

發布日期:2025 年 10 月 10 日

經典桌遊「是誰呢?」是演繹推理的經典之作。每位玩家一開始都會拿到一張臉孔圖板,然後透過一連串的是非題縮小可能性,直到能自信地找出對手的祕密角色為止。
在 Google I/O Connect 大會上觀看內建 AI 的示範後,我開始思考:如果能與瀏覽器中的 AI 玩「是誰?」遊戲,會怎麼樣呢?有了用戶端 AI,相片會在本地解讀,因此親友的自訂「猜猜我是誰?」遊戲內容會保留在我的裝置上,確保隱私和安全。
我的背景主要是使用者介面和使用者體驗開發,習慣打造完美無瑕的體驗。我希望透過自己的詮釋,達到這個目標。
我的應用程式「AI Guess Who?」是使用 React 建構,並透過 Prompt API 和瀏覽器內建模型,打造出能力出乎意料的對手。在這個過程中,我發現要獲得「完美像素」的結果並不容易。不過,這個應用程式示範了如何運用 AI 建構周全的遊戲邏輯,以及提示工程在修正這項邏輯並獲得預期結果方面的重要性。
請繼續閱讀,瞭解內建的 AI 整合功能、我遇到的挑戰,以及最終採用的解決方案。您可以玩這個遊戲,並在 GitHub 上找到原始碼。
遊戲基礎:React 應用程式
在查看 AI 實作方式之前,我們先來瞭解應用程式的結構。我使用 TypeScript 建構標準 React 應用程式,並以中央 App.tsx 檔案做為遊戲的指揮。這個檔案包含:
- 遊戲狀態:追蹤遊戲目前階段的列舉 (例如
PLAYER_TURN_ASKING、AI_TURN、GAME_OVER)。這是最重要的狀態片段,因為它會決定介面顯示的內容,以及玩家可執行的動作。 - 角色清單:有多個清單會指定有效角色、每位玩家的秘密角色,以及已從棋盤上淘汰的角色。
- 遊戲對話:問題、答案和系統訊息的記錄。
介面會細分為下列邏輯元件:

隨著遊戲功能越來越多,複雜度也隨之增加。一開始,整個遊戲的邏輯都是在單一大型自訂 React Hook useGameLogic 中管理,但很快就變得過於龐大,難以瀏覽和偵錯。為提升可維護性,我將這個 Hook 重構為多個 Hook,每個 Hook 各自負責單一工作。例如:
useGameState管理核心狀態usePlayerActions代表輪到玩家useAIActions適用於 AI 的邏輯
主要 useGameLogic 鉤子現在會做為乾淨的組合器,將這些較小的鉤子放在一起。這項架構變更並未改變遊戲功能,但大幅簡化了程式碼集。
使用 Prompt API 建立遊戲邏輯
這項專案的核心是使用 Prompt API。
我已將 AI 遊戲邏輯新增至 builtInAIService.ts。主要職責包括:
- 允許限制性二元答案。
- 教導模型遊戲策略。
- 教導模型分析。
- 讓模型忘記先前的對話。
允許限制性二元答案
玩家如何與 AI 互動?如果玩家問「你的角色戴帽子嗎?」,AI 必須「查看」秘密角色的圖片,並給出明確的答案。
我一開始嘗試的結果很糟糕,模型的回覆是「我認為 Isabella 這個角色沒有戴帽子」,而不是提供二元答案「是」或「否」。一開始,我使用非常嚴格的提示解決這個問題,基本上是要求模型只能回覆「是」或「否」。
雖然這樣做可行,但我發現使用結構化輸出是更好的做法。只要向模型提供 JSON 結構定義,就能確保模型回覆「是」或「否」。
const schema = { type: "boolean" };
const result = session.prompt(prompt, { responseConstraint: schema });
這讓我得以簡化提示,並讓程式碼可靠地處理回應:
JSON.parse(result) ? "Yes" : "No"
教導模型遊戲策略
相較於讓模型發起並提出問題,要求模型回答問題簡單許多。猜猜我是誰?的優秀玩家不會隨機提問,他們會問問題,一次刪除最多字元。理想的問題會使用二進位問題,將可能的剩餘字元減少一半。
如何教導模型這項策略?再次強調,提示工程是關鍵。generateAIQuestion()的提示其實是「是誰呢?」賽局理論的簡短課程。
一開始,我要求模型「提出好問題」,結果難以預測。為改善結果,我新增了負面限制。提示現在包含類似下列的指示:
- 「CRITICAL: Ask about existing features ONLY」(重要:只能詢問現有功能)
- 「重要:請發揮原創精神。請勿重複提問」。
這些限制會縮小模型的焦點,避免模型提出不相關的問題,讓模型成為更令人愉快的對手。您可以在 GitHub 上查看完整提示檔案。
教導模型分析
這項挑戰是難度最高,也是最重要的。如果模型問「你的角色戴帽子嗎?」,而玩家回答「否」,模型如何得知棋盤上哪些角色已淘汰?
