteindelijk tot een doorbraak kan leiden, waardoor de strategie in de latere fasen van het spel meestal iets beter werkt.
Geef het model geheugenverlies.
De grootste kracht van een taalmodel is het geheugen. Maar in dit spel werd die grootste kracht juist een zwakte. Toen ik een tweede spel startte, stelde het model verwarrende of irrelevante vragen. Mijn slimme AI-tegenstander had natuurlijk de volledige chatgeschiedenis van het vorige spel onthouden. Hij probeerde twee (of zelfs meer) spellen tegelijk te begrijpen.
In plaats van dezelfde AI-sessie opnieuw te gebruiken, vernietig ik deze nu expliciet aan het einde van elk spel, waardoor de AI in feite geheugenverlies krijgt.
Wanneer je op ' Opnieuw spelen' klikt, reset de functie startNewGameSession() het speelbord en creëert een gloednieuwe AI-sessie. Dit was een interessante les in het beheren van de sessiestatus, niet alleen in de app, maar ook binnen het AI-model zelf.
Extraatjes: Aangepaste spellen en spraakinvoer
Om de ervaring boeiender te maken, heb ik twee extra functies toegevoegd:
Aangepaste personages : Met
getUserMedia()kunnen spelers hun camera gebruiken om hun eigen set van 5 personages te creëren. Ik heb IndexedDB gebruikt om de personages op te slaan, een browserdatabase die perfect is voor het opslaan van binaire gegevens zoals afbeeldingsblobs. Wanneer je een aangepaste set maakt, wordt deze opgeslagen in je browser en verschijnt er een optie om deze opnieuw af te spelen in het hoofdmenu.Spraakinvoer : Het clientmodel is multimodaal . Het kan tekst, afbeeldingen en ook audio verwerken. Door de MediaRecorder API te gebruiken om microfooninvoer vast te leggen, kon ik de resulterende audio aan het model geven met de prompt: "Transcribeer de volgende audio...". Dit voegt een leuke manier toe om te spelen (en een leuke manier om te zien hoe het mijn Vlaamse accent interpreteert). Ik heb dit vooral gemaakt om de veelzijdigheid van deze nieuwe webfunctionaliteit te demonstreren, maar eerlijk gezegd was ik het zat om steeds opnieuw vragen te typen.
Demo
Je kunt het spel hier direct testen of in een nieuw venster spelen en de broncode op GitHub vinden.
Tot slot
Het bouwen van "AI Guess Who?" was absoluut een uitdaging. Maar met een beetje hulp van het lezen van documentatie en wat AI om AI te debuggen (ja... dat heb ik gedaan), bleek het een leuk experiment te zijn. Het benadrukte het enorme potentieel van het draaien van een model in de browser voor het creëren van een privé, snelle ervaring zonder internetverbinding. Dit is nog steeds een experiment, en soms speelt de tegenstander gewoon niet perfect. Het is niet pixelperfect of logisch perfect. Bij generatieve AI zijn de resultaten modelafhankelijk.
In plaats van naar perfectie te streven, zal ik ernaar streven het resultaat te verbeteren.
Dit project benadrukte ook de voortdurende uitdagingen van prompt-engineering. Het geven van prompts werd echt een enorm belangrijk onderdeel, en niet altijd het leukste. Maar de belangrijkste les die ik leerde, was het ontwerpen van de applicatie om perceptie en deductie van elkaar te scheiden, en zo de mogelijkheden van AI en code te verdelen. Zelfs met die scheiding merkte ik dat de AI nog steeds (voor een mens) overduidelijke fouten kon maken, zoals tatoeages verwarren met make-up of de draad kwijtraken over wiens geheime personage er werd besproken.
Telkens was de oplossing om de aanwijzingen nog explicieter te maken, door instructies toe te voegen die voor een mens vanzelfsprekend lijken, maar essentieel zijn voor het model.
Soms voelde het spel oneerlijk aan. Af en toe had ik het gevoel dat de AI het geheime personage van tevoren "wist", ook al werd die informatie nooit expliciet in de code gedeeld. Dit illustreert een cruciaal aspect van de strijd tussen mens en machine:
Het gedrag van een AI moet niet alleen correct zijn, maar ook eerlijk aanvoelen .
Daarom heb ik de prompts aangepast met duidelijke instructies, zoals: "Je weet NIET welk personage ik heb gekozen" en "Niet valsspelen". Ik heb geleerd dat je bij het bouwen van AI-agenten tijd moet besteden aan het definiëren van beperkingen, waarschijnlijk zelfs meer dan aan instructies.
De interactie met het model kan nog verder worden verbeterd. Door met een ingebouwd model te werken, verlies je weliswaar wat van de kracht en betrouwbaarheid van een enorm servermodel, maar je wint aan privacy, snelheid en offline functionaliteit. Voor een spel als dit was die afweging het experimenteren zeker waard. De toekomst van client-side AI wordt met de dag beter, modellen worden ook steeds kleiner, en ik kan niet wachten om te zien wat we de volgende keer zullen kunnen bouwen.