

Yayınlanma tarihi: 10 Ekim 2025

Klasik masa oyunu Kim Bu?, tümdengelimli akıl yürütme konusunda ustalık sınıfı niteliğindedir. Her oyuncu, yüzlerin yer aldığı bir tahtayla başlar ve bir dizi evet/hayır sorusuyla rakibinin gizli karakterini kesin olarak belirleyene kadar olasılıkları daraltır.
Google I/O Connect'te yerleşik yapay zeka demosunu gördükten sonra, tarayıcıda çalışan yapay zekaya karşı Tahmin Etme Oyunu oynayabilseydim nasıl olurdu diye düşündüm. İstemci tarafı yapay zeka sayesinde fotoğraflar yerel olarak yorumlanacağından, arkadaş ve aile üyelerinden oluşan özel bir Tahmin Etme oyunu cihazımda gizli ve güvenli kalır.
Genellikle kullanıcı arayüzü ve kullanıcı deneyimi geliştirme alanında çalışıyorum ve piksel açısından mükemmel deneyimler oluşturmaya alışkınım. Yorumumla tam olarak bunu yapabileceğimi umuyordum.
React ile oluşturulan AI Guess Who? uygulamam, şaşırtıcı derecede yetenekli bir rakip oluşturmak için Prompt API'yi ve tarayıcıda yerleşik bir modeli kullanıyor. Bu süreçte, "piksel açısından mükemmel" sonuçlar elde etmenin o kadar da kolay olmadığını keşfettim. Ancak bu uygulama, yapay zekanın nasıl kullanılarak iyi düşünülmüş bir oyun mantığı oluşturulabileceğini ve bu mantığı iyileştirip beklediğiniz sonuçları elde etmek için istem mühendisliğinin önemini gösteriyor.
Yerleşik yapay zeka entegrasyonu, karşılaştığım zorluklar ve bulduğum çözümler hakkında bilgi edinmek için okumaya devam edin. Oyunu oynayabilir ve kaynak kodunu GitHub'da bulabilirsiniz.
Oyunun temeli: React uygulaması
Yapay zeka uygulamasını incelemeden önce uygulamanın yapısını gözden geçirelim. TypeScript ile standart bir React uygulaması oluşturdum. Bu uygulamada, oyunun yöneticisi olarak işlev görecek merkezi bir App.tsx dosyası var. Bu dosya şunları içerir:
- Oyun durumu: Oyunun mevcut aşamasını (ör.
PLAYER_TURN_ASKING,AI_TURN,GAME_OVER) izleyen bir enum. Bu, arayüzün ne göstereceğini ve oyuncunun hangi işlemleri yapabileceğini belirlediği için en önemli durum parçasıdır. - Karakter listeleri: Etkin karakterleri, her oyuncunun gizli karakterini ve tahtadan çıkarılan karakterleri belirten birden fazla liste vardır.
- Oyun içi sohbet: Sorular, yanıtlar ve sistem mesajlarının yer aldığı bir günlük.
Arayüz, mantıksal bileşenlere ayrılmıştır:

Oyunun özellikleri arttıkça karmaşıklığı da arttı. Başlangıçta, oyunun tüm mantığı tek bir büyük özel React kancası içinde yönetiliyordu useGameLogic ancak bu kanca, gezinmek ve hata ayıklamak için çok büyük hale geldi. Bakımı kolaylaştırmak için bu kancayı, her biri tek bir sorumluluğa sahip birden fazla kancaya yeniden düzenledim.
Örneğin:
useGameStatetemel durumu yönetirusePlayerActions, oyuncunun sırası içindir.useAIActions, yapay zekanın mantığı içindir.
Ana useGameLogic kanca artık bu küçük kancaları bir araya getiren temiz bir besteci görevi görüyor. Bu mimari değişiklik, oyunun işlevselliğini değiştirmedi ancak kod tabanını çok daha temiz hale getirdi.
İstem API'si ile oyun mantığı
Bu projenin temelinde Prompt API'nin kullanımı yer alır.
builtInAIService.ts oyununa yapay zeka oyun mantığını ekledim. Başlıca sorumlulukları şunlardır:
- Kısıtlayıcı, ikili yanıtlara izin verin.
- Modele oyun stratejisini öğretin.
- Model analizini öğretin.