模型應會移除所有戴帽子的使用者。我一開始嘗試時,經常發生邏輯錯誤,有時模型會刪除錯誤的字元,有時則不會刪除任何字元。此外,「帽子」是什麼?「無邊帽」算不算「帽子」?說實話,這也是人類辯論中可能發生的情況。當然,一般錯誤也難免發生。從 AI 的角度來看,頭髮可能看起來像帽子。
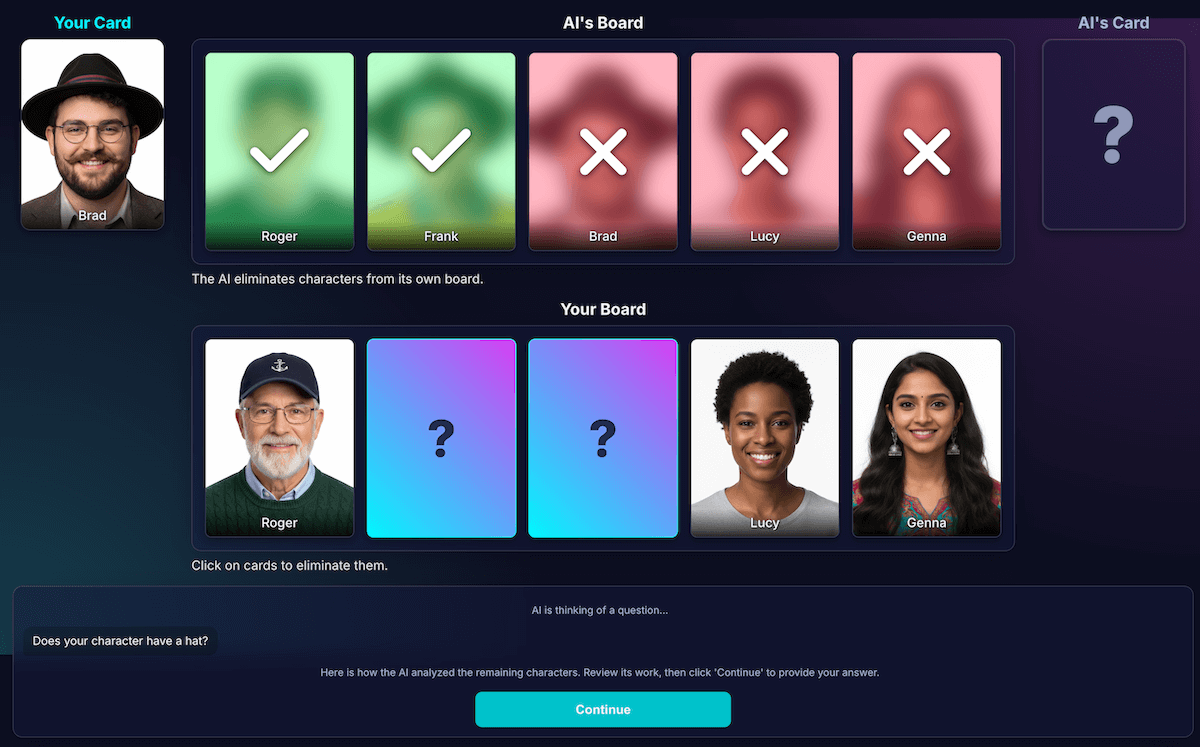
我重新設計了架構,將感知與程式碼推論分開:
AI 負責視覺分析。模型擅長進行視覺分析。 我指示模型以嚴格的 JSON 結構定義傳回問題和詳細分析。模型會分析棋盤上的每個角色,並回答「這個角色是否具備這項特徵?」這個問題。模型會傳回結構化 JSON 物件:
{ "character_id": "...", "has_feature": true }再次強調,結構化資料是獲得成功結果的關鍵。
遊戲程式碼會根據分析結果做出最終決定。應用程式程式碼會檢查玩家的答案 (「是」或「否」),並逐一查看 AI 的分析結果。如果玩家回答「否」,程式碼就會知道要刪除每個
has_feature字元。true
我發現這種分工方式是建構可靠 AI 應用程式的關鍵。 運用 AI 的分析功能,並將二元決策留給應用程式碼。
為檢查模型的感知能力,我建構了這項分析的視覺化呈現方式。這樣一來,就能更輕鬆確認模型是否正確解讀。
提示工程
不過,即使有這種區隔,我還是發現模型的感知能力可能存在缺陷。系統可能會誤判角色是否戴眼鏡,導致淘汰結果錯誤,令人沮喪。為解決這個問題,我嘗試了兩步驟程序:AI 會提出問題,收到玩家的答案後,系統會以該答案做為脈絡,再次進行分析。理論上,第二次檢查可能會發現第一次檢查的錯誤。
