

发布时间:2025 年 10 月 10 日

经典桌游《猜猜我是谁?》是演绎推理的经典之作。每位玩家都从一个面孔棋盘开始,通过一系列“是”或“否”问题缩小可能性范围,直到能够自信地找出对手的秘密角色。
在 Google I/O Connect 大会上看到内置 AI 的演示后,我开始思考:如果我能与浏览器中的 AI 对战“猜猜我是谁”游戏,会怎么样?借助客户端 AI,照片会在本地进行解读,因此包含亲朋好友的自定义“猜猜是谁?”游戏会始终在我的设备上保持私密性和安全性。
我的背景主要是界面和用户体验开发,我习惯于打造像素级完美体验。我希望通过自己的解读来做到这一点。
我的应用 AI Guess Who? 是使用 React 构建的,并使用 Prompt API 和浏览器内置模型来创建出人意料的强大对手。在这个过程中,我发现要获得“完美像素”的结果并非易事。不过,此应用展示了如何使用 AI 构建周到的游戏逻辑,以及提示工程在完善此逻辑并获得预期结果方面的重要性。
请继续阅读,了解内置的 AI 集成、我遇到的挑战以及最终确定的解决方案。您可以玩这款游戏,还可以在 GitHub 上找到源代码。
游戏基础:React 应用
在了解 AI 实现之前,我们先回顾一下应用的结构。我使用 TypeScript 构建了一个标准 React 应用,其中包含一个充当游戏指挥器的中央 App.tsx 文件。此文件包含:
- 游戏状态:一种枚举,用于跟踪游戏的当前阶段(例如
PLAYER_TURN_ASKING、AI_TURN、GAME_OVER)。这是最重要的状态,因为它决定了界面显示的内容以及玩家可执行的操作。 - 角色列表:有多个列表用于指定有效角色、每位玩家的秘密角色以及哪些角色已从棋盘上淘汰。
- 游戏聊天:问题、答案和系统消息的运行日志。
该界面分为以下逻辑组件:

随着游戏功能的增加,其复杂性也随之提高。最初,整个游戏的逻辑都在一个大型自定义 React hook useGameLogic 中进行管理,但很快就变得过于庞大,难以浏览和调试。为了提高可维护性,我将此钩子重构为多个钩子,每个钩子都承担单一责任。例如:
useGameState管理核心状态usePlayerActions表示轮到玩家useAIActions适用于 AI 的逻辑
现在,主要 useGameLogic 钩子充当干净的编排器,将这些较小的钩子放在一起。此架构变更并未改变游戏的功能,但使代码库变得更加简洁。
使用 Prompt API 实现游戏逻辑
此项目的核心是使用 Prompt API。
我已将 AI 游戏逻辑添加到 builtInAIService.ts。其主要职责包括:
- 允许限制性二元回答。
- 教模型游戏策略。
- 教模型分析。
- 让模型失忆。
允许限制性二元答案
玩家如何与 AI 互动?当玩家问“你的角色戴帽子吗?”时,AI 需要“查看”其秘密角色的图片,并给出明确的回答。
我最初的尝试一团糟。回答是对话式的:“不,我想到的人物 Isabella 似乎没有戴帽子”,而不是提供二元“是”或“否”回答。最初,我通过非常严格的提示解决了这个问题,基本上是命令模型仅回答“是”或“否”。
虽然这种方法可行,但我了解到一种使用结构化输出的更好方法。通过向模型提供 JSON 架构,我可以保证获得 true 或 false 的回答。
const schema = { type: "boolean" };
const result = session.prompt(prompt, { responseConstraint: schema });
这样一来,我便可简化提示,并让代码可靠地处理响应:
JSON.parse(result) ? "Yes" : "No"
教模型游戏策略
让模型回答问题比让模型发起并提出问题要简单得多。优秀的《是谁?》玩家不会随意提问。他们会提出一次性排除最多字符的问题。理想的问题会通过二元问题将剩余的可能字符数减少一半。
如何教模型这种策略?再次强调,提示工程generateAIQuestion() 的提示实际上是“猜猜我是谁?”游戏理论的简明课程。
最初,我让模型“提出一个好问题”。结果难以预测。为了改进结果,我添加了负约束条件。提示现在包含类似于以下内容的说明:
- “CRITICAL:仅询问现有功能”
- “严重:坚持原创。请勿重复问题”。
这些限制缩小了模型的关注范围,防止其提出无关的问题,从而使其成为一个更令人愉快的对手。您可以在 GitHub 上查看完整的提示文件。
教模型分析
这是迄今为止最困难、最重要的挑战。当模型提出“你的角色戴帽子吗?”之类的问题时,如果玩家回答“否”,模型如何知道棋盘上哪些角色被淘汰了?