- Modele amnezi verin.
Kısıtlayıcı, ikili yanıtlara izin ver
Oyuncu, yapay zekayla nasıl etkileşim kurar? Bir oyuncu "Karakterinin şapkası var mı?" diye sorduğunda yapay zeka, gizli karakterinin resmine "bakıp" net bir yanıt vermelidir.
İlk denemelerim berbattı. Yanıt, "Evet" veya "Hayır" şeklinde ikili bir cevap vermek yerine sohbet eder gibi yanıt veriyordu: "Hayır, düşündüğüm karakter Isabella şapka takmıyor." Başlangıçta bunu çok katı bir istemle çözdüm. Temel olarak modele yalnızca "Evet" veya "Hayır" şeklinde yanıt vermesini söylüyordum.
Bu yöntem işe yarasa da yapılandırılmış çıkış kullanarak daha iyi bir yöntem olduğunu öğrendim. Modele JSON şeması sağlayarak doğru veya yanlış yanıt almayı garanti edebiliyordum.
const schema = { type: "boolean" };
const result = session.prompt(prompt, { responseConstraint: schema });
Bu sayede istemi basitleştirebildim ve kodumun yanıtı güvenilir bir şekilde işlemesini sağlayabildim:
JSON.parse(result) ? "Yes" : "No"
Modele oyun stratejisini öğretme
Modele bir soruyu yanıtlamasını söylemek, modelin soru başlatıp sormasını sağlamaktan çok daha basittir. İyi bir Tahmin Et Bakalım? oyuncusu rastgele sorular sormaz. Tek seferde en çok karakteri eleyen sorular sorarlar. İdeal bir soru, ikili sorular kullanarak olası kalan karakter sayısını yarıya indirir.
Bir modele bu stratejiyi nasıl öğretebilirsiniz? Yine istem mühendisliği. generateAIQuestion() istemi, aslında Kim Bu? oyun teorisiyle ilgili kısa bir ders niteliğinde.
Başlangıçta modelden "iyi bir soru sormasını" istedim. Sonuçlar tahmin edilemezdi. Sonuçları iyileştirmek için negatif kısıtlamalar ekledim. İstem artık aşağıdakine benzer talimatlar içeriyor:
- "CRITICAL: Ask about existing features ONLY" (KRİTİK: YALNIZCA MEVCUT ÖZELLİKLER HAKKINDA SORU SOR)
- "CRITICAL: Be original. Soruyu TEKRARLAMAYIN".
Bu kısıtlamalar, modelin odak noktasını daraltır ve alakasız sorular sormasını önler. Bu sayede model, çok daha keyifli bir rakip hâline gelir. İstemin tam dosyasını GitHub'da inceleyebilirsiniz.
Model analizini eğitme
Bu, açık ara en zorlu ve en önemli mücadeleydi. Model, "Karakterinizin şapkası var mı?" gibi bir soru sorduğunda ve oyuncu hayır yanıtını verdiğinde model, tahtasındaki hangi karakterlerin elendiğini nasıl anlar?
Model, şapkalı herkesi elemelidir. İlk denemelerimde mantık hataları vardı. Model bazen yanlış karakterleri veya hiçbir karakteri silmiyordu. Ayrıca "şapka" nedir? "Bere" kelimesi "şapka" olarak mı sayılır? Dürüst olmak gerekirse bu, insan tartışmalarında da yaşanabilir. Elbette genel hatalar da olabilir. Saçlar, yapay zeka açısından şapka gibi görünebilir.