該流程的運作方式如下:
- AI 回合 (API 呼叫 1):AI 問:「你的角色有鬍子嗎?」
- 輪到玩家:玩家查看自己的秘密角色 (沒有鬍子),然後回答「否」。
- AI 回合 (API 呼叫 2):AI 會再次查看所有剩餘字元,並根據玩家的答案決定要刪除哪些字元。
在步驟二中,模型可能仍會將留有淺色鬍渣的角色誤認為「沒有鬍鬚」,因此無法消除鬍鬚,即使使用者希望模型這麼做也一樣。核心感知錯誤並未修正,額外步驟只是延遲了結果。與人類對手對弈時,我們可以指定這方面的協議或說明;但在目前的 AI 對手設定中,情況並非如此。
這項程序會增加第二次 API 呼叫的延遲時間,但準確度不會大幅提升。如果模型第一次判斷錯誤,第二次也經常會出錯。我已將提示還原為只審查一次。
改善分析結果,而非新增更多分析
我依據使用者體驗原則判斷,解決方案並非更多分析,而是更優質的分析。
我投入大量心力調整提示,為模型新增明確的指令,要求模型仔細檢查工作並著重於獨特功能,結果證明這是提升準確度的有效策略。目前更可靠的流程運作方式如下:
AI 回合 (API 呼叫):系統會提示模型同時生成問題和內部分析,並傳回單一 JSON 物件。
- 問題:「你的角色戴眼鏡嗎?」
- 分析 (資料):
[ {character_id: 'brad', has_feature: true}, {character_id: 'alex', has_feature: false}, {character_id: 'gina', has_feature: true}, ... ]輪到玩家:玩家的秘密角色是 Alex (沒有戴眼鏡),因此他們回答「否」。