模型应消灭所有戴帽子的人。我早期的尝试遇到了很多逻辑错误,有时模型会错误地消除字符,有时则不会消除任何字符。另外,“帽子”是什么?“无边便帽”是否算作“帽子”?说实话,这也是人类辩论中可能会出现的情况。当然,也会出现一般性错误。从 AI 的角度来看,头发可能看起来像帽子。
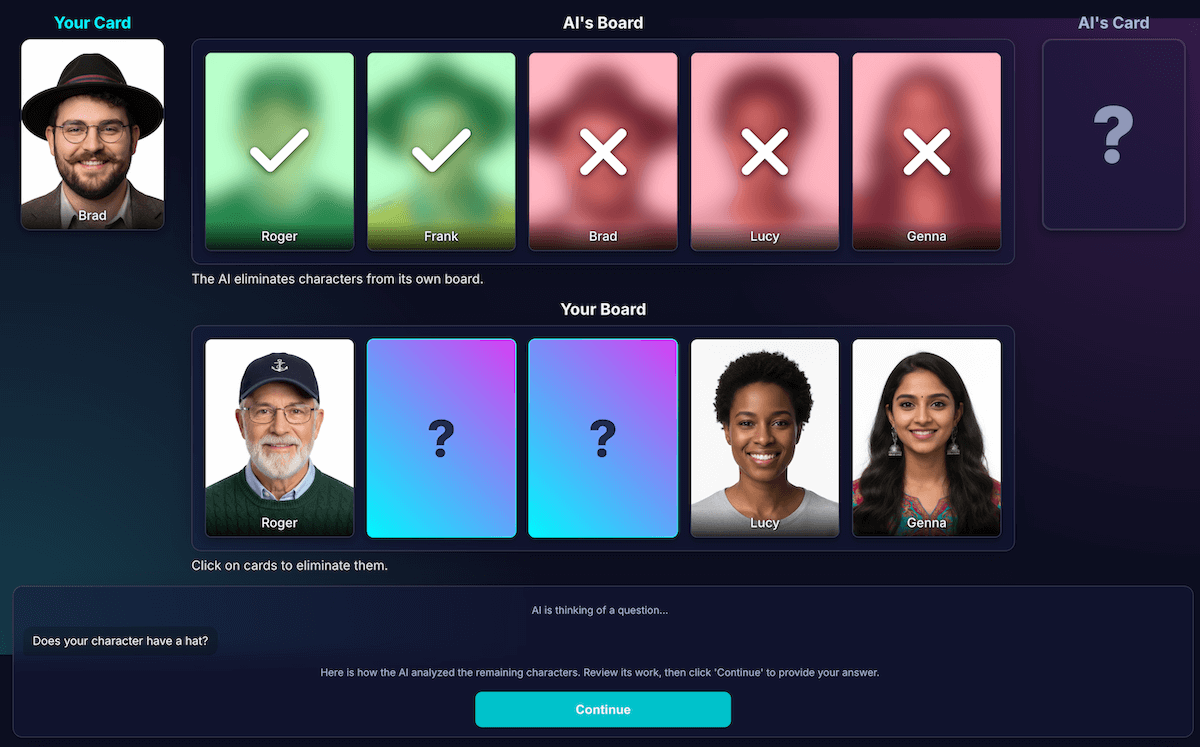
我重新设计了架构,将感知与代码推导分离开来:
AI 负责视觉分析。模型擅长进行视觉分析。 我指示模型以严格的 JSON 架构返回其问题和详细分析。模型会分析棋盘上的每个字符,并回答“此字符是否具有此特征?”这一问题。模型会返回一个结构化 JSON 对象:
{ "character_id": "...", "has_feature": true }再次强调,结构化数据是取得成功结果的关键。
游戏代码使用分析结果做出最终决策。应用代码会检查玩家的回答(“是”或“否),并遍历 AI 的分析结果。如果玩家回答“否”,代码会知道要消除
has_feature为true的每个字符。
我发现,这种分工是构建可靠的 AI 应用的关键。 使用 AI 的分析功能,并将二元决策留给应用代码。
为了检查模型的感知能力,我构建了此分析的可视化图表。这样一来,就更容易确认模型的感知是否正确。
提示工程
不过,即使进行了这种分离,我还是注意到模型的感知可能存在缺陷。它可能会错误判断角色是否戴眼镜,从而导致令人沮丧的错误淘汰。为了解决这个问题,我尝试了一个两步流程:AI 会先提出问题。在收到玩家的回答后,它会以该回答为上下文执行第二次全新分析。这种理论认为,第二次检查可能会发现第一次检查中的错误。
该流程的运作方式如下:
- AI 回合(API 调用 1):AI 询问“你的角色有胡须吗?”