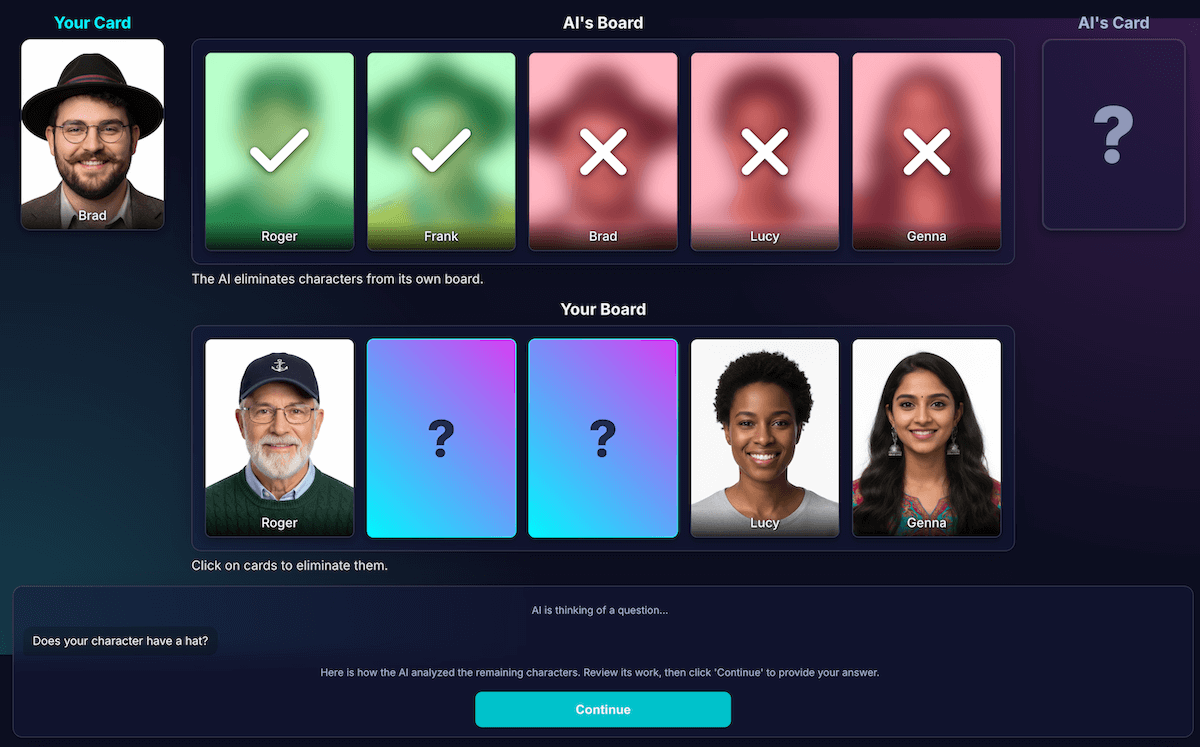
Mimaride, algılamayı kod çıkarımından ayıracak şekilde yeniden tasarım yaptım:
Görsel analizden yapay zeka sorumludur. Modeller, görsel analiz konusunda mükemmeldir. Modele, sorusunu ve ayrıntılı analizini katı bir JSON şemasıyla döndürmesi talimatını verdim. Model, tahtasındaki her karakteri analiz eder ve "Bu karakterde bu özellik var mı?" sorusunu yanıtlar. Model, yapılandırılmış bir JSON nesnesi döndürür:
{ "character_id": "...", "has_feature": true }Başarılı bir sonuç için yine yapılandırılmış veriler çok önemlidir.
Oyun kodu, son kararı vermek için analizden yararlanır. Uygulama kodu, oyuncunun yanıtını ("Evet" veya "Hayır") kontrol eder ve yapay zekanın analizini yineler. Oyuncu "Hayır" yanıtını verirse kod,
has_featurekarakterinintrueolduğu her yeri siler.
Bu iş bölümünün, güvenilir yapay zeka uygulamaları oluşturmak için çok önemli olduğunu gördüm. Yapay zekayı analiz özelliklerinden yararlanmak için kullanın ve ikili kararları uygulama kodunuza bırakın.
Modelin algısını kontrol etmek için bu analizin görselleştirilmiş halini oluşturdum. Bu sayede, modelin algısının doğru olup olmadığını doğrulamak kolaylaştı.
İstem mühendisliği
Ancak bu ayrım yapıldığında bile modelin algısının kusurlu olabileceğini fark ettim. Bir karakterin gözlük takıp takmadığını yanlış değerlendirerek sinir bozucu ve yanlış bir eleme yapabilir. Bununla mücadele etmek için iki adımlı bir süreç denedim: Yapay zeka sorusunu soruyordu. Oyuncunun yanıtını aldıktan sonra, yanıtı bağlam olarak kullanarak ikinci ve yeni bir analiz yapardı. Bu teorinin amacı, ikinci bir incelemenin ilk incelemedeki hataları yakalayabileceğiydi.
Bu akışın işleyiş şekli:
- Yapay zeka sırası (API çağrısı 1): Yapay zeka, "Karakterinizin sakalı var mı?" diye soruyor.