回合結束:應用程式的 JavaScript 程式碼會接管。不需要再詢問 AI 其他問題。並反覆處理步驟 1 中的分析資料。
- 玩家回答「否」。
- 程式碼會尋找
has_feature為 true 的每個字元。 - 並將 Brad 和 Gina 翻倒。這項邏輯是確定性的,而且會立即執行。
這項實驗至關重要,但需要經過許多次試驗。我不知道情況是否會好轉,有時情況甚至會更糟。如何獲得最一致的結果,目前還沒有確切的科學方法 (或許以後會有)。
但與新的 AI 對手對弈幾輪後,出現了一個絕妙的新問題: 僵局。
避免死結
如果只剩下兩三個非常相似的字元,模型就會陷入迴圈。並詢問他們共有的特徵,例如「你的角色戴帽子嗎?」
我的程式碼會正確將此視為浪費的回合,而 AI 會嘗試另一個同樣廣泛的特徵,也就是角色也共有的特徵,例如「你的角色戴眼鏡嗎?」
我使用新規則強化提示:如果問題生成嘗試失敗且剩餘字元數為三個或更少,策略就會變更。
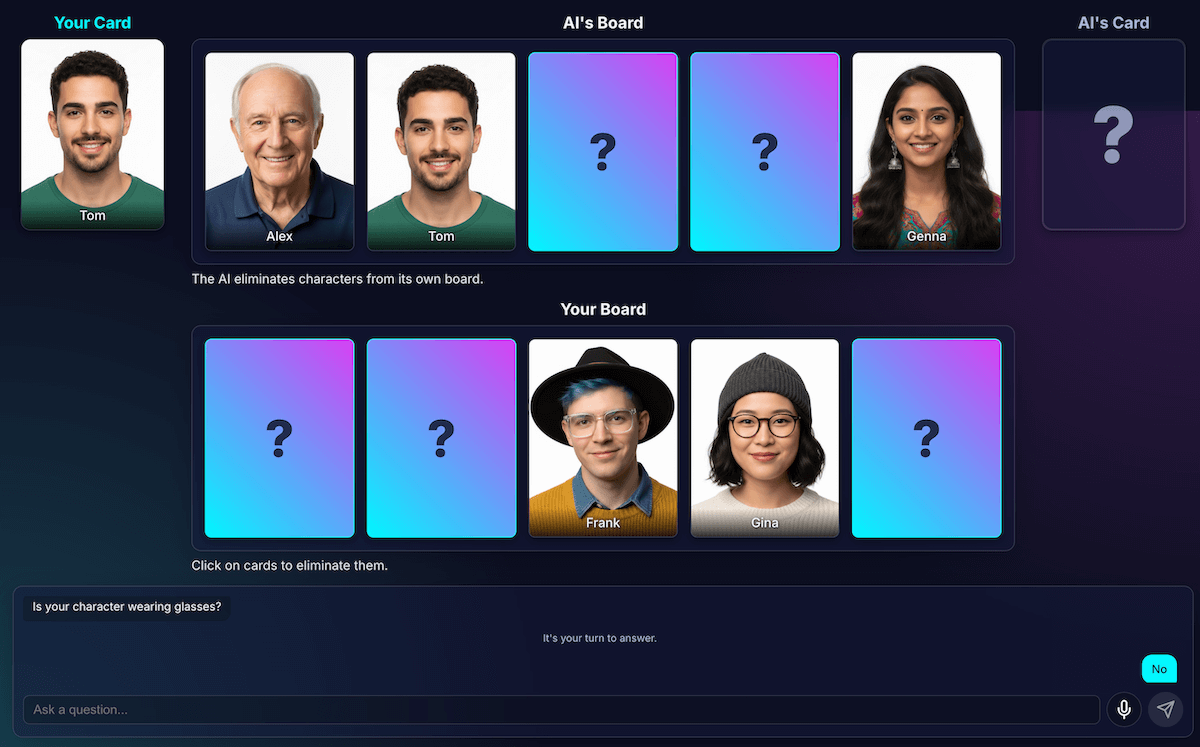
新指令明確指出:「請詢問更具體、獨特或組合的視覺特徵,找出差異,而非廣泛的特徵。」舉例來說,系統會提示你詢問角色是否戴著棒球帽,而不是詢問是否戴著帽子。
這會迫使模型更仔細地查看圖片,找出最終能帶來突破性進展的微小細節,讓模型在遊戲後期的策略運作得更好 (大多數時候)。
讓模型失憶
