

The raw data of the Chrome UX Report (CrUX) is available on BigQuery, a database on Google Cloud. Using BigQuery requires a GCP project and basic knowledge of SQL.
In this guide, learn how to use BigQuery to write queries against the CrUX dataset to extract insightful results about the state of user experiences on the web:
- Understand how the data is organized
- Write a basic query to evaluate an origin's performance
- Write an advanced query to track performance over time
Data organization
Start by looking at a basic query:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
To run the query, enter it into the query editor and press the "Run query" button:
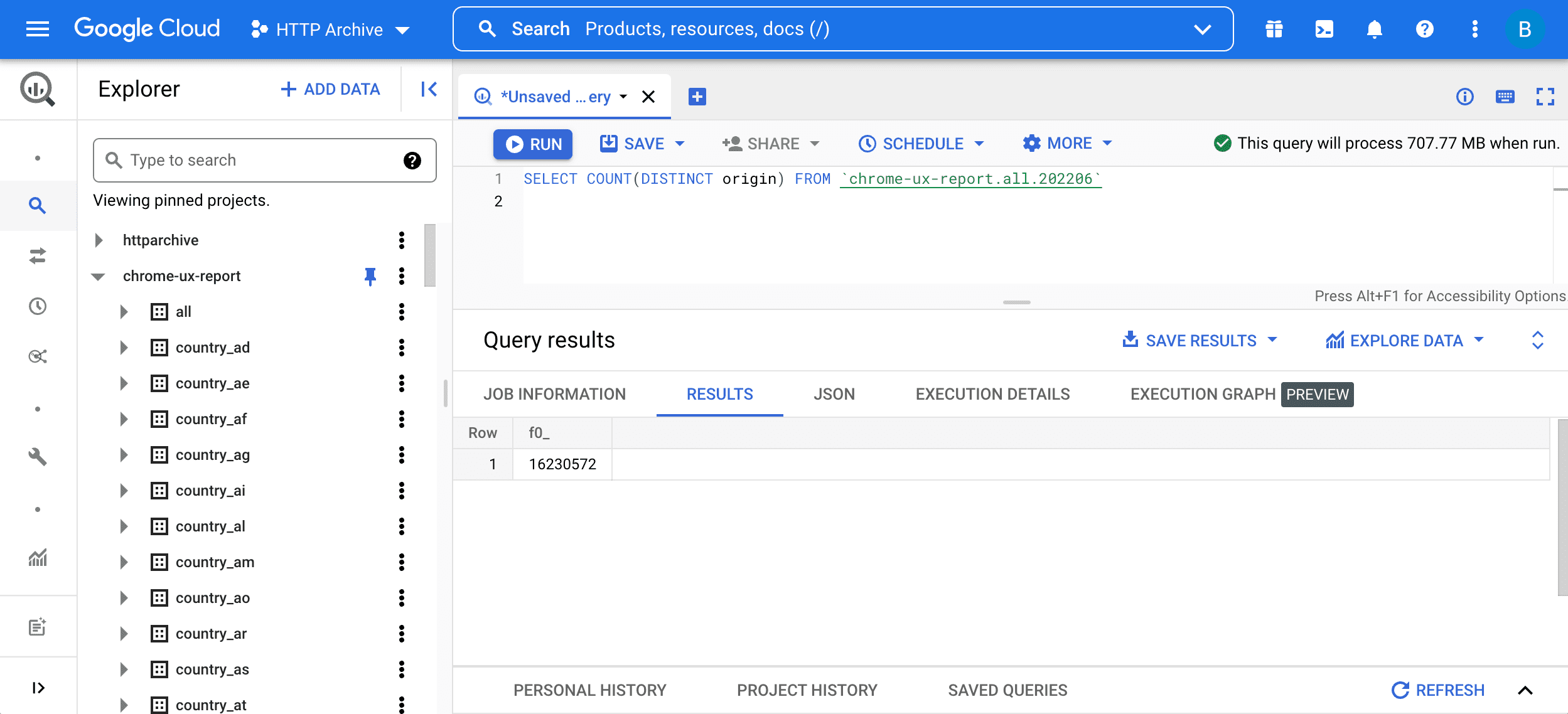
There are two parts to this query:
SELECT COUNT(DISTINCT origin)means querying for the number of origins in the table. Roughly speaking, two URLs are part of the same origin if they have the same scheme, host, and port.FROM chrome-ux-report.all.202206specifies the address of the source table, which has three parts:- The Cloud project name
chrome-ux-reportwithin which all CrUX data is organized - The dataset
all, representing data across all countries - The table
202206, the year and month of the data in YYYYMM format
- The Cloud project name
There are also datasets for every country. For example, chrome-ux-report.country_ca.202206 represents only the user experience data originating from Canada.