- Oyuncunun sırası: Oyuncu, gizli karakterine bakar (karakterin sakalı yoktur) ve "Hayır" yanıtını verir.
- Yapay zeka sırası (API çağrısı 2): Yapay zeka, kalan tüm karakterlerine tekrar bakmasını ve oyuncunun yanıtına göre hangilerini eleyeceğini belirlemesini etkili bir şekilde ister.
İkinci adımda, model, hafif sakallı bir karakteri "sakalsız" olarak algılamaya devam edebilir ve kullanıcının beklentisine rağmen bu karakteri eleyemeyebilir. Temel algılama hatası düzeltilmedi ve ek adım yalnızca sonuçları geciktirdi. İnsan rakibe karşı oynarken bu konuda bir anlaşma veya açıklama belirtebiliriz. Ancak yapay zeka rakibimizle oynarken bu durum geçerli değildir.
Bu işlem, doğrulukta önemli bir artış sağlamadan ikinci bir API çağrısından kaynaklanan gecikme ekledi. Model ilk seferinde yanlışsa genellikle ikinci seferde de yanlış oluyordu. Yalnızca bir kez inceleme yapılması için istemi geri aldım.
Daha fazla analiz eklemek yerine iyileştirin
Bir kullanıcı deneyimi ilkesinden yararlandım: Çözüm daha fazla analiz değil, daha iyi analizdi.
İstemleri iyileştirmek için çok fazla zaman harcadım. Modele, çalışmalarını tekrar kontrol etmesi ve belirgin özelliklere odaklanması için net talimatlar ekledim. Bu, doğruluğu artırmak için daha etkili bir strateji olduğunu kanıtladı. Mevcut ve daha güvenilir akışın işleyiş şekli:
Yapay zeka dönüşü (API çağrısı): Model, hem sorusunu hem de dahili analizini aynı anda oluşturması için yönlendirilir ve tek bir JSON nesnesi döndürür.
- Soru: "Karakterin gözlük takıyor mu?"
- Analiz (veri):
[ {character_id: 'brad', has_feature: true}, {character_id: 'alex', has_feature: false}, {character_id: 'gina', has_feature: true}, ... ]Oyuncunun sırası: Oyuncunun gizli karakteri Alex (gözlüksüz) olduğundan "Hayır" yanıtını veriyor.
Tur sona erer: Uygulamanın JavaScript kodu devreye girer. Yapay zekaya başka bir şey sormasına gerek yoktur. 1. adımdaki analiz verilerini yineler.
- Oyuncu "Hayır" dedi.
- Kod,
has_featuredeğerinin doğru olduğu her karakteri arar. - Brad ve Gina'yı yere düşürür. Mantık deterministtir ve anlıktır.
Bu deneme süreci çok önemliydi ancak çok fazla deneme yanılma gerektirdi. İyileşip iyileşmeyeceğini bilmiyordum. Bazen durum daha da kötüleşiyordu. En tutarlı sonuçları nasıl elde edeceğinizi belirlemek kesin bir bilim değildir (henüz değilse de...).
Ancak yeni yapay zeka rakibimle birkaç tur oynadıktan sonra harika bir sorunla karşılaştım: beraberlik.
Kilitlenmeden çıkma
Yalnızca iki veya üç çok benzer karakter kaldığında model döngüye giriyordu. Örneğin, "Karakteriniz şapka takıyor mu?" gibi, hepsinin paylaştığı bir özellik hakkında soru sorulur.
Kodum bunu boşa harcanmış bir dönüş olarak doğru şekilde tanımlayacak ve yapay zeka, karakterlerin de paylaştığı, aynı derecede geniş kapsamlı başka bir özellik deneyecek. Örneğin, "Karakteriniz gözlük takıyor mu?"
İstemde yeni bir kural ekleyerek iyileştirme yaptım: Soru oluşturma girişimi başarısız olursa ve üç veya daha az karakter kalırsa strateji değişir.