- 玩家的回合:玩家查看自己的秘密角色(该角色是剃光胡须的),然后回答“不是”。
- AI 回合(API 调用 2):AI 会有效地要求自己再次查看所有剩余的角色,并根据玩家的回答确定要排除哪些角色。
在第 2 步中,即使用户希望模型消除有浅胡茬的角色,模型仍可能错误地将有浅胡茬的角色识别为“没有胡须”,从而未能消除该角色。核心感知错误未修复,而额外的步骤只是延迟了结果。与人类对手对弈时,我们可以就此达成协议或进行澄清;但在当前与 AI 对手对弈的设置中,情况并非如此。
此过程会因第二次 API 调用而增加延迟时间,但不会显著提高准确性。如果模型第一次预测错误,那么第二次预测也往往会出错。我将提示恢复为仅检查一次。
改进,而不是添加更多分析
我遵循了一项用户体验原则:解决方案不是进行更多分析,而是进行更优质的分析。
我投入了大量精力来优化提示,为模型添加了明确的指令,要求其仔细检查自己的工作并专注于独特的功能,事实证明,这是一种更有效的提高准确性的策略。以下是当前更可靠的流程的工作方式:
AI 回合(API 调用):系统会提示模型同时生成问题和内部分析,并返回单个 JSON 对象。
- 问题:“你的角色戴眼镜吗?”
- 分析(数据):
[ {character_id: 'brad', has_feature: true}, {character_id: 'alex', has_feature: false}, {character_id: 'gina', has_feature: true}, ... ]玩家的回合:玩家的秘密角色是 Alex(不戴眼镜),因此他们回答“否”。
回合结束:应用的 JavaScript 代码接管控制权。无需再向 AI 提出任何其他问题。它会遍历第 1 步中的分析数据。
- 该玩家回答“否”。
- 该代码会查找
has_feature为 true 的每个字符。 - 它会翻转显示 Brad 和 Gina。逻辑是确定性的,并且是即时的。
这种实验至关重要,但需要进行大量试错。我不知道情况是否会好转。有时,情况甚至更糟。如何获得最一致的结果并不是一门精确的科学(至少目前还不是,以后是否会成为一门精确的科学也未可知)。