語言模型最強大的功能就是記憶。但在這款遊戲中,這項優勢卻成了弱點。開始第二場遊戲時,系統會詢問令人困惑或不相關的問題。當然,智慧 AI 對手會保留前一場遊戲的完整對話記錄。它會試圖同時理解兩場 (甚至更多) 賽事。
我現在不會重複使用同一個 AI 工作階段,而是在每場遊戲結束時明確終止工作階段,讓 AI 忘記先前的遊戲內容。
按一下「Play Again」(再玩一次) 時,startNewGameSession() 函式會重設棋盤,並建立全新的 AI 工作階段。這堂課很有趣,不僅介紹了如何管理應用程式中的工作階段狀態,也說明瞭如何管理 AI 模型本身的工作階段狀態。
進階功能:自訂遊戲和語音輸入
為了讓體驗更吸引人,我新增了兩項額外功能:
自訂角色:玩家可使用
getUserMedia()建立自己的 5 個角色。我使用 IndexedDB 儲存字元,這個瀏覽器資料庫非常適合儲存圖片 Blob 等二進位資料。建立自訂組合後,系統會將其儲存至瀏覽器,主選單中也會顯示重播選項。語音輸入:用戶端模型支援多模態。 可處理文字、圖片和音訊。使用 MediaRecorder API 擷取麥克風輸入內容後,我就可以將產生的音訊 Blob 透過提示「轉錄下列音訊...」提供給模型。這項功能不僅增添了遊戲樂趣,還能以有趣的方式瞭解 Google 如何解讀我的佛蘭德語口音。我建立這個應用程式主要是為了展示這項新網路功能的多元性,但說實話,我已經厭倦了一遍又一遍地輸入問題。
示範
您可以在這裡直接測試遊戲,或在新視窗中玩遊戲,並在 GitHub 上找到原始碼。