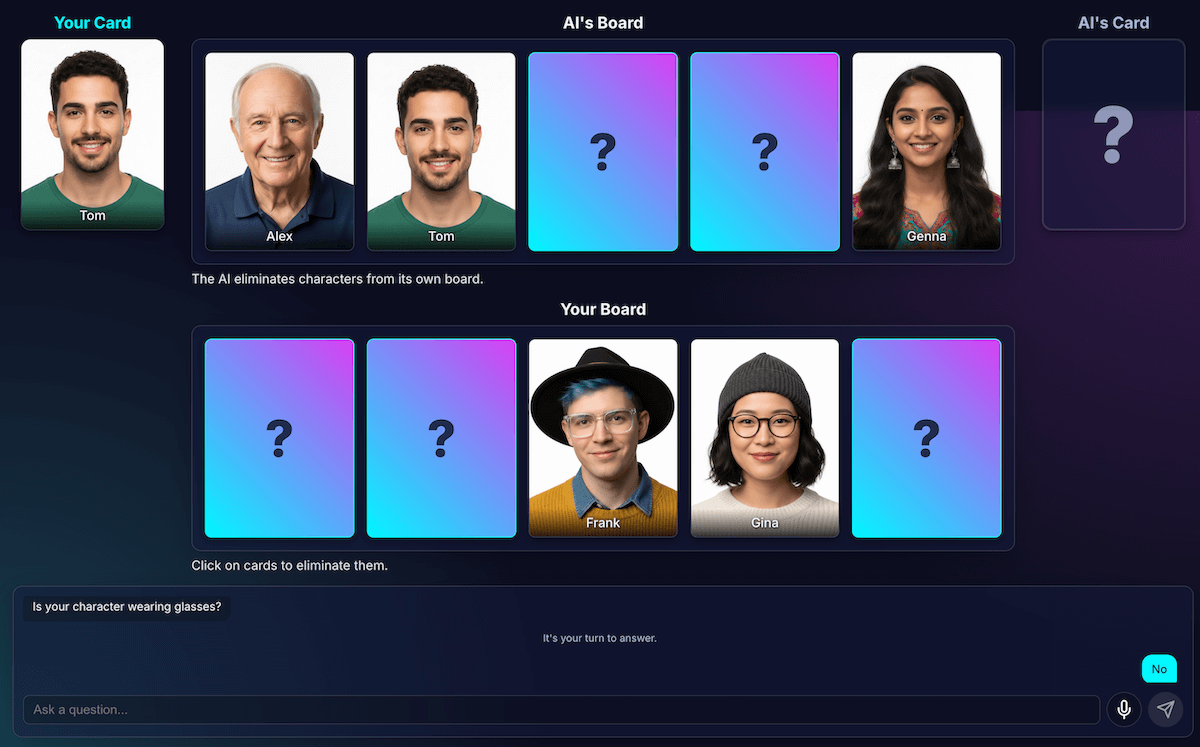
Yeni talimat açıkça belirtiyor: "Fark bulmak için geniş bir özellik yerine daha spesifik, benzersiz veya birleştirilmiş bir görsel özellik hakkında soru sormanız gerekir." Örneğin, karaktere şapka takıp takmadığını sormak yerine beyzbol şapkası takıp takmadığını sorması istenir.
Bu, modelin nihayet bir atılıma yol açabilecek küçük ayrıntıyı bulmak için görüntülere çok daha yakından bakmasını sağlar. Böylece, çoğu zaman oyunun sonlarındaki stratejisi biraz daha iyi çalışır.
Modele amnezi yaşatın
Dil modelinin en büyük gücü hafızasıdır. Ancak bu oyunda en büyük gücü zayıflığı haline geldi. İkinci bir oyuna başladığımda kafa karıştırıcı veya alakasız sorular soruyordu. Elbette akıllı yapay zeka rakibim, önceki oyundaki tüm sohbet geçmişini saklıyordu. Aynı anda iki (hatta daha fazla) oyunu anlamlandırmaya çalışıyordu.
Aynı yapay zeka oturumunu yeniden kullanmak yerine, her oyunun sonunda oturumu açıkça sonlandırıyorum. Bu sayede yapay zeka amnezi oluyor.
Tekrar Oyna'yı tıkladığınızda startNewGameSession() işlevi, tahtayı sıfırlar ve yepyeni bir yapay zeka oturumu oluşturur. Bu, yalnızca uygulamada değil, yapay zeka modelinin kendisinde de oturum durumunu yönetme konusunda ilginç bir dersti.