但在与新的 AI 对手对弈几轮后,出现了一个非常棒的新问题:僵局。
摆脱死锁
当只剩下两个或三个非常相似的字符时,模型会陷入循环。它会询问一个他们共有的特征,例如“你的角色戴帽子吗?”
我的代码会正确地将此问题识别为浪费的轮次,然后 AI 会尝试另一个同样广泛的特征,即所有角色都共有的特征,例如“你的角色戴眼镜吗?”
我通过一项新规则增强了提示:如果问题生成尝试失败且剩余字符数不超过 3 个,则更改策略。
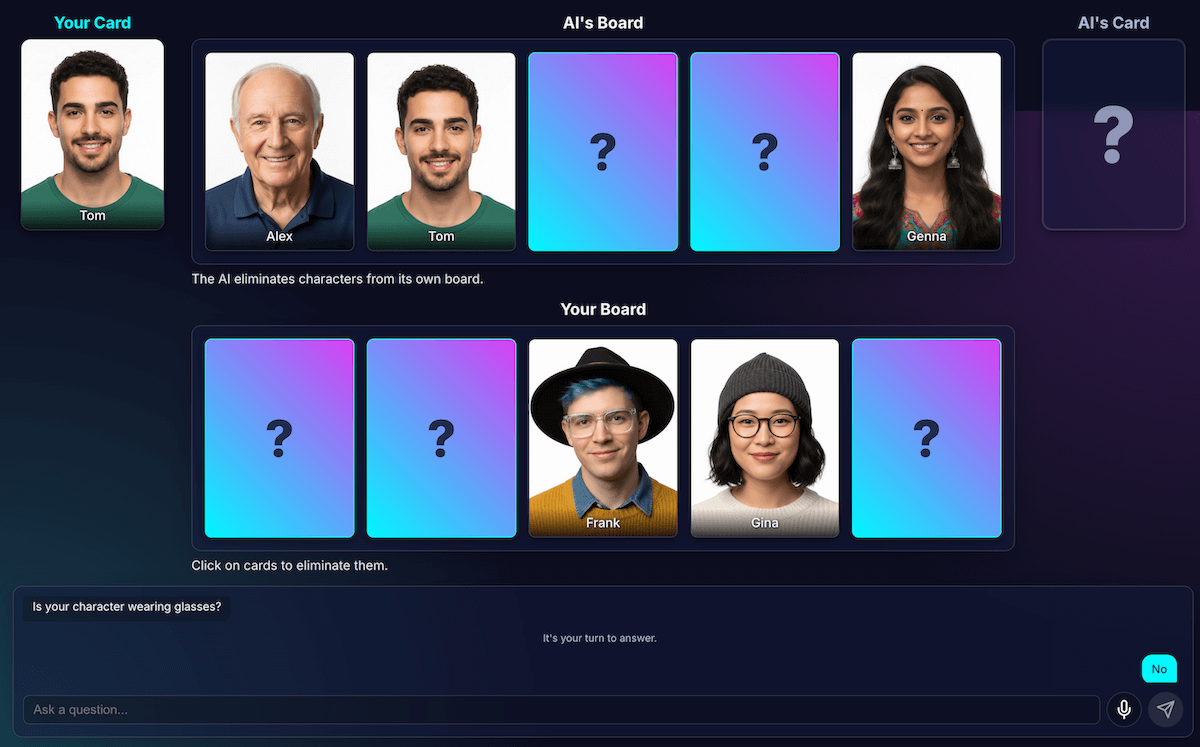
新指令明确指出:“您必须询问更具体、独特或组合的视觉特征,而不是宽泛的特征,才能找到差异。” 例如,系统不会询问角色是否戴帽子,而是提示询问角色是否戴棒球帽。
这会迫使模型更仔细地查看图片,以找到最终能带来突破性进展的那个小细节,从而使其后期策略在大多数情况下都能发挥更好的效果。
让模型患上失忆症
语言模型最强大的功能是记忆能力。但在这款游戏中,它最大的优势却变成了弱点。当我开始第二局游戏时,它会问一些令人困惑或无关的问题。当然,我的智能 AI 对手保留了之前游戏中的整个聊天记录。它试图同时理解两场(甚至更多场)比赛。
现在,我不会重复使用同一 AI 会话,而是在每场游戏结束时明确销毁它,这相当于让 AI 患上失忆症。
当您点击再玩一次时,startNewGameSession() 函数会重置棋盘并创建一个全新的 AI 会话。这堂课很有趣,它不仅介绍了如何在应用中管理会话状态,还介绍了如何在 AI 模型本身中管理会话状态。
锦上添花:自定义游戏和语音输入
为了让体验更具吸引力,我添加了两项额外功能:
自定义角色:借助
getUserMedia(),玩家可以使用摄像头创建自己的 5 个角色。我使用 IndexedDB 保存了这些字符,这是一个非常适合存储图片 blob 等二进制数据的浏览器数据库。创建自定义组后,系统会将其保存到您的浏览器中,并且主菜单中会显示重放选项。语音输入:客户端模型是多模态模型。 它不仅可以处理文本和图片,还可以处理音频。