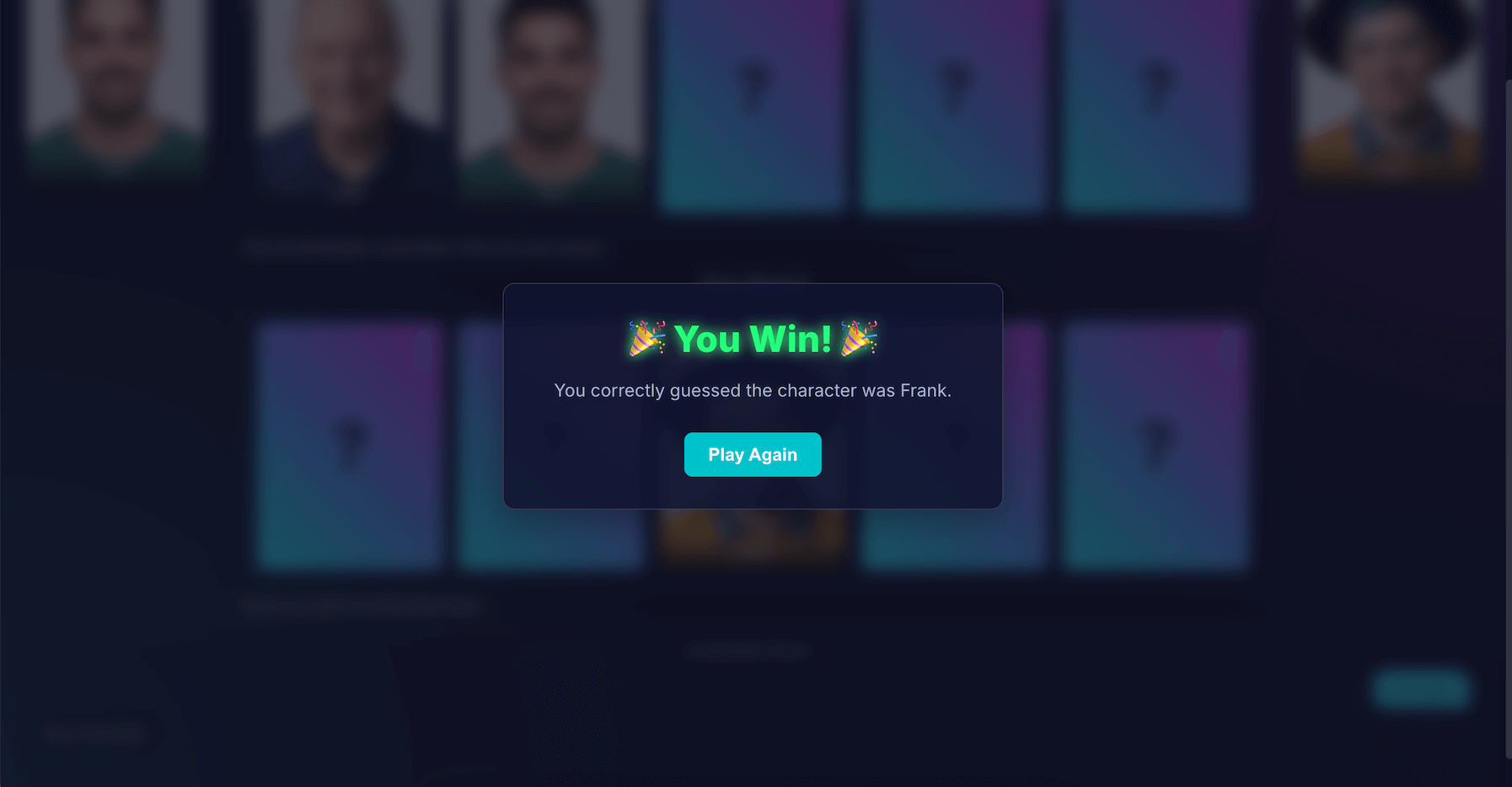
結論
建構「AI 猜猜我是誰」絕對是一大挑戰。但只要參閱說明文件,並運用 AI 偵錯 AI (沒錯,我這麼做了),結果發現這是一項有趣的實驗。這項技術凸顯了在瀏覽器中執行模型所帶來的巨大潛力,可打造私密、快速且不需網路連線的體驗。這項功能仍在實驗階段,有時對手不會完美出牌。這項功能並非完美無缺,生成式 AI 的結果取決於模型。
我不會追求完美,而是著重於提升結果。
這項專案也凸顯了提示工程持續面臨的挑戰。提示成為了非常重要的一環,但並非總是充滿樂趣。但我學到的最重要一課,是設計應用程式架構,將感知與推論分開,並劃分 AI 和程式碼的功能。即使有這種區隔,我發現 AI 仍可能犯下 (對人類而言) 顯而易見的錯誤,例如將紋身誤認為化妝,或是忘記討論的是誰的秘密角色。
每次的解決方法都是讓提示更加明確,加入對人類來說顯而易見,但對模型來說至關重要的指令。
有時遊戲會讓人覺得不公平。有時我覺得 AI「知道」秘密字元,即使程式碼從未明確分享該資訊。這顯示了人與機器之間的重要差異:
AI 的行為不僅要正確,還必須感覺公平。
因此我更新了提示,加入直白的指示,例如「你不知道我選了哪個角色」和「不得作弊」。我發現建構 AI 代理時,定義限制所花的時間可能比指令還多。
與模型的互動方式可能會持續改善。使用內建模型會失去大型伺服器端模型的部分功能和可靠性,但可確保隱私、提升速度,並支援離線作業。對於這類遊戲,這種取捨非常值得實驗。用戶端 AI 的未來發展日新月異,模型也越來越小,我迫不及待想看看我們接下來能打造出什麼。