Ek özellikler: Özel oyunlar ve sesli giriş
Deneyimi daha ilgi çekici hale getirmek için iki ek özellik ekledim:
Özel karakterler:
getUserMedia()ile oyuncular, kameralarını kullanarak kendi 5 karakterlik setlerini oluşturabilir. Karakterleri kaydetmek için IndexedDB'yi kullandım. Bu, resim blob'ları gibi ikili verileri depolamak için mükemmel bir tarayıcı veritabanı. Özel bir set oluşturduğunuzda bu set tarayıcınıza kaydedilir ve ana menüde tekrar oynatma seçeneği görünür.Ses girişi: İstemci tarafı model çok formatlıdır. Metin, resim ve sesleri işleyebilir. Mikrofon girişini yakalamak için MediaRecorder API'yi kullanarak ortaya çıkan ses blob'unu "Aşağıdaki sesi transkribe et..." istemiyle modele aktarabilirim. Bu sayede eğlenceli bir şekilde oynayabilir (ve Flaman aksanımı nasıl yorumladığını görebilirsiniz). Bunu daha çok bu yeni web özelliğinin çok yönlülüğünü göstermek için oluşturdum ancak dürüst olmak gerekirse soruları tekrar tekrar yazmaktan sıkılmıştım.
Demo
Oyunu doğrudan buradan test edebilir veya yeni bir pencerede oynayabilir ve kaynak kodunu GitHub'da bulabilirsiniz.
Son düşünceler
"Yapay Zeka ile Kim Bu?" oyununu geliştirmek kesinlikle zorlu bir süreçti. Ancak dokümanları okuyarak ve yapay zekayı hata ayıklamak için yapay zekadan yardım alarak (evet... Bunu yaptım ve eğlenceli bir deneme oldu. Bu makalede, özel, hızlı ve internet gerektirmeyen bir deneyim oluşturmak için tarayıcıda model çalıştırmanın muazzam potansiyeli vurgulandı. Bu özellik hâlâ deneysel aşamada olduğundan rakip bazen mükemmel oynamayabilir. Piksel veya mantık açısından mükemmel değildir. Üretken yapay zeka ile sonuçlar modele bağlıdır.
Mükemmelliğe ulaşmak yerine sonucu iyileştirmeyi hedefleyeceğim.
Bu proje, istem mühendisliğinin sürekli zorluklarını da vurguladı. İstemler, bu sürecin büyük bir parçası haline geldi ve her zaman en eğlenceli kısım olmadı. Ancak öğrendiğim en önemli ders, uygulamayı algıyı çıkarımdan ayıracak, yapay zeka ve kodun yeteneklerini bölecek şekilde tasarlamaktı. Bu ayrım yapılmasına rağmen yapay zekanın, dövmeleri makyajla karıştırmak veya hangi karakterin sırrından bahsedildiğini unutmak gibi (insanlar için) bariz hatalar yapmaya devam ettiğini gördüm.
Her seferinde çözüm, istemleri daha da açık hale getirmek ve bir insan için açık olan ancak model için gerekli olan talimatlar eklemek oldu.
Bazen oyunun adil olmadığını hissettim. Zaman zaman, kod bu bilgiyi açıkça paylaşmamasına rağmen yapay zekanın gizli karakteri önceden "bildiğini" hissettim. Bu, insan ve makine arasındaki önemli bir farkı gösterir:
Yapay zekanın davranışı sadece doğru olmakla kalmamalı, aynı zamanda adil olmalıdır.
Bu nedenle istemleri, "Hangi karakteri seçtiğimi BİLMİYORSUN" ve "Hile yok" gibi net talimatlarla güncelledim. Yapay zeka temsilcileri oluştururken sınırlamaları tanımlamaya talimatlardan daha fazla zaman ayırmanız gerektiğini öğrendim.
Modelle etkileşim iyileştirilmeye devam edilebilir. Yerleşik bir modelle çalışarak büyük bir sunucu tarafı modelinin gücünü ve güvenilirliğini kaybedersiniz ancak gizlilik, hız ve çevrimdışı çalışma özelliği kazanırsınız. Bu tür bir oyun için bu ödünleşme, denemeye değerdi. İstemci tarafı yapay zekanın geleceği her geçen gün daha iyiye gidiyor, modeller de küçülüyor. Bir sonraki adımda neler yapabileceğimizi görmek için sabırsızlanıyorum.