使用 MediaRecorder API 捕获麦克风输入,我可以向模型提供生成的音频 blob,并附带提示:“转写以下音频…”这为游戏增添了乐趣(也让我能有趣地了解它如何解读我的弗拉芒语口音)。我创建这个应用主要是为了展示这项新 Web 功能的用途广泛,但说实话,我厌倦了一遍又一遍地输入问题。
演示
您可以直接在此处测试游戏,也可以在新窗口中玩游戏,并在 GitHub 上找到源代码。
最后总结
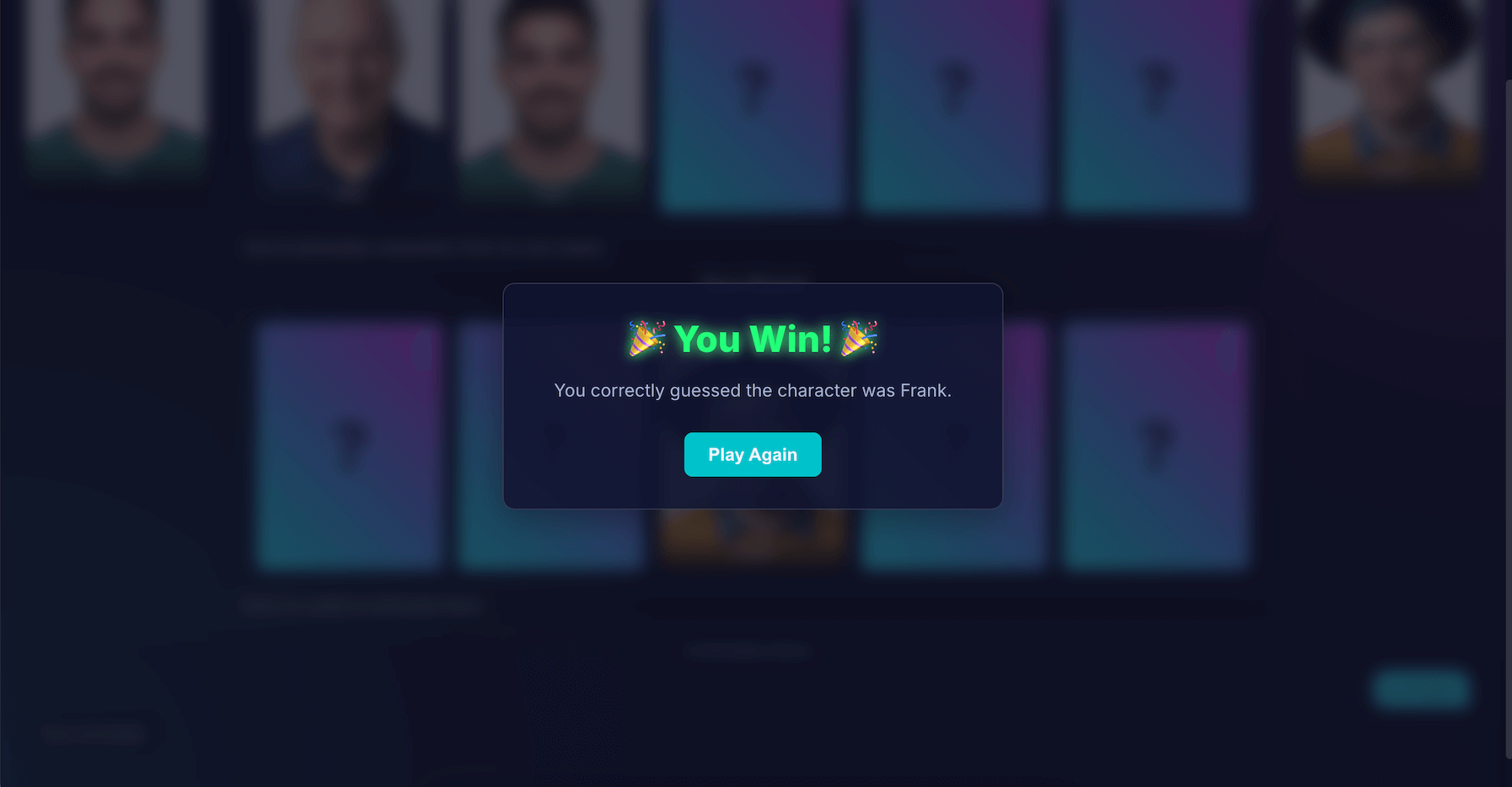
构建“AI 猜猜是谁?”绝对是一项挑战。不过,在阅读文档和借助 AI 调试 AI 的帮助下(是的,我尝试了一下),结果发现这真是一次有趣的实验。它突显了在浏览器中运行模型以创建私密、快速且无需联网的体验的巨大潜力。这仍是一项实验,有时对手的棋艺并不完美。 它并非像素级完美或逻辑级完美。借助生成式 AI,结果取决于模型。
我不会追求完美,而是会努力改善结果。
该项目还突显了提示工程面临的持续挑战。提示确实成为了一个非常重要的部分,但并不总是最有趣的部分。但我学到的最关键的一课是,设计应用时要将感知与推理分开,划分 AI 和代码的功能。即使进行了这种分离,我还是发现 AI 可能会犯(对人类而言)明显的错误,例如将纹身误认为化妆,或者忘记正在讨论的是谁的秘密角色。
每次,解决方案都是让提示更加明确,添加对人类来说显而易见但对模型来说至关重要的指令。
有时,游戏感觉不公平。有时,我感觉 AI 提前“知道”了秘密字符,即使代码从未明确分享过该信息。这展示了人与机器之间的一个关键区别:
AI 的行为不仅需要正确,还需要感觉公平。
因此,我更新了提示,添加了直截了当的指令,例如“你不知道我选择了哪个角色”和“不许作弊”。我了解到,在构建 AI 智能体时,您应该花时间定义限制,甚至可能比指令花费的时间还要多。
与模型的互动可以继续改进。使用内置模型会损失一些大型服务器端模型的功能和可靠性,但可以提高隐私保护能力、速度和离线功能。对于这类游戏,这种权衡取舍非常值得一试。客户端 AI 的未来正在日益完善,模型也越来越小,我迫不及待想看看我们接下来能打造出什么。