Within each dataset there are tables for every month since 201710. New tables for the previous calendar month are published regularly.
The structure of the data tables (also known as the schema) contains:
- The origin, for example
origin = 'https://www.example.com', which represents the aggregate user experience distribution for all pages on that website - The connection speed at the time of page load, for example,
effective_connection_type.name = '4G'(removed from February 2025) - The device type, for example
form_factor.name = 'desktop' - The UX metrics themselves
The data for each metric is organized as an array of objects. In JSON notation, first_contentful_paint.histogram.bin would look similar to this:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
Each bin contains a start and an end time in milliseconds and a density representing the percent of user experiences within that time range. In other words, 12.34% of FCP experiences for this hypothetical origin, connection speed, and device type are less than 100ms. The sum of all bin densities is 100%.
Browse the structure of the tables in BigQuery.
Evaluate performance
We can use our knowledge of the table schema to write a query that extracts this performance data.
SELECT
fcp
FROM
`chrome-ux-report.all.202502`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
form_factor.name = 'phone' AND
fcp.start = 0
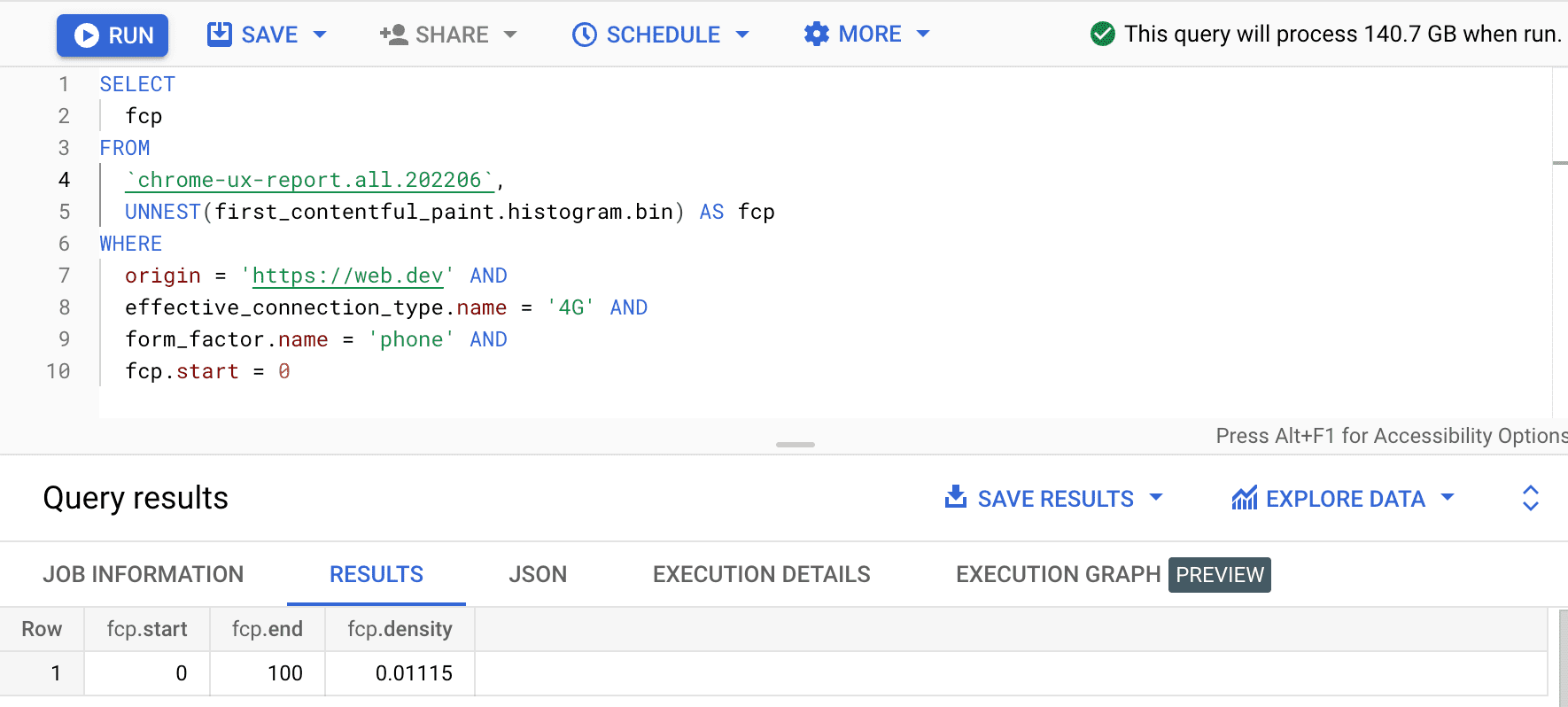
The result is 0.01115, meaning that 1.115% of user experiences on this origin are between 0 and 100ms on 4G and on a phone. If we want to generalize our query to any connection and any device type, we can omit them from the WHERE clause and use the SUM aggregator function to add up all of their respective bin densities:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
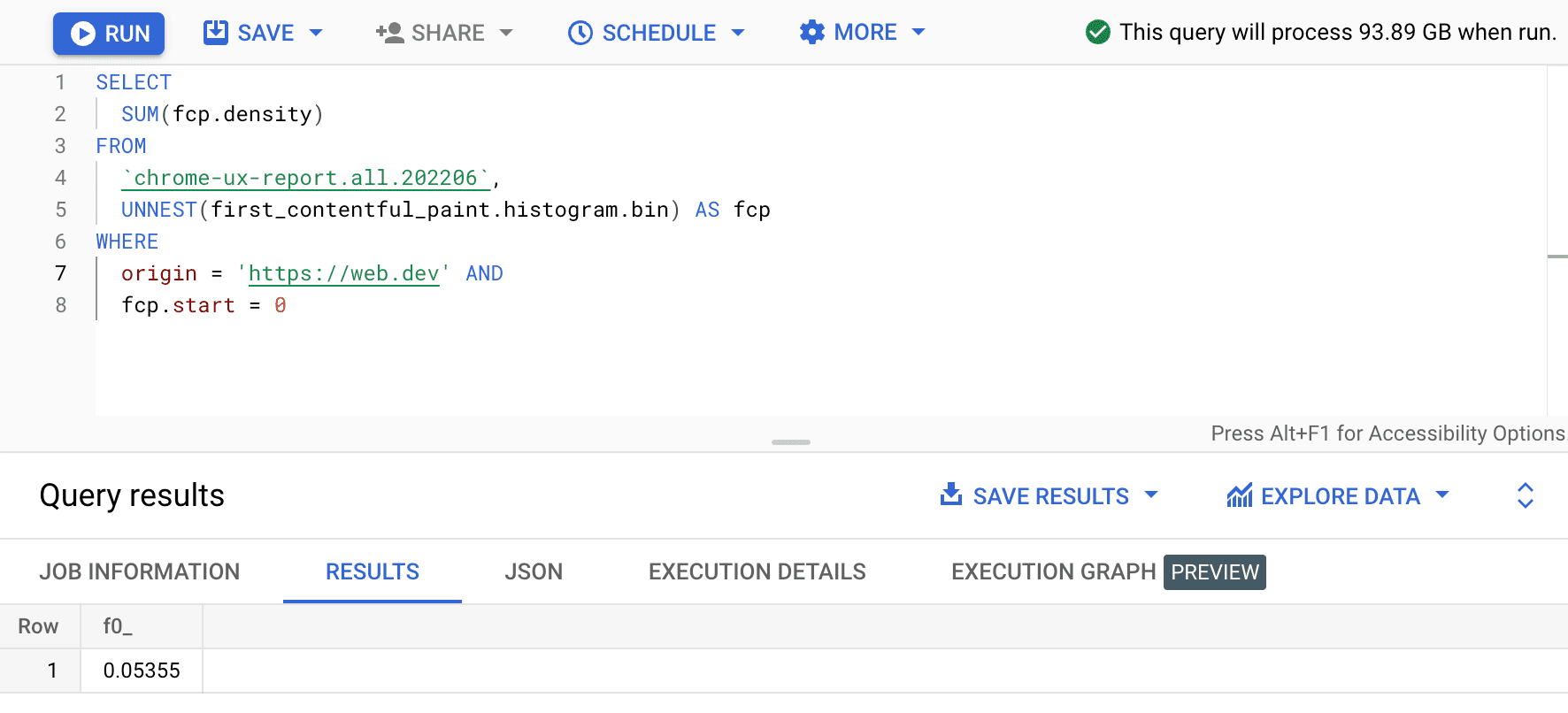
The result is 0.05355, or 5.355% across all devices and connection types. We can modify the query slightly and add up the densities for all bins that are in the "fast" FCP range of 0–1000ms:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
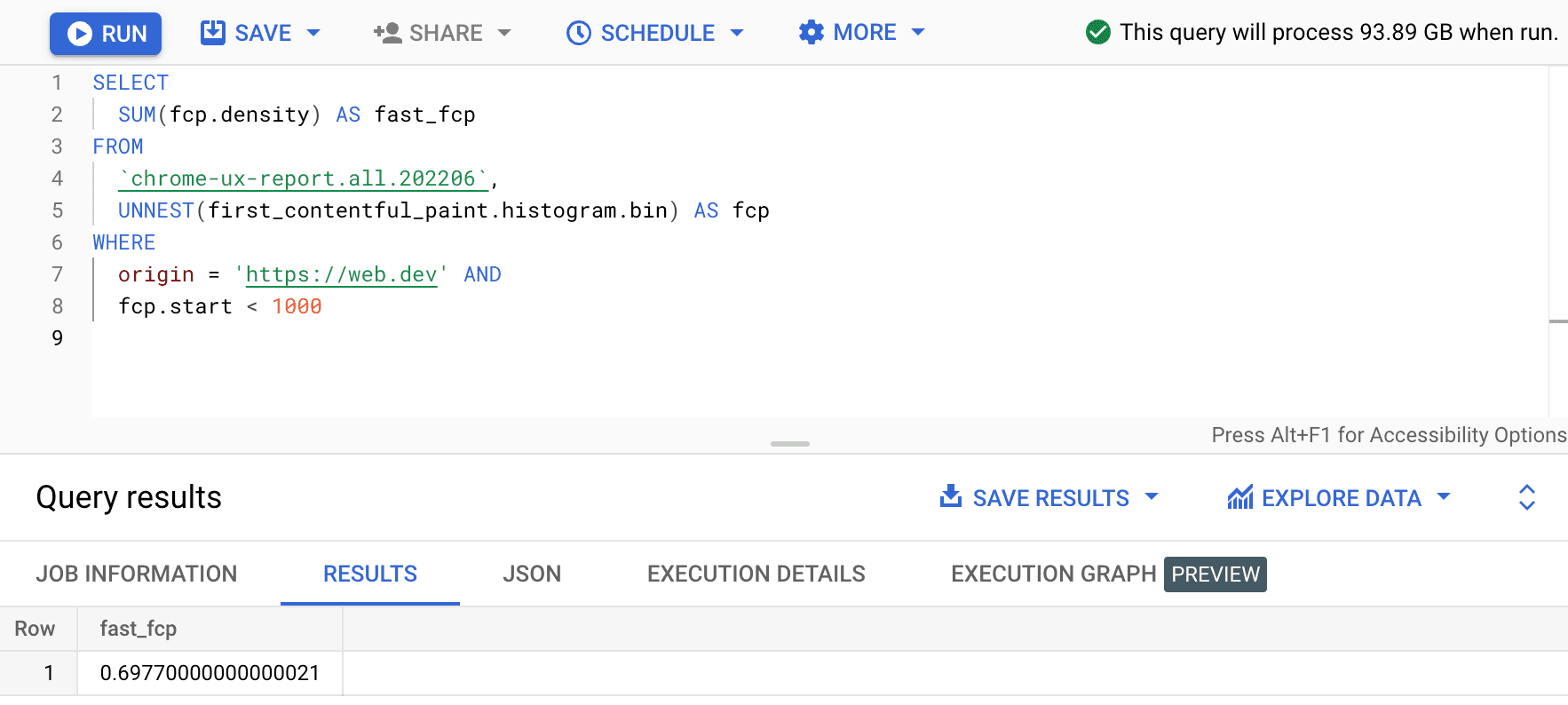
This gives us 0.6977. In other words, 69.77% of the FCP user experiences on web.dev are considered "fast" according to the FCP range definition.
Track performance
Now that we've extracted performance data about an origin, we can compare it to the historical data available in older tables. To do that, we could rewrite the table address to an earlier month, or we could use the wildcard syntax to query all months:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
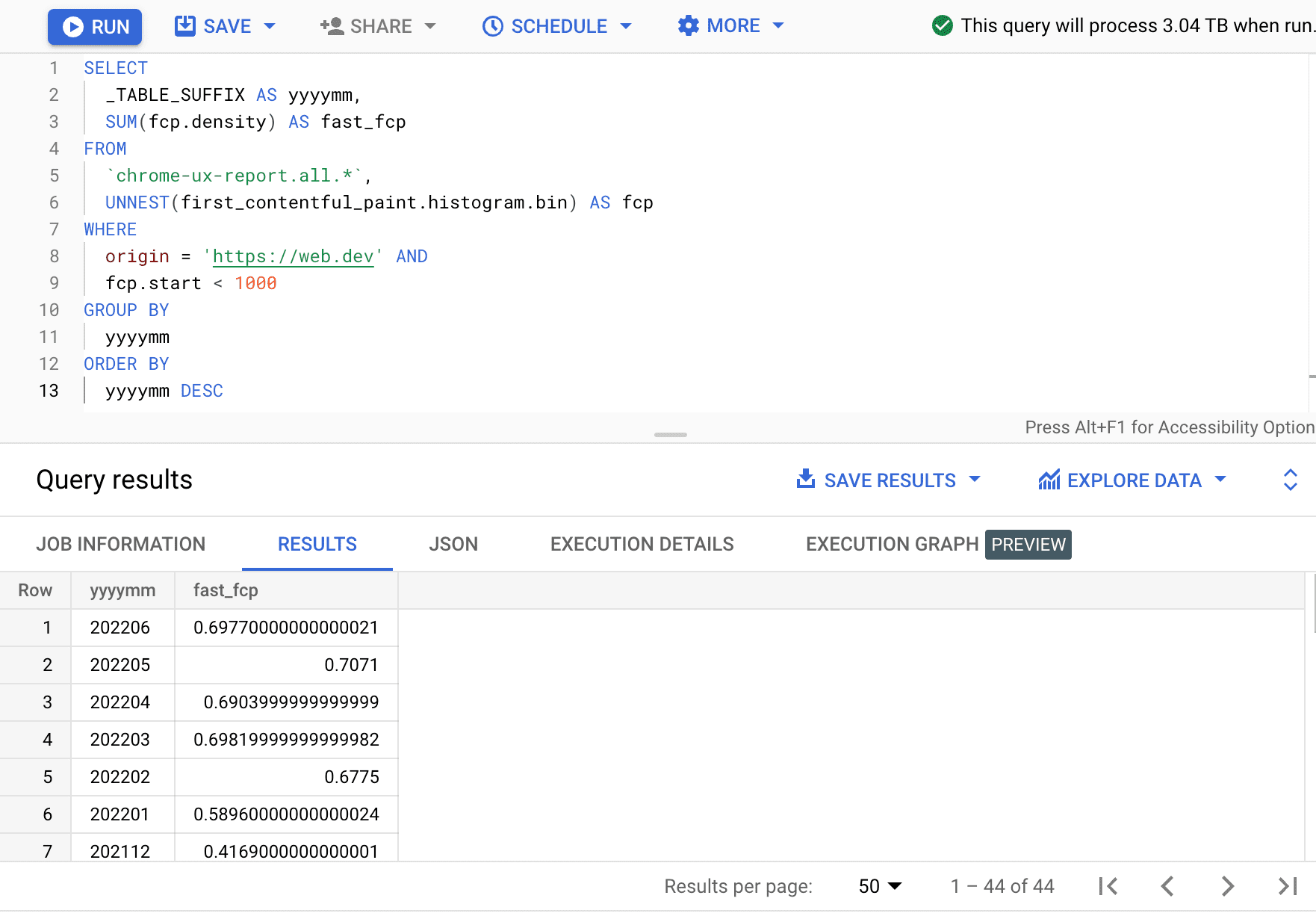
Here, we see that the percent of fast FCP experiences varies by a few percentage points each month.
| yyyymm | fast_fcp |
|---|---|
| 202206 | 69.77% |
| 202205 | 70.71% |
| 202204 | 69.04% |
| 202203 | 69.82% |
| 202202 | 67.75% |
| 202201 | 58.96% |
| 202112 | 41.69% |
| ... | ... |
With these techniques, you're able to look up the performance for an origin, calculate the percent of fast experiences, and track it over time. As a next step, try querying for two or more origins and comparing their performance.
FAQ
These are some of the frequently asked questions about the CrUX BigQuery dataset:
When would I use BigQuery as opposed to other tools?
BigQuery is only needed when you can't get the same information from other tools like the CrUX Vis and PageSpeed Insights. For example, BigQuery lets you slice the data in meaningful ways and even join it with other public datasets like the HTTP Archive to do some advanced data mining.
Are there any limitations to using BigQuery?
Yes, the most important limitation is that by default users can only query 1TB worth of data per month. Beyond that, the standard rate of $5/TB applies.
Where can I learn more about BigQuery?
Check out the BigQuery documentation